Issues with huge data
jagadeesh595 opened this issue · 11 comments
Below are the few issues I am getting when I am trying to upload a file with around one million records. Help me on resolving the issues. When I am try to find the solution in blogs, all are suggesting to modify some logic. But I am using redisgraph-bulk-loader utility directly.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 3565: invalid continuation byte
_csv.Error: line contains NULL byte
Not working if column value contains quotes and comma.
redisgraph_bulk_loader.bulk_insert.CSVError: /home/ec2-user/test.csv:2 Expected 4 columns, encountered 5 ('1,3,4,"5,6"')
GraphName should be unique always for each new upload. In this case, if I want to add some more nodes to same graph or if I want establish relationships from some other file how to achieve this.
Hi @jagadeesh595,
Not working if column value contains quotes and comma.
This may be resolvable by using the --quote argument to change input-quoting behavior. The next suggestion would render this unnecessary, however.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 3565: invalid continuation byte
_csv.Error: line contains NULL byte
These may also be problems with type inference logic. You may wish to try using an updated branch (to be merged soon) that introduces enforced schema; this will solve your first problem as well.
git checkout improve-loader-logic
And updated your header rows as described in the updated branch's docs.
If this does not resolve your issues, you may need to look deeper into encoding problems.
GraphName should be unique always for each new upload. In this case, if I want to add some more nodes to same graph or if I want establish relationships from some other file how to achieve this.
The bulk loader is a one-time tool, and currently all updates to existing graphs must be made using Cypher queries.
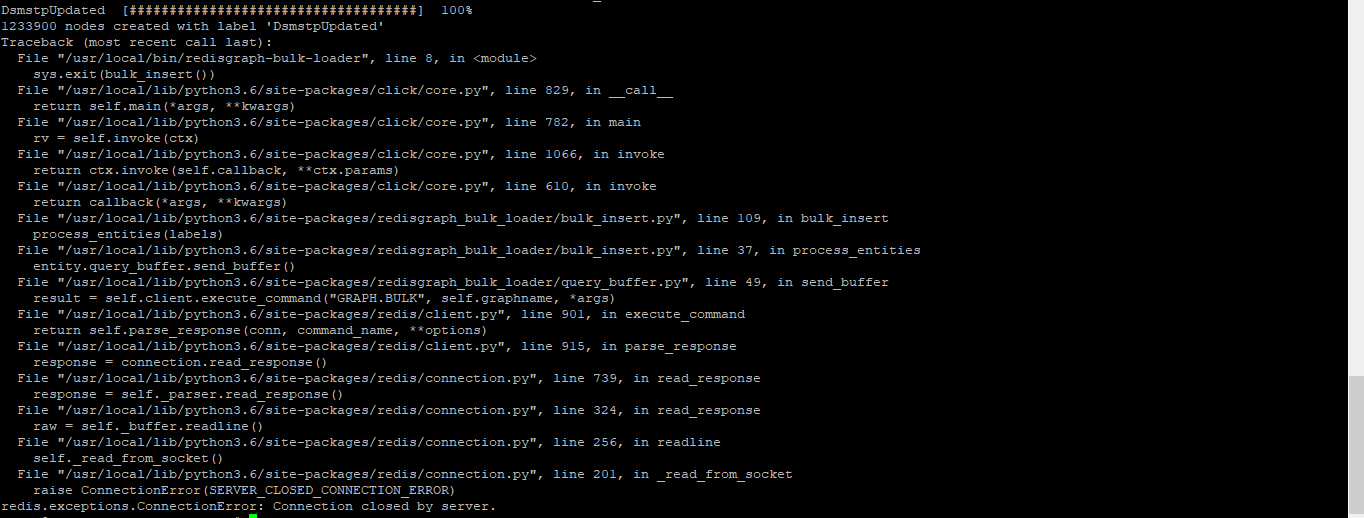
Thank you for the update. In the below file, I have 1.2 million records and when run the command, all the data got processed and then thrown below error. Do I need to keep any other Flag related to token size or buffer size or token count?
Command: /usr/local/bin/redisgraph-bulk-loader GRAPH_DEMO2 -n filename.csv -q 1
Those flags should not have any relevance here; you shouldn't need to modify them.
It looks like the Redis server crashed while processing the input generated by the Python script. Did it produce a crash log?
Additionally, if you can share your sample data or provide steps to reproduce I could look into this further!
We verified from the server side, it is working fine. With small set of data I am able to upload. With this bulk data, connection closed issue is occurring.
Hm, interesting! You can try lowering the values of the debug flags max-token-count, max-buffer-size, and max-token-size. If this causes the issue to resolve itself, then there is a bug in the tool's sizing logic that must be addressed.
The below two issues exists when there are special characters exists in the data. We have replaced all the special characters with empty space and now we are able to create nodes. Hope this should be taken care at python program level. Also, it would be better, if it shows custom error message with at which line and column issue exists.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 3565: invalid continuation byte
_csv.Error: line contains NULL byte
Can you give some examples of the special characters that triggered these errors? We ought to be able to handle them, but if not then I agree that a custom error message would be much more useful.
special characters like bullets as below

New issue: Earlier I was uploaded successfully one of my files with the content of 1.2 million nodes. Seems like new code changes merged 2 days back, now I am getting error when I was trying to upload the same file again. Below is the error. At least in this case we need to show custom error message to tell where exactly the issue is happening.
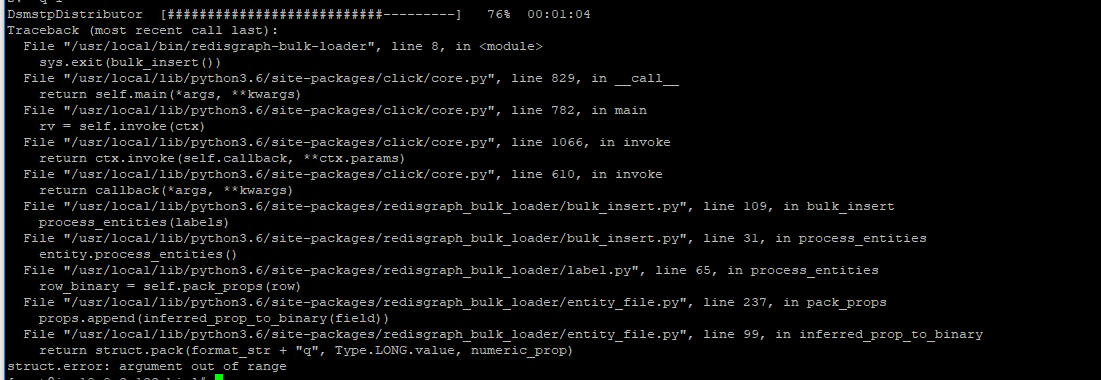
I agree that we should have a more descriptive error here.
Are you able to provide test data to reproduce this issue? Without steps to reproduce, I can do little to investigate this issue.
Hi @jagadeesh595 ,
I've pushed some changes that should solve the struct.error problem you encountered most recently.
With respect to the CSV errors, I'm ambivalent about trying to introduce encoding detection for CSVs with non-standard characters - these methods tend to be slow and there is no perfectly accurate solution. The Unicode bullet character is properly handled by both RedisGraph and the bulk loader; I do not know what encoding yours came from.
If you can provide the Python backtraces that caused these errors, I should be able to introduce more descriptive error messages!
My issues got resolved, Thank you!