16_ARMv8_高速缓存(一)cache要素
carloscn opened this issue · 0 comments
16_ARMv8_高速缓存(一)cache要素
图片源于Computer-Architecture-ComputerOrganizationAndDesign5thEdition2014 致敬伟大的工程师艺术家。
本篇总体思路来源于文献 1,感谢大神,膜拜
本篇实验部分来源于文献 2,感谢大神,膜拜
一部分知识来源于我的line manager - Tony
1 局部性原理
我们以一个图书馆学习的过程为例(这个是计算机组成和设计中举例的)我觉得非常好,来解释局部性原理和CACHE,内存和CPU之间的关系。设想一下,导师让小明写从0写一篇论文《研究影响母猪生产的关键原因》,小明首先要做的就是去图书馆收集一些资料。小明到了图书馆之后,没有找一个位置坐下,而是去了关于畜牧业的书架,拿了相关性比较高的《母猪生产原理》《母猪生活习性》和《如何养好母猪》三本书,小明猜测这些书和要写的论文相关度十分的高,可以作为写论文的一些指引,因此就找个位置坐下,并把这三本书放在自己最靠近的位置以方便自己去随时拿书参考。小明就进入了一天写论文的任务中。读着读着,小明在《母猪生活习性》中看到了一句话“食料可能对母猪生育率产生影响”但是没有展开,小明觉得这个可能是研究论文的关键点,因此,**就起身去书架寻找《母猪食料配方》**这本书,找到这本书之后也放在了自己的旁边,但是图书馆的管理员只允许每个同学在周边堆积三本书,因此小明暂时把《如何养好母猪》这本书先还到书架上面。

上面的整个过程实际上就包含了很学术的定义,局部性原理和cache和cpu和内存之间的关系。**局部性原理(principle of locality)**分为时间局部性和空间局部性:
- 时间局部性:如果一个数据被引用,那么在不久的将来它可能自再次被引用。比如,小明会多次引用《母猪生产原理》,所以小明把《母猪生产原理》放在了自己的旁边,方便自己随时查阅。
- 空间局部性:如果某个数据被引用,那么它地址相近的数据项很可能也会被引用。比如,图书馆的管理员喜欢对书籍进行分门别类,把同样的具备相关性的书籍都放在空间上更近的位置,所以小明踏入图书馆的第一件事就是去畜牧业类别的书籍找到自己想要的,而不是去文史类或者天文学的书架。
诚然,我们生活中的设计处处透露着智慧,这一切的管理的目的就是为了提升效率,节约大家的时间,我们可能在生活中对这些已经非常熟悉了,但是可能我们不知道学术届把这种行为已经定义出一个名词以方便我们的的学术交流。多数的程序中都是有循环的,因此这部分指令和数据就会被重复的访问,呈现出很高的时间局部性;指令通常也是顺序执行的,从而又呈现出高度的空间局部性。
计算机中的存储器的层次设计实际上就是根据局部性原理为指导而设计出来的,在计算机体系中存储层次由不同的速度和容量的多级存储器组成,这个也能看出整个计算机的设计**是多么绝妙,trade off成本和速度,真的是一点都不浪费。
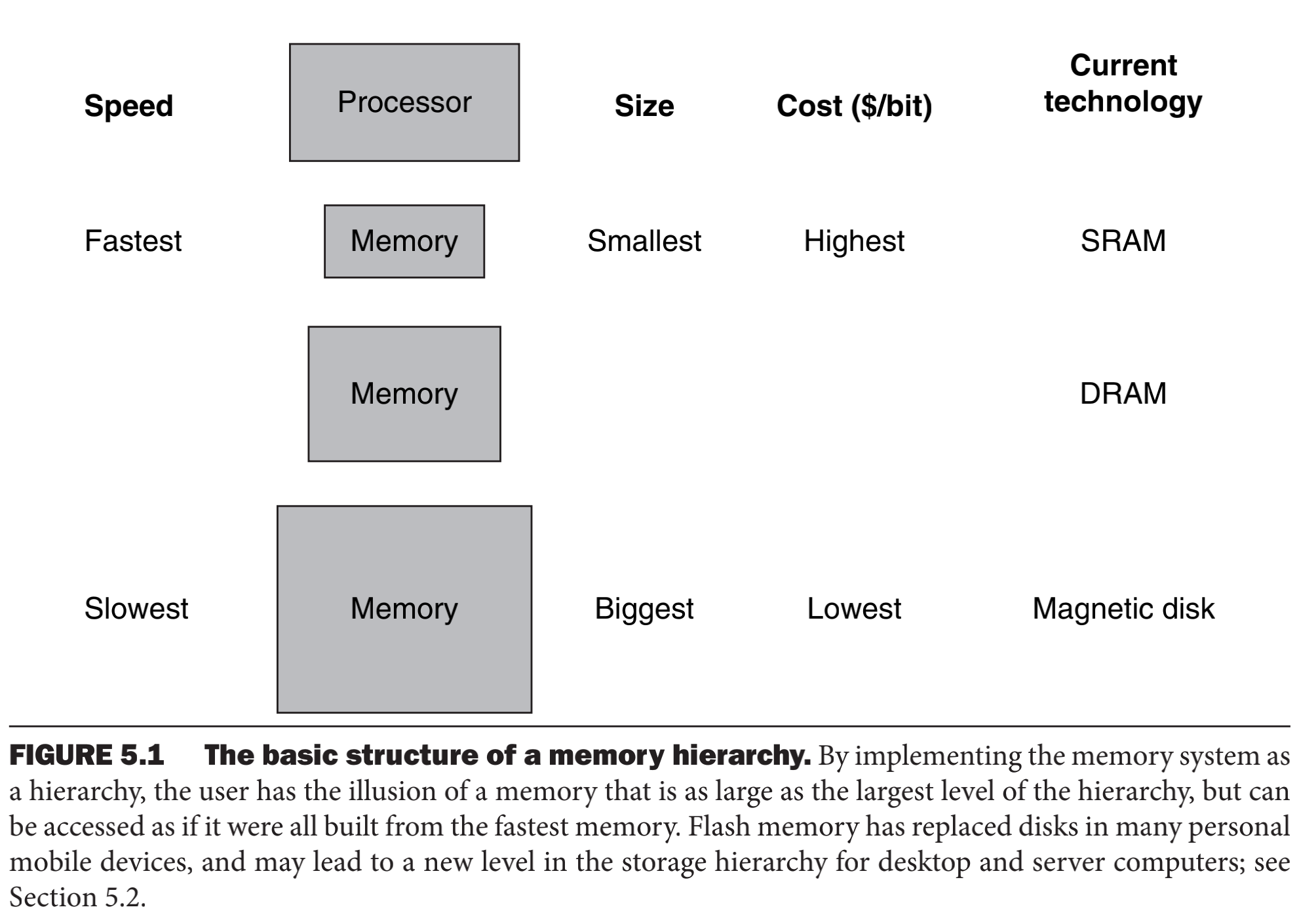
像图书馆一样,离处理器越近的一层,访问速度更快,而离CPU越远的,就需要更大的代价才能拿到数据。存储器层次可以分为多层,但我们去看数据复制的话,我们只把注意力放在两个层次之间,而且我们把数据交换的最小单元称为一个块或者一个行,比如,小明把《母猪产后护理》一本书作为一个块。如果处理器需要的数据就在临近的块中,称为一次命中(hit)。如果临近的存储器找不到这个数据,就称为一次缺失(miss)。
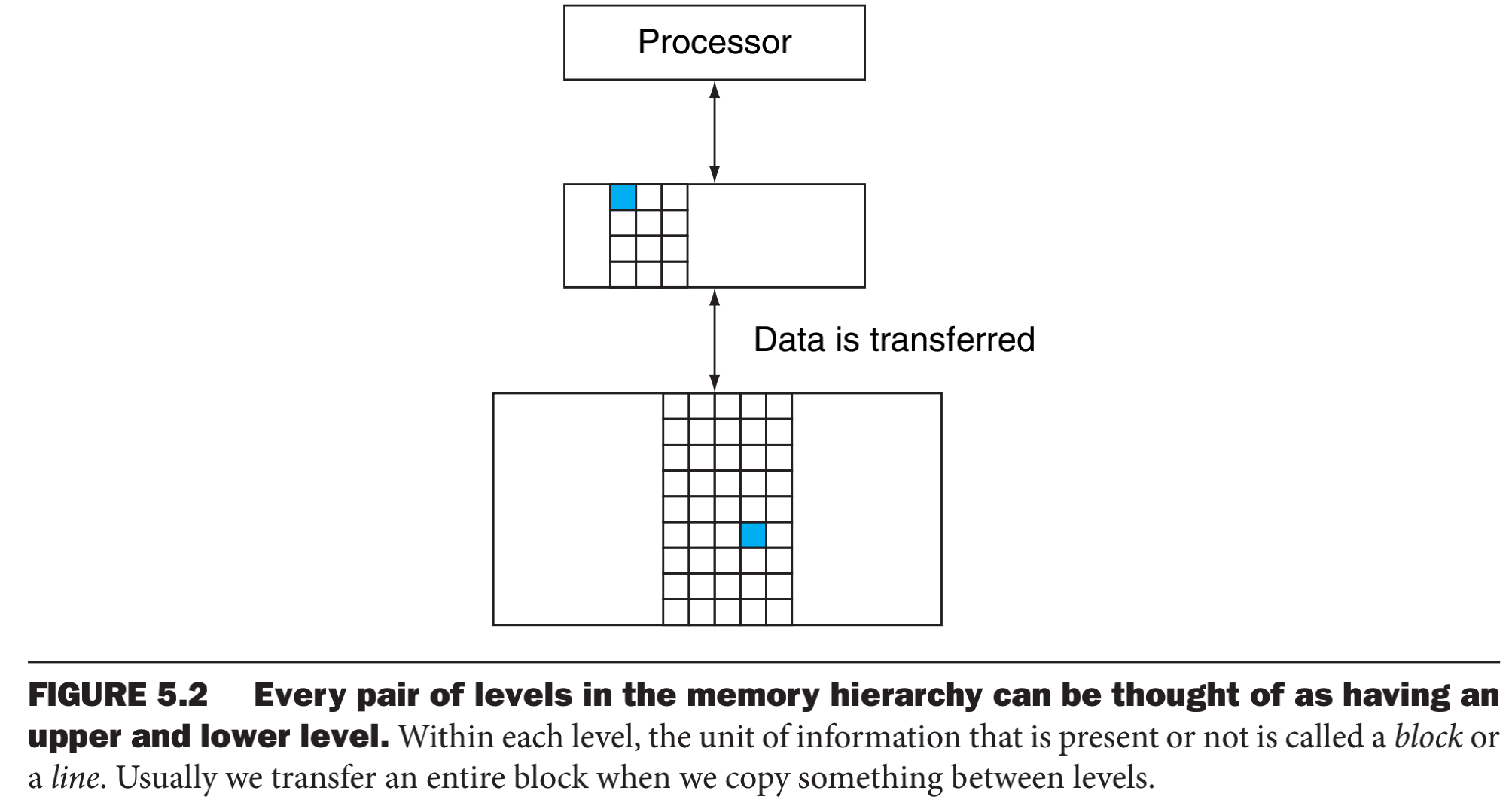
还定义了两个时间,用于度量性能。命中时间(hit time),访问存储器层次结构中高层存储器所需要的时间;缺失损失(miss penalty),把相应的块(行)从底层替换到高层的时间,还需要加上传输的时间。
2 高速缓存基础知识
Cache: a safe place for hiding or storing things. ---- Webster’s New World Dictionary of the American Language, Th ird College Edition, 1988
高速缓冲最早出现在20世纪60年代研究性质的机器中,而如今被普遍利用到计算机或者嵌入式的设备中。这一部分我们来研究一下高速缓冲的一些基本工作原理(不涉及硬件实现,只是高速缓冲的逻辑实现)。
2.1 直接映射
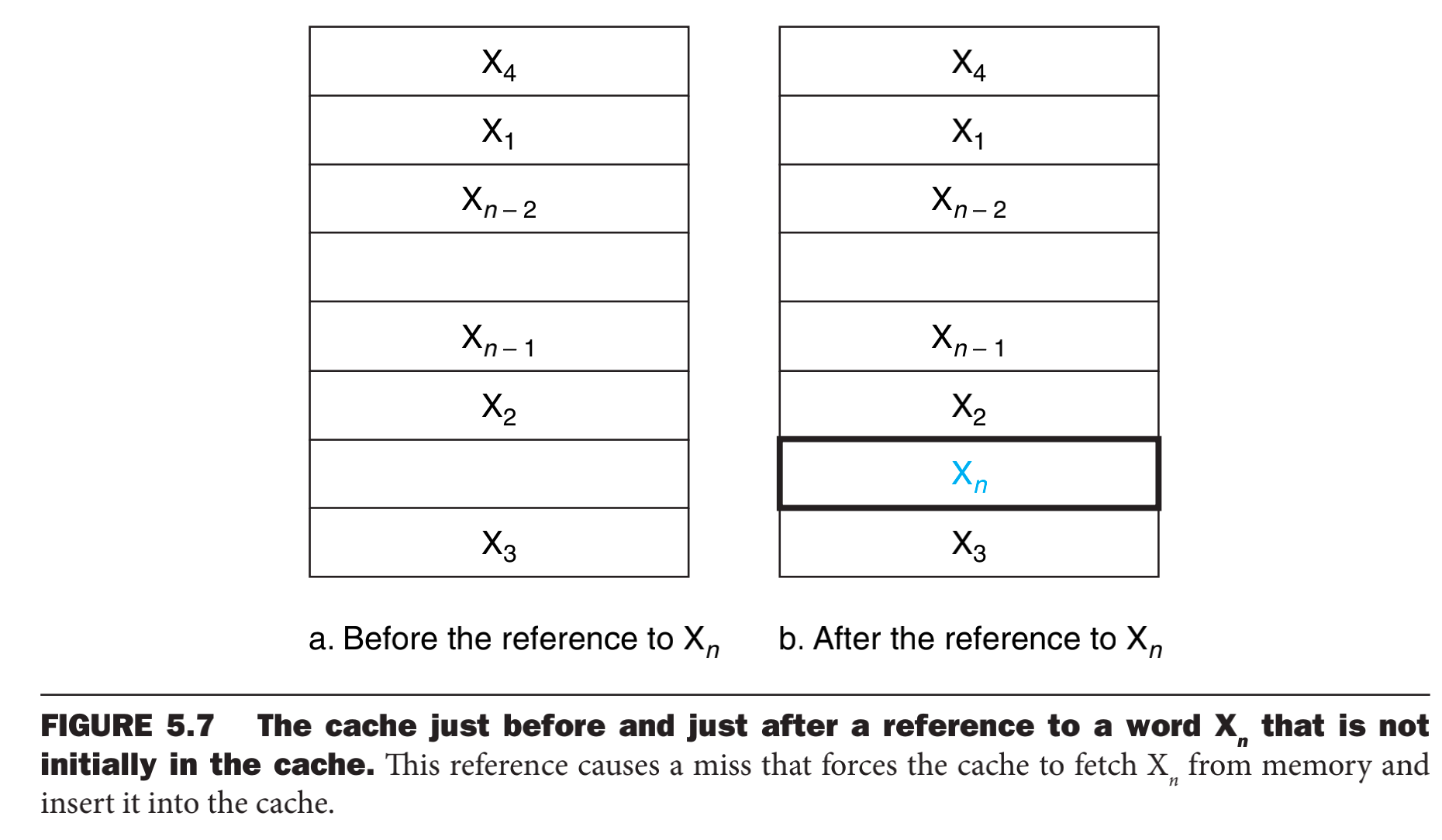
现在目前高速缓冲中存在最近查查询项目x1 x2 xn-1的集合,而处理器请求的xn不在高速缓冲中。当cpu访问引起的一次缺失使得高速缓冲从存储器中取出xn,然后把xn放在cache中。因此,这就引出了两个问题:
- 怎么知道一个数据项是不是在cache中?
- 如果在,那么如何找到它的?
如果每个字都放在cache中确定的位置(用一个地址表示),那么如果他在cache中,我们就知道怎么找到它。给主存的每个字都分配一个cache地址是最简单的方法,通过地址就可以找到cache的数据,这种方法是直接映像高速缓冲(direct mapped),主内存的地址会映射cache内的地址。通常设计的映射关系是:
(块地址)modulo(cache中的块的数量)
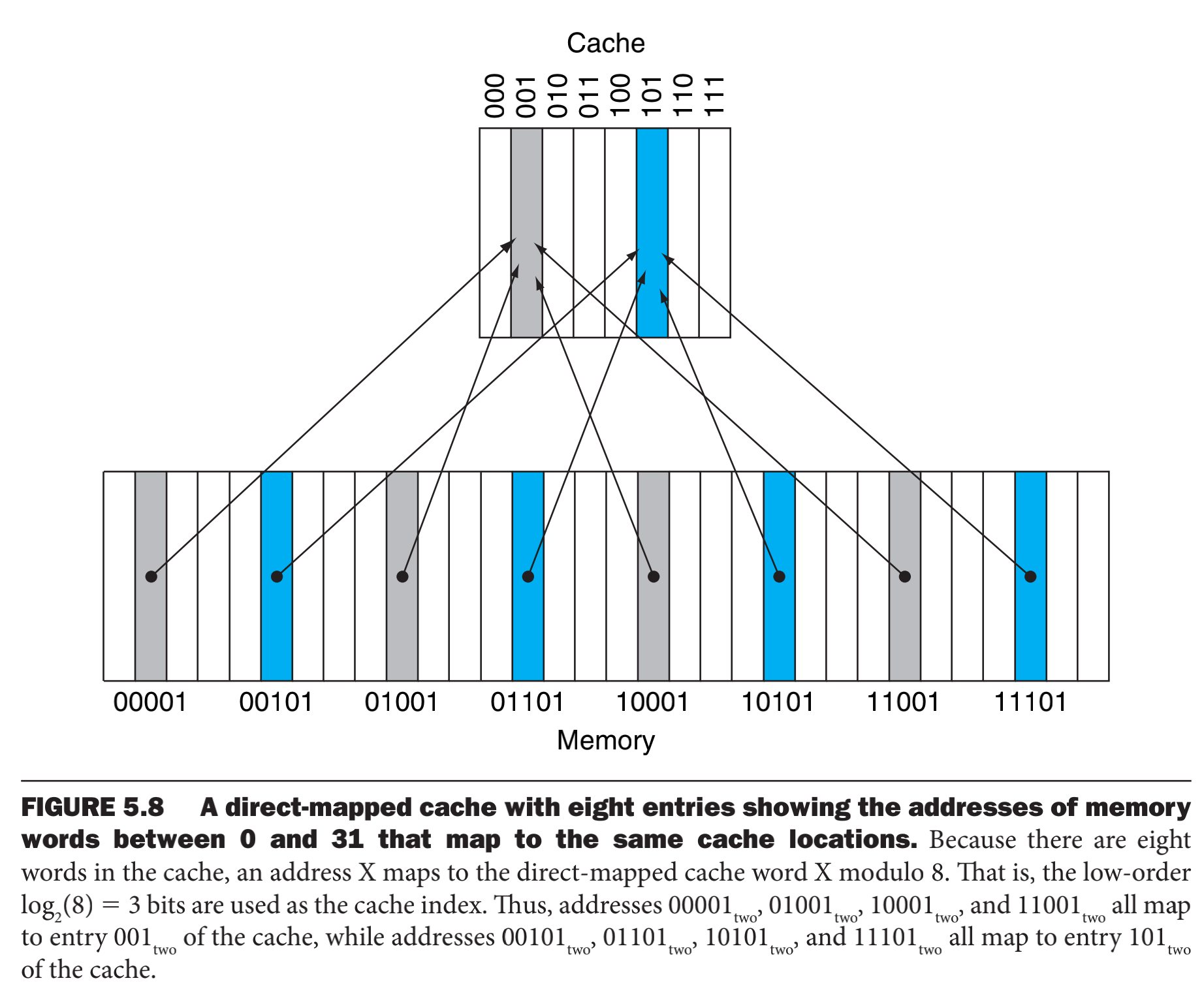
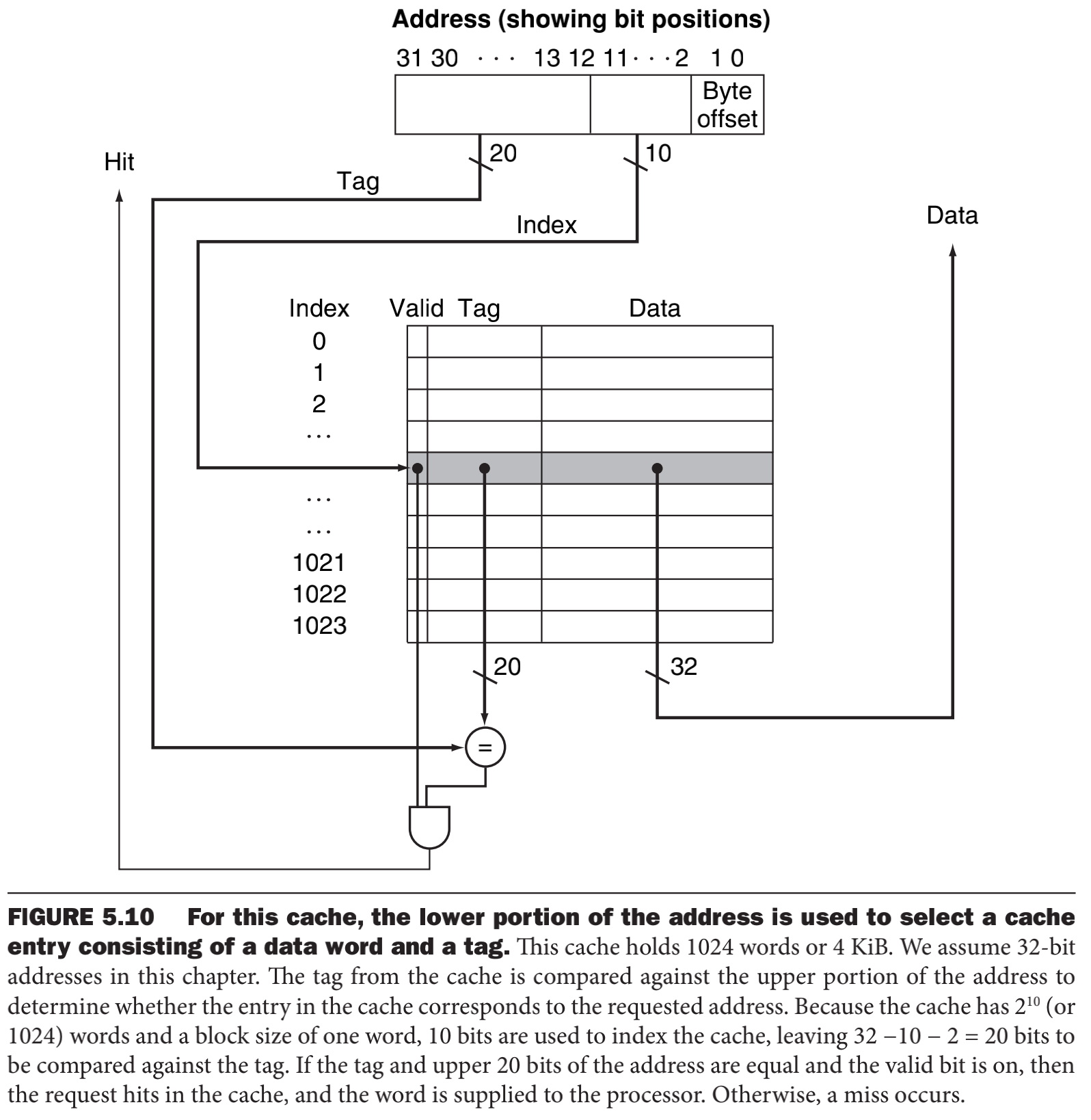
如果cache中数目是2的幂,只需要取地址的低log2(高速缓冲中块的数目)位作为判断,例如一个cache存储块的数目是8个,那么我们就在主存中取低3位作为映射,就是主存地址1(00001) ~ 29(11101)映射到高速缓存地址1(001) ~ 5(101),但是有个问题了,主存的地址在cache中会有重叠和共用的区域,如何去加以区分或者说怎么才能知道请求的字是否在高速缓冲中?这里就引入了**标记(tag)的机制,这里的tag必须能够包含cache中是否是所请求的信息。tag只需要包含地址的高位部分(就是主存中没有用作cache下标那些位)。还需要有效位(valid bit)**来表示是否含有一个有效地址,如果不是一个有效地址不应该被处理器读取。当一个处理器启动的时候,cache通常是空的,有效位都被标记为无效。
2.2 访问cache
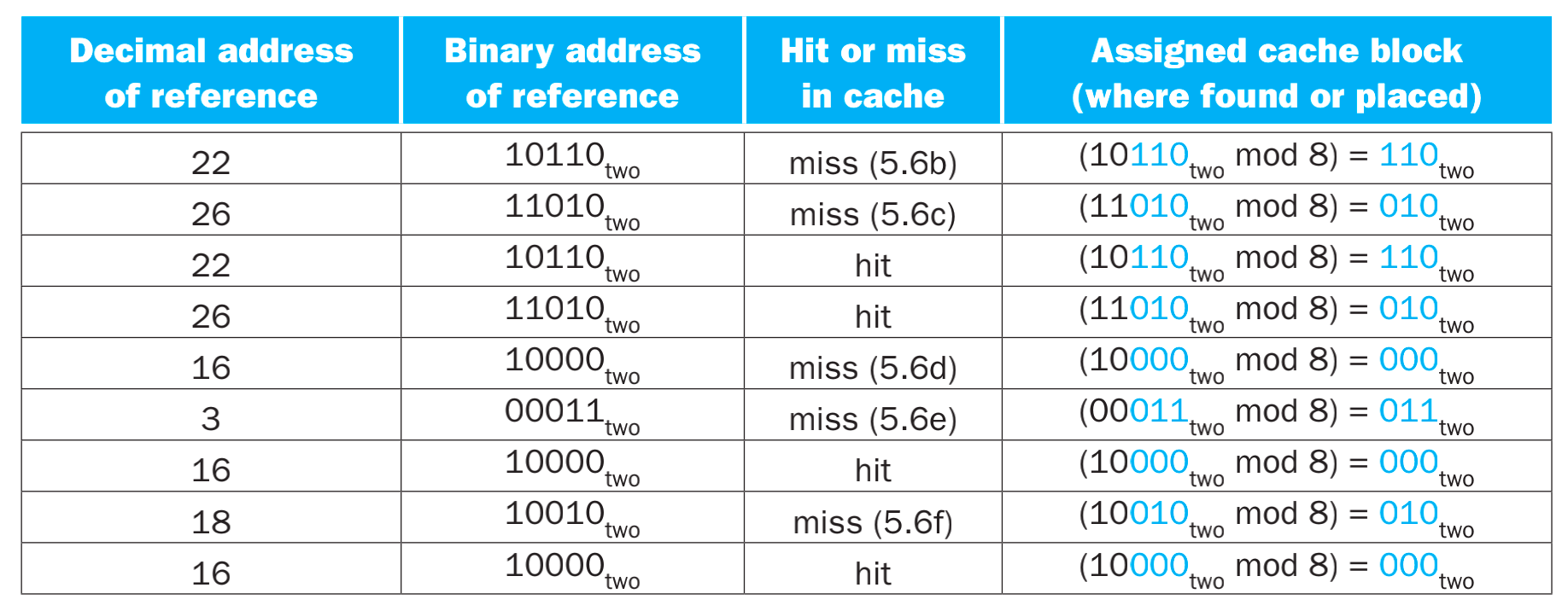
我们来研究一下cache具体如何更新数据的,有一下数据,访问地址顺序就是 22 -> 26 -> 22 -> 26 -> 16 -> 3 -> 16 -> 18 -> 16,注意,这里面18和16的末尾三位都是010,会发生驱逐。
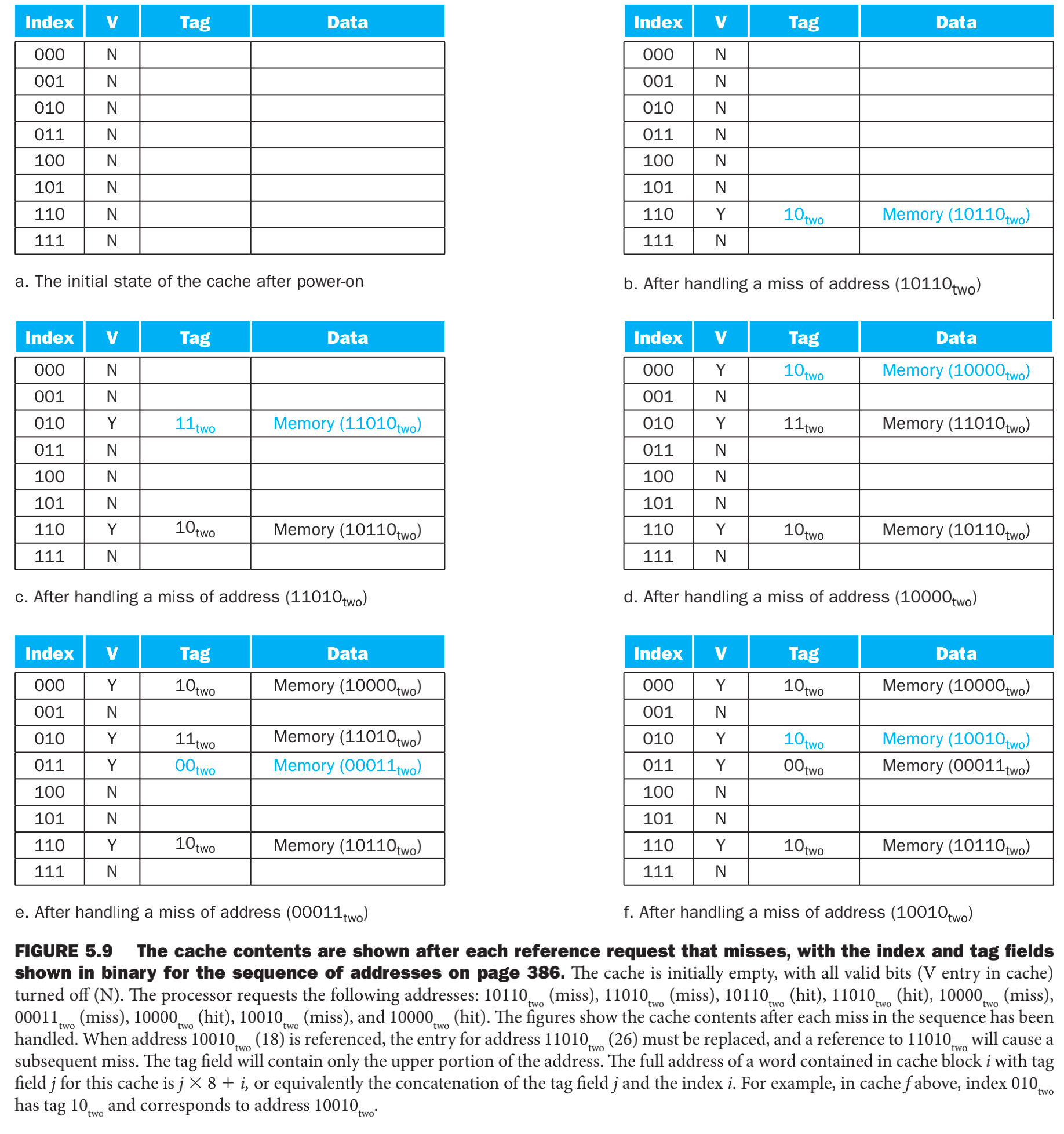
- a. cpu初始化状态,所有的valid bit(V位)都被标记为无效。
- b. 22号地址(10-110B),发现V位是无效地址,产生缺失损失异常,从memory中load 10-110B,Tag被标记为10, 数据被标为10010内存中存储的数据。
- c. 同理,26号地址(11-010B)也是一样,load内存到cache。
- d. 再次访问22号地址,发现V位是有效位,直接读内存数据。
- e. f都同理,只不过f发现tag不一致就会驱逐出以前的数据,把自己放进去。这种举动使得cache具有时间局部性:最近访问过的字节替换较早访问的字。
2.3 cache大小的影响
在图中对比在没有un-cache和cache时候的性能对比,可以看出,在存在cache的系统中,选择合适大小的cache line size可以显著提升效率,但是如果cache size和访问的大小不正确,还不如无缓冲的访问内存3。

cahce block的大小直接影响,升高空间局部性(缺失率下降),如果所示,随着block size的增大, 缺失率下降(不同的去曲线)。这是因为如果是小块,此时高速缓存中块的数目变得小,会发生一些竞争影响效率。这就造成了一个块中的数据在多次访问之前就会被替换出系统,另一方面,对于一个太大的块而言,块中的各个字之间的空间局部性降低,也会影响整体效率。
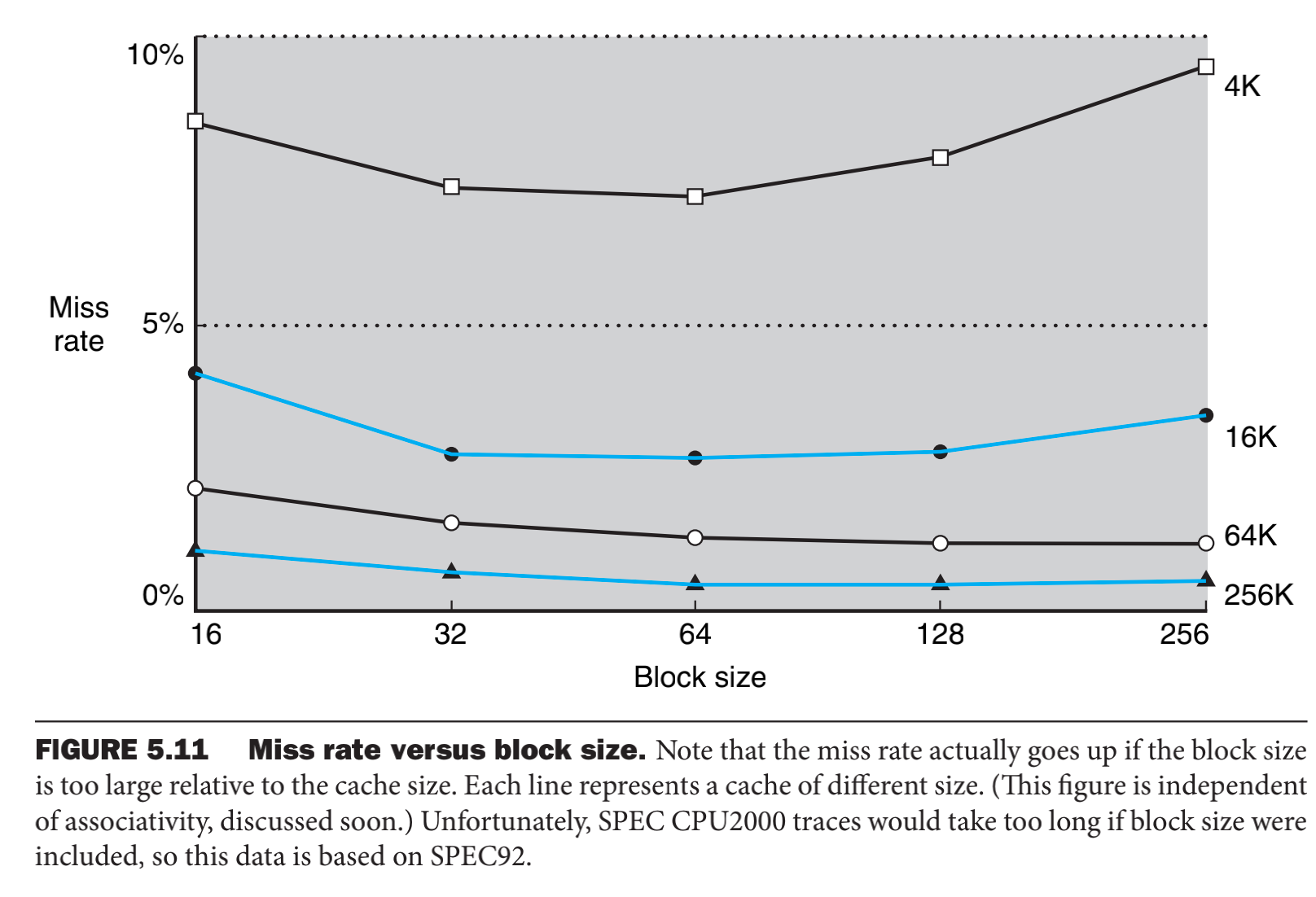
单纯的增大块的大小还会引入一个比较严重的问题,就是缺失时间增大(虽然缺失减少,但发生缺失就需要更长的时间),在缺失之后需要从ram传送到cpu的时间会增加。那如何减少传输时间呢,这样既能提升局部空间性能,又能在缺失的时候加速,从而双向提高效率。最简单的方法是尽早重执行(early restart),就是当所请求的块一旦返回时马上继续执行,而不需要等待整个块传输完毕之后再执行。许多处理器都是这样做的。另一个比较复杂的机制就会重新组织存储器,请求的字优先传到cache,然后再传余下的部分,这种技术被称为请求字优先(requested word first),或者关键字优先(critical word first)。
2.4 cache缺失处理
处理器的控制机制在cache命中的时候不需要做太多的处理;而当缺失的时候,需要从主存(或者低一级的cache)中取出相应的数据来处理缺失。在SOC上面,需要处理器控制机制和一个重填cache的独立控制器共同完成。这里有个问题就是cache缺失导致的一个阻塞,在缺失时间内处理器时阻塞状态的,而不是使用中断,保护中断上下文,在指令流水线阻塞和cache缺失阻塞原理上差不多。
2.4.1 read
得益于多条流水线技术,处理器在一个周期可以执行多个指令。当一条流水线指令发生缺失的时候,指令寄存器的内容无效。为了把正确的指令取到缓冲中,在执行指令的第一个时钟周期计数器加一个增量,因此产生cache缺失的指令地址等于程序计数器-4。一旦有了地址,就可以指示主存储器执行一次读操作,然后把取得的新的字写入到cache中。
- 把程序计数器PC的值-4送入存储器中。
- 指示主存执行一次读操作,并等待主存访问完成。
- 写cache条目,把存储器中读到的cache条目的数据部分,和地址的高位写入标记域,设置有效位。
- 重新执行第一步,此时就能发现指令在高速缓冲中了。
2.4.2 write
2.4.2.1 write-through
写操作比读比较复杂,毕竟读不需要更改数据,而写需要改变数据。假设一个存储指令写入cache,而恰好somehow发生了一些异常,主存和cache相应的数据就会有所不同。这种情况下,高速缓冲和主存之间存在一致性的问题 (inconsistent)。保存主存和cache一致的简单方法就是不仅把数据写入高速缓冲,也把它写入到主存中。这种方法叫做**写通过 (write-through) **。
写操作还值得注意的是,发生缺失的时候。这个过程稍微有点复杂,数据是存储在内存中的,我们西安从内存中取出块字,数据块接着被放入cache,此时发现cache没有有效映射该地址,就引起缺失异常,这里在不同的处理器中有不同的策略回写数据到cache,同时使用完全地址将数据写入主存中。
遵从大多数write-through高速缓冲的策略,有缺失时取(fetch-on-miss)、写时取(fetch-on-write)或者也叫缺失时分配,就是把cache的一块分配给缺失的地址,并且在写数据和继续执行前把块剩余的部分取到cache中。另外我们可以分配cache块但不取数据(写时不取,no-fetch-on-write),或者甚至不分配块**(写时不分配,no-allocate-on-write)**。这种不把写数据放入高速缓存中的策略叫做,写绕过(write-around),因为数据绕过了cache而直接存入了内存。这些机制产生的原因是,有时候程序在读整个块数据之前会先写先写整个块。在这种情况,由初始的写缺失引起的取数据就不必要了。
2.4.2.2 write-buffer
这样的方法十分简单粗暴,但是一些数据表明,每次write-through的方式都会访问主存,大大降低了执行效率,甚至让机器性能降低了10倍多。引入了**写缓冲(write-buffer)**的方法来解决问题。当一个数据在被写入主存的时候,先把它存在写缓冲队列里面,再把写缓冲的数据写入cache,接着处理器继续执行指令。写缓冲队列是一个写敏感的结构,当写入之后,原来的写的条目被释放。如果写缓冲队列满了,就发生了阻塞。为了减小阻塞,通常做法是增大队列深度。
2.4.2.3 write-back
还有一个更高效的方法,写回机制(write-back)。采用写回的方法,新的值仅仅被写入cache中块,而不被刷入内存中的块。只有等到cache这个块被替换的时候,才会把这个块刷入内存中。写回的方法可以提高系统的性能,尤其是当处理器生成写操作的速度和主存的速度一样快甚至更快的时候,缺点也是有的,就是写回机制在处理器实现上面比较复杂。
2.5 cache映像方式
Direct Mapped
到目前为止,当我们把一个块放入cache的时候,用的是简单的定位方式:一个块只能放到cache中的一个位置。如前面所示,这个方式称为直接映像(direct mapped),因为存储器中任意一块地址都能被直接映射到存储层次的更高位置。
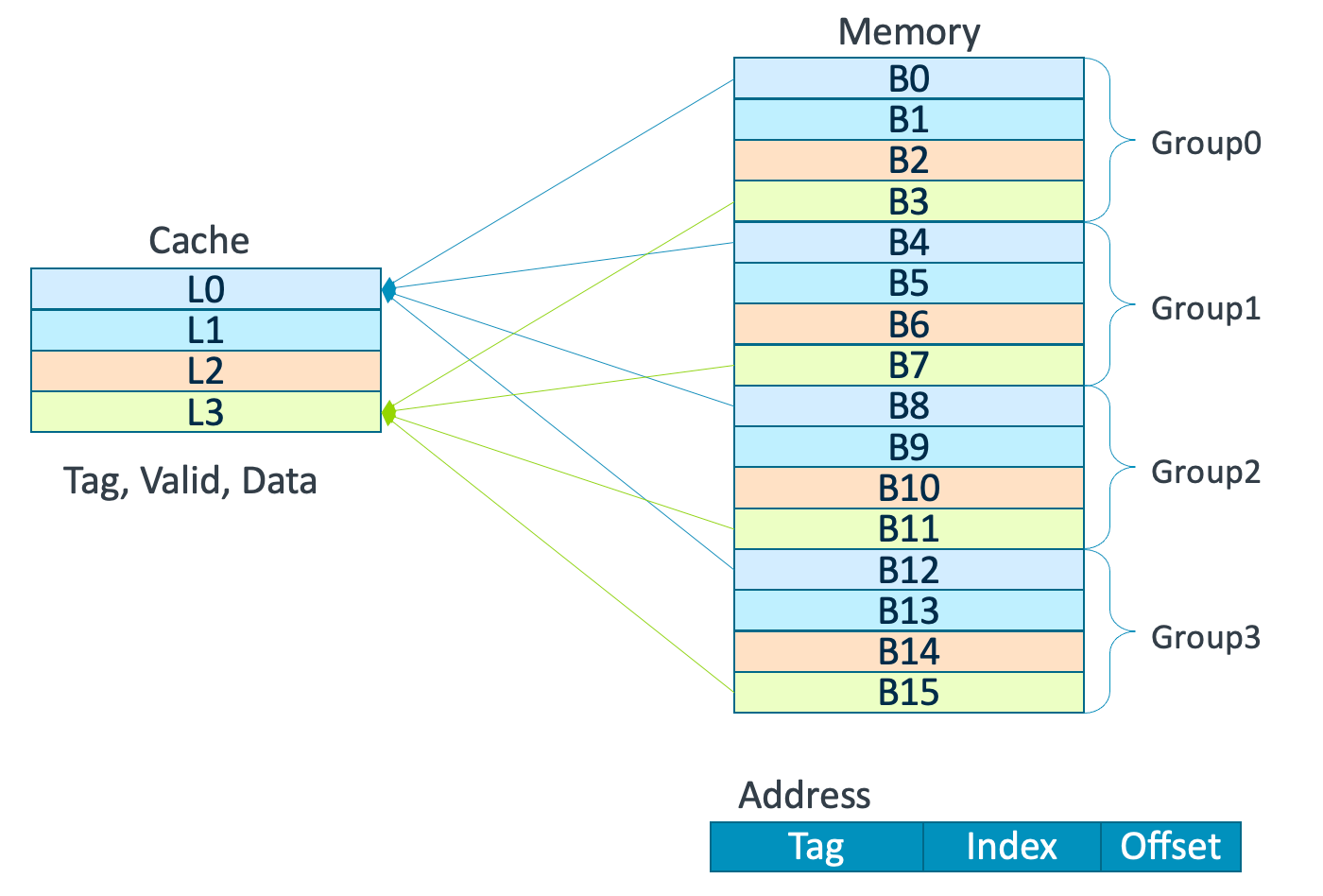
- 所有主存只能存入cache中特定的位置(log2(cache大小))
- 硬件实现简单,成本低。
- 替换操作频繁,命中率较低。
Fully associative
另一个极端的方式是:一个cache块可以放在cache的任意的位置,这叫全相联(Fully associative mapped)。在这种映射方式的cache中要找一个给定块,因为该块可以被放在任意的位置,就必须检索cache中所有的项。为了提高检索效率,它由与cache中每项相关的一个比较器并行完成的。这些比较器增大了硬件的开销,因而这种映射方式只适用于块数量较小的cache。
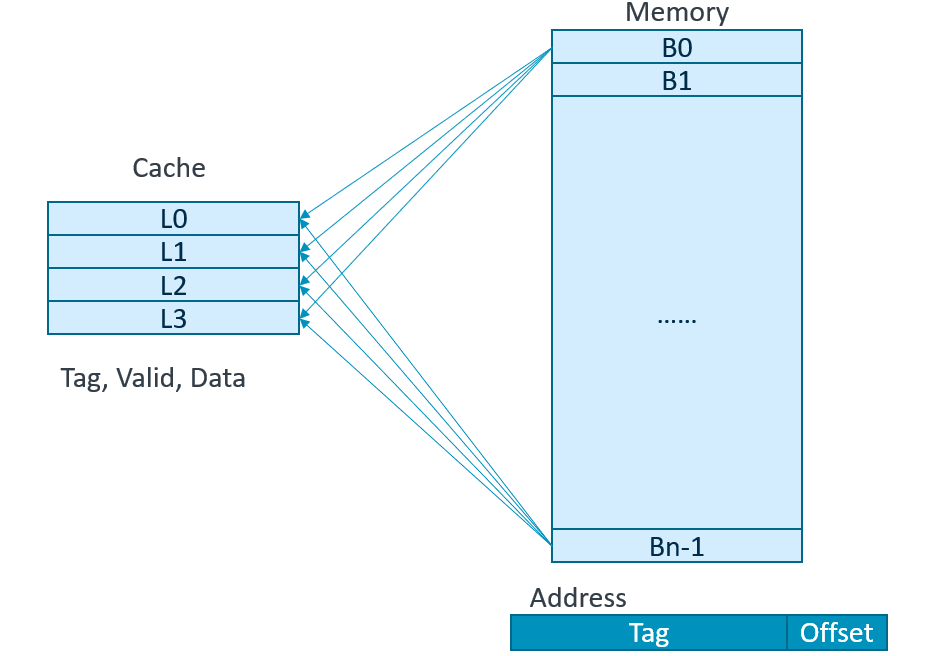
- 所有内存块都能任意映射到任意的缓存块中。
- 命中率较高,缓存存储空间利用率高。
- 速度低,成本高
Set associative
介于直相联和全相联之间的设计称为组相联(set associative mapped)。在一个组相联的cache中,每个块都可以被放在固定数量(至少2个)的位置上;每个块由n个位置可放的组相联cache称为n路组相联cache。一个n路组相联cache由许多组构成,每个组由n个块。存储器每个块由下标域对应cache中唯一的组,并可以放在此组的任意一个块的位置上。因此组相联映像是把直接映像和全相联映像结合起来。
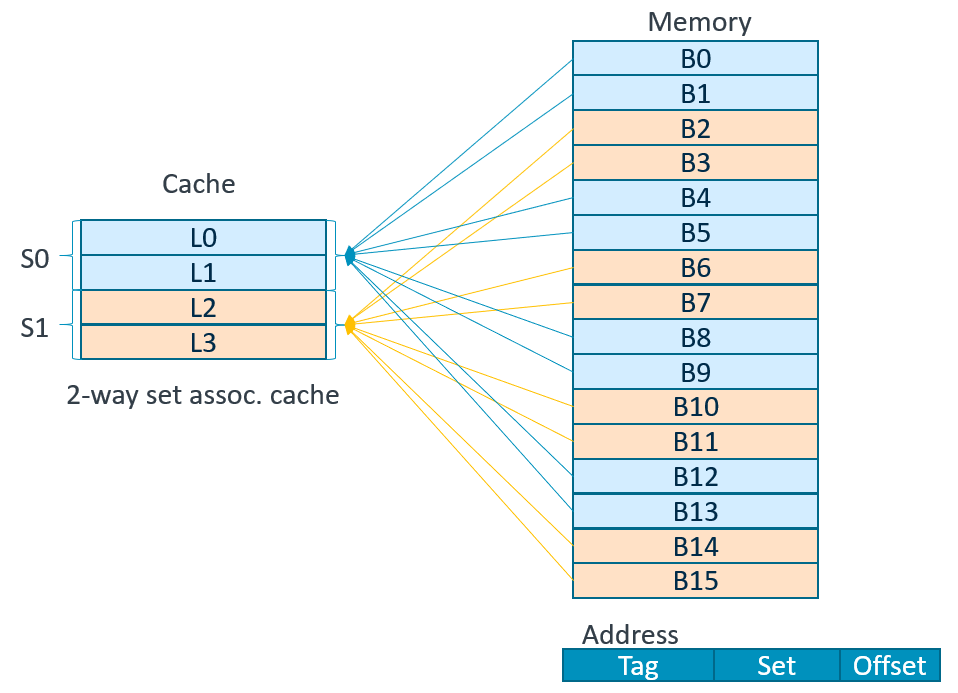
- 组间直相联,组内全相联
- 组号相同
- 组内各个块任意存放
- 块的冲突概率比较低,块利用率大幅提高,块缺失率明显降低。
ARM的CPU就会使用组相联的方式设计Cache:
| CPU | LSZ (Byte) | L1-I | L1D | L2 |
|---|---|---|---|---|
| A9 | 32 | 4-way set assoc. | 4-way set assoc. | 8/16-way set assoc. |
| A53 | 64 | 2-way set assoc. | 4-way set assoc. | 16-way set assoc. up to 2MB |
| M55 | 32 | 2-way set assoc. | 4-way set alloc | O |
- Instruction cache
- Read-Allocate.
- Data cache and unified cache
- Read-Allocate, Write-Allocate.
- Write-Back, Write-Through.
- Transient hints.
数据访问分析
在全相联cache中,块可以放到任何地方因而要检索cache所有的块的标记。如图所示,显示了根据三种联合方式的cache,总容量为8,块12被放置的情况。
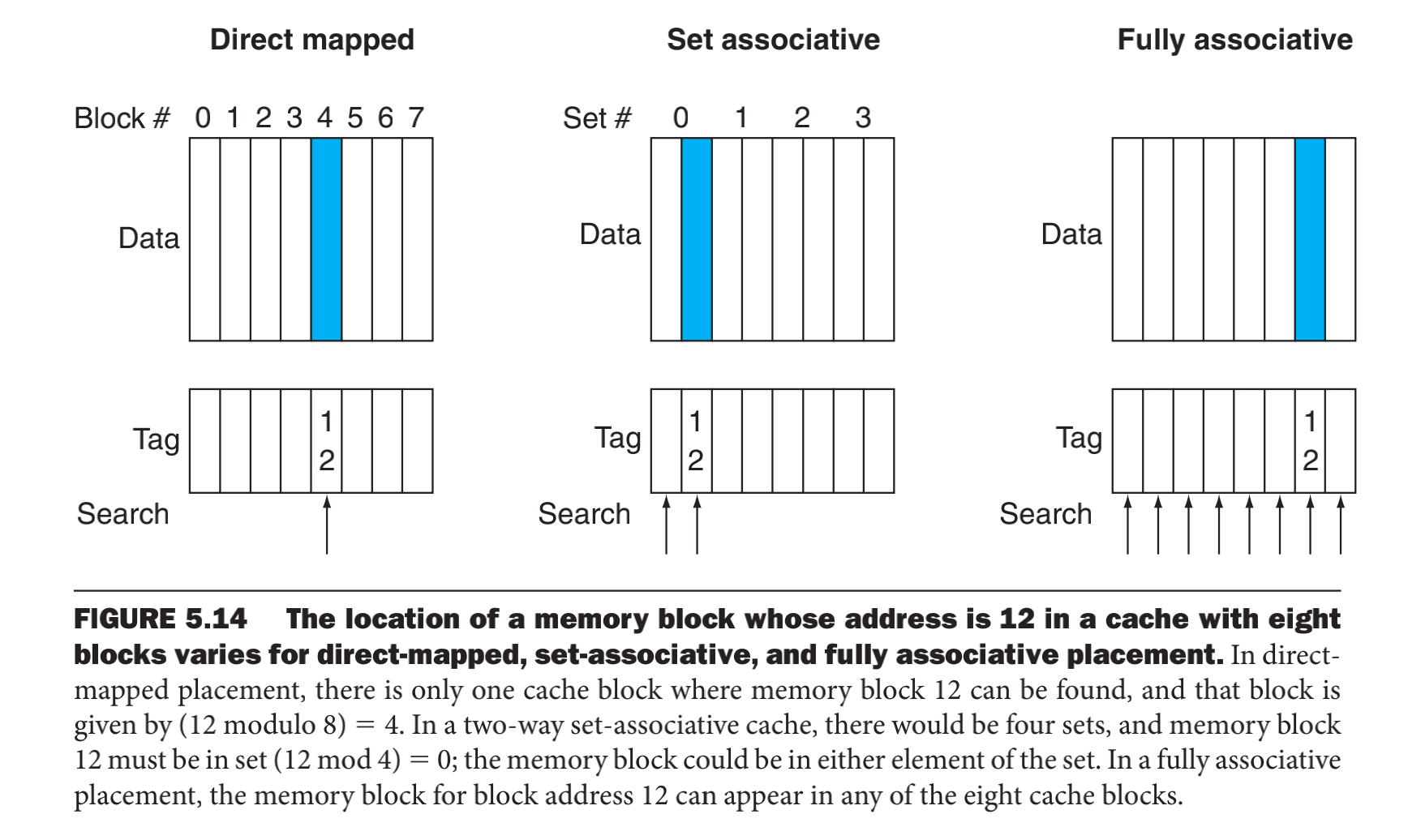
- 在直相联方式下,主存块12只能防在一个高速缓存块中,该块为12%8 = 4。
- 在2路组相联高速缓冲中,有4个组,主存块12必须放在组(12%4=0)中,可以放在该组的任意一块。
- 在全相联cache中,地址为12的主存块可以出现在cache中8个块的任何一块。
2.5 associativity
associativity是cache一个重要的特性,组相联的时候如果一个way中cache line数量越多,那么他的asociativity越好,cache line越多则出西安cache thrashing的概率就越低。但是这同样是有代价的,最大的代价体现在硬件上面,更多的cache line会让每次访问变慢。而且每行需要更多的bits来作为一些算法的判定依据,例如LRU就需要state位。更多的cache line还会增加命中时间。
当直接映像的高速缓冲产生缺失,被请求的块只能进入cache中的一个位置,而占用了该位置的块就会被驱逐。在组相联的cache中,放置被请求的块要做选择,因此驱逐哪一个块也要做选择。在全相联的cache中,所有的块都有可能被替换掉。在组相联的cache中,我们需要在选定组中的块里面进行选择。最常用的方法是最近最少使用法(LRU)。在LRU方法中,被替换的块就是最久没有使用的块。LRU替换算法的实现是通过追踪组中每一块的相对使用情况。对一个2路的组相联高速缓冲来说,追踪何时用到块中的两个单元是这样实现的,在每个组里单独保留一位,该位指示了哪个单元刚被访问过。当可associativity提高的时候,实现LRU就困难些,这部分和MMU的缺页算法有些类似4。这部分有人有人做了很多研究,如下图5,可以看见不同算法在页大小和cache命中率的影响。
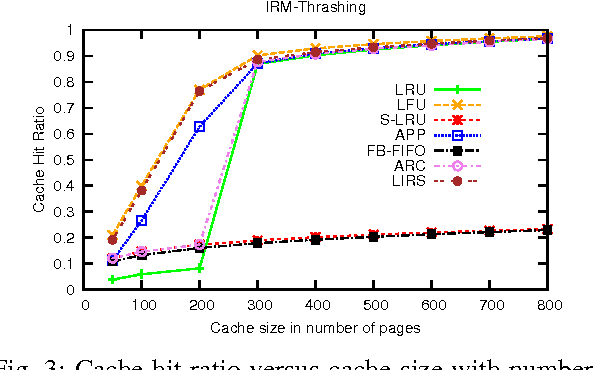
在Cortex-A57处理器中,L1采用LRU算法,L2采用随机法;Cortex-A72处理器中,L2采用为随机法或者伪LRU法;Intel I7处理器中,L1和L2都采用8-way,L3采用16-ways。
Cache thrashing复现6
在组相联的模式中存在一种cache thrashing的问题(抖动),cache thrashing会导致cache的性能非常差,在有cache的情况下,被程序无缓存的使用内存。我们如何复现这种情况呢?假设cache是2ways组相联模式。
#define MAX_SIZE (1024*1024) // 4MB size
char a[MAX_SIZE], b[MAX_SIZE], c[MAX_SIZE], d[MAX_SIZE];
void cache_thrashing(void)
{
int i = 0;
for (i = 1; i < MAX_SIZE; i++) {
a[i] = b[i] + c[i]*d[i];
}
}我们分配的abcd四个数组每一个都是4MB的大小,因此这四个元素地址的低22位是相同的,在组相联模式下,cache被关联到不同的way的相同行号的cache line。
执行i的操作:
- 为了执行运算,a[i], b[i], c[i], d[i]必须同时驻留在内存中
- 执行 c[i] * d[i],此时由于cache line是2个ways,即便是c[i]和d[i]的低22位地址一致,通过tag也能将c和d区分开。c和d的计算结果被暂时保存到寄存器里面,不涉及cache访问。
- 执行b[i] + 操作,此时c[i]的cache line需要被逐出(假设c在2步最先被load)
- 为了保存结果a的结果,d所在cache line也需要被逐出。
接着执行i+1操作
- 需要计算c[i+1]*d[i+1],但是d和c的cache line 已经被逐出,所以需要逐出a和b的cache line 再重新加载d和c的cache line。
- 再计算 b[i+1] + 操作的时候也一样。
通过这么几个步骤的运算,可以看出每一步操作都cache都被换入换出到主存里面,这就是有cache的情况,却无缓冲的使用内存,也就称为cache strashing。我们也观察到了,能够构成这种情况的原因是:
- 偶然的数组对齐,让低地址一致,使之cache line被映射到通过一个位置。
- N个数组同时运算,N超过了ways的数量。
那么我们该如何做呢?
- 当发生多个数组运算的时候,分配空间时,使其不要为2的幂次,一个新的size将溢出一条cache line,这就使得a,b,c,d向量在cache上映射到了不同的位置,此时4个值可能同时驻留在cache里面。
- 或者将多维数组改为奇数。
cache trashing使得循环至少增加100倍的效率。
2.6 多级cache
现代的计算机或者微控制器都使用了cache。在大多数情况下,cache和cpu都集成到一个芯片上。为了进一步缩小高时钟频率和访问DRAM相对较慢之间的差距,高性能处理器通常都会再增加一级cache。这种二级的cache,位于处理器芯片内或者是位于处理器芯片外部的单独SRAM,当访问近cpu的cache缺失之后,就会访问二级cache。如果二级cache包含请求的数据,缺失损失就是二级cache访问的时间,这要比主存的访问时间要少的多。如果两集cache都不包含这个数据,那么就产生了更大的缺失时间。有数据显示,有二级cache的处理器性能是没有二级cache的性能的2.8倍。
一级cache和二级cache因为分工不同,所以使命也不一样。两级cache互相作用允许有各有偏重。由于二级cache的存在,一级cache的缺失损失大为减少,这就允许一级cache做得小一些,缺失率高也没有关系。对二级cache而言,由于一级cache的存在,访问时间已经不再重要,因为二级cache的缓存的访问时间只影响一级cache缺失的时间,而不直接影响一级cache命中时间或者处理时间。因此,一级cache比较小,块也小。二级cache要比一级cache更大,而且块也要比一级的更大。
2.6.1 cache line size
这个程序是读取数组memory以不同的大小,来测试cpu分级存储的性能。下面的实验真实机器上通过调整程序访存模式来探测多级 cache 结构以及 TLB 的大小。
long data[MAXELEMS]; /* The global array we’ll be traversing */
/* test - Iterate over first "elems" elements of array "data" with
* stride of "stride", using4x4 loop unrolling.
*/
int test(int elems, int stride)
{
long i, sx2 = stride*2, sx3 = stride*3, sx4 = stride*4;
long acc0 = 0, acc1 = 0, acc2 = 0, acc3 = 0;
long length = elems;
long limit = length - sx4;
/* Combine 4 elements at a time */
for (i = 0; i < limit; i += sx4) {
acc0 = acc0 + data[i];
acc1 = acc1 + data[i+stride];
acc2 = acc2 + data[i+sx2];
acc3 = acc3 + data[i+sx3];
}
/* Finish any remaining elements */
for (; i < length; i++) {
acc0 = acc0 + data[i];
}
return ((acc0 + acc1) + (acc2 + acc3));
}
/* run - Run test(elems, stride) and return read throughput (MB/s).
* "size" is in bytes, "stride" is in array elements, and Mhz is
* CPU clock frequency in Mhz.
*/
double run(int size, int stride, double Mhz)
{
double cycles;
int elems = size / sizeof(double);
test(elems, stride); /* Warm up the cache */
cycles = fcyc2(test, elems, stride, 0); /* Call test(elems,stride) */
return (size / stride) / (cycles / Mhz); /* Convert cycles to MB/s */
}测试代码如上,我们来做个假设:
- 如果一次性访问的数据stride能够完整的被cache line(块)大小cover,那么就花很少的时间可以访问到。
- 如果一次性访问的数据stride超过了cache line(块)大小,那么存在一部分数据需要到二级cache甚至三级cache中才能访问到,增加了缺失时间。
我们来观察一下,这个计算机:
- L1 D-Cache: 32KB
- L2 Cache: 256KB
- L3 Cache: 8MB
- Cache line(block): 64 - bytes
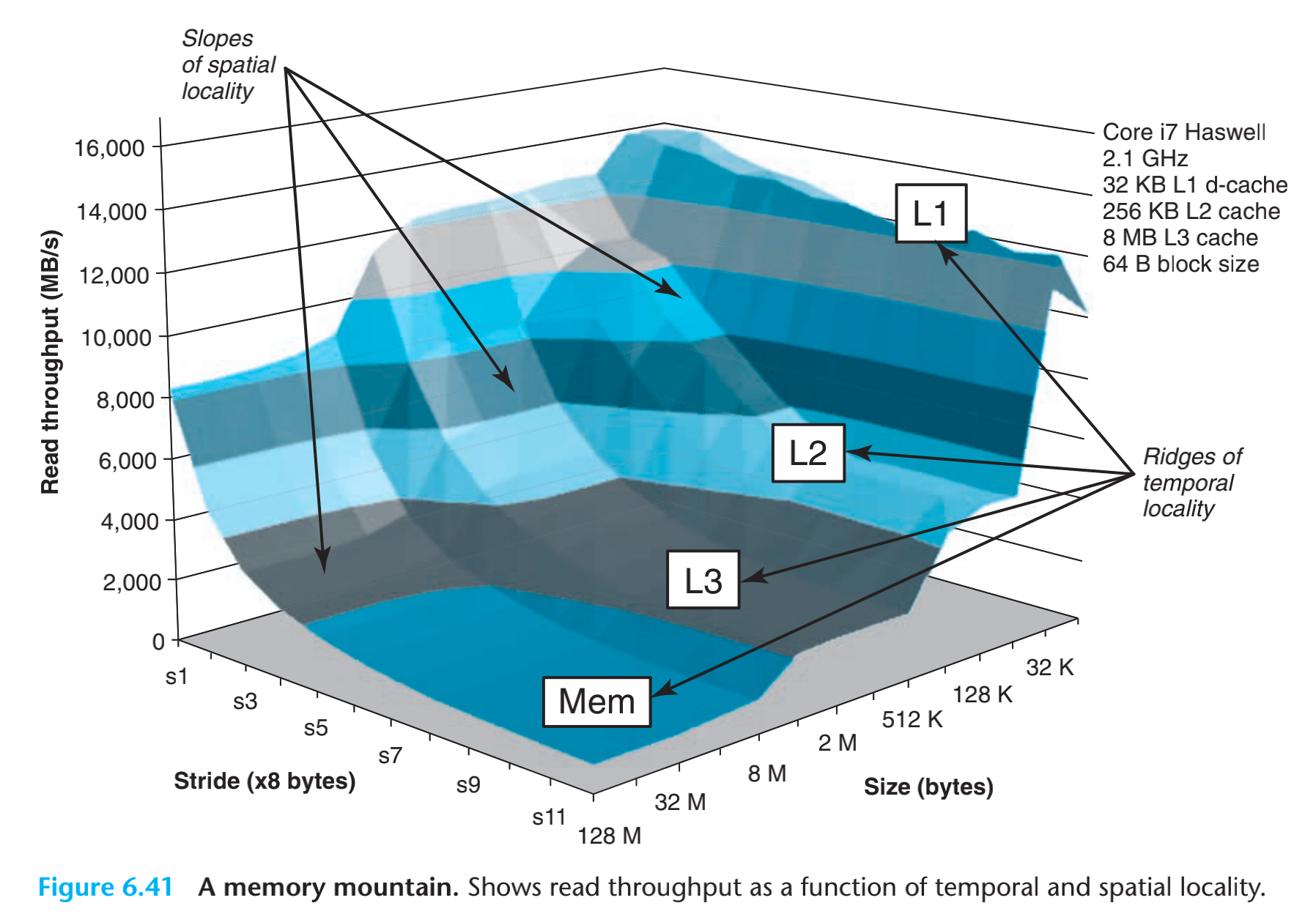
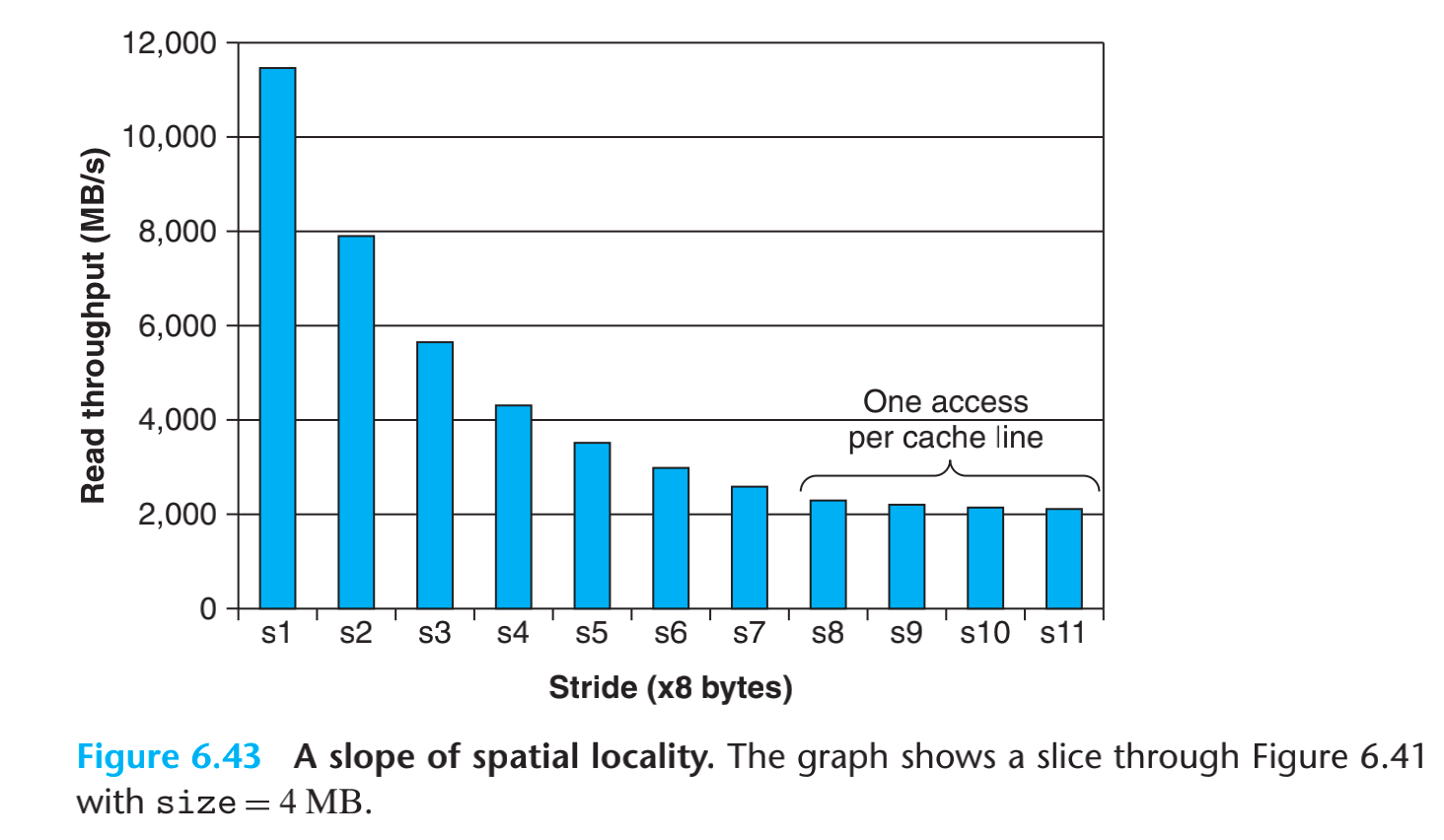
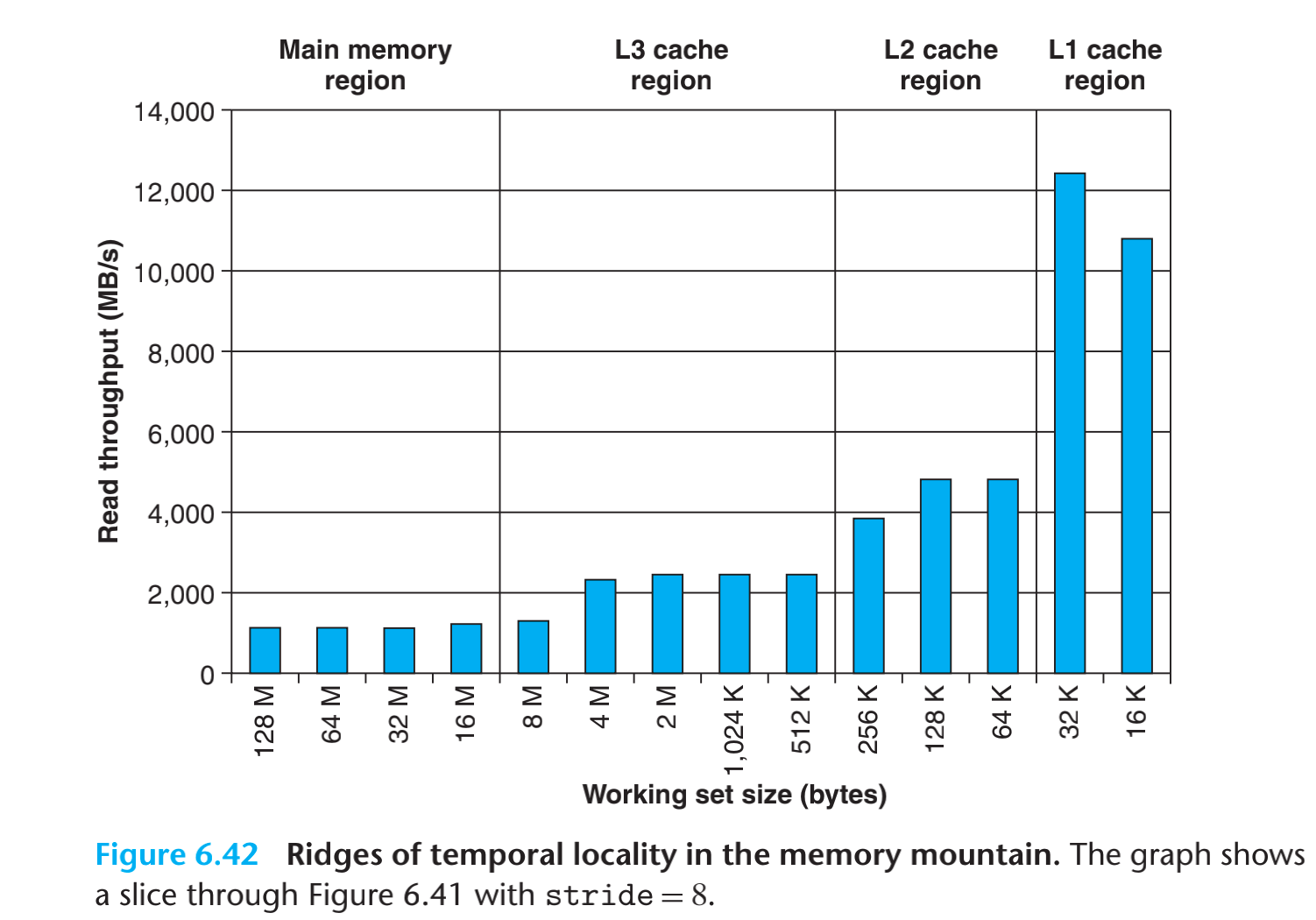
从图中可以看到,stride位8byte,且读取size位32K,刚好一个L1cache的大小的时候性能是最好的。当访问size,进入L2的时候性能几乎掉了60%,当进入L3的时候性能在L2的基础上又降低了40%。
当size是4MB的,布长也是有影响的,s7的时候刚好是64byte(cache line size),超过s7的时候性能基本没有变化。
 |
 |
|---|
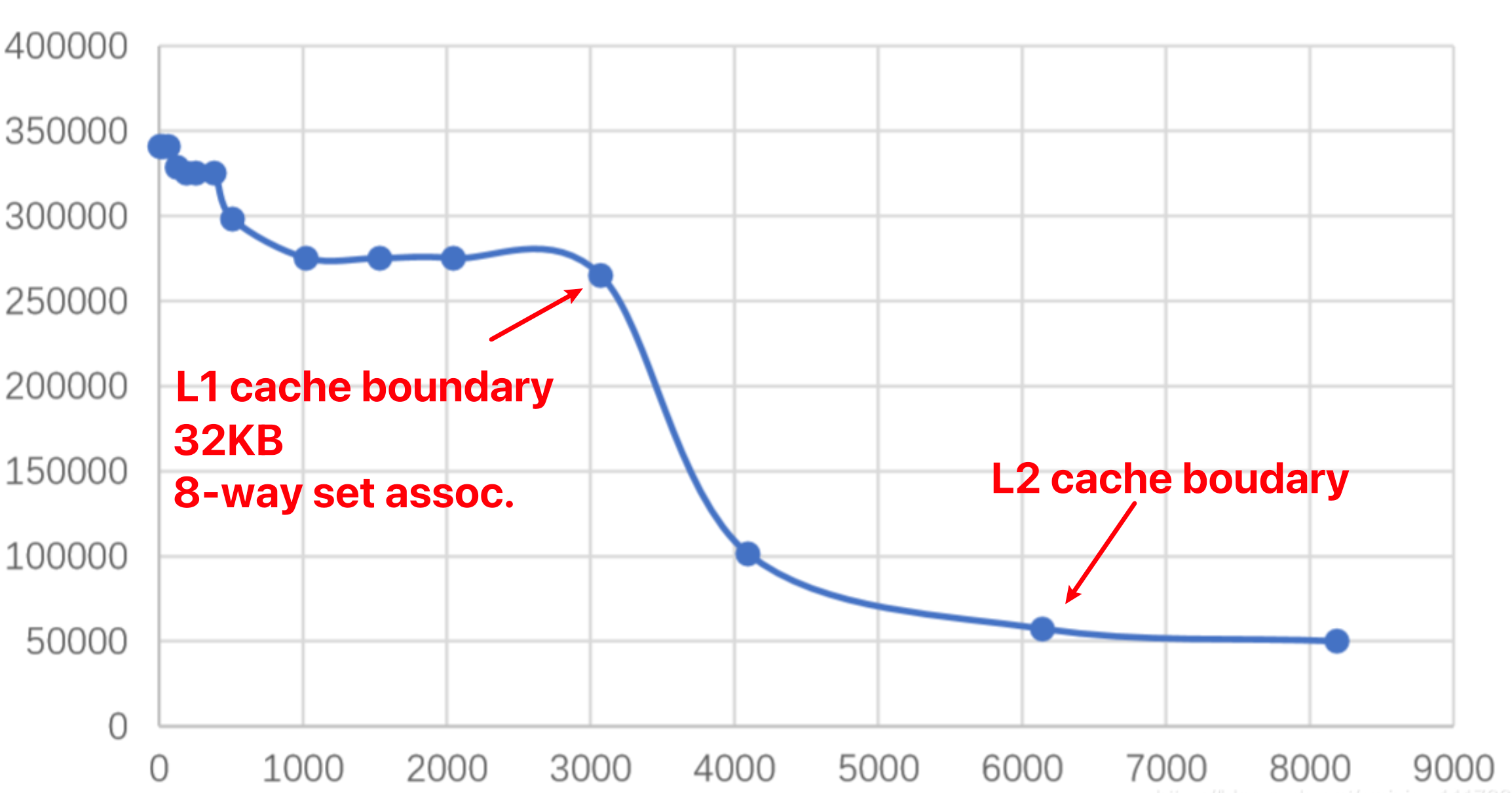
有学生也在windows下做了相应的测试7,得到了一样的结论。
 |
 |
|---|
总体上来看,缺失时间对数据访问效率影响是很大的。
2.6.2 横向与纵向遍历
2.6.2.1 二维数组
从另一个角度,我们从二维数组的横向遍历和纵向遍历时间消耗也能体会到缺失时间对性能影响的证据。数组的第一个索引是纵向,第二个索引是横向,可以见到如下代码8。
int[][] array = new int[64 * 1024][1024];
//横向遍历 80ms
for(int i = 0; i < 64 * 1024; i ++)
for(int j = 0; j < 1024; j ++)
array[i][j] ++;
// 纵向遍历 2100+ms
for(int i = 0; i < 1024; i ++)
for(int j = 0; j < 64 * 1024; j ++)
array[j][i] ++;
- 横向遍历,int i =0 ,int j=0 时 CPU需要获取array[0][0]的值,
- CPU某个核 尝试从CPU缓存读取该数据 未命中
- 缓存中不存在则去读取主内存,而缓存的最小单位是缓存行(通常为64字节)
- 一个int所占字节为4,则这一次从主内存获取到了:
- array[0][0]、array[0][1]...array[0,15],并将这16个值放入缓存中。
- 后续的15次遍历(i=0,j=1,2,3,4...15)都将从缓存中命中。
- 读取array[0][17],访问CPU缓存,未命中。则重复步骤2。
所以,大部分情况下CPU都可以从缓存中命中到需要遍历的值。
- 纵向遍历,int i =0 ,int j=0 时 CPU需要获取array[0][0]的值,
- (1)、(2)相同
- (3)int i=0,int j = 1 则需要获取array[1][0]的值,而缓存行中没有存放array[1][0]的值,
只能重复步骤(2)从内存中读取。
2.6.2.2 三维数组
这部分我作为结论了解一下就好了,再往下深究就没边了。通常三维数组用于矩阵的乘法。
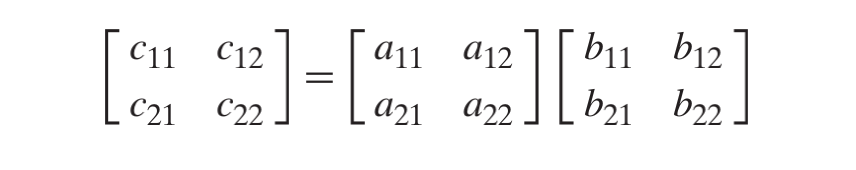
那么对于运算矩阵乘法有以下的6种可能性:

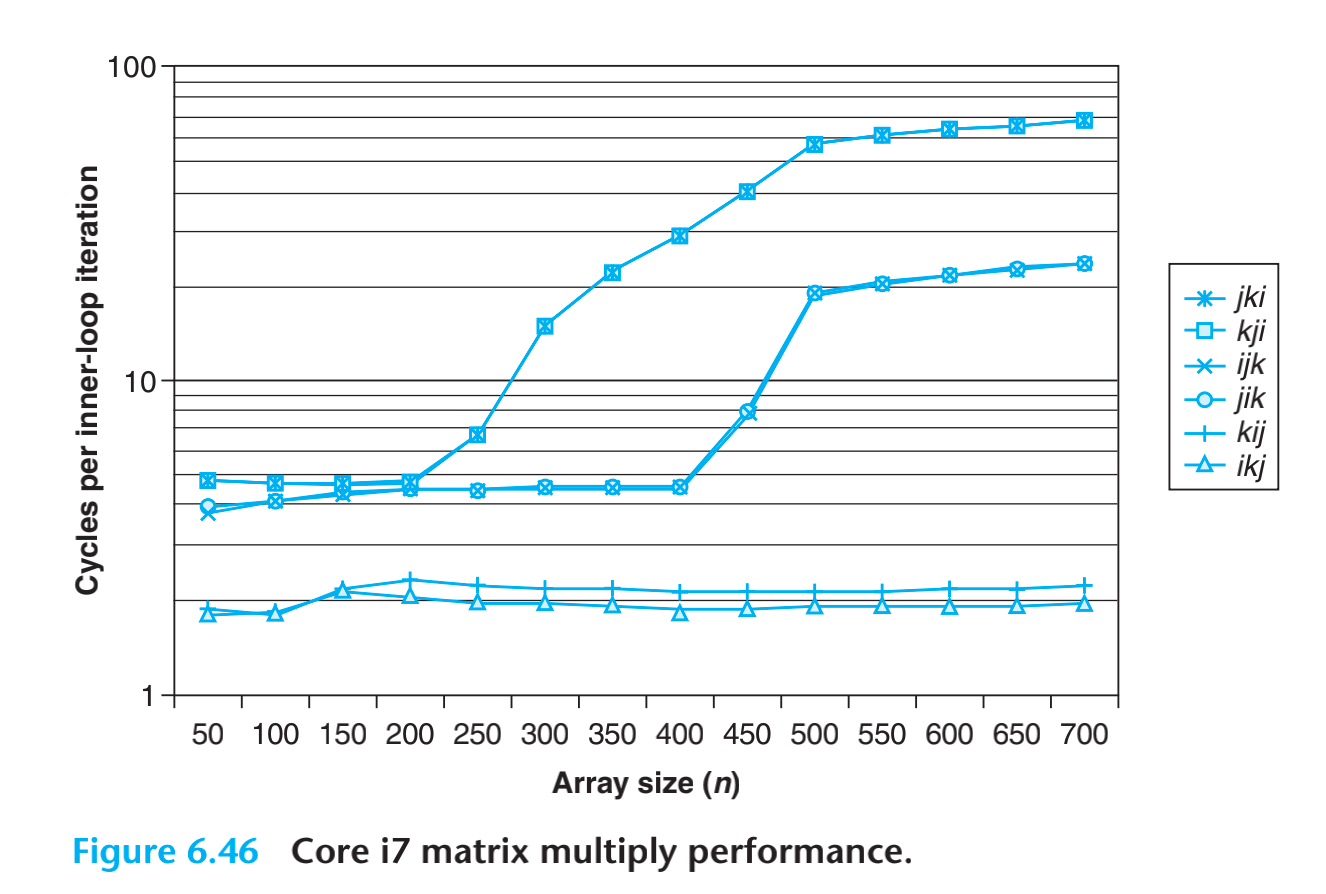
我们可以看到性能:
- jki / kji 性能最高
- ijk / jik 性能其次,是最差和最优的中间的位置
- kij / ikj 性能最差
可以得到结论,如果两个数组都是按照cache line的方向且按照cache line的大小取值的,那就收获最好的吞吐率。反之,就是最差的吞吐率。
关于程序的性能,我们需要有更深层级的架构理解。很多算法我们并不能理所应当的从复杂度的角度来评判性能,除了算法的复杂度,也有架构层级设计的影响问题。标准的算法分析忽视了存储器层次的影响,只是单独的从算法逻辑的角度去分析。合理的去使用存储器结构对于高性能就十分关键。
3 MMU、Cache与TLB
Cache的作用和术语我们上面的部分已经整理下来了,接下来就是我们把cache放在系统中,看看cache 如何发挥的作用。在一些处理器中cache和mmu是两个单独的模块,而在一些处理器中常常把mmu和cache绑定在一起,我觉得这样也是合理的。严格意义来讲,MMU的作用只是虚拟地址转换物理地址的工具,并没有提供任何加速的功能,反而因为硬件级别的映射,多了查找的消耗,反而在寻址上面减慢了速度。像TLB和Cache的提出,也正是来减缓这种损失(TLB作用),甚至起到了加速的作用(cache作用)。
CPU发出物理地址(逻辑地址),进入到MMU模块,接着在TLB中查找这个地址是不是已经映射了,如果tlb命中那么就把这个地址移交到cache来读取该地址的数据,如果cache命中,则直接可以把地址的数据递交给cpu,如果cache没有命中,则阻塞cpu等待cache的替换;如果tlb层级没有命中,则发生缺页异常,进入到cpu的异常处理流程,换页之后再重新执行指令递交给cache。从这个比较上层的层级来看,TLB存储的是虚拟地址和物理地址的映射关系,而cache存储的物理地址和地址里面存储的数据的关系。在每个处理器里面设计者不得不根据实际情况来确定TLB条目、cache大小结构、MMU页帧大小。我们这里可以引用文献1提供的经典数据,作为一个参考:
- TLB size:16~512个项
- block size:1 ~ 2 页表项
- 命中时间: 0.5 ~ 1时钟周期
- 缺页损失: 10 ~ 100个时钟周期
- 缺失率: 0.01% ~ 1%
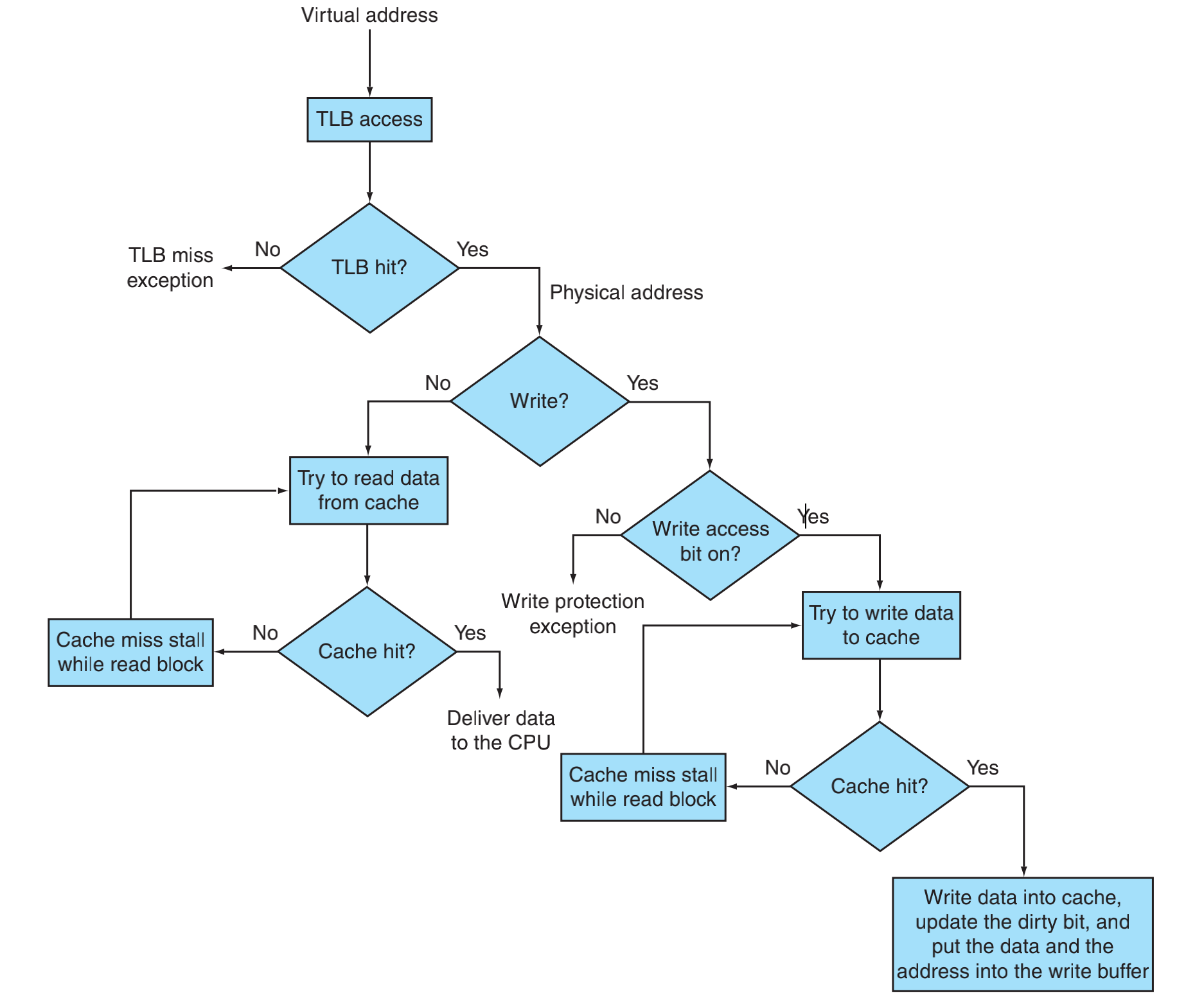
我们来研究一下具体MMU、TLB、Cache怎么工作的,下图是内置FastMATH的MMU、TLB和Cache,这个cache设计的是全相联的,由指令和数据访问共享。
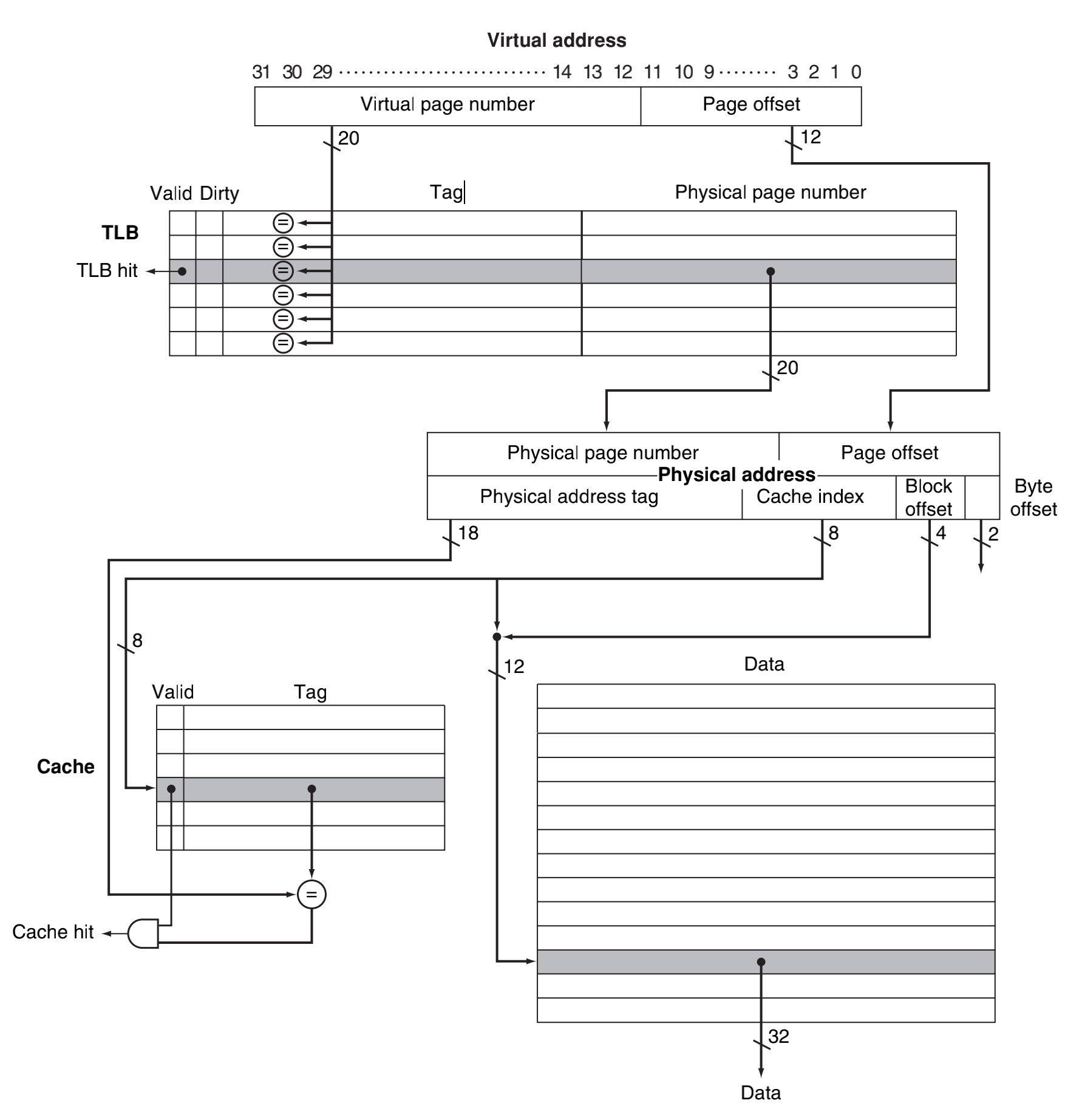
cpu发出一个虚拟地址请求:
- TLB命中
- 如果没有命中,产生一个TLB缺失异常。
- 如果命中,提取物理地址
- 如果是读操作
- 在cache中查找地址
- cache命中,传输数据到cpu
- 没有命中miss stall阻塞等待刷cache
- 在cache中查找地址
- 如果是写操作
- 写访问位是否允许?
- 不允许写,触发保护异常
- 允许写,准备向cache写数据
- cache命中,写数据进入到cache,更新dirty bit,并且把数据写入到那个地址的内存里。
- cache没有命中,cache miss stall,等待刷cache
- 写访问位是否允许?
- 如果是读操作