各种窗口函数的使用
Opened this issue · 0 comments
astak16 commented
create table employee(
id int,
month int,
salary int
);
insert into employee values
(1, 1, 20),
(2, 1, 20),
(1, 2, 30),
(2, 2, 30),
(3, 2, 40),
(1, 3, 40),
(3, 3, 60),
(1, 4, 60),
(3, 4, 70),
(1, 7, 90),
(1, 8, 90);序号函数
序号函数有:row_number()、 rank()、 dense_rank()
具体的使用方法看:序号函数的使用
偏移量函数
偏移量函数是从窗口的首行或者末行开始偏移 n 行
lead()
当前分组内,当前行向下偏移,语法 lead(expr, n, default)
expr:可以是列名或者表达式n:当前行下第n行的值,可选,默认为1default:当前后没有n行的值,可选,默认为null
比如 id = 1, month = 1, lead_salary = 40 ,它的 lead_salary = 40 是 id = 1, month = 3 的 salary
SELECT
id,
MONTH,
salary,
lead( salary, 2 , 0) over ( PARTITION BY id ORDER BY `month` ) lead_salary
FROM
employee;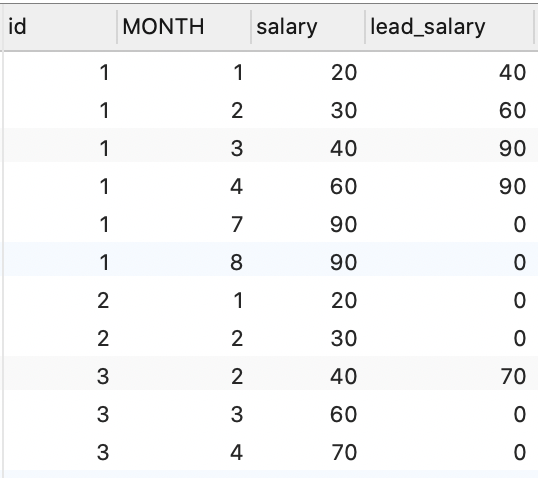
lag()
当前分组内,当前行向上偏移,语法 lag(expr, n, default)
用法和 lead 一样
SELECT
id,
MONTH,
salary,
lag( salary, 2 , 0) over ( PARTITION BY id ORDER BY `month` ) lag_salary
FROM
employee;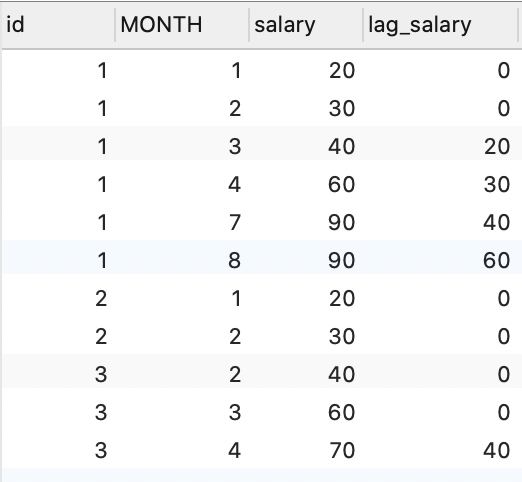
分布函数
分布函数的返回值是 0 ~ 1 之间的数
percent_rank()
当前 序号 - 1占 总行数 - 1 的比例: rank() - 1 / total_row() - 1
分子是 rank() ,所以序号可能会重复
SELECT
*,
rank() over ( PARTITION BY id ORDER BY `month` ) as rk,
percent_rank() over ( PARTITION BY id ORDER BY `month` ) as p_rk
FROM
employee;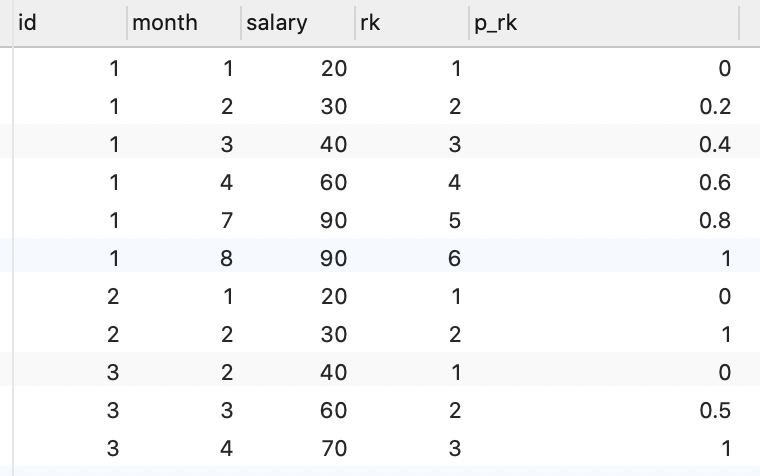
cume_dist()
当前 序号占 总行数 的比例: rank() / total_row()
分子也是 rank() ,所以序号可能会重复
SELECT
*,
rank() over ( PARTITION BY id ORDER BY `month` ) AS rk,
cume_dist() over ( PARTITION BY id ORDER BY `month` ) AS c_rk
FROM
employee;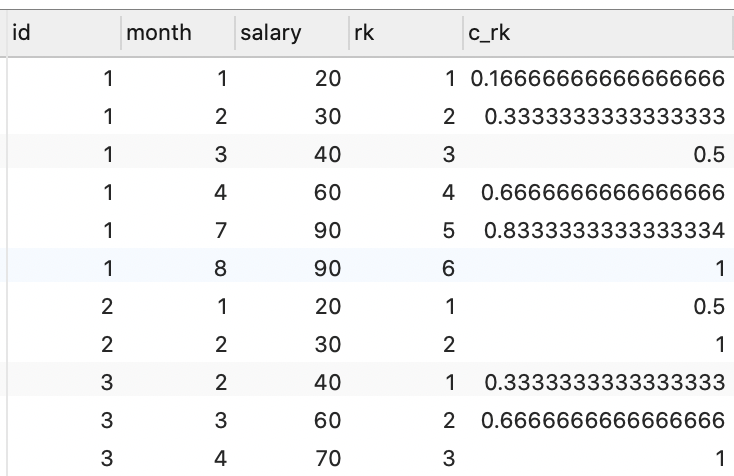
其他函数
first_value()
当前分组总第一个值,不受 order by 影响
SELECT
*,
first_value(salary) over ( PARTITION BY id ORDER BY `month`) AS first_val
FROM
employee;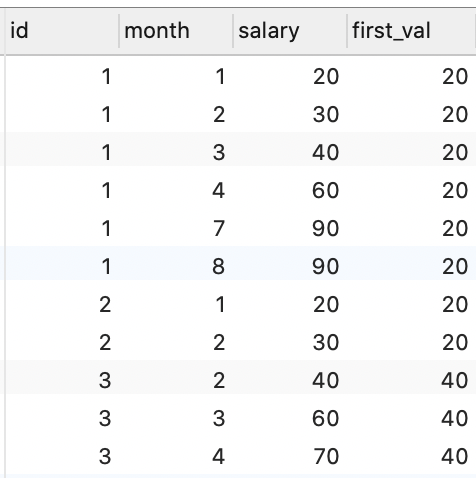
last_value()
和 fitst_value() 有区别, last_value() 并不是当前分组的最后一个值,会收 order by 影响
SELECT
*,
last_value(salary) over ( PARTITION BY id ORDER BY `month`) AS last_val
FROM
employee;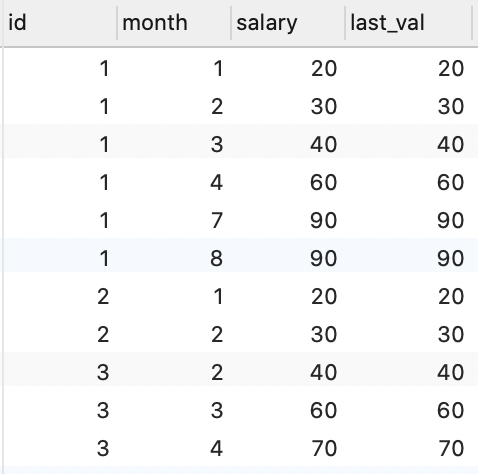
nth_value()
当前分组内,第 n 的值,小于 n 的值,为 null
SELECT
*,
nth_value(salary, 2) over ( PARTITION BY id ORDER BY `month`) AS nth_val
FROM
employee;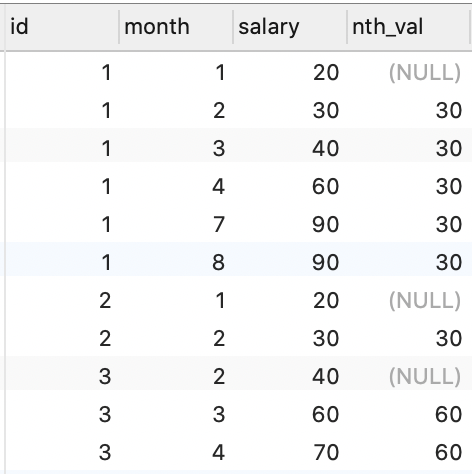
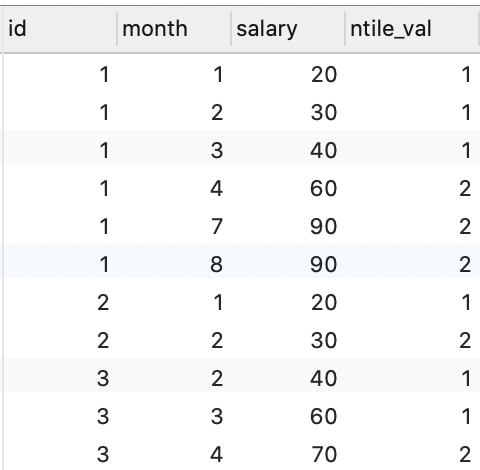
ntile()
当前分组内,分成 n 组,从小到开始,直到分完,分组内总条数不一定被 n 整除,所以不一定平均分配。
SELECT
*,
ntile(2) over ( PARTITION BY id ORDER BY `month`) AS ntile_val
FROM
employee;