
인터넷에서 유명하는 합성 소스 또는 유행을 의미하는 밈과
새롭게 생겨나는 신조어를 사전 형식으로 검색 할 수 있는 사이트입니다.

2021.12.18. (토) ~ 2022.01.28. (금)
| Back-End | Front-End |
|---|---|
김용빈(팀장) |
이한샘 |
임전혁 |
정주혜 |
이지연 |
| 분류 | 기술 |
|---|---|
| Language | |
| Framework | |
| Build Tool | |
| DB | |
| In-Memory DB | |
| Server | |
| CI/CD | |
| Other |



조회 기능) 조회 성능 여러가지 방법으로 개선하기
우리 밈글밈글 사이트는 목록 조회의 기능이 많았다. 그렇기 때문에 성능을 개선해야 한다면 조회의 성능이어야 한다고 생각했고, 이를 위한 많은 고민을 했다.
목록 조회에는 많은 관계가 들어간다.
-
작성자 정보
-
조회수 정보
-
좋아요 개수 정보
-
댓글 개수 정보
-
좋아요 여부 정보
-
댓글 목록 정보
...
기존의 Spring Data JPA를 이용한 방식은 쿼리의 자유로운 호출이 어렵기 때문에 목록 조회에서 관계 엔티티의 데이터를 불러오기 위한 N+1 문제를 회피하기 어려웠다. 이는 특히 관계가 많은 게시글 목록 조회에서 치명적인 성능 저하를 일으켰다.
이 문제를 해결하기 위한 방법은 단순했다. 바로 관계 데이터를 위한 컬럼을 만들고 이 데이터를 update 함으로써 관리를 하는 것이었다. 이는 필요 이상의 관계 데이터를 호출하지 않게 되고, 가장 높은 수준의 성능 개선을 이룰 수 있을 것으로 생각이 되었다.
해답이 빨리 나온 문제였다. 하지만 우리는 챌린지를 하는 입장에서, 관계를 유지하면서 이 데이터를 이용해 최대한의 성능을 뽑아내는 것을 목표로 성능개선을 시도해보기로 했고, 이에 대한 고민을 시작했다.
아래 내용은 성능 개선을 위해 고려한 내용들이다.
FetchJoin은 N+1 문제를 해결하는 가장 일반적인 방법이다. 문제는 페이지네이션을 하기엔 매우 무거운 구조라는 것이다. FetchJoin은 페이지네이션을 시도시 limit을 쿼리 내에서 시행하는 것이 아닌 전체 레코드를 서버가 받아온 뒤 그 데이터의 일부를 잘라 클라이언트에 내려주는 방식이기 때문에 전체 목록 조회와 같은 기능에서 적합하지 않았다. 그렇기 때문에 댓글 목록 불러오기와 같은 부분에 적용하는 것으로 하고 다른 방법을 찾아보기로 했다.
스칼라 서브쿼리를 이용하면 목록을 한 방 쿼리로 불러올 수 있게 되고, 이것은 성능의 개선으로 이어질 것이라고 생각했다. DB에 방문하는 빈도를 줄이면 속도가 증가될 것이라는 순진한 생각에 기인한 발상이었다. 이는 절반은 맞았다. 탐색하는 레코드의 수가 적을 경우 이 속도는 즉시 처리하는 수준으로 크게 증가했다. 문제는 역시 전체 조회에서 발생했다. 더미데이터를 넣고 테스트를 해보니 그 성능이 개선 이전보다는 빠르긴 하지만, 더미데이터 양이 많아질수록 그 속도가 떨어지는 현상이 발생했다. 결국 스칼라 서브쿼리를 사용하는 방식 역시 전체 목록 조회에서 적합하지 않았기 때문에, 게시글 상세 조회 영역에 적용하는 것으로 하고 다른 방법을 찾아보기로 했다.

마지막에 생각한 것은 분할 호출을 통해 조인을 최소화시키면 어떨까 라는 점이었다. 이 방식은 얼핏 보면 Spring Data JPA에서와 같은 방식으로 보일 수 있지만, N+1 문제를 발생시키는 것이 아닌, 전체 조회에서 불러와야 하는 쿼리의 수만큼만 호출하는 점이 달랐다.
이를 위해 스칼라 서브쿼리를 별도의 쿼리로 분리하고, HashMap에 저장하여 이 데이터를 호출하는 방식으로 활용했다.

// 작성자 맵
HashMap<String, String> userInfoMap = getUserInfoMap(questionList);
// 나도 궁금해요 맵
HashMap<String, Boolean> curiousTooMap = getCuriousTooMap(questionIdList);
// 좋아요 개수 맵
HashMap<Long, Long> curiousTooCountMap = getCuriousTooCountMap(questionList);
// 댓글 개수 맵
HashMap<Long, Long> commentCountMap = getDictQuestionCommentCountMap(questionList);
// 채택 여부 맵
HashMap<Long, Long> completeMap = getIsComplete(questionIdList);데이터들을 미리 일괄적으로 호출하고 운용하는 것이다.
dictQuestionResponseDtoList.add(DictQuestionResponseDto.builder()
// ...
.username(userInfoMap.get(questionId+":username"))
.profileImageUrl(userInfoMap.get(questionId+":profileImage"))
.writer(userInfoMap.get(questionId+":nickname"))
.isCuriousToo(user != null && curiousTooMap.get(questionId + ":" + userId) != null)
.isComplete(completeMap.get(questionId) != null)
.build()
);HashMap의 get 시간복잡도가 O(1)인 점을 이용하여 HashMap 안에 전체 레코드를 보관한 뒤, get으로 호출하는 방식으로 값 자체를 불러오거나, 값의 유효성을 검사하는 방식을 사용했다.
이렇게 풀테이블스캔을 분할하여 호출하도록 쿼리를 작성하고 벤치마킹을 시행해보니, 눈에 띄는 개선 효과를 얻을 수 있었다.

1차 개선(스칼라 서브쿼리 사용) 시기보다도 3배정도 빨라진 성능을 보여줬다. 만족할만한 수준의 성능 개선이었다고 느꼈다.
처음의 개선안대로 컬럼을 만들어 관리했다면 어쩌면 위의 벤치마킹 결과보다 훨씬 높은 수준의 성능 개선이 이루어졌을 수 있다. 하지만 우리 프로젝트의 가장 메인 토픽이었던 우리의 구조 속에서 우리의 고민을 담아보자는 취지로 시행했던 성능 개선 시도였기 때문에, 유익한 경험이었다고 생각한다.
알림 기능) 새로운 알림이 생겼을 경우에만 DB에서 받아오기
우리 페이지는 알람을 받는데 웹소켓을 사용하지 않았다. 페이지를 이동할 때마다 알람 정보를 요청하는 식으로 작동한 것이다. 이것은 변화량이 적은 알람 기능에 있어서 비효율적인 동작이다. 그렇기 때문에 이 부분에 대한 개선이 필요했다. 지금부터 적을 부분은 당장 적용한 부분(백엔드 단일)과 이후에 더욱 강화하여 적용할 수 있는 부분(프론트엔드와 협업)들이다.
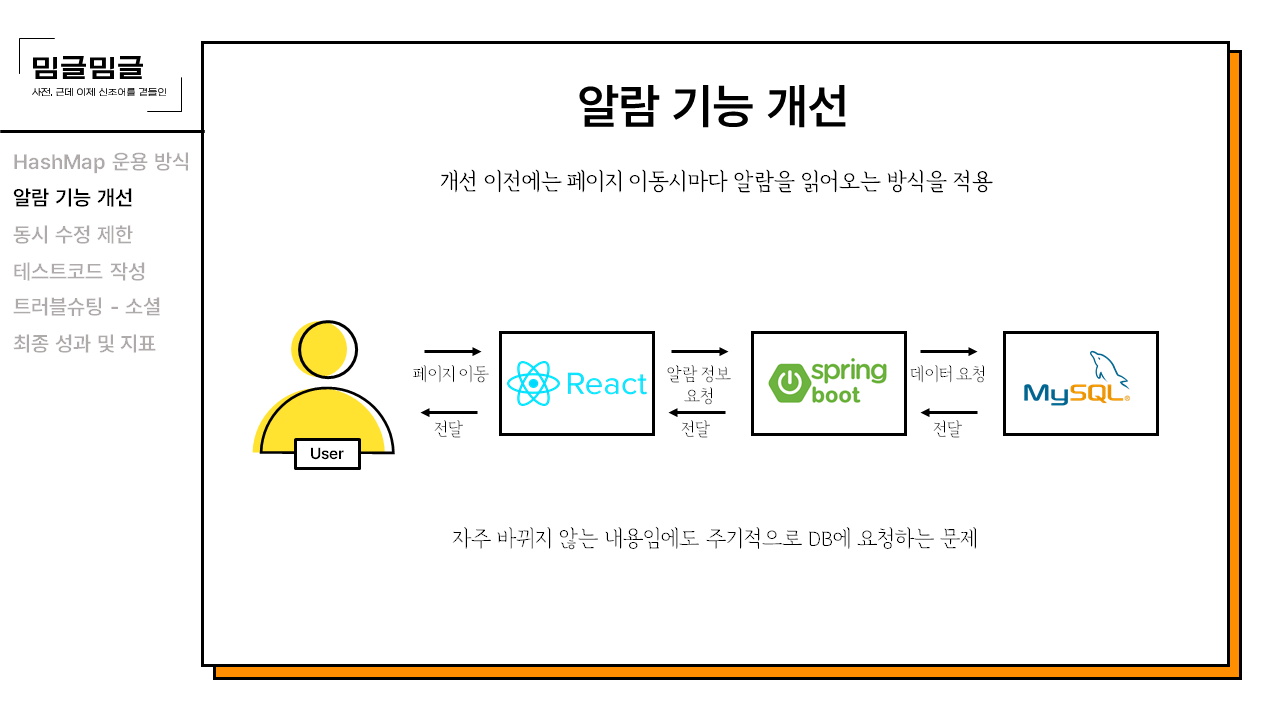
현재의 방식은 페이지를 이동할 때마다 백엔드에 알람 정보를 요청, 사용자의 알람 테이블에서 알람 정보를 모두 가져오는 식으로 되어있다. 이는 자주 바뀌지 않는 내용인데도 주기적으로 DB에 요청하기 때문에 DB는 불필요한 부하를 안게 되고, 이것은 상당히 마음이 불편한 일이다. 요청이 만약에 많이 밀린다면 속도 저하 요인이 될 수 있는 부분이다. 이 부분에 대한 개선이 필요했다.
그렇게 고민을 하던 중, 우리 페이지의 특성을 떠올렸다.
우리 페이지는 알람 기능을 웹소켓을 이용해 구현하지 않았기 때문에, 페이지 이동시마다 요청을 한다. 어, 그러면 페이지 이동을 할 때마다 데이터가 바뀌었는지를 체크해서 DB를 방문할지 여부를 결정하면 되는 것 아닌가?
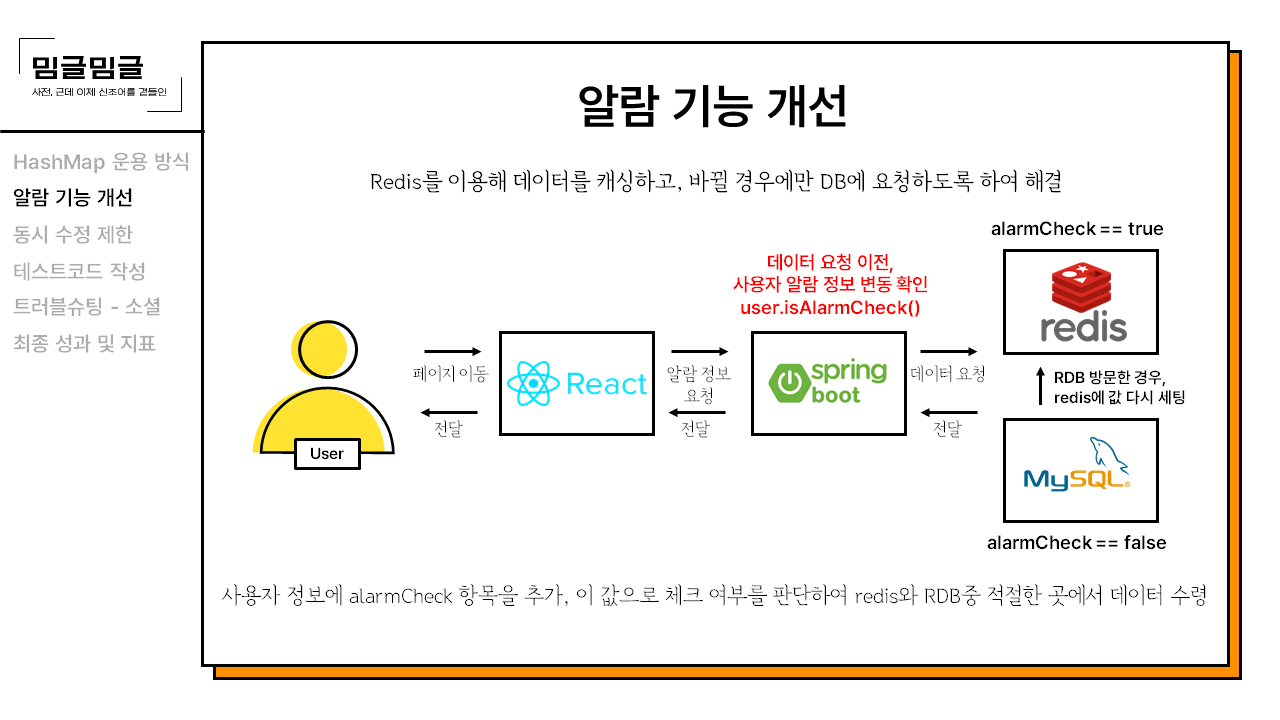
사용자에게 AlarmCheck 컬럼을 추가하고, 이 값을 이용해 바뀌지 않았을 땐 redis에서 값을 받아오다가, 바뀌었을 경우엔 DB에서 값을 가져오고, MySQL은 redis에 새로운 값을 세팅해주는 것이다. 그리고 이후엔 다시 redis를 이용해 통신한다. 이 방식을 적용함으로써 DB에 방문하는 빈도를 크게 낮출 수 있었고, 이것은 측정하진 못 했지만 사이트 자체의 퍼포먼스 개선에 영향을 주었을 것이라고 생각한다.
여기까지는 백엔드에서 단독으로 적용 가능한 부분이었다. 이 방식은 백엔드에서 단독으로 적용할 수 있기 때문에 프론트엔드의 노력이 추가되지 않는다는 장점이 있지만, 알람을 읽었을 경우 읽은 알람에 대한 처리를 별도로 해줘야 하는 점 때문에 다소 불필요한 절차가 추가될 가능성이 있다. 이 문제를 해결하기 위해선 프론트엔드와의 협업이 필요하다고 생각했고, 이 과정을 통해 추가적으로 작업에 수행되는 스텝 수를 줄일 수 있을 것이라는 생각이 들었다.
이하는 실제 시스템에 적용되진 않았으며, 이론상 생각만 해 본 부분이라 도표가 없는 점 양해 부탁.
-
기본적으로 알람 정보는 받아오고나면 로컬 스토리지에서 관리.
-
페이지 이동시마다 리액트가 스프링부트에 알람 정보를 요청.
-
스프링부트는 redis에서 값을 확인. 이 값은 변화 여부만 기록함.
-
변화되지 않았을 경우 리액트는 로컬 스토리지의 데이터 반환.
이렇게 만들 경우, 사용자 데이터에 알람 체크 컬럼이 필요가 없어진다. 백엔드 측에서의 관리 포인트가 하나 줄어드는 것이다. 그리고 알람 확인 여부를 프론트에서 관리할 수 있기에 redis의 값을 수정하는 절차도 줄일 수 있게 된다.
사전 기능) 사전의 동시 수정 제한
우리가 만들었던 밈글밈글 사이트는 오픈사전 형식이었기 때문에 최초 작성자가 아니라고 해도 누구나 편집을 할 수 있게 되어 있다. 이 말은, 다른 사람들이 하나의 용어사전 글을 동시에 수정할 수 있다는 것이다. 이는 수정을 일찍 마친 사람의 데이터가 손쉽게 소실될 수 있음을 의미하기 때문에 이런 부분들을 제한할 수 있어야 했다.
당시 나왔던 대안은 두 가지가 있었다.
-
동시에 수정이 불가능하도록 하자!
-
용어 사전 페이지의 편집 기능을 다른 뜻 추가 기능처럼 만들어서 아래에 붙이도록 하자!
개인적으로 2.의 적용안이 좋다고 생각했지만, 이미 페이지 개발은 2.와 다른 형식으로 완료된 상태였기 때문에, 이를 적용하기 위해선 추가적인 프론트엔드의 작업 수요가 발생하는 상황이었다. 안그래도 시안에 쫓겨 작업을 하던 프론트엔드 분들에게 부하를 가할 수는 없는 노릇이었고, 이에 따라 자연스럽게 1.로 적용하게 되었다.
처음에는 이 방식을 어떻게 적용할까에 대해 여기저기 찾아다녔다. 처음 찾아본 곳은 선배 기수의 처리 방식이었다.
마침 동시처리를 제한하는 형식의 사이트가 이미 있었기 때문에 그곳의 소스코드를 봤다. 항해99 2기의 판단(Pandan)이라는 팀의 작업물이었는데, 이곳은 DB만 사용하는 방식이었기 때문에 나는 조금 색다르게 적용해보고 싶었다.
그래서 Redis를 쓰기로 했다.
그럼 이제 본문으로 넘어간다.

이에 따라 늦게 작성한 사용자의 데이터만 반영이 되고, 먼저 작성한 사람의 데이터는 수정내역의 뒤안길로 사라져버리는 문제가 있었다. 사용자가 정성스럽게 작성한 데이터가 소실되는 것은 매우 뼈아픈 일이었기 때문에, 이 문제를 해결하기 위해서는 둘 중 한명만 수정이 가능하게 해야했다. 이를 위해 우리는 만료기한을 지정해준 상태로 레디스에 값을 세팅 해주는 방식을 적용했다.
// DictServicepublic Boolean getDictHealthCheck(Long dictId, UserDetailsImpl userDetails) {
String key = DICT_HEALTH_CHECK_KEY + ":" + dictId;
String result = redisService.getDictHealth(key);
String username = userDetails.getUsername();
// 키가 없으면 자신의 아이디로 등록, 키가 있을 경우 내 아이디와 일치하면 갱신if(result == null || username.equals(result)){
redisService.setDictHealth(key, username);
return true;
}
// 키가 이미 존재하면서 나의 키가 아니면 수정 불가.return false;
}// RedisServicepublic String getDictHealth(String key) {
return redisStringTemplate.opsForValue().get(key);
}
public void setDictHealth(String key, String str) {
redisStringTemplate.opsForValue().set(key, str);
redisStringTemplate.expire(key, 15, TimeUnit.SECONDS);
}여기에 추가로 프론트엔드에서 레디스 만료시간 갱신을 위한 요청을 주기적으로 보내주면 끝나는 코드였다. 폴링 방식이지만 10초 정도에 한 번씩의 요청은 나쁘지 않은 것 같은데? 싶다.
레디스를 사용하니 추가적인 이점도 얻을 수 있었다. 바로 코드의 간소화였다. DB를 탐색하며 값이 변동하는지 아닌지에 대한 컬럼을 확인해서 처리를 하고 사용자가 비정상적인 경로로 나가는 것을 체크해야 하고... 그러한 방식을 간단한 방식으로 처리할 수 있게 되었다. 위의 코드가 전부다.


도표로 보자면 이러한 방식이다.
그럼에도 잠재적인 위험은 존재하는데, 바로 사용자가 만료 시간(15초) 이상 인터넷 연결이 끊겨있는 상태가 발생할 경우 작성한 내용의 기록 권한을 잃어버리는 것이다. 현재는 프론트엔드 측에서 임시 저장을 해주는 등의 기능을 제공한다면 될 것이라고 생각하고 있다. 하지만 더욱 뾰족한 해결방안이 필요해보인다. 아직 이 부분에 대해선 답을 찾지 못 했다.
사전 기능) 유튜브 연관동영상 검색 결과 신뢰도 높이기
유튜브 영상을 검색해 관련성 있는 영상을 가져오는 기능을 구현하던 중 문제가 발생했다.
유튜브 영상의 검색결과가 생각보다 그렇게 관련성이 높은 결과가 잘 나오지 않는다는 점이었다.

키워드와 거의 정확히 관련이 있는 영상만 가져와야 하는 상황이었기 때문에 이것은 꽤나 심각한 문제였다. 그래서 대책을 강구하기 시작했다.
그렇게 생각하던 중, 제목이 유사한 영상을 채택한다면 일반적으로 꽤나 높은 신뢰도의 영상을 서치할 수 있게 될 것이라고 생각했다. 그래서 찾은 것이 문자열의 유사도를 구하는 알고리즘이었다.
내가 채택한 알고리즘은 레벤슈타인 거리 알고리즘(Levenshtein distance algorithm) 이었다. 이 알고리즘은 문장의 유사도를 0~1 사이의 실수로 표시해주는 알고리즘이다. 이 알고리즘을 선택한 이유는 구현 방식이 단순해서였다. 시간상의 이유로 코드는 복붙으로 사용하겠지만, 그 로직은 이해해야 하지 않겠는가. 그래서 가져다 쓸 수 있는 것 중 이해가 가장 쉽다고 생각되는 것을 선택했다.
private double similarity(String s1, String s2) {
String longer = s1, shorter = s2;
if (s1.length() < s2.length()) {
longer = s2;
shorter = s1;
}
int longerLength = longer.length();
if (longerLength == 0) return 1.0;
return (longerLength - editDistance(longer, shorter)) / (double) longerLength;
}
private int editDistance(String s1, String s2) {
s1 = s1.toLowerCase();
s2 = s2.toLowerCase();
int[] costs = new int[s2.length() + 1];
for (int i = 0; i <= s1.length(); i++) {
int lastValue = i;
for (int j = 0; j <= s2.length(); j++) {
if (i == 0) {
costs[j] = j;
} else {
if (j > 0) {
int newValue = costs[j - 1];
if (s1.charAt(i - 1) != s2.charAt(j - 1)) {
newValue = Math.min(Math.min(newValue, lastValue), costs[j]) + 1;
}
costs[j - 1] = lastValue;
lastValue = newValue;
}
}
}
if (i > 0) costs[s2.length()] = lastValue;
}
return costs[s2.length()];
}원리는 간단하다. 두 개의 문자열을 입력받아 둘의 유사도에 따른 가중치를 계산해 출력해주는 알고리즘이다. 이것을 이용해 연관성 있는 영상 중 더 연관성 있는 내용을 출력해낼 수 있을 것이다.
내가 이 알고리즘을 활용한 방식은 다음과 같다.
-
Youtube Data API v3을 활용해 영상 검색 결과를 받아온다.
-
그 중 제목이 내가 입력한 키워드와 일치하도록 한 번 더 필터링한다.
-
알고리즘 시행 결과, 유사도 67% 이상인 내용을 가져오도록 정책을 설정해준다.

Q) 왜 유사도가 67% 이상이어야 하나요?
A) 가장 먼저 고려한 점은 사전의 단어가 3글자 이하일 때였는데, 3글자 이하의 단어는 신뢰도가 100%가 아니면 우연의 일치로 동일한 문자열이 나올 경우 관계 없는 동영상이 가져와지는 빈도가 높아진다. 그렇기 때문에 3글자 까지는 최소한 100%의 신뢰도를 가져야만 했다.
다음으로 고려한 부분은 그러면 몇 글자부터 몇 퍼센트의 유사도를 가져와야할까라는 점이었는데, 일반적인 단어들의 동향을 살펴보니, 4글자 부터는 명사뿐 아니라 동사도 등장하기 시작했다. 동사의 경우 활용에 따라 용어의 끝자가 다르게 쓰일 때가 있는데, 이 경우를 고려하여 유사도를 설정해줘야 했고, 이에 따라 67%의 신뢰도로 설정하게 되었다.