Large Language Model based Long-tail Query Rewriting in Taobao Search
Opened this issue · 0 comments
淘宝主搜 | 大模型在长尾Query改写召回上的实践
- 参考论文:Large Language Model based Long-tail Query Rewriting in Taobao Search
- 公司:淘宝主搜
- 链接:https://arxiv.org/pdf/2311.03758.pdf
- 会议:WWW2024 under review
太长不看
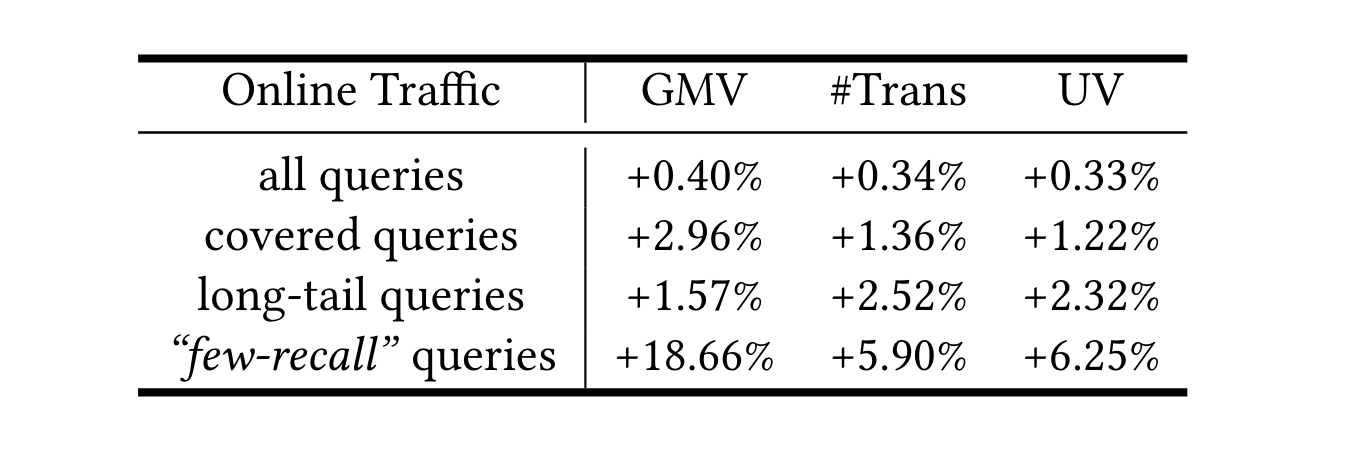
淘宝主搜把通义千问大模型应用在Query改写上,去改善那些低资源query上的召回效果。2023年10月就已经推全。14天的AB指标如下,GMV,订单和UV都有明显增长(比上一代重写模型CLE-QR高出0.4%、0.34%和0.33%,意味着为淘宝搜索贡献了数百万GMV),特别是在低资源query上。注意,基于LLM改写query的覆盖面仅占比30%左右,但是还是撬动了大盘。
具体方法
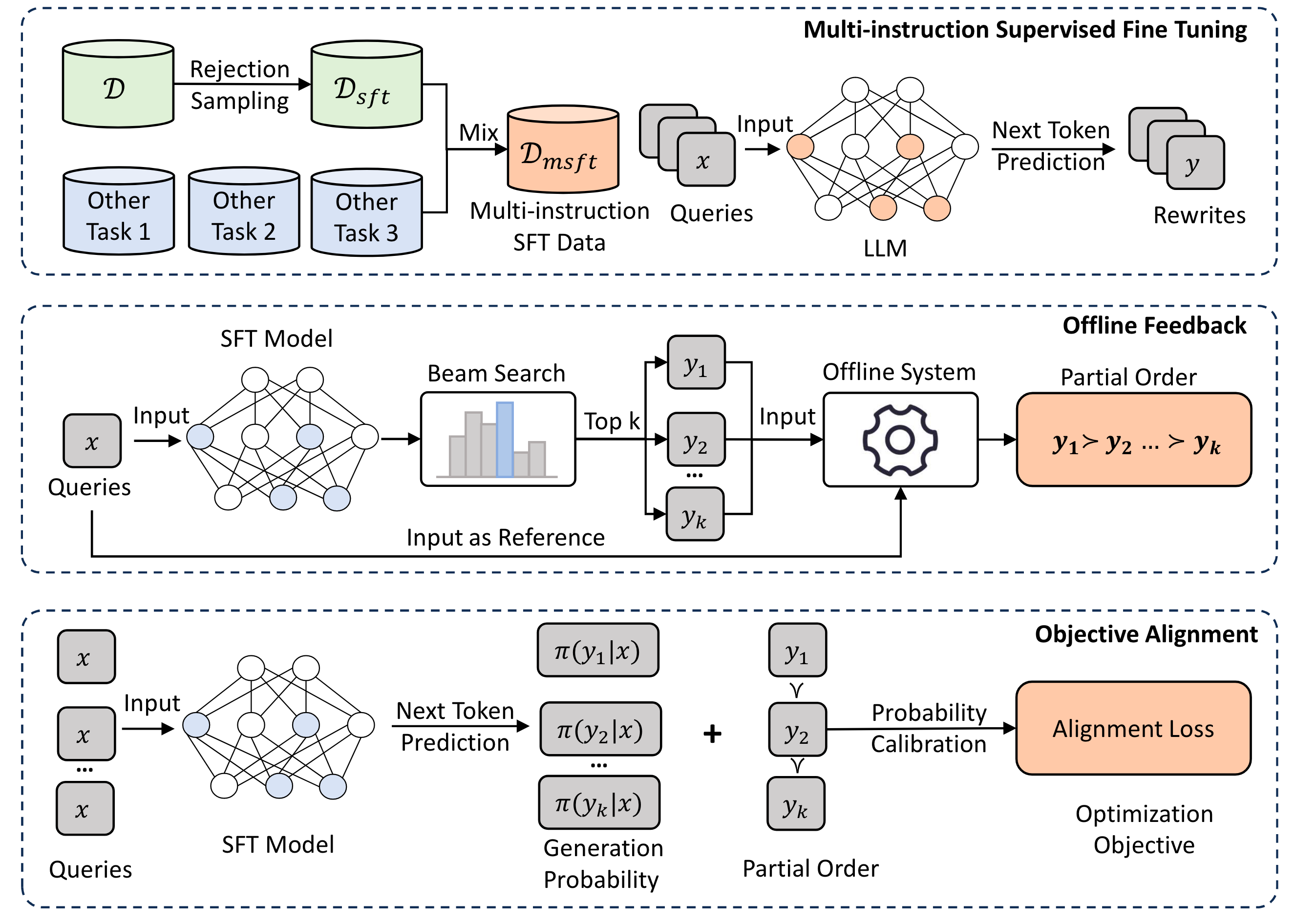
多指令数据集构建+SFT
- 步骤一:构建查询改写数据集$\mathcal{D}$: 利用线上的query改写策略$\pi$去生成(查询$x$,改写$y$) pair对,从而采样一批数据。
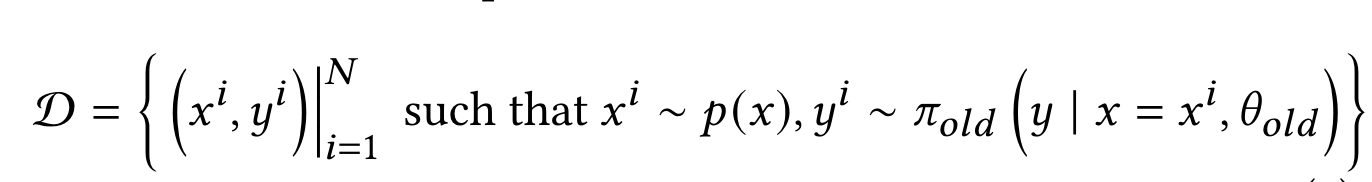
- 步骤二:带相关性约束的拒绝采样策略:保证改写结果和原query之间的相关性,引入了相关性指标去过滤。其中$rele(\cdot)$表示判断相关性方法,$\tau$就是阈值。
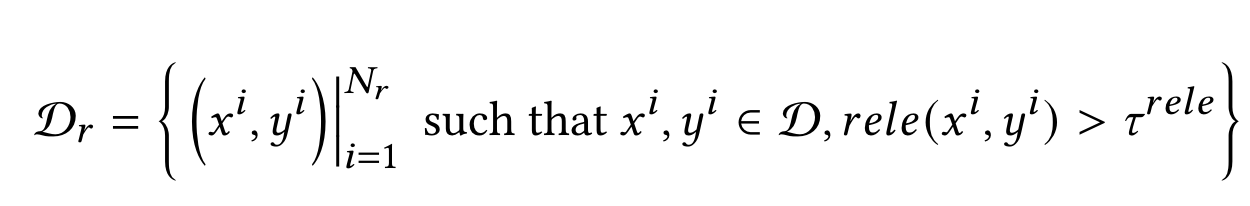
- 步骤三:带增量约束的拒绝采样策略:为了确保重写可以在一定程度上扩展原始查询的语义含义,避免低资源query的问题,定义了一个“增量”指标$incr$去过滤。同时还引入该query下交互多的(比如点击)的商品的标题$\mathcal{E_x}$加入数据集作为语义补充。
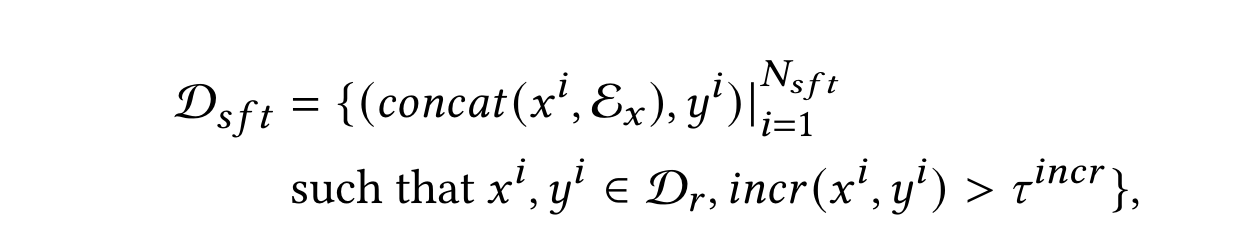
- 步骤四:构建辅助任务(质量分类)指令数据集:从线上日志去捞(查询,改写)pair对,构建prompt,然后让人工标注判断是否相关。

- 步骤五:构建辅助任务(商品标题预测)指令数据集:用query和query下最高后验的商品标题构建(query, title) pair对,并组织成prompt形式。(注意:这里可能原文prompt写错了)

- 步骤六:构建辅助任务(CoT)指令数据集:让人工标注去对query生成重写,并补充CoT过程,最后形成如下的prompt。

- 步骤七:SFT过程:将上述数据集混合在一起,在LLM上进行SFT过程(自回归生成)。和经典的SFT过程一样,LLM的prefix被固定住,不计算loss。其中$\pi$表示基于LLM的query改写模型。
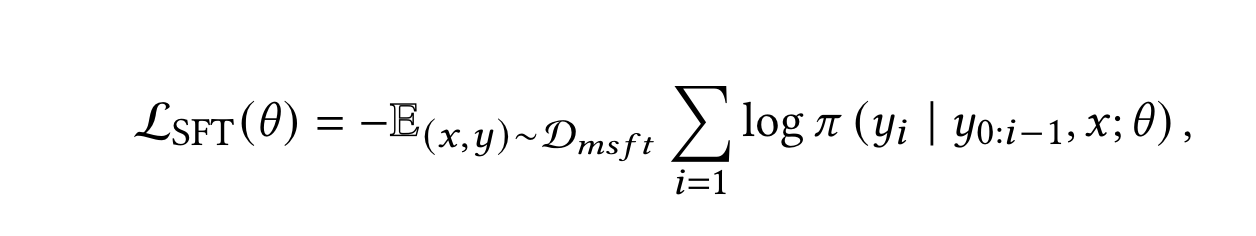
离线反馈指标
定义了三个指标(相关性,增量,全域成交hitrate)来衡量改写质量,用于alignment过程的评估。其中相关性、增量也被用于步骤二和三的过滤策略。
这三个指标在淘宝搜索的离线系统上运行,即模拟线上请求query,通过SFT后的LLM获取改写结果,然后将这些重写结果和线上query送进离线系统,获取检索结果,并通过这三个指标去评估改写质量,从而得到重写结果的偏序关系。
- 相关性指标:在改写query的检索结果中,利用相关性模型计算原始query和检索商品标题的相关性。该指标表示相关性大于阈值的数量在改写query的检索结果中的比例。比例越高,说明改写query和原始query的语义gap越小。
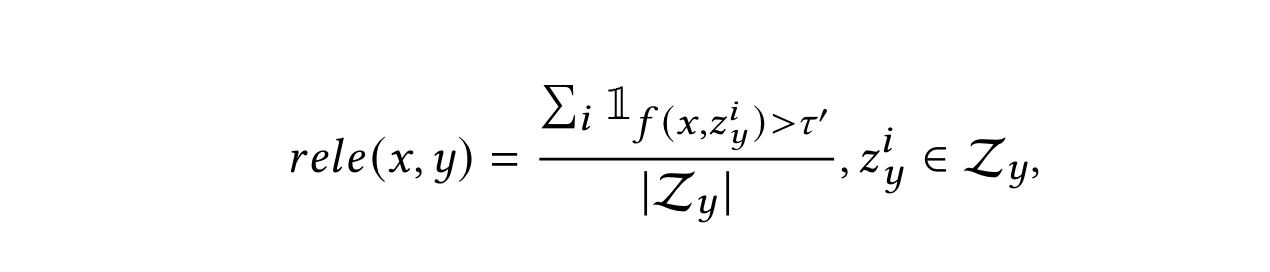
- 增量指标:确保重写可以在一定程度上扩展原始查询的语义含义,避免低资源query的问题而定义的。$\mathcal{Z_e}$是淘宝自己定义的该query下质量高的检索结果合集。笔者这里理解可能是精品库,比如历史上该query下成交率很高的商品库之类的。这个指标表示改写query的检索结果中属于“精品”库且相关性大于阈值的数量 与 “基线”的比例。比例越高,说明改写query能够带来的增量越高。

- 全域成交hitrate指标:$\mathcal{E}$表示在搜索场景外的成交商品集合。$\mathcal{Z_x}$和$\mathcal{Z_y}$表示离线检索系统中利用原始query和改写query检索到的商品集合。假设一个商品在搜索场中并未被交易,但是与当前用户的query在语义上有关联。这说明原始query没有成功检索到该产品。然而,如果改写query能返回该商品,那就意味着该商品存在于$\mathcal{Z_x} \cup \mathcal{Z_y}$中。这证明了改写query确实能够弥补原始query丢失的某些语义。
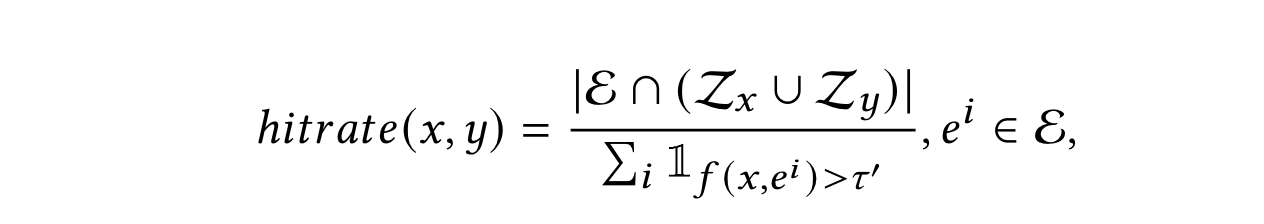
基于PRO算法的alignment
这部分详细的细节可以看阿里出的这篇论文:Preference Ranking Optimization for Human Alignment
为了避免通过reward model引入bias,引入了基于Bradley Terry模型的偏好排名优化(PRO)。该方法旨在强制模型学习离线反馈提供的query改写结果的偏序关系。根据Bradley Terry模型,选择策略的概率应与其相应的奖励成比例。给定一个偏序关系$y_1>y_2$,preference概率则表示为:
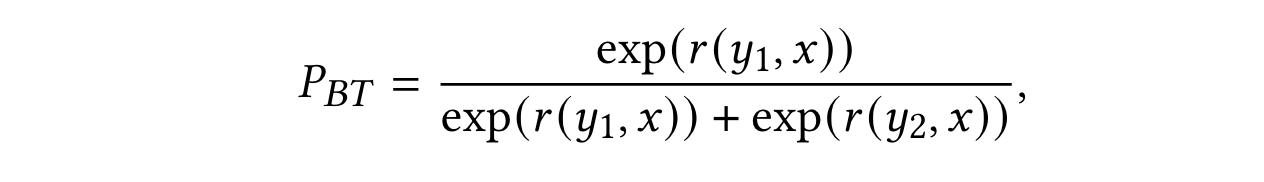
在PRO中,$r(\cdot)$是奖励函数,定义为LLM生成的改写的归一化对数概率。PRO将这个pair-wise的偏序关系扩展到更一般的list-wise偏序。此外,引入温度以捕捉基于奖励的排序的重要性。PRO损失由以下方程表示:
其中$\mathcal{T_k^i}=1/(r(y_k)-r(y_i))$和$\mathcal{T_k^k}=\min_{i>k}{\mathcal{T_k^i}}$表示排序差异。$\mathcal{D_{PRO}}$是用于alignment的数据集,$\pi_{PRO}$就是策略模型,$n$是候选改写的数量。
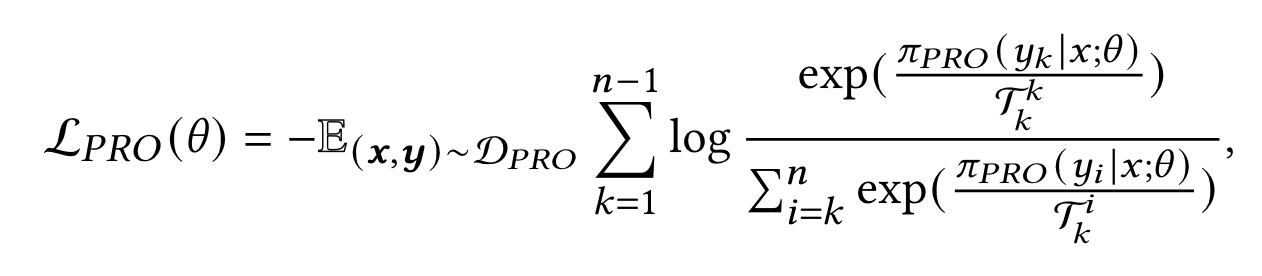
alignment过程中的最终loss即为:
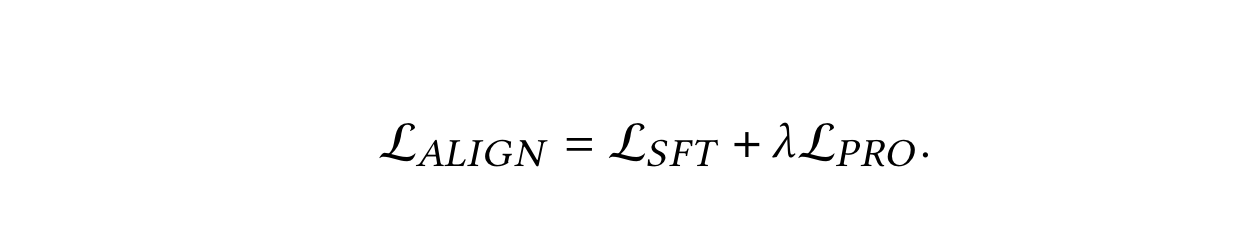
在线serving
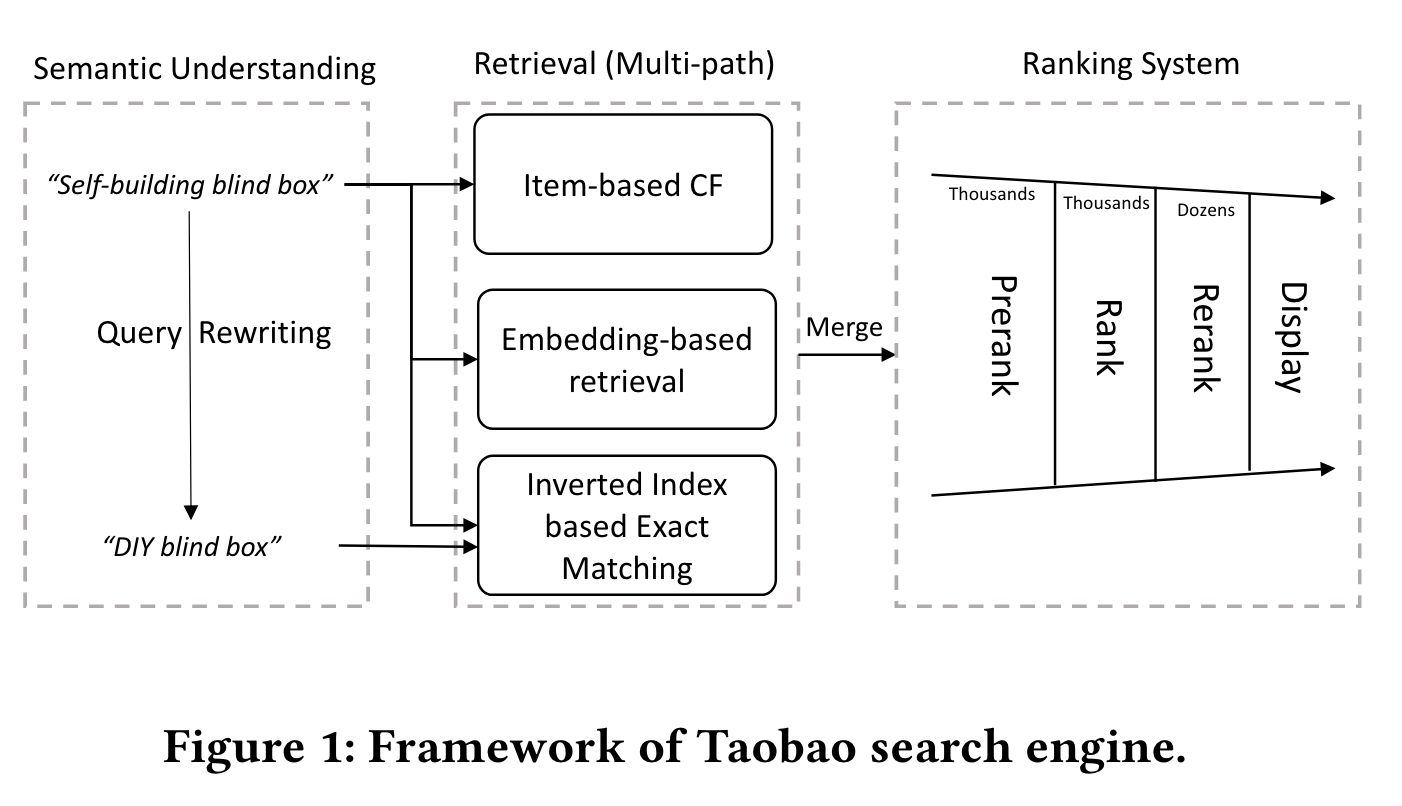
起一个离线任务收集低资源query (业务自己去定义,文中说的是query下检索结果70%不相关或者结果数量少于1w),用LLM进行改写,存到redis里面。线上serving,命中redis中query的,相应改写结果会用于倒排索引补充召回。
数据集和执行细节
训练集
-
SFT过程:从2023年9月前的线上改写日志里面捞了20 million的记录。然后执行了两轮拒绝采样,获得了419,806个<query, rewrite>pair对。此外将155,662个手动重写数据包含在数据集中,以确保SFT模型的重写符合人类偏好。最后,将质量分类、商品标题预测和CoT任务中的每个任务各选取了50,000个样本,并与查询重写数据集结合,构建了多指令SFT数据集。
-
alignment过程:从查询重写数据集中随机选择了10,000个查询。对于每个查询,我们使用SFT模型生成5个候选查询。这些50,000个重写结果随后使用淘宝离线系统进行评分。在去除任何异常值后,对齐训练数据集共包含45,350个候选重写。
测试集
对于离线测试集,从淘宝搜索日志中选择了14,981个查询来评估模型的性能。其中,50%的查询是按实际查询比例随机抽样的。此外,为了评估模型重写长尾查询的能力,从长尾查询中抽样了剩余50%的数据。
执行细节
用于模型训练的优化器是AdamW。在多指令SFT阶段,模型的学习率设置为1e-5,进行一次epoch的训练。在目标对齐阶段,模型的学习率设置为1e-6,进行四次epoch的训练。此外,重写任务的提示最大长度设置为64,而其他任务的最大长度设置为256。
离线结果
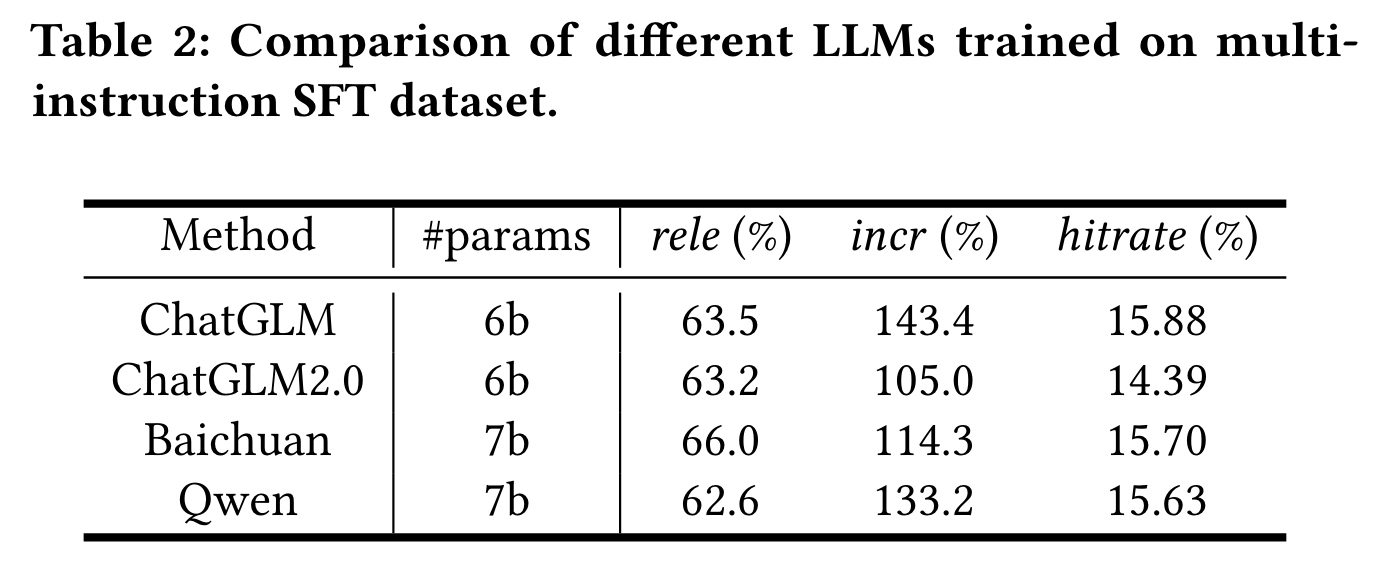
版权限制加上千问有电商数据预训练,所以就用了千问模型作为基座。
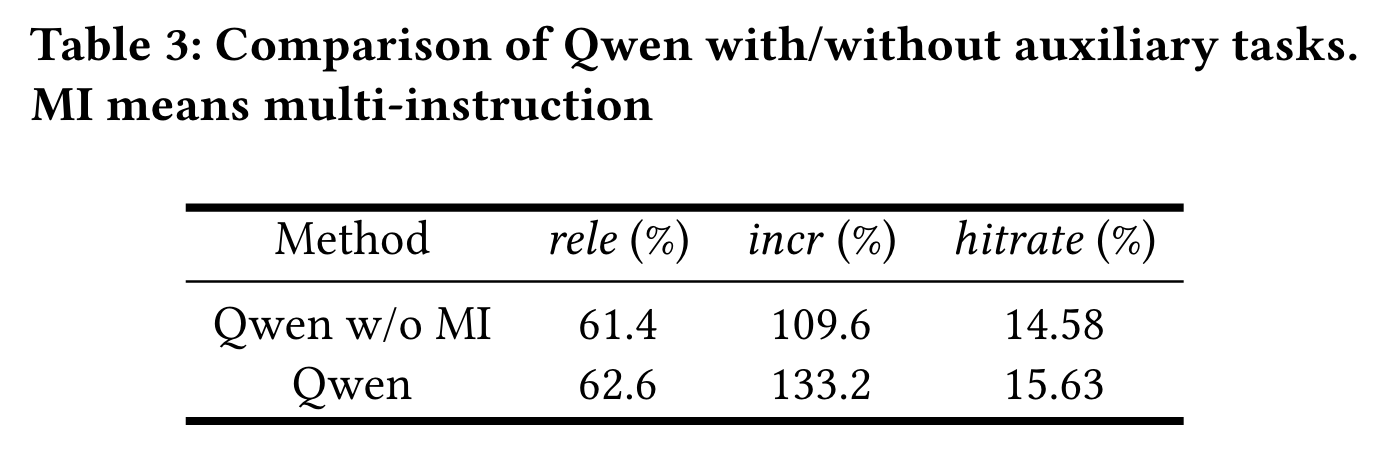
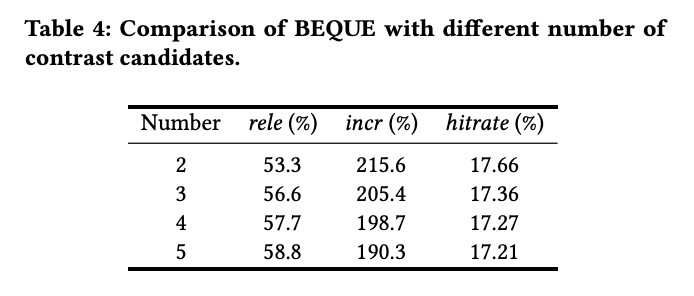
对齐过程中的候选重写数量也做了消融。
这里抄了下翻译,简单看看即可。
将BEQUE与多个基准进行比较,包括CLE-QR、query2doc(Q2D)、BART、Qwen和基于RL的LLM。CLE-QR是淘宝搜索的上一代查询重写器,它基于对比学习生成语义表示并检索相关的重写。BART是一种基于编码器-解码器结构的强大预训练生成模型。我们使用在线日志中的查询对对其进行微调,以增强其重写电子商务查询的能力。Qwen是一种基于解码器结构的大规模语言模型,包含70亿个参数。同样,我们使用在线日志中的查询pair对其进行微调,以增强其重写电子商务查询的能力。此外,引入了基于RL的LLM,并利用相关性、增量和hitrate作为奖励,鼓励RL模型对齐。

结论如下:
- 生成模型在“Torso”和“Tail”查询情景下优于判别模型
- LLM模型相比小型模型表现出更优秀的长尾语义理解能力
- 检索增强方法展示了有限的语义扩展能力
- 强化学习(RL)可能会引入偏差并影响重写LLMs的有效性
- 不同的离线指标在奖励方面有不同的作用