Taro 技术揭秘之taro-cli
Opened this issue · 3 comments
前言
Taro 是由凹凸实验室打造的一套遵循 React 语法规范的多端统一开发框架。
使用 Taro,我们可以只书写一套代码,再通过 Taro 的编译工具,将源代码分别编译出可以在不同端(微信小程序、H5、App 端等)运行的代码。实现 一次编写,多端运行。 关于 Taro 的更多详细的信息可以看官方的介绍文章 Taro - 多端开发框架 ,或者直接前往 GitHub 仓库 NervJS/taro 查看 Taro 文档及相关资料。

Taro 项目实现的功能强大,项目复杂而庞大,涉及到的方方面面(多端代码转换、组件、路由、状态管理、生命周期、端能力的实现与兼容等等)多,对于大多数人来说,想要深入理解其实现机制及原理,还是比较困难的。
Taro 技术揭秘系列文章将为你逐步揭开 Taro 强大的功能之后的神秘面纱,带领你深入 Taro 内部,了解 Taro 是怎样一步一步实现 一次编写,多端运行 的宏伟目标,同时也希望借此机会抛砖引玉,促进前端圈涌现出更多的,能够解决大家痛点的开源项目。
首先,我们将从负责 Taro 脚手架初始化和项目构建的的命令行工具,也就是 Taro 的入口:@tarojs/cli 开始。
taro-cli 包
taro 命令
taro-cli 包位于 Taro 工程的 packages 目录下,通过 npm install -g @tarojs/cli 全局安装后,将会生成一个taro 命令。主要负责项目初始化、编译、构建等。直接在命令行输入 taro ,会看到如下提示:
➜ taro
👽 Taro v0.0.63
Usage: taro <command> [options]
Options:
-V, --version output the version number
-h, --help output usage information
Commands:
init [projectName] Init a project with default templete
build Build a project with options
update Update packages of taro
help [cmd] display help for [cmd]在这里可以详细看看 taro 命令用法及作用。
包管理与发布
首先,我们需要了解 taro-cli 包与 taro 工程的关系。
将 Taro 工程 clone 下来之后,我们可以看到工程的目录结构如下,整体还是比较简单明了的。
.
├── CHANGELOG.md
├── LICENSE
├── README.md
├── build
├── docs
├── lerna-debug.log
├── lerna.json // Lerna 配置文件
├── package.json
├── packages
│ ├── eslint-config-taro
│ ├── eslint-plugin-taro
│ ├── postcss-plugin-constparse
│ ├── postcss-pxtransform
│ ├── taro
│ ├── taro-async-await
│ ├── taro-cli
│ ├── taro-components
│ ├── taro-components-rn
│ ├── taro-h5
│ ├── taro-plugin-babel
│ ├── taro-plugin-csso
│ ├── taro-plugin-sass
│ ├── taro-plugin-uglifyjs
│ ├── taro-redux
│ ├── taro-redux-h5
│ ├── taro-rn
│ ├── taro-rn-runner
│ ├── taro-router
│ ├── taro-transformer-wx
│ ├── taro-weapp
│ └── taro-webpack-runner
└── yarn.lock
Taro 项目主要是由一系列 npm 包组成,位于工程的 packages 目录下。它的包管理方式和 Babel 项目一样,将整个项目作为一个 monorepo 来进行管理,并且同样使用了包管理工具 Lerna。
Lerna 是一个用来优化托管在 git/npm 上的多 package 代码库的工作流的一个管理工具,可以让你在主项目下管理多个子项目,从而解决了多个包互相依赖,且发布时需要手动维护多个包的问题。
关于 Lerna 的更多介绍可以看官方文档 Lerna:A tool for managing JavaScript projects with multiple packages。
packages 目录下十几个包中,最常用的项目初始化与构建的命令行工具 taro-cli 就是其中一个。在 Taro 工程根目录运行 lerna publish 命令之后,lerna.json 里面配置好的所有的包会被发布到 npm 上去。
目录结构
taro-cli 包的目录结构如下:
./
├── bin // 命令行
│ ├── taro // taro 命令
│ ├── taro-build // taro build 命令
│ ├── taro-update // taro update 命令
│ └── taro-init // taro init 命令
├── package.json
├── node_modules
├── src
│ ├── build.js // taro build 命令调用,根据 type 类型调用不同的脚本
│ ├── config
│ │ ├── babel.js // Babel 配置
│ │ ├── babylon.js // JavaScript 解析器 babylon 配置
│ │ ├── browser_list.js // autoprefixer browsers 配置
│ │ ├── index.js // 目录名及入口文件名相关配置
│ │ └── uglify.js
│ ├── creator.js
│ ├── h5.js // 构建h5 平台代码
│ ├── project.js // taro init 命令调用,初始化项目
│ ├── rn.js // 构建React Native 平台代码
│ ├── util // 一系列工具函数
│ │ ├── index.js
│ │ ├── npm.js
│ │ └── resolve_npm_files.js
│ └── weapp.js // 构建小程序代码转换
├── templates // 脚手架模版
│ └── default
│ ├── appjs
│ ├── config
│ │ ├── dev
│ │ ├── index
│ │ └── prod
│ ├── editorconfig
│ ├── eslintrc
│ ├── gitignore
│ ├── index.js // 初始化文件及目录,copy模版等
│ ├── indexhtml
│ ├── npmrc
│ ├── pagejs
│ ├── pkg
│ └── scss
└── yarn-error.log
其中关键文件的作用已添加注释说明,大家可以先大概看看,有个初步印象。
通过上面的目录树可以看出,taro-cli 工程的文件并不算多,主要目录有:/bin、/src、/template,我已经在上面详细标注了主要的目录和文件的作用,至于具体的流程,咱们接下来再分析。
用到的核心库
- tj/commander.js Node.js 命令行接口全面的解决方案,灵感来自于 Ruby's commander。可以自动的解析命令和参数,合并多选项,处理短参等等,功能强大,上手简单。
- jprichardson/node-fs-extra 在nodejs的fs基础上增加了一些新的方法,更好用,还可以拷贝模板。
- chalk/chalk 可以用于控制终端输出字符串的样式。
- SBoudrias/Inquirer.js NodeJs 命令行交互工具,通用的命令行用户界面集合,用于和用户进行交互。
- sindresorhus/ora 加载中状态表示的时候一个loading怎么够,再在前面加个小圈圈转起来,成功了console一个success怎么够,前面还可以给他加个小钩钩,ora就是做这个的。
- SBoudrias/mem-fs-editor 提供一系列API,方便操作模板文件。
- shelljs/shelljs ShellJS 是Node.js 扩展,用于实现Unix shell 命令执行。
- Node.js child_process 模块 用于新建子进程。子进程的运行结果储存在系统缓存之中(最大200KB),等到子进程运行结束以后,主进程再用回调函数读取子进程的运行结果。
taro init
taro init 命令主要的流程如下:

taro 命令入口
当我们全局安装 taro-cli 包之后,我们的命令行里就多了一个 taro 命令。
$ npm install -g @tarojs/cli那么 taro 命令是怎样添加进去的呢,其原因在于 package.json 里面的 bin 字段;
"bin": {
"taro": "bin/taro"
},上面代码指定,taro 命令对应的可执行文件为 bin/taro。npm 会寻找这个文件,在 [prefix]/bin 目录下建立符号链接。在上面的例子中,taro会建立符号链接 [prefix]/bin/taro。由于 [prefix]/bin 目录会在运行时加入系统的 PATH 变量,因此在运行 npm 时,就可以不带路径,直接通过命令来调用这些脚本。
关于prefix,可以通过npm config get prefix获取。
$ npm config get prefix
/usr/local通过下列命令可以更加清晰的看到它们之间的符号链接:
$ ls -al `which taro`
lrwxr-xr-x 1 chengshuai admin 40 6 15 10:51 /usr/local/bin/taro -> ../lib/node_modules/@tarojs/cli/bin/tarotaro 子命令
上面我们已经知道 taro-cli 包安装之后,taro 命令是怎么和 /bin/taro 文件相关联起来的, 那 taro init 和 taro build 又是怎样和对应的文件关联起来的呢?
命令关联与参数解析
这里就不得不提到一个有用的包:tj/commander.js Node.js 命令行接口全面的解决方案,灵感来自于 Ruby's commander。可以自动的解析命令和参数,合并多选项,处理短参等等,功能强大,上手简单。具体的使用方法可以参见项目的 README。
更主要的,commander 支持 git 风格的子命令处理,可以根据子命令自动引导到以特定格式命名的命令执行文件,文件名的格式是 [command]-[subcommand],例如:
taro init => taro-init
taro build => taro-build
/bin/taro 文件内容不多,核心代码也就那几行 .command() 命令:
#! /usr/bin/env node
const program = require('commander')
const {getPkgVersion} = require('../src/util')
program
.version(getPkgVersion())
.usage('<command> [options]')
.command('init [projectName]', 'Init a project with default templete')
.command('build', 'Build a project with options')
.command('update', 'Update packages of taro')
.parse(process.argv)command方法
用法:.command('init <path>', 'description')
command的 用法稍微复杂,原则上他可以接受三个参数,第一个为命令定义,第二个命令描述,第三个为命令辅助修饰对象。
- 第一个参数中可以使用 <> 或者 [] 修饰命令参数
- 第二个参数可选。
- 当没有第二个参数时,commander.js 将返回 Command 对象,若有第二个参数,将返回原型对象。
- 当带有第二个参数,并且没有显示调用 action(fn) 时,则将会使用子命令模式。
- 所谓子命令模式即,
./pm,./pm-install,./pm-search等。这些子命令跟主命令在不同的文件中。
- 第三个参数一般不用,它可以设置是否显示的使用子命令模式。
注意第一行
#!/usr/bin/env node,有个关键词叫 Shebang,不了解的可以去搜搜看。
参数解析及与用户交互
前面提到过,commander 包可以自动解析命令和参数,在配置好命令之后,还能够自动生产 help(帮助) 命令和 version(版本查看) 命令。并且通过program.args便可以获取命令行的参数,然后再根据参数来调用不同的脚本。
但当我们运行 taro init 命令后,如下所示的命令行交互又是怎么实现的呢?
$ taro init taroDemo
Taro即将创建一个新项目!
Need help? Go and open issue: https://github.com/NervJS/taro/issues/new
Taro v0.0.50
? 请输入项目介绍!
? 请选择模板 默认模板这里使用的是SBoudrias/Inquirer.js 来处理命令行交互。
用法其实很简单:
const inquirer = require('inquirer') // npm i inquirer -D
if (typeof conf.description !== 'string') {
prompts.push({
type: 'input',
name: 'description',
message: '请输入项目介绍!'
})
}prompt()接受一个问题对象的数据,在用户与终端交互过程中,将用户的输入存放在一个答案对象中,然后返回一个Promise,通过then()获取到这个答案对象。so easy!
借此,新项目的名称、版本号、描述等信息可以直接通过终端交互插入到项目模板中,完善交互流程。
当然,交互的问题不仅限于此,可以根据自己项目的情况,添加更多的交互问题。inquirer.js强大的地方在于,支持很多种交互类型,除了简单的input,还有confirm、list、password、checkbox等,具体可以参见项目的工程README。
此外,你还在执行异步操作的过程中,你还可以使用 sindresorhus/ora 来添加一下 loading 效果。使用chalk/chalk 给终端的输出添加各种样式。
模版文件操作
最后就是模版文件操作了,主要分为两大块:
- 将输入的内容插入到模板中
- 根据命令创建对应目录结构,copy 文件
- 更新已存在文件内容
这些操作基本都是在 /template/index.js 文件里。
这里还用到了shelljs/shelljs 执行shell 脚本,如初始化 git git init,项目初始化之后安装依赖npm install等。
拷贝模板文件
拷贝模版文件主要是使用 jprichardson/node-fs-extra 的copyTpl()方法,此方法使用ejs模板语法,可以将输入的内容插入到模版的对应位置:
this.fs.copyTpl(
project,
path.join(projectPath, 'project.config.json',
{description,projectName}
);更新已经存在的文件内容
更新已经存在的文件内容是很复杂的工作,最可靠的方法是把文件解析为AST,然后再编辑。一些流行的 AST parser 包括:
Cheerio:解析HTML。Babylon:解析JavaScript。- 对于
JSON文件,使用原生的JSON对象方法。
使用 Regex 解析一个代码文件是邪道,不要这么干,不要心存侥幸。
taro build
taro build 命令是整个 taro 项目的灵魂和核心,主要负责 多端代码编译(h5,小程序,React Native等)。
taro 命令的关联,参数解析等和 taro init 其实是一模一样的,那么最关键的代码转换部分是怎样实现的呢?
这个部分内容过于庞大,需要单独拉出来一篇讲。不过这里可以先简单提一下。
编译工作流与抽象语法树(AST)
Taro 的核心部分就是将代码编译成其他端(H5、小程序、React Native等)代码。一般来说,将一种结构化语言的代码编译成另一种类似的结构化语言的代码包括以下几个步骤:
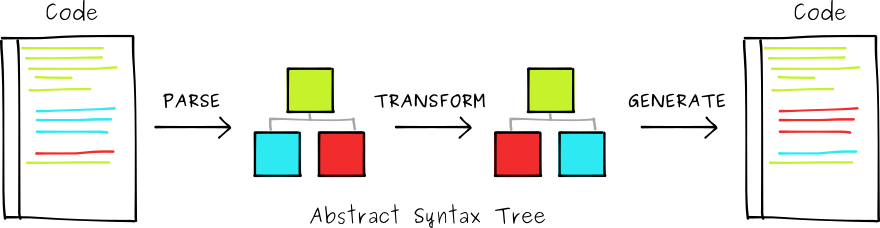
首先是 parse,将代码 解析(Parse)成 抽象语法树(Abstract Syntex Tree),然后对 AST 进行 遍历(traverse)和 替换(replace)(这对于前端来说其实并不陌生,可以类比 DOM 树的操作),最后是 生成(generate),根据新的 AST 生成编译后的代码。
Babel 模块
Babel 是一个通用的多功能的 JavaScript 编译器,更确切地说是源码到源码的编译器,通常也叫做 转换编译器(transpiler)。 意思是说你为 Babel 提供一些 JavaScript 代码,Babel 更改这些代码,然后返回给你新生成的代码。
此外它还拥有众多模块可用于不同形式的 静态分析。
静态分析是在不需要执行代码的前提下对代码进行分析的处理过程 (执行代码的同时进行代码分析即是动态分析)。 静态分析的目的是多种多样的, 它可用于语法检查,编译,代码高亮,代码转换,优化,压缩等等场景。
Babel 实际上是一组模块的集合,拥有庞大的生态。Taro 项目的代码编译部分就是基于 Babel 的以下模块实现的:
- babylon Babylon 是 Babel 的解析器。最初是 从Acorn项目fork出来的。Acorn非常快,易于使用,并且针对非标准特性(以及那些未来的标准特性) 设计了一个基于插件的架构。
- babel-traverse Babel Traverse(遍历)模块维护了整棵树的状态,并且负责替换、移除和添加节点。
- babel-types Babel Types模块是一个用于 AST 节点的 Lodash 式工具库, 它包含了构造、验证以及变换 AST 节点的方法。 该工具库包含考虑周到的工具方法,对编写处理AST逻辑非常有用。
- babel-generator Babel Generator模块是 Babel 的代码生成器,它读取AST并将其转换为代码和源码映射(sourcemaps)。
- babel-template babel-template 是另一个虽然很小但却非常有用的模块。 它能让你编写字符串形式且带有占位符的代码来代替手动编码, 尤其是生成的大规模 AST的时候。 在计算机科学中,这种能力被称为准引用(quasiquotes)。
解析页面 config 配置
在业务代码编译成小程序的代码过程中,有一步是将页面入口 js 的 config 属性解析出来,并写入 *.json 文件,供小程序使用。那么这一步是怎么实现的呢,这里将这部分功能的关键代码抽取出来:
// 1. babel-traverse方法, 遍历和更新节点
traverse(ast, {
ClassProperty(astPath) { // 遍历类的属性声明
const node = astPath.node
if (node.key.name === 'config') { // 类的属性名为 config
configObj = traverseObjectNode(node)
astPath.remove() // 将该属性移除掉
}
}
})
// 2. 遍历,解析为 JSON 对象
function traverseObjectNode(node, obj) {
if (node.type === 'ClassProperty' || node.type === 'ObjectProperty') {
const properties = node.value.properties
obj = {}
properties.forEach((p, index) => {
obj[p.key.name] = traverseObjectNode(p.value)
})
return obj
}
if (node.type === 'ObjectExpression') {
const properties = node.properties
obj = {}
properties.forEach((p, index) => {
// const t = require('babel-types') AST 节点的 Lodash 式工具库
const key = t.isIdentifier(p.key) ? p.key.name : p.key.value
obj[key] = traverseObjectNode(p.value)
})
return obj
}
if (node.type === 'ArrayExpression') {
return node.elements.map(item => traverseObjectNode(item))
}
if (node.type === 'NullLiteral') {
return null
}
return node.value
}
// 3. 写入对应目录的 *.json 文件
fs.writeFileSync(outputPageJSONPath, JSON.stringify(configObj, null, 2))通过以上代码的注释,可以清晰的看到,通过以上三步,就可以将工程里面的 config 配置转换成小程序对应的 json 配置文件。
但是,哪怕仅仅是这一小块功能点,真正实现起来也没那么简单,你还需要考虑大量的真实业务场景及极端情况:
- 应用入口app.js 和页面入口 index.js 的 config 是否得单独处理?
- tabBar配置怎样转换且保证功能及交互一致?
- 用户的配置信息有误怎样提示?
更多代码编译相关内容,还是放在下一篇吧。
总结
到此,taro-cli 的主要目录结构,命令调用,项目初始化方式等基本都捋完了,有兴趣的同学可以结合着工程的源代码自己跟一遍,应该不会太费劲。
taro-cli 目前是将模版放在工程里面的,每次更新模版都要同步更新脚手架。而 vue-cli 是将项目模板放在 git 上,运行的时候再根据用户交互下载不同的模板,经过模板引擎渲染出来,生成项目。这样将模板和脚手架分离,就可以各自维护,即使模板有变动,只需要上传最新的模板即可,而不需要用户去更新脚手架就可以生成最新的项目。 这个后期可以纳入优化的范畴。
下一篇文章,我们将一起进入 Taro 代码编译的世界。
想知道将 react 编译到小程序,在将 react 的 AST 转换成小程序的 AST 的过程中是怎么做的呢?
文章已更新,简单提了一下与原理,要想把整个转换过程将清楚,估计单独一篇都不够。 @linxiaoru
期待后续的文章 @Pines-Cheng