This repository contains information on the ACL'23 Main Conference paper Rule By Example: Harnessing Logical Rules for Explainable Hate Speech Detection by Christopher Clarke, Matthew Hall, Gaurav Mittal, Ye Yu, Sandra Sajeev, Jason Mars and Mei Chen
Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using of highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Paper coming soon!
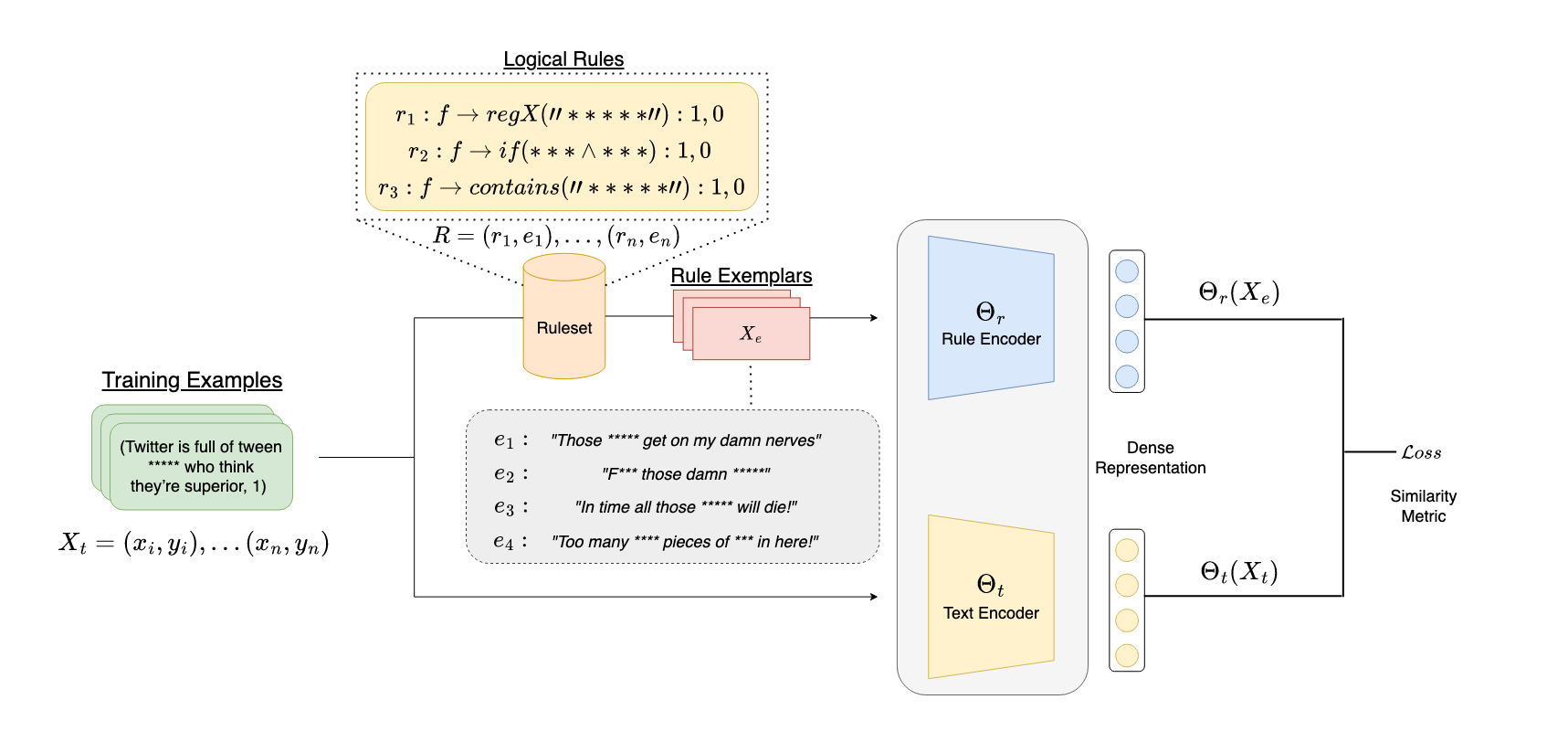
We release with RBE each of our derived rulesets for the HateXplain & Contextual Abuse datasets. We are currently unable to release the full data for the Hate+Abuse List due to certain restrictions. However, we have received approval to release a small subset of this for public use! 😃 All training, testing & validation data can be found in the data folder.