Training for new language
AntonFirc opened this issue · 11 comments
Hello,
as a part of my research I'm trying to train my own models for synthesis of Czech language, while training the synthesizer I ran into a weird behaviour I cannot really explain:
This is the latest output of the synthesizer training:
Step 92717 [2.414 sec/step, loss=0.36553, avg_loss=0.38032]
The loss nicely converges through the whole training, but the alignment plots are like this the whole training and the loss shown in the plots is steadily increasing and all of the alignment plots look like this:
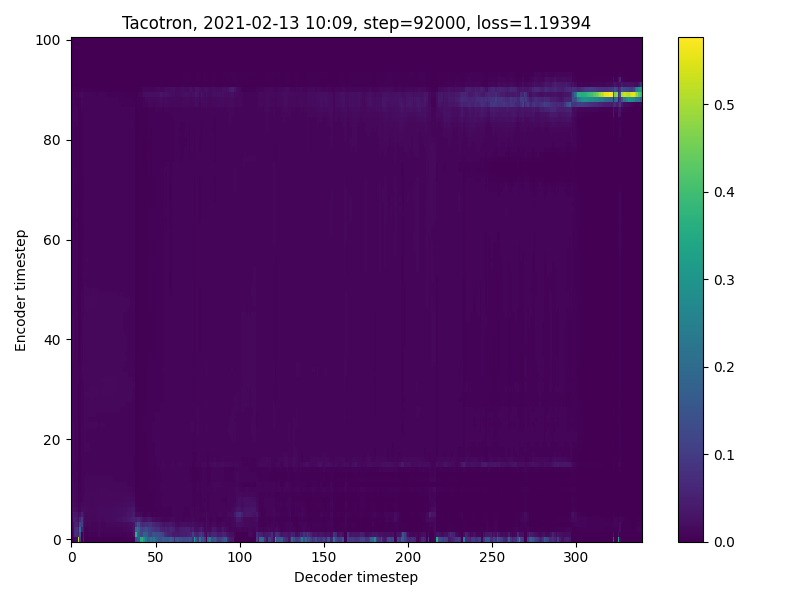
What wad done prior to synthesizer training:
- processed CommonVoice dataset (combined Czech, Polish, Slovenian, Ukrainian and Russian in order to get as many speakers as possible, all Slav languages)
- trained the encoder model for approx. 32k steps, with loss below 0.05 and EER below 0.004
- "translated" the Cyrrilic script of Russian and Ukrainian transcriptions to Latin
- added the extra symbols to
synthesizer/utils/symbols.py - changes eval sentences in
hparams.pyto Czech language
The generated wavs are okay-ish, the speech is understandable but even the best ones sound a bit robotic.
May the mismatch between the eval sentences language and majority of clips (Czech / Russian) cause the loss difference between training output and plots?
Why are all of the alignments plots almost exactly the same?
May this be any kind of "bug" in the eval scenario?
Thank you for any recommendations or thoughts on this topic!
Train the synthesizer on a single language dataset. The different languages are confusing the attention mechanism. Alignment plots will look like that until attention has been learned (10-25k steps). It is important to use clean audio with consistent quality between speakers.
Thanks for the reply! Did not know that, will try.
Unfortunately, the single language dataset contains only 36hrs of speech with 302 speakers, which is from my observations not enough to achieve good results thus training from scratch seems as a waste of time..?
I'm thinking of resuming the training but just with one language.. is there a chance this approach will work?
The model will be usable with 300 speakers. You can go to my webpage and compare results for RTVC-4 (1172 speakers) and RTVC-5 (109 speakers). https://blue-fish.github.io/experiments/RTVC-5.html
You can resume training on 1 language, but I suggest restarting from scratch and observing the process from the beginning.
Okay, thanks for sharing the knowledge. Will post an update about achieved results.
Hi @blue-fish , following your advice I managed to get the attention plots to show the desired line, however it still does not reach both corners and the loss started to diverge again:
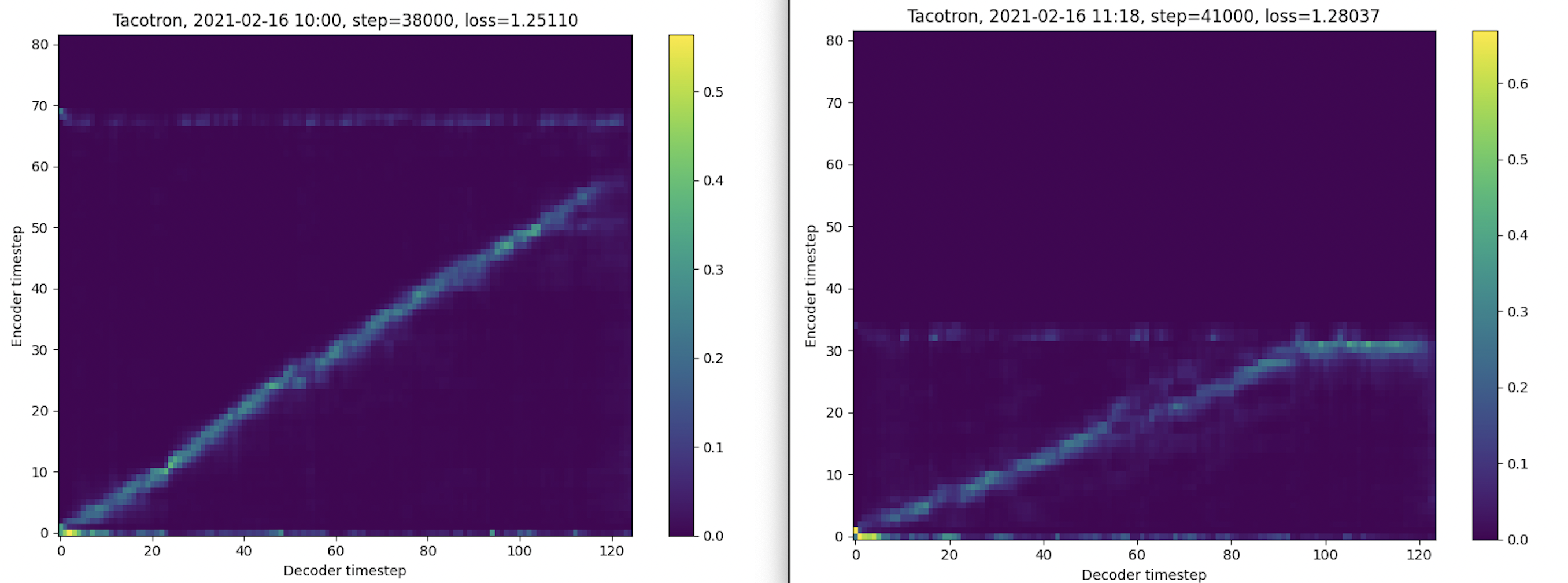
Step 41645 [1.985 sec/step, loss=0.42938, avg_loss=0.38850]
I stripped the dataset of other languages, and left Czech only. Afterwards I tried to remove silences from the clips. I removed the silence using VAD, and I tried to strip everything before 95% of frames contained audio, and everything after 30% of frames were silent again. This way I might have spit some sentences in half if there was longer pause between words or because of a comma.
The eval-generated wavs contain huge amount of silence at the end, almost 50/50 speech/silence at the end. Is that normal?
Also, the speech sounds very much robotic.
So I am wondering whether the 40k steps are not enough to get things right and I should continue the training or it's just a waste of time?
Why even after the silence removal (and quite aggressive one) the attention line suddenly ends in 3/4 of the plot?
Might the encoder model be the key to this disaster ... with only 32k trained steps?
I just found one interesting thing:
The alignment plots I posted here are from <model-dir>/eval-dir/plots. But when I look into the <model-dir>/plots there are plots created with the model backup, the plots saved there look much better and the loss is below 0.5. Even the wavs in <model-dir>/wavs sound fairly normally.
What is the difference between these folders, and what is the difference between the plots and wavs in those folders?
Tacotron has separate modes for training and inference. Recall that the decoder is autoregressive: the previous mel frame is used to predict the next one. The decoder runs in teacher-forcing mode for training, where the previous frames come from the ground truth. This ensures the predicted mel has the same shape as the ground truth, allowing loss to be calculated. The use of ground truth in teacher forcing makes the model appear better than it really is. The audio in <model-dir>/wavs comes from teacher forcing.
When synthesizing unseen text, Tacotron runs in inference mode. Since you don't have a ground truth, Tacotron feeds back its own mel outputs to the decoder. In the early stages of training a model, the decoder is not good. Any errors in output propagate to future frames and it eventually breaks down. This explains your 50/50 speech and silence that you observe for eval. It will get better with more steps.
For training, the lines in attention plots usually stop somewhere in the middle. This is because the text sequences and target spectrograms are padded to make use of batching. If the input text is padded, the line does not go to the top. If the spectrogram is padded, the line becomes horizontal before reaching the right side.
I am unavailable to answer further questions on this subject. Feel free to ask anyway in case someone else from the community can help. You are encouraged to read the papers (1712.05884, 1806.45558) and study the code.
@AntonFirc did you manage to train it to an acceptable degree in the end? Many slavic languages seem to have this problem...
@dumblob I did manage to get some usable output; however, the attention plots remained distorted. You can look here at the synthesized samples in the Czech language. I plan to look into this problem once again as I have a few ideas on improving the final quality. Are you working on something related?
@dumblob I did manage to get some usable output; however, the attention plots remained distorted. You can look here at the synthesized samples in the Czech language.
Thanks.
I plan to look into this problem once again as I have a few ideas on improving the final quality.
Feel free to share your findings, I'd be interested in them.
Are you working on something related?
Nothing serious - I'm just looking for a way to have offline home automation with voice assistant which shall have "flavours" depending on the liking of the users.
@AntonFirc Did you make any progress? I am specifically interested in Czech language, is there a way to train a usable model?