-
Definition
- Memory allocation refers to the process by which the program makes space for the storage data.
- When declare a variable of a type, enough memory is allocation locally to store data of that type. The allocation is local, occurring within the scope of the function, and when that function returns the memory is deallocated.
- When program finishes, memory is deallocated and merge to main memory or use by another program.
-
Some type of Memory Allocation:
- Static Memory Allocation: Memory is allocated at compile time.
- Dynamic Memory Allocation: Memory is allocated at execute time.
-
Local Memory Allocation on the Stack
int a = 10;-
The declaration of the integer a will allocate memory for the storage for an integer (4-bytes). We refer to the data stored in memory via the variable a.
-
Local Memory Allocationrefers to the process by which the program makes "space" for the storage of data. When you declare a variable of a type, enough memory is allocation locally to store data of that type. The allocation is local, occurring within the scope of the function, and when that function returns the memory is deallocated
int * plus(int a, int b) {
int c = a + b;
return &c;
}
int main(int argc, char * argv[]) {
int *ptr= plus(1, 2);
printf("%d\n", * p);
}-
In above example, What's the problem? The memory of c is deallocated once the function returns, and now p is referencing a memory address which is unallocated. The print statement, which deferences p, following the pointer to the memory address, may fail.
-
Another term for local memory allocation is
stack allocationbecause the way programs track execution across functions is based on a stack. -
Each function is contained within a structure on the stack called a stack frame. A stack frame contains all the allocated memory from variable deliberations as well as a pointer to the execution point of the calling function, the so called return pointer. A very common exploit in computer security is a buffer overflow attack where an attacker overwrite the return pointer such that when the function returns, code chosen by the attacker is executed.
int get_two(){
return 2;
}
int get_one(){
return 1;
}
int add_one_two(){
int one = get_one();
int two = get_two();
return one+two;
}
int main(){
int a = add_one_two();
}- Global Memoy Allocation on the Heap
- The sample program with
plus()from the previous section doesn't work properly when returning a memory reference, it does not mean you cannot write functions that return a memory reference.
Node* node = new Node();-
The local variable declaration is for the variable node, but that's just a pointer to some memory. The variable node is declared on the stack and has enough memory to store a memory address.
-
The value of that memory address is set by the return of the call new Node(). The new function will automatically allocate enough memory to store a Node structure and the node variable now references that memory. Of course, the memory cannot have been allocated on the stack, this memory must have been allocated somewhere else, the
newfunction performs a dynamic memory allocate on the heap. -
The deallocation function is free() (equivalent to delete in C++), which takes a pointer value as input and "frees" the referenced memory on the heap.
-
Memory Leaks
- In C (and C++), the programer is responsible for memory management, which includes both the allocation and deallocation of memory. As a result, there are many mistakes that can be made, which is natural considering that all programers make mistakes. Perhaps the most common mistake is a memory leak, where heap allocated memory is not freed.
-
Program Layout: Stack vs. Heap
2^64-1---> .----------------------.
High Addresses | Enviroment |
|----------------------|
| | Functions and variable are declared
| STACK | on the stack.
base pointer -> | - - - - - - - - - - -|
| | |
| v |
: :
. . The stack grows down into unused space
. Empty . while the heap grows up.
. .
. . (other memory maps do occur here, such
. . as dynamic libraries, and different memory
: : allocat)
| ^ |
| | |
break point -> | - - - - - - - - - - -| Dynamic memory is declared on the heap
| HEAP |
| |
|----------------------|
| BSS | The compiled binary code is down here as
|----------------------| well as static and initialzed data
| Data |
|----------------------|
Low Addresses | Text |
0 -----> '----------------------'
- At the higher addresses is the stack and the lower address is the heap. The two memory allocation regions grow into the middle of the address space, which is unused and unallocated.
- In this way, the two allocations will not interfere with each other.
- Stack
base pointerpoint to the top of stack, when function call or return, it will shift appropriately. - The
break pointrefers to the top of the programs data segment, which contains the heap. As the heap fills up, requirement more space, the break is set to higher addresses.
-
Between the break point and the base pointer is unallocated memory, but it may not be unused. This region can be memory mapped, which is the process of loading data directly from files into memory. You can directly memory map files, but often this is done automatically for you when you read and write files.
-
Another common use for the middle addresses is the loading of dynamic shared libraries. When you make a call to a function like printf() or malloc(), the code for those functions exist in shared libraries, the standard C library, to be precise. Your program must run that code, but the operating system doesn't want to have load more code into memory than needed. Instead, the O.S. loads shared libraries dynamically, and when it does so, it maps the necessary code into the middle address spaces.
- Quick overview of key-value stores
- Some method:
- get(key): get some data previously saved under the identifier "key", or fail if no data was stored for "key"
- set(key, value): store the "value" in memory under the identifier "key", so we can access it later referencing the same "key". If some data was already present under the "key", this data will be replaced.
- remove(key): Delete the data that was stored under the "key"
- exist(key): Check the "key" already stored or not.
- Underlying implementations using B-Trees. Sometimes, the data is too big to fit in memory, or the data must be persisted in case the system crashes for any reason.
- Implement key-value stores
- Programming language: C/C++
- Algorithmics and data structures: BTree
- Memory management
- Concurrency control with multi-processors or multi-threading
- Networking with a server/client model
- I/O problems with disk access and use of the file system
- Producer - Consumer problems
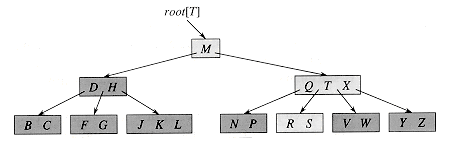
- Structure:
- BTree has some important fields like:
- next_pos: mean next position in file, new node created will be here.
- root_pos: mean that position belong to root node.
- degree: the goal of a b-tree is to minimize the number of disk accesses. degree depends upon disk block size
- BTreeNode:
- child: list of BTreeNode contains child of current node
- num: number of key store in node, number of child equal num plus one
- child_pos: very important field, this array contains the position of child node in file
- pos: position of current node
- leaf: identify node was leaf or not
- BTree has some important fields like:
- On POSIX systems, in blocking mode
recvwill only block until some data is present to be read. - Call
recvin non-blocking mode will return any data that the system has in it's read buffer for that socket. But, it don't wait for the data. - Non-blocking sockets can also be used in conjunction with the select() API. In fact, if you reach a point where you actually WANT to wait for data on a socket that was previously marked as "non-blocking", you could simulate a blocking recv() just by calling select() first, followed by recv().
- Thread pool contain a queue, this queue contains some task, task was added by method add_task(), when server handle client request, it process request, get data from request, and type of task, then create Task object and pass it through add_task().
- Thread pool fields:
- m_pool_size: how many thread available inside pool
- m_task_mutex: use to lock when add some task into task queue
- m_task_cond_var: use to notify thread in thread pool, have some task available in task queue.
- m_threads: a vector contains m_pool_size thread, use to release thread pointer when shutdown server.
- m_pool_state: thread pool status, use to notify any thread running that server will shutdown and don't process any task.
- Using pthread_mutex
- Define class call Mutex, it contain:
- m_lock: the mutex instance
- is_locked: use to identify lock or not
- Problems: In the same time system allow multi-process can read database. But when write to database only one process can write and no one can read or write in this time.
- Using a variable call rc, and init rc = 0, two Mutex: m_db_mutex, m_rc_mutex
void Server::get_func(void *arg) {
m_rc_mutex.lock(); // doc quyen truy xuat bien rc
rc++;
if (rc == 1) { // tien trinh doc dau tien => khong cho ghi
m_db_mutex.lock();
}
m_rc_mutex.unlock();
// read database
VALUE result = store->get(data->key);
// end read database
m_rc_mutex.lock(); // doc quyen truy xuat
rc--; // giam tien trinh doc
if (rc == 0) { // tien trinh doc cuoi cung
m_db_mutex.unlock();
}
m_rc_mutex.unlock();
}
void Server::set_func(void *arg) {
m_db_mutex.lock();
store->set(data->key, data->value);
m_db_mutex.unlock();
}
-
Client
- Multiple Client open connection to connect to Server
- After connect successfuly, client enter command like: get(key), set(key,value), remove(key), exist(key)
- Data from client contain:
- key, value
- type: get, set, remove or exist
- sign: to identify valid package send to server
- Client serialize structured data with protobuf method. After that socket client will send this package to Server.
-
Server
- Server create some thread running for task. To manage thread, I'm created class call ThreadPool, it keep task queue, list threads, some lock, ...
- Server create socket call listener to listen any connection from client.
- when Socket open to accept connection, the file description was added to fd_set.
- Server using method call select() to detect data arrive from client
- When data arrived, using method recv() to get data, after that protobuf will Deserialize this package and get data.
- From data we will detect type in order to create suitable task. Task will be added to task queue. Any free thread in thread pool will access to task queue and do task.