21_ARMv8_barrier(二)内存屏障案例
carloscn opened this issue · 0 comments
21_ARMv8_barrier(二)内存屏障案例
本节通过具体的案例对使用barrier的场景进行分析,这里一共是12个场景。
- 消息传递问题
- 单方向内存屏障和自旋锁
- 多核异构的通信机制MailBox传递消息
- 单核/多核系统发送消息(d-cache相关)
- 无效DMA缓冲(d-cache相关)
- 单核/多核处理器修改代码(i-cache相关)
- 单核/多核处理器系统更新页表(TLB相关)
- BBM机制更新页表(TLB相关)
- DMA案例
- 存储缓冲区和写内存屏障指令
- 无效队列与读内存屏障指令
- Linux内核中的内存屏障指令
1. 消息传递问题
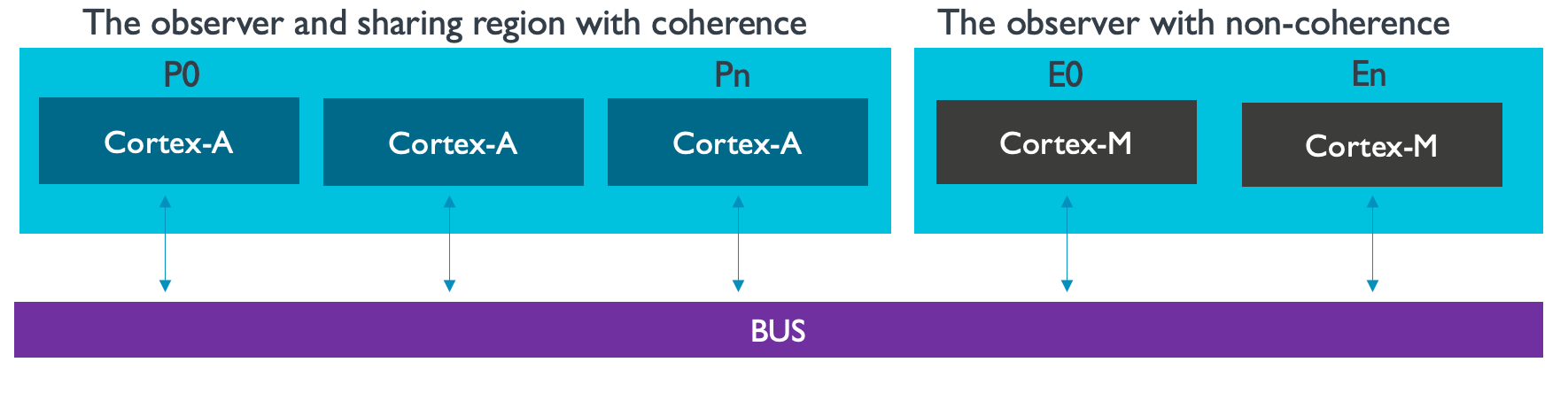
需要对场景进行假设,如图所示,p0~pn是高速缓冲一致性观察范围内的CPU,而e0-e1是没有cache一致性观察范围内的CPU。
【例1】在弱一致性内存模型下,CPU1和CPU2通过传递以下代码片段来传递消息。
//CPU1
str x5, [x1]
str x0, [x2]
//CPU2
WAIT([x2]==1)
ldr x5, [x1]这个原始的目的是,CPU把x5的值存储到x1内的地址中,接着x2寄存器为标志位寄存器用于CPU2的判定,如果判定完毕,会把数据从x1寄存器内的地址存入x5。这是正常的思维,但是CPU执行的时候因为x1和x2和x5之间没有依赖,因此可能发生乱序执行:先标志位置位后再修改x5的值,那么就会发生错误。
解决方案一:通过带有内存屏障的stlr来代替str,使之具备序的要求。
//CPU1
str x5, [x1]
stlr x0, [x2] // use stlr
//CPU2
WAIT([x2]==1)
ldr x5, [x1]解决方案二:在CPU中塑造寄存器依赖来有序的要求。
//CPU1
str x5, [x1]
stlr x0, [x2] // use stlr
//CPU2
WAIT([x2]==1)
and w12, w12, wzr
ldr x5, [x1,w12] // w12产生依赖2. 单方向内存屏障和自旋锁
ARMv8指令集把加载-获取和存储-释放内存屏障原语集成到了独占内存访问指令中。根据结合的情况,分成下面4种情况:
- 没有集成屏障功能的LDXR和STXR指令。note,ARM64的指令的写法是LDXR和STXR,ARM32的指令写法是LDREX和STREX。
- 仅仅集成了加载-获取内存功能的是:LDAXR STXR
- 仅仅集成了存储-释放内存功能的是:LDXR STLXR
- both加载-获取和存储-释放的内存屏障原语是:LDAXR STLXR指令。
在使用原子加载存储指令时可以通过清除全局监视器来出发一个事件,从而唤醒因为WFE指令而睡眠的CPU没这样不需要DSB和SEV指令。通常会在**自旋锁(spin lock)**的实现中用到。
2.1 获取一个自旋锁
自旋锁的实现原理非常简单。当lock为0的时候,表示锁是空闲的;当lock为1的时候,表示锁已经被CPU持有了。
【例2】下面一段代码获取自旋锁的伪代码,其中X1寄存器存放自旋锁,W0寄存器的值为1
prfm pst11keep, [x1] // PRFM是预取指令,把lock先预取到cache里面,起到加速的作用
loop
ldaxr w5, [x1] // 使用内置的加载-获取独占访问读取lock的值
cbnz w5, loop // 判断锁是不是为0
stxr w5, w0, [x1] // 使用stxr指令把w0写入lock,这样就获取了锁
cbnz w5, loop
// 成功获取自旋锁这里只使用了内置加载-存储内存屏障指令的独占访问指令就够了,主要用于防止在临界区内的加载存储指令被乱序重排。
2.2 释放一个自旋锁
释放一个自旋锁不需要使用独占的存储指令,因为通常只有锁的持有者会修改和更新这个锁。不过,为了让其他的观察者能看到这个锁的变化,还需要使用存储-释放内存屏障原语。
【例3】释放锁的伪代码
// ↑ 锁的临界区读写操作
stlr wzr, [x1] // 清除锁释放锁只需要使用STLR指令向lock里面写0即可。STLR指令内置了存储-释放内存屏障原语,组织锁的临界区里加载存储指令越出临界区。
2.3 使用WFE和SEV指令优化自旋锁
ARMv8体系结构对自旋锁有个特殊的优化,使用WFE(Wait For Event)机制降低在自旋锁等待锁耗时的功耗,它会让CPU进入低功耗模式,直到有一个异步异常或者特定的时间才会被环形。这个时间可以通过清除全局独占监视器的方式来出发和唤醒。
【例4】使用WFE和SEV指令优化自旋锁的代码
sevl // sevl指令是sev指令的本地版,它会向CPU发送一个唤醒事件。通常以一个WFE指令开始的循环里使用。
prfm pst11keep, [x1] // PRFM是预取指令,把lock先预取到cache里面,起到加速的作用
loop
wfe
ldaxr w5, [x1] // 使用内置的加载-获取独占访问读取lock的值
cbnz w5, loop // 判断锁是不是为0
stxr w5, w0, [x1] // 使用stxr指令把w0写入lock,这样就获取了锁
cbnz w5, loop
// 成功获取自旋锁【例5】释放锁的伪代码
// ↑ 锁的临界区读写操作
stlr wzr, [x1] // 清除锁使用STLR指令来释放锁并且让处理器的独占监视器监视测到锁的临界区的变化,即处理器的全局监视器检测到内存区域从独占访问状态编程开放访问状态,从而触发了一个WFE事件,来唤醒等待这个自旋锁的CPU。
2.4 邮箱传递消息
多核之间可以通过邮箱机制来共享数据。下面举个例子两个CPU通过邮箱机制来共享数据,其中全局变量SHARE_DATA表示共享数据,FLAGS表示标志位。
// CPU0
ldr x1, =SHARE_DATA
ldr x2, =FLAG
str x6, [x1] // write data to x6
dmb ishst // flush
str xzr, [x2] // update flag is 0.
//----------------------------------------------------
// CPU1
ldr x1, =SHARE_DATA
ldr x2, =FLAG
loop: // wait CPU0 for updating flag.
ldr x7, [x2]
cbnz x7, loop
dmb ishld
ldr x8, [x1] // read sharing data在本例子中,CPU0和CPU1均使用了DMB指令。在CPU0侧,DMB指令是为了保证这两次存储操作执行顺序的。如果先执行了更新FLAG,那么CPU1可能接收到错误的数据。在CPU1侧,等待FLAG和读共享数据之间插入DMB指令,是为了保证读到FLAG之后才去读共享数据,要不然就读到了错误的共享数据。注意两条DMB指令是带参数的。在CPU0侧使用ishst,ish表示内部共享域,st表示内存屏障指令访问次序为存储-存储操作。CPU1使用isbld,ld表示内存屏障访问次序为加载-加载操作。
2.5 单核和多核发送消息
在单核系统中CPU发送消息给非一致性观察者,非一致性观察者可以是系统中的其他处理器,例如系统中存在Cortex-M处理器。
CPU0:
str w5, [x1] //str指令更新X1的地址的值
dc cvac, x1 // dc指令用来清理x1地址对应的数据告诉缓冲。dc指令的参数为cvac
dmb ish 保证后面str指令执行之前看到dc指令执行完毕
str w0, [x4] // 设置x4寄存器用于通知其他处理器
E0:
WAIT_ACQ ([x4] == 1)
ldr w5, [x1]在非高速缓冲一致性的E0处理器里面,可以从X1中读出信息。cache指令维护,是通过指令直接维护地址,这样就完成cache和内存之间的交互。
在多核系统中,数据高速缓冲维护指令会广播到其他的CPU上面,通常高速缓冲维护指令需要和内存屏障指令混合使用。假设CPU0和CPU1以及E0三个CPU直接共享数据和发送消息。CPU0先把数据写入内存中,然后发送一个消息给CPU1。CPU1等待消息,然后再发消息,通知E0处理器来读取数据:
CPU0:
str w5, [x1] // str指令更新X1的地址的值
stlr w0, [x2]
CPU1:
WAIT_ACQ ([x2] == 1)
dmb sy // 保证正确读取x2之后才允许进行cache clean操作
dc cavc, x1 // 使用PoC的方式来清理cache系统所有的CPU以及缓存都被清理掉。
dmb sy
str w0, [x4]
E0:
WAIT_ACQ ([x4] == 1)
ldr w5, [x1]2.6 无效DMA缓冲区
与外部观察者共享数据的时候,我们需要考虑数据可能随时被缓冲到cache里面,例如把数据写入一个使能了cache内存区域的场景。CPU0准备了了一个DMA缓冲区,并且对应的cache都失效,然后发送一条消息给E0处理器。E0收到消息之后往这个DMA缓冲区里写数据。写完之后再发送一个条消息给CPU0。CPU0收到消息之后把DMA缓冲区的内容读出来。对应的伪代码如下:
CPU0:
dc ivac, x1 // 使DMA缓冲区对应的cache失效
dmb sy // 等待真正的失效
str w0, [x3] // 向E0发送消息
WAIT_ACQ ([x4] == 1) // 等待E0
ldr w5, [x1] // 循环等待E0设置标志位
E0:
WAIT ([x3] == 1) // 等待CPU0发送的消息
str w5, [x1] // 向DMA中写入数据
stlr w0, [x4] // 设置X4寄存器,相当于向CPU0发送消息在linux内核里面使i-cahce失效的函数是flush_icache_range()
<linux5.0/arch/arm64/include/asm/cacheflush.h>
static inline void flush_icache_range(unsigned long start, unsigned long end)
{
__flush_ichache_range(start, end);
smp_mb();
smp_call_function(do_nothing, NULL, 1);
}