PTX-ISA
CUDA PTX-ISA Document 中文翻译版
参考官方文档Parallel Thread Execution ISA进行的翻译学习
其中PTX版本为7.8
记录一下学习过程,部分内容会经过提炼加上一些自己的理解。
Chapter 1. Intruduction
1.1 Scalable Data-Parallel Computing using GPUS
PTX定义了一套抽象设备层面的ISA用于通用的并行编程指令。让开发人员可以忽略掉具体的目标设备指令集差异,进行通用的开发。
[ps: 和LLVM IR的设计定位相似]
1.2 Goals of PTX
- 提供了一套覆盖多各种GPU架构的稳定ISA。
- 可以提供近似native的性能(个人理解基本约等于汇编指令,写的逻辑基本就是机器执行逻辑)。
- 为C/C++和其他编译器提供与目标设备架构无关的ISA。
- 为应用和中间件开发人员提供了易用的ISA。
- 为优化代码的生成器和转换器提供了通用ISA。
- 简化库、性能内核和体系结构测试的手工编码。
- 提供了可扩展的编程模型,涵盖多种架构的GPU。
1.3 PTX ISA Version 7.8
7.8版本有如下新特性:
- 新增支持
sm_90和sm_89_架构的支持; - 扩展
bar和barrier指令以支持可选的范围限定符.cta; - 扩展空间限定符
.shared支持可选的子限定符::cta; - 新增
movmatrix指令,支持warp内寄存器进行矩阵转置; - 新增
stmatrix指令,支持将一个或多个矩阵存入共享内存中; - 扩展
.f64浮点类型mma操作,支持形状.m16n8k4、.m16n8k8和.m16n8k16。 - 扩展
bf16数据类型的add,sub,mul,set,setp,cvt,tanh,ex2,atom,red指令 - 新增可选浮点格式
.e4m3和.e5m2;(应该是用与8bit浮点) - 扩展
cvt指令以支持.e4m3和.e5m2浮点格式的转换; - 新增
griddepcontrol指令,作为交流空间以控制存在依赖的线程网格的执行; - 新增
mbarrier指令,可允许在一个新的阶段完成try_wait检查操作; - 新增对新线程组
cluster的支持,cluster是由多个CTA(Cooperative Thread Array)组成; - 为
cluster新增fence,membar,ld,st,atom,red指令; - 为
cluster额外所需的共享空间状态添加支持; - 为
.shared添加加::cluster子限定符,表明cluster-level可见的共享内存,并为其提供相应的isspacep,cvta,ld,st,atom,red指令; - 新增
mapa指令,用于将共享内存中的地址映射到相应的地址,地址位于cluster中不同的cta中。 - 新增
getctarank指令,以查询包含所给地址的CTA的位置; - 新增
barrier.cluster同步指令; - 扩展内存一致性模型以覆盖cluster域;
- 新增cluster相关的特殊寄存器,包括:
%is_explicit_cluster,%clusterid,%nclusterid,%cluster_ctaid,%cluster_nctaid,%cluster_ctarank,%cluster_nctarank; - 新增了cluster维度相关指令,包括:
.reqnctapercluster,.explicitcluster,.maxclusterrank。
Chapter 2. Programming Model
2.1 A Highly Multithreaded Coprocessor
GPU是可以并行执行打量线程的设备,可协助CPU分担大数据量的计算工作。
2.2 Thread Hierarchy
执行GPU内核函数的线程被划分为线程网格(Grid),而Grid又可以再向下划分为Cluster和CTA。
2.2.1 Cooperative Thread Arrays
在PTX的概念中,CTA是一组可以相互通信的线程所组成的线程块,对应CUDA中的Thread Block。
在CTA中同样有warp的概念,warp是CTA的最小执行线程集合,这个概念就不多赘述了。
如下图所示:

2.2.2 Cluster of Coopperative Thread Arrarys
Cluster是由多个CTA组成,设置Cluster大小是可选的,默认是1x1x1的大小。
其中也有特定的符号可以查询CTA的id等。存放在特殊寄存器中。
需要注意的是目前只在sm_90或以上的硬件架构中才支持这一概念。
如下图所示:

2.2.3 Grid of Cluster
Grid是最高的线程等级,包含了多个Cluster。
其中也有特定的符号可以查询Cluster的id等。存放在特殊寄存器中。
2.3 Memory Hierarchy
以sm_90架构为例,因为引入了Cluster的概念,其中的内存分类如下图所示:

主要分为以下几种:
- global memory,可读可写,线程共享;
- constant memory,只读,cached,线程共享;
- texture,只读,cached;
- surface,可读可写,cached;
- shared memory,CTA中线程共享;
- local memory,线程独占;
Chapter 3. PTX Machine Model
3.1 A Set of SIMT Multiprocessors
GPU硬件模型如下图所示:

3.2 Independent Thread Scheduling
在Volta架构之前,一个warp内的32个线程因为共用一个程序计数器,通过active mask来区别active thread。
但是从Volta架构开始,支持了warp内的线程独立调度,每个线程都有自己独立的程序计数器,也就是当出现一个warp内的线程分化的时候,允许不同的线程做不同的事情,不再阻塞。
开发者在编写Volta及以上架构的PTX代码时,需要特别留意因为独立线程调度操作引起的向下兼容性问题。
3.3 On-chip Shared Memory
根据Figure4中的信息显示,每个Multiprocessor可以利用的片上内存主要分为以下四种:
- 每个processor都有一组32-bit的本地寄存器;
- 每个processor共享的
shared memory,其拥有并行数据缓存; - 每个processor可通过共享的只读cache,加速读取设备的指定常量存储区域
constant memory,内存有限; - 每个processor可通过共享的只读cache,加速读取设备指定的存储区域
texutre,支持多种寻址模式和数据滤波器;
需要注意的是,local memory和global memory没有专用cache加速。
Chapter 4. Syntax
PTX源程序模块带有汇编语法风格的指令操作符和操作数。通过ptxas后端编译优化器对PTX源模块进行优化、编译并生成对应的二进制对象文件。
4.1 Source Format
源模块是以ASCII文本形式,以\n进行换行。
所有空格将被忽略,除非在语言中被用于分格标记。
接受C风格的预处理标记,通过#标记,如:#include, #define, #if, #ifdef, #else, #endif, #line, #file
PTX区分大小写,关键字用小写。
每个PTX模块必须以指定PTX语言版本的.version指令开始,
接着是一个.target指令,指定假设的目标体系结构。
4.2 Comments
PTX的注释服从C\C++风格,使用/* 注释内容 */或//均可。
4.3 Statements
PTX中的陈述语句既包含预处理(directive)也包含指令(instruction),以可选的指令标记开头并以分号结尾。
例子:
.reg .b32 r1, r2;
.global .f32 array[N];
start: mov.b32 r1, %tid.x;
shl.b32 r1, r1, 2; // shift thread id by 2 bits
ld.global.b32 r2, array[r1]; // thread[tid] gets array[tid]
add.f32 r2, r2, 0.5; // add 1/2
【PS】文档原话:“A PTX statement is either a directive or an instruction”。这里directive和instruction的区别理解了半天,最后可以理解为,directive近似预处理的东西或者说特殊字符处理,起到编译器指示作用。而instruction是指令,可以理解为发生在机器上的“动词”。
4.3.1 Directive Statements
PTX中支持的编译器指示如下表所示:

【PS】可以看到如.reg、pragma等常用的编译指示关键字。
4.3.2 Instruction Statements
指令由一个指令操作码和由逗号分隔的零个或多个操作数组成,并以分号结束。操作数可以是寄存器变量,常量表达式、地址表达式或指令标签名称。
指令有一个可选的判断条件作控制流的跳转。判断条件在可选的指令标记后面,在操作码前面,并被写成@p,其中p是一个条件寄存器。判断条件可以取非,写成@!p。
指令标记之后的字段,首先是目标操作数,后续是源操作数。
指令关键字如下表所示:

4.4 Identifiers
用户定义的标识符,服从C++的规则,字母或者下划线开头,或者以$开头。
PTX没有指定标识符的最大长度,并表示所有实现至少支持1024个字符。
PTX支持以%为前缀的变量,用于避免命名冲突,如:用户定义的变量和编译器生成的变量名。
PTX以%为前缀预定义了一个常量和一小部分特殊寄存器,如下表所示:

其中WARP_SZ表明了目标设备的warp大小,默认值都是32。
4.5 Constants
PTX支持整型和浮点常量和常量表达式。这些常数可用于数据初始化和作为指令的操作数。对于整型、浮点和位大小类型检查规则是相同的。
对于判断类型的数据和指令,允许使用整型常量,即0为False和!0为True。
4.5.1 Integer Constants
整型常量的大小为64位,有符号或无符号,即每个整数常量的类型为.s64或.u64。
而在指令或数据初始化中使用时,每个整整型常量会根据使用时的数据或指令类型转换为适当的大小。
整型常量可以写作十六进制、十进制、八进制、二进制,写法同C语言一直,最后加U表示unsigned:
十六进制: 0[xX]{hexdigit}+(U)
十进制: {nonzero-digit}{digit}+(U)
八进制: 0{octal digit}+(U)
二进制: 0[bB]{bit}+(U)
4.5.2 Floating-Point Constants
浮点常量表示为64位双精度值,所有浮点常量表达式都使用64位双精度算术求值。
需要注意的是如果用十六进制表示,是表示32位单精度浮点。并且可能不会被用在常量表达式中。
浮点数的值的第一种表示,可以用一个可选的小数点和带符号的指数进行表达(应该是指:1.34e-2)。但和C\C++不同的是,在PTX里面不能通过后缀来区分浮点数的的类型,比如:1.0f。
浮点数的值的第二种表示,可以使用十六进制进行表示,如下:
0[fF]{hexdigit}{8} // single-precision floating point
0[dD]{hexdigit}{16} // double-precision floating point
举个例子:
mov.f32 $f3, 0F3f800000; // 1.0, 表示:$f3 = 1.0;
4.5.3 Predicate Constants
整型常量也可以作为判断数据,0表示False,!0表示True。
4.5.4 Constant Expressions
在PTX中,常量表达式是使用C中的操作符形成的,并使用与C中类似的规则求值,但通过限制类型和大小、删除大多数强制转换和定义完整语义来简化,以消除C中表达式求值依赖于实现的情况。(减去编译器推导数据类型等的负担)
常量表达不支持从整型到浮点数的类型转换。
常量表达式中的优先级顺序从上到下如小表所示,第一行执行优先级最高,同一行的优先级相同,对于多个一元操作求值的话是从右向左的顺序,而二元操作是从左向右:

4.5.5 Integer Constant Expression Evaluation
整型常量表达式,在编译时有一套规则进行推导。这些规则基于C中的规则,但它们已被简化为只适用于64位整数,并且在所有情况下都完全定义了行为。(可以理解为不会有二义性的表达式)
- 默认整型常数是
signed除非需要转换为unsigned防止溢出,或者手动添加U后缀如:
42, 0x1234, 0123 are signed.
0xfabc123400000000, 42U, 0x1234U are unsigned
- 一元加减符保留输入操作数的类型,如:
+123, -1, -(-42) are signed.
-1U, -0xfabc123400000000 are unsigned.
- 一元操作中的取非
!操作会产生带符号的0或1。 - 位操作中的取反操作
~默认将源操作数是为unsigned,结果也为unsigned。 - 一些二元操作需要规范化源操作数,如果其中有一个是
unsigned,那么需要将两个源操作数都转换为unsigned进行计算。这种被称为常用算数转换。 - 加减乘除执行计算之后,结果与源操作数的数据类型保持一致,即,有一个为
unsigned则结果也为unsigned,反之则为signed。 - 取余
%的操作会将操作数解释为unsigned,与C不同,C允许负除数。但属于实现定义行为 - 移位操作的第二个源操作数解释为
unsigned,结果数据类型与第一个源操作数一致。如果是signed右移则为算术右移,unsigned为逻辑右移。 - 位与
&,位或|,位异或^操作也服从常用数据转换规则。 - 与
&&,或||,等于==,不等!=操作产生signed结果,值为0或1。 - 大小比较运算符(
<、>、<=、>=)对于源操作数符服从常用转换规则,产生signed结果,值为0或1。 - 可使用
(.s64)或(.u64)将表达式转换为signed或unsigned。 - 对于三元判断符
?:,第一个源操作数必须是整型,但第二个和第三个可以是整型或者浮点型,其结果类型与选择的操作数类型一致。
4.5.6 Summary of Constant Expression Evaluation
下表总结了常量表达式的推导规则:

Chapter 5. State Spaces, Types, and Variables
虽然特殊的资源在不同架构的GPU上可能是不同的,但资源种类是通用的,这些资源通过状态空间和数据类型在PTX中被抽象出来。
5.1 State Spaces
状态空间是具有特定特征的存储区域。所有变量都驻留在某个状态空间中。状态空间的特征包括其大小、可寻址性、访问速度、访问权限和线程之间的共享级别。
不同的状态空间如下表所示:

不同状态空间的性质如下表所示:

5.1.1 Register State Space
.reg寄存器读写速度很快,但是数量有限制,并且不同架构的寄存器数量不一样。当寄存器使用超标时,会溢出到内存中,影响读写速度。
寄存器可以是有类型的,也可以是无类型的,但是寄存器大小是被严格限制的,除了1-bit的判断符(bool)寄存器以外,还有宽度为8-bit\16-bit\32-bit\64-bit的标量寄存器,以及16-bit\32-bit\64-bit\128-bit的矢量寄存器。
8-bit寄存器最常见用途是和ld、st和cvt指令一起使用,或作为向量组的元素。
寄存器与其他状态空间的区别在于,它们不是完全可寻址的,也就是说,不可能引用寄存器的地址。(可以理解为仅在作用域内有效,即寄存器是栈上存储)
寄存器对于多字的读写可能会需要做边界对齐。
5.1.2 Special Register State Space
.sreg特殊寄存器是预定义的平台特殊寄存器,如grid、cluster等相关参数,所有的特殊寄存器都是预定义的。
5.1.3 Constant State Space
.const常量状态空间是由host端初始化的只读内存,通常使用ld.const进行访问,目前常量内存的限制为64KB。
另外还有一个640KB的常量内存,被划分为10个64KB的区域,驱动程序可以在这些区域上进行初始化数据分配,并通过指针的形式作为kernel参数传入。
但是,因为这十个常量内存区域并不连续,所以驱动程序在分配的时候应该保证每一块常量内存不得超过64KB,不得越界。
静态大小的常量变量有一个可选的变量初始化器。默认情况下,没有显式初始化式的常数变量被初始化为零。驱动程序分配的常量缓冲区由host初始化,并将指向这块常量内存的指针作为kernel参数传入。
5.1.3.1. Banked Constant State Space (deprecated)
被弃用的就不赘述了。
5.1.4. Global State Space
.global全局状态空间是能够被kernel中所有线程都访问到的内存空间,使用ld.global、st.global和atom.global指令访问全局内存。
没有显示初始化的全局变量默认初始化为0。
5.1.5. Local State Space
.local本地状态空间是每个线程私有的内存空间。通常是带缓存的标准内存。其有大小限制,因为必须按每一个线程进行分配。
使用ld.local、st.local进行本地变量的访问。
在编译的ABI的时候,我们必须将.local声明在函数作用域内,并且内存申请在栈上。
在不支持堆栈的实现中,所有本地内存变量都存储在固定地址中,不支持递归函数调用,并且.local变量可能在模块(module)作用域声明。
在PTX 3.0及一下,module-scope .local将默认被禁用。
5.1.6. Parameter State Space
.param参数状态空间主要用于以下情况:
- 作为从host传入kernel的输入参数;
- 在kernel执行过程中,为调用的device函数声明正式的输入和返回参数;
- 通常可用于声明局部作用域的字节矩阵,主要通过值传递大型的结构体。
kernel函数参数与device函数参数是不同的,一个是内存的访问与共享权限不同(read-only对比read-write,per-kernel对比per-thread)。
PTX 1.x版本只支持kernel函数参数,从2.0开始.param才支持device函数参数(需要sm_20及以上架构)。
【PS】PTX代码不应该对.param空间变量的相对位置或顺序做任何假设。(个人理解应该保持唯一的相对顺序)
5.1.6.1. Kernel Function Parameters
每个内核函数定义都包含一个可选的参数列表。这些参数是在.param状态空间中声明的可寻址只读变量。通过使用ld.param指令访问内核参数值。内核参数变量被grid内的所有线程共享。
内核参数的地址可以使用mov指令移动到寄存器中。结果地址在.param状态空间中,可以使用ld.param指令访问。
两个例子:
.entry foo ( .param .b32 N, .param .align 8 .b8 buffer[64] )
{
.reg .u32 %n;
.reg .f64 %d;
ld.param.u32 %n, [N];
ld.param.f64 %d, [buffer];
...
.entry bar ( .param .b32 len )
{
.reg .u32 %ptr, %n;
mov.u32 %ptr, len; // 寄存器%ptr指向len变量的地址
ld.param.u32 %n, [%ptr]; //寄存器%n读取%ptr指针指向的值
【PS】:现阶段的应用中,不循序创建一个指向由kernel参数传入的常量内存的通用指针。(没试过,不太确定cvta.const指令是什么)
5.1.6.2. Kernel Function Parameter Attributes
kernel函数参数可以用可选的.ptr属性声明,可用来指示参数是指向内存的指针,也可表明指针所指向内存的状态空间和对齐方式。
5.1.6.3. Kernel Parameter Attribute: .ptr
.ptr语法:
.param .type .ptr .space .align N varname
.param .type .ptr .align N varname
.space = { .const, .global, .local, .shared };
其中.space和.align是可选的属性,.space缺失则默认是.const, .global, .local, .shared中的一种(基本属于未定义,所以一般还是不建议省略),.align缺失则默认按照4 byte对齐。
【PS】:.ptr、.space和.align之间不能有空格。
举个例子:
.entry foo ( .param .u32 param1,
.param .u32 .ptr.global.align 16 param2,
.param .u32 .ptr.const.align 8 param3,
.param .u32 .ptr.align 16 param4 // generic address
// pointer
) { .. }
5.1.6.4. Device Function Parameters
从PTX2.0开始扩展了device参数空间的使用,最常见的用法是不按照寄存器大小传值,如传入8 bytes大小的结构体参数。
举个例子:
// pass object of type struct { double d; int y; };
.func foo ( .reg .b32 N, .param .align 8 .b8 buffer[12] )
{
.reg .f64 %d;
.reg .s32 %y;
ld.param.f64 %d, [buffer];
ld.param.s32 %y, [buffer+8];
...
}
// 下面的片段来自kernel中对于device函数的调用
// struct { double d; int y; } mystruct; is flattened, passed to foo
...
.reg .f64 dbl;
.reg .s32 x;
.param .align 8 .b8 mystruct; // 在local内存上声明结构体
...
st.param.f64 [mystruct+0], dbl; // 结构体赋值
st.param.s32 [mystruct+8], x; // 结构体赋值
call foo, (4, mystruct); // device函数调用,传参
函数的输入参数可以使用ld.param进行读,返回值可以使用st.param进行写。
但是写input参数和读返回值都是不合法的。
除了按值传递结构外,当形式形参的地址在被调用的函数中被取时,还需要.param空间标注。
在PTX中,函数输入参数的地址可以使用mov指令移动到寄存器中。注意,如果需要,参数将被复制到堆栈中,因此地址将位于.local状态空间中,并通过ld.local和st.local指令进行访问。
不能使用mov来获取局部作用域的.param空间变量的地址。从PTX ISA 6.0版本开始,可以使用mov指令获取设备函数返回参数的地址。
举个例子:
// pass array of up to eight floating-point values in buffer
.func foo ( .param .b32 N, .param .b32 buffer[32] )
{
.reg .u32 %n, %r;
.reg .f32 %f;
.reg .pred %p;
ld.param.u32 %n, [N];
// 注意此处,如果buffer实在foo的local-scope内部,那么是不能使用mov来获取地址的。
mov.u32 %r, buffer; // forces buffer to .local state space
Loop:
setp.eq.u32 %p, %n, 0;
@%p: bra Done;
ld.local.f32 %f, [%r];
...
add.u32 %r, %r, 4;
sub.u32 %n, %n, 1;
bra Loop;
Done:
...
}
5.1.7. Shared State Space
.shared共享内存属于执行运算的CTA并且可以被同属一个cluster中的所有CTA的线程读写。
附加的子限定符::cta或::cluster可以在使用.shared的指令中指定状态空间,指示该地址是否属于正在执行的CTA或cluster中的任何CTA的共享内存。(即cluster共享,还是CTA内部共享)
.shared::cta的地址窗口也属于.shared::cluster的地址窗口。如果.shared状态空间中没有指定子限定符,则默认为::cta。例如,ld.shared等价于ld.shared::cta。
在.shared状态空间中声明的变量引用当前CTA中的内存地址。指令mapa给出了cluster中另一个CTA中对应变量的.shared::cluster地址。
共享内存通常有一些优化来支持共享。一个例子是广播,所有线程从同一个地址读取。另一种是从顺序线程的顺序访问。
5.1.8. Texture State Space (deprecated)
弃用的纹理状态空间,不多赘述。
5.2. Types
5.2.1. Fundamental Types
在PTX中,基本类型反映了目标架构支持的原生数据类型。基本类型同时指定类型和大小。
寄存器变量总是一种基本类型,指令对这些类型进行操作。
基本类型如下:

大多数指令都有一个或多个类型说明符,用于完全指定指令的行为。操作数类型和大小将根据指令类型进行检查,以确保兼容性.
位大小相同的任何基本类型之间都是兼容的。
原则上,所有基本类型(除开predicate类型)可以只用位大小进行声明,但标明具体类型,可以提升可读性并且方便做类型检查。
5.2.2. Restricted Use of Sub-Word Sizes
.u8、.s8和.b8被限制在ld、st和cvt指令中使用。
.fp16只能被用在与fp32和fp64的相互转化中,以及半精度浮点指令和纹理获取指令中。
.fp16x2只能被用在半精度浮点指令和纹理获取中。
为了方便起见,ld、st和cvt指令允许源操作数和目标数据操作数比指令类型的大小更宽。
例如,在加载、存储或转换为其他类型和大小时,8位或16位的值可能直接保存在32位或64位寄存器中。
5.2.3. Alternate Floating-Point Data Formats
PTX中支持的基本浮点类型具有隐式的位表示,表示用于存储指数和尾数的位数。(也就是说对于浮点来说,有多种不同的位表示方规则)。
比如:IEEE 754的标准fp16的位组合规则是,1个符号位 + 5个指数位 + 10个精度位。简称位s1-e5-m10
在PTX中还额外支持如下特殊的半精度位组合:
- bf16
- s1-e8-m7,寄存器中的
bf16必须被声明为.b16。
- s1-e8-m7,寄存器中的
- e4m3
- s1-e4-m3,e4m3编码不支持infinity和Nan,被限制在0x7f和0xff。e4m3必须以pack的形式
e4m3x2,并且必须被声明位.b16。
- s1-e4-m3,e4m3编码不支持infinity和Nan,被限制在0x7f和0xff。e4m3必须以pack的形式
- e5m2
- s1-e5-m2,同e4m3类似,也必须以pack的形式使用
e5m2x2,并且必须被声明为.b16。
- s1-e5-m2,同e4m3类似,也必须以pack的形式使用
- ft32
- 这是一种特殊的32位浮点,由矩阵乘和累加指令支持,范围与fp32相同,但是精度低一些(>=10bit),具体的内部布局由实现定义。PTX便于从
.fp32到.tf32的转化,.tf32寄存器必须声明为.b32。
- 这是一种特殊的32位浮点,由矩阵乘和累加指令支持,范围与fp32相同,但是精度低一些(>=10bit),具体的内部布局由实现定义。PTX便于从
替代数据格式不能用作基本类型。它们被某些指令支持为源格式或目标格式。
5.3. Texture Sampler and Surface Types
PTX中有一些内建的不透明类型来定义texture、sampler、surface descriptor变量。
这些类型的命名字段类似于结构体,但所有的信息如:布局、字段顺序、基址和总体大小都隐藏在PTX程序中,因此称为不透明。
这些不透明类型的使用有如下限制:
- 变量定义在全局(module)作用域和内核参数列表中;
- module-scope变量的静态初始化使用逗号隔开静态赋值表达式;
- texture\sampler\surface的引用通过texture\surface的load\save指令完成
tex,suld,sust,sured。 - 通过查询指令检索指定成员的值;
- 创建指向不透明变量的指针可以使用
mov指令,如:mov.u64 reg, opaque_var。产生的指针可以从内存中读写,也可以通过参数传递给函数,还可以被texture\surface的读写查询指令所引用。 - 不透明变量不能出现在初始化中,如:初始化一个指针指向不透明变量。
【PS】:从PTX ISA 3.1版本开始支持使用指向不透明变量的指针间接访问texture\surface,需要目标架构sm_20及以上。
上述的三种内建的不透明类型是.texref、.samplerref和.surfref。
使用texture + sampler的时候,由两种操作模式可以选择:
- 一种是
unified mode,这种模式下,texture和sampler都用过单个.texref进行访问。 - 另一种模式是
independent mode,这种模式下,texture和sampler都有各自的句柄,允许他们分开定义再合并使用,在这种模式下.texref中关于sampler的定义将被忽略,因为会在.samplerref被定义。
下面两张表列出了在两种模式下面各种成员,这些成员及其值有具体的获取方法,在纹理HW类中定义,以及通过API查询。
-
Unified Mode
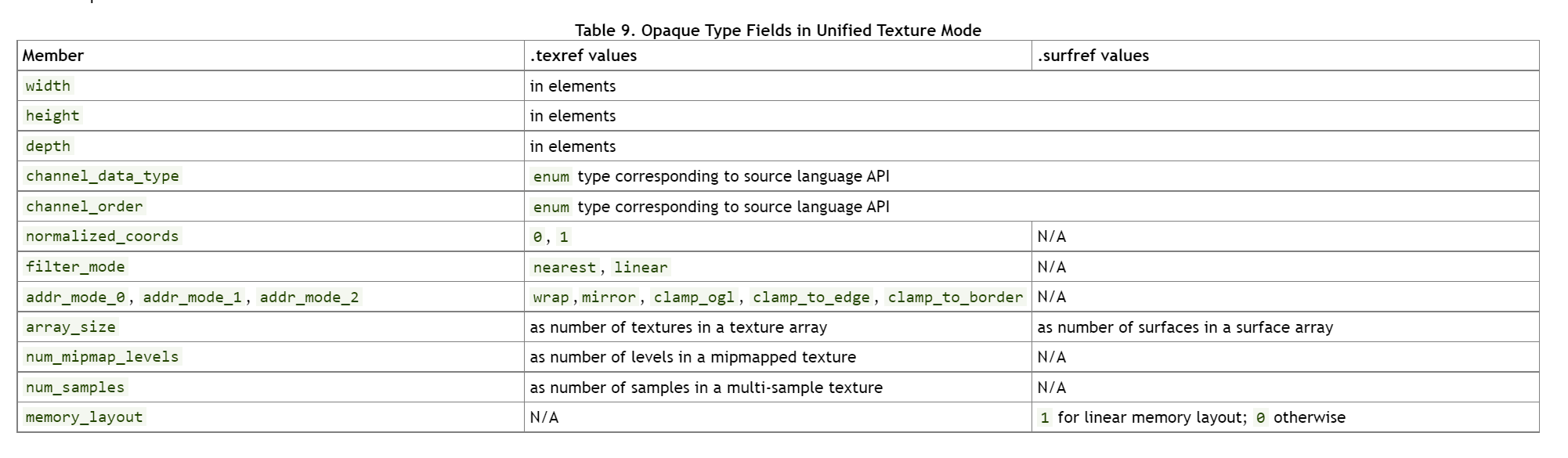
-
Independent Mode
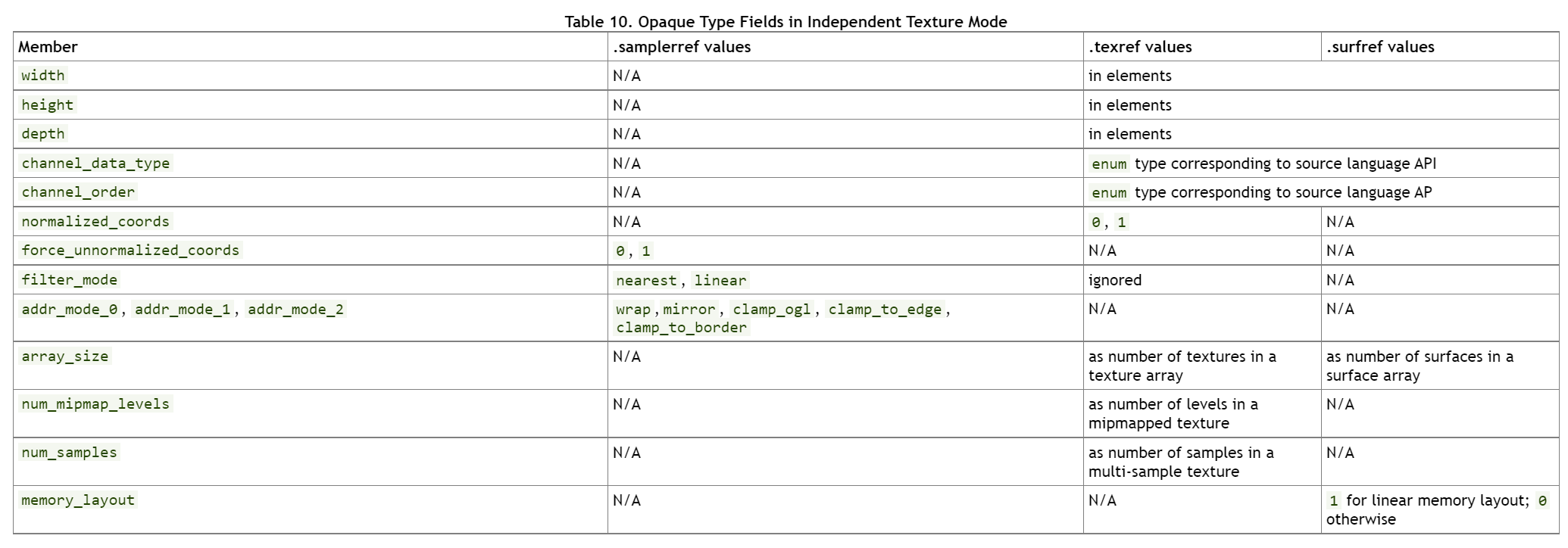


5.3.1. Texture and Surface Properties
上表中的width、height和depth表示texture\surface在每个维度的元素个数(更准确的说可以理解为像素pixel)。
其中每一个像素的属性可以由channel_data_type和channel_order来表示。、
OpenCL中的定义是被PTX支持的,所以可以参考OpenCL的定义如下:


5.3.2. Sampler Properties
关于sampler的属性,代表的意义如下:
normalized_coords:表示坐标是否归一化为[0.0, 1.0f]。如果没有被显式设置,则会在runtime阶段根据源码进行设置(也就是说还有可能默认被设为开启??没试过,通常是默认非归一化的)filter_mode:表示如何基于坐标值计算texture读取的像素。addr_mode_{0,1,2}: 定义了每个维度的寻址模式,该模式决定了每个维度如何处理out-of-range的坐标。force_unnormalized_coords: 在Independant Mode下独有的属性,字面意思很好理解,会去将texture中的normalized_coords强行改写为unnormalized_coords当其被设置为True时,如果是False,那么就默认使用texture中的设置。- 【PS】:该属性被用在编译OpenCL to PTX的时候。
我们在声明这些不透明类型的时候,如果位于module-scope中,则需要使用.global状态空间;而如果位于kernel参数列表中,则需要使用.param状态空间。
举个例子:
.global .texref my_texture_name;
.global .samplerref my_sampler_name;
.global .surfref my_surface_name;
在,.global状态空间中,可以使用静态列表进行初始化,如:
.global .texref tex1;
.global .samplerref tsamp1 = { addr_mode_0 = clamp_to_border,
filter_mode = nearest
};
5.3.3. Channel Data Type and Channel Order Fields
见5.3.1的表
5.4. Variables
在PTX中,除了基本的数据类型,还支持简单的聚合数据类型,如矢量(vector)和数组(array)。
5.4.1. Variable Declarations
所有的存储数据都是通过变量声明来定义的。
标量声明包含,变量所在状态空间,类型和大小,变量命。以及可选的数组大小,可选的初始化方式,可选的变量固定地址。
如:
.global .u32 loc;
.reg .s32 i;
.const .f32 bias[] = {-1.0, 1.0}; //初始化常量内存
.global .u8 bg[4] = {0, 0, 0, 0}; //初始化全局内存
.reg .v4 .f32 accel; // 初始化vector float4 寄存器
.reg .pred p, q, r; // 初始化predict寄存器p、q、r
5.4.2. Vectors
任何长度为2或4的non-predicat基础类型矢量可以通过.v2或.v4的前缀进行声明。
矢量必须是基础类型,可以被声明为寄存器,长度不能超过128bit,只包含3个元素的矢量也会被创建为.v4矢量,剩余一个元素是padding位。
例子:
.global .v4 .f32 V; // a length-4 vector of floats
.shared .v2 .u16 uv; // a length-2 vector of unsigned short
.global .v4 .b8 v; // a length-4 vector of bytes
默认情况下,矢量的大小是内存对齐的(与长度和类型大小有关),所以在我们进行矢量读写的时候,应该保证访问的内存大小是对齐到矢量的整数倍的。
5.4.3. Array Declarations
数组的声明和C一样,无论是一维还是多维,并且声明的大小必须是常量表达式。
例子:
.local .u16 kernel[19][19];
.shared .u8 mailbox[128];
当数组的声明伴随着初始化表达式时,数组的第一维尺寸是可以被省略的,一维的尺寸是由舒适化表达式中的元素决定的。
例子:
.global .u32 index[] = { 0, 1, 2, 3, 4, 5, 6, 7 }; // index[8]
.global .s32 offset[][2] = { {-1, 0}, {0, -1}, {1, 0}, {0, 1} }; // index[4][2]
5.4.4. Initializers
变量的初始化方法在前文也有提到,和C\C++是类似的。并且时支持不完整的初始化,会默认进行补0操作。
例子:
.const .f32 vals[8] = { 0.33, 0.25, 0.125 };
等价于:.const .f32 vals[8] = { 0.33, 0.25, 0.125, 0.0, 0.0, 0.0, 0.0, 0.0 };
.global .s32 x[3][2] = { {1,2}, {3} };
等价于:.global .s32 x[3][2] = { {1,2}, {3,0}, {0,0} };
当前只支持const和global内存空间的变量初始化操作,如果上述两种空间中的变量没有显式的初始化,则默认初始化位0。不允许初始化外部变量。
在初始化式中出现的变量名表示变量的地址;这可用于静态初始化指向变量的指针。
初始化式支持var+offset的表达式,offset表示基于var地址的byte偏移。
PTX提供了一个操作符generic(),用于获取变量的地址。
从PTX ISA 7.1版本开始,提供了一个mask()操作符,其中mask是一个整型的立即数。
mask()操作符中唯一允许的表达式是整数常量表达式和符号表达式,用于表示变量地址。
mask()操作符可以理解为通过通过为&操作和移位操作提取出某个byte的数据,并且作为初始化数据。
支持的mask立即数有:
0xFF, 0xFF00, 0xFF0000, 0xFF000000, 0xFF00000000,
0xFF0000000000, 0xFF000000000000, 0xFF00000000000000。
.const .u32 foo = 42;
.global .u32 bar[] = { 2, 3, 5 };
.global .u32 p1 = foo; // offset of foo in .const space
.global .u32 p2 = generic(foo); // generic address of foo
// array of generic-address pointers to elements of bar
.global .u32 parr[] = { generic(bar), generic(bar)+4, generic(bar)+8 };
// 为了简洁此处省略掉了mask操作符
// 提取foo的某一个btye初始化为u8数据。
.global .u8 addr[] = {0xff(foo), 0xff00(foo), 0xff0000(foo), ...};
.global .u8 addr2[] = {0xff(foo+4), 0xff00(foo+4), 0xff0000(foo+4),...}
.global .u8 addr3[] = {0xff(generic(foo)), 0xff00(generic(foo)),...}
.global .u8 addr4[] = {0xff(generic(foo)+4), 0xff00(generic(foo)+4),...}
// mask() operator with integer const expression
.global .u8 addr5[] = { 0xFF(1000 + 546), 0xFF00(131187), ...};
TODO: 这部分还有关于device function name出现在初始化式里面的情况。因为此处还不太理解,所以后续再展开。
持有变量或函数地址的变量类型只能是.u8、.u32或.u64。
.u8类型只能搭配在mask()使用(如上文所述,mask操作符取的就是8-bit数据)。
初始化式不支持.fp16、.fp16x32和.pred,其余类型都支持。
.global .s32 n = 10;
.global .f32 blur_kernel[][3]= {{.05,.1,.05},{.1,.4,.1},{.05,.1,.05}};
.global .u32 foo[] = { 2, 3, 5, 7, 9, 11 };
.global .u64 ptr = generic(foo); // generic address of foo[0]
.global .u64 ptr = generic(foo)+8; // generic address of foo[2]
5.4.5 Alignment
所有可寻址变量的内存字节对齐数,可以在变量生命的时候被定义,使用可选的.align关键字。
关于对齐,和c\c++中的类似,就不多赘述了,举个例子:
// allocate array at 4-byte aligned address. Elements are bytes.
.const .align 4 .b8 bar[8] = {0,0,0,0,2,0,0,0};
注意,所有访问内存的PTX指令都要求地址与访问大小的倍数对齐。内存指令的访问大小是在内存中访问的总字节数。如:ld.v4.b32的访问大小是16bytes,而atom.fp16x2的访问大小是4bytes。
5.4.6. Parameterized Variable Names
由于PTX支持虚拟寄存器,编译器前端生成大量寄存器名是很常见的。寄存器支持像数组一样的批量声明。
例子:
// 声明了100个寄存器,按照后缀区别。
.reg .b32 %r<100>; // declare %r0, %r1, ..., %r99
这种简写语法可以用于任何基本类型和任何状态空间,并且可以在前面加上一个对齐说明符。数组变量不能以这种方式声明,也不允许初始化式。
5.4.7. Variable Attributes
变量可以用可选的.attribute指令来声明,该指令允许指定变量的特殊属性。关键字.attribute后面是在括号内的属性说明。多个属性用逗号分隔。
5.4.8. Variable Attribute Directive: .attribute
目前在手册中只说了如下的一种.attribute属性:
.managed:该属性指定变量将分配到统一虚拟内存中,在该内存中,系统中的host和device可以直接引用该变量。注意只能用于.global状态空间。
该属性在PTX ISA 4.0中首次出现。 在sm_30及以上架构被支持。
例子:
.global .attribute(.managed) .s32 g;
.global .attribute(.managed) .u64 x;
Chapter 6. Instruction Operands
6.1 Operand Type Information
指令中的所有操作数都有其声明中的已知类型。每个操作数类型必须与指令模板和指令类型所确定的类型兼容。类型之间不存在自动转换。
类型与指令类型不同但与指令类型兼容的操作数被静默转换为指令类型。
6.2. Source Operands
源操作数在指令描述中用通常用名称a、b和c表示。
ALU的操作指令必须声明在.reg寄存器空间,并且大多数情况下,操作数的大小都必须一致。
cvt指令接受任何类型和大小的操作数,因为它的任务就是对做转换。
ld、st、mov和cvt指令都是将数据从一处拷贝到另一处,需要注意的是:
ld和st指令是将数据在可寻址空间和寄存器空间之前移动。mov指令则是在寄存器之间进行移动。
大部分指令有可选的判断变量控制执行逻辑,而有一部分指令需要用到判断变量作为源操作数,这些判断变量通常用p,q,r,s表示。
6.3. Destination Operands
结果操作数通常由d表示,并且是寄存器状态空间中的标量或向量变量。
6.4. Using Addresses, Arrays, and Vectors
使用标量变量作为操作数很简单。地址、数组和向量的使用则相对复杂(手册说的:有趣)。
6.4.1. Addresses as Operands
所有内存指令都接受一个地址操作数,该操作数指定被访问的内存位置。这个地址操作数可以是:
- [var]
- 可寻址变量
var的名字
- 可寻址变量
- [reg]
- 一个包含字节地址的整型寄存器或者bit-size寄存器。
- [reg + immOff]
- 寄存器 + 字节偏移(uint32)的地址。
- [var + immOff]
- 可寻址变量 + 字节偏移(uint32)
- [immAddr]
- 一个立即数表示的字节地址
- var[immOff]
- 一个数组元素(会在Arrays as Operands章节介绍)
当寄存器包含地址的时候,通常会被声明为bit-size或者整型类型。
内存指令的访问大小是在内存中访问的总字节数。例如,ld.v4.b32的访问大小为16字节,而atom.fp16x2是4个字节。
地址必须与访问大小的倍数自然对齐。如果地址没有正确对齐,结果行为是未定义的。
地址大小可以是32位或64位。地址会根据需要进行零扩展,扩展到指定的宽度,如果寄存器宽度超过目标架构所支持的地址宽度(如:32-bit架构用64-bit地址),则截断地址。
地址运算使用整数运算和逻辑运算来执行。包括指针算术和指针比较。所有的地址和地址计算都是基于字节的。不支持c风格的指针算术(这里我理解为,不支持像C那样可以按照bit位进行计算)。
mov指令可用于将变量的地址移动到指针中。该地址是该变量在状态空间中的地址偏移量。
举一些例子:
.shared .u16 x;
.reg .u16 r0;
.global .v4 .f32 V;
.reg .v4 .f32 W;
.const .s32 tbl[256];
.reg .b32 p;
.reg .s32 q;
ld.shared.u16 r0,[x]; //从shared memory中读取x到寄存器r0中
ld.global.v4.f32 W, [V]; //从global memory中读取v4向量到v4寄存器W中
ld.const.s32 q, [tbl+12]; //从const memory中读取tble[12]的元素到寄存器q中
mov.u32 p, tbl; //将常量表tbl的地址拷贝到寄存器p中,注意此处存在隐式转换,但逻辑无误
6.4.1.1. Generic Addressing
当一条内存指令没有表明状态空间时,这条操作会被认定为使用泛型地址
.const、.param、.local和.shared都是泛型地址空间中的一段滑窗。
每一个内存空间的滑窗段由滑窗的初始地址以及对应的空间大小来定义。
需要注意的是泛型地址会默认映射到.global空间中,除非被表表明是.const、.local和.shared。
.prama滑窗是属于.global滑窗的一部分。
在每个滑窗内,泛型地址映射的地址是可以理解为滑窗基地址的偏移。(个人理解这个地址是基于滑窗基地址的相对地址,不是绝对地址)
6.4.2. Arrays as Operands
所有类型的数组可以声明,并且在声明数组的空间中成为地址常量。数组的大小在程序中是一个常量。
可以使用显式计算的字节地址访问数组元素,也可以使用方括号表示法索引数组。
举个例子:
ld.global.u32 s, a[0];
ld.global.u32 s, a[N-1];
mov.u32 s, a[1]; // move address of a[1] into s
6.4.3. Vectors as Operands
矢量操作只被部分受限制的指令所支持,包括ld、st、mov和tex。矢量可以被当作参数传给调用函数。
矢量的元素可以通过后缀.x、.y、.z和.w进行访问,r、g、b和a也是可以的/
可以通过矢量对标量寄存器进行批量赋值,举个例子:
.reg .v4 .f32 V;
.reg .f32 a, b, c, d;
mov.v4.f32 {a,b,c,d}, V; //用V一次性对a\b\c\d进行赋值
使用矢量读写可以提升读写的性能。矢量读写的目标寄存器可以是矢量寄存器,也可以是组合的标量寄存器,如:
ld.global.v4.f32 {a,b,c,d}, [addr+16];
ld.global.v2.u32 V2, [addr+8];
//对于{a,b,c,d},假设有一个矢量寄存器V,其值与坐标对应关系
// a = V.x = V.r;
// b = V.y = V.g;
// c = V.z = V.b;
// d = V.w = V.a;
6.4.4. Labels and Function Names as Operands
分支标记(Lable)只能用在bra\brx.idx指令中,函数名(function name)只能用在call指令中。
函数名可以在mov指令中使用,目的在于将函数指针地址存放在寄存器中,用于直接的调用。
从PTX ISA 3.1版本开始,mov指令可以用来获取kernel的地址,然后传递给系统调用,进行GPU kernel初始化。
6.5. Type Conversion
在算数、逻辑、移动等指令中的所有操作数都必须是相同的数据类型和大小。如果操作数数据类型或大小不相同,那么必须在进行才做之间做数据转换。
6.5.1. Scalar Conversions
下表中表示了各个数据类型之间相互转换会有的操作,如:u16转换到u32是高位直接补0。
其中如果转换到浮点数的时候,源操作数的大小超过了浮点数能表示的最大值,那么会直接被表示为浮点数的最大值。(如IEEEf32和f64最大值表示为Inf,而fp16约为131,000?手册中是~13100)

6.5.2. Rounding Modifiers
在转换指令中可能会需要表明舍入修饰符(rounding modifier),其中整型和浮点型都分别有四种和五种rounding modifier。
浮点型如下表所示:

PS: "LSB" -- "least significant bit(最低有效位)"。
"rounds to nearest even"应该是,如:1.5这种距离1和2距离相近的情况下,我们会舍入到偶数2。
整型如下表所示:

6.6. Operand Costs
不同的状态空间中的操作指令会有着不同的速度,比如寄存器的操作指令是最快的,而全局空间的操作指令是最慢的。
有许多让发可以隐藏指令的操作延迟,如:
- 多线程执行,这样会硬件在某一线程执行完内存操作之后自动切换到另一个线程,调度隐藏延迟;
- 尽可能早的分配读取指令,因为在后续的指令使用到读取的结果之前,后续指令并不会被阻塞。
- ....
下表大致估计了各个状态空间指令的时钟周期:

Chapter 7. Abstracting the ABI
7.1. Function Declarations and Definitions
在PTX中,函数定义使用.func进行标注,函数的定义包含可选的返回值列表、可选的输入参数列表以及必须的函数名。
并且必须在函数调用之前定义函数(这个没啥好说的)。
简单例子:
.func foo
{
...
ret;
}
...
// call foo;
...
标量和向量的基础类型的输入参数和返回参数,可以使用寄存器变量。在函数被调用时,实参可以是寄存器变量或常量,返回值可以直接放入寄存器变量中。调用时的实参和返回变量的类型和大小必须与被调用者对应的形式参数相匹配。
举个例子:
.func (.reg .u32 %res) inc_ptr ( .reg .u32 %ptr, .reg .u32 %inc ) // func. (返回值) 函数名 (输入参数)
{
add.u32 %res, %ptr, %inc;
ret;
}
...
call (%r1), inc_ptr, (%r1,4);
...
当使用ABI(Application Binary Interface)时,.reg状态空间的参数必修至少为32-bit。所以要么在传参之前将小于32-bit的标量数据进行类型转换,要么使用接下来例句的按照结构体封装的.param状态空间参数。
像C中的结构体和联合体这样的对象,在PTX中被扁平化成寄存器或字节数组,并使用.param空间内存表示。如:
struct {
double dbl;
char c[4];
};
在PTX中,因为内存的访问需要对齐,所以上述的结构体参数总共占的内存为12bytes,并且8bytes对齐因为需要对齐访问fp64的数据。
看一个比较完整的例子:
.func (.reg .s32 out) bar (.reg .s32 x, .param .align 8 .b8 y[12])
{
.reg .f64 f1;
.reg .b32 c1, c2, c3, c4;
...
ld.param.f64 f1, [y+0];
ld.param.b8 c1, [y+8];
ld.param.b8 c2, [y+9];
ld.param.b8 c3, [y+10];
ld.param.b8 c4, [y+11];
...
... // computation using x,f1,c1,c2,c3,c4;
}
{
.param .b8 .align 8 py[12];
...
st.param.b64 [py+ 0], %rd;
st.param.b8 [py+ 8], %rc1;
st.param.b8 [py+ 9], %rc2;
st.param.b8 [py+10], %rc1;
st.param.b8 [py+11], %rc2;
// scalar args in .reg space, byte array in .param space
call (%out), bar, (%x, py);
...
}
在上述例子中,我们需要注意的.param被使用的两种方式:
- 在函数的定义中
.param参数y表示函数的形式参数; - 其次,在调用函数之前声明一个
.param变量py,并用于设置传递给函数的结构体。
接下来是一些概念性的方式来考虑在设备函数中使用.param状态空间。
- 对于调用者而言:
.param状态空间用于设置后续被传入被调函数的参数,或者接受被调函数返回值的变量。
- 对于被调函数而言:
- 反之,被调函数中
.param用于表示被传入的参数或者被返回的非参数。
- 反之,被调函数中
对于参数传递则会有如下的一些约束:
- 对于调用者而言:
- 参数可以是
.param、.reg或者是常数; - 当
.param修饰的函数形参是字节数组的时候,实参也必须是字节数组,并且类型、大小和对齐尺寸都必须匹配。并且实参必须声明在与调用者相同的作用域内。 - 当
.patam修饰的函数形参是基础类型的标量或矢量时,实参必须是在.param或.reg空间,且大小和类型要匹配。或者说是类型匹配的常数; - 当
.reg修饰函数形参时,约束与上一条相同; - 当
.reg修饰函数形参时,其大小至少为32-bit; - 使用
st.param进行参数传递必须立即跟在函数调用之前,使用ld.param进行返回值收集必须立即跟在函数调用之后,不支持任何控制流操作,主要时为了方便编译器进行优化(自己写的时候记住就行)。
- 参数可以是
- 对于被调函数而言:
- 输入值和返回值可以是
.param和.reg状态空间修饰的; - 在
.param状态空间的内存,必须按照1\2\4\8\16字节进行对齐; - 在
.reg状态空间的参数,大小至少为32-bit; .reg可以被用于接收和返回基础类型的标量或者矢量,在non-ABI模式下也包括sub-word size(不太理解non-ABI模式,但是sub-word size应该是只小于32-bit的大小)。
- 输入值和返回值可以是
注意,参数传递的状态空间是.reg还是.param对参数最终是在物理寄存器中还是在堆栈中传递没有影响。参数到物理寄存器和堆栈位置的映射取决于ABI定义和参数的顺序、大小和对齐方式。
7.1.1. Changes from PTX ISA Version 1.x
PS: 看的时候直接跳过了这一小结,因为感觉稍微有点久远了。
7.2. Variadic Functions
PTX 6.0版本支持将无大小的数组形参传递给一个函数,该函数可用于实现可变变量函数。
具体的一些参考在后续章节会接着说。(后续的11章)
7.3. Alloca
PTX提供了alloca指令用于在runtime在每个线程的local stack上申请内存。被alloca返回的内存指针内存可以被ld.local和st.local指令进行访问。
为了促进用alloca分配的内存的回收,PTX提供了两个附加指令:
stacksave允许读取本地变量中堆栈指针的值;stackrestore可以用保存的值恢复堆栈指针。 PS: 上述两个指令是PTX ISA 7.3预览版所加入的特性,后续可能还会有改变,所以并不能保证向后兼容。
Chapter 8. Memory Consistency Model
在多线程执行的过程中,因为不同的两个线程,他们各自的两个操作可能并没有按照顺序进行。在这种时候可能就会导致内存上的一些问题。内存一致性模型则可以更好的约束这些潜在的问题。
8.1. Scope and applicability of the model
在此模型下指定的约束适用于任何PTX ISA版本,运行在sm_70或更高的架构上。
内存一致性模型,不适用与texture(包括ld.global.nc)和surface内存的访问。
8.1.1. Limitations on atomicity at system scope
当与主机CPU通信时,具有系统作用域的64位强操作可能不会在某些系统上原子地执行。
原子操作的保证性在这里不多展开。CUDA Programming Guide里面有详细说明
8.2. Memory operations
PTX内存模型中的基本存储单元是1个字节。PTX程序可用的每个状态空间都是内存中连续字节的序列。并且每个字节的地址都是唯一的。
内存一致性模型规范使用术语“address”或“memory address”来表示虚拟地址,使用术语“memory location”来表示物理内存位置。
8.2.1. Overlap
当两端内存段存在交集是,称之为Overlap,当两个内存指令指定的虚拟地址相同但物理内存存在交集时,二者也是Overlap的。
8.2.2. Aliases
如果两个不同的虚拟地址映射到相同的物理内存位置,则称它们为别名。
8.2.3. Vector Data-types
内存一致性模型将在物理地址上执行的操作与标量数据类型联系起来,这些数据类型的最大大小和对齐方式为64-bit。
向量数据类型的内存操作被建模为一组标量数据的等效内存操作,以未知的顺序在向量中的元素上进行。(我理解如果时v4.u8这种加法,位置顺序是指具体先计算那哪一个u8是未知的,通常我们也并不关心)
8.2.4. Packed Data-types
Packed数据如.fp16x2,访问的是物理内存上连续的两个fp16数据。其内存操作指令也是等效为一组标量的指令,以未知的顺序在packed data上进行。
8.2.5. Initialization
内存值的初始化,如果没有任何显式的赋值操作,那么字节会被初始化为未知但不变的值。(随机值但一定是所有字节都是一样的随机值)
8.3. State spaces
在内存一致性模型中定义的关系独立于状态空间。
例如,PTX指令ld.relax .shared.sys的同步效果与ld.relax .shared.cluster的同步效果相同。因为非同一cluster之内的线程不能执行访问同一shared内存位置的操作。
8.4. Operation types
操作类型大致可以分为下表所示的一些类:

8.5. Scope
每一条强操作都必须表明作用域,这些作用域有:

需要注意的是warp并不是作用域,CTA则是内存一致性模型中的拥有最小线程集合的作用域。
8.6. Proxies
内存代理是应用于内存访问方法的抽象标签。当两个内存操作使用不同的内存访问方法时,它们被称为不同的代理。
在Table17中定义的内存操作使用通用的内存访问方法,即通用代理。其他操作,如texture和surfasce都使用不同的内存访问方法,也不同于通用方法。
需要使用proxy fence来同步不同代理之间的内存操作。尽管虚拟别名使用通用的内存访问方法,但由于使用不同的虚拟地址就像使用不同的代理一样,因此它们需要一个proxy fence来维护内存顺序。
8.7. Morally strong operations
满足如下所有条件的两条操作,我们说他们互为morally strong operations:
- 操作按程序顺序相关(即,它们都由相同的线程执行),或者每个操作都是强操作,并指定包含线程的作用域执行另一个操作。
- 两个操作都通过同一个代理执行。
- 如果两者都是内存操作,那么它们完全重叠(overlap completely)。
8.7.1. Conflict and Data-races
当两个内存重叠的操作至少有一个是写的时候,我们称之为conflict。
如果两个存在conflict的内存操作在因果顺序上不相关,且它们不是morally strong,则它们被称为data-races。
8.7.2. Limitations on Mixed-size Data-races
在完全overlap情况下出现的data-race称之为uniform-size data-race,在不完全overlap的情况下称之为mixed-size data-race。
如果PTX程序包含一个或多个mixed-size data-race,则内存一致性模型中的公理不适用。但对于uniform-size data-race是适用的。
注意原子操作能够保证在任何情况下都可以保证执行无误。
8.8. Release and Acquire Patterns
一些指令序列会产生参与内存同步的模式。release使得来自当前线程t的先前操作对来自其他线程的某些操作可见。acquire模式使来自其他线程的一些操作对当前线程t的后续操作可见。
在内存位置M上的release包含如下一些操作:
- 在M上的
release操作:
st.release [M];
atom.acq_rel [M];
- 一个
release操作之后紧跟着一个strong write(见上文Table17):
st.release [M];
st.relaxed [M];
- 一个内存栅栏操作之后紧跟着一个
strong write操作:
fence;
st.relaxed [M];
任何由release模式建立的内存同步只影响在该模式中按程序顺序发生的第一个指令操作之前的操作。
在内存位置M上的acquire包含如下一些操作:
- 在M上的
acquire操作:
ld.acquire [M];
atom.acq_rel [M];
- 一个
acquire操作之后紧跟着一个strong write(见上文Table17):
ld.relaxed [M];
ld.acquire [M];
- 一个
strong read指令后紧跟这内存栅栏操作:
ld.relaxed [M];
fence;
由acquire模式建立的任何内存同步,只影响该模式中按程序顺序发生的最后一条指令操作之后的操作。
8.9. Ordering of memory operations
内存一致性模型定义了通信顺序、因果顺序、程序顺序之间不允许存在的矛盾。
8.9.1. Program Order
Program order是一个传递关系,在线程执行的操作上形成一个总顺序,但不关联来自不同线程的操作。
8.9.2. Observation Order
Observation order通过可选的原子read-modify-write操作序列将写操作W与读操作R联系起来。
当出现如下两种情况之一是,Observation order中的写操作W会先于读操作R:
- R和W是
morally strong并且R 读取由W写入的值; - 对于一些原子操作Z,在Observation order中W先于Z并且Z先于R。
8.9.3. Fence-SC Order
Fence-SC order是一个非循环的部分顺序,在运行时确定,与每一对morally strong fence.sc操作相关。
8.9.4. Memory synchronization
同步操作实在运行时不同的线程之间进行的操作。这种同步操作在线程之间建立了因果关系(Causality order)
不同线程之间的同步操作包括如下几种:
- 一个
fence.sc操作X与一个fence.sc操作Y同步,且在Fence-SC order中X位于Y之前; bar{.cta}.sync或bar{.cta}.red或bar{.cta}.arrive与bar{.cta}.red或bar{.cta}.sync在同一个barrier上进行同步;- 一个
barrier.cluster.arrive与barrier.cluster.wait进行同步; - release模式的X与acquire模式的Y同步,如果X中的写操作按照Observation Order先于Y中的读操作,并且X中的第一个操作和Y中的最后一个操作是
morally strong。
一些同步操作也可以通过相关的CUDA API来实现,如:cuda stream的同步等。
8.9.5. Causality Order
不想翻译这一部分了,后面如果有新体会再翻译吧,因果关系可以直接按照字面理解,就是两条操作之间如果存在依赖,那就存在因果关系。
8.9.6. Coherence Order
存在一种部分传递顺序,将重叠写操作联系起来,在运行时确定,称为一致性顺序(Coherence Order)。
当两个写操作是morally strong或者他们存在因果关系时,他们是满足一致性顺序的。
但当两个写操作存在data-race的时候,他们不满足一致性顺序。
8.9.7. Communication Order
通信顺序是在运行时确定的非传递顺序,它将写操作与其他overlapping的内存操作联系起来。
8.10. Axioms
8.10.1. Coherence
"If a write W precedes an overlapping write W’ in causality order, then W must precede W’ in coherence order." (公理就不用翻译了)
8.10.2. Fence-SC
"Fence-SC order cannot contradict causality order. For a pair of morally strong fence.sc operations F1 and F2, if F1 precedes F2 in causality order, then F1 must precede F2 in FenceSC order." (也就是如果两个操作存在因果关系,那么他们一定符合Fence-SC order)
8.10.3. Atomicity
关于原子性,直接看下图所示的对比,就可以略知一二。

8.10.4. No Thin Air
没太理解这部分,上个图先:

文档中有一句话说的是:" Only the values x == 0 and y == 0 are allowed to satisfy this cycle."
8.10.5. Sequential Consistency Per Location
直接上图,可能更直观:

上图的意思我理解就是,无论T2执行顺序再T1前还是T1之后,T2中R2读取的值始终与R1是保持一致的。
8.10.6. Causality
通信顺序中的关系不能与因果顺序相矛盾。
对应的描述暂时不翻译了,只能意会不能言传:



Chapter 9. Instruction Set
本章就是整个手册的大头了,介绍各种指令的格式、语法以及作用等。
9.2. PTX Instructions
通常来说,PTX指令有0-4个操作数,并且有一个可选的条件判断符在操作符的左边,并且用@前缀表示:
@p opcode;
@p opcode a;
@p opcode d, a;
@p opcode d, a, b;
@p opcode d, a, b, c;
上述指令中,位于操作符右边最近的操作数d为目标操作数,其余为源操作数。
当setp操作修改两个目标操作数时,我们通过|符号进行多个操作数的分隔:
setp.lt.s32 p|q, a, b; // p = (a < b); q = !(a < b);
对于某些指令,目标操作数是可选的。用下划线(_)表示的bit bucket操作数可以用来代替目标寄存器。
9.3. Predicated Execution
在PTX中,条件寄存器时虚拟的(个人理解就是在物理资源上没有对应的寄存器),通过.pred作为类型标注,所以条件寄存器可以按照如下方式声明:
.reg .pred p, q, r;
所有的指令都可以增加条件操作数来控制执行,使用@{!}p来进行条件标注。@!p表示条件p取非,注意任何时候表示条件前缀@必不可少
举个例子:
// c代码中的判断
if (i < n)
j = j + 1;
// 对应的ptx代码
setp.lt.s32 p, i, n; // p = (i < n)
@p add.s32 j, j, 1; // if i < n, add 1 to j
如果上述例子有额外的分支,ptx代码如下:
setp.lt.s32 p, i, n; // compare i to n
@!p bra L1; // if p==False, jump to L1
add.s32 j, j, 1;
L1: ...
9.3.1. Comparisons
9.3.1.1. Integer and Bit-Size Comparisons
直接上图:

9.3.1.2. Floating Point Comparisons



9.3.2. Manipulating Predicates
条件判断值可以由如下的指令计算和操作,如:and, or, xor, not, mov。
PTX中没有直接的办法可以将条件值和整型值之间做转换,也没有直接的办法去读写条件寄存器的值。
不过,setp指令可以根据整型值生成条件值,selp指令可以根据条件值生成整型值。
举个例子:
selp.u32 %r1,1,0,%p; // selp其实就是实现的 ?: 三目运算操作符
9.4. Type Information for Instructions and Operands
类型指令一定会有显式的类型大小标注。举个例子:
.reg .u16 d, a, b;
add.u16 d, a, b; // perform a 16-bit unsigned add
有些指令甚至需要多个类型标注,大部分情况出现在cvt类型转换指令中。如:
.reg .u16 a;
.reg .f32 d;
cvt.f32.u16 d, a; // convert 16-bit unsigned to 32-bit float
指令和操作数的类型一致性服从如下原则:
- Bit-size类型与其他任意的同size类型一致;
- 有符号整型和无符号整型在大小相同的情况下是一致的,并且整型操作数可能会被默认转换为指令类型。例如,在有符号整数指令中使用的无符号整数操作数将被该指令视为有符号整数;
- 浮点类型只有在大小相同的情况下才一致。也就是说,它们必须完全匹配(完全匹配的意思应该是指,符号位-指数位-精度位的大小均一致)。
关于类型检测规则如下表所示:

9.4.1. Operand Size Exceeding Instruction-Type Size
为了方便起见,ld、st和cvt指令允许源操作数和目标操作数比指令类型更宽,这样就可以使用常规宽度寄存器加载、存储和转换较窄的值。
当源操作数的位数超过了指令大小,源数据会被截断处理(chopped)。
数据之间转换的情况如下表所示,需要注意的是某些指令对于某些类型是不支持的,如:cvt指令不支持bX类型的指令。

上表中的注意事项总结如下:
- 源寄存器大小必须大于或等于指令类型大小;
- Bit-size源寄存器可以与任何类型搭配使用,只不过可能会出现数据截断的情况;
- 整型源寄存器可以与任何Bit-size或整型类型搭配使用,不过也存在数据截断的情况;
- 浮点只能与Bit-size或完全匹配的浮点类型搭配使用。
对于目标寄存器,当目标操作数的大小超过指令类型的大小时,目标数据将被零扩展(zero-extend)或符号扩展(sign-extend)到目标寄存器的大小。如果对应的指令类型是带符号整数,则数据是带符号扩展;否则,数据为零扩展。

上表中的注意事项基本与源操作数类型转换中的一样,不再赘述。
9.5. Divergence of Threads in Control Constructs
在同一个CTA中执行的线程,如果不同的线程进入了不同的控制流分支中,那么我们说这是线程分化(divergent)。反之,如果所有线程都执行同样的控制流分支,那么我们说是线程统一(uniform)。
线程分化的性能会比线程统一差,不过编译器会尽可能帮我们优化线程分化代码,但是理想状态下,如果程序员能够在PTX程序中尽可能约束线程统一逻辑,自然是最好。(这是基础了。。。会写ptx大的程序员不可能不清楚这人一点)
9.6. Semantics
指令语义描述的目标是用尽可能简单的语言描述所有情况下的结果。语义是用C语言描述的,除非C语言表达能力不够。
9.6.1. Machine-Specific Semantics of 16-bit Code
这一小节说的不是特别多,个人觉得总结起来就一句话,如果说是追求更好的性能,那么针对16bit的机器,尽量使用16-bit代码,不然虽然在PTX层面可以统一代码,但是到了实际的机器平台上面,可能会引入额外的转换操作或者执行差异等等。
9.7. Instructions
接下来基本就是本手册的干货部分了,逐个讲解了PTX中的所有指令的作用即用法。
9.7.1. Integer Arithmetic Instructions
9.7.1.1. Integer Arithmetic Instructions: add
9.7.1.2. Integer Arithmetic Instructions: sub
9.7.1.3. Integer Arithmetic Instructions: mul
add\sub\mul指令,没有除法。
用法:
// 加法指令
add.type d, a, b;
add{.sat}.s32 d, a, b; // .sat applies only to .s32
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
// 减法指令
sub.type d, a, b;
sub{.sat}.s32 d, a, b; // .sat applies only to .s32
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
// 乘法指令
mul.mode.type d, a, b;
.mode = { .hi, .lo, .wide };
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
// 举个例子
mul.wide.s16 fa,fxs,fys; // 16*16 bits yields 32 bits
mul.lo.s16 fa,fxs,fys; // 16*16 bits, save only the low 16 bits
mul.wide.s32 z,x,y; // 32*32 bits, creates 64 bit result
注意事项:
- 上述的
.sat标识符是指Saturation,即将结果限制在[MinInt, MaxInt]防止溢出,sub\add只能用于s32的数据类型,而mul指令只能用于hi.sat.s32的情况。 - 乘法指令中的
.wide模式只支持16-bit和32-bit的整型类型,并且默认会双倍扩展源操作数的位数。
9.7.1.4. Integer Arithmetic Instructions: mad
乘加指令
用法如下:
mad.mode.type d, a, b, c;
mad.hi.sat.s32 d, a, b, c;
.mode = { .hi, .lo, .wide };
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
注意事项:
.mode与乘法相同,只限制乘法的结果。.sat使用限制与乘法相同
9.7.1.5. Integer Arithmetic Instructions: mul24
9.7.1.6. Integer Arithmetic Instructions: mad24
24-bit的快速乘法与24-bit快速乘加
用法如下:
// 快速乘法
mul24.mode.type d, a, b;
.mode = { .hi, .lo };
.type = { .u32, .s32 };
// 快速乘加
mad24.mode.type d, a, b, c;
mad24.hi.sat.s32 d, a, b, c;
.mode = { .hi, .lo };
.type = { .u32, .s32 };
注意事项:
- 源操作数是由32-bit寄存器搭载,计算结果也保存在32-bit寄存器中;
.lo模式下,获取24bit x 24bit = 48bit中的低32-bit数据存储,.hi则是取高32-bit数据存储。- 如果没有硬件的支持,
mul24.hi、mad24.hi可能是无效的。(不过一般也不太会有人用这个)
9.7.1.7. Integer Arithmetic Instructions: sad
绝对值差求和,表达式如下:
// d = c + ((a<b) ? b-a : a-b);
sad.type d, a, b, c;
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
9.7.1.8. Integer Arithmetic Instructions: div
除法单说,用法和其余四则运算是一样的:
div.type d, a, b;
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
注意事项: 除0所得结果是未定义的。
9.7.1.9. Integer Arithmetic Instructions: rem
整型除法求余数,等价于C语言中的%运算符。
rem.type d, a, b;
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
9.7.1.10. Integer Arithmetic Instructions: abs
9.7.1.11. Integer Arithmetic Instructions: neg
取绝对值和相反数
abs.type d, a;
.type = { .s16, .s32, .s64 };
neg.type d, a;
.type = { .s16, .s32, .s64 };
注意事项: 只支持有符号整型。
9.7.1.12. Integer Arithmetic Instructions: min
9.7.1.13. Integer Arithmetic Instructions: max
在两者中间选取min\max值
min.type d, a, b;
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
max.type d, a, b;
.type = { .u16, .u32, .u64, .s16, .s32, .s64 };
注意事项: 有无符号是不同的,这里应该是想说,比较的两个数应该同为有符号或者无符号。
9.7.1.14. Integer Arithmetic Instructions: popc
统计源操作数中有多少bit位是1。
popc.type d, a;
.type = { .b32, .b64 };
popc.b32 d, a;
popc.b64 cnt, X; // cnt is .u32
// 对应的C语言逻辑
.u32 d = 0;
while (a != 0) {
if (a & 0x1) d++;
a = a >> 1;
}
注意事项:
- 目标操作数总是32-bit的寄存器;
- 在
sm_20及以上的架构才支持。
9.7.1.15. Integer Arithmetic Instructions: clz
从高位往低位统计bit位为0的个数。
clz.type d, a;
.type = { .b32, .b64 };
// C语言表示
// 注意这里是默认从符号位的后一位开始统计的,所以mask为0x80000000.
.u32 d = 0;
if (.type == .b32) { max = 32; mask = 0x80000000; }
else { max = 64; mask = 0x8000000000000000; }
while (d < max && (a&mask == 0) ) {
d++;
a = a << 1;
}
注意事项:
- 在
sm_20以及往上的架构才支持 - 指令的目标操作数均为
.u32
9.7.1.16. Integer Arithmetic Instructions: bfind
找到整型数中非符号位中最高有效bit位的位置。
bfind.type d, a;
bfind.shiftamt.type d, a;
.type = { .u32, .u64, .s32, .s64 };
指令说明:
- 如果是unsigned int,则返回为1的最高bit位,如果是signed int,负数返回为0的最高bit位,正数则返回为1的最高bit位;
- 如果
.shiftamt被标注,可以理解为当前的bit位离最高有效位还需要左移多少位。 - 如果没有非符号有效位被找到,指令会返回
0xffffffff.
注意事项:
- 在
sm_20以及往上的架构才支持 - 指令的目标操作数均为
.u32
9.7.1.17. Integer Arithmetic Instructions: fns
找到被设为1的第n个bit位。
fns.b32 d, mask, base, offset;
说明:
mask是被选择的32-bit数,有.b32,.u32,.s32的数据类型offset是基于base的位数选择,需要注意的是offset = 1表示第一个bit位即:base + 0, 是.s32类型d是dst,数据类型为.b32- 如果找不到被设为1的bit位,则d = 0xffffffff
注意事项:
- 在
sm_30以及往上的架构才支持 - PTX 6.0版本引入该指令
9.7.1.18. Integer Arithmetic Instructions: brev
bit位反转指令
brev.type d, a;
.type = { .b32, .b64 };
说明:
- 这里所说的反转Bit位,不是按位取反,而是进行轴对称反转,如:b[0] = a[31], b[1] = a[30]以此类推。
注意事项:
- 在
sm_20以及往上的架构才支持 - 在PTX 2.0版本引入
9.7.1.19. Integer Arithmetic Instructions: bfe
截取对应的bit段
bfe.type d, a, b, c;
.type = { .u32, .u64, .s32, .s64 };
说明:
- bit段从
a中选取,差的Bit位补0或着超出的部分按照符号位补齐 b表示截取bit段的开始bit位c表示截取bit段的长度,其中b和c的取值都在0~255的范围内- 如果截取的结果
d的位数大于a,那么缺失的部分则按照a的符号位进行补齐。
注意事项:
- 在
sm_20以及往上的架构才支持 - PTX 2.0版本引入该指令
9.7.1.20. Integer Arithmetic Instructions: bfi
插入bit段
bfi.type f, a, b, c, d;
.type = { .b32, .b64 };
// example
bfi.b32 d,a,b,start,len;
说明:
- 从a中的截取Bit段放入b中,最终结果存储在f中,c表示bit插入的开始位置,d表示bit插入的长度
- a\b\f拥有相同的数据类型,c\d为
u32类型但是数值只能在0~255之间 - 如果插入长度为0,则结果f=b
- 如果插入开始位置超过了最高位,结果f=b
注意事项:
- 在
sm_20以及往上的架构才支持 - PTX 2.0版本引入该指令
9.7.1.21. Integer Arithmetic Instructions: szext
符号扩展或零扩展
szext.mode.type d, a, b;
.mode = { .clamp, .wrap };
.type = { .u32, .s32 };
// example
szext.clamp.s32 rd, ra, rb;
szext.wrap.u32 rd, 0xffffffff, 0; // Result is 0.
说明:
- 符号扩展或零扩展从a扩展N个Bit位,其中N在操作数b中指定。结果值存储在d中
- 如果a是
s32则默认为符号扩展,u32则默认为零扩展。b为u32 - 如果N是0,那么
szext的结果也是0,如果N>=32,那么szext的结果取决于.mode的选择 - 如果选择
clamp模式,输出直接为a - 如果选择
wrap模式,则使用N的包装值进行计算(没太看懂,但是可能也用不上。。。)
注意事项:
- 在
sm_70以及往上的架构才支持 - PTX 7.6版本引入该指令
9.7.1.22. Integer Arithmetic Instructions: bmsk
生成Bit段掩码(注意这里生成掩码是指激活bit位为1)
bmsk.mode.b32 d, a, b;
.mode = { .clamp, .wrap };
// example
bmsk.clamp.b32 rd, ra, rb;
bmsk.wrap.b32 rd, 1, 2; // Creates a bitmask of 0x00000006. 即 0b0110
说明:
- 生成一个32-bit的Bit掩码,开始位置为a,设为1的bit段长度为b,结果存放在d中
- 在以下两种情况下生成的掩码为0:
- a >= 32
- b == 0
- 在
.clamp模式下,b的取值在[0,32],在.wrap模式下,b的取值在[0,31]
注意事项:
- 在
sm_70以及往上的架构才支持 - PTX 7.6版本引入该指令
9.7.1.23. Integer Arithmetic Instructions: dp4a
对32-bit中的4个byte进行dot-product
dp4a.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
// example
dp4a.u32.u32 d0, a0, b0, c0;
dp4a.u32.s32 d1, a1, b1, c1;
说明:
a和b是32-bit的输入- 如果
a和b均为u32则c为u32,否则c为s32 - 其中对
a和b按字节提取的时候,需要进行sign-extend或者zero-extend之后进行计算
对应的c代码:
// d = dot(a, b) + c
d = c;
// Extract 4 bytes from a 32bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_4(a, .atype);
Vb = extractAndSignOrZeroExt_4(b, .btype);
for (i = 0; i < 4; ++i) {
d += Va[i] * Vb[i];
}
注意事项:
- 在
sm_61以及往上的架构才支持 - PTX 5.0版本引入该指令
9.7.1.24. Integer Arithmetic Instructions: dp2a
类似于dp4a指令,两个16-bit和和两个8-bit的乘累加操作
dp2a.mode.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
.mode = { .lo, .hi };
// example
dp2a.lo.u32.u32 d0, a0, b0, c0;
dp2a.hi.u32.s32 d1, a1, b1, c1;
说明: 直接看c代码逻辑比较好理解
d = c;
// Extract two 16-bit values from a 32-bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_2(a, .atype);
// Extract four 8-bit values from a 32-bit input and sign or zer extend
// based on input type.
Vb = extractAndSignOrZeroExt_4(b, .btype);
b_select = (.mode == .lo) ? 0 : 2;
for (i = 0; i < 2; ++i) {
d += Va[i] * Vb[b_select + i];
}
注意事项:
- 在
sm_61以及往上的架构才支持 - PTX 5.0版本引入该指令