A simple script to find open Amazon AWS S3 buckets in your target websites. S3 buckets are a popular way of storing static contents among web developers. Often, developers tend to set the bucket permissions insecurely during development, and forget to set them correctly in prod, leading to (security) issues.
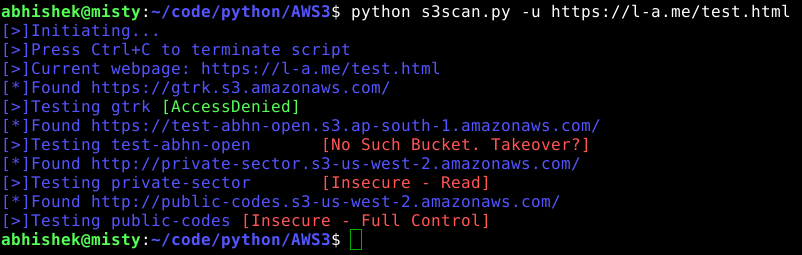
- Searching for insecure S3 buckets in a target website during reconnaissance stage.
- Differentiating between publicly unavailable, secured, read only, read + write and full access buckets
- Automated crawling and searching for Bucket URLs in website's page source.
No worries if you don't have them. You'll install them in 'Installation' section anyway.
- Python
- Pip
- BeautifulSoup
- Boto3
- AWS account for access and secret token
Install Python Pip using your OS's package manager
pip2 install beautifulsoup boto3
git clone https://github.com/abhn/S3Scan.git
cd S3Scan
If you already have awscli installed and configured, you should have the necessary tokens with you. If not, follow the steps.
Login to your AWS panel and generate your ACCESS_KEY and SECRET_KEY. Although fairly straightforward, if you are lost, here is a guide. Now you can either add them to your .bashrc (recommended), or add them to the script itself (not recommended).
To add the credentials to your .bashrc,
echo export AWS_ACCESS_KEY_ID="API7IQGDJ4G26S3VWYIZ" >> ~/.bashrc
echo export AWS_SECRET_ACCESS_KEY="jfur8d6djePf5s5fk62P5s3I6q3pvxsheysnehs" >> ~/.bashrc
source ~/.bashrc
Done!
Usage: $ python ./s3scan.py [-u] url
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-u URL, --url=URL url to scan
-d turn on debug messages
MIT