ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models [website] [arxiv]
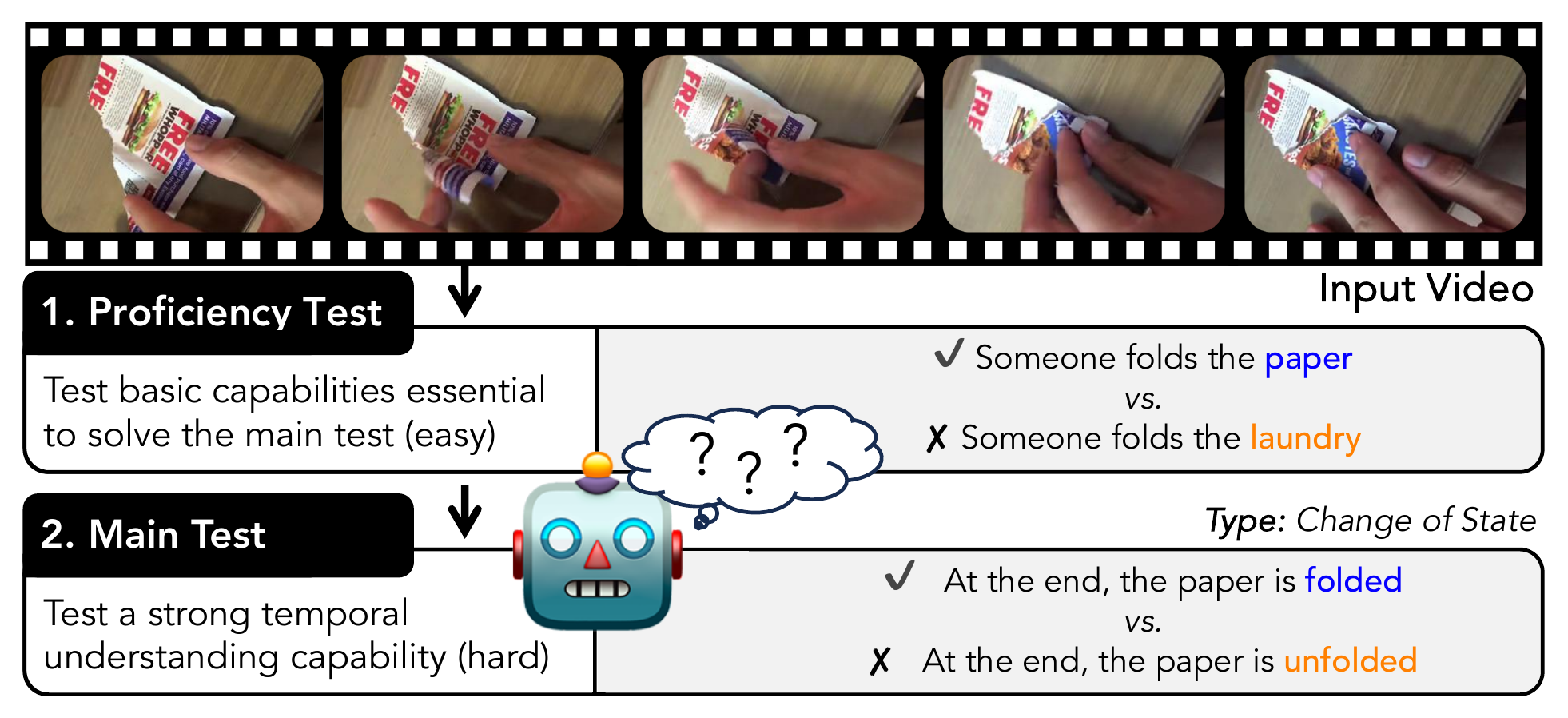
This repository contains all necessary information for the ViLMA benchmark, including data setup, model setup and execution, and evaluation procedures. ViLMA (Video Language Model Assessment) presents a comprehensive benchmark for Video-Language Models (VidLMs) to evaluate their linguistic and temporal grounding capabilities in five dimensions: action counting, situation awareness, change of state, rare actions and spatial relations. ViLMA also includes a two stage evaluation procedure as (i) proficiency test (P) that assesses fundamental capabilities deemed essential before solving the five tests, (ii) main test (T) which evaluates the model under the proposed five diverse tests, and (iii) a combined score of these two tasks (P+T).
Execute the following steps,
git clone git@github.com:ilkerkesen/vilma.git # clone this repo.
cd vilma
conda create -n vilma --file spec-file # create the environment.
pip install -e . # install the codebase as an editable package.Our benchmark is built upon several different video resources. In this section, we share the details on how to setup these data resources.
This dataset is required to run the experiments for the repetitive action counting task. Use this link to download the data. You can run the following command sequence to setup this data resource,
wget -c http://isis-data.science.uva.nl/tomrunia/QUVARepetitionDataset.tar.gz
tar -xvf QUVARepetitionDataset.tar.gz -C /path/to/extracted/
./bin/normalize_fps /path/to/quva/videos /path/to/quva/normalized_videos
python tasks/counting/normalize_annotations.py --data-dir /path/to/quvaThis snippet first downloads the data, extracts it to somewhere, then performs FPS normalization on the data. For more details check the counting documentation.
This dataset is required to run the experiments for the relation task. Follow the instruction reported to this link to download the data.
This dataset is required to run the experiments for the change-state task. Authors only provide the annotations and do not distribute the videos. We have selected a subset of the dataset annotations limiting ourselves to items for which videos are still available on YouTube (last checked 06.04.2023). Videos can be downloaded using this script.
This dataset is required to run the experiments for the change-state task. Authors only store the urls of videos and their annotations in JSON format. We have selected a subset of their annotations for which videos are still availble (last checked 06.04.2023). Videos can be downloaded using this script.
This dataset is required to run the experiments for the change-state task. Videos are provided by the original authors and can be downloaded in a single zipped file via the following link. The video names are the YouTube ids of the videos.
This dataset is required to run the experiments for the change-state task. Raw videos are not provided by the authors. We have selected a subset of their annotations for which videos are still availble (last checked 06.04.2023). Videos can be downloaded using this script.
This dataset is required to run the experiments for the Semantic Role Labelling task. Raw videos are not provided by the authors. We have selected a subset of their annotations for which videos are still availble (last checked 16.05.2023). Videos can be downloaded using this script.
We share the details of each model in a seperate documentation file under ./models/{modality}/ directory. We have implemented the following models so far,
Each adapted model produces a result annotation file which contains the predicted scores. We use a script to evaluate these result annotation files.
Here is a dummy results annotation file,
{
"0": {
"scores": [
0.9998931884765625,
0.9999251365661621
]
},
"1": {
"scores": [
0.9999557733535767,
0.999962568283081
]
}
}These JSON files are actually key/value stores where the keys are the example ids (same with the data annotations). Each value is a dict which has the scores key. The value of this scores key represent the scores for each text input for the corresponding example. The first value always belongs to the true caption score. The remaining values are the scores for the foils in the same order as in the data annotation file. Note that, these scores could be either perplexity values, similarity scores or video-text matching probabilities, and this completely depends on the model.
Please do run the ./bin/eval.py script to evaluate the models. It takes one argument which is the file path, and one option which specifies whether the model produces probabilities or scores (TODO: implement for the perplexity scores also as well). Here is an example,
python ./bin/eval.py /path/to/the/results/file.json --mode {similarity,probability,perplexity}Passing --mode probability option makes the script treat the scores as probabilities, and allows user to produce the scores for the accuracy, precision and AUROC metrics. Similarly, passing --mode perplexity forces script to work with perplexity values.
If you find ViLMA beneficial for your research, please cite it,
@misc{kesen2023vilma,
title={ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models},
author={Ilker Kesen and Andrea Pedrotti and Mustafa Dogan and Michele Cafagna and Emre Can Acikgoz and Letitia Parcalabescu and Iacer Calixto and Anette Frank and Albert Gatt and Aykut Erdem and Erkut Erdem},
year={2023},
eprint={2311.07022},
archivePrefix={arXiv},
primaryClass={cs.CL}
}