Training spec
jisngprk opened this issue · 2 comments
jisngprk commented
I have question about training spec of your model. I want to know about sequence length, batch size, training time, GPU type, # of GPU, # of training samples, and loss
You looks like acquire 3.7 loss. Could you describe the parameter of training to acquire those performance?
Line 93 in 71ebf91
Are these parameters used to get the loss ?
affjljoo3581 commented
I'm sorry but I cannot remember the detailed training configurations for the example loss figure described in README:
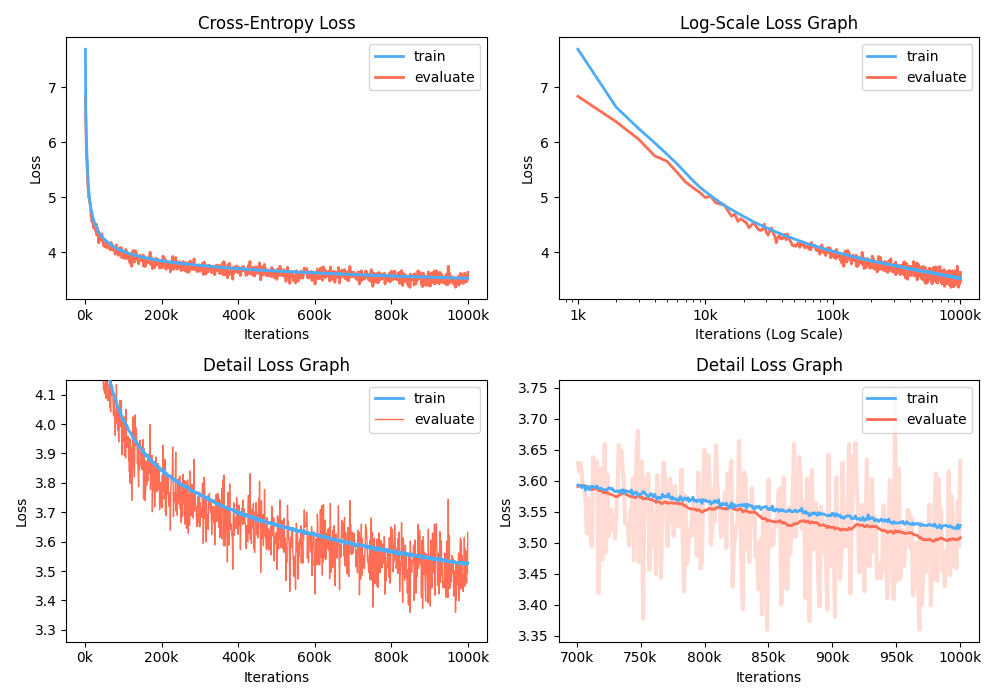
But I can share the other training result with its configurations. It should be helpful!
Dataset
- I constructed a custom Korean dataset collected from several platforms. The total size of the raw text file is about 30GB and it contains about 5.04B tokens.
- The vocabulary size is 32000 and
unk-ratiois 0.00005. - The number of tokens in each sequence is less than 512. (
seq_len = 512)
Model
- The model consists of 24 transformer-encoder layers and the dimensionality of hidden units is 1024. The total parameter size is 304M.
Environment
- The model was trained for 8 epochs, on 2 x Tesla V100 GPUs.
- The entire training spent about 24 days.
Result
- test loss: 3.2398
- test perplexity: 25.5819
jisngprk commented
Thank you!