an in-memory immutable data manager
![]()




Vineyard (v6d) is an innovative in-memory immutable data manager that offers out-of-the-box high-level abstractions and zero-copy in-memory sharing for distributed data in various big data tasks, such as graph analytics (e.g., GraphScope), numerical computing (e.g., Mars), and machine learning.

Vineyard is a CNCF sandbox project and indeed made successful by its community.
- Overview
- Features of vineyard
- Getting started with Vineyard
- Deploying on Kubernetes
- Frequently asked questions
- Getting involved in our community
- Third-party dependencies
Vineyard is specifically designed to facilitate zero-copy data sharing among big data systems. To illustrate this, let's consider a typical machine learning task of time series prediction with LSTM. This task can be broken down into several steps:
- First, we read the data from the file system as a
pandas.DataFrame. - Next, we apply various preprocessing tasks, such as eliminating null values, to the dataframe.
- Once the data is preprocessed, we define the model and train it on the processed dataframe using PyTorch.
- Finally, we evaluate the performance of the model.
In a single-machine environment, pandas and PyTorch, despite being two distinct systems designed for different tasks, can efficiently share data with minimal overhead. This is achieved through an end-to-end process within a single Python script.
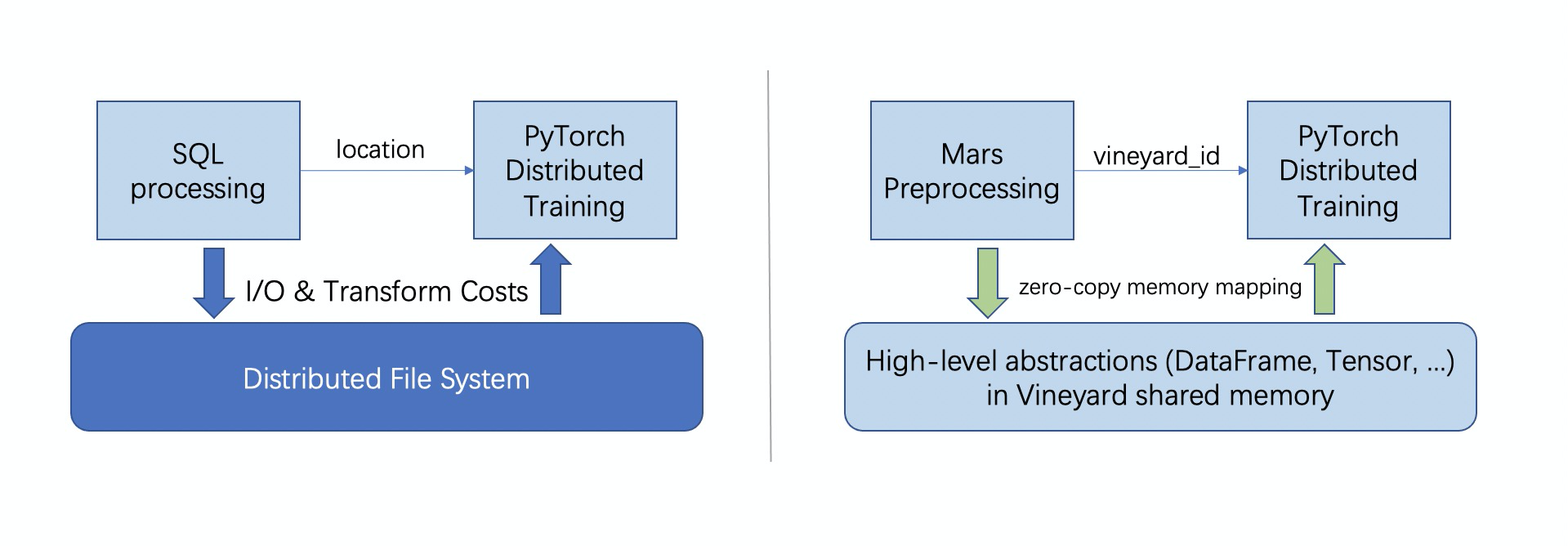
What if the input data is too large to be processed on a single machine?
As depicted on the left side of the figure, a common approach is to store the data as tables in
a distributed file system (e.g., HDFS) and replace pandas with ETL processes using SQL over a
big data system such as Hive and Spark. To share the data with PyTorch, the intermediate results are
typically saved back as tables on HDFS. However, this can introduce challenges for developers.
- For the same task, users must program for multiple systems (SQL & Python).
- Data can be polymorphic. Non-relational data, such as tensors, dataframes, and graphs/networks (in GraphScope) are becoming increasingly common. Tables and SQL may not be the most efficient way to store, exchange, or process them. Transforming the data from/to "tables" between different systems can result in significant overhead.
- Saving/loading the data to/from external storage incurs substantial memory-copies and IO costs.
Vineyard addresses these issues by providing:
- In-memory distributed data sharing in a zero-copy fashion to avoid introducing additional I/O costs by leveraging a shared memory manager derived from plasma.
- Built-in out-of-the-box high-level abstractions to share distributed data with complex structures (e.g., distributed graphs) with minimal extra development cost, while eliminating transformation costs.
As depicted on the right side of the above figure, we demonstrate how to integrate vineyard to address the task in a big data context.
First, we utilize Mars (a tensor-based unified framework for large-scale data computation that scales Numpy, Pandas, and Scikit-learn) to preprocess the raw data, similar to the single-machine solution, and store the preprocessed dataframe in vineyard.
| single | data_csv = pd.read_csv('./data.csv', usecols=[1]) |
| distributed | import mars.dataframe as md
dataset = md.read_csv('hdfs://server/data_full', usecols=[1])
# after preprocessing, save the dataset to vineyard
vineyard_distributed_tensor_id = dataset.to_vineyard() |
Then, we modify the training phase to get the preprocessed data from vineyard. Here vineyard makes the sharing of distributed data between Mars and PyTorch just like a local variable in the single machine solution.
| single | data_X, data_Y = create_dataset(dataset) |
| distributed | client = vineyard.connect(vineyard_ipc_socket)
dataset = client.get(vineyard_distributed_tensor_id).local_partition()
data_X, data_Y = create_dataset(dataset) |
Finally, we execute the training phase in a distributed manner across the cluster.
From this example, it is evident that with vineyard, the task in the big data context can be addressed with only minor adjustments to the single-machine solution. Compared to existing approaches, vineyard effectively eliminates I/O and transformation overheads.
Vineyard serves as an in-memory immutable data manager, enabling efficient data sharing across different systems via shared memory without additional overheads. By eliminating serialization/deserialization and IO costs during data exchange between systems, Vineyard significantly improves performance.
Computation frameworks often have their own data abstractions for high-level concepts. For example, tensors can be represented as torch.tensor, tf.Tensor, mxnet.ndarray, etc. Moreover, every graph processing engine has its unique graph structure representation.
The diversity of data abstractions complicates data sharing. Vineyard addresses this issue by providing out-of-the-box high-level data abstractions over in-memory blobs, using hierarchical metadata to describe objects. Various computation systems can leverage these built-in high-level data abstractions to exchange data with other systems in a computation pipeline concisely and efficiently.
A computation doesn't need to wait for all preceding results to arrive before starting its work. Vineyard provides a stream as a special kind of immutable data for pipelining scenarios. The preceding job can write immutable data chunk by chunk to Vineyard while maintaining data structure semantics. The successor job reads shared-memory chunks from Vineyard's stream without extra copy costs and triggers its work. This overlapping reduces the overall processing time and memory consumption.
Many big data analytical tasks involve numerous boilerplate routines that are unrelated to the computation itself, such as various IO adapters, data partition strategies, and migration jobs. Since data structure abstractions usually differ between systems, these routines cannot be easily reused.
Vineyard provides common manipulation routines for immutable data as drivers. In addition to sharing high-level data abstractions, Vineyard extends the capability of data structures with drivers, enabling out-of-the-box reusable routines for the boilerplate parts in computation jobs.
Vineyard is available as a python package and can be effortlessly installed using pip:
pip3 install vineyardFor comprehensive and up-to-date documentation, please visit https://v6d.io.
If you wish to build vineyard from source, please consult the Installation guide. For instructions on building and running unittests locally, refer to the Contributing section.
After installation, you can initiate a vineyard instance using the following command:
python3 -m vineyardFor further details on connecting to a locally deployed vineyard instance, please explore the Getting Started guide.
Vineyard is designed to efficiently share immutable data between different workloads, making it a natural fit for cloud-native computing. By embracing cloud-native big data processing and Kubernetes, Vineyard enables efficient distributed data sharing in cloud-native environments while leveraging the scaling and scheduling capabilities of Kubernetes.
To effectively manage all components of Vineyard within a Kubernetes cluster, we have developed the Vineyard Operator. For more information, please refer to the Vineyard Operator documentation.
Vineyard shares many similarities with other open-source projects, yet it also has distinct features. We often receive the following questions about Vineyard:
Q: Can clients access the data while the stream is being filled?
Sharing one piece of data among multiple clients is a target scenario for Vineyard, as the data stored in Vineyard is immutable. Multiple clients can safely consume the same piece of data through memory sharing, without incurring extra costs or additional memory usage from copying data back and forth.
Q: How does Vineyard avoid serialization/deserialization between systems in different languages?
Vineyard provides high-level data abstractions (e.g., ndarrays, dataframes) that can be naturally shared between different processes, eliminating the need for serialization and deserialization between systems in different languages.
. . . . . .
For more detailed information, please refer to our FAQ page.
- Join the CNCF Slack and participate in the
#vineyardchannel for discussions and collaboration. - Familiarize yourself with our contribution guide to understand the process of contributing to vineyard.
- If you encounter any bugs or issues, please report them by submitting a GitHub issue or engage in a conversation on Github discussion.
- We welcome and appreciate your contributions! Submit them using pull requests.
Thank you in advance for your valuable contributions to vineyard!
- Wenyuan Yu, Tao He, Lei Wang, Ke Meng, Ye Cao, Diwen Zhu, Sanhong Li, Jingren Zhou.
Vineyard: Optimizing Data Sharing in Data-Intensive Analytics.
ACM SIG Conference on Management of Data (SIGMOD), industry, 2023.
.
If you use this software, please cite our paper using the following metadata:
@article{yu2023vineyard,
author = {Yu, Wenyuan and He, Tao and Wang, Lei and Meng, Ke and Cao, Ye and Zhu, Diwen and Li, Sanhong and Zhou, Jingren},
title = {Vineyard: Optimizing Data Sharing in Data-Intensive Analytics},
year = {2023},
issue_date = {June 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {1},
number = {2},
url = {https://doi.org/10.1145/3589780},
doi = {10.1145/3589780},
journal = {Proc. ACM Manag. Data},
month = {jun},
articleno = {200},
numpages = {27},
keywords = {data sharing, in-memory object store}
}We thank the following excellent open-source projects:
- apache-arrow, a cross-language development platform for in-memory analytics.
- boost-leaf, a C++ lightweight error augmentation framework.
- cityhash, CityHash, a family of hash functions for strings.
- dlmalloc, Doug Lea's memory allocator.
- etcd-cpp-apiv3, a C++ API for etcd's v3 client API.
- flat_hash_map, an efficient hashmap implementation.
- gulrak/filesystem, an implementation of C++17 std::filesystem.
- libcuckoo, libcuckoo, a high-performance, concurrent hash table.
- mimalloc, a general purpose allocator with excellent performance characteristics.
- nlohmann/json, a json library for modern c++.
- pybind11, a library for seamless operability between C++11 and Python.
- s3fs, a library provide a convenient Python filesystem interface for S3.
- skywalking-infra-e2e A generation End-to-End Testing framework.
- skywalking-swck A kubernetes operator for the Apache Skywalking.
- wyhash, C++ wrapper around wyhash and wyrand.
- rax, an ANSI C radix tree implementation.
- MurmurHash3, a fast non-cryptographic hash function.
Vineyard is distributed under Apache License 2.0. Please note that third-party libraries may not have the same license as vineyard.
