Entreprise : Prêt à Dépenser
Logo : 
Développer un modèle de scoring de crédit permettant de prédire la capacité de remboursement des clients n'ayant pas ou peu d'historique bancaire.
- 📊 Données : Base de Données
- 🔍 Missions du projet :
- Construire un modèle de scoring capable de prédire la probabilité de défaut de paiement.
- Développer un dashboard interactif pour aider les gestionnaires de crédits à interpréter les prédictions.
- Mettre en production le modèle via une API Flask, intégrée au dashboard.
- Ouverture et exploration des fichiers
- Préparation des données :
- Création et transformation des variables (dummisation, factorisation)
- Fusion des fichiers et simplification des datasets lourds
- Sélection des nouveaux clients pour l'application
-
📊 Techniques de gestion du déséquilibre :
- SMOTE, Class_Weight, Undersampling, Oversampling

-
⚙ Comparaison des modèles de Machine Learning :
- DummyClassifier, LogisticRegression, RandomForestClassifier, LGBMClassifier
- KNN et XGBOOST (trop longs à exécuter)
-
🔧 Optimisation des hyperparamètres via GridSearchCV
-
🏆 Meilleur modèle sélectionné : LGBMClassifier
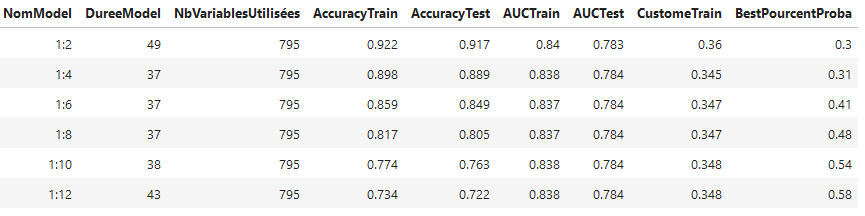


-
Réduction des variables (seuil < 70% de NaNs)
-
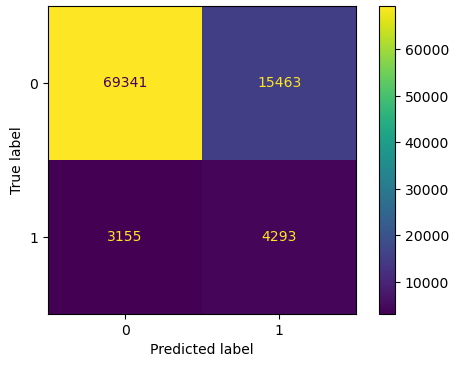
Évaluation des performances :
- Matrice de confusion pour validation des résultats
- Optimisation du seuil de probabilité pour améliorer la métrique de scoring
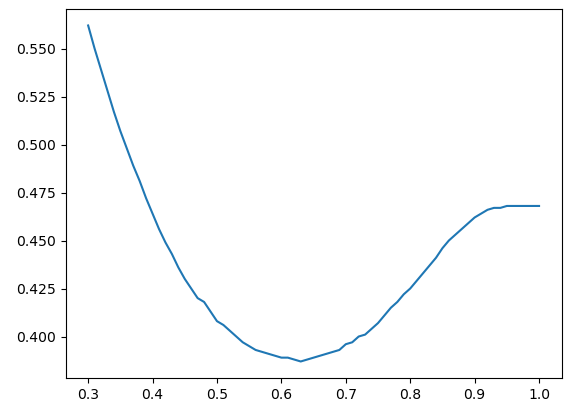
-
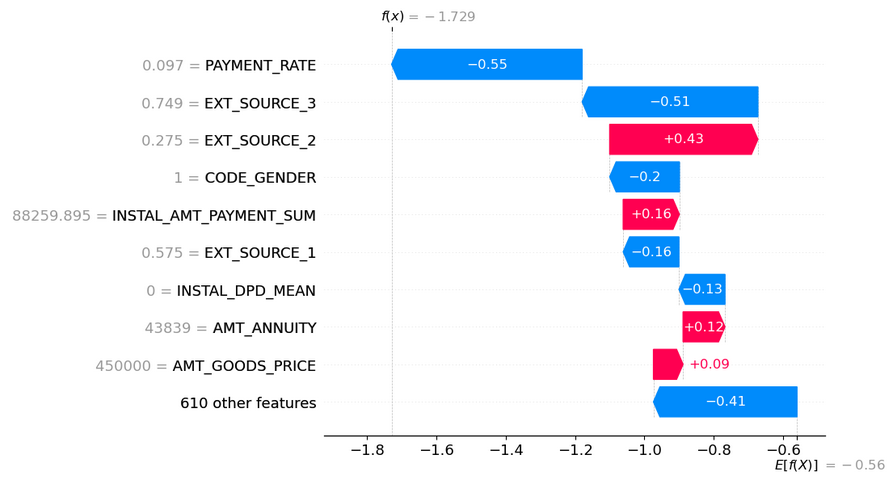
Analyse des variables les plus importantes :
- Feature Importances, SHAP globale et locale



✅ Mise en production sur une API Flask hébergée sur Heroku
✅ Développement d'une application Streamlit intégrant l'API
🖥 Interface utilisateur :

📊 Exemple de prédiction pour un client :

📉 Graphiques explicatifs des prédictions :

-
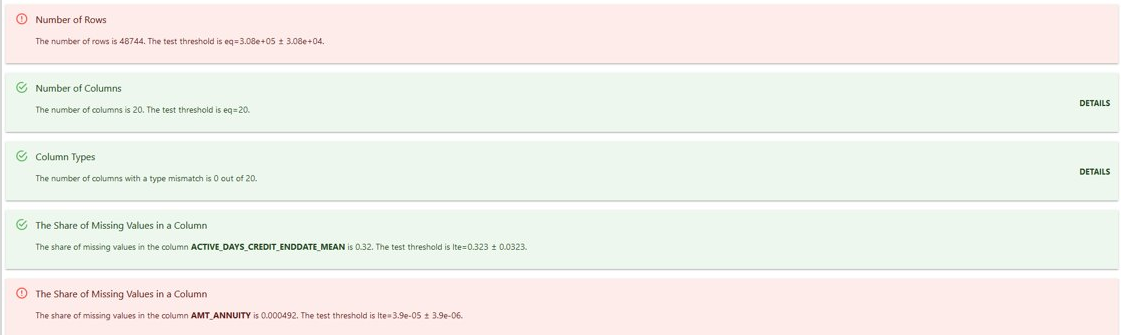
Objectif : Analyser la stabilité du modèle au fil du temps
-
Variables utilisées : Top 20 features les plus influentes



- Langage : Python 🐍
- Librairies : Pandas, Seaborn, Matplotlib, Scikit-learn, LightGBM, MLflow
- Déploiement : Flask (API) sur Heroku, Dashboard Streamlit
- Méthodes utilisées : Machine Learning, SHAP, Feature Engineering, Data Drift Analysis
💡 Ce projet a été réalisé dans le cadre de ma formation Data Science. N’hésitez pas à laisser vos suggestions ou à me contacter pour en discuter !
📩 Contact :
📧 johan.rocheteau@hotmail.fr
🔗 LinkedIn