Day 4 scale 之 fit_transform & transform
Closed this issue · 7 comments
想請問在 Day4 scaling 的部分為什麼 X_train 採 fit_transform, X_test 採transform,而非兩者都採 fit_transform
@Ericostco 間單來說我們針對訓練集的資料進行縮放,假設用 minmaxscaler 呼叫 fit_transform 會針對 X_train 的最小值最大值記錄起來接著進行 scaling。接著我們要對測試集 X_test 縮放的時候直接transform,此時會針對 training set 的 min max 為基準進行縮放哦。因為在呼叫 fit_transform 時會將資料集的縮放資訊儲存到 scaler 中。
在 Scikit-learn 中,scaler 是用於特徵縮放的一種工具,可以將特徵數據轉換成具有特定特性或範圍的形式。這裡針對 scaler 中的 fit_transform 和 transform 兩個方法進行說明:
- fit_transform 方法:
- fit_transform 方法結合了兩個步驟:fit(擬合)和 transform(轉換)。
在進行數據轉換之前,首先需要對 Scaler 進行擬合。這意味著 Scaler 會計算訓練數據的統計量(例如min和max),並在後續的轉換中使用這些統計量。 - 這個方法通常在訓練數據上使用,因為它同時完成了擬合和轉換,並且可以根據訓練數據的統計特性來進行轉換。
- transform 方法:
- transform 方法僅進行數據轉換,而不進行擬合過程。
- 在使用 transform 方法之前,必須先對 Scaler 進行擬合,通常使用 fit 方法來完成這一步。
- transform 方法接受一個數據集作為輸入,然後根據先前對 Scaler 進行擬合時計算的統計量進行轉換。
- 這個方法通常在測試數據或其他新數據上使用,因為在之前的擬合過程中已經得到了 Scaler 的統計特性,所以可以直接使用 transform 方法來對新數據進行相同的特徵縮放轉換,確保與訓練數據具有相同的特性。
詳細內容可以參考這篇文章的第五點哦!
[Day 27] 機器學習常犯錯的十件事: https://ithelp.ithome.com.tw/articles/10279778
@andy6804tw 感謝回覆,大致上了解fit_transform及transform的差異,fit_transform 會先對儲存資料集的數據統計(擬合)並根據此進行轉換,而transform則單純根據此進行轉換。
現在我有一個新的疑惑,若今天要對 input features 進行OrdinalEncoder,而該input features有過多的categories,可能會導致測試數據在transform時會遇到一個以上未知的種類。然而,在OrdinalEncoder的parameters中似乎只能設定一個unknown_value,這樣測試數據在transform時會導致不同的categories給予相同的編碼。
我想在實務上應該會盡量避免此情況,想請問通常做法會是比較偏向哪種做法
- 先將資料集編碼後再切割?
- 盡量讓資料集每個種類都在fit_transform進行編碼?但可能遇到新的資料也會有上述狀況
- 更換其他的編碼方式等?
感謝 @andy6804tw 撥空閱讀
@Ericostco Hi
建議該項類別的特徵在訓練一個機器學習模型時候就必須盡可能把所有會出現的種類都依序標記上去。因此先將資料集編碼後再切割以及盡量讓資料集每個種類都在fit_transform進行編碼是必須做的。只有這樣做才能確保當下模型是看過最豐富的標籤種類。
不過確實模型上線後可能又會有新的標籤出現。就以 MLOps 來說我建議新的資料或標籤蒐集到一定程度再進行模型重新訓練(retrain)的步驟。AI模型訓練是仰賴大數據,因此當沒看過的資料或標籤種類沒看過模型會有越來越不準的問題。因此對於軟體開發週期來說,模型定期 retrain 更新是蠻重要的議題。
提供一個關鍵字讓您參考=>概念漂移 (Concept drift)
@andy6804tw Hello
想請問先將資料集編碼後再切割不是會造成資料洩漏嗎?
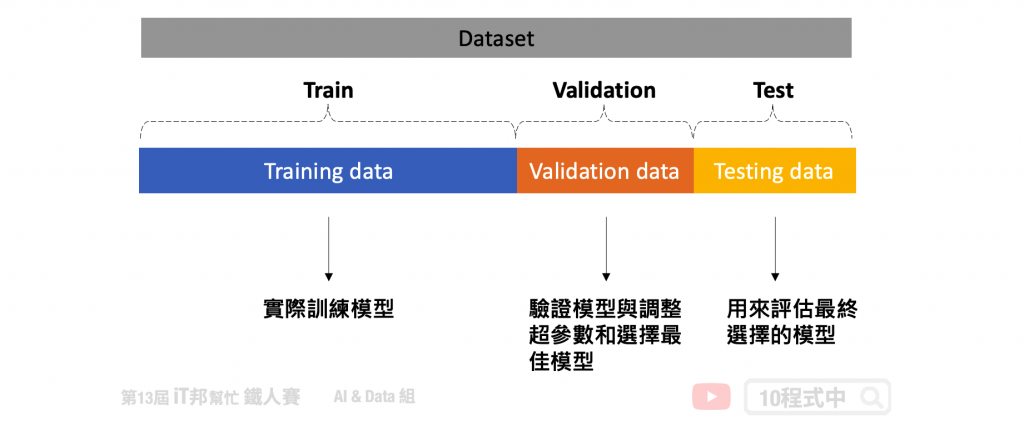
文中第五點是針對資料正規化分布有洩漏的問題,假設train資料集A特徵的分佈10~100,我們同時也預期 val/test 也會落於這區間內,所以我們希望模型訓練的資料是足夠豐富多樣的上下界分布很明確。而類別的特徵理當而言預期蒐集完一個資料集我們會希望他是最足夠豐富每個特徵盡可能地涵蓋現實生活中會遇到的數值(分佈)或類別(標籤)。通常實務上很難接受一筆新的資料裡面的類別特徵的標籤是在訓練沒看過的,因為我們無法預期AI會輸出什麼東西(不可控),假設不確定因素很高,這時候就要回過頭評估該特徵是否真的是關鍵因子(可透過XAI分析重要程度),影響度低可以試著將該特徵移除或是做其他的特徵工程。一個完整的資料科學步驟會先將收集的資料集整包進行離群值清理、特徵編碼、缺失值處理。我自己是習慣先處理好標籤確保收集的資料足夠豐富盡可能都遇到了,接著切 train、validation 此時要確保兩邊的資料集都有按照比例平均分配到標籤。這時候的 validation 屬於訓練階段模型不會看過也不會拿來學習,目的是要觀察是否已經收斂並評估是否過擬合/欠擬合用。
模型都訓練完後,我會再另外搜集另一個測試用的資料。做最後的模型驗證。若資料集取得不易也可以一個dataset切三等份,若切下去會太少或有豐富度降低問題,折衷辦法就只有 train/test。簡而言之,若有遇到新的沒看過的標籤就應當儲存起來等到足夠多時就在重新啟動retrain機制。
以上是我的觀點與建議提供參考!
@andy6804tw 真的很感謝你這麼用心回覆,讓我釐清不少機器學習實務上的疑惑!
@Ericostco 不客氣!另外今年我有出新的主題(XAI)哦,有興趣可以繼續學習