This is the official implementation of our ICML 2023 paper "LinSATNet: The Positive Linear Satisfiability Neural Networks".
With LinSATNet, you can enforce the satisfiability of general positive linear constraints to the output of neural networks.
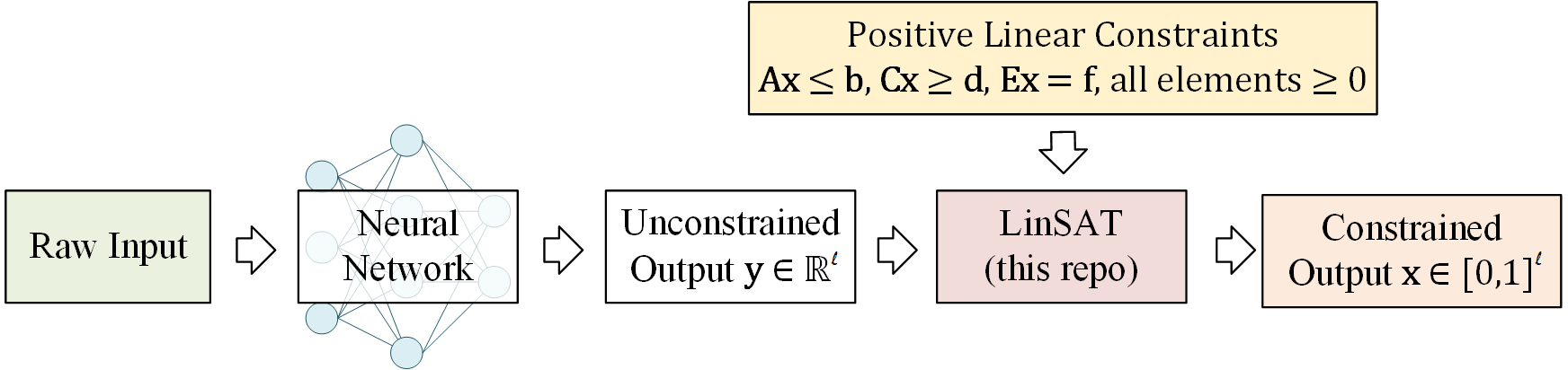
LinSATNet supports sparse constraints starting
v0.1.1! The forward and backward should be identical to the dense
version, but the sparse version is expected to be more efficient in time and GPU memory. Upgrade by
pip install --upgrade linsatnet
The LinSAT layer is fully differentiable, and the gradients are exactly computed. Our implementation now supports PyTorch.
You can install it by
pip install linsatnetAnd get started by
from LinSATNet import linsat_layer- LinSATNet
There is a quick example if you run LinSATNet/linsat.py directly. In this
example, the doubly-stochastic constraint is enforced for 3x3 variables.
To run the example, first clone the repo:
git clone https://github.com/Thinklab-SJTU/LinSATNet.gitGo into the repo, and run the example code:
cd LinSATNet
python LinSATNet/linsat.pyIn this example, we try to enforce doubly-stochastic constraint to a 3x3 matrix. The doubly-stochastic constraint means that all rows and columns of the matrix should sum to 1.
The 3x3 matrix is flattened into a vector, and the following positive
linear constraints are considered (for
E = torch.tensor(
[[1, 1, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 1, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 1]], dtype=torch.float32
)
f = torch.tensor([1, 1, 1, 1, 1, 1], dtype=torch.float32)We randomly init w and regard it as the output of some neural networks:
w = torch.rand(9) # w could be the output of neural network
w = w.requires_grad_(True)We also have a "ground-truth target" for the output of linsat_layer, which
is a diagonal matrix in this example:
x_gt = torch.tensor(
[1, 0, 0,
0, 1, 0,
0, 0, 1], dtype=torch.float32
)The forward/backward passes of LinSAT follow the standard PyTorch style and are readily integrated into existing deep learning pipelines.
The forward pass:
linsat_outp = linsat_layer(w, E=E, f=f, tau=0.1, max_iter=10, dummy_val=0)The backward pass:
loss = ((linsat_outp - x_gt) ** 2).sum()
loss.backward()You can also set E as a sparse matrix to improve the time & memory efficiency
(especially for large-sized input). Here is a dumb example (consider to construct
E in sparse for the best efficiency):
linsat_outp = linsat_layer(w, E=E.to_sparse(), f=f, tau=0.1, max_iter=10, dummy_val=0)We can also do gradient-based optimization over w to make the output of
linsat_layer closer to x_gt. This is what happens when you train a
neural network.
niters = 10
opt = torch.optim.SGD([w], lr=0.1, momentum=0.9)
for i in range(niters):
x = linsat_layer(w, E=E, f=f, tau=0.1, max_iter=10, dummy_val=0)
cv = torch.matmul(E, x.t()).t() - f.unsqueeze(0)
loss = ((x - x_gt) ** 2).sum()
loss.backward()
opt.step()
opt.zero_grad()
print(f'{i}/{niters}\n'
f' underlying obj={torch.sum(w * x)},\n'
f' loss={loss},\n'
f' sum(constraint violation)={torch.sum(cv[cv > 0])},\n'
f' x={x},\n'
f' constraint violation={cv}')And you are likely to see the loss decreasing during the training steps.
To use LinSATNet in your own project, make sure you have the package installed:
pip install linsatnetand import the pacakge at the beginning of your code:
from LinSATNet import linsat_layer, init_constraintsLinSATNet.linsat_layer(x, A=None, b=None, C=None, d=None, E=None, f=None, constr_dict=None, tau=0.05, max_iter=100, dummy_val=0, mode='v2', grouped=True, no_warning=False) [source]
LinSAT layer enforces positive linear constraints to the input x and
projects it with the constraints
Parameters:
-
x: PyTorch tensor of size ($n_v$ ), it can optionally have a batch size ($b \times n_v$ ) -
A,C,E: PyTorch tensor of size ($n_c \times n_v$ ), constraint matrix on the left hand side -
b,d,f: PyTorch tensor of size ($n_c$ ), constraint vector on the right hand side -
constr_dict: a dictionary with initialized constraint information, which is the output of the functionLinSATNet.init_constraints. Specifying this variable could avoid re-initializing the constraints for the same constraints and improve the efficiency -
tau: (default=0.05) parameter to control the discreteness of the projection. Smaller value leads to more discrete (harder) results, larger value leads to more continuous (softer) results. -
max_iter: (default=100) max number of iterations -
dummy_val: (default=0) the value of dummy variables appended to the input vector -
mode: (default='v2') LinSAT kernel implementation.v1is the one came with the ICML paper,v2is the improved version with (usually) better efficiency -
grouped: (default=True) group non-overlapping constraints in one operation for better efficiency -
no_warning: (default=False) turn off warning message
return: PyTorch tensor of size (
Notations:
-
$b$ means the batch size. -
$n_c$ means the number of constraints ($\mathbf{A}$ ,$\mathbf{C}$ ,$\mathbf{E}$ may have different$n_c$ ) -
$n_v$ means the number of variables
- You must ensure that your input constraints have a non-empty feasible space.
Otherwise,
linsat_layerwill not converge. It is also worth noting thatxis in the range of[0, 1], and you may add a multiplier to scale it. - You may tune the value of
taufor your specific tasks. Monitor the output of LinSAT so that the "smoothness" of the output meets your task. Reasonable choices oftaumay range from1e-4to100in our experience. - Be careful of potential numerical issues. Sometimes
A x <= 1does not work, butA x <= 0.999works. - The input vector
xmay have a batch dimension, but the constraints can not have a batch dimension. The constraints should be consistent for all data in one batch. - Input constraints as sparse tensors can usually help you save GPU memory. When
working with sparse constraints,
A,C,Eshould betorch.sparse_coo_tensor, andb,d,fshould be dense tensors.
Here we introduce the mechanism inside LinSAT. It works by extending the Sinkhorn algorithm to multiple sets of marginals (to our best knowledge, we are the first to study Sinkhorn with multi-sets of marginals). The positive linear constraints are then enforced by transforming the constraints into marginals. For more details and formal proofs, please refer to our paper.
Let's start with the classic Sinkhorn algorithm. Given non-negative score matrix
If you are seeing the math formulas not rendered correctly, it is an issue of github. Please refer to our main paper for better view.
The algorithm steps are:
Initialize
Note that the above formulation is modified from the conventional Sinkhorn formulation.
$\Gamma_{i,j}u_j$ is equivalent to the elements in the "transport" matrix in papers such as (Cuturi 2013). We prefer this new formulation as it generalizes smoothly to Sinkhorn with multi-set marginals in the following.To make a clearer comparison, the transportation matrix in (Cuturi 2013) is
$\mathbf{P}\in\mathbb{R}_{\geq 0}^{m\times n}$ , and the constraints are$$\sum_{i=1}^m P_{i,j}=u_{j},\quad \sum_{j=1}^n P_{i,j}=v_{i}$$ $P_{i,j}$ means the exact mass moved from$u_{j}$ to$v_{i}$ .The algorithm steps are:
Initialize
$\Gamma_{i,j}=\frac{s_{i,j}}{\sum_{i=1}^m s_{i,j}}$
$\quad$ repeat:
$\qquad{P}_{i,j}^{\prime} = \frac{P_{i,j}v_{i}}{\sum_{j=1}^n {P}_{i,j}}$ ;$\triangleright$ normalize w.r.t.$\mathbf{v}$
$\qquad{P}_{i,j} = \frac{{P}_{i,j}^{\prime}u_j}{\sum_{i=1}^m {P}_{i,j}^{\prime}}$ ;$\triangleright$ normalize w.r.t.$\mathbf{u}$
$\quad$ until convergence.
We discover that the Sinkhorn algorithm can generalize to multiple sets of marginals.
Recall that
It assumes the existence of a normalized
The algorithm steps are:
Initialize
In our paper, we prove that the Sinkhorn algorithm for multi-set marginals shares the same convergence pattern with the classic Sinkhorn, and its underlying formulation is also similar to the classic Sinkhorn.
Then we show how to transform the positive linear constraints into marginals, which are handled by our proposed multi-set Sinkhorn.
For an linsat_layer), the following matrix
is built
where
The score matrix
-
Packing constraint
$\mathbf{A}\mathbf{x}\leq \mathbf{b}$ . Assuming that there is only one constraint, we rewrite the constraint as$$\sum_{i=1}^l a_ix_i \leq b.$$ Following the "transportation" view of Sinkhorn, the output$\mathbf{x}$ moves at most$b$ unit of mass from$a_1, a_2, \cdots, a_l$ , and the dummy dimension allows the inequality by moving mass from the dummy dimension. It is also ensured that the sum of$\mathbf{u}_p$ equals the sum of$\mathbf{v}_p$ . The marginal distributions are defined as
-
Covering constraint
$\mathbf{C}\mathbf{x}\geq \mathbf{d}$ . Assuming that there is only one constraint, we rewrite the constraint as$$\sum_{i=1}^l c_ix_i\geq d.$$ We introduce the multiplier$$\gamma=\left\lfloor\sum_{i=1}^lc_i / d \right\rfloor$$ because we always have$$\sum_{i=1}^l c_i \geq d$$ (else the constraint is infeasible), and we cannot reach the feasible solution where all elements in$\mathbf{x}$ are 1s without this multiplier. Our formulation ensures that at least$d$ unit of mass is moved from$c_1, c_2, \cdots, c_l$ by$\mathbf{x}$ , thus representing the covering constraint of "greater than". It is also ensured that the sum of$\mathbf{u}_c$ equals the sum of$\mathbf{v}_c$ . The marginal distributions are defined as
-
Equality constraint
$\mathbf{E}\mathbf{x}= \mathbf{f}$ . Representing the equality constraint is more straightforward. Assuming that there is only one constraint, we rewrite the constraint as$$\sum_{i=1}^l e_ix_i= f.$$ The output$\mathbf{x}$ moves$e_1, e_2, \cdots, e_l$ to$f$ , and we need no dummy element in$\mathbf{u}_e$ because it is an equality constraint. It is also ensured that the sum of$\mathbf{u}_e$ equals the sum of$\mathbf{v}_e$ . The marginal distributions are defined as
After encoding all constraints and stacking them as multiple sets of marginals, we can call the Sinkhorn algorithm for multi-set marginals to enforce the constraints.
The Traveling Salesman Problem (TSP) is a classic NP-hard problem. The standard TSP aims at finding a cycle visiting all cities with minimal length, and developing neural solvers for TSP receives increasing interests. Beyond standard TSP, here we develop a neural solver for TSP with extra constraints using LinSAT layer.
Contributing author: Yunhao Zhang
To run the TSP experiment, please follow the code and instructions in
TSP_exp/.
Standard graph matching (GM) assumes an outlier-free setting namely bijective mapping. One-shot GM neural networks (Wang et al., 2022) effectively enforce the satisfiability of one-to-one matching constraint by single-set Sinkhorn. Partial GM refers to the realistic case with outliers on both sides so that only a partial set of nodes are matched. There lacks a principled approach to enforce matching constraints for partial GM. The main challenge for existing GM networks is that they cannot discard outliers because the single-set Sinkhorn is outlier-agnostic and tends to match as many nodes as possible. The only exception is BBGM (Rolinek et al., 2020) which incorporates a traditional solver that can reject outliers, yet its performance still has room for improvement.
Contributing author: Ziao Guo
To run the GM experiment, please follow the code and instructions in ThinkMatch/LinSAT.
Predictive portfolio allocation is the process of selecting the best asset allocation based on predictions of future financial markets. The goal is to design an allocation plan to best trade-off between the return and the potential risk (i.e. the volatility). In an allocation plan, each asset is assigned a non-negative weight and all weights should sum to 1. Existing learning-based methods (Zhang et al., 2020), (Butler et al., 2021) only consider the sum-to-one constraint without introducing personal preference or expert knowledge. In contrast, we achieve such flexibility for the target portfolio via positive linear constraints: a mix of covering and equality constraints, which is widely considered for its real-world demand.
Contributing author: Tianyi Chen
To run the portfolio experiment, please follow the code and instructions in
portfolio_exp/.
If you find our paper/code useful in your research, please cite
@inproceedings{WangICML23,
title={{LinSATNet}: The Positive Linear Satisfiability Neural Networks},
author={Wang, Runzhong and Zhang, Yunhao and Guo, Ziao and Chen, Tianyi and Yang, Xiaokang and Yan, Junchi},
booktitle={International Conference on Machine Learning (ICML)},
year={2023}
}