redisgraph-bulk-loader returns with a non-existent identifier error
Raj-Joshi-dev opened this issue · 18 comments
Hi,
I am trying to bulk load nodes and relationships via CSV using the redisgraph-bulk-loader, but it returns with Relationship specified as a non-existent identifier. src: 2; dest: relationship
Nodes get created with labels "nodes" which is not intended.
Here is the log :
$ redisgraph-bulk-loader DemoGraph -n import/nodes.csv -r import/relationships.csv
101 nodes created with label 'nodes'
Relationship specified a non-existent identifier. src: 2; dest: relationship
Traceback (most recent call last):
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/bin/redisgraph-bulk-loader", line 33, in <module>
sys.exit(load_entry_point('redisgraph-bulk-loader==0.9.6', 'console_scripts', 'redisgraph-bulk-loader')())
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/bulk_insert.py", line 120, in bulk_insert
process_entities(reltypes)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/bulk_insert.py", line 31, in process_entities
entity.process_entities()
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/relation_type.py", line 66, in process_entities
raise e
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/relation_type.py", line 62, in process_entities
dest = self.query_buffer.nodes[end_id]
KeyError: 'relationship'
However, I do not understand the format of CSV required to bulk-load. I used the same csv format to load data in Neo4j and Memgraph which worked.
nodes.csv
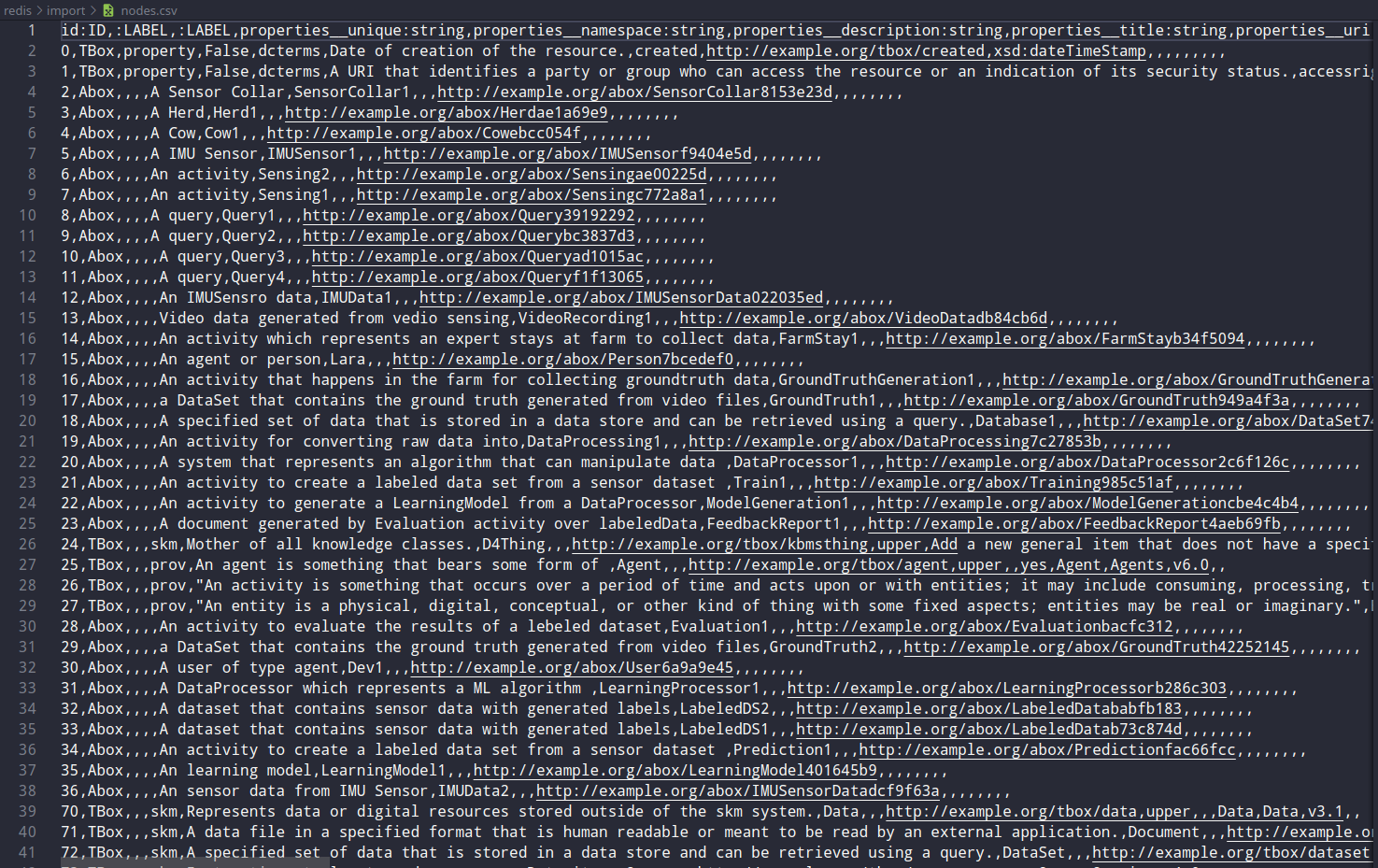
relationships.csv

Also, I am unable to access the graph via redis-cli as it returns null even for the nodes.
Help would be appreciated. 🙂
Hi @Raj-Joshi-dev,
The input flags and CSV format required by redisgraph-bulk-loader are detailed in the README in sections like https://github.com/RedisGraph/redisgraph-bulk-loader#input-constraints. It differs somewhat from that of Neo4j and Memgraph.
One important note is that :LABEL and :TYPE are not supported column types; your command will ultimately end up looking more like:
redisgraph-bulk-loader DemoGraph --enforce-schema --nodes-with-label TBox import/nodes.csv --relations-with-type relation import/relationships.csv
Thank you @jeffreylovitz 😄 for your quick response.
The input flags and CSV format required by
redisgraph-bulk-loaderare detailed in the README in sections like https://github.com/RedisGraph/redisgraph-bulk-loader#input-constraints. It differs somewhat from that of Neo4j and Memgraph.One important note is that
:LABELand:TYPEare not supported column types; your command will ultimately end up looking more like:redisgraph-bulk-loader DemoGraph --enforce-schema --nodes-with-label TBox import/nodes.csv --relations-with-type relation import/relationships.csv
After reading the documentation again and sanitizing CSV files I ran the above command. However, now there is IndexError: list index out of range error. There were TYPE and LABEL errors before running the command which I eliminated by removing respective columns.
Error Log :
$ redisgraph-bulk-loader DemoGraph --enforce-schema --nodes-with-label TBox import/nodes.csv --relations-with-type relation import/relationships.csv
Traceback (most recent call last):
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/bin/redisgraph-bulk-loader", line 33, in <module>
sys.exit(load_entry_point('redisgraph-bulk-loader==0.9.6', 'console_scripts', 'redisgraph-bulk-loader')())
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/bulk_insert.py", line 117, in bulk_insert
reltypes = parse_schemas(RelationType, query_buf, relations, relations_with_type, config)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/bulk_insert.py", line 23, in parse_schemas
schemas[idx + offset] = cls(query_buf, csv_tuple[1], csv_tuple[0], config)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/relation_type.py", line 11, in __init__
super(RelationType, self).__init__(infile, type_str, config)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/entity_file.py", line 189, in __init__
self.convert_header() # Extract data from header row.
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/entity_file.py", line 260, in convert_header
self.convert_header_with_schema(header)
File "/home/raj/Desktop/2020-msc-raj-dharmendra-joshi/src/.env/lib/python3.9/site-packages/redisgraph_bulk_loader/entity_file.py", line 238, in convert_header_with_schema
col_type = convert_schema_type(pair[1].upper().strip())
IndexError: list index out of range
nodes.csv (sanitized)
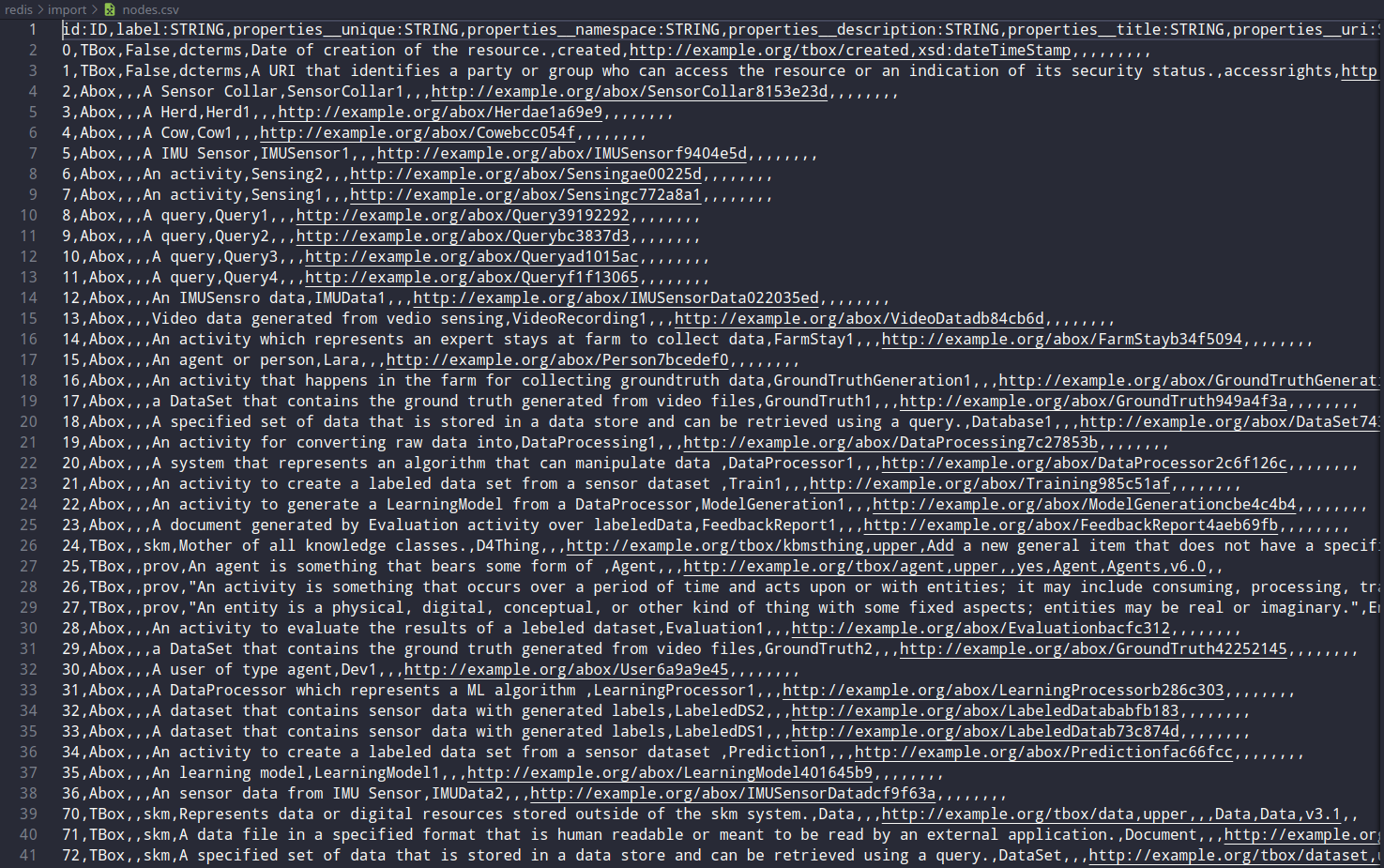
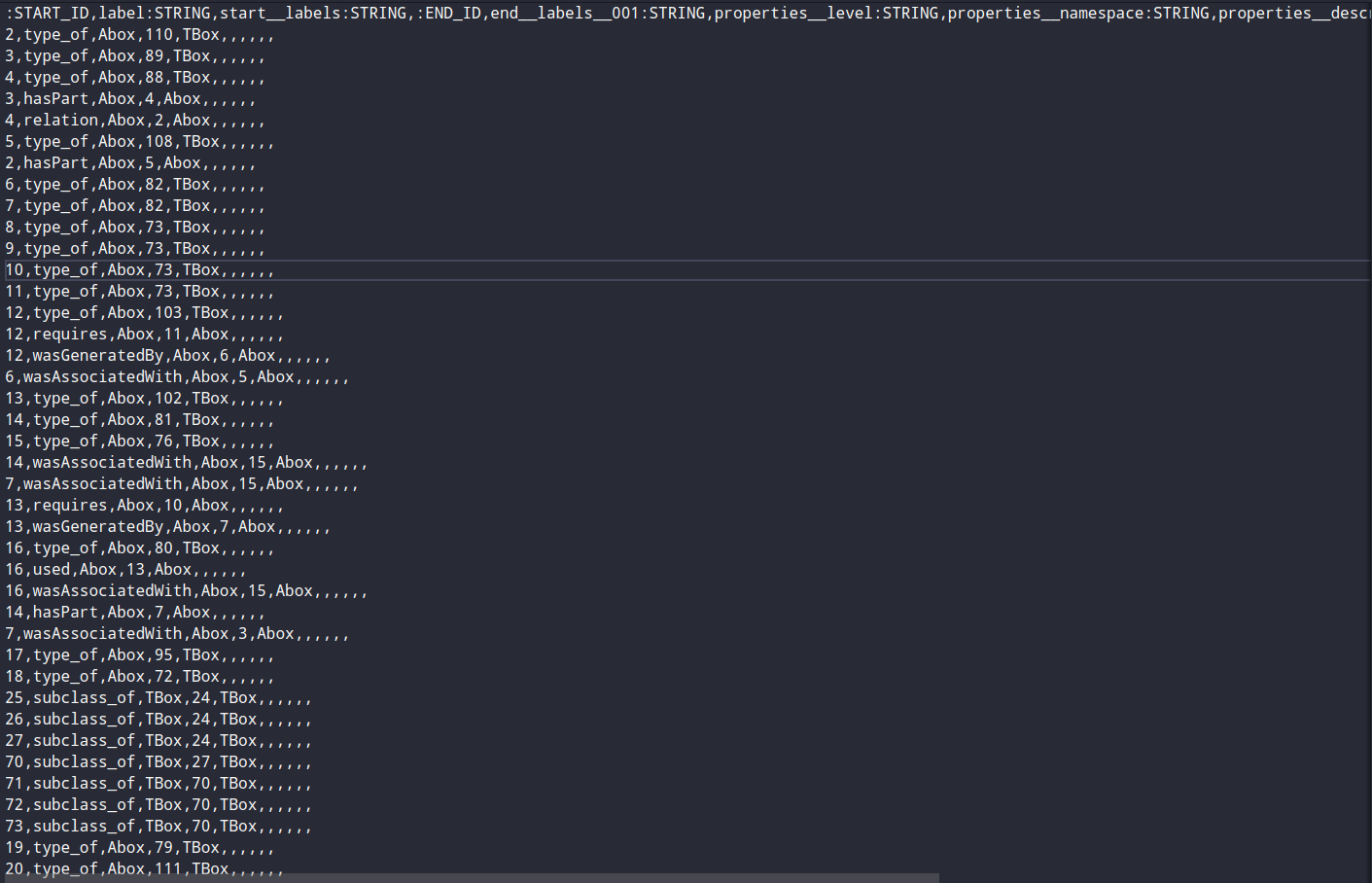
relationships.csv (sanitized)
After searching solutions for the error, most of the state
IndexErrors happen all the time. To solve the “indexerror: list index out of range” error, you should make sure that you’re not trying to access a non-existent item in a list. If you are using a loop to access an item, make sure that loop accounts for the fact that lists are indexed from zero. If that does not solve the problem, check to make sure that you are using range() to access each item by its index value.
Meaning my dataset is missing some key values?
PS: I am learning this for the first time.
The error you're encountering occurs at this line - https://github.com/RedisGraph/redisgraph-bulk-loader/blob/master/redisgraph_bulk_loader/entity_file.py#L233 .
At this point, we are trying to retrieve the type specified after the colon in a specific field of a header line. As such, an IndexError indicates that no colon was found in one of the fields. Can you validate these inputs or provide all of the header rows?
@jeffreylovitz Thank you for pointing out the error here
I have now successfully imported CSV into RedisGraph. However, I would like to add the remaining nodes from CSV in one command if possible.
I tried as following ways but none worked :
$ redisgraph-bulk-loader DemoGraph --enforce-schema --nodes-with-label TBox ABox import/nodes.csv
Log: Error: Got unexpected extra arguments
$ redisgraph-bulk-loader DemoGraph --enforce-schema --nodes-with-label ABox import/nodes.csv --nodes-with-label Tbox import/nodes.csv --relations-with-type relations import/relationship.csv
Log : 101 nodes created with label 'ABox' Node identifier '0' was used multiple times - second occurrence at import/nodes.csv:3
TBox and ABox nodes need to be separated into 2 different files. Right now you're importing nodes.csv twice, which will of course cause identifier collisions. If after separating them into two files, there are still shared identifiers between them, you can scope them with ID namespaces - https://github.com/redisgraph/redisgraph-bulk-loader#id-namespaces
you can scope them with ID namespaces - https://github.com/redisgraph/redisgraph-bulk-loader#id-namespaces
Okay from my understanding I modified schema like this :
nodes.csv
":ID(Cow)","label:STRING","properties_unique:STRING","properties_namespace:STRING"...
relationship.csv
":START_ID(Cow)","label:STRING","start_labels:STRING",":END_ID(Cow)","end_labels_001:STRING"...
command : $ redisgraph-bulk-loader CowGraph --enforce-schema --nodes import/nodes.csv --relations import/relationship.csv
Log:
101 nodes created with label 'nodes' 150 relations created for type 'relationship' Construction of graph 'CowGraph' complete: 101 nodes created, 150 relations created in 0.047860 seconds
So all my nodes have been imported successfully, but I have few questions regarding this :
- Is the schema correct according to RedisGraph?
- Is this the correct way to import using the tool?
- Also, querying on the DB would work fine with these identifiers?
Because I am going to write a Master Thesis on this subject, so I will have to investigate this.
Thank you again for your assistance. 🙂
I feel like this probably isn't generating the structure you want. Your nodes all have the literal label nodes and your edges have the type relationship, and you have the node properties label, properties_unique, and properties_namespace.
Header rows typically look like:
:ID(Person),firstName:STRING,lastName:STRING,gender:STRING,birthday:LONG,creationDate:LONG,locationIP:STRING,browserUsed:STRING
This is from the file Person.csv, which generates nodes with the label Person.
I feel like this probably isn't generating the structure you want.
That's what I suspect. However, I am working with 3 different openCypher projects at the moment and trying to build a Polyglot query system around it. So, I can share my initial dataset which I had obtained from the Neo4j instance, maybe it can make your input more clear to me in what direction I should move forward.
Schema
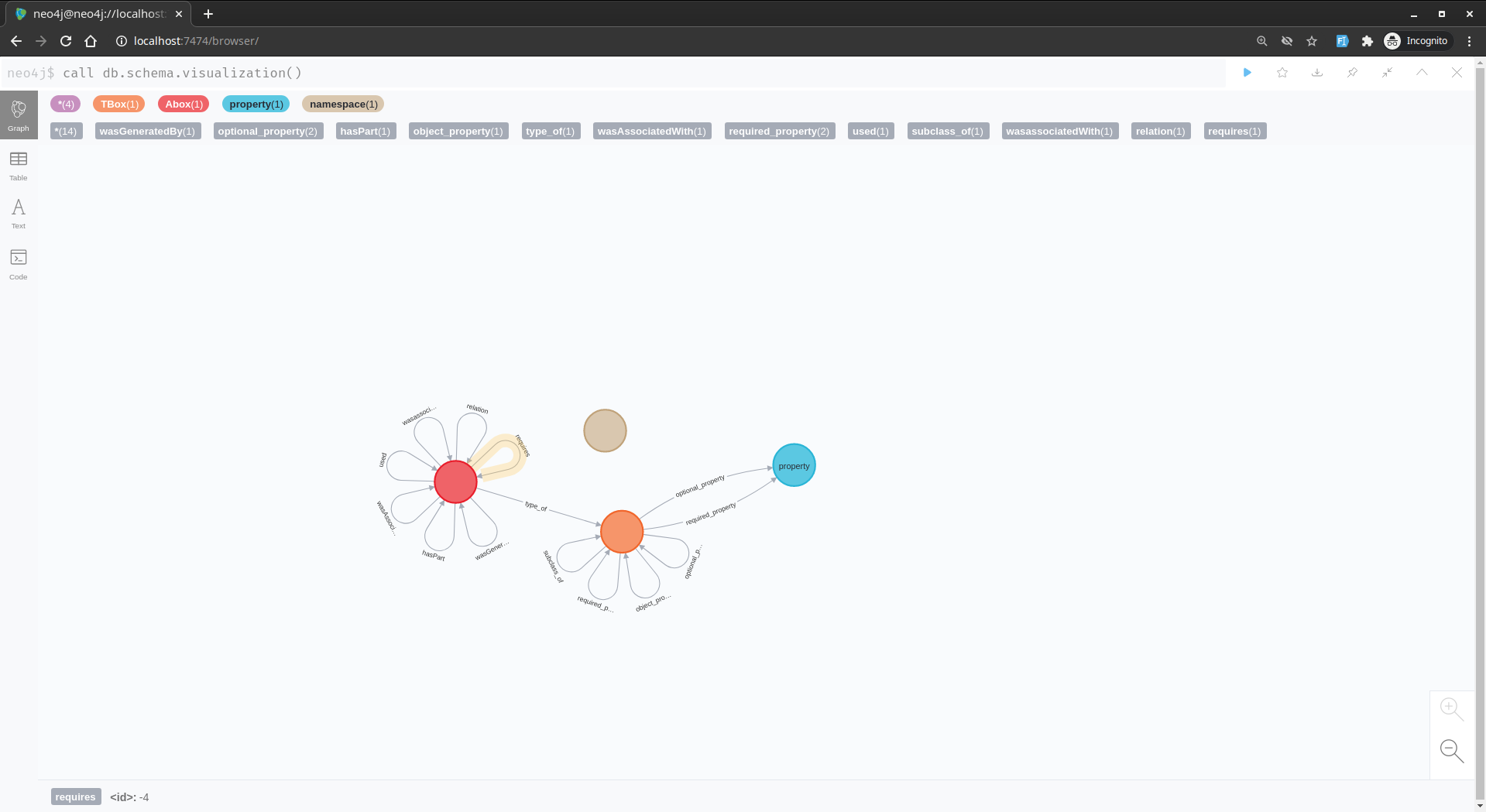
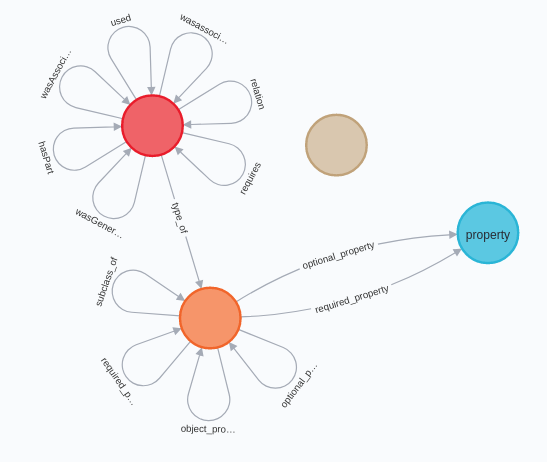
Roughly this is the table structure
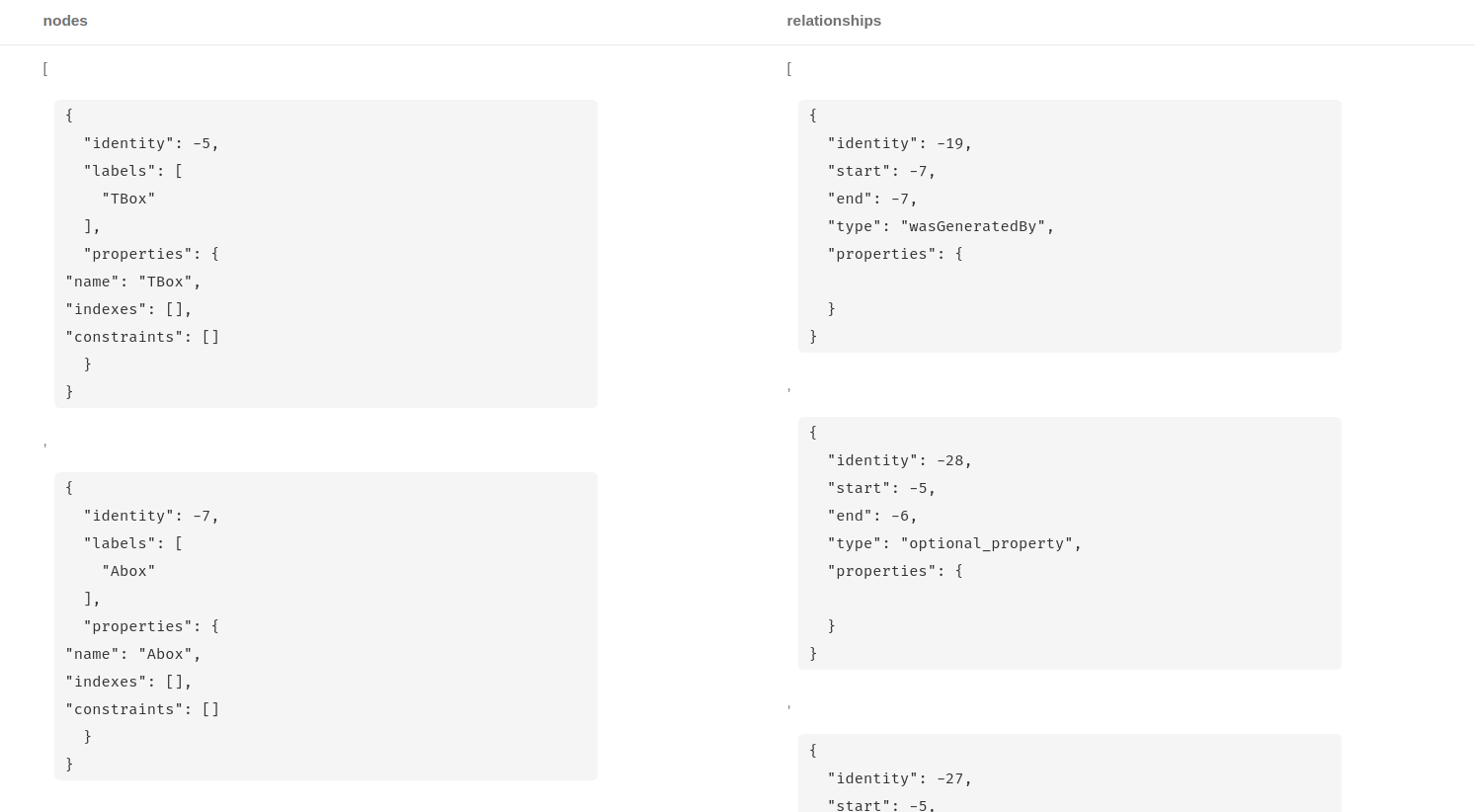
I face a challenge to import the same schema inside RedisGraph at the moment and it is difficult.
Alternatively, is there a way in RedisGraph to import schemas directly from Neo4j via JSON or other utility?
My best shot is using the bulk-loader at the moment.
Your input would be appreciated. @jeffreylovitz
That is very helpful, thanks!
I agree that the bulk loader is the right approach for you, but we'll have to restructure your inputs.
You'll need two node files, which for simplicity should be Abox.csv and Tbox.csv (if not using the --nodes-with-label argument, the bulk loader will use the file's base name as the label).
Similarly, you'll want a unique and appropriately-named CSV file for each relationship type.
It looks like your edges have no properties and your nodes only have a name property, so generate appropriate node IDs to make the correct relationships, and have label file CSV headers like so:
:ID, name:string
You'll need two node files, which for simplicity should be
Abox.csvandTbox.csv(if not using the--nodes-with-labelargument, the bulk loader will use the file's base name as the label).
I think I will go with --nodes-with-label for now.
Similarly, you'll want a unique and appropriately named CSV file for each relationship type.
There are 12 of them according to Neo4j browser, so 12 CSVs 😨
It looks like your edges have no properties and your nodes only have a name property, so generate appropriate node IDs to make the correct relationships, and have label file CSV headers like so:
:ID, name:string
Alright, this here gave me clarity regarding properties of edges (none) so that is good news, however generating appropriate node IDs would put extra manual effort, don't you think so? 🤕
More schema information:
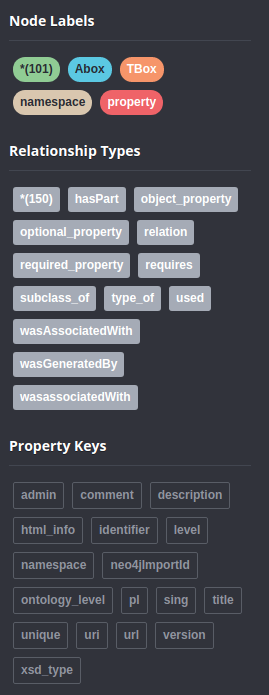
If you have any unique fields on the nodes, those can be used as the IDs, but in the absence of that you'll have to generate identifiers for them somehow. How else would you resolve the endpoints of edges?
If you have any unique fields on the nodes, those can be used as the IDs, but in the absence of that, you'll have to generate identifiers for them somehow. How else would you resolve the endpoints of edges?
I guess I have the identifier present in the Neo4j dataset (at least that's what I can see CSV & JSON), however during the formating process of CSV from Neo4j to Memgraph I might have deleted those, now I am porting from MemGraph to RedisGraph. maybe that is the problem?
Quick example:
I exported all the relationships from Neo4j and CSV looks like this -
p "[{""identifier"":http://example.org/abox/Cowebcc054f,""description"":A Cow,""title"":Cow1,""neo4jImportId"":4},{},{""identifier"":http://example.org/abox/SensorCollar8153e23d,""description"":A Sensor Collar,""title"":SensorCollar1,""neo4jImportId"":2}]" "[{""identifier"":http://example.org/abox/Sensingc772a8a1,""description"":An activity,""title"":Sensing1,""neo4jImportId"":7},{},{""identifier"":http://example.org/abox/Herdae1a69e9,""description"":A Herd,""title"":Herd1,""neo4jImportId"":3}]" "[{""identifier"":http://example.org/abox/Herdae1a69e9,""description"":A Herd,""title"":Herd1,""neo4jImportId"":3},{},{""identifier"":http://example.org/abox/Cowebcc054f,""description"":A Cow,""title"":Cow1,""neo4jImportId"":4}]" "[{""identifier"":http://example.org/abox/Sensingae00225d,""description"":An activity,""title"":Sensing2,""neo4jImportId"":6},{},{""identifier"":http://example.org/abox/IMUSensorf9404e5d,""description"":A IMU Sensor,""title"":IMUSensor1,""neo4jImportId"":5}]" "[{""identifier"":http://example.org/abox/SensorCollar8153e23d,""description"":A Sensor Collar,""title"":SensorCollar1,""neo4jImportId"":2},{},{""identifier"":http://example.org/abox/IMUSensorf9404e5d,""description"":A IMU Sensor,""title"":IMUSensor1,""neo4jImportId"":5}]"
More JSON like structure looks like this
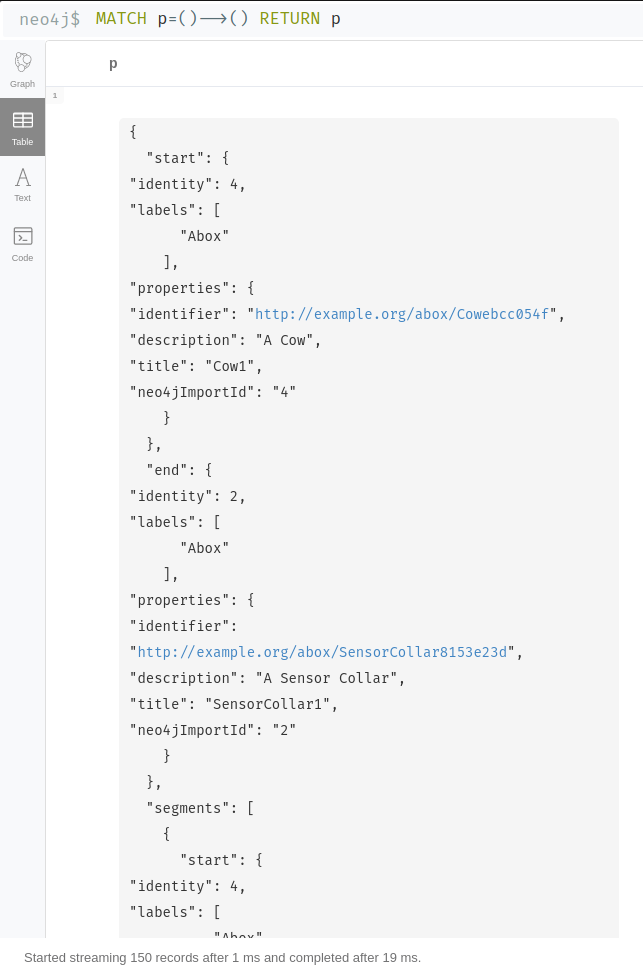
Initially, I just had a JSON file but somehow I managed to generate CSV out of it because Memgraph and RedisGraph do not support JSON import as far as I know.
You are correct that RedisGraph does not yet support JSON import.
Your relationships don't need IDs, just the nodes (again, to resolve the nodes as relationship endpoints). If you can export the identity field from Neo4j (or just invoke the ID function), you'll have the IDs you need.
If you can export the
identityfield from Neo4j (or just invoke theIDfunction), you'll have the IDs you need.
Alright, I now seem to understand the whole point, unique identifiers are what we're looking for. I went back to the original JSON and processed it. I can see id with nodes now.
Like this :
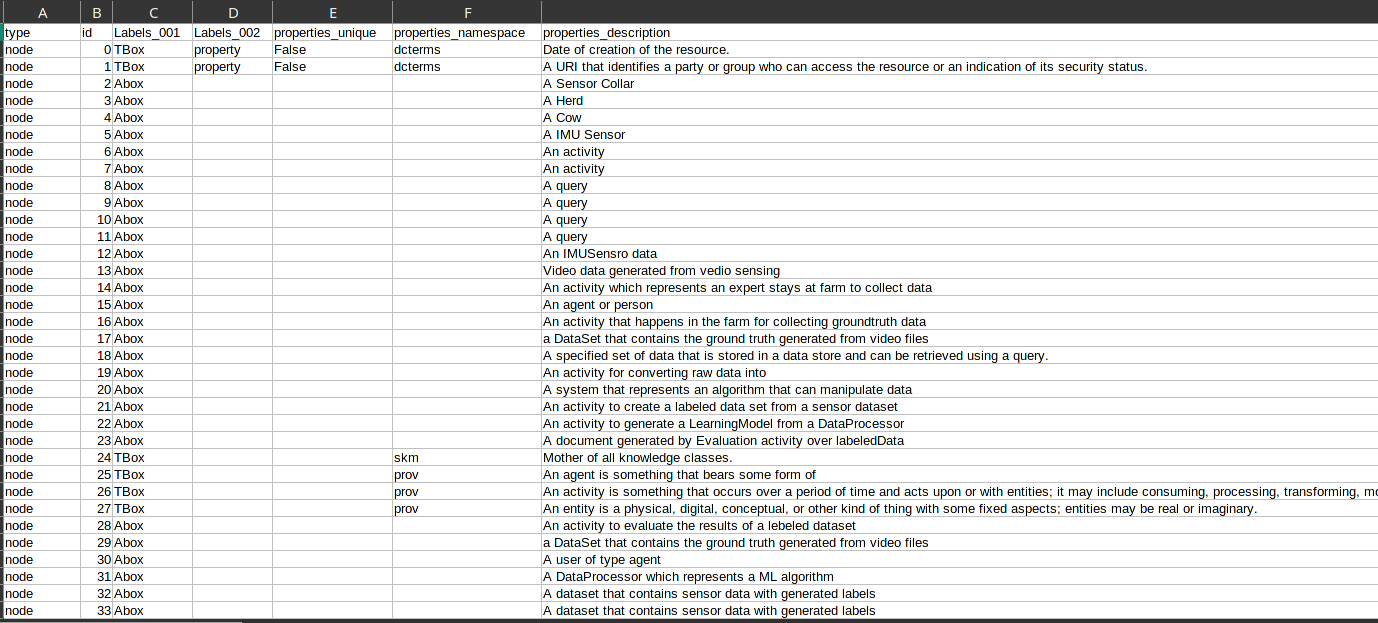
Raw text :
type,id,Labels_001,Labels_002,properties_unique,properties_namespace,properties_description,properties_title,properties_uri,properties_xsd_type,properties_identifier,properties_ontology_level,properties_html_info,properties_admin,properties_sing,properties_pl,properties_version,properties_comment,properties_url,label,start_id,start_labels,end_id,end_labels_001,properties_level,end_labels_002 node,0,TBox,property,False,dcterms,Date of creation of the resource.,created,http://example.org/tbox/created,xsd:dateTimeStamp,,,,,,,,,,,,,,,, node,1,TBox,property,False,dcterms,A URI that identifies a party or group who can access the resource or an indication of its security status.,accessrights,http://example.org/tbox/accessrights,xsd:anyURI,,,,,,,,,,,,,,,, node,2,Abox,,,,A Sensor Collar,SensorCollar1,,,http://example.org/abox/SensorCollar8153e23d,,,,,,,,,,,,,,, node,3,Abox,,,,A Herd,Herd1,,,http://example.org/abox/Herdae1a69e9,,,,,,,,,,,,,,, node,4,Abox,,,,A Cow,Cow1,,,http://example.org/abox/Cowebcc054f,,,,,,,,,,,,,,, node,5,Abox,,,,A IMU Sensor,IMUSensor1,,,http://example.org/abox/IMUSensorf9404e5d,,,,,,,,,,,,,,, node,6,Abox,,,,An activity,Sensing2,,,http://example.org/abox/Sensingae00225d,,,,,,,,,,,,,,, node,7,Abox,,,,An activity,Sensing1,,,http://example.org/abox/Sensingc772a8a1,,,,,,,,,,,,,,, node,8,Abox,,,,A query,Query1,,,http://example.org/abox/Query39192292,,,,,,,,,,,,,,, node,9,Abox,,,,A query,Query2,,,http://example.org/abox/Querybc3837d3,,,,,,,,,,,,,,, node,10,Abox,,,,A query,Query3,,,http://example.org/abox/Queryad1015ac,,,,,,,,,,,,,,,
I think this should do the trick? @jeffreylovitz 🙂
Those IDs look good! You should be able to convert that into the previously-discussed CSV format and import everything successfully 👍
It worked! 😄
Closing remarks :
After separating and formatting CSVs, I am finally able to import them into RediGraph without errors.
Command :
$ redisgraph-bulk-loader DemoGraph --enforce-schema --nodes import/TBox.csv --nodes import/ABox.csv --nodes import/Namespace.csv --relations-with-type relations import/relationship.csv
Log :
66 nodes created with label 'TBox'
31 nodes created with label 'ABox'
4 nodes created with label 'Namespace'
150 relations created for type 'relations'
Construction of graph 'DemoGraph' complete: 101 nodes created, 150 relations created in 0.034705 seconds
Last question @jeffreylovitz
Is the --relations-with-type needed while importing the relationship?
Yes, each relation csv file must be specified with --relations/-r or --relations-with-type/-R!
Thanks for your answers! 🙂