该存储库提供了各种实现、数据集和研究论文,旨在帮助研究人员和开发人员构建准确高效的 Text2SQL 模型。 借助此存储库,用户可以探索 Text2SQL 研究的最新进展。
-
WikiSQL [paper] [code] [dataset] 一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
-
CoSQL [paper] [code] [dataset] 是一个用于构建跨域对话文本到sql系统的语料库。它是Spider和SParC任务的对话版本。CoSQL由30k+回合和10k+带注释的SQL查询组成,这些查询来自Wizard-of-Oz的3k个对话集合,查询了跨越138个领域的200个复杂数据库。每个对话都模拟了一个真实的DB查询场景,其中一个工作人员作为用户探索数据库,一个SQL专家使用SQL检索答案,澄清模棱两可的问题,或者以其他方式通知。
-
CHASE [paper] [code] [dataset] 一个跨领域多轮交互text2sql中文数据集,包含5459个多轮问题组成的列表,一共17940个<query, SQL>二元组,涉及280个不同领域的数据库。
-
BIRD-SQL [paper] [code] [dataset] 数据集是一个英文的大规模跨领域文本到SQL基准测试,特别关注大型数据库内容。该数据集包含12,751对文本到SQL数据对和95个数据库,总大小为33.4GB,跨越37个职业领域。BIRD-SQL数据集通过探索三个额外的挑战,即处理大规模和混乱的数据库值、外部知识推理和优化SQL执行效率,缩小了文本到SQL研究与实际应用之间的差距。
-
DuSQL-中文多表SQL解析数据集 DuSQL是一个面向实际应用的数据集,包含200个数据库,覆盖了164个领域,问题覆盖了匹配、计算、推理等实际应用中常见形式。该数据集更贴近真实应用场景,要求模型领域无关、问题无关,且具备计算推理等能力。Text-to-SQL任务的输入为数据库D和自然语言问题Q,输出为对应的SQL查询语句Y。在DuSQL数据集中,每一条样本是由数据库D、自然语言问题Q、SQL查询语句Y构成的一个三元组 (D, Q, Y ),其中,数据库由若干张表格构成,表格之间通过外键连接。
-
NL2SQL-中文单表SQL解析数据集 NL2SQL是一个多领域的简单数据集,其主要包含匹配类型问题。该数据集主要验证模型的泛化能力,其要求模型具有较强的领域泛化能力、问题泛化能力。
-
Cspider-中英文多表SQL解析数据集 CSpider是一个多语言数据集,其问题以中文表达,数据库以英文存储,这种双语模式在实际应用中也非常常见,尤其是数据库引擎对中文支持不好的情况下。该数据集要求模型领域无关、问题无关,且能够实现多语言匹配。
- Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect
- A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions
- A survey on deep learning approaches for text-to-SQL
-
Awesome Knowledge Distillation of LLM Papers [github] Brief description: A collection of papers related to knowledge distillation of large language models (LLMs). If you want to use LLMs for benefitting your own smaller models training, just take a look at this collection.
-
Specializing Smaller Language Models towards Multi-Step Reasoning
-
Teaching Small Language Models to Reason
-
Large Language Models are Reasoning Teachers
-
The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning Brief description: 收集大量的COT数据,两次训练。COT+二次finetune效果优
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- (DAIL-SQL) Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
- (2023-nips-DIN-SQL) DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
- C3: Zero-shot Text-to-SQL with ChatGPT[PDF][Code]
- MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL[PDF][Code]
- How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings
- (QDecomp) 2023-EMNLP-Exploring Chain of Thought Style Prompting for Text-to-SQL.
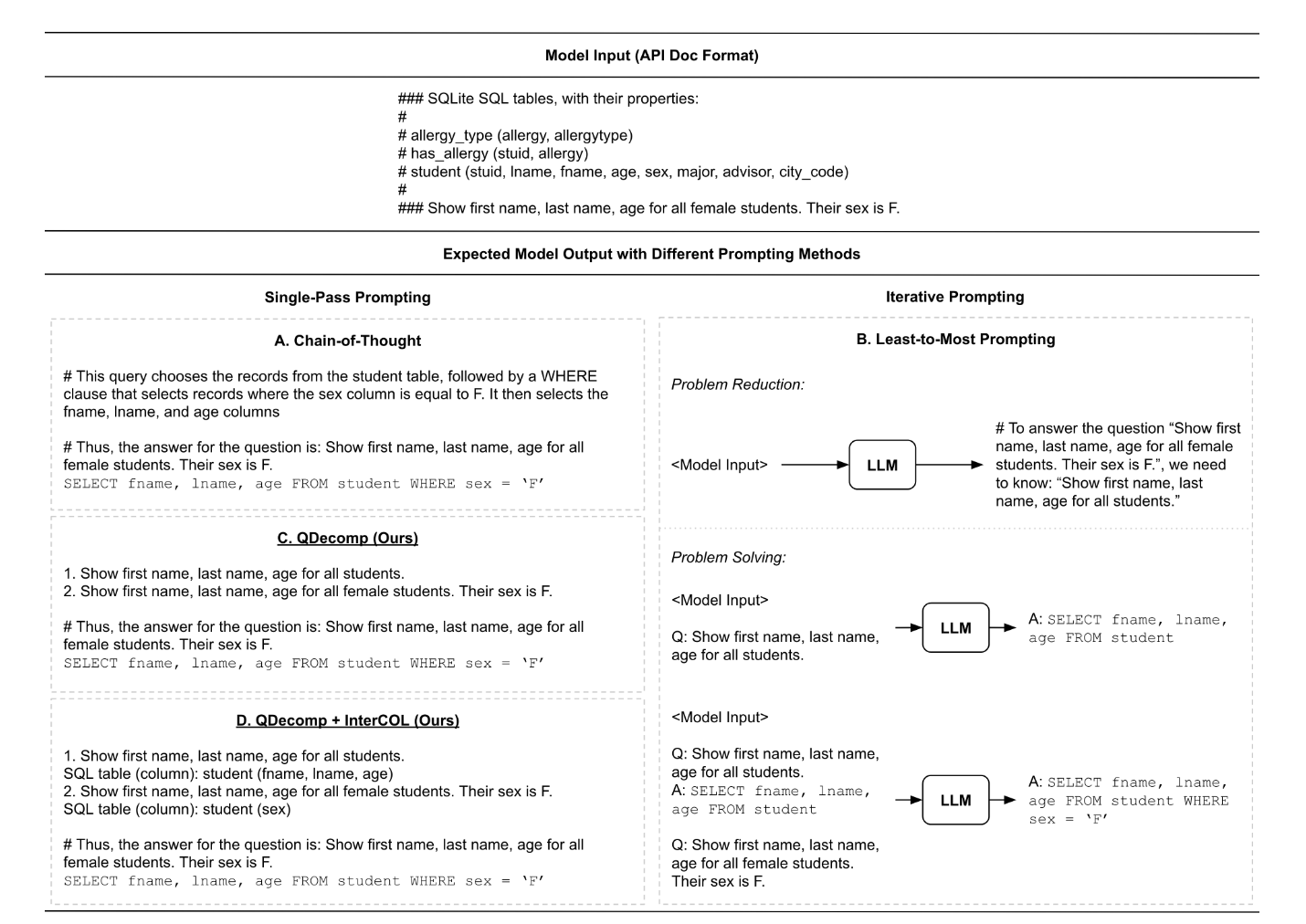
- 2023-EMNLP-F-Selective Demonstrations for Cross-domain Text-to-SQL[PDF][Code]
- 2023-EMNLP-F-ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain-of-Thought. [PDF][Code]
- 2023-EMNLP-F-Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
- 2023-EMNLP-F-Enhancing Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
- 2023-EMNLP-F-SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data.
- Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations

- SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
- Sqlcoder [Code]
- 2023-EMNLP-Benchmarking and Improving Text-to-SQL Generation under Ambiguity.
- 2023-EMNLP-Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL. (label)
- 2023-EMNLP-F-Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison.
- 2023-ACL-Multitask Pretraining with Structured Knowledge for Text-to-SQL Generation.
- Improving Generalization in Language Model-Based Text-to-SQL Semantic Parsing: Two Simple Semantic Boundary-Based Techniques
- SPSQL: Step-by-step Parsing Based Framework for Text-to-SQL Generation
百度整理的数据 https://www.modb.pro/db/495086