When I wanted to migrate that program to sequence signal data, I found that @register_model("mbt2018") The compress and decompress methods of class JointAutoregressiveHierarchicalPriors are very complex
Opened this issue · 1 comments
When I wanted to migrate that program to sequence signal data, I found that
The compress and decompress methods of class
@register_model("mbt2018")
JointAutoregressiveHierarchicalPriors
are very complex. Why is it so complex compared to the compress function and the decompress function of the previous models?
s = 4 # scaling factor between z and y
kernel_size = 5 # context prediction kernel size
padding = (kernel_size - 1) // 2
y_height = z_hat.size(2) * s
y_width = z_hat.size(3) * s
- What is the purpose of the above s? Is it necessary?
y_q = self.gaussian_conditional.quantize(y_crop, "symbols", means_hat)
- Why is symbol quantization used here instead of dequantize, which is the opposite of training?
Also, do I have to train the aux loss very small to get similar results for the forward function and the compress and decompress functions?
Thank you very much for your answer!
The autoregression portion requires a loop of many steps at runtime. This is because the needed information for decoding only becomes available as the tensor is being decoded pixel-by-pixel from top-left to bottom-right. In contrast, during training, all the information about the tensor is immediately available, so that "decoding" can be done in one small step.
| Autoregressive loop |
|---|
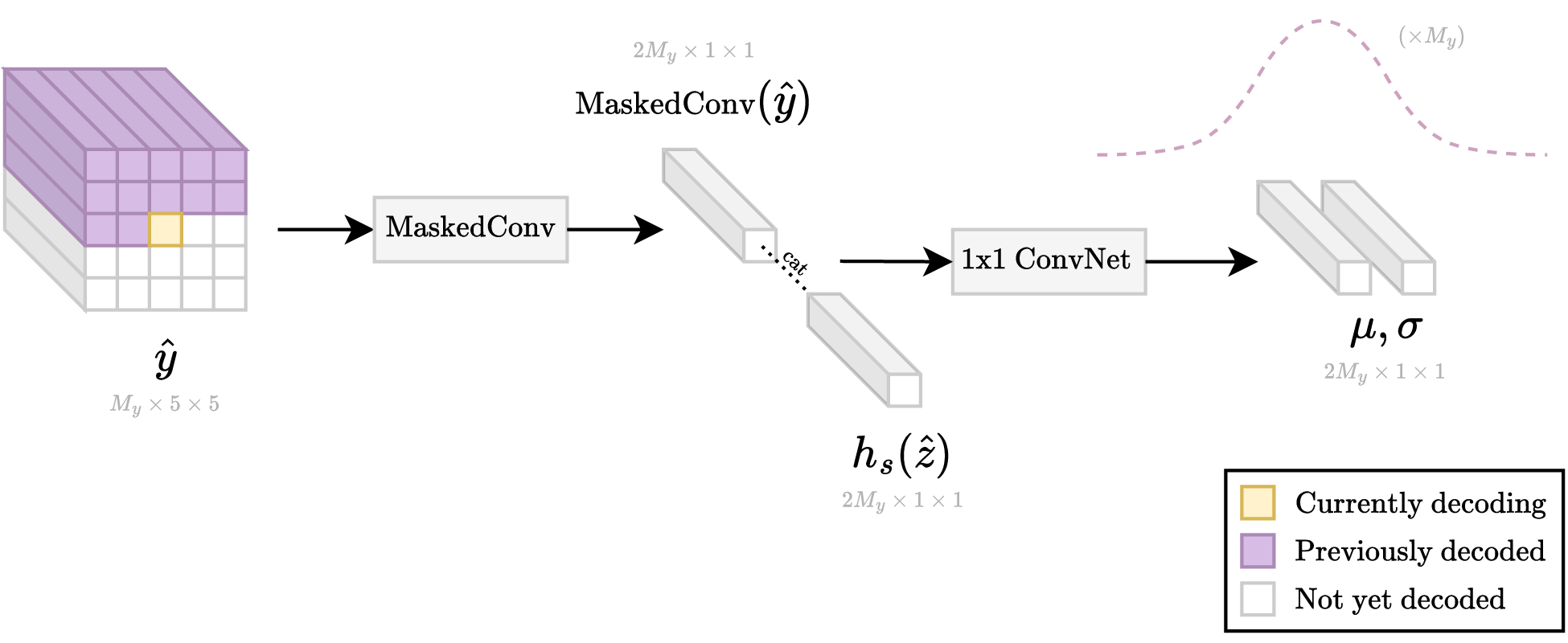 |
| The above operations are repeated in a loop done in raster-scan order (top-left to bottom-right). Previously decoded (purple) pixels are used to help predict the current pixel (yellow). |
Also, previous models contain some amount of code for runtime decoding too, but it's hidden inside the EntropyBottleneck and GaussianConditional classes.
zis smaller thanyby a factor ofs = 2 * 2since there are 2x conv downsample layers of stride 2. Since the decoder has access toz_hat, it uses the shape ofz_hatto determine how bigy_hatwill be. This is necessary because they_hatbitstream doesn't directly record the shape ofy_hat.- Symbol quantization is more accurate than e.g. additive uniform noise. Additive noise is used during training is to ensure the model is resilient to some amount of quantization error.
- For typical image compression models, aux loss usually doesn't need to be that small. See: