ElenaPolitov001's Stars
steveloughran/spark-test-failures
steveloughran/icloud_photos_downloader
A command-line tool to download photos from iCloud
steveloughran/datasets
datasets of things. Licence: Creative Commons 2.0. Use with Accreditation
steveloughran/languages
Play with random languages of the Past of Software
steveloughran/hadoop-connectors
Libraries and tools for interoperability between Hadoop-related open-source software and Google Cloud Platform.
steveloughran/spark-timeline-integration
SPARK-1537 standalone: timeline server integration
steveloughran/hadoop
Mirror of Apache Hadoop
steveloughran/spark
Mirror of Apache Spark
CYH1370/https-github.com-steveloughran-winutils
win bin hadoop
steveloughran/steveloughran.github.io
stevelou0624/stevelou0624.github.io
stevelou
apache/hadoop
Apache Hadoop
JonasAmiri/CreateAccessToDatabase
etherceo1x1/Free-CAD
ElenaPolitov001/hyperbot
hyper bot
HippoRun/Burger
Node Express Handlebars Overview In this assignment, you'll create a burger logger with MySQL, Node, Express, Handlebars and a homemade ORM (yum!). Be sure to follow the MVC design pattern; use Node and MySQL to query and route data in your app, and Handlebars to generate your HTML. Important Be sure to utilize the MYSQL Heroku Deployment Guide in order to deploy your assignment. Before You Begin Eat-Da-Burger! is a restaurant app that lets users input the names of burgers they'd like to eat. Whenever a user submits a burger's name, your app will display the burger on the left side of the page -- waiting to be devoured. Each burger in the waiting area also has a Devour it! button. When the user clicks it, the burger will move to the right side of the page. Your app will store every burger in a database, whether devoured or not. Check out this video of the app for a run-through of how it works. Submission on BCS Please submit both the deployed Heroku link to your homework AND the link to the Github Repository! Instructions App Setup Create a GitHub repo called burger and clone it to your computer. Make a package.json file by running npm init from the command line. Install the Express npm package: npm install express. Create a server.js file. Install the Handlebars npm package: npm install express-handlebars. Install the body-parser npm package: npm install body-parser. Install MySQL npm package: npm install mysql. Require the following npm packages inside of the server.js file: express body-parser DB Setup Inside your burger directory, create a folder named db. In the db folder, create a file named schema.sql. Write SQL queries this file that do the following: Create the burgers_db. Switch to or use the burgers_db. Create a burgers table with these fields: id: an auto incrementing int that serves as the primary key. burger_name: a string. devoured: a boolean. Still in the db folder, create a seeds.sql file. In this file, write insert queries to populate the burgers table with at least three entries. Run the schema.sql and seeds.sql files into the mysql server from the command line Now you're going to run these SQL files. Make sure you're in the db folder of your app. Start MySQL command line tool and login: mysql -u root -p. With the mysql> command line tool running, enter the command source schema.sql. This will run your schema file and all of the queries in it -- in other words, you'll be creating your database. Now insert the entries you defined in seeds.sql by running the file: source seeds.sql. Close out of the MySQL command line tool: exit. Config Setup Inside your burger directory, create a folder named config. Create a connection.js file inside config directory. Inside the connection.js file, setup the code to connect Node to MySQL. Export the connection. Create an orm.js file inside config directory. Import (require) connection.js into orm.js In the orm.js file, create the methods that will execute the necessary MySQL commands in the controllers. These are the methods you will need to use in order to retrieve and store data in your database. selectAll() insertOne() updateOne() Export the ORM object in module.exports. Model setup Inside your burger directory, create a folder named models. In models, make a burger.js file. Inside burger.js, import orm.js into burger.js Also inside burger.js, create the code that will call the ORM functions using burger specific input for the ORM. Export at the end of the burger.js file. Controller setup Inside your burger directory, create a folder named controllers. In controllers, create the burgers_controller.js file. Inside the burgers_controller.js file, import the following: Express burger.js Create the router for the app, and export the router at the end of your file. View setup Inside your burger directory, create a folder named views. Create the index.handlebars file inside views directory. Create the layouts directory inside views directory. Create the main.handlebars file inside layouts directory. Setup the main.handlebars file so it's able to be used by Handlebars. Setup the index.handlebars to have the template that Handlebars can render onto. Create a button in index.handlebars that will submit the user input into the database. Directory structure All the recommended files and directories from the steps above should look like the following structure: . ├── config │ ├── connection.js │ └── orm.js │ ├── controllers │ └── burgers_controller.js │ ├── db │ ├── schema.sql │ └── seeds.sql │ ├── models │ └── burger.js │ ├── node_modules │ ├── package.json │ ├── public │ └── assets │ ├── css │ │ └── burger_style.css │ └── img │ └── burger.png │ │ ├── server.js │ └── views ├── index.handlebars └── layouts └── main.handlebars Reminder: Submission on BCS Please submit both the deployed Heroku link to your homework AND the link to the Github Repository! Minimum Requirements Attempt to complete homework assignment as described in instructions. If unable to complete certain portions, please pseudocode these portions to describe what remains to be completed. Hosting on Heroku and adding a README.md are required for this homework. In addition, add this homework to your portfolio, more information can be found below. Hosting on Heroku Now that we have a backend to our applications, we use Heroku for hosting. Please note that while Heroku is free, it will request credit card information if you have more than 5 applications at a time or are adding a database. Please see Heroku’s Account Verification Information for more details. Create a README.md Add a README.md to your repository describing the project. Here are some resources for creating your README.md. Here are some resources to help you along the way: About READMEs Mastering Markdown Add To Your Portfolio After completing the homework please add the piece to your portfolio. Make sure to add a link to your updated portfolio in the comments section of your homework so the TAs can easily ensure you completed this step when they are grading the assignment. To receive an 'A' on any assignment, you must link to it from your portfolio. One More Thing This is a really tough homework assignment, but we want you to put in your best effort to finish it. If you have any questions about this project or the material we have covered, please post them in the community channels in slack so that your fellow developers can help you! If you're still having trouble, you can come to office hours for assistance from your instructor and TAs. Good Luck!
ElenaPolitov001/community-skeleton
UVdesk Opensource Community Helpdesk Project built for all to make a Full Ticketing Support System along with many more other features.
uvdesk/community-skeleton
UVdesk Opensource Community Helpdesk Project built for all to make a Full Ticketing Support System along with many more other features.
ElenaPolitov001/laravel-crm
Free & Opensource Laravel CRM solution for SMEs and Enterprises for complete customer lifecycle management.
krayin/laravel-crm
Free & Opensource Laravel CRM solution for SMEs and Enterprises for complete customer lifecycle management.
AnimeshMondol/CSE299-Project
# SU19CSE299S02G05 <p align="center"> <img width="200" height="200" src="https://media.licdn.com/dms/image/C560BAQEFJPl7DXD1Dg/company-logo_200_200/0?e=2159024400&v=beta&t=4wzyvb7GBsvMovoet_LGS9uj_Gso_kmfWqCXnqydCDI"> </p> <h1 style="text-align: center">         North South University</h1> #        Project Name: Stop Food Waste **                      CSE299: JUNIOR DESIGN** **                        SEC: 02, Group: 05** **                Instructor:** **SHAIKH SHAWON AREFIN SHIMON (SAS3)** **                      Semester:** **Summer 2019** <br> **                        GROUP MEMBERS**                        1. **Animesh Mondol**                          **ID: 1611971042** **                   Email: animesh.sarkar02@northsouth.edu**                        2. **Shamsunnar Sumi**                          **ID: 1621762042**                    **Email: shamsunnar.sumi@northsouth.edu**           **GitHub Repository Link:** **https://github.com/AnimeshMondol/SU19CSE299S02G05NSU**                       **Date Prepared: 19/06/2019** <br><br><br><br><br> **Project Details:** Our project idea is Stop Food Waste. In our country during different program there are some large amount of food are being wasted. So we want to make a web app where people can donate that food to the poor needy people. With this web app we are trying to solve the problem of food faced by a certain amount of people in our country. We also want to use mobile phone access to the users so that they can use mobile phone to access the web page. **Features:** <br> **Login:** The system provides security features through email-password matching where only authorized user can access the system. **Admin Login:** In this part the manager will keep up the donated elements and donor details. He/ She will be able to know all the information and edit them. He/ She can assign people where to pick up the food from which will be shown in Google Map. 1. Add user 2. Remove user 3. View user 4. View request 5. Remove request 6. View donation 7. Confirm pickup location 8. Logout **User Login:** In this part user will be able to login and he/she will be able to see all the donor and there will be an option where user can be a donor. He/ She can also see the place in the map where to go, to pick up the food. **User Login:** 1. Donate food 2. Sign In 3. Become a donor 4. Send request 5. View request 6. About us 7. Contact us 8. Logout **Donate food:** In this part user can donote food by seeing the request id send by the other user. It will also contain a form where donor needs to add his name, mobile, email, req_id, quntity. By submitting the form it will take it to the user map for setup the location in the map. **Request for food:** In this part user can request for food to the website so that other user(donor) can donote food to them for donotion. **Donote Us** In this part user will have a option to donote us money if they want for the development purpose. In this part there will be Bkash and Rocket no where donors can donate us. It will contain a form where name,mobile,amount and transaction id will be asked to stored on DB. **View requests** Here user can see the pending requests for food. **About Us:** In this section there will be information about the program. **Contact Us** In this part there will be information about how to contact us and also there will be a part where user can poot comments and ask for help directly to the admin. **Technology:** HTML, PHP, CSS, Bootstrap template, My SQL Server, Google Map API. **Business Plan:** It is mainly a free to use for everyone. There will be no need for any amount of money to create an account in this webpage. But through Google AdSense we want to monetize the webpage. Also if any donor wants to donate some amount of money they can do it through Bkash , Rocket . <br><br> **Design:** We used the template of Bootstrap containing all the CSS and JS files downloaded from their website. We don't use any extra design in the webpage. But we used some image files to make the website look a little good. **Planning:** After selecting the project, we started our work by creating a UML diagram to make our work easy and it helped us to understand what we need to add or not in our website. Then we created issues in the project board. Then by weekly submission we tried to solve those issues. The project contains total of 43 closed issues which was used to make this website. All the details are shown in the project bord https://github.com/AnimeshMondol/SU19CSE299S02G05NSU/projects/1 **What did/didn't work:** Around 85-90% of our project run's very well. But we faced some problems. They are: 1. As we were unable to constract the foregin key in the DB after login the user need to input his name, mobile no , email and other informations manually. 2. For the donate us page under user, we didn't find any proper solution on how we can give the user the confermation about if his donation is received or not. So we manually take the name , mobile , the amount of money he donated and transaction id and store in the DB. 3. The admin map has some bugs that we were unable to fix. It doesn't refresh after the pickup confermation was done by the admin. 4. We wanted user to make the pickup request from his/her phone but we didn't able to make the website suitable for phones. **Screenshots:** 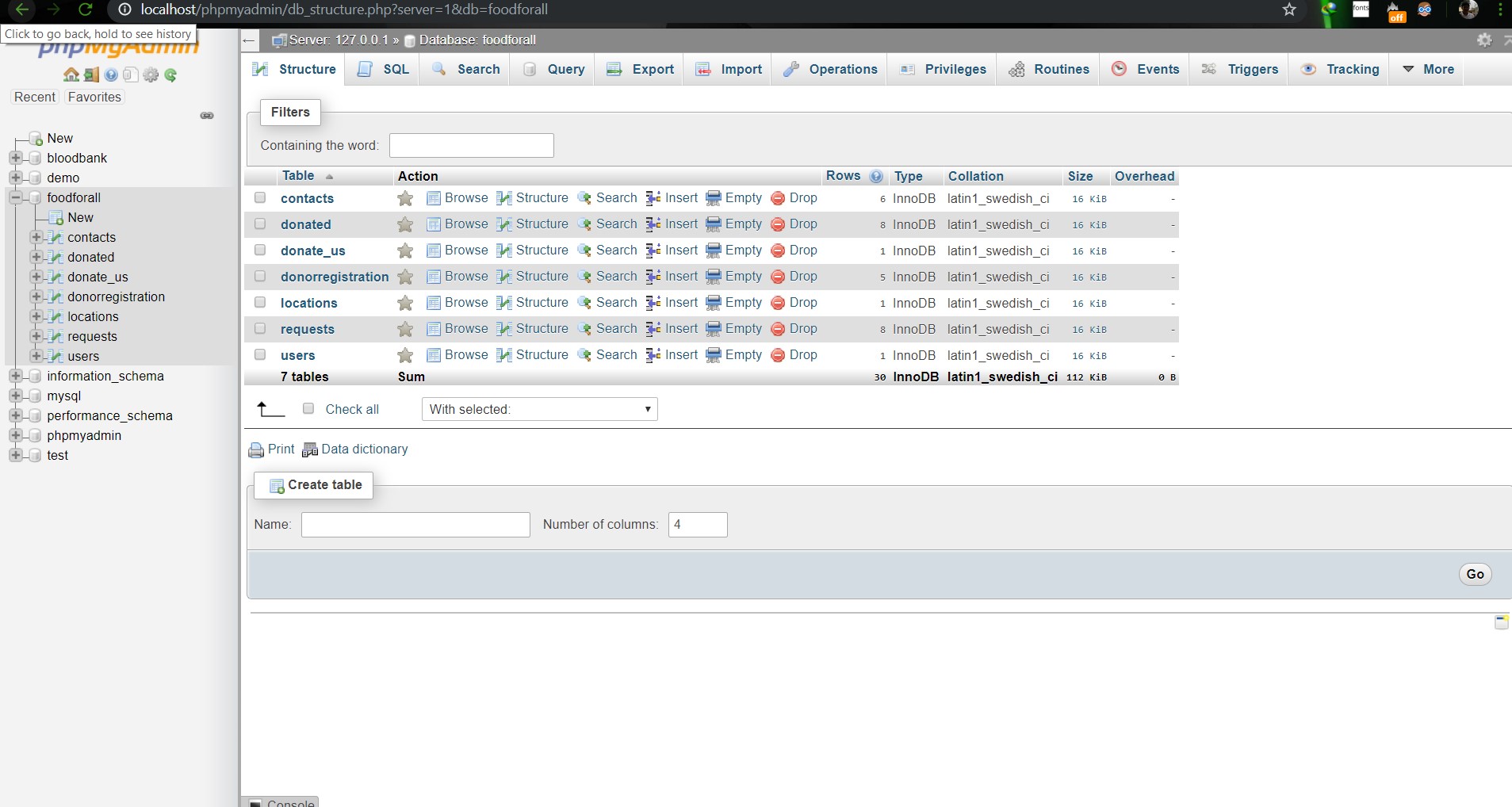                        **Image: DB(Foodforall)** <br> 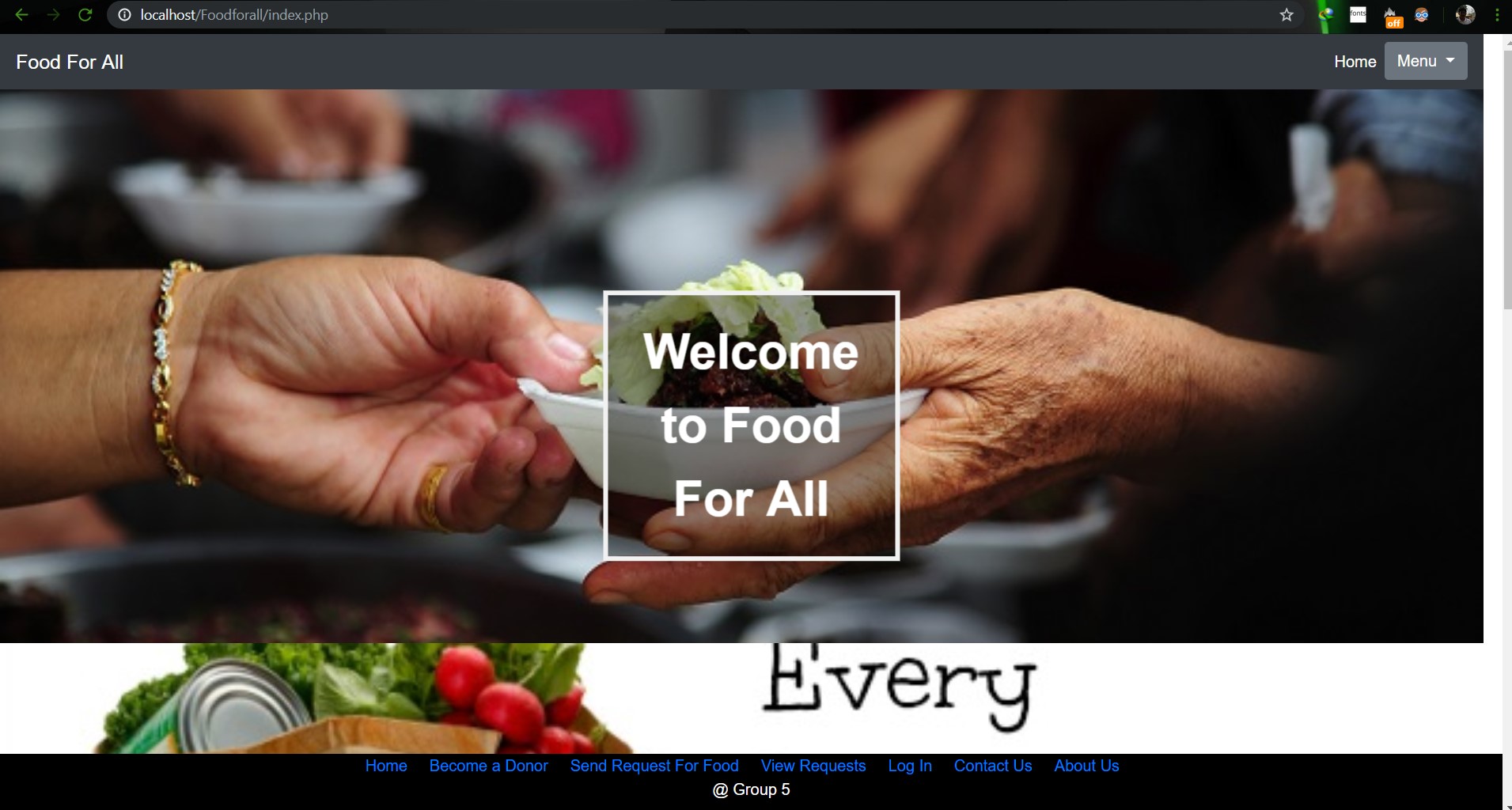                         **Image: Homepage** <br> 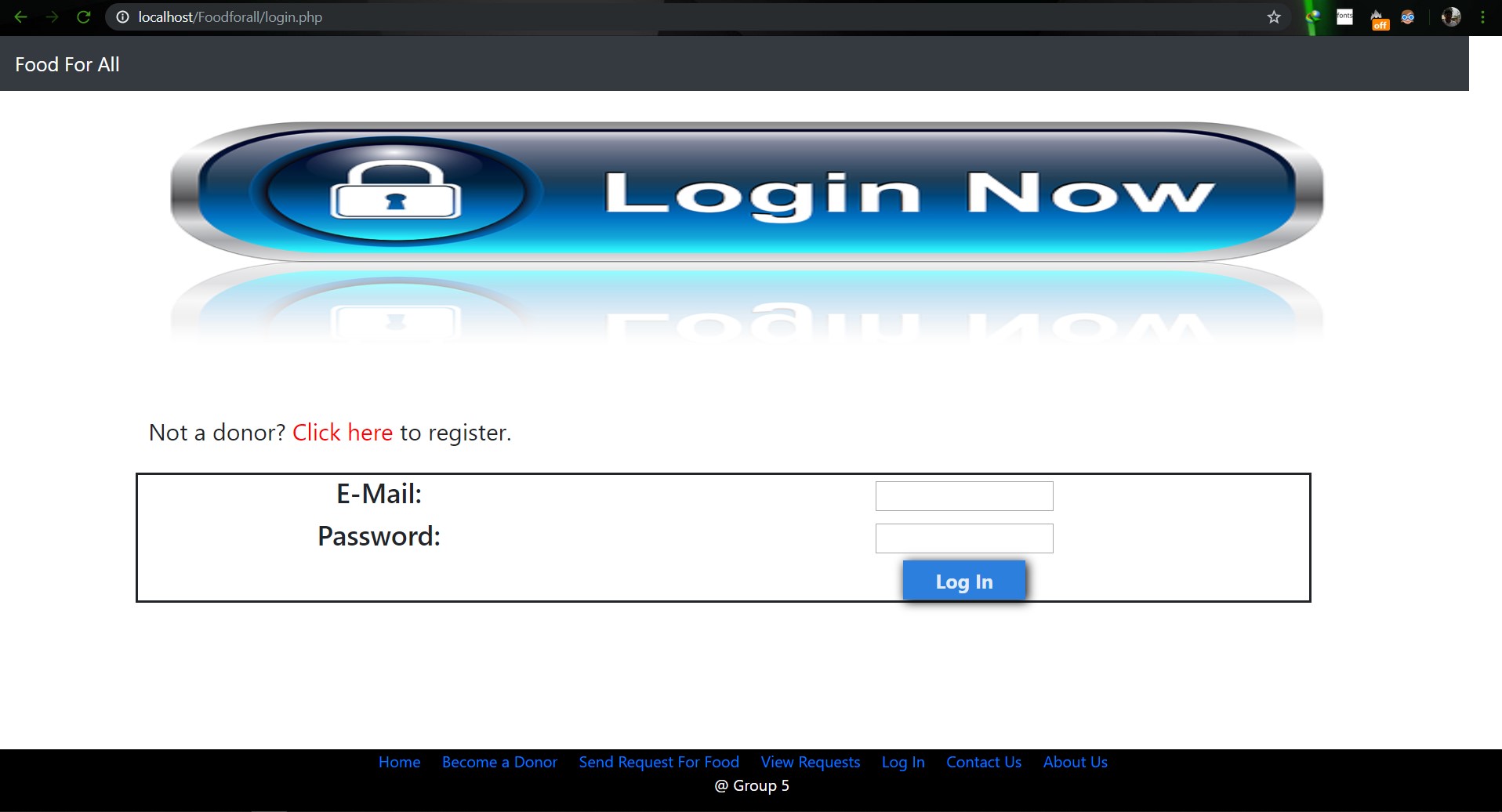                         **Image: Login Page** <br> 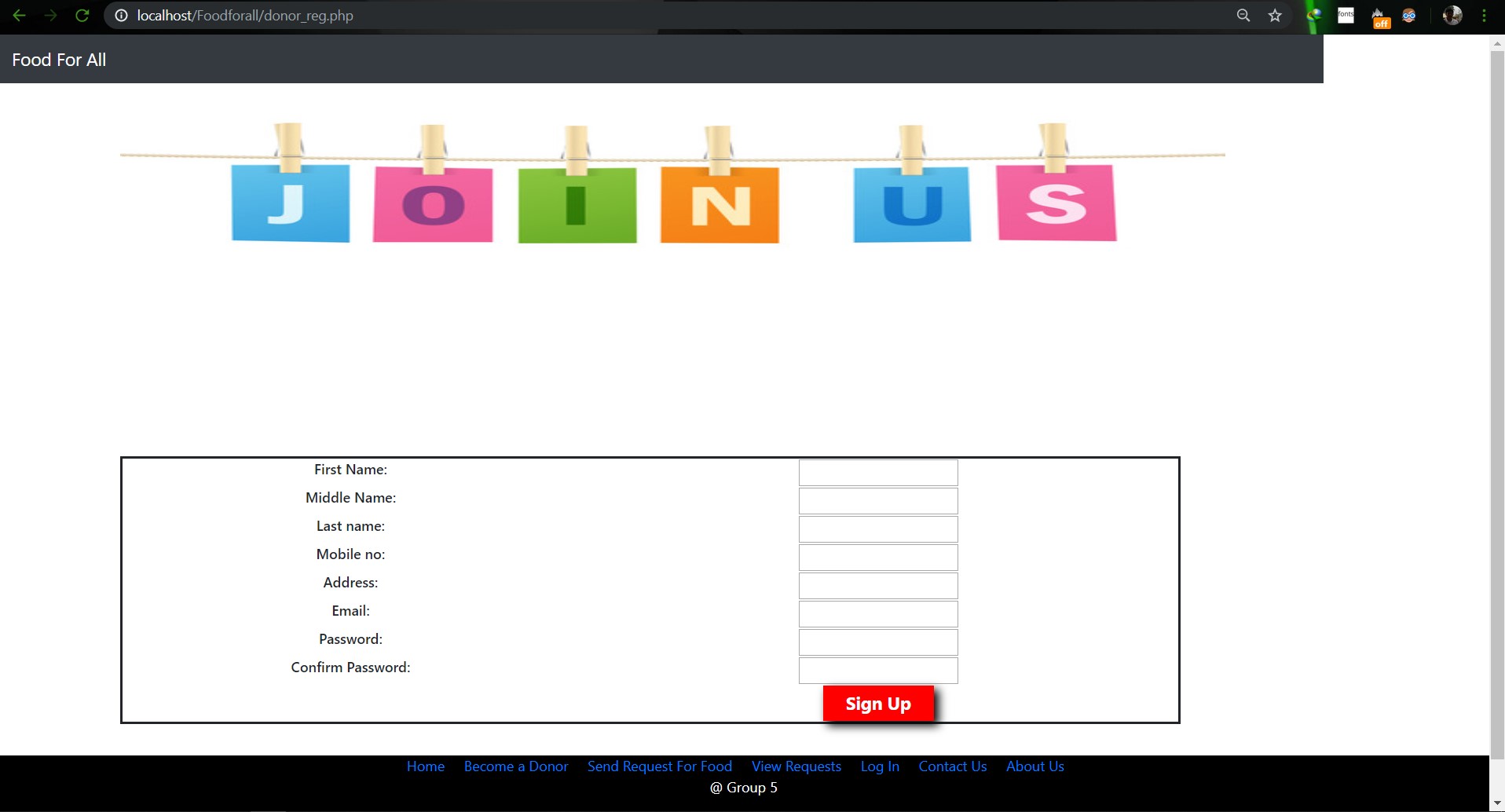                        **Image: Join us Page** <br> 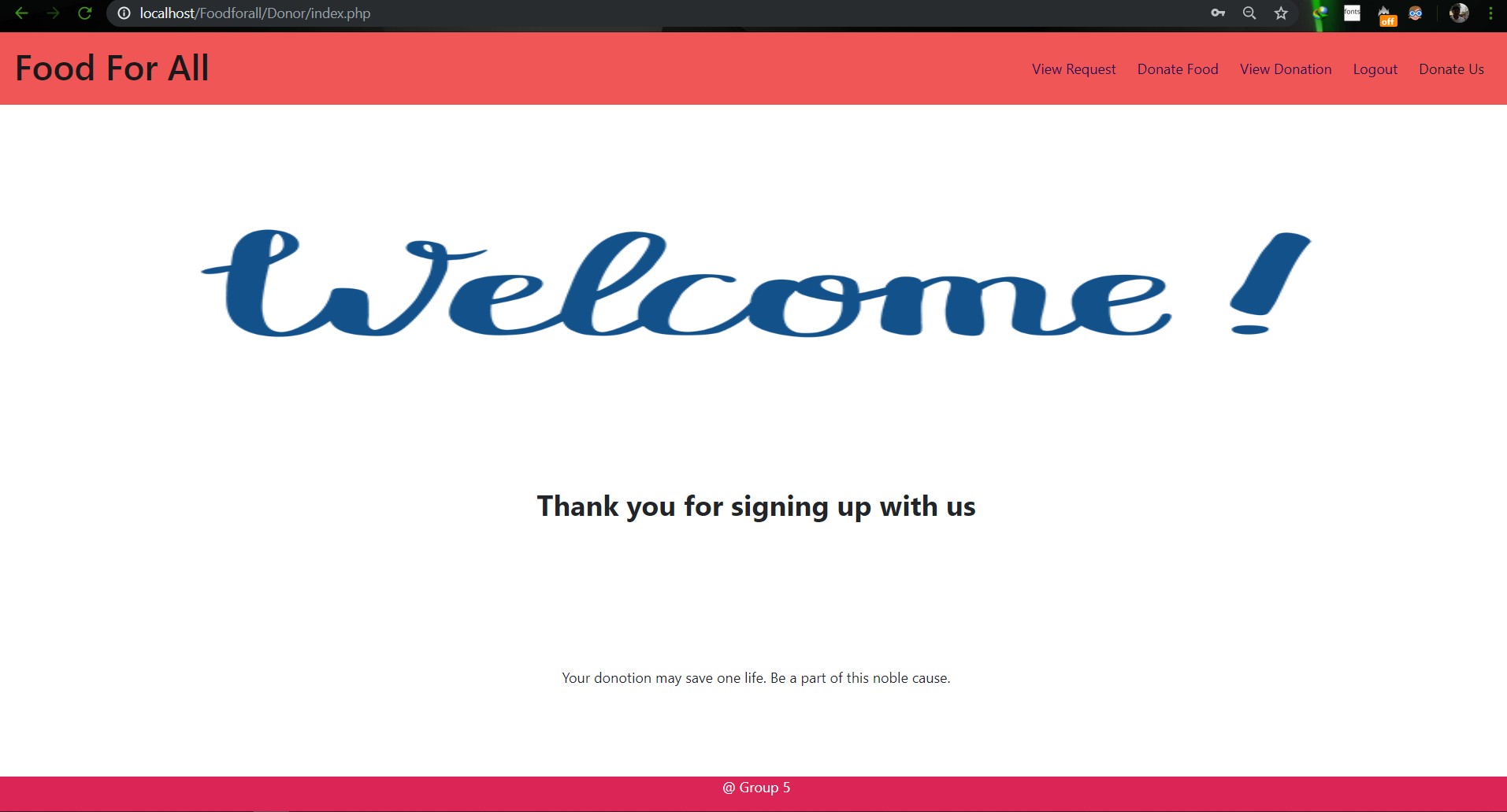                        **Image: Donor Login Page** <br> 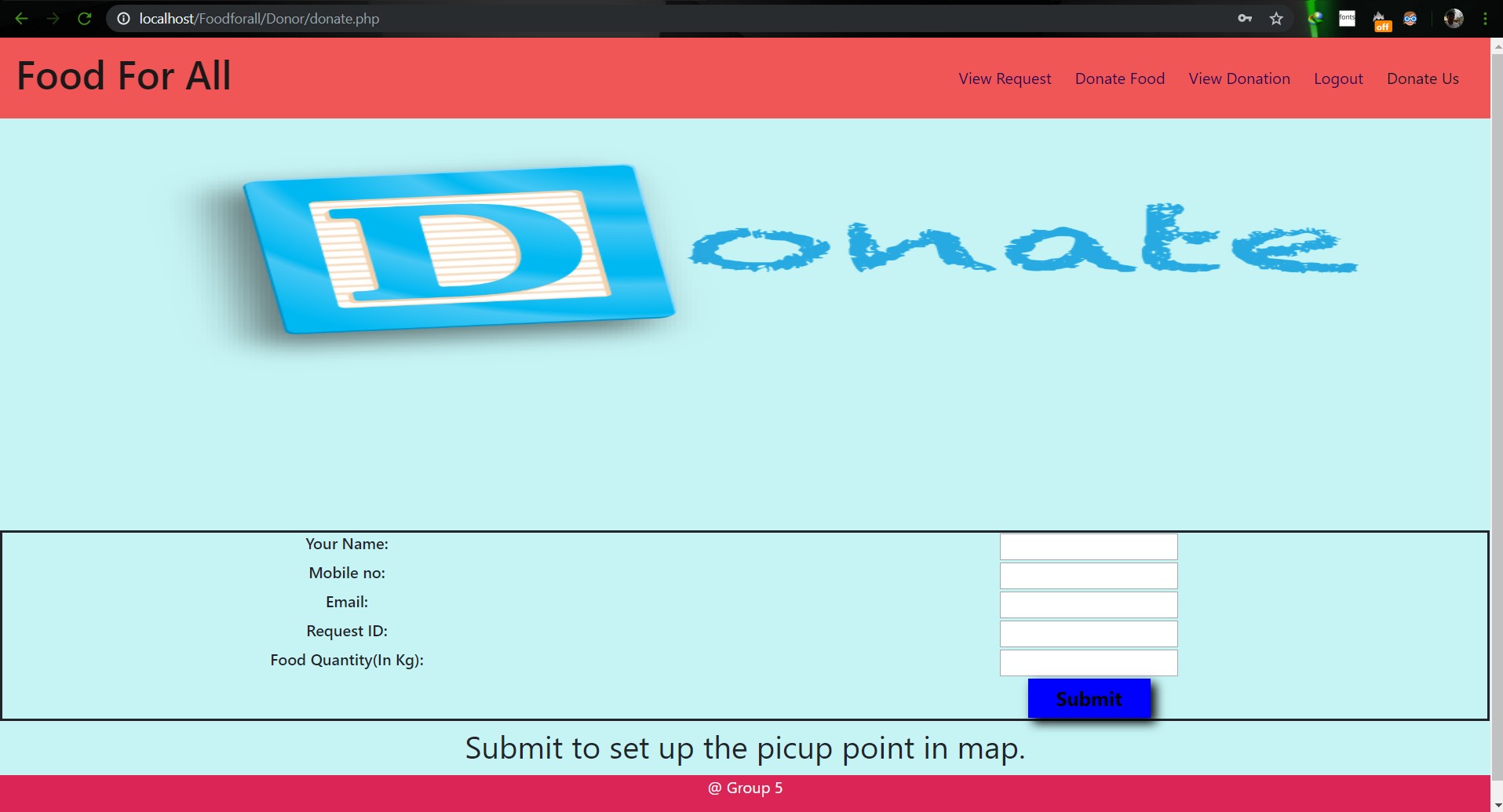                        **Image: Food Donation** <br> 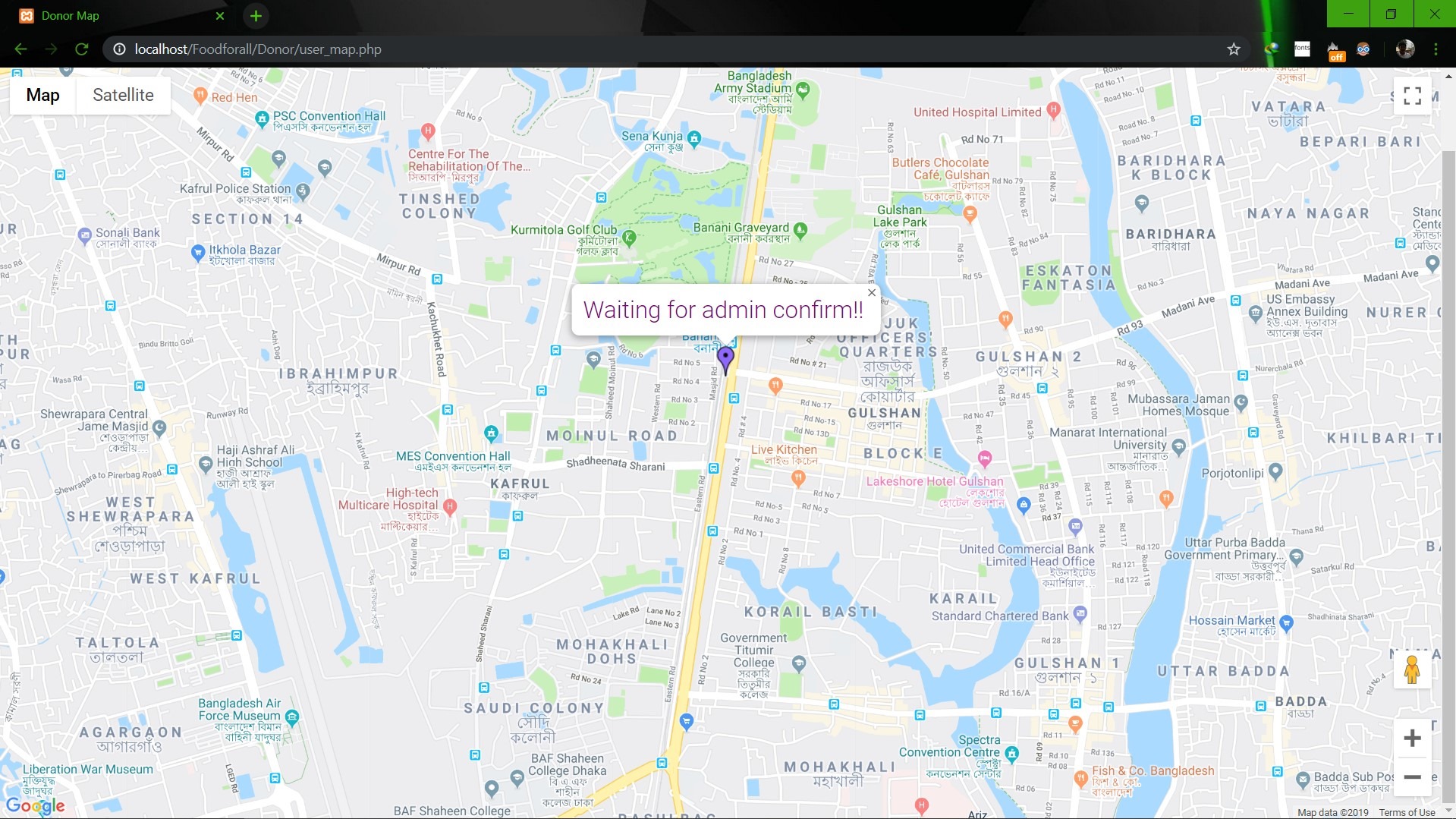                        **Image: User map** <br>                         **Image: Admin Login** <br> 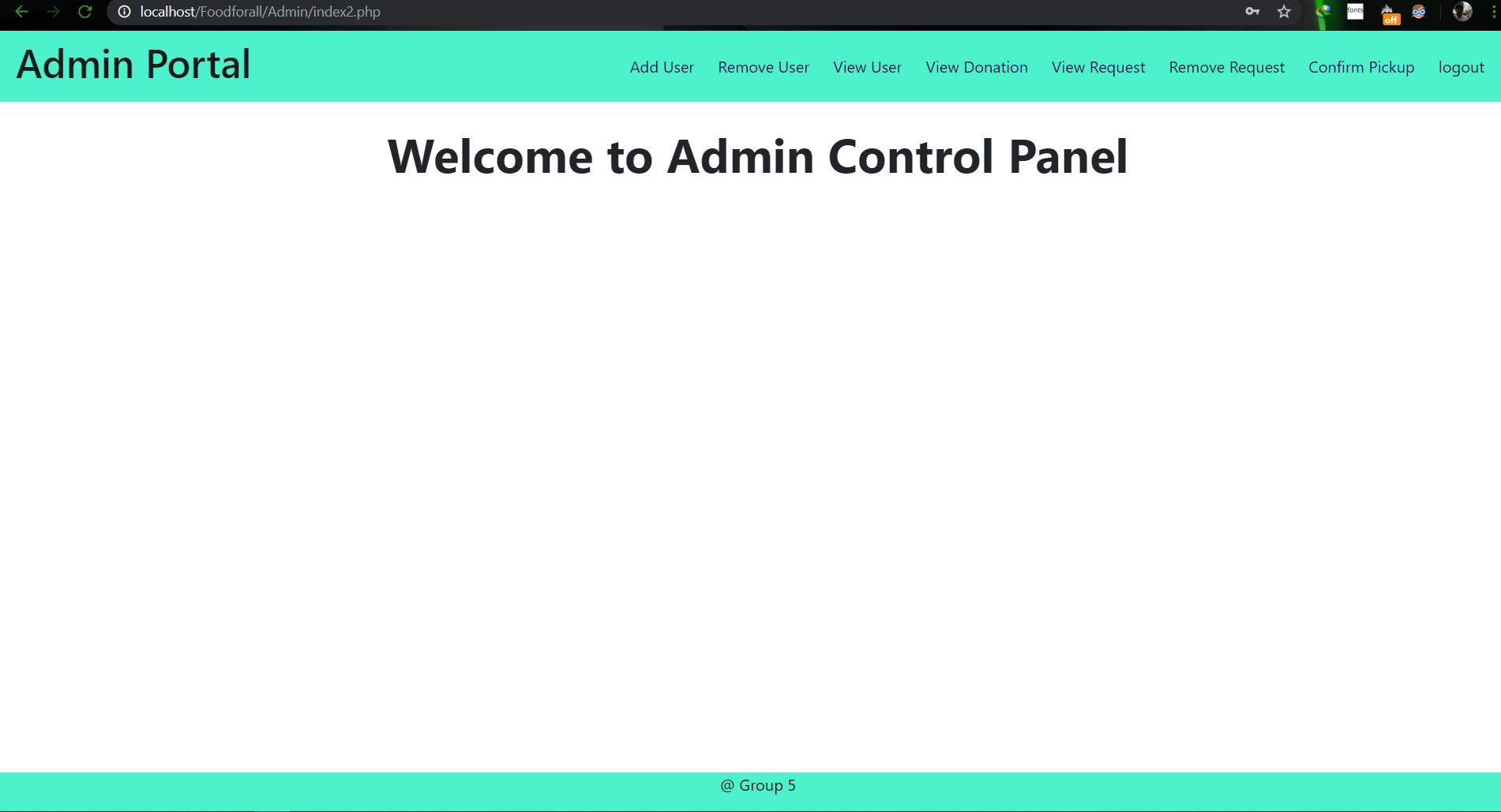                        **Image: Admin Home** <br> 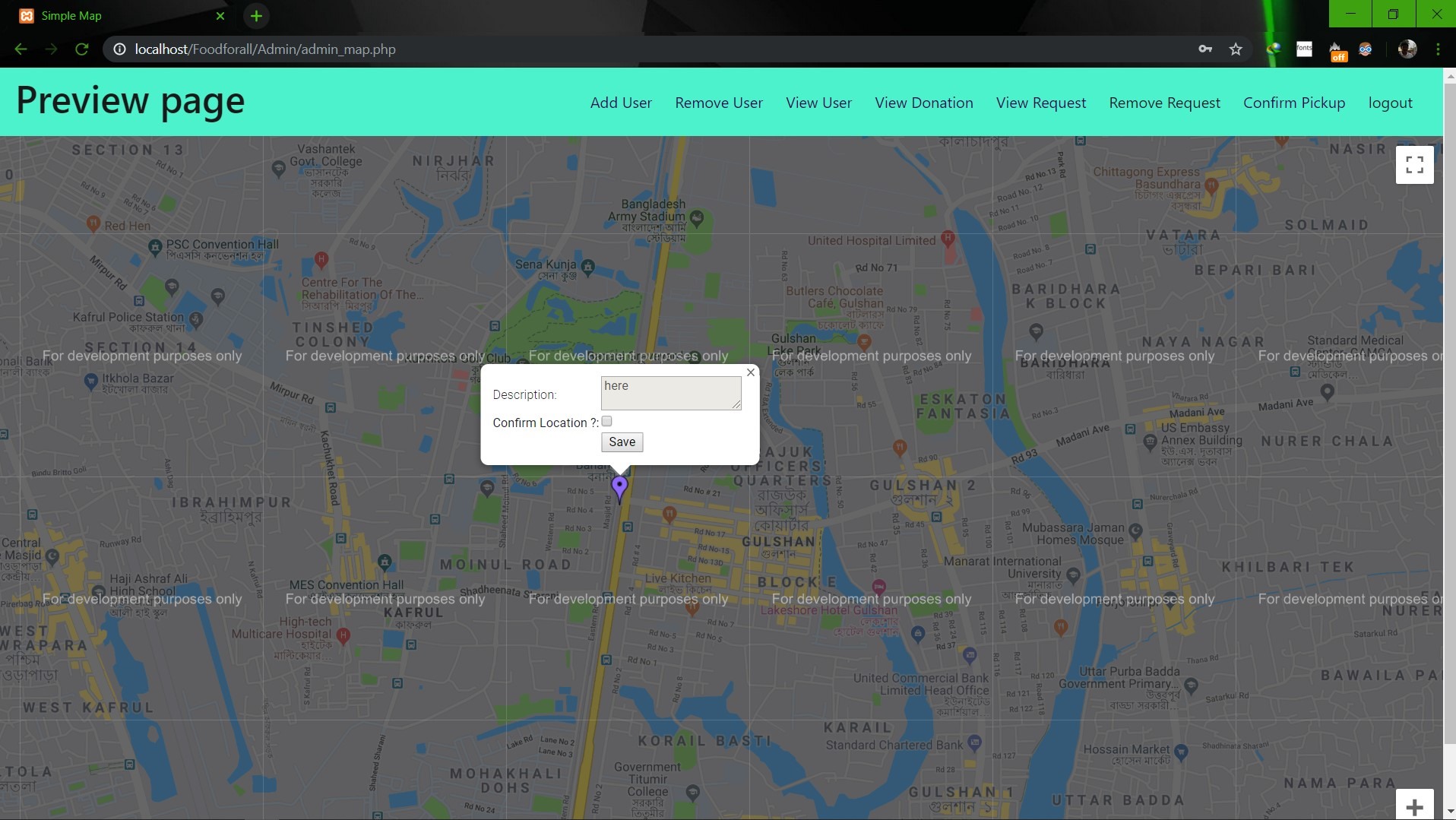                        **Image: Admin map** <br><br><br> **Conclusion:** 1. First of all we learnt how to use Github. It was completely new for us. But we now know how to use it. 2. We learnt about PHP, HTML and How to create DB connection in Mysql to create a project. 3. If we have more time we may be able to make the full project work properly. 4. In future, if we get chance we also want to create a android app for this weabsite. **References:** 1.https://getbootstrap.com/docs/4.3/examples/starter-template/ 2.https://www.w3schools.com/ 3.https://www.youtube.com/ 4.https://stackoverflow.com/questions/22138746/php-form-not-inserting-into-mysql-database 5.https://www.google.com/search?q=html+color+picker&oq=html+&aqs=chrome.0.69i59j69i57j69i60j69i65l2j69i60.3167j0j7&sourceid=chrome&ie=UTF-8 6.https://www.geeksforgeeks.org/ 7.https://www.youtube.com/watch?v=q2VV3-yWupU 8.https://bitbucket.org/webeasystep/markers_manager_php_mysql/src/master/
MayankChauhan2111/CredicXoTask-and-bonus
Python Task Greetings from Credicxo, Congratulations, You have been shortlisted for the coding round. The details of the test are mentioned below . Kindly read all the instructions and reply with submissions on this email ONLY. Technologies : Python latest, BS4/Scrapy/Selenium, requests. MAIN TASK In this task we want you to scrape a minimum hundred URLs. The URL will be in format of"https://www.amazon.{country}/dp/{asin}".The country code and Asin parameters are in the CSV file https://docs.google.com/spreadsheets/d/1BZSPhk1LDrx8ytywMHWVpCqbm8URT xTJrIRkD7PnGTM/edit?usp=sharing. The CSV file contains 1000 rows. Use Selenium or bs4 to Scarpe the following details from the page. 1. Product Title 2. Product Image URL 3. Price of the Product 4. Product Details If any URL throws Error 404 then print the {URL} not available and skip that URL. After completing each round of hundred URLs mention the total time it took to complete them in the feedback section of task submission page. The output should be in the list of dictionaries, finally represented in JSON. Upload only your code file, resultant JSON file and a proper readme explaining how you approached the problem. BONUS 1: If possible, add the google Colab button in your repository. To directly access your code in Google Colab. BONUS 2: If possible, try connecting some Database like MySQL or PostgreSQL and dump the data in the database. (You still need to create the output JSON file.) BONUS TASK This task is not mandatory but if you are able to do it then your chances of getting in would be increased significantly. Technologies: Python latest, BS4/Scrapy/Selenium, requests. In this task, you need to write a script to bypass Amazon Captcha, Example website: https://www.amazon.com/errors/validateCaptcha 1. Write a script that solves the captcha and submit the form. 2. Also explain how did you approach this problem to find a solution. Upload this task in the same repository where you upload your main task but inside the folder Bonus Task. Note: You can't use the existing captcha solving services API. You must remember the following points while submitting, otherwise your submission may be rejected. Submit your task at - https://forms.gle/3NXcax4TYjb6mTxD7 1. Upload Project Github link in “Task Link” Section. 2. Add Your Name and contact number in the form. 3. You can add comments (additional information you want us to know in your submission) in the “Feedback/Instructions to use” Section. 4. Please attach your resume. Deadline to submit is two days from the date on which you received this task. Best Regards, HR Team Credicxo Tech Pvt. Ltd.
MayankChauhan2111/Credicxo
Python Task Greetings from Credicxo, Congratulations, You have been shortlisted for the coding round. The details of the test are mentioned below . Kindly read all the instructions and reply with submissions on this email ONLY. Technologies : Python latest, BS4/Scrapy/Selenium, requests. MAIN TASK In this task we want you to scrape a minimum hundred URLs. The URL will be in format of"https://www.amazon.{country}/dp/{asin}".The country code and Asin parameters are in the CSV file https://docs.google.com/spreadsheets/d/1BZSPhk1LDrx8ytywMHWVpCqbm8URT xTJrIRkD7PnGTM/edit?usp=sharing. The CSV file contains 1000 rows. Use Selenium or bs4 to Scarpe the following details from the page. 1. Product Title 2. Product Image URL 3. Price of the Product 4. Product Details If any URL throws Error 404 then print the {URL} not available and skip that URL. After completing each round of hundred URLs mention the total time it took to complete them in the feedback section of task submission page. The output should be in the list of dictionaries, finally represented in JSON. Upload only your code file, resultant JSON file and a proper readme explaining how you approached the problem. BONUS 1: If possible, add the google Colab button in your repository. To directly access your code in Google Colab. BONUS 2: If possible, try connecting some Database like MySQL or PostgreSQL and dump the data in the database. (You still need to create the output JSON file.) BONUS TASK This task is not mandatory but if you are able to do it then your chances of getting in would be increased significantly. Technologies: Python latest, BS4/Scrapy/Selenium, requests. In this task, you need to write a script to bypass Amazon Captcha, Example website: https://www.amazon.com/errors/validateCaptcha 1. Write a script that solves the captcha and submit the form. 2. Also explain how did you approach this problem to find a solution. Upload this task in the same repository where you upload your main task but inside the folder Bonus Task. Note: You can't use the existing captcha solving services API. You must remember the following points while submitting, otherwise your submission may be rejected. Submit your task at - https://forms.gle/3NXcax4TYjb6mTxD7 1. Upload Project Github link in “Task Link” Section. 2. Add Your Name and contact number in the form. 3. You can add comments (additional information you want us to know in your submission) in the “Feedback/Instructions to use” Section. 4. Please attach your resume. Deadline to submit is two days from the date on which you received this task. Best Regards, HR Team Credicxo Tech Pvt. Ltd.
Kwamb0/SQL-Challenge
Background It is a beautiful spring day, and it is two weeks since you have been hired as a new data engineer at Pewlett Hackard. Your first major task is a research project on employees of the corporation from the 1980s and 1990s. All that remain of the database of employees from that period are six CSV files. In this assignment, you will design the tables to hold data in the CSVs, import the CSVs into a SQL database, and answer questions about the data. In other words, you will perform: Data Modeling Data Engineering Data Analysis Before You Begin Create a new repository for this project called sql-challenge. Do not add this homework to an existing repository. Clone the new repository to your computer. Inside your local git repository, create a directory for the SQL challenge. Use a folder name to correspond to the challenge: EmployeeSQL. Add your files to this folder. Push the above changes to GitHub. Instructions Data Modeling Inspect the CSVs and sketch out an ERD of the tables. Feel free to use a tool like http://www.quickdatabasediagrams.com. Data Engineering Use the information you have to create a table schema for each of the six CSV files. Remember to specify data types, primary keys, foreign keys, and other constraints. Import each CSV file into the corresponding SQL table. Data Analysis Once you have a complete database, do the following: List the following details of each employee: employee number, last name, first name, gender, and salary. List employees who were hired in 1986. List the manager of each department with the following information: department number, department name, the manager’s employee number, last name, first name, and start and end employment dates. List the department of each employee with the following information: employee number, last name, first name, and department name. List all employees whose first name is “Hercules” and last names begin with “B.” List all employees in the Sales department, including their employee number, last name, first name, and department name. List all employees in the Sales and Development departments, including their employee number, last name, first name, and department name. In descending order, list the frequency count of employee last names, i.e., how many employees share each last name.
Kwamb0/SQL-homework
Background It is a beautiful spring day, and it is two weeks since you have been hired as a new data engineer at Pewlett Hackard. Your first major task is a research project on employees of the corporation from the 1980s and 1990s. All that remain of the database of employees from that period are six CSV files. In this assignment, you will design the tables to hold data in the CSVs, import the CSVs into a SQL database, and answer questions about the data. In other words, you will perform: Data Modeling Data Engineering Data Analysis Before You Begin Create a new repository for this project called sql-challenge. Do not add this homework to an existing repository. Clone the new repository to your computer. Inside your local git repository, create a directory for the SQL challenge. Use a folder name to correspond to the challenge: EmployeeSQL. Add your files to this folder. Push the above changes to GitHub. Instructions Data Modeling Inspect the CSVs and sketch out an ERD of the tables. Feel free to use a tool like http://www.quickdatabasediagrams.com. Data Engineering Use the information you have to create a table schema for each of the six CSV files. Remember to specify data types, primary keys, foreign keys, and other constraints. Import each CSV file into the corresponding SQL table. Data Analysis Once you have a complete database, do the following: List the following details of each employee: employee number, last name, first name, gender, and salary. List employees who were hired in 1986. List the manager of each department with the following information: department number, department name, the manager’s employee number, last name, first name, and start and end employment dates. List the department of each employee with the following information: employee number, last name, first name, and department name. List all employees whose first name is “Hercules” and last names begin with “B.” List all employees in the Sales department, including their employee number, last name, first name, and department name. List all employees in the Sales and Development departments, including their employee number, last name, first name, and department name. In descending order, list the frequency count of employee last names, i.e., how many employees share each last name.
armankarimpour/HyperChessArman
Welcome to Hyper Bot ! Create your own permanent Hyper Bot ( runs on Heroku, no Lc0 ) If you want to create your own permanent bot, do the following: Sign up to GitHub https://github.com/join , if you have not already. With your GitHub account visit https://github.com/hyperchessbot/hyperbot , then click on Fork. Create a BOT account if you do not already have one. To create one use an account that has not played any games yet, log into this account, then visit https://hypereasy.herokuapp.com/auth/lichess/bot , approve oauth and then on the page you are taken to click on 'Request upgrade to bot'. Create an API access token with your BOT account at https://lichess.org/account/oauth/token ( should have scopes Read incoming challenges / Create, accept, decline challenges / Play games with the bot API ) Sign up to Heroku https://signup.heroku.com/ , if you have not already. At Heroku create a new app using New / Create new app. Choose Europe for region. In the app's dashboard go to the Deploy tab. Use the GitHub button to connect the app to your forked repo. Press Search to find your repositories, then select hyperbot. You need to deploy the master branch. Enable Automatic Deploys and press Deploy Branch, for the initial deploy. Wait for the build to finish. In Heroku Settings / Reveal Config Vars create a new variable TOKEN and set its value to your newly created access token, then create a new variable BOT_NAME and set its value to your bot's lichess username. For more detailed instructions and screenshots on setting up your Heroku app refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Creating-and-configuring-your-app-on-Heroku#creating-and-configuring-your-app-on-heroku . Congratulations, you have an up and running lichess bot. If you want to use 3-4-5 piece tablebases on Heroku, refer to this guide https://github.com/hyperchessbot/hyperbot/wiki/Update-Heroku-app-to-latest-version-using-Gitpod#enabling-syzygy-tablebases . Upgrade to bot and play games in your browser To upgrade an account, that has played no games yet, to bot, and to make this bot accept challenges and play games in your browser, visit https://hypereasy.herokuapp.com . For detailed instructions see https://lichess.org/forum/off-topic-discussion/hyper-easy-all-variants-lichess-bot-running-in-your-browser#1 . Update Heroku app to latest version using Gitpod Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Update-Heroku-app-to-latest-version-using-Gitpod#update-heroku-app-to-latest-version-using-gitpod . Creating a MongoDb account Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Creating-a-MongoDb-account#creating-a-mongodb-account . Build external multi game PGN file with MongoDb book builder ( version 2 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Build-book-from-external-multi-game-PGN-file#build-book-from-external-multi-game-pgn-file . Install bot on Windows ( runs Lc0 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Install-bot-on-Windows-(-runs-Lc0-)#install-bot-on-windows--runs-lc0- . Install bot on goorm.io ( runs Lc0 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Install-bot-on-goorm.io-(-runs-Lc0-)#install-bot-on-goormio--runs-lc0- . Download a net for Lc0 Dowload a net from https://lczero.org/dev/wiki/best-nets-for-lc0 . Rename the weights file 'weights.pb.gz', then copy it to the 'lc0goorm' folder. Overwrite the old file. Update to latest version on Windows / goorm Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Update-to-latest-version-on-Windows-or-goorm#update-to-latest-version-on-windows--goorm . Explanation of files Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Explanation-of-files#git . Contribute to code Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Contribute-to-code#contribute-to-code . Discussion / Feedback Discuss Hyper Bot on Discord https://discord.gg/8m3Muay . Post issues on GitHub https://github.com/hyperchessbot/hyperbot/issues . Getting assistance in lichess PM You can seek assistance in lichess PM using your BOT account. Open an issue at https://github.com/hyperchessbot/hyperbot/issues with the GitHub account on which your forked Hyper Bot, with the title 'Identifying lichess account'. Give a link to your lichess account in the issue. After identification you can PM https://lichess.org/@/hyperchessbotauthor . Seeking assistance in lichess PM without verifying your lichess account with your GitHub account may get you blocked. The block may be lifted once you identify your lichess account with your GitHub account. Config vars KEEP_ALIVE_URL : set this to the full link of your bot home page ( https://[yourappname].herokuapp.com , where change [yourappname] to your Heroku app name ) if you want your bot to be kept alive from early morning till late night Heroku server time, keeping alive a free Heroku bot for 24/7 is not possible, because a free Heroku account has a monthly quota of 550 hours ALWAYS_ON : requires paid Heroku account, set it to 'true' to keep the bot alive 24/7, you have to set KEEP_ALIVE_URL to your bot's full home page link for ALWAYS_ON to work ( see also the explanation of KEEP_ALIVE_URL config var ) ALLOW_CORRESPONDENCE : set it to 'true' to allow playing correspondence and infinite time control games CORRESPONDENCE_THINKING_TIME : think in correspondence as if the bot had that many seconds left on its clock ( default : 120 ), the actual thinking time will be decided by the engine MONGODB_URI : connect URI of your MongoDb admin user ( only the host, no slash after the host, do database specified, no query string ), if defined, your latest games or games downloaded from an url ( version 2 only ) will be added to the database on every startup, by default this config var is not defined USE_MONGO_BOOK : set it to 'true' to use the MongoDb book specified by MONGODB_URI DISABLE_ENGINE_FOR_MONGO : set it to 'true' to disable using engine completely when a MongoDb book move is available ( by default the bot may ignore a MongoDb book move at its discretion and use the engine instead for better performance and to allow for more varied play ) MONGO_VERSION : MongoDb book builder version, possible values are 1 ( default, builds a book from bot games as downloaded from lichess as JSON ), 2 ( builds a book from bot games as downloaded from lichess as PGN, or from an arbitrary url specified in PGN_URL ) PGN_URL : url for downloading a multi game PGN file for MongoDb book builder ( version 2 only ) MAX_GAMES : maximum number of games to be built by MongoDb book builder GENERAL_TIMEOUT : timeout for event streams in seconds ( default : 15 ) ENGINE_THREADS : engine Threads uci option ( default : 1 ) ENGINE_HASH : engine Hash uci option in megabytes ( default : 16 ) ENGINE_CONTEMPT : engine Contempt uci option in centipawns ( default : 24 ) ENGINE_MOVE_OVERHEAD : engine Move Overhead uci option in milliseconds ( default : 500 ) ALLOW_PONDER : set it to 'true' to make the bot think on opponent time BOOK_DEPTH : up to how many plies into the game should the bot use the book, choosing too high book depth is running the risk of playing unsound moves ( default : 20 ) BOOK_SPREAD : select the move from that many of the top book moves, choosing to high book spread is running the risk of playing unsound moves ( default : 4 ) BOOK_RATINGS : comma separated list of allowed book rating brackets, possible ratings are 1600, 1800, 2000, 2200, 2500 ( default : '2200,2500') BOOK_SPEEDS : comma separated list of allowed book speeds, possible speeds are bullet, blitz, rapid, classical ( default : 'blitz,rapid' ) LOG_API : set it to 'true' to allow more verbose logging, logs are available in the Inspection / Console of the browser USE_SCALACHESS : set it to 'true' to use scalachess library and multi variant engine ACCEPT_VARIANTS : space separated list of variant keys to accept ( default : 'standard' ), for non standard variants USE_SCALACHESS has to be set to 'true' , example : 'standard crazyhouse chess960 kingOfTheHill threeCheck antichess atomic horde racingKings fromPosition' ACCEPT_SPEEDS : space separated list of speeds to accept ( default : 'bullet blitz rapid classical' ), to allow correspondence set ALLOW_CORRESPONDENCE to 'true' DISABLE_RATED : set it to 'true' to reject rated challenges DISABLE_CASUAL : set it to 'true' to reject casual challenges DISABLE_BOT : set it to 'true' to reject bot challenges DISABLE_HUMAN : set it to 'true' to reject human challenges GAME_START_DELAY : delay between accepting challenge and starting to play game in seconds ( default : 2 ) CHALLENGE_INTERVAL : delay between auto challenge attempts in minutes ( default : 30 ) CHALLENGE_TIMEOUT : start attempting auto challenges after being idle for that many minutes ( default : 60 ) USE_NNUE : space separated list of variant keys for which to use NNUE ( default: 'standard chess960 fromPosition' ) USE_LC0 : set it to 'true' to use Lc0 engine, only works with Windows and goorm installation, on Heroku and Gitpod you should not use it or set it to false USE_POLYGLOT : set it to 'true' to use polyglot opening book WELCOME_MESSAGE : game chat welcome message ( delay from game start : 2 seconds , default : 'coded by @hyperchessbotauthor' ) GOOD_LUCK_MESSAGE : game chat good luck message ( delay from game start : 4 seconds , default : 'Good luck !' ) GOOD_GAME_MESSAGE : game chat good game message ( delay from game end : 2 seconds , default : 'Good game !' ) DISABLE_SYZYGY : set it to 'true' to disable using syzygy tablebases, note that syzygy tablebases are always disabled when USE_LC0 is set to 'true', syzygy tablebases are only installed for deployment on Heroku APP_NAME : Heroku app name ( necessary for interactive viewing of MongoDb book ) ABORT_AFTER : abort game after that many seconds if the opponent fails to make their opening move ( default : 120 ) DECLINE_HARD : set it to 'true' to explicitly decline unwanted challenges ( by default they are only ignored and can be accepted manually )
armankarimpour/hyperarman
Welcome to Hyper Bot ! Create your own permanent Hyper Bot ( runs on Heroku, no Lc0 ) If you want to create your own permanent bot, do the following: Sign up to GitHub https://github.com/join , if you have not already. With your GitHub account visit https://github.com/hyperchessbot/hyperbot , then click on Fork. Create a BOT account if you do not already have one. To create one use an account that has not played any games yet, log into this account, then visit https://hypereasy.herokuapp.com/auth/lichess/bot , approve oauth and then on the page you are taken to click on 'Request upgrade to bot'. Create an API access token with your BOT account at https://lichess.org/account/oauth/token ( should have scopes Read incoming challenges / Create, accept, decline challenges / Play games with the bot API ) Sign up to Heroku https://signup.heroku.com/ , if you have not already. At Heroku create a new app using New / Create new app. Choose Europe for region. In the app's dashboard go to the Deploy tab. Use the GitHub button to connect the app to your forked repo. Press Search to find your repositories, then select hyperbot. You need to deploy the master branch. Enable Automatic Deploys and press Deploy Branch, for the initial deploy. Wait for the build to finish. In Heroku Settings / Reveal Config Vars create a new variable TOKEN and set its value to your newly created access token, then create a new variable BOT_NAME and set its value to your bot's lichess username. For more detailed instructions and screenshots on setting up your Heroku app refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Creating-and-configuring-your-app-on-Heroku#creating-and-configuring-your-app-on-heroku . Congratulations, you have an up and running lichess bot. If you want to use 3-4-5 piece tablebases on Heroku, refer to this guide https://github.com/hyperchessbot/hyperbot/wiki/Update-Heroku-app-to-latest-version-using-Gitpod#enabling-syzygy-tablebases . Upgrade to bot and play games in your browser To upgrade an account, that has played no games yet, to bot, and to make this bot accept challenges and play games in your browser, visit https://hypereasy.herokuapp.com . For detailed instructions see https://lichess.org/forum/off-topic-discussion/hyper-easy-all-variants-lichess-bot-running-in-your-browser#1 . Update Heroku app to latest version using Gitpod Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Update-Heroku-app-to-latest-version-using-Gitpod#update-heroku-app-to-latest-version-using-gitpod . Creating a MongoDb account Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Creating-a-MongoDb-account#creating-a-mongodb-account . Build external multi game PGN file with MongoDb book builder ( version 2 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Build-book-from-external-multi-game-PGN-file#build-book-from-external-multi-game-pgn-file . Install bot on Windows ( runs Lc0 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Install-bot-on-Windows-(-runs-Lc0-)#install-bot-on-windows--runs-lc0- . Install bot on goorm.io ( runs Lc0 ) Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Install-bot-on-goorm.io-(-runs-Lc0-)#install-bot-on-goormio--runs-lc0- . Download a net for Lc0 Dowload a net from https://lczero.org/dev/wiki/best-nets-for-lc0 . Rename the weights file 'weights.pb.gz', then copy it to the 'lc0goorm' folder. Overwrite the old file. Update to latest version on Windows / goorm Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Update-to-latest-version-on-Windows-or-goorm#update-to-latest-version-on-windows--goorm . Explanation of files Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Explanation-of-files#git . Contribute to code Refer to this Wiki https://github.com/hyperchessbot/hyperbot/wiki/Contribute-to-code#contribute-to-code . Discussion / Feedback Discuss Hyper Bot on Discord https://discord.gg/8m3Muay . Post issues on GitHub https://github.com/hyperchessbot/hyperbot/issues . Getting assistance in lichess PM You can seek assistance in lichess PM using your BOT account. Open an issue at https://github.com/hyperchessbot/hyperbot/issues with the GitHub account on which your forked Hyper Bot, with the title 'Identifying lichess account'. Give a link to your lichess account in the issue. After identification you can PM https://lichess.org/@/hyperchessbotauthor . Seeking assistance in lichess PM without verifying your lichess account with your GitHub account may get you blocked. The block may be lifted once you identify your lichess account with your GitHub account. Config vars KEEP_ALIVE_URL : set this to the full link of your bot home page ( https://[yourappname].herokuapp.com , where change [yourappname] to your Heroku app name ) if you want your bot to be kept alive from early morning till late night Heroku server time, keeping alive a free Heroku bot for 24/7 is not possible, because a free Heroku account has a monthly quota of 550 hours ALWAYS_ON : requires paid Heroku account, set it to 'true' to keep the bot alive 24/7, you have to set KEEP_ALIVE_URL to your bot's full home page link for ALWAYS_ON to work ( see also the explanation of KEEP_ALIVE_URL config var ) ALLOW_CORRESPONDENCE : set it to 'true' to allow playing correspondence and infinite time control games CORRESPONDENCE_THINKING_TIME : think in correspondence as if the bot had that many seconds left on its clock ( default : 120 ), the actual thinking time will be decided by the engine MONGODB_URI : connect URI of your MongoDb admin user ( only the host, no slash after the host, do database specified, no query string ), if defined, your latest games or games downloaded from an url ( version 2 only ) will be added to the database on every startup, by default this config var is not defined USE_MONGO_BOOK : set it to 'true' to use the MongoDb book specified by MONGODB_URI DISABLE_ENGINE_FOR_MONGO : set it to 'true' to disable using engine completely when a MongoDb book move is available ( by default the bot may ignore a MongoDb book move at its discretion and use the engine instead for better performance and to allow for more varied play ) MONGO_VERSION : MongoDb book builder version, possible values are 1 ( default, builds a book from bot games as downloaded from lichess as JSON ), 2 ( builds a book from bot games as downloaded from lichess as PGN, or from an arbitrary url specified in PGN_URL ) PGN_URL : url for downloading a multi game PGN file for MongoDb book builder ( version 2 only ) MAX_GAMES : maximum number of games to be built by MongoDb book builder GENERAL_TIMEOUT : timeout for event streams in seconds ( default : 15 ) ENGINE_THREADS : engine Threads uci option ( default : 1 ) ENGINE_HASH : engine Hash uci option in megabytes ( default : 16 ) ENGINE_CONTEMPT : engine Contempt uci option in centipawns ( default : 24 ) ENGINE_MOVE_OVERHEAD : engine Move Overhead uci option in milliseconds ( default : 500 ) ALLOW_PONDER : set it to 'true' to make the bot think on opponent time BOOK_DEPTH : up to how many plies into the game should the bot use the book, choosing too high book depth is running the risk of playing unsound moves ( default : 20 ) BOOK_SPREAD : select the move from that many of the top book moves, choosing to high book spread is running the risk of playing unsound moves ( default : 4 ) BOOK_RATINGS : comma separated list of allowed book rating brackets, possible ratings are 1600, 1800, 2000, 2200, 2500 ( default : '2200,2500') BOOK_SPEEDS : comma separated list of allowed book speeds, possible speeds are bullet, blitz, rapid, classical ( default : 'blitz,rapid' ) LOG_API : set it to 'true' to allow more verbose logging, logs are available in the Inspection / Console of the browser USE_SCALACHESS : set it to 'true' to use scalachess library and multi variant engine ACCEPT_VARIANTS : space separated list of variant keys to accept ( default : 'standard' ), for non standard variants USE_SCALACHESS has to be set to 'true' , example : 'standard crazyhouse chess960 kingOfTheHill threeCheck antichess atomic horde racingKings fromPosition' ACCEPT_SPEEDS : space separated list of speeds to accept ( default : 'bullet blitz rapid classical' ), to allow correspondence set ALLOW_CORRESPONDENCE to 'true' DISABLE_RATED : set it to 'true' to reject rated challenges DISABLE_CASUAL : set it to 'true' to reject casual challenges DISABLE_BOT : set it to 'true' to reject bot challenges DISABLE_HUMAN : set it to 'true' to reject human challenges GAME_START_DELAY : delay between accepting challenge and starting to play game in seconds ( default : 2 ) CHALLENGE_INTERVAL : delay between auto challenge attempts in minutes ( default : 30 ) CHALLENGE_TIMEOUT : start attempting auto challenges after being idle for that many minutes ( default : 60 ) USE_NNUE : space separated list of variant keys for which to use NNUE ( default: 'standard chess960 fromPosition' ) USE_LC0 : set it to 'true' to use Lc0 engine, only works with Windows and goorm installation, on Heroku and Gitpod you should not use it or set it to false USE_POLYGLOT : set it to 'true' to use polyglot opening book WELCOME_MESSAGE : game chat welcome message ( delay from game start : 2 seconds , default : 'coded by @hyperchessbotauthor' ) GOOD_LUCK_MESSAGE : game chat good luck message ( delay from game start : 4 seconds , default : 'Good luck !' ) GOOD_GAME_MESSAGE : game chat good game message ( delay from game end : 2 seconds , default : 'Good game !' ) DISABLE_SYZYGY : set it to 'true' to disable using syzygy tablebases, note that syzygy tablebases are always disabled when USE_LC0 is set to 'true', syzygy tablebases are only installed for deployment on Heroku APP_NAME : Heroku app name ( necessary for interactive viewing of MongoDb book ) ABORT_AFTER : abort game after that many seconds if the opponent fails to make their opening move ( default : 120 ) DECLINE_HARD : set it to 'true' to explicitly decline unwanted challenges ( by default they are only ignored and can be accepted manually )
etherceo1x1/codes
BUILD YOUR OWN BLOCKCHAIN: A PYTHON TUTORIAL Download the full Jupyter/iPython notebook from Github here Build Your Own Blockchain – The Basics¶ This tutorial will walk you through the basics of how to build a blockchain from scratch. Focusing on the details of a concrete example will provide a deeper understanding of the strengths and limitations of blockchains. For a higher-level overview, I’d recommend this excellent article from BitsOnBlocks. Transactions, Validation, and updating system state¶ At its core, a blockchain is a distributed database with a set of rules for verifying new additions to the database. We’ll start off by tracking the accounts of two imaginary people: Alice and Bob, who will trade virtual money with each other. We’ll need to create a transaction pool of incoming transactions, validate those transactions, and make them into a block. We’ll be using a hash function to create a ‘fingerprint’ for each of our transactions- this hash function links each of our blocks to each other. To make this easier to use, we’ll define a helper function to wrap the python hash function that we’re using. In [1]: import hashlib, json, sys def hashMe(msg=""): # For convenience, this is a helper function that wraps our hashing algorithm if type(msg)!=str: msg = json.dumps(msg,sort_keys=True) # If we don't sort keys, we can't guarantee repeatability! if sys.version_info.major == 2: return unicode(hashlib.sha256(msg).hexdigest(),'utf-8') else: return hashlib.sha256(str(msg).encode('utf-8')).hexdigest() Next, we want to create a function to generate exchanges between Alice and Bob. We’ll indicate withdrawals with negative numbers, and deposits with positive numbers. We’ll construct our transactions to always be between the two users of our system, and make sure that the deposit is the same magnitude as the withdrawal- i.e. that we’re neither creating nor destroying money. In [2]: import random random.seed(0) def makeTransaction(maxValue=3): # This will create valid transactions in the range of (1,maxValue) sign = int(random.getrandbits(1))*2 - 1 # This will randomly choose -1 or 1 amount = random.randint(1,maxValue) alicePays = sign * amount bobPays = -1 * alicePays # By construction, this will always return transactions that respect the conservation of tokens. # However, note that we have not done anything to check whether these overdraft an account return {u'Alice':alicePays,u'Bob':bobPays} Now let’s create a large set of transactions, then chunk them into blocks. In [3]: txnBuffer = [makeTransaction() for i in range(30)] Next step: making our very own blocks! We’ll take the first k transactions from the transaction buffer, and turn them into a block. Before we do that, we need to define a method for checking the valididty of the transactions we’ve pulled into the block. For bitcoin, the validation function checks that the input values are valid unspent transaction outputs (UTXOs), that the outputs of the transaction are no greater than the input, and that the keys used for the signatures are valid. In Ethereum, the validation function checks that the smart contracts were faithfully executed and respect gas limits. No worries, though- we don’t have to build a system that complicated. We’ll define our own, very simple set of rules which make sense for a basic token system: The sum of deposits and withdrawals must be 0 (tokens are neither created nor destroyed) A user’s account must have sufficient funds to cover any withdrawals If either of these conditions are violated, we’ll reject the transaction. In [4]: def updateState(txn, state): # Inputs: txn, state: dictionaries keyed with account names, holding numeric values for transfer amount (txn) or account balance (state) # Returns: Updated state, with additional users added to state if necessary # NOTE: This does not not validate the transaction- just updates the state! # If the transaction is valid, then update the state state = state.copy() # As dictionaries are mutable, let's avoid any confusion by creating a working copy of the data. for key in txn: if key in state.keys(): state[key] += txn[key] else: state[key] = txn[key] return state In [5]: def isValidTxn(txn,state): # Assume that the transaction is a dictionary keyed by account names # Check that the sum of the deposits and withdrawals is 0 if sum(txn.values()) is not 0: return False # Check that the transaction does not cause an overdraft for key in txn.keys(): if key in state.keys(): acctBalance = state[key] else: acctBalance = 0 if (acctBalance + txn[key]) < 0: return False return True Here are a set of sample transactions, some of which are fraudulent- but we can now check their validity! In [6]: state = {u'Alice':5,u'Bob':5} print(isValidTxn({u'Alice': -3, u'Bob': 3},state)) # Basic transaction- this works great! print(isValidTxn({u'Alice': -4, u'Bob': 3},state)) # But we can't create or destroy tokens! print(isValidTxn({u'Alice': -6, u'Bob': 6},state)) # We also can't overdraft our account. print(isValidTxn({u'Alice': -4, u'Bob': 2,'Lisa':2},state)) # Creating new users is valid print(isValidTxn({u'Alice': -4, u'Bob': 3,'Lisa':2},state)) # But the same rules still apply! True False False True False Each block contains a batch of transactions, a reference to the hash of the previous block (if block number is greater than 1), and a hash of its contents and the header Building the Blockchain: From Transactions to Blocks¶ We’re ready to start making our blockchain! Right now, there’s nothing on the blockchain, but we can get things started by defining the ‘genesis block’ (the first block in the system). Because the genesis block isn’t linked to any prior block, it gets treated a bit differently, and we can arbitrarily set the system state. In our case, we’ll create accounts for our two users (Alice and Bob) and give them 50 coins each. In [7]: state = {u'Alice':50, u'Bob':50} # Define the initial state genesisBlockTxns = [state] genesisBlockContents = {u'blockNumber':0,u'parentHash':None,u'txnCount':1,u'txns':genesisBlockTxns} genesisHash = hashMe( genesisBlockContents ) genesisBlock = {u'hash':genesisHash,u'contents':genesisBlockContents} genesisBlockStr = json.dumps(genesisBlock, sort_keys=True) Great! This becomes the first element from which everything else will be linked. In [8]: chain = [genesisBlock] For each block, we want to collect a set of transactions, create a header, hash it, and add it to the chain In [9]: def makeBlock(txns,chain): parentBlock = chain[-1] parentHash = parentBlock[u'hash'] blockNumber = parentBlock[u'contents'][u'blockNumber'] + 1 txnCount = len(txns) blockContents = {u'blockNumber':blockNumber,u'parentHash':parentHash, u'txnCount':len(txns),'txns':txns} blockHash = hashMe( blockContents ) block = {u'hash':blockHash,u'contents':blockContents} return block Let’s use this to process our transaction buffer into a set of blocks: In [10]: blockSizeLimit = 5 # Arbitrary number of transactions per block- # this is chosen by the block miner, and can vary between blocks! while len(txnBuffer) > 0: bufferStartSize = len(txnBuffer) ## Gather a set of valid transactions for inclusion txnList = [] while (len(txnBuffer) > 0) & (len(txnList) < blockSizeLimit): newTxn = txnBuffer.pop() validTxn = isValidTxn(newTxn,state) # This will return False if txn is invalid if validTxn: # If we got a valid state, not 'False' txnList.append(newTxn) state = updateState(newTxn,state) else: print("ignored transaction") sys.stdout.flush() continue # This was an invalid transaction; ignore it and move on ## Make a block myBlock = makeBlock(txnList,chain) chain.append(myBlock) In [11]: chain[0] Out[11]: {'contents': {'blockNumber': 0, 'parentHash': None, 'txnCount': 1, 'txns': [{'Alice': 50, 'Bob': 50}]}, 'hash': '7c88a4312054f89a2b73b04989cd9b9e1ae437e1048f89fbb4e18a08479de507'} In [12]: chain[1] Out[12]: {'contents': {'blockNumber': 1, 'parentHash': '7c88a4312054f89a2b73b04989cd9b9e1ae437e1048f89fbb4e18a08479de507', 'txnCount': 5, 'txns': [{'Alice': 3, 'Bob': -3}, {'Alice': -1, 'Bob': 1}, {'Alice': 3, 'Bob': -3}, {'Alice': -2, 'Bob': 2}, {'Alice': 3, 'Bob': -3}]}, 'hash': '7a91fc8206c5351293fd11200b33b7192e87fad6545504068a51aba868bc6f72'} As expected, the genesis block includes an invalid transaction which initiates account balances (creating tokens out of thin air). The hash of the parent block is referenced in the child block, which contains a set of new transactions which affect system state. We can now see the state of the system, updated to include the transactions: In [13]: state Out[13]: {'Alice': 72, 'Bob': 28} Checking Chain Validity¶ Now that we know how to create new blocks and link them together into a chain, let’s define functions to check that new blocks are valid- and that the whole chain is valid. On a blockchain network, this becomes important in two ways: When we initially set up our node, we will download the full blockchain history. After downloading the chain, we would need to run through the blockchain to compute the state of the system. To protect against somebody inserting invalid transactions in the initial chain, we need to check the validity of the entire chain in this initial download. Once our node is synced with the network (has an up-to-date copy of the blockchain and a representation of system state) it will need to check the validity of new blocks that are broadcast to the network. We will need three functions to facilitate in this: checkBlockHash: A simple helper function that makes sure that the block contents match the hash checkBlockValidity: Checks the validity of a block, given its parent and the current system state. We want this to return the updated state if the block is valid, and raise an error otherwise. checkChain: Check the validity of the entire chain, and compute the system state beginning at the genesis block. This will return the system state if the chain is valid, and raise an error otherwise. In [14]: def checkBlockHash(block): # Raise an exception if the hash does not match the block contents expectedHash = hashMe( block['contents'] ) if block['hash']!=expectedHash: raise Exception('Hash does not match contents of block %s'% block['contents']['blockNumber']) return In [15]: def checkBlockValidity(block,parent,state): # We want to check the following conditions: # - Each of the transactions are valid updates to the system state # - Block hash is valid for the block contents # - Block number increments the parent block number by 1 # - Accurately references the parent block's hash parentNumber = parent['contents']['blockNumber'] parentHash = parent['hash'] blockNumber = block['contents']['blockNumber'] # Check transaction validity; throw an error if an invalid transaction was found. for txn in block['contents']['txns']: if isValidTxn(txn,state): state = updateState(txn,state) else: raise Exception('Invalid transaction in block %s: %s'%(blockNumber,txn)) checkBlockHash(block) # Check hash integrity; raises error if inaccurate if blockNumber!=(parentNumber+1): raise Exception('Hash does not match contents of block %s'%blockNumber) if block['contents']['parentHash'] != parentHash: raise Exception('Parent hash not accurate at block %s'%blockNumber) return state In [16]: def checkChain(chain): # Work through the chain from the genesis block (which gets special treatment), # checking that all transactions are internally valid, # that the transactions do not cause an overdraft, # and that the blocks are linked by their hashes. # This returns the state as a dictionary of accounts and balances, # or returns False if an error was detected ## Data input processing: Make sure that our chain is a list of dicts if type(chain)==str: try: chain = json.loads(chain) assert( type(chain)==list) except: # This is a catch-all, admittedly crude return False elif type(chain)!=list: return False state = {} ## Prime the pump by checking the genesis block # We want to check the following conditions: # - Each of the transactions are valid updates to the system state # - Block hash is valid for the block contents for txn in chain[0]['contents']['txns']: state = updateState(txn,state) checkBlockHash(chain[0]) parent = chain[0] ## Checking subsequent blocks: These additionally need to check # - the reference to the parent block's hash # - the validity of the block number for block in chain[1:]: state = checkBlockValidity(block,parent,state) parent = block return state We can now check the validity of the state: In [17]: checkChain(chain) Out[17]: {'Alice': 72, 'Bob': 28} And even if we are loading the chain from a text file, e.g. from backup or loading it for the first time, we can check the integrity of the chain and create the current state: In [18]: chainAsText = json.dumps(chain,sort_keys=True) checkChain(chainAsText) Out[18]: {'Alice': 72, 'Bob': 28} Putting it together: The final Blockchain Architecture¶ In an actual blockchain network, new nodes would download a copy of the blockchain and verify it (as we just did above), then announce their presence on the peer-to-peer network and start listening for transactions. Bundling transactions into a block, they then pass their proposed block on to other nodes. We’ve seen how to verify a copy of the blockchain, and how to bundle transactions into a block. If we recieve a block from somewhere else, verifying it and adding it to our blockchain is easy. Let’s say that the following code runs on Node A, which mines the block: In [19]: import copy nodeBchain = copy.copy(chain) nodeBtxns = [makeTransaction() for i in range(5)] newBlock = makeBlock(nodeBtxns,nodeBchain) Now assume that the newBlock is transmitted to our node, and we want to check it and update our state if it is a valid block: In [20]: print("Blockchain on Node A is currently %s blocks long"%len(chain)) try: print("New Block Received; checking validity...") state = checkBlockValidity(newBlock,chain[-1],state) # Update the state- this will throw an error if the block is invalid! chain.append(newBlock) except: print("Invalid block; ignoring and waiting for the next block...") print("Blockchain on Node A is now %s blocks long"%len(chain)) Blockchain on Node A is currently 7 blocks long New Block Received; checking validity... Blockchain on Node A is now 8 blocks long
ElenaPolitov001/neuro-modelling-interface
Пользовательский интерфейс для системы нейроморфного моделирования
lava-nc/lava-dl
Deep Learning library for Lava