14_ARMv8_内存管理(二)-ARM的MMU设计
carloscn opened this issue · 0 comments
14_ARMv8_内存管理(二)-ARM的MMU设计
- 以ELF作为引子展开MMU的作用,为了和ELF做一些知识关联工作。[13_ARMv8_内存管理与MMU(一)-内存管理要素]
- 以《操作系统概念》的虚拟内存管理一节,为MMU做一些理论和基础知识的储备。[13_ARMv8_内存管理与MMU(一)-内存管理要素]
- 以《ARMv8体系架构》的MMU为例子,了解在CPU层级MMU的实现和配置。[13_ARMv8_内存管理与MMU(二) - ARMv8架构虚拟内存MMU]
- 以《Linux内核》的内存管理为例子,来研究MMU怎么实现的。[Linux_Kernel_MMU设计(一)]
1 页表结构
谈及页表结构,或者我们从互联网的资源上去查,就会有个误区,无论是现代大多数的处理器,或者linux内核里面,页表的结构设计是分层设计的,也就是多级页表(multiple-level page table),实际上并不是这样的,在不同的处理器上面也采用不同的页表充当内存管理的枢纽。这里我们引用操作系统概念内部提出的三种页表结构:分层页表(multiple-level page table),哈希页表(hashed page table)。

1.1 分层页表(multiple-level page table)
现代计算机系统多为32位或者64位(最大逻辑寻址空间2^32或者2^64),假设一个页面大小为4KB (2^12)大小,32位的页表就需要有(2^20)条目,如果每个条目占4个字节,那么整个页表就占了2^22。页表是和进程绑定的概念,每个进程都该有一张页表,试想一下,如果每个进程启动光页表就占了2^22大小,这会造成很大的资源浪费。因此,有人提出了分层页表(multiple-leve page table)的概念,用以节约页表的空间。
我们先研究一下两层页表结构:
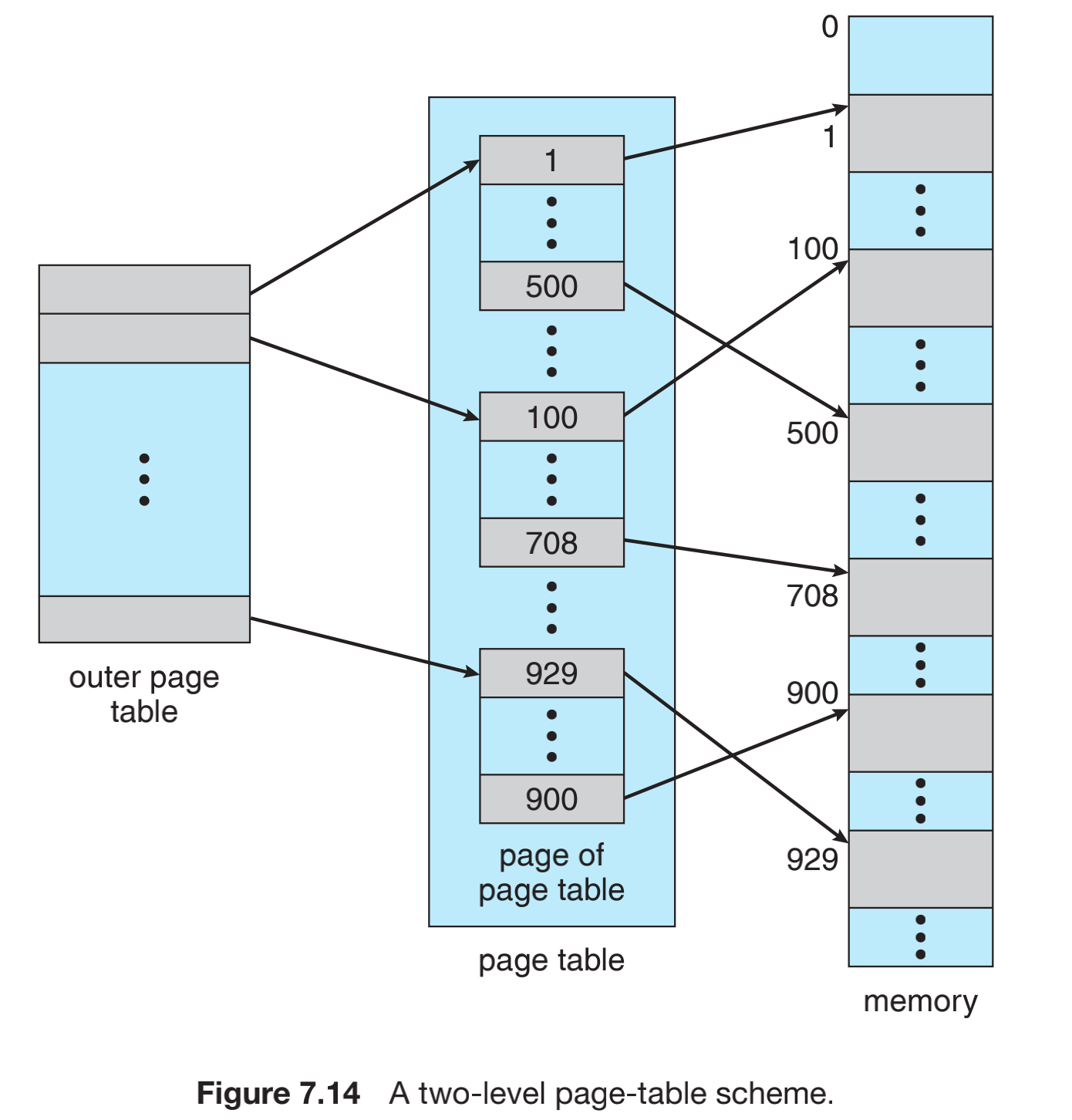
最左边是第一级页表(outer page table),一级页表负责存储的是二级页表每个页的首地址,二级页表中存的是在内存中的地址。因此,在硬件上面,我们需要一级页表的页码数据p1,还需要二级页表的数据p2,还需要二级页表的偏移数据d,有这三个数据就可以拿到想要访问的数据了。
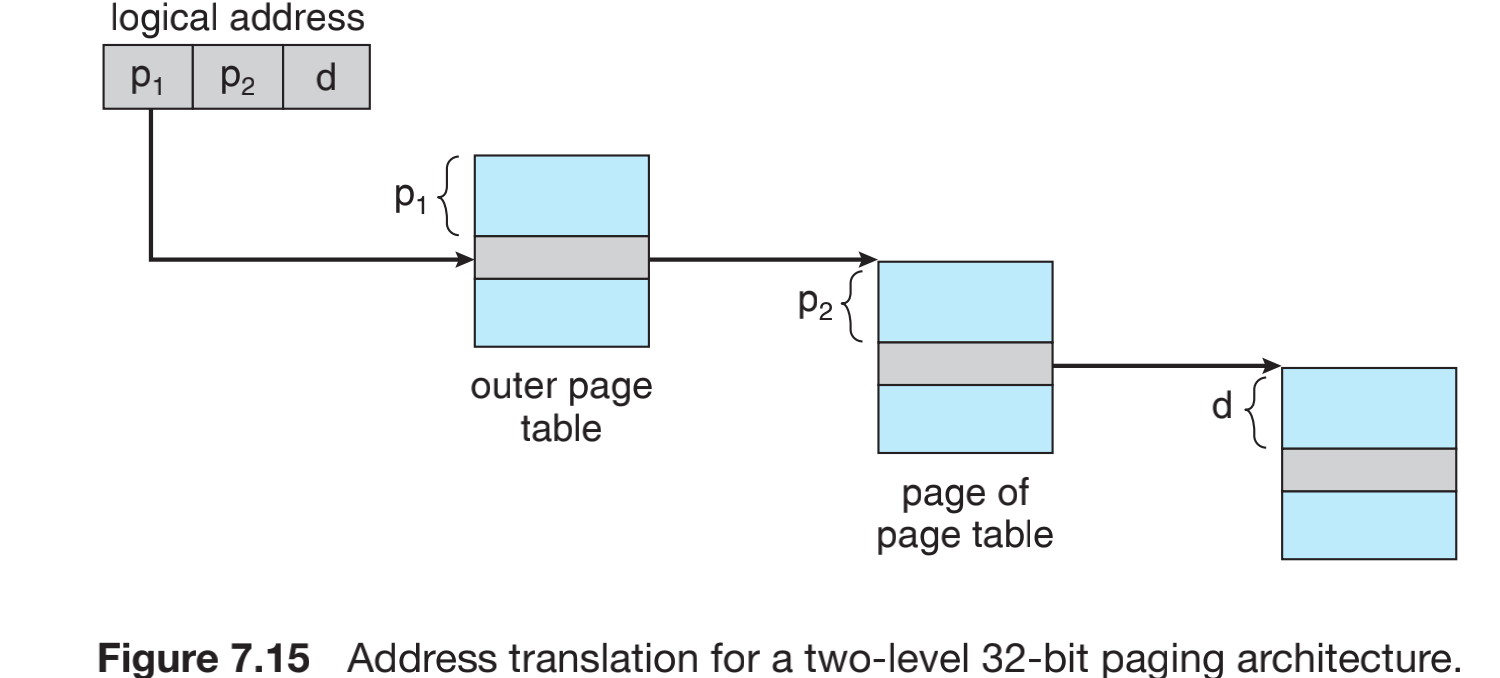
采用这种结构地址是由外向内的,这种方案称为向前映射页表(forward-mapped page table)。
- 页表属于树形结构 (tree table)。
- 每个表的大小固定。
- 在每一个页表上都有失效-有效校验位。
从进程ELF的角度看,ELF会对代码的段合并,然后按照页帧的大小进行分页处理,这个时候虚拟内存会进行编址,这个就是大名鼎鼎的VMA了。我们来看一下vma的规律(这个不一定代表arm架构,只是一种思路)。最高位(红色)表示第一级页表的位置p1,中间(绿色)表示二级页表的位置p2,最低位(蓝色)表示偏移d。
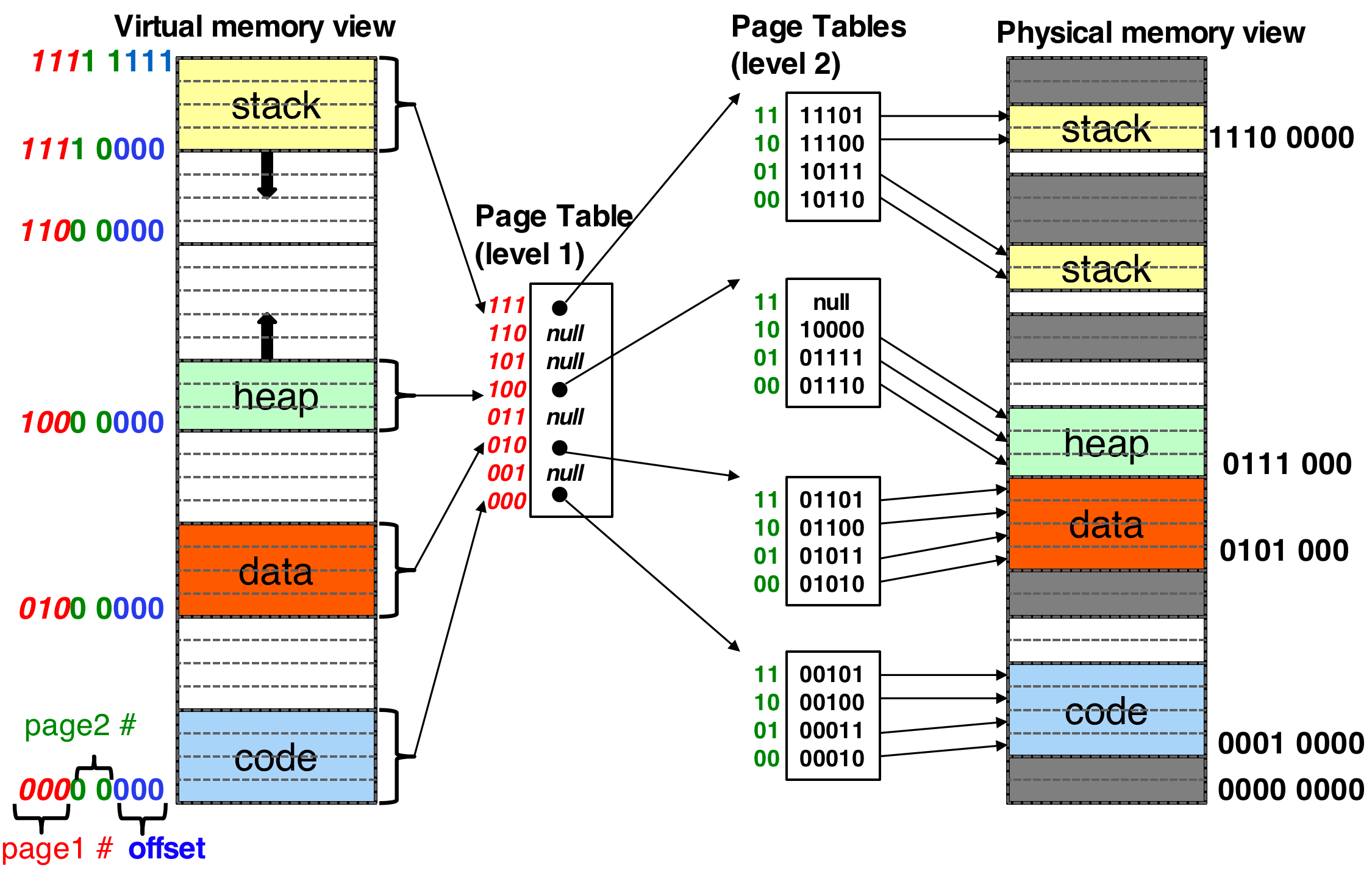
这里需要注意的是:
- 虚拟内存在以页为粒度顺序的连续,在物理内存中不一定是连续的。
- 栈和堆是一个不固定的区域,随着栈和堆的吃空,新分配的空间也会被重新映射。这些空间在虚拟空间上面是连续的。
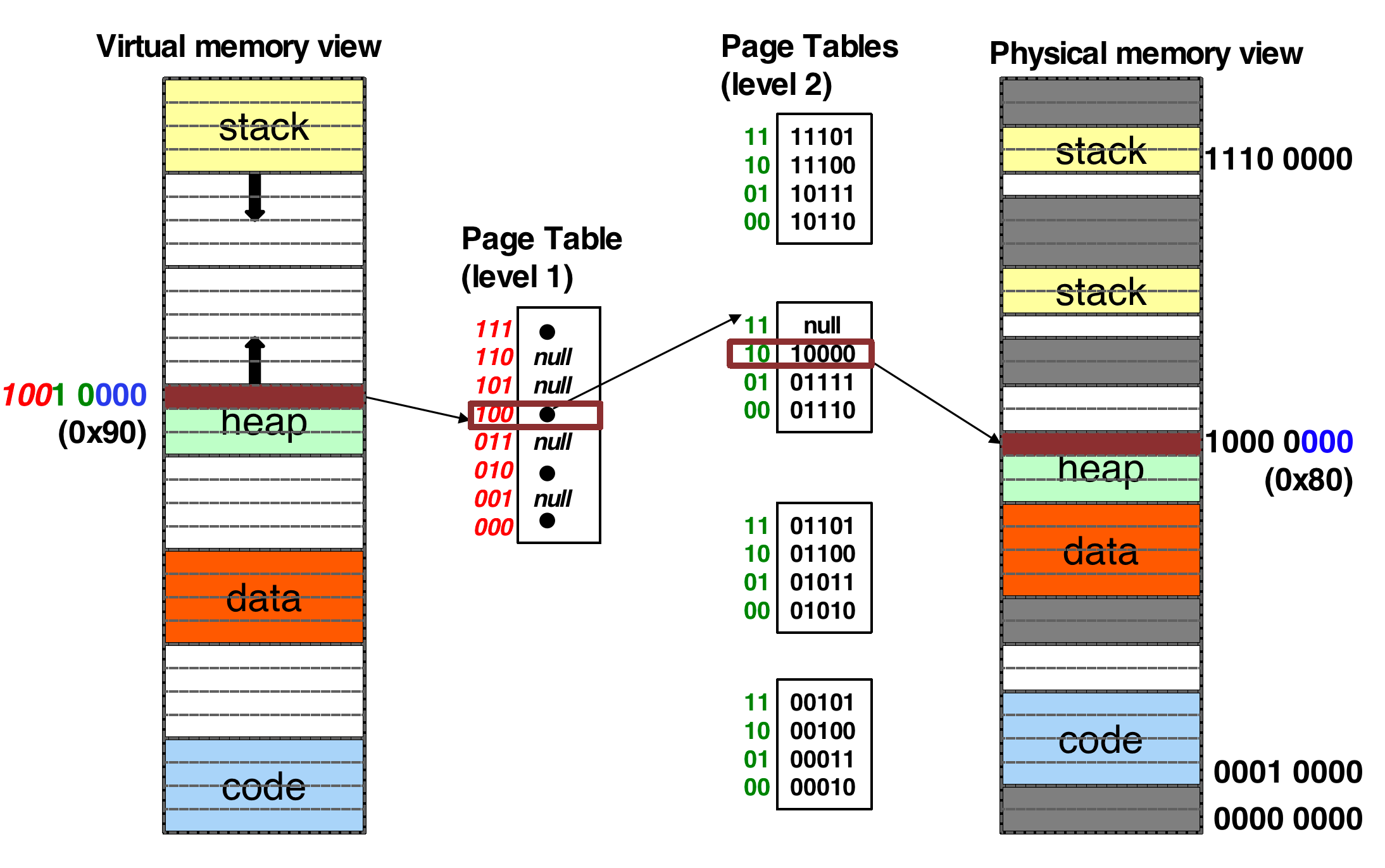
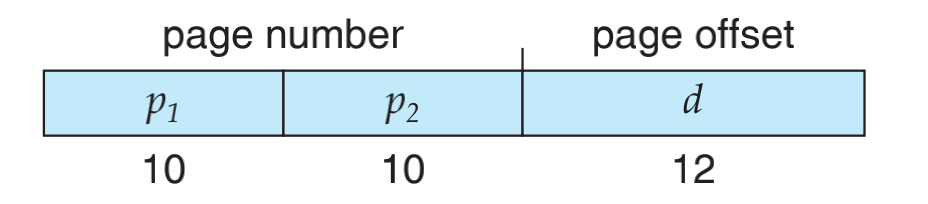
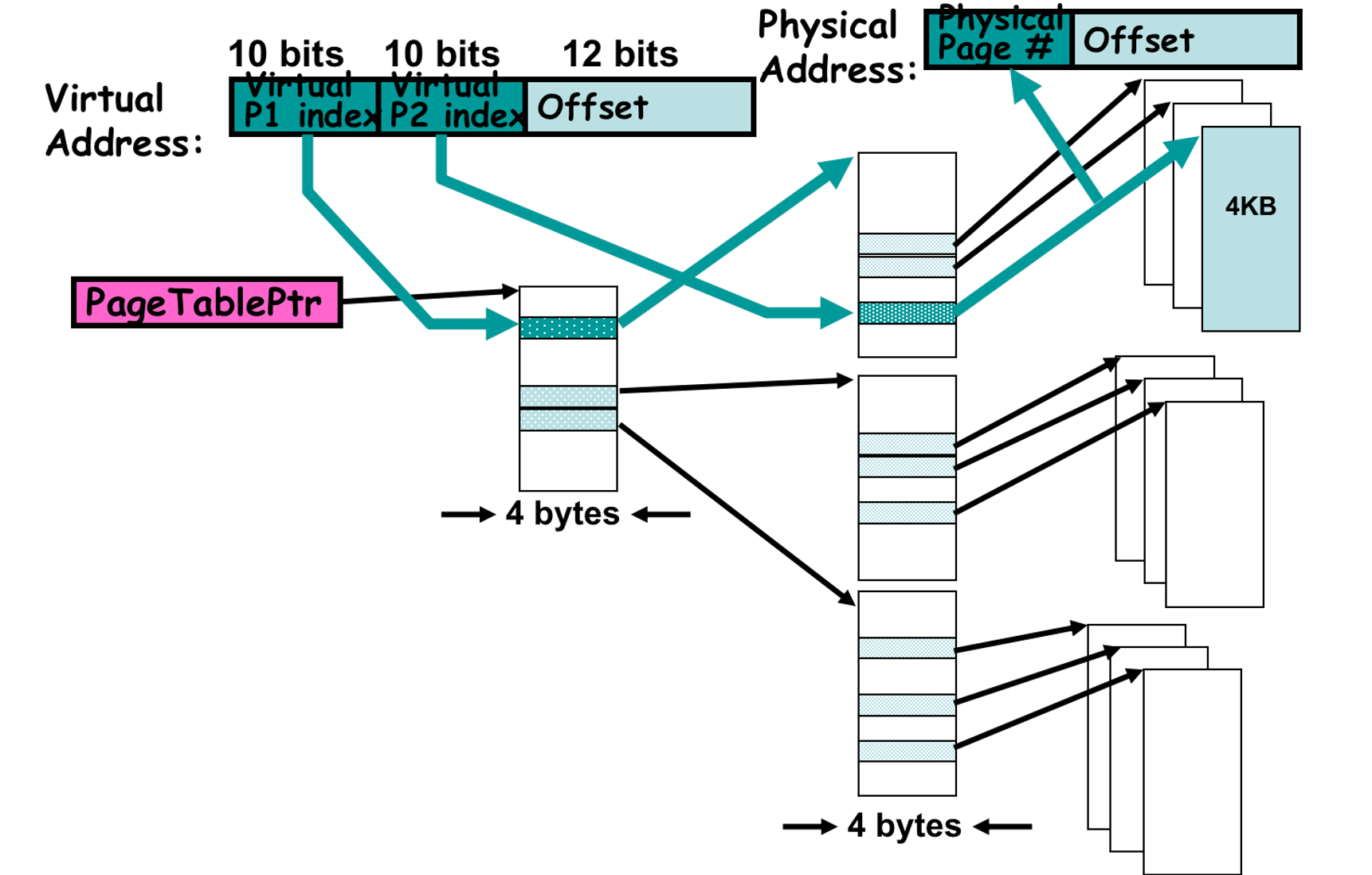
现在我们计算一下二级页表可以容纳多少内存:
- Bits of
d = log (page size) - Bits of
p1 >= log (# entries in level-1 table) - Bits of
p2 >= log (# entries in level-2 table) - Physical page number is limited by entry size of level-2 table.
- logical space size =
# entry in level-1 table*# entry in level 2 table*`` page size` - A logical address (on 32-bit machine with 4K page size) is divided into:
- a page number consisting of 20 bits
- a page offset consisting of 12 bits
- Each entry uses 4 bytes
- A 1-page table with 4KB contains 1K entries and each uses 4B
- 1K entries require 10 bits for P1 and P2 offset
- The page number is further divided into:
- a 10-bit level-1 index
- a 10-bit level-2 index
- Maximum logical space size
- entry in level-1 page table * # entry in level-2 page table * page size = 1K * 1K * 4KB = 2^32 bytes = 4GB
2.2 哈希页表(hashed page table)
我这里说一下hash表,之前学过算法和数据结构但对这个哈希表已经就饭吃了。我们加密算法中hash是算摘要的,无论输入的数据有多长,就会输出一串固定长度的十六进制的字符串数据,而字符串的长度可以是md5、sha224、sha256这些hash算法决定的。所以我们利用hash这个特性,一个固定的input快速的输出一个固定的output1。但是hash运算可能会存在碰撞的问题2。hashed page table就是利用hash元函数,输入不同的地址,然后得到一个唯一的输出然后取长度模,这样就可以快速的查到值了。
处理大于32位地址空间的常用方法是使用哈希页表(hashed page table),采用虚拟页码作为哈希值,哈希页表PTE是一个链表结构。如图所示3:
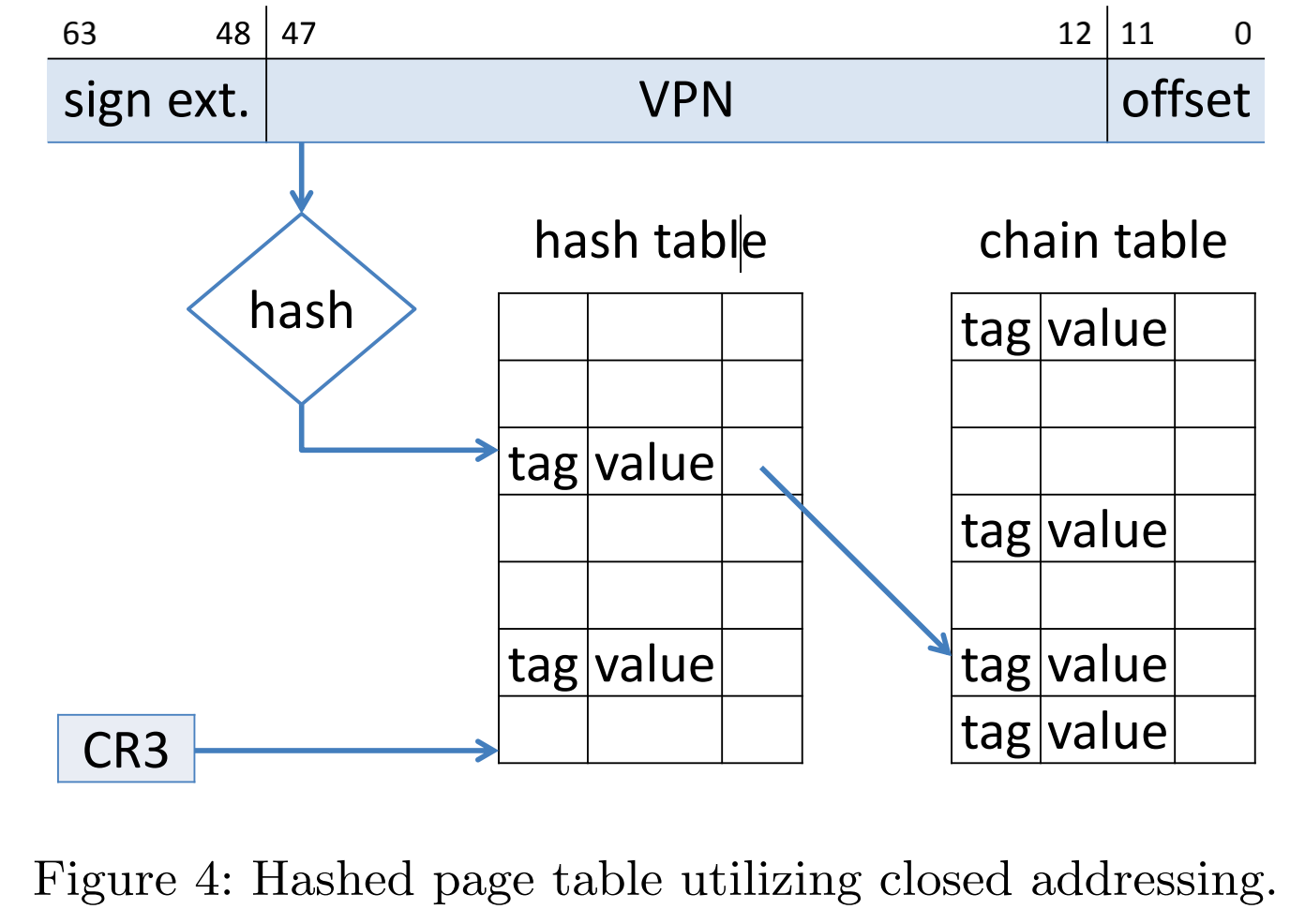
虚拟地址的虚拟页码做hash到哈希表,用虚拟页码与链表内的第一个元素的第一个字段比较。如果匹配,那么相应的帧码就用来形成物理地址;如果不匹配,那么与链表内的后续节点的第一个字段进行比较,以查找匹配的页码。
2 ARM架构的MMU页表
操作系统概念给我们提供了一个理论基础,所有的架构设计都无法脱离这些最基础的**,因此在ARM架构上面也能体现出这种**。ARMv7和ARMv8架构使用了分层页表设计(multi-level page table),ARMv7架构因为是32位的架构处理器,因此需要二级页表就可以满足了4;但是ARMv8架构最高支持到64位,因此在64位的模式下,ARMv8使用了四级页表,这里需要注意的是,ARMv8只有64位执行状态下才会使用4级页表,而在32位下又有另一种配置,除此之外,ARMv8不同的异常等级,使用的MMU页表形态也大有不同5,我们后面展开来讲。
2.1 ARMv7的页表设计
ARMv7是一个32位的处理器架构,因此虚拟内存有4GB大小的寻址空间。ARMv7采用的是分层页表设计,并且分了两层。在ARMv7架构上面将页表分为L1和L2。在L1页表包含了所有的4GB的虚拟地址空间(4096条32位长度的记录PTE(page table entry)),因此每一条记录(PTE)可以代表1Mb的虚拟内存6。在CPU虚拟地址(virtual address)编址上,高12位(31:20)表示L2的入口地址p1,中8位(19:12)表示L2的入口地址p2,低12位(11:0)表示二级页表的偏移d。
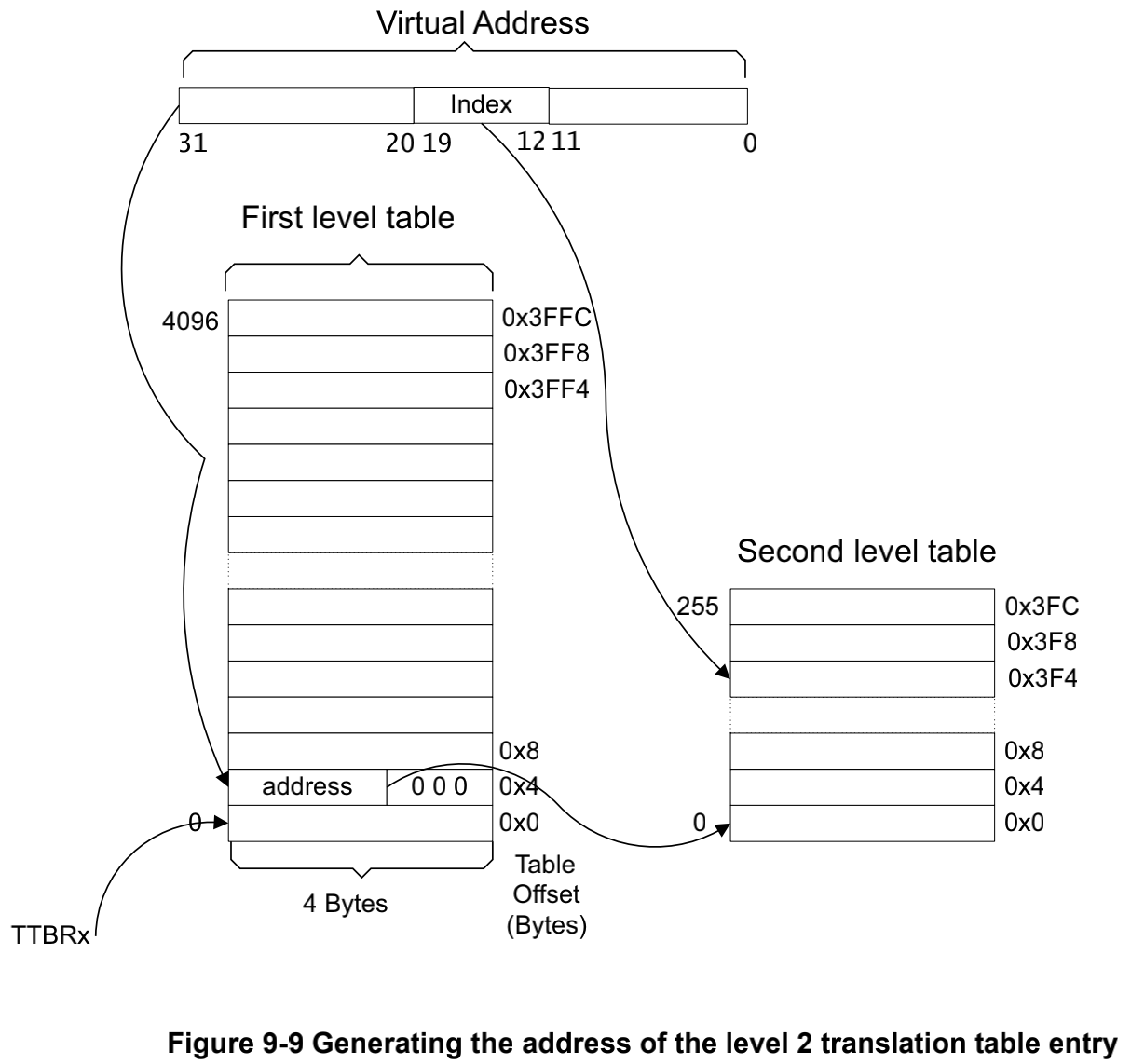
这里需要注意的是,armv7架构在经典版本中,都是二级页表设计但是大物理内存地址扩展LPAE(large physical address extension)的MMU设计有三级页表7。在armv7-a早起的是实现,如cortex-A8和cortex-A9就不支持LPAE。LPAE是在编译阶段设定的,默认的armv7的配置不能默认的去使能,否则legacy版本的armv7就不能使用了。到了ARMv8架构上,LPAE已经被默认使能。
2.2 ARMv8的MMU设计
2.2.1 设计要素
组成元素
MMU在ARM架构上不只是页表设计,还包含其他机制,一个完成的MMU,包含TLB、table walk unit、cache、memory还有memory的TLB。
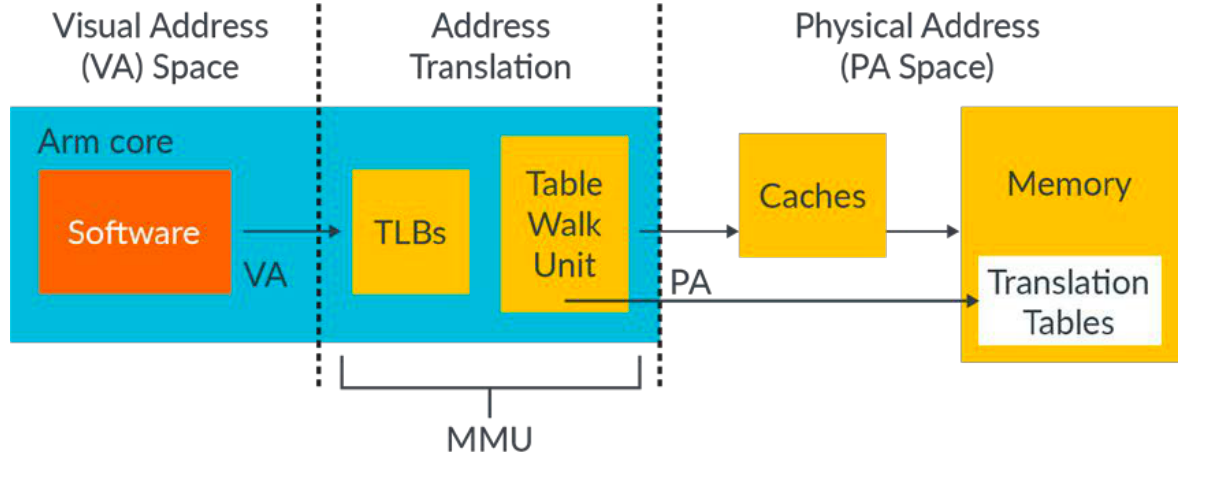
- TLB (translation look-aside buffer):高速缓冲,用于缓冲次级页表的转换结果,提升查询效率。和操作系统概念中描述的功能是一致的,armv8先对请求的地址在TLB中查询,如果该地址存在则被命中,接着就会立即返回结果。
- Table walk unit:对于TLB entry不仅仅包含物理和虚拟地址,也包含内存属性、cache的配置、访问权限、地址空间id(address space id, ASID),虚拟机id(VMID)。如果cpu请求的地址没用命中,接着table walk unit就会被调用,用于在内存中查找请求地址。最新的请求地址会被更新到TLB内部便于重新利用。
映射规则
那么虚拟地址和物理地址的映射规则如何呢?
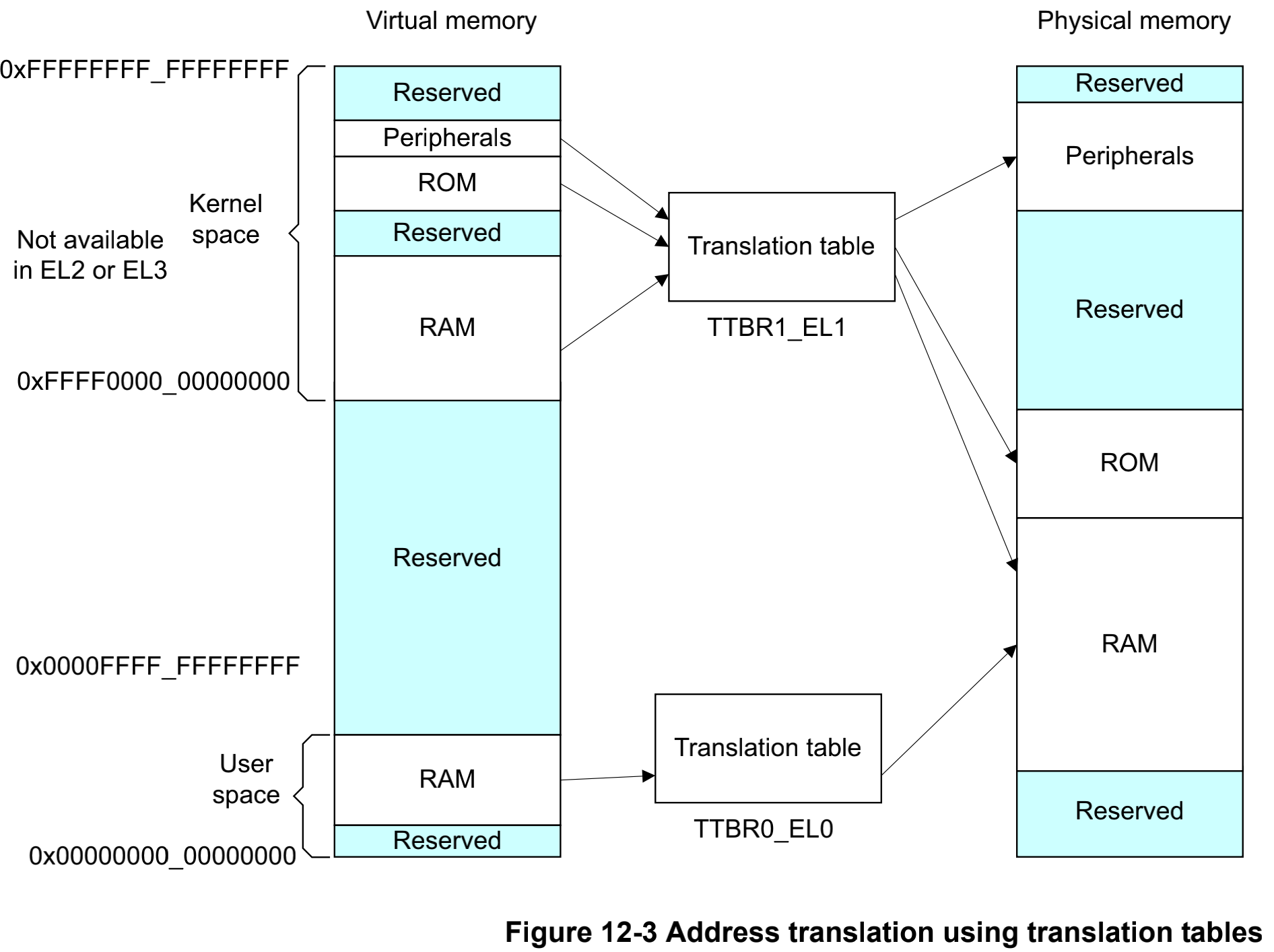
- 在虚拟内存视角,内存是隔离开且可能是连续的,然而在物理内存视角可以是碎片化的。
- 虚拟内存是给程序员、编译器和连接器使用的,而物理内存是给hardware使用的。
- 虚拟内存有可能存在一种同样映射到同一个物理地址的可能性,如图kernel space的RAM和user space的RAM都被映射到物理内存的同一块地址上面了,这也是动态链接的底层逻辑,MMU可以映射同一块内存给不同的进程。
- 需要有地址转译机制完成映射,在armv8里面不同的异常登记有不同的转译表,EL0是user space,EL1对应kernel space。
- 地址转译MMU会控制内存访问权限、内存序和cache的配置。
- MMU的理念就是让内存对进程是透明的。
空间分离
kernel和application的虚拟地址空间分离。在操作系统运行中,是允许多个应用程序或者任务并发运行的,每一个进程都有一个自己独立的应用空间转换表,但是kernel space作为一个进程的上下文,从一个进程切换到另一个进程。然而,在kernel space中有大量的经常使用的指令和数据,因此在设计上处理器会把这部分空间地址固定映射,这也是操作系统概念提到的通用做法。armv8-a在架构层面需要做出这样的支持8。
首先,通过TTBR0_EL1和TTBR1_EL1分别指定基地址;其次,通过地址的一些高位来判断cpu是选择TTBR0的地址还是TTBR1的地址,如果虚拟地址的高位都是0,则选择TTBR0,反过来这些位如果是1,那么就选择TTBR1的地址。在armv8-a上面虚拟地址的高16位来做这项判定。
aarch64的执行模式,取指令和数据访问的虚拟地址都是64位的,其中16已经被占据用以区分是kernel或者userspace的映射,只剩下48位的寻址能力用来映射两个区域到物理内存上面,如图所示,高16位指示kernel space还是userspace,低48位指定的是物理空间,这样的话kernel 和 user可以共用这块物理地址,而在虚拟内存上是分离的。这里还需要注意的是,EL2和EL3是hypervisor和secure monitor的异常模式,不存在kernel space的概念,只有TTBR0,没有TTBR1,这就导致了EL2/3下面,前16位被浪费掉,只能寻址48bit的物理内存。* 注:48位地址空间可以输出的寻址范围256TB,在现在这个时代已经大的不可想象了。 **
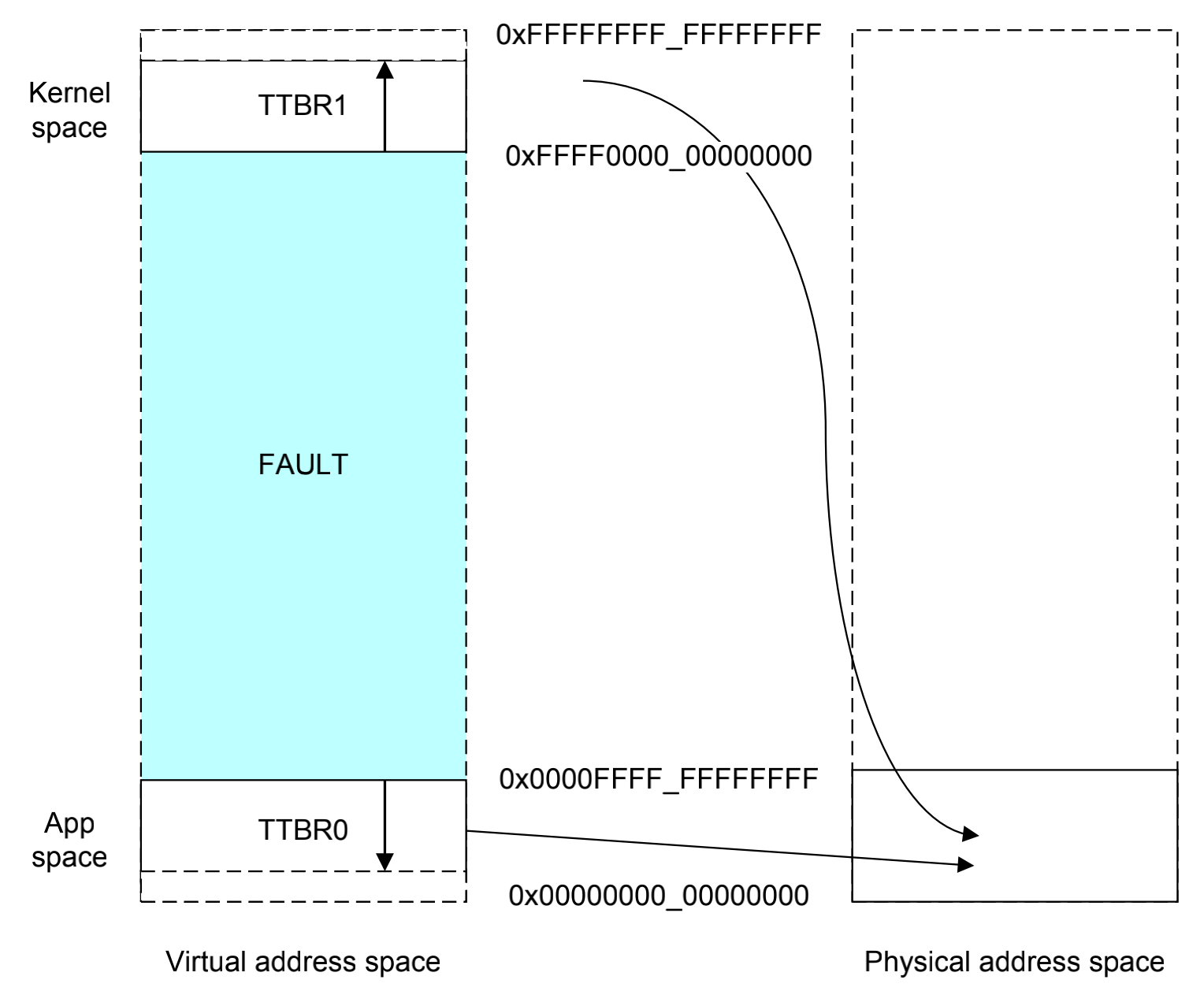
高16位和低48位的这样的分割,实际上也是可以控制的,我们通过TCR_EL1寄存器(Translation control register)可以控制有效位的检查。

-
这个寄存器中含包TCR_EL1包含长T0SZ[5:0]和T1SZ[5:0],用来控制输入地址的的最大值。
-
IPS字段用来配置地址转换后的物理地址的最大值。
- 如果转换指定的输出地址在物理地址范围之外,那么这个访问就会出错。
- 000 / 32
- 001 / 36
- 010 / 40
- 等
-
TGx用来配置TTBRx页表的粒度大小。
- 00: 4kb
- 01:16kb
- 11:64kb
-
我们可以配置用于第一个索引的转换表的等级。一个完整的转换流程需要三到四级的页表。我们不需要完全是实现每一级页表。用于第一个索引的页表也就是,被TxSZ的大小决定页表的级数。
多处理器
那么我们场景更复杂一点,在SMP对称多处理器背景下,如何完成同一块物理内存的映射,他们不打架吗?
关于这个问题,在stackoverflow上面有激烈的讨论9,我也没有看出一个所以然。
cpu0和cpu1是共享一份页表的,当其中一个cpu修改了页表,就必须让另一个cpu知道,这里又个非常重要的多核同步TLB机制,BBM(Break-Before-Make),用以保持TLB的coherency。
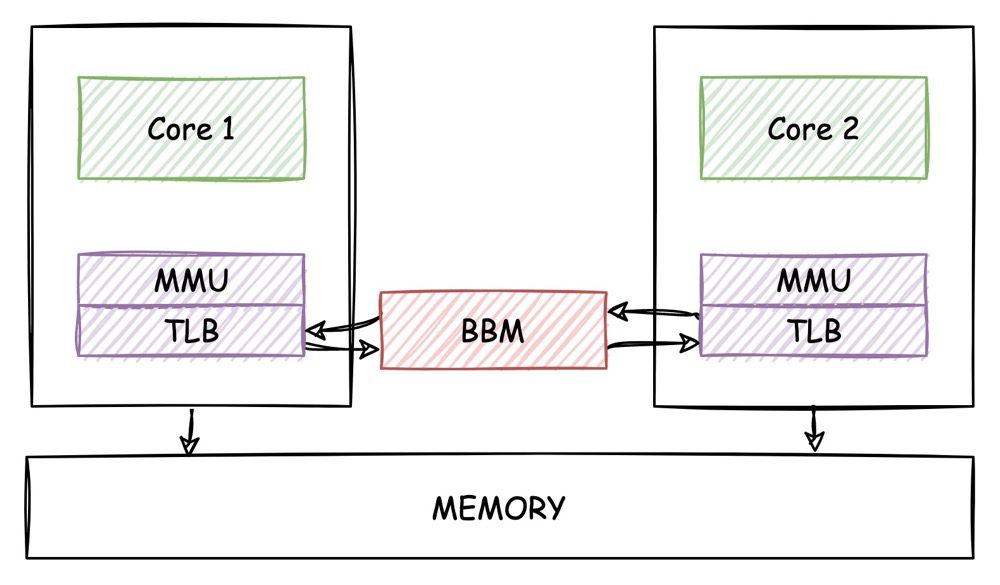
但是这个机制还有个问题,页表被多个cpu进行了共享,在刷新BBM的时候,这些cpu可能正在运行,所以这个就造成了,TLB的caching可能会破坏一致性(一个 处理器可能看见一个错误的数据或者一个被覆盖的数据)或者TLB冲突会产生10。这个我们后面在讨论。
内存属性11
ARMv8-a体系架构处理器主要提供两种内存属性,普通类型的内存(Normal memory)和设备类型的内存(Device memory)。arm提出这两个memory models主要是为了管理和组织内存的行为,因此就在内存上面引入了很多属性,其实这也是跟随操作系统的概念为操作系统而服务的。如图所示,在操作系统中会提出外部io的映射、有内核的数据和指令、有应用程序,所以要对这些OS的模组使用的内存进行一些属性描述。
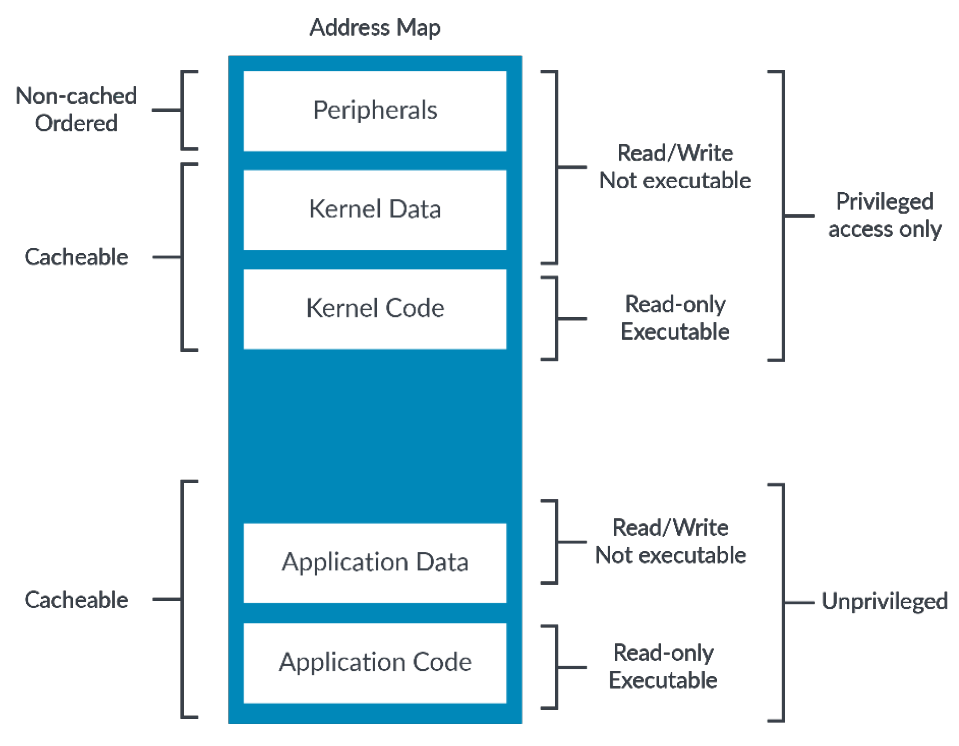
那么这些内存属性和我们的MMU有什么关系呢?我们MMU页表上面有对这部分的描述。
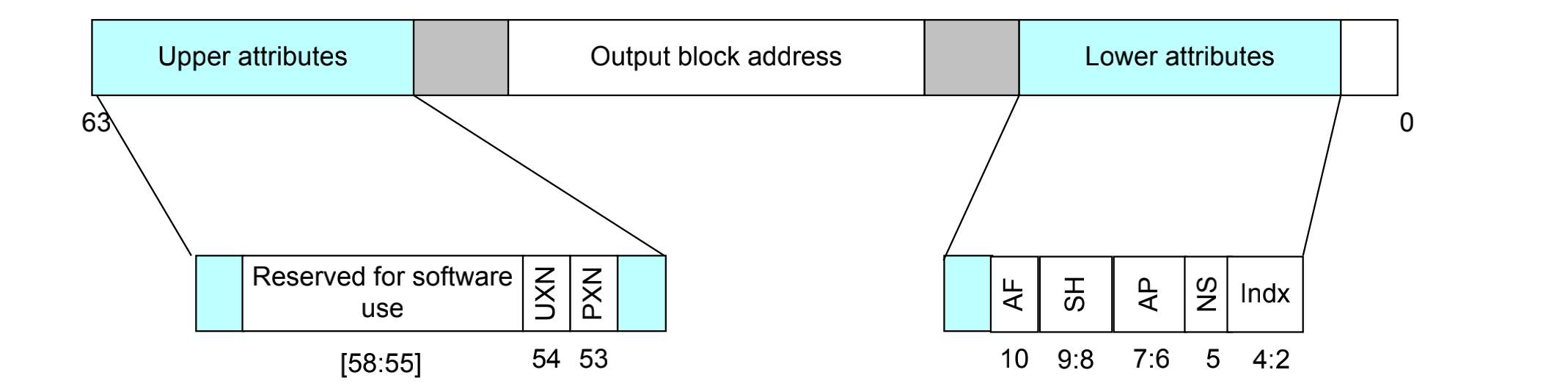
而且由于arm的页表是多级页表,也具备多级页表之间的属性继承。
normal memory
普通类型内存实现的是弱一致性(weakly ordered)内存模型,没有额外的约束,可以提高内存的访问性能。通常代码段、数据段等这些内存段会被放在普通的内存里面。普通能可以让处理器做很多有话,比如分支预测、数据预测、高速缓存行预取和填充、乱序和加载等硬件优化。在OS里面,kernel data,kernel指令,用户空间的数据和指令都是普通类型内存。
所以在normal memory中存在re-ordering的序的问题,这个部分我们在barrier的专题来讲解,反正要记住,barrier的作用域仅仅是normal memory。
device memory
在OS内部,设备类型的内存主要是peripherals的映射,包含内存映射IO。设备类型内存会有很多的限制,设备类型内存都是严格按照指令顺序执行的。通常设备内存留给设备来访问。若系统中所有的内存都设置为设备内存就会有很大的副作用。例如:
-
设备内存无法缓存,这是因为有很少的可能性让cache来访问外围器件。
-
指令不应该被标记为设备内存,arm推荐设备区域总是被标记为不可执行的,否则处理器可能会从设备内存取指,这个对一些读敏感的设备造成一些挑战,比如FIFO设备。
在设备内存的世界也具备一些属性:
- G属性(Gathering)和nG(non Gathering):聚合表示在同一个内存属性的区域中允许多次访问的内存操作合并成一次总线传输。若G属性,则会做总线合并访问;若为nG属性,则会按照访问内存的次数和大小来访问内存,不会做合并优化。
- R属性(Re-ordering)和nR属性(non Re-ordering):访问相同的外围映射,能够被重排或者不能。当指定R属性的时候,访问相同的区域的时候视为normal内存。
- E属性(Early write acknowledgement)和nE:提前写应答和不提前写应答。当向外部设备写数据的时候,处理器先把数据写入缓冲区中,若使能了则提前写应答,则数据到达写缓冲区的时候会发送写应答;若没有使能,则数据到达外设设备的时候才会写应答。
对于内存属性,提供如下四种:
- Device-nGnRnE
- Device-nGnRE
- Device-nGRE
- Device-GRE
内存属性的描述,是在MAIR_ELx寄存器中。(memory attribute indirection register)。MAIR被分为8段,每一段都可以用于描述不同的内存属性。
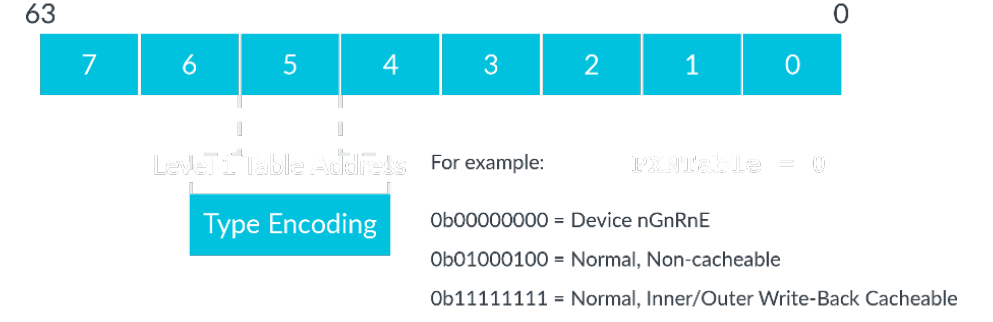
2.2.2 ARMv8的页表设计
页表种类
这里有四个类型的页表:
- 非安全世界的NS.EL0和NS.EL1的页表
- 非安全世界的NS.EL2(hypervisor)
- 非安全世界的NS.EL2(虚拟化页表)
- 安全世界的EL3
这里的每一个页表都是独立的,都有自己的配置和页表实体。
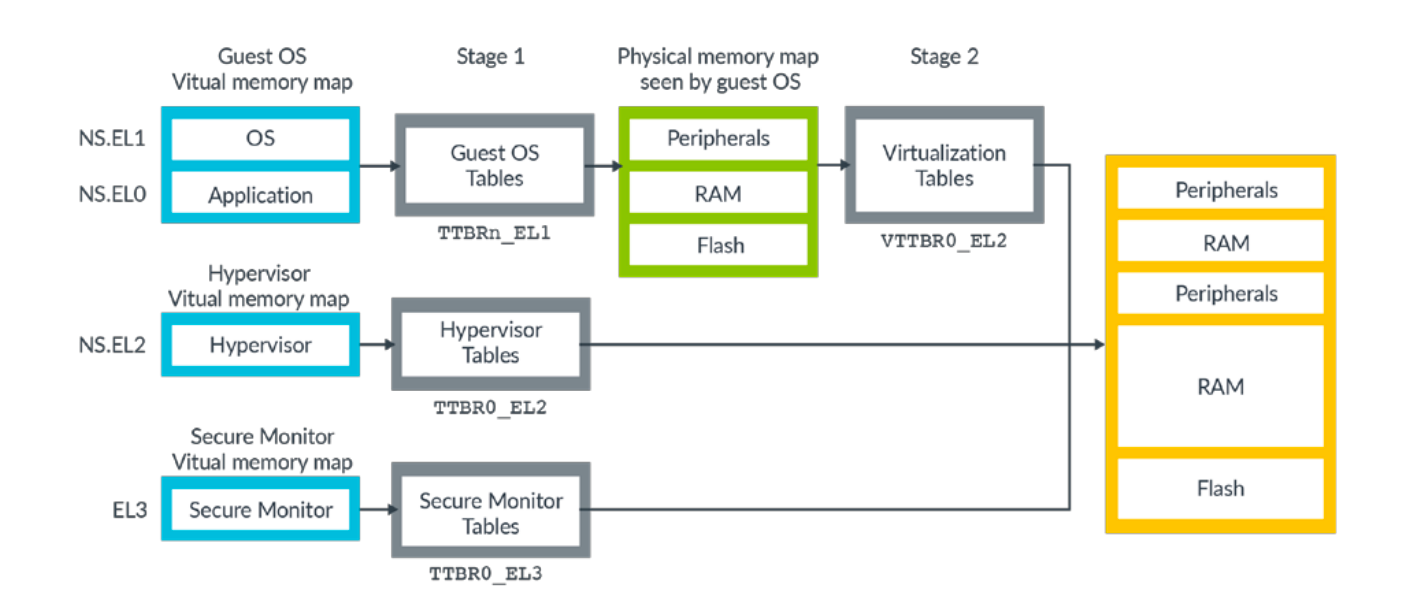
aarch64执行状态的MMU支持单一阶段的页表转换,也支持虚拟化扩展中的两个阶段的页表转换。单一阶段的页表转换,直接把虚拟地址(VA)转换为物理地址(PA)。然而在虚拟化扩展的两个阶段的页表转换中,如图所示10,在阶段1先把虚拟地址转换为中间物理地址(Intermediate physical address, IPA),第二阶段的时候,IPA转换为PA,我们把第一个阶段叫做 guest translation,转换过来的IPA被OS认为就是物理地址空间,第二阶段叫做host translation,这部分是由hypervisor来控制一系列的转换。
在aarch32的执行状态下,继承armv7的页表格式来运行32位的内存的应用。
页表映射
单页表映射
当一个处理器带着一个虚拟地址发起一次数据访问或者取指令,MMU硬件会把虚拟地址转译成物理地址。对于一个在n位地址的空间的虚拟地址,那么他的高64-n比特必须是0或者1,否则这个地址的访问会触发错误。这个原因我们在要素中已经说明,高N位表示的是kernel space或者user space。
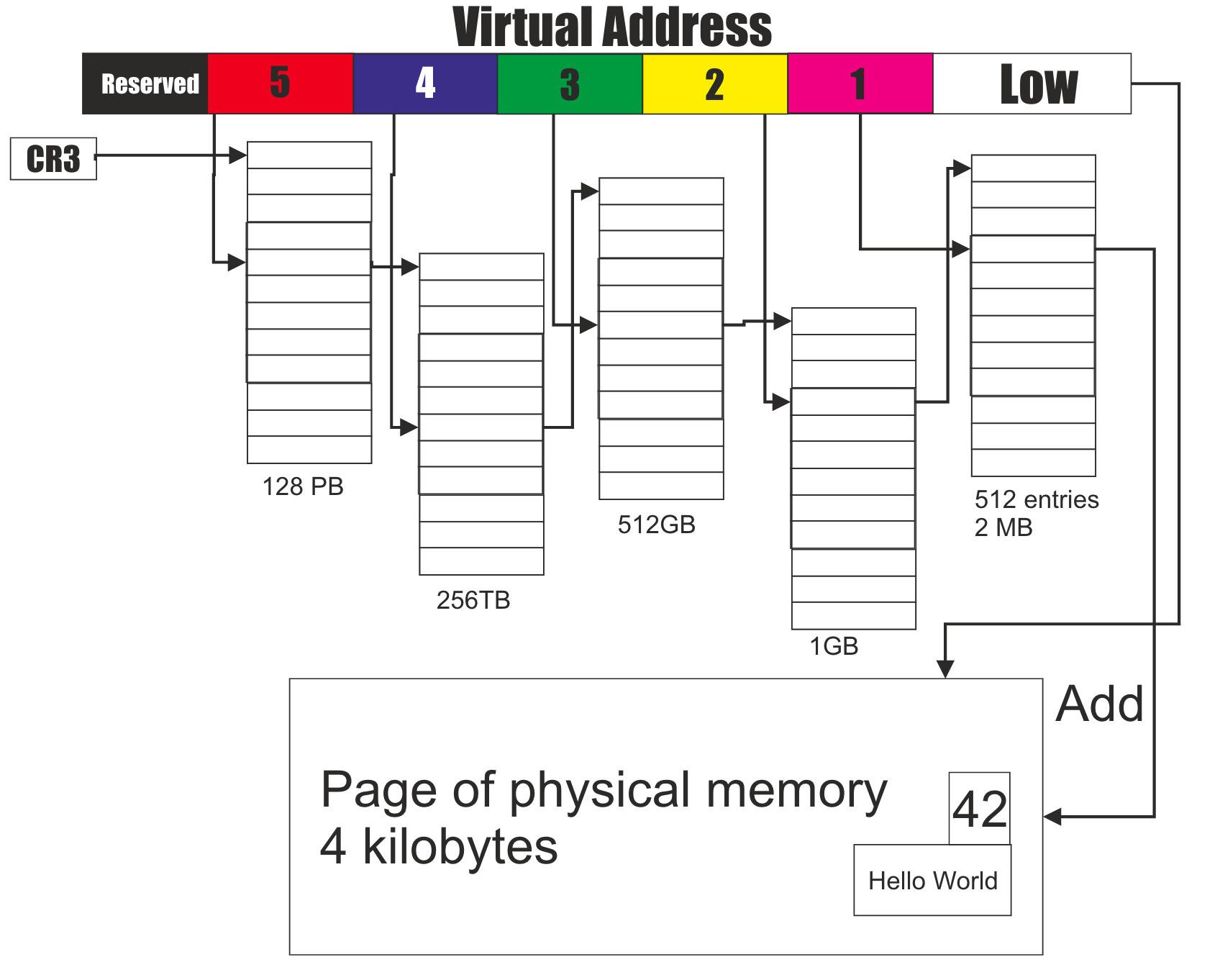
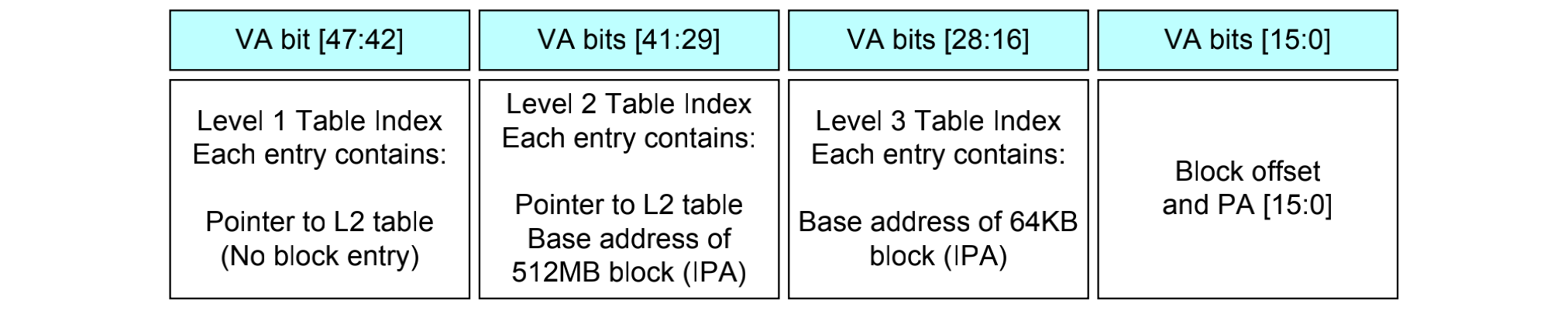
我们来研究一下armv8-a架构的页表映射过程,这里假设只有一级页表,并且使用64kb的物理帧页力度,42位的虚拟地址空间。
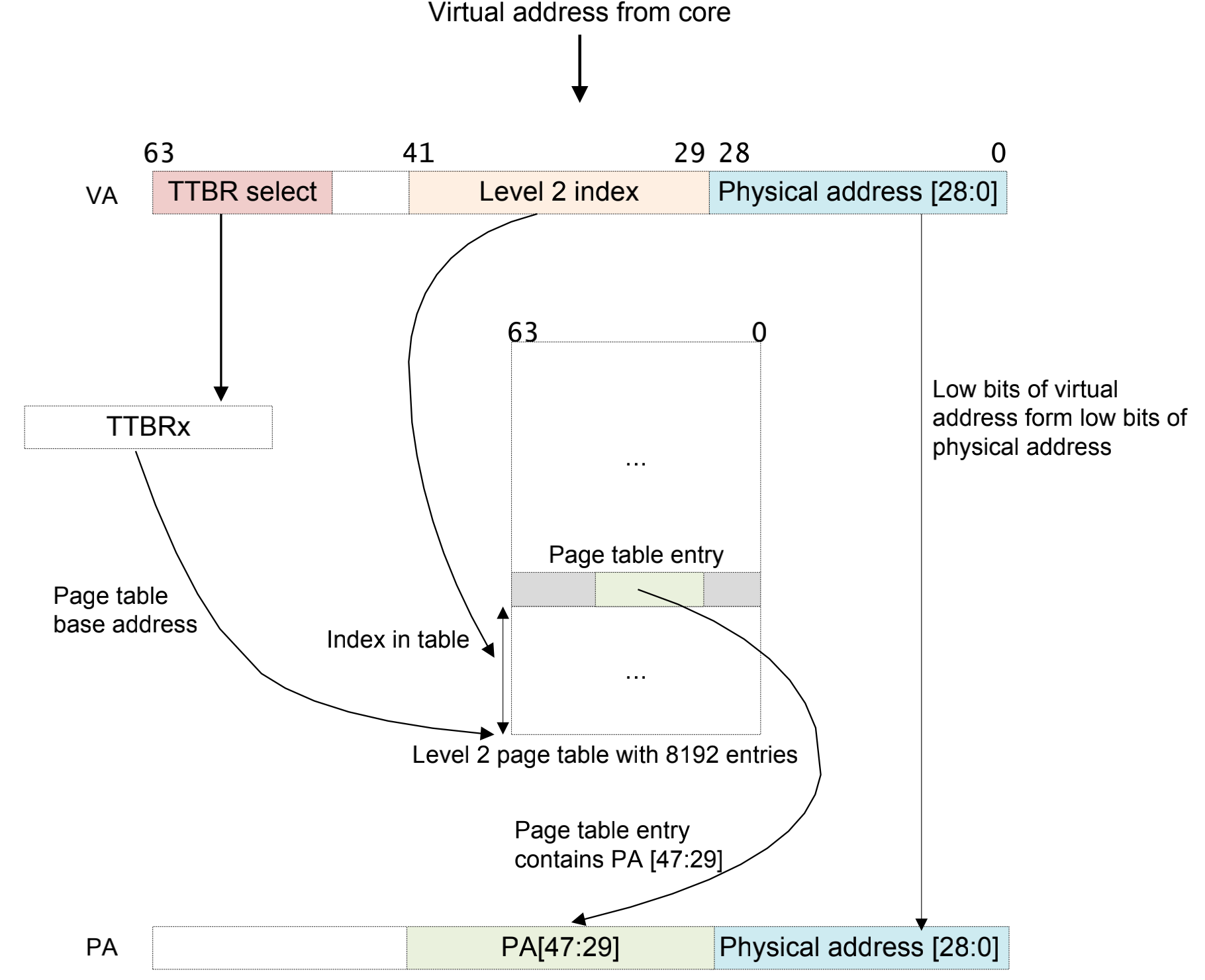
- 一个虚拟地址从cpu请求过来,这个虚拟地址包含64-42=22位的TTBRx的指示:
- 如果是1,这个虚拟地址是来自于kernel space的请求
- 如果都是0,这个虚拟地址是来自于user space的请求
- 41:29是,一共是13位,这里包含的是页表的入口地址,一共8192x64bit个。
- MMU这个时候会检查这个地址是不是合法的。
- 最后把二级页表的地址和物理地址组合起来形成PA。
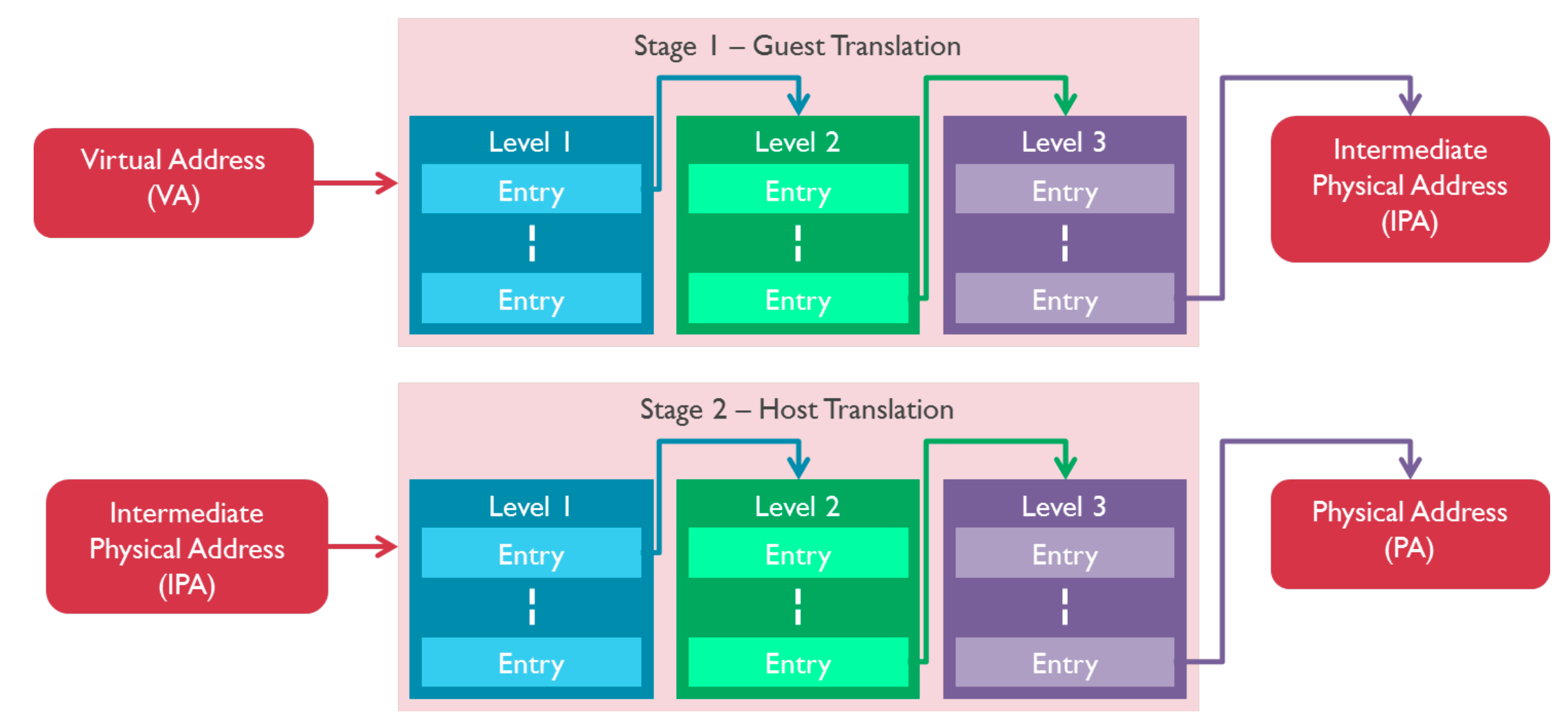
多级页表映射
实际上,如此简单的页表严重限制了地址空间的划分。取而代之的方案就是使用多级页表转换:
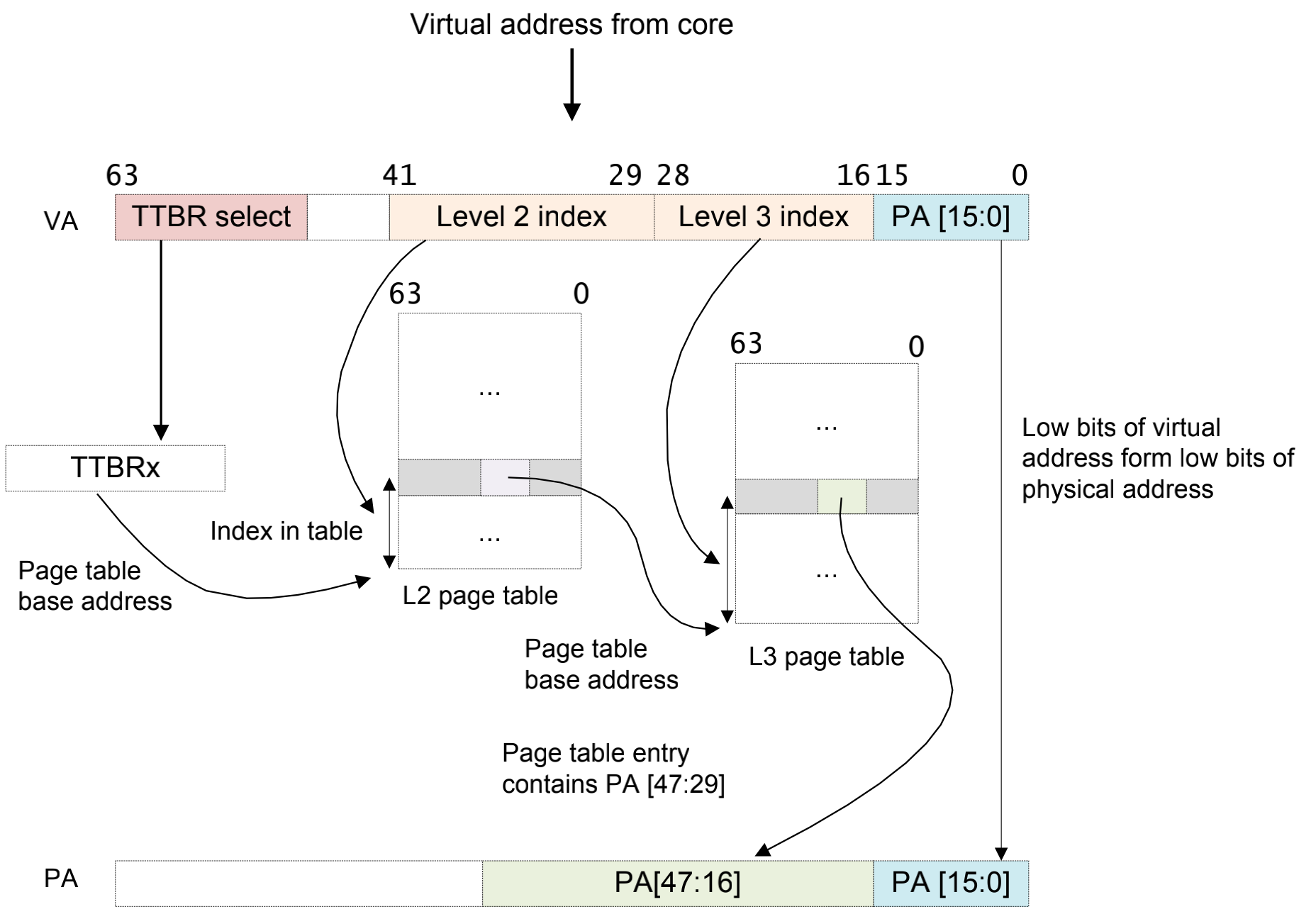
aarch64最高可以支持4级页表,在一些x86_64体系架构中也支持125级页表,如图所示13作为一个5级页表的设计例子在x86_64架构上面。最终页表的支持的级数是和处理器架构、操作系统内核有关的。
安全与非安全
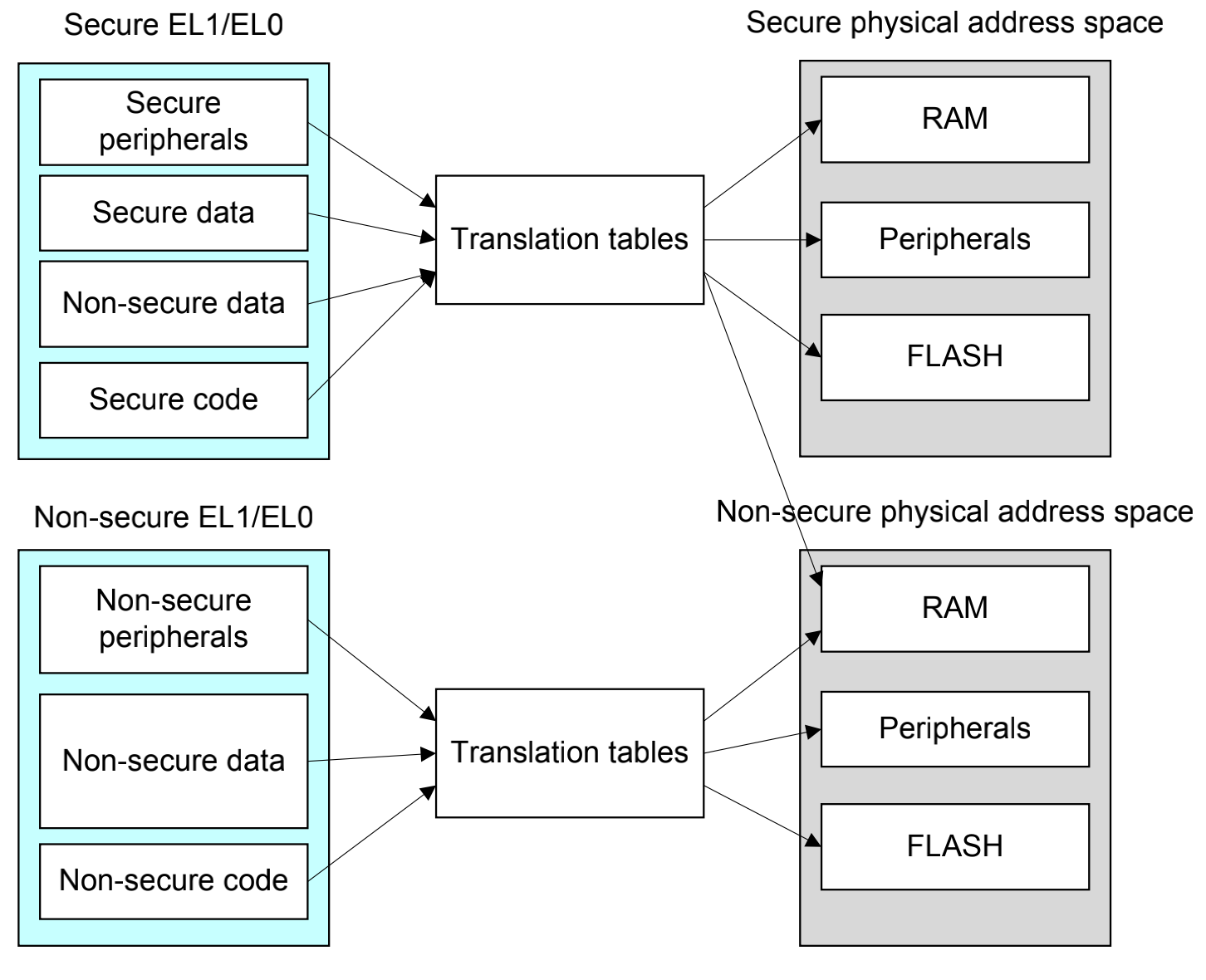
从安全和非安全的角度来看,arm定义了两个物理地址空间,安全地址空间和非安全地址空间。在理论上,两个地址空间应该是相互平行和独立,一个系统也应该被设计出隔离两个空间的属性。然而在大部分真实的系统中,指示把安全和非安全作为一个访问属性,而非两个真实的隔离的空间,所以安全和非安全的概念是逻辑上的,而不是物理上的。我们设定,normal world只能够访问被标记为非安全的空间,而secure world有着更高的权限,既可以访问安全的空间,又可以访问非安全空间。实现这个控制,是在页表上做的手脚。
在安全世界和非安全世界也有cache一致性的问题。例如,由于安全地址0x8000和非安全地址0x8000是逻辑上不同的地址,但是他们可能会在cache**存。有一个理想的手段就是禁止安全和非安全的互相访问,但实际上我们只要禁止非安全向安全的访问就可以。为了避免安全世界的冲突,必须使用非安全访问非安全的空间,在安全的页表中加上非安全的映射。
多重虚拟地址空间
任何时候,只有一个虚拟地址空间被使用(在当前的安全状态异常等级)。然而,在概念上,由于有三个不同的TTBRs,因此就有三个不同的平行的虚拟空间(EL0/1,EL1和EL3)
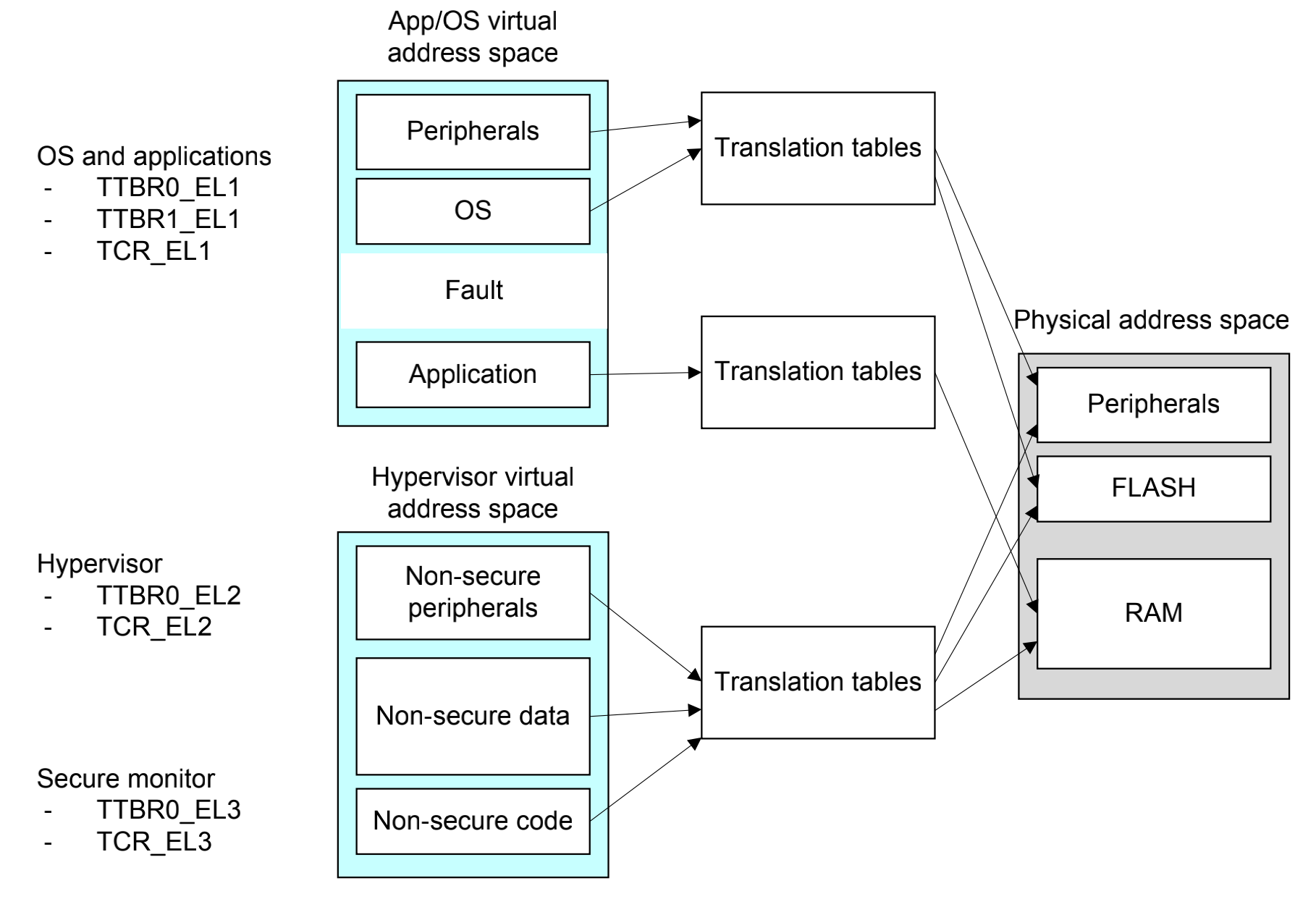
在一个系统里面也可能有安全和非安全的EL1/0,当切换world的时候,安全监视器需要保存和恢复这些寄存器。
MMU关闭之后
当MMU被使能之后,MMU就可以进行页表控制。相反,当MMU被屏蔽,比如在arm复位之后的很短的时间,内存处于默认的状态。
默认状态时,arm用于取指的类型是一个带着被SCTRL_ELx.1控制的可缓存的属性:
- 当1=0,取指使用一个非缓存性质的和前一级页表共享的属性
- 当1=1,可缓存的, the Cacheable, Inner Write-Through Read-Allocate No Write-Allocate, Outer Write-Through Read-Allocate No Write-Allocate Outer Shareable attribute is used.
在一个使用虚拟化的系统,arm允许hypervisor去复写操作系统的默认内存类型。在第一阶段MMU被关闭的的状态下,当HCR_EL2.DC位使能数据cache之后对于非安全的EL0/1的一些访问,默认的内存类型是normal,non-shareable,inner write-back, read and write allocate, outer wirte-back read and write allocate。这个可能在cache已经被配置为hypervisor的场景下是有用的。
写系统寄存器来控制MMU是一些上下文切换的事件,在这里并没有ordering的要求对于写系统寄存器。上下文切换的事件不会被保证能被观察到,除非产生一个上下文的同步事件。
MSR TTBR0_EL1, X0 // Set TTBR0
MSR TTBR1_EL1, X1 // Set TTBR1
MSR TCR_EL1, X2 // Set TCR
ISB // The ISB forces these changes to be
// seen before the MMU is enabled.
MRS X0, SCTLR_EL1 // Read System Control Register
// configuration data
ORR X0, X0, #1 // Set [M] bit and enable the MMU.
MSR SCTLR_EL1, X0 // Write System Control Register
// configuration data
ISB // The ISB forces these changes to be
// seen by the next instruction页表格式
上面的页表由于也是分层页表,所以在设计格式上面肯定有不一样的地方,在aarch64的执行状态下,独有的长描述符转页表格式(long descriptor translation table format);armv7和aarch32的执行状态,有对应的短描述符转页表格式(short descriptor translation table format)与前面提到的大物理地址扩展(LPAE)。ARMv8体系结构,支持4KB, 16KB, 64KB三种帧面粒度。
AArch64的描述符格式
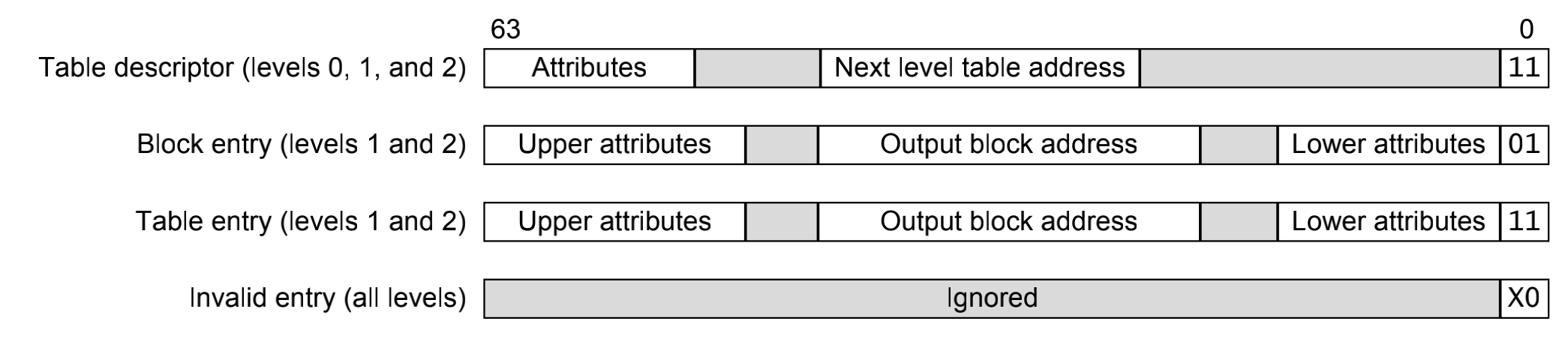
描述符格式在EL0/1/2/3都有涉及,比较特殊的就是一级和四级的页表格式,L0~L3页表描述符格式完全不一样。L0~L2的页表比较类似(前三级)
L0~L2的页表项可以分为三类,这个页表的类型是通过最低1位来指示的:
- 无效页表 invalid entry: bit[0] = 0
- 块类型页表 block entry(L1和L2),bit[0] = 1 & bit[1]=0,表示一个大内存块的页表项,其中包含最终的物理地址。
- 页类型页表 table entry(L1和L2),bit[0] = 1& bit[1]=1,表示该描述符指向了下一级页表的物理地址。
简单的说,在这个等级,如果有下一级页表的存在,那么就启动页类型页表,如果没有下一级的存在了,那么这一级就启动块类型页表。
页表颗粒度
我们在上面的要素中提到,armv8-a体系架构的页表的颗粒度有三种选择,4K/16K/64K。那么如果不同颗粒度大小的页表在页表的格式体现上也是很有影响的。这个作用只做用到最后一级页表上面。
4KB
在4KB granule,硬件会使用4-level的页表,48bit的地址对这个配置是最好的选择,输出地址对应bit[47:12]

16KB
在16KB granule,硬件会使用4-level的页表,输出地址对应bit[47:14]

64KB
在64KB granule,硬件会使用3-level的页表,输出地址对应bit[47:16]。
页表属性
-
共享性与缓存性:指的是页面是否使能了高速缓冲及高速缓冲的范围。只有普通内存可以使能高速缓存,通过页表项attrIndx[2:0]来配置。另外还可以指定缓存属性是属于内部共享还是外部共享。内部共享指的是只能是cpu内部的成员才能访问的,外部的共享是核和核之间的共享。
-
访问权限:访问权限控制的是页面的可读性、可写性权限。通过AP[2:1]来控制。

需要注意的是,AP[1]为1的时候,非特权和特权模式具有相同的访问权限,这就有个问题了。特权模式下内核态是可以访问用户态的任意空间的。攻击者可以在内核态任意访问用户态的代码。为了修复这个漏洞,ARM v8.1 架构里面新增了PAN(特权禁止访问)的设计,在PSTATE的中新增了一位PAN。当内核态访问用户态内存的时候会触发一个访问权限异常,从而限制在内核态恶意访问用户态的内存。
-
执行权限:页表属性通过PXN字段以及XN/UXN字段来设置CPU是否对这个页面具有执行权限。
- 当系统中有两套页表时,使用UXN(unprivileged eXecute-Never)用来设计非特权模式下的页表是否有访问权限。若UXN为1,则表示没有;反之亦然。
- 当系统中只有一套也表示,使用XN字段。
- 当系统中有两套页表时,PXN(privileged eXecute-Never)用来设计特权模式下的页表(通常是内核空间的页表)是否具有可执行权限。若PXN为1,表示不具备可可执行权限。
- 为了提高安全性,SCTRL_ELx寄存器还用WXN字段来配置全局控制执行权限。
-
访问标记位: 页面有个属性是访问标记,AF(Access Flag),用来指示页面是不是被处理器访问过。操作系统中的页面回收依赖这个特性。
-
全局和进程特有TLB:nG字段,用来设置TLB的类型。TLB的表项分成全局和进程特有的。当nG为1的时候,表示页面对应的TLB时进程特有的,反之,TLB是全局的。
-
脏位(dirty state)
3 问题回顾
Q1: 为什么页表要设计成为多级页表?直接使用一级页表是否可行?多级页表又引入了什么问题?
现代处理器架构大部分超32位的,我们以32为例子,32位寻址空间是4GB,如果我们只使用一级页表,每一个进程创建的时候,都会创建一个非常大的页表。因此我们引入多级页表,第一级页表存放第二级页表的索引,次级页表按需创建,只有在进程需要的时候才去创建次级页表,大大节约了空间。但问题是,增加了页表层级,索引次数就会上升,正常我访问一个内存如果一级页表我只索引一次,如果多级页表,还要拿着次级页表的索引再去查地址,这就导致了效率减少50%,试想,如此频繁的进程和内存交换数据的过程,就会产生很大的效率浪费。目前主流的方法是引入TLB机制,快表查询,预加载一部分次级页表的地址在TLB中。