0x26_LinuxKernel_设备驱动(一)综述与文件系统关联
carloscn opened this issue · 0 comments
0x26_LinuxKernel_设备驱动(一)综述与文件系统关联
我们早在2018年的时候,研究了Linux的驱动,但是并没有系统的学习,只能算是初步的了解整个开发流程。时至今日,我们应该更关注细节,更应该知道驱动程序所处的复杂场景,这样才能设计出健壮、稳定的设备驱动。因为,将花费5篇博客的长度,对Linux设备驱动进行系统化的综述。对于2018年的例子,我们作为example,可以参考:
- Linux Driver - GPIO键盘驱动开发记录_OMAPL138 [2018-1-14]
- 基于OMAPL138的Linux字符驱动_GPIO驱动AD9833(一)之miscdevice和ioctl [2018-6-19]
- 基于OMAPL138的Linux字符驱动_GPIO驱动AD9833(二)之cdev与read、write [2018-6-21]
- 基于OMAPL138的字符驱动_GPIO驱动AD9833(三)之中断申请IRQ [2018-6-23]
- Linux内核调用SPI驱动_实现OLED显示功能 [2018-8-23]
- Linux内核调用I2C驱动_驱动嵌套驱动方法MPU6050 [2018-10-2]
linux驱动是linux kernel占比最高的部分。本节注重的是对于设备驱动的内核端的论述,至于Linux驱动有专题进行分析。
写好一个设备驱动,我们需要有意识的注意一下基本能力:
- Linux驱动的框架。这些框架是如何和用户空间进行交互的,执行路径是哪些?Linux驱动框架的API是什么?设备号、设备描述、file_operations的实现和ioctl交互过程等等?
- Linux内核的内存管理的API。Linux驱动实际上属于内核开发的范围,可以使用内核的机制,设备驱动不免和内存打交道,如设备需要知道用户空间的数据需要和用户程序交互,设备需要做DMA操作等。常见的应用场景有很多,如设备在内核的内存需要映射到用户空间,然后和用户空间中的程序进行交互,这就会用到
mmap(难点),另外DMA也是一大难点,很多设备驱动需要分配和管理DMA缓冲区,这些实际上都是内存管理的范畴。 - 了解Linux内核中中断管理。因为几乎所有的设备都支持中断,所以中断程序是设备驱动中不可获取的一部分。我们需要了解和熟悉Linux内核提供的中断管理的接口。例如如何注册中断、如何编写中断处理函数。
- 了解Linux内核中同步和锁等相关的API。因为Linux是多进程、多用户的操作系统,而且支持内核抢占,所以进程之间的通信变得非常复杂,即便是编写简单的字符设备驱动也需要考虑锁之间的竞争问题。
- 了解编写驱动芯片的底层原理。设备驱动运行设备,前面知识不过是工具,真正能让设备运行起来的还是设备本身的硬件设计,要遵循硬件厂商的手册。
1. Linux的I/O体系
1.1 综述
让用户能够按照规定访问到外设,这是Linux内核的使命,这些外设被称为输入输出I/O。内核必须处理3个比较重要的问题。
- 根据设备的类型和模型,使用各种方法对硬件寻址;
- 内核必须提供访问各种设备的方法或者接口;
- 用户还必须知道内核中有哪些设备。
我们的外设一方面是给操作系统直接使用的,一方面需要porting出接口让用户能够访问到。用户访问路径可以通过如下图所示:
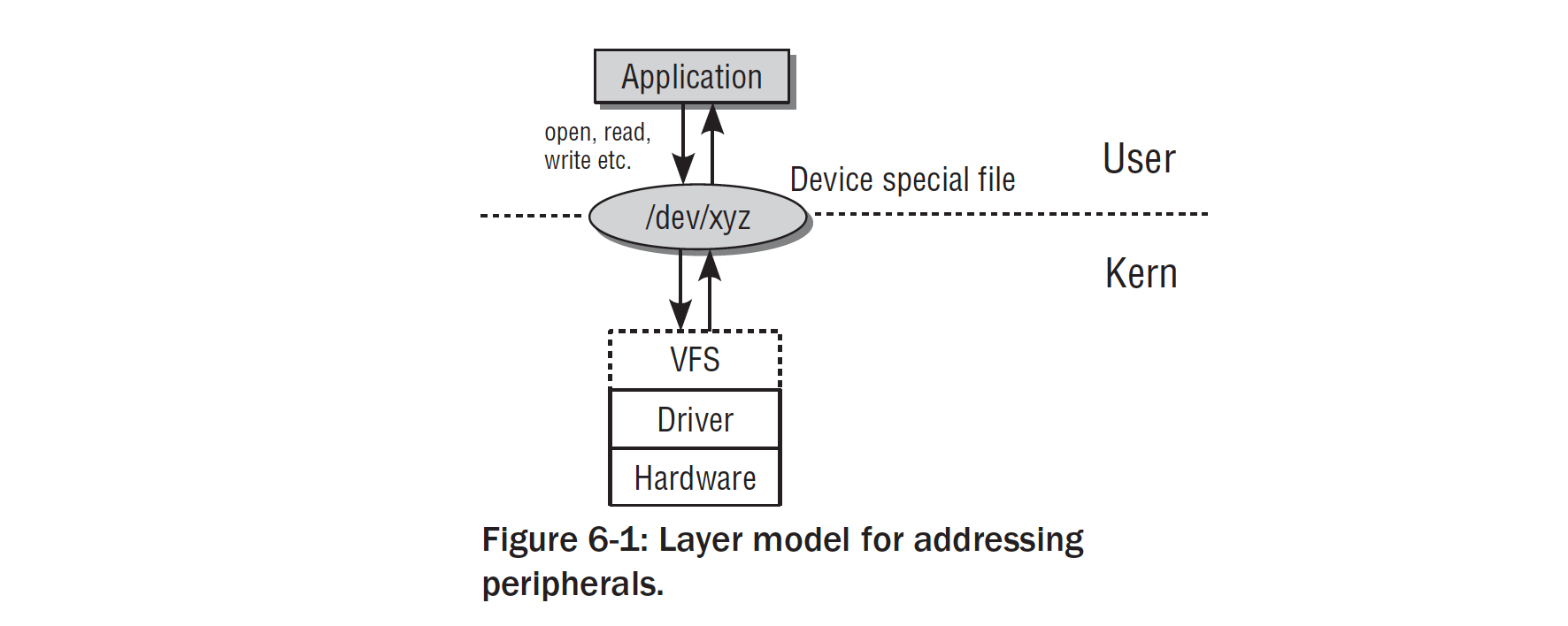
用户层通过操作设备节点文件/dev/xyz是kernel和userspace的桥梁,在kernel端是委托给VFS虚拟文件系统做服务的。 Linux的I/O体系如图所示:
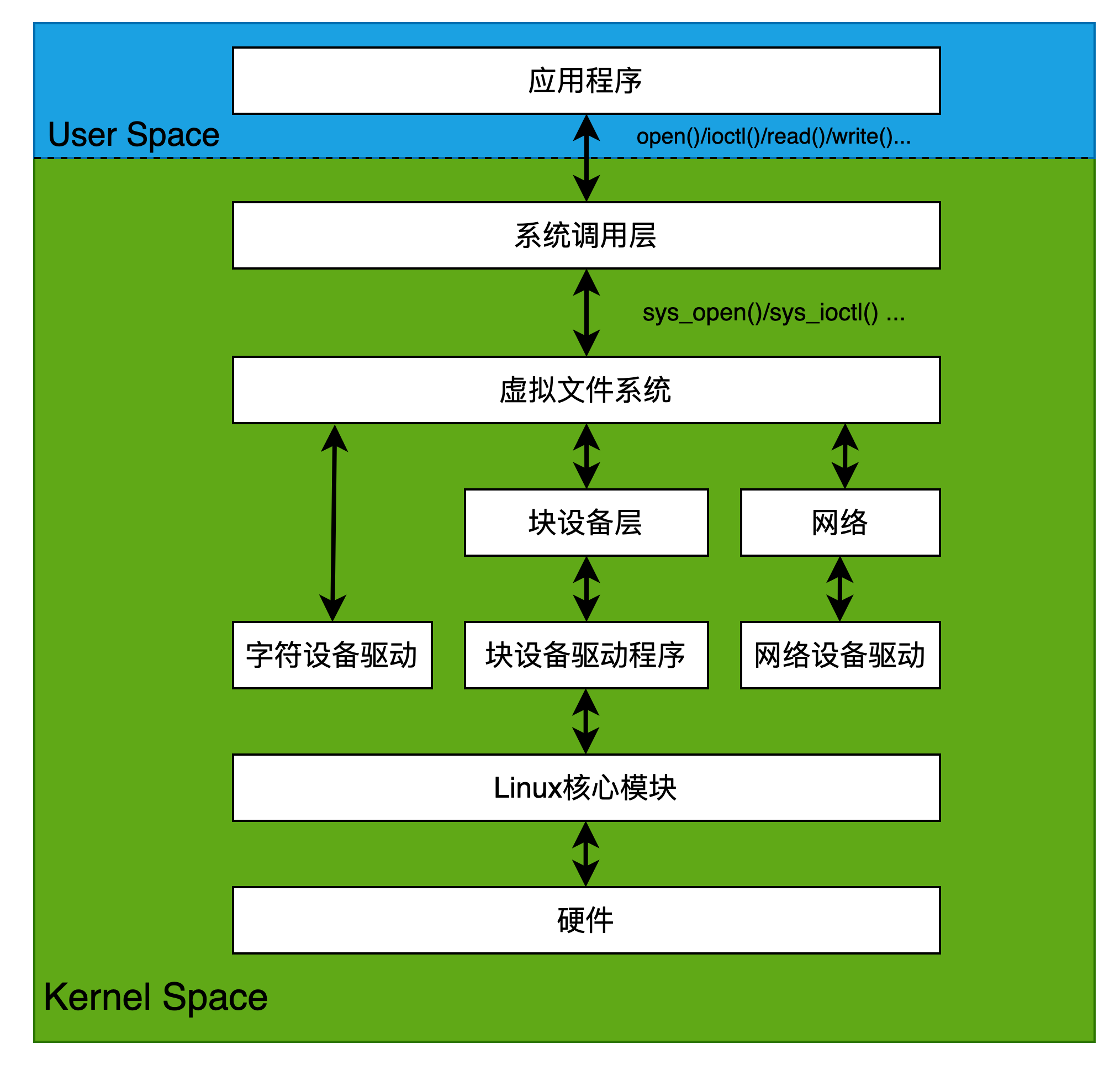
Linux把设备抽象成三种类型:
- 字符设备
- 块设备
- 网络设备
1.2 扩展硬件
1.2.1 总线系统
硬件设备可以通过各种各样的接口连接到BOARD(CPU)上面。因此就涉及了总线系统。这里列举常用的总线系统:
- PCI (Peripheral Component Interconnect):许多体系结构上使用的主要系统总线。PCI设备插入系统的扩展槽中,支持热插拔,使得设备可以在运行时候接入和断开。PCI的传输速度最大能够达到每秒几百兆字节,所以使用非常广泛。
- ISA (Industrial Standard Architecture):比较古老的总线,应用依旧广泛。因为ISA在电路设计上非常简单,这个就让很多个人及小公司很容易使用。但随着时间推移,这个总线引发了越来越多的问题,因此在比较高级的系统中被替代掉了。
- SBUS:这个一个非常高级的总线,历史悠久。由SUN公司制作,是一个公开发行的总线,但未能在其他体系架构中赢得一个位置。
- IEEE1394:某些厂商也称其为FireWire,有一些也称为I.Link。它预先设计了热插拔的功能、非常高的传输速率。IEEE1394是高端笔记本电脑上非常流行的一种外部总线,提供了一种高速的扩展选项。
- USB (Universal Serial Bus):不言而喻,非专业人士都是知道这个接口的存在(市场接受度)。USB的拓扑结构超乎寻常,其中设备不是按照一条单链表排布的,而是按照树形结构排布。USB还有一个特性就是为各个设备预留带宽,可以达到均衡作用。
- SCSI (Small Computer System Interface):这个总线过去称为专业人员总线,因为相关外设的成本十分高。由于SCSI支持非常高的数据吞吐率,因此在服务器系统上寻址硬盘,适合大多数的CPU体系结构。
- 并口和串口(Parallel and Serial Interface):总线结构简单,速率极低,用于外部连接,非常古老。
总线系统和PCI有非常“暧昧”的关系:
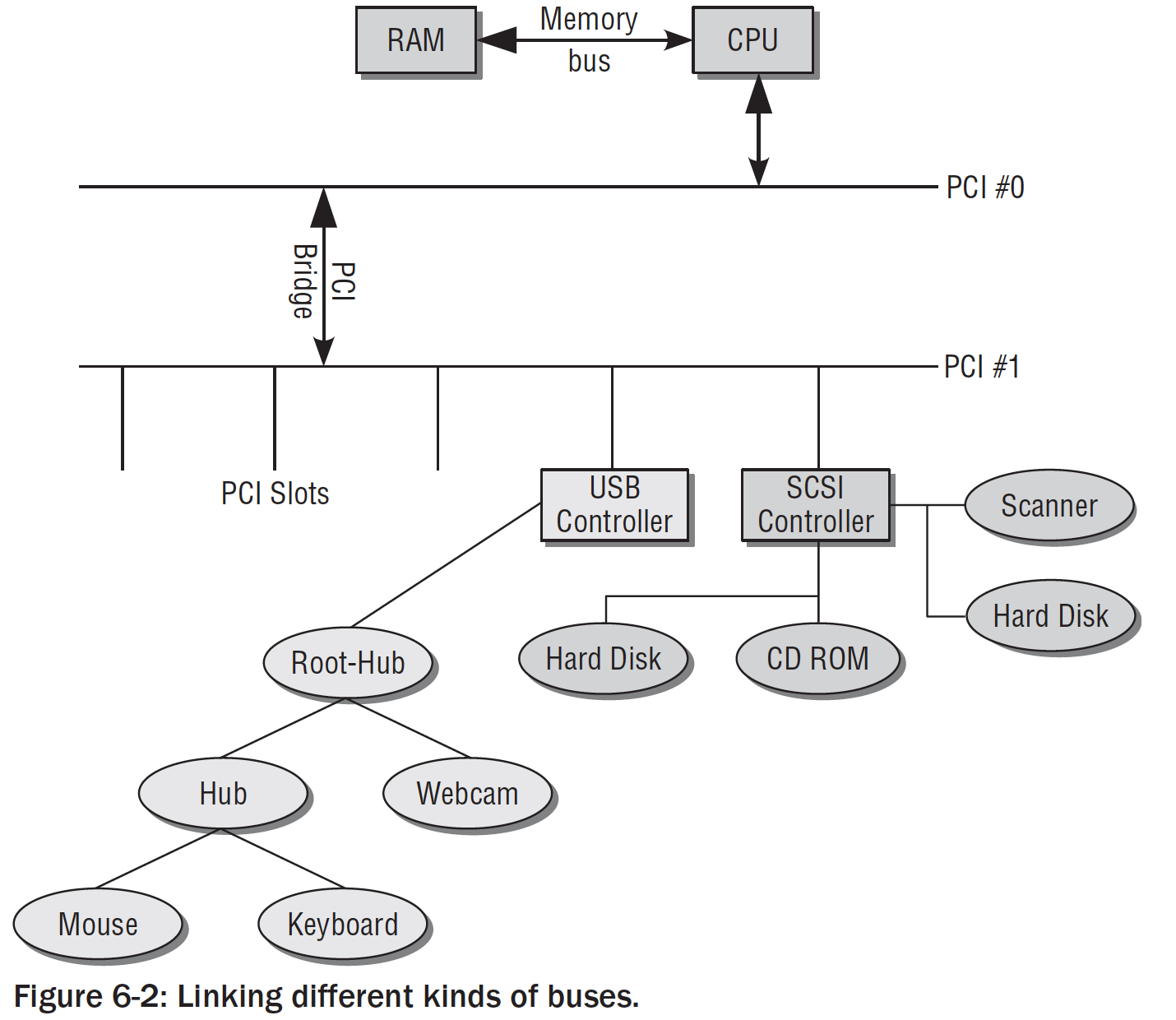
无论什么架构的CPU(BOARD),系统都不会只有一种总线,而是一些总线的组合。当前PC设计包括通过桥接的PCI总线。一些总线,如USB,FireWire无法作为主总线,时钟需要由另一个系统总线将数据传递给处理器。
1.2.2 外设的交互
我们可以从数据量和查询方式两个维度来分析与外设的交互。如果驱动是以字节计的少量数据,那么我们可以通过I/O端口的方式来交互数据,而如果是大量的数据交换,那么我们可以通过I/O内存映射的方式来做数据交换。I/O端口交互方式,内核发送数据给IO控制器,每个IO端口都有端口标识符,数据被传输到设备进行处理。处理器管理一个独立的虚拟地址空间,可以用于管理所有的IO地址,这个地址被称为device memory,IO地址空间无法关联到Normal Memory。IO端口映射方式,讲特定的端口映射到普通内存中,可以向处理普通内存一样操作外设。显卡一般会使用这样的操作。为了使用内存映射,首先必须IO端口映射到普通内存上,主要包括(ioremap和iounmap)命令,分别用于映射IO内存区和解除映射。
另一个维度是查询方式,系统如何知道某个设备的数据已经就绪?就分为轮询Polling和中断interrupt方式。轮询策略十分简单,只需重复访问设备数据是否可用,如果可用从处理器取回数据。显然这样十分浪费系统资源,为检查外设状态需要话费大量的运行时间,从而会影响重要的任务执行。中断是个更好的选择方式,每个CPU都提供了中断线,由各个系统设备共享。每个中断通过唯一的号码标识,内核对使用的每个中断提供了一个服务例程。中断缺点是中断会暂停正常的系统工作,中断机制也比较复杂。在外设的数据已经就绪,需要由内核或应用程序处理的时候,外设会引发一个中断。时钟这种方法,系统就不再需要频繁检测是否数据可用。
Note,不是所有的总线通过IO语句寻址,也有通过总线系统访问。并非所有的设备都连接到了总线系统,例如CD和硬盘连接到了SCSI接口。
2. 访问设备
用户空间如何找到我们的驱动程序呢?访问到我们的设备通过一种设备特殊文件(设备文件)。这些文件不关联到任何的硬盘或者存储介质上的数据段上,而是建立了某个设备驱动程序的连接以支持与扩展设备的通信。就应用程序而言,普通文件和设备文件都可以通过一些接口来访问,例如open/read/write之类的,但是对于设备文件来说,还提供了更丰富的接口用于支撑更多的逻辑。
2.1 设备文件
我们在Linux系统里面很容易找到设备文件的“影子”,例如/dev/*目录下面的文件:

但是这个仅仅是设备名称是给人看的。程序之间寻找到这个设备并不是靠名称,而是借助文件系统中的一些概念【文件的主、从设备标识】。这些号码在文件系统中作为特别的文件属性。
我们可以通过最简单的方式访问设备:echo "hello" > /dev/ttyS0,意义就是向连接的串口调制解调器发送一个初始化的字符串。
2.2 字符设备、块设备和其他设备
上面我们也说了,Linux根据外设的共性和不同把设备类抽象成了不同的类型,分为:
- 字符设备
- 块设备
- 网络设备
2.2.1 标识设备文件
这个主要是根据外设和系统交换数据的方式进行分类的。字符设备通常归纳为数据传输量比较低的,相应地,块设备用于数据量比较大的设备。内核会对他们进行区分。
我们来更具体的来看一下字符设备的表述方式:
✗ ls -l /dev/sd* /dev/ttyS{0,1}
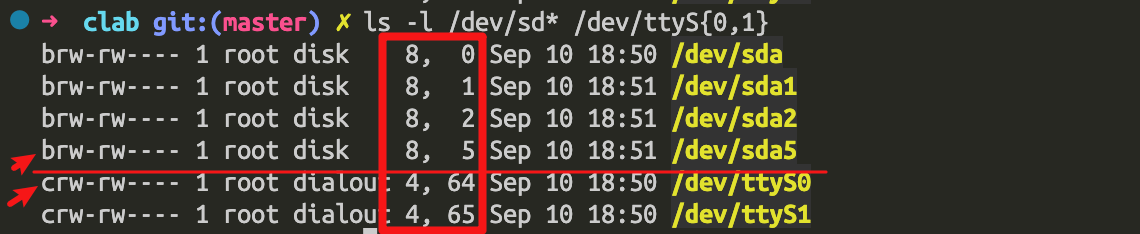
- 注意箭头的位置,
c表示字符设备,b表示块设备; - 对于设备文件,并没有文件大小的,所以增加了两个值,前面的是主设备号,后面的是从设备号,二者结合起来就形成了一个唯一的号码(设备之间就是通过主设备号和从设备号来找到这个设备的)
- 内核采用主设备号来标识驱动程序。使用两个号码的原因,也和驱动框架通用结构有关系。首先,系统可能包含几个同样类的设备,由同一个设备驱动程序管理。其次可以将同样的设备合并起来,便于插入到内核的数据结构中进行管理。
- 主设备号的分配可以在http://www.lanana.org 获取。定义在
Documentation/devices.txt文件。在<major.h>中定义。
以下是主从设备号的划分。被抽象成dev_t的结构体(32-bits)
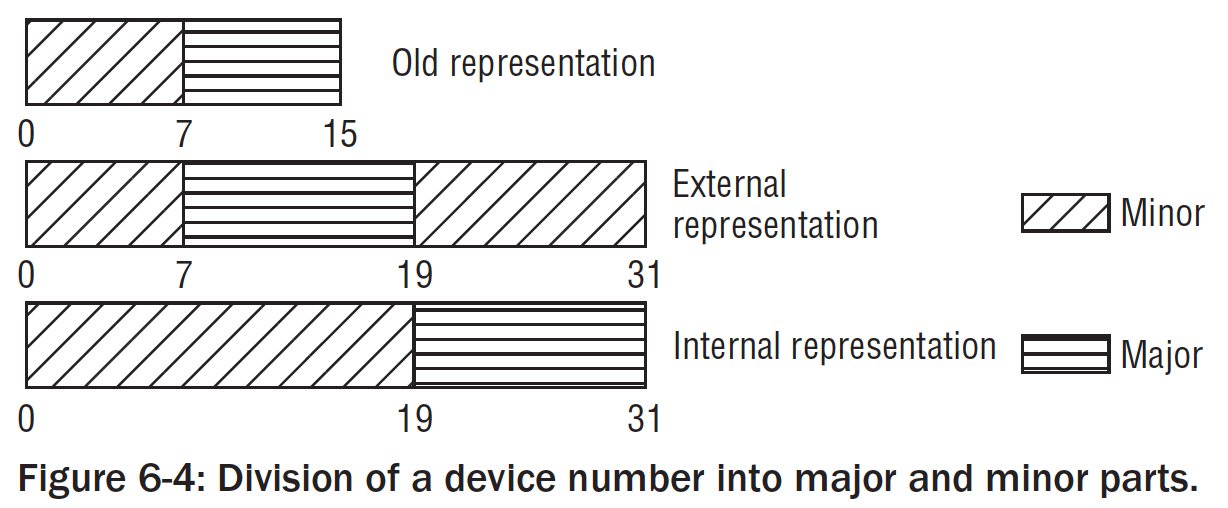
2.2.2 动态创建设备文件
/dev中的设备节点一般是在基于磁盘文件系统创建的。随着支持的设备越来越多,因此必须对这些设备有更好的管理方式,典型的发布版本共有20000项目。一般系统都会包含少量的设备,因而大多数都是不必要的。因此几乎所有的发布版都将/dev内容的管理工作托管到udevd这是一个守护进程,允许从用户层动态创建设备文件。
udevd的基本**与图所示:
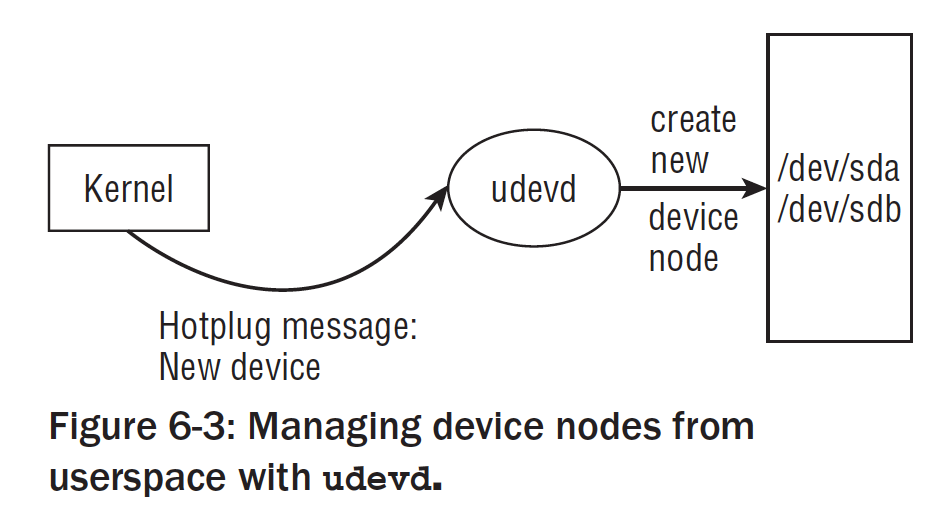
当kernel检测出一个设备热插拔的时候,都会创建一个kobject的对象。该对象借助sysfs文件系统导出到用户层。此外,内核还想用户空间发送一个热插拔的消息(module)范畴。如果在系统启动期间发现了新设备,或者在运行期间有新设备接入(如U盘),内核产生热插拔消息包括驱动程序的主设备号和从设备号。此时udevd守护进程所需要完成的所有工作,就是监听这些消息。在注册设备时,会在/dev/中创建对应的项,接下来就可以从用户层访问设备了。
总结下来就是:热插拔事件->内核创建kobject对象->借助sysfs文件系统导出到用户层->发送消息给守护进程(主设备号/从设备号)-> 守护进程在/dev/下面创建节点。
需要注意的是,引入udev机制,/dev/并不是放在磁盘的文件系统,而是tmpfs,这是RAM磁盘的文件系统的变体,这意味着这个节点并不是持久性的,系统关机和重启之后就会消失。
除此之外,在用户空间还可以使用mknod的命令进行创建
mkndo filename type major minor
2.2.3 使用ioctl进行设备寻址
既然最终创建了设备文件节点,可以使用通用的read和write函数来对设备进行操作,为啥还需要ioctl这个东西?答曰:一些设备配置功能和属性超越了read和write的框架,所以需要一个接口用于配置设备。比如,在一个驱动设计中,read和write函数通常都大量的实现了通信业务,但是如果还需要配置的话,那么我们不得不订制一套协议,让用户或者内核知道这这部分数据是配置和业务的。
通常的方法就是协议增加magic,那么magic法的弊端就是magic碰撞。到时候可能会引起系统崩溃。而且这份代码不得不交给用户空间的人来实现,这无疑是增加了用户的负担。
因为这个原因,内核提供了一种方法,能够支持设备的特殊属性配置,而不依赖于read和write函数。因此就引入了ioctl的接口函数,全名叫做输入输出控制接口。
asmlinkage long sys_ioctl(unsigned int fd, unsigned int cmd, unsigned long arg)
2.2.4 网卡设备
网卡设备既不是字符设备也不是块设备,因为网络是在太重要了,网卡在内核里面有着特殊的地位。因此网卡没有设备文件。用户和网卡通信,Linux提供了套接字的方式。socket是一个抽象层,对所有网卡提供了一个抽象视图。
除此之外还有USB也是没有设备文件的,这部分不得不由硬件直接暴露接口给用户层。
2.2.5 注册过程
内核如果能了解到系统中有哪些字符设备和块设备可用,那自然是很有利的,因而需要维护一个数据库。此外就必须提供一个接口,以便驱动开发者可以把自己的设备添加到数据库里面去。
设备数据库
字符设备和块设备是分开管理的,标识号也不一样,他们在内核的数据库的结构体也是不一样的:
- 字符设备:
struct cdev->cdev_map - 块设备:
struct genhd->bdev_map
内核开辟了两个全局数组用来存储字符设备实例和块设备实例,就是cdev_map和bdev_map,他们的声明都是strcut kobj_map的实例。管理方式如下:
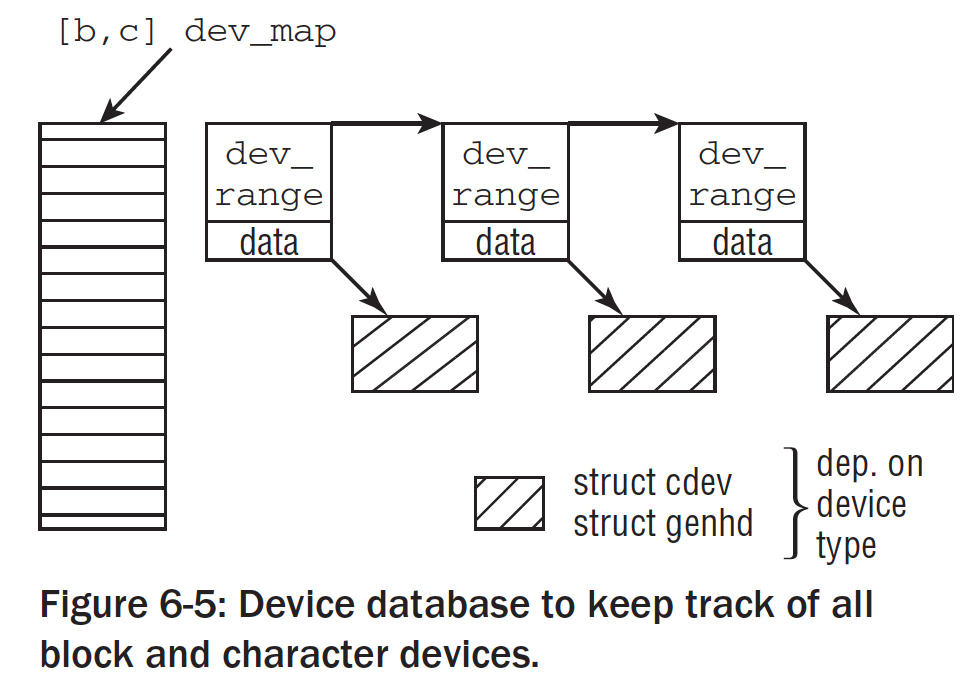
// drivers/base/map.c
struct kobj_map {
struct probe {
struct probe *next;
dev_t dev;
unsigned long range;
struct module *owner;
kobj_probe_t *get;
...
void *data;
} *probes[255];
struct mutex *lock;
};这里使用了hash表的方式来跟踪设备号的值。
- next将所有散列元素放在一个单链表中;
- dev表示设备号(32bit的包含主设备号和从设备号)
- 从设备号的范围存储在range中;
- owner指向设备驱动的模块(如果有的话)
- get指向一个函数,可以返回与设备关联的kobj实例。
- 块设备和字符设备的区别就在data上面,字符设备指向一个
struct cdev的结构体,而块设备是struct genhd的实例;
注册过程
字符设备
在内核中注册字符设备需要两步来完成:
- 注册或分配一个设备号的范围。
register_chrdev_region而alloc_chrdev_region由内核来选择适当的范围。 - 获取到了范围之后,需要将设备添加到字符设备数据库中,以激活设备。
cdev_init,cdev_add两个函数。 - 返回成功之后,设备进入活动状态。
块设备
块设备只需要调用add_disk即可。较早版本的调用register_blkdev。块设备将显示在/proc/devices中。
3. 与文件系统关联
无论字符设备还是块设备,最终都会以节点的方式映射到用户空间,用户可以通过访问这些设备类似于操作文件一样,使用文件访问的接口对设备节点进行访问。那么在驱动程序中就离不开文件系统的一套表述方式。
3.1 inode中的设备文件
我们从Linux IO体系结构图上面也可以看到,系统调用层最终需要虚拟文件系统VFS作为支持。VFS的原理就是抽象各个各种文件系统,最终统一合并成一个接口。我们来提取一下相关inode节点的有关成员:
//<fs.h>
struct inode {
...
dev_t i_rdev; // 存储了设备号
...
umode_t i_mode; // 存储了文件类型
...
struct file_operations *i_fop; // 函数指针集合,包括很多文件系统的操作
...
union {
...
struct block_device *i_bdev; // 联合体指向字符设备或者块设备结构体。
struct cdev *i_cdev;
};
...
};3.2 标准文件操作
在打开一个设备文件的时候,各种文件系统的实现都会调用init_special_inode函数,这个函数是为字符设备或者块设备创建一个inode:
https://elixir.bootlin.com/linux/v4.14.265/source/fs/inode.c#L1990
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
else
printk(KERN_DEBUG "init_special_inode: bogus i_mode (%o) for"
" inode %s:%lu\n", mode, inode->i_sb->s_id,
inode->i_ino);
}
EXPORT_SYMBOL(init_special_inode);这个函数通过inode参数传递进来设备类型之外,底层文件系统还必须返回主从设备号。代码会根据不同的设备类型,向inode提供不同的文件操作。从代码上看,除了块设备、字符设备,还有管道FIFO设备。
3.3 字符设备操作
3.3.1 字符设备表示
字符设备的硬件通常非常简单,而且驱动程序结构也不难实现。字符设备通过cdev来表示:
struct cdev {
struct kobject kobj;
struct module *owner;
const struct file_operations *ops;
struct list_head list;
dev_t dev;
unsigned int count;
};- kobject可以参考:Linux机制之对象管理和引用计数(kobject) 里面描述了内核对象,可以使用kobj里面的uevent,引用计数和文件系统等机制;
- list还是表示一个链表结构;
- count表示设备关联的从设备号的数目;
- ops就是我们这节的重点,字符设备的文件操作;
3.3.2 字符设备打开
fs/devices.c中的chrdev_open是打开字符设备的通用函数。假设设备没有打开过,根据给出的设备号,kobject_lookup查询字符设备的数据库,并返回与该驱动程序关联的kobject实例。该返回值可以用于获取cdev实例。
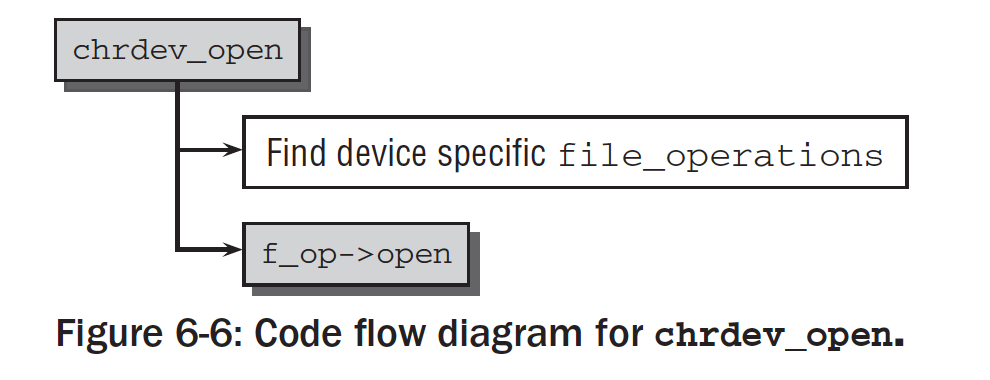
获得了对应的设备的cdev实例,内核通过cdev->ops还可以访问特定的设备file-operations。接下来设置各种数据结构之间的关系:
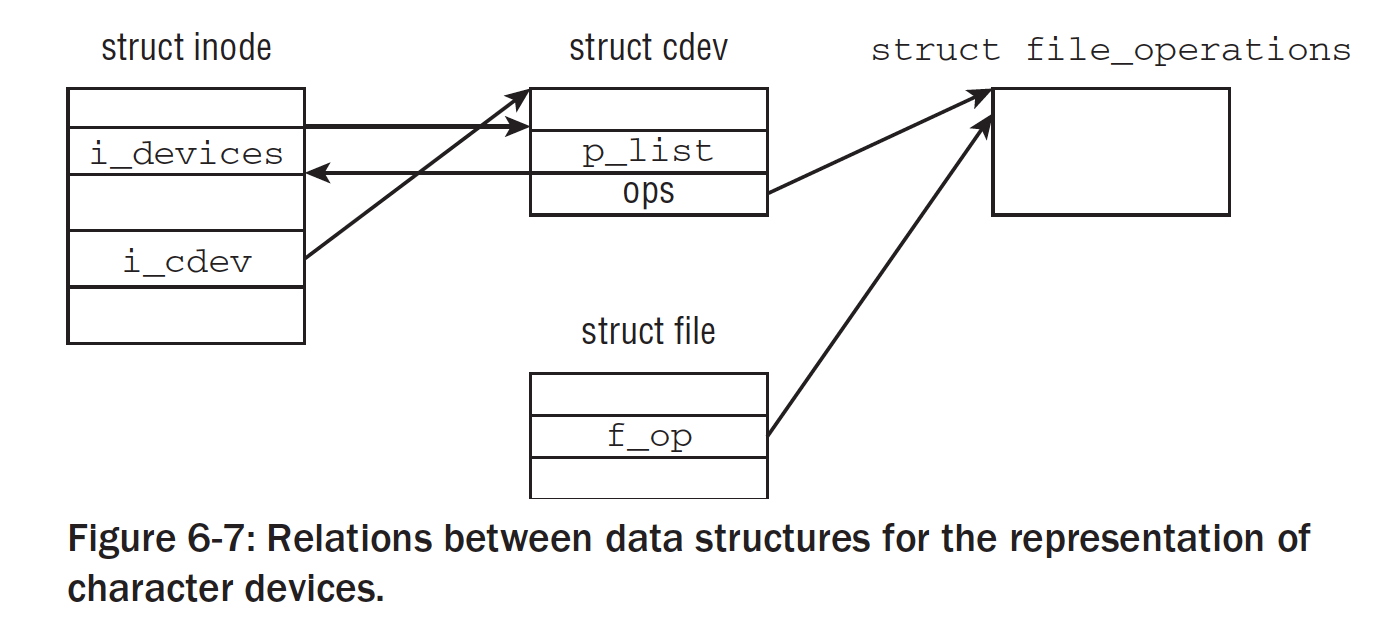
inode->i_cdev指向所选择的cdev实例。在下一次打开inode的时候,就不必查询字符设备的数据库,因此我们可以使用缓存值;- 该inode会添加到
inode->list中; file->f_ops是用于struct file的file_operations设置指向了struct cdev给出的file_operations
接下来会调用struct file新的file_operations中的open方法(现在是特定设备的open方法),在设备上执行所需要的初始化任务(有些外设在第一次使用之前,需要通过握手来协商操作的细节)。该函数也可以对数据结构做一点修改,以适应特定的从设备号。
我们考虑一个关于内存的字符设备的例子,假如其主设备号为1。根据LANANA标准,该设备有10个不同的从设备号。每个从设备都提供了不同的功能,这些都与内存访问操作相关。下面表表示了一些从设备号,及相关的文件:
| Minor | File | Description |
|---|---|---|
| 1 | /dev/mem | 物理内存 |
| 2 | /dev/kmem | 虚拟kernel空间的内存 |
| 3 | /dev/null | 比特位桶 |
| 4 | /dev/port | 访问IO口 |
| 5 | /dev/zero | NULL字符源 |
| 8 | /dev/random | 非确定性随机数发生器 |
一些设备是我们熟悉的,特别是/dev/null。无需深入到各个设备从设备号的细节,根据设备描述我们就可以很清楚的知道,尽管这些从设备号都设计了内存访问,但所实现的功能有很大区别。对于这些内存访问,我们把file_operations的open指向mem_open函数,这样就完成了内存操作的映射。mem_open函数定义在driver\char\mem.c
https://elixir.bootlin.com/linux/v4.14.265/source/drivers/char/mem.c#L897
static int memory_open(struct inode *inode, struct file *filp)
{
int minor;
const struct memdev *dev;
minor = iminor(inode);
if (minor >= ARRAY_SIZE(devlist))
return -ENXIO;
dev = &devlist[minor];
if (!dev->fops)
return -ENXIO;
filp->f_op = dev->fops;
filp->f_mode |= dev->fmode;
if (dev->fops->open)
return dev->fops->open(inode, filp);
return 0;
}
static const struct file_operations memory_fops = {
.open = memory_open,
.llseek = noop_llseek,
};实现了一个分配器(根据设备号区分各个设备devlist[minor],并且适当的选择open函数):
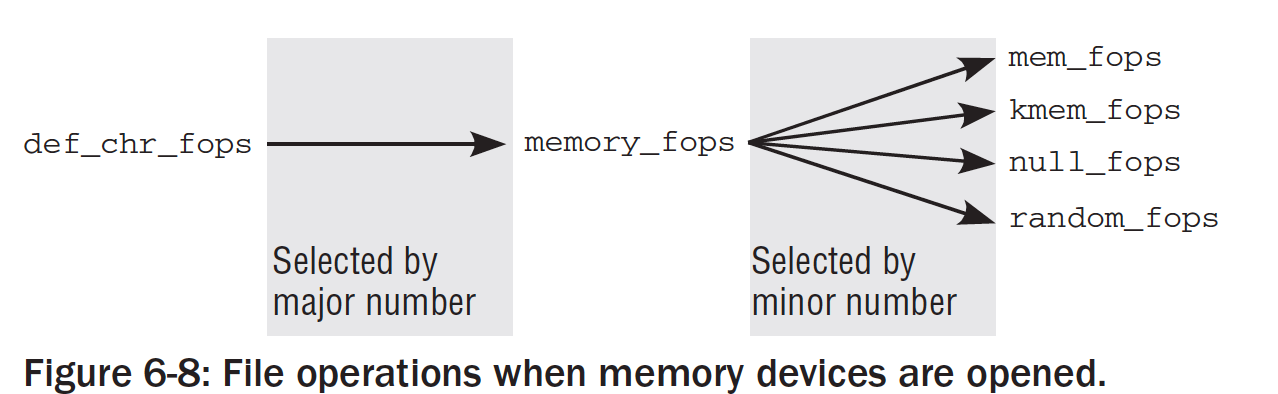
上图表示当内存设备被打开的时候,文件操作是如何改变的。根据主设备号找到类的操作,再由类的操作结构找到从设备号,接着找到相应的真实操作。尅看到真是null和random的结构也是如此。
//drivers/char/mem.c
static struct file_operations null_fops = {
.llseek = null_lseek,
.read = read_null,
.write = write_null,
.splice_write = splice_write_null,
};
//drivers/char/random.c
struct file_operations random_fops = {
.read = random_read,
.write = random_write,
.poll = random_poll,
.ioctl = random_ioctl,
};3.2.3 字符设备读写
读写字符设备实际上不是一个有趣的工作,因为VFS和设备驱动之间已经建立了关联。调用标准的write和read操作,内核路径就会调用到系统调用,最终作用到file_operations中的相关操作。这些方法具体依赖设备的不同而不同。
比如/dev/null设备使用read_null和write_null的实现,从空设备上写和读实际上什么都不需要操作,所以时间就很简单。
drivers/char/mem.c
static ssize_t read_null(struct file * file, char __user * buf, size_t count, loff_t *ppos)
{
return 0;
}
static ssize_t write_null(struct file * file, const char __user * buf, size_t count, loff_t *ppos)
{
return count;
}file_operations提供了丰富的接口函数:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iterate) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*mremap)(struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
};- llseek()方法用来修改文件当前读写位置;
- read()方法从设备驱动向用户空间传输数据;
- write()方法刚好反过来;
- poll()方法用来把用户空间的数据写入设备,用于阻塞式IO;
- unlocked_ioctl和compat_ioctl方法用来与设备相关的控制命令进行具体实现;
- mmap方法用来将设备的内存映射到用户进程虚拟空间地址。
- open用来打开
- release方法用来关闭设备
- aio_read和aio_write异步IO,可以通过发送信号或者回调函数的方法来通知;
- fsync方法实现了异步通知的特性。驱动设备写入后返回写入字长不能保证一定成功,如果某个应用想要肯定确认写入成功,需要调用fsync来确保数据从驱动缓冲区刷到了用户缓冲区中。
4. misc机制
miscellaneous 杂项的设备。Linux内核把一些不符合预先确定的字符设备划分为杂项设备,这类设备的主设备号是10。Linux内核使用miscdevice结构体来描述这类设备。
struct miscdevice {
int minor;
const char *name;
const struct file_operations *fops;
struct list_head list;
struct device *parent;
struct device *this_device;
const struct attribute_group **groups;
const char *nodename;
umode_t mode;
};
extern int misc_register(struct miscdevice *misc);
extern int misc_deregister(struct miscdevice *misc);Linux内核会提供注册杂项设备的两个函数,驱动可采用misc_resgister和misc_deregister来注册和注销设备。由于会自动创建节点,不需要mknod命令手动创建,因此使用misc_device机制来创建字符设备还是比较方便的。
5. 实现字符驱动的机制
这部分想做一些驱动程序的原型,来引用一些内核的机制。一个最简单的驱动里面包含了,对于设备的注册和注销、配置控制的实现、数据的交互write和read。这样在用户空间就可以使用驱动程序了。但是现实的状况不会是这么容易,业务逻辑的复杂和芯片本身的设计两者之间的调配需要去驱动肩负起更多的工作,甚至因为在同一个内核里面,驱动的开发要有意识去感知其他驱动的出现。如果对于驱动的性能有要求,那就需要引入更多的考虑和更多的机制。
内存交互就是一个比较重要的问题,我们似乎都知道,使用copy_{to, from}_user()的接口来操作用户和内核的内存。但是考虑到内核空间可以随意的访问进程上的任何地址空间,为什么不可以使用memcpy呢?如果深挖的话,挖出一个很有趣的话题,可以参考:Linux机制copy_{to, from}_user.md anyway,在driver里面,要严格的使用copy接口。
copy_{to, from}_user可能会睡眠,因此不可以持自旋锁。
- 内核和用户交换数据通过
copy_{to, from}_user()的接口,那么读写时序要如何保证呢?两者之间谁什么时候读?谁什么时候写?如果共同的读还好,如果共同的写怎么处理?所以要引入kfifo机制。 - 读写的时候是一个IO的操作过程,用户在调的write和read的时候会不会被阻塞,如果在用户异步的应用了使用了我们阻塞的设计,这会不会导致他需要维护一个很繁琐的状态机?因此我们在设计驱动的时候要考虑阻塞的设计还是非阻塞的设计。
- 如果一个进程要监控多个设备,如果我们采用上面的阻塞和非阻塞模式,在一个进程监控多个设备里面,用户不得不起多个线程对驱动进行操作。例如,一个应用又要监控鼠标事件、又要监控摄像头数据。如果采用阻塞和非阻塞,其中访问一个IO设备并进入睡眠之后,那么就没有办法访问别的驱动了,用户只能启动多个线程或者进程,这样就很浪费。因此Linux驱动又提供了IO的多路复用机制。
- 上面如果用阻塞和非阻塞模式,为什么不能唤醒读写进程?这就涉及了进程访问地址范围的问题。
- 我们同样也可以和用户空间使用类似于“完成变量”(条件变量)的方法告诉用户设备的数据已经就绪了,可以来取了,这就是异步通知-信号机制。
因为驱动是在内核空间,所以可以借助Linux的内核机制,比如锁、互斥量、信号量、完成-等待队列、信号等等。可以说,驱动是Linux内核机制最多的使用者了。
5.1 最简单的示例
我们这里给出一个最简单的字符驱动的示例:
- 创建一个虚拟设备,学习如何实现一个字符设备驱动的读写方法;
- 在用户空间写测试程序来检测读写函数是否成功;
driver端程序:
挑出重点的,写读函数:
static ssize_t
demodrv_read(struct file *file, char __user *buf, size_t lbuf, loff_t *ppos)
{
int actual_readed;
int max_free;
int need_read;
int ret;
printk("%s enter\n", __func__);
max_free = MAX_DEVICE_BUFFER_SIZE - *ppos;
need_read = max_free > lbuf ? lbuf : max_free;
if (need_read == 0)
dev_warn(mydemodrv_device, "no space for read");
ret = copy_to_user(buf, device_buffer + *ppos, need_read);
if (ret == need_read)
return -EFAULT;
actual_readed = need_read - ret;
*ppos += actual_readed;
printk("%s, actual_readed=%d, pos=%lld\n",__func__, actual_readed, *ppos);
return actual_readed;
}
static ssize_t
demodrv_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
int actual_write;
int free;
int need_write;
int ret;
printk("%s enter\n", __func__);
free = MAX_DEVICE_BUFFER_SIZE - *ppos;
need_write = free > count ? count : free;
if (need_write == 0)
dev_warn(mydemodrv_device, "no space for write");
ret = copy_from_user(device_buffer + *ppos, buf, need_write);
if (ret == need_write)
return -EFAULT;
actual_write = need_write - ret;
*ppos += actual_write;
printk("%s: actual_write =%d, ppos=%lld\n", __func__, actual_write, *ppos);
return actual_write;
}这个write函数最终写的是长度为MAX_DEVICE_BUFFER_SIZE的长条状buffer,使用ppos指针指向位置。这个buffer由user和kernel两者操作。
int main()
{
char buffer[64];
int fd;
int ret;
size_t len;
char message[] = "Testing the virtual FIFO device";
char *read_buffer;
len = sizeof(message);
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failded\n", DEMO_DEV_NAME);
return -1;
}
/*1. write the message to device*/
ret = write(fd, message, len);
if (ret != len) {
printf("canot write on device %d, ret=%d", fd, ret);
return -1;
}
read_buffer = malloc(2*len);
memset(read_buffer, 0, 2*len);
/*close the fd, and reopen it*/
close(fd);
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failded\n", DEMO_DEV_NAME);
return -1;
}
ret = read(fd, read_buffer, 2*len);
printf("read %d bytes\n", ret);
printf("read buffer=%s\n", read_buffer);
close(fd);
return 0;
}这个程序有个极大的弊端看到没,使用write或者read的时候,还要重新open这个程序。这是为啥?我们看驱动的实现,在read和write里面没有加任何的阻塞实现,而用户侧的接口和内核之间的调用并不是直接调用的这么简单,中间需要穿透系统调用,VFS,系统核心层,这是一个很复杂的过程。续写缓冲是否就绪,这些都不为人知。这里有几个注意事项:
- 如果一个字符驱动write()成功返回,就表示驱动已经把数据传送下去,但并不保证数据已经被写道设备中去了。我们要考虑:第一,用户的数据有没有刷到内核的数据缓冲里(copy_from_user是否结束);第二,内核的数据缓冲有没有作用写到设备上(通过fsync()接口确认)。
- 如果实例里面有多个调用者尤其是多CPU情况,即便是在程序是读写是顺序的。内核同步必须避免指令重新排序,优化屏障(Optimization barrier)避免编译器的重排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。所以这里导致可能未读的数据被覆盖,可能脏数据被读走也可能会是指令重排的结果。
- copy_from_user可能会阻塞睡眠下去,原因就是用户传入的地址所代表的的空间(大概率,内核分配空间是立即生效的,用户的空间是被延迟分配的)或者内核空间缺页造成缺页异常,系统需要
do_page_fault来处理缺页空间,这个过程是阻塞睡眠的。因此不能使用自旋锁,不能在中断上下文使用这个函数,而考虑使用mutex。 - read和write返回字节数可能是1-请求数中的任意数字,用户侧必须考虑处理这种情况。
- read和write不一定是必须实现的,有些驱动可能是只读,只写设备。
话说回来,我们在read和write里面必须加一些读写的保护,因为在内核空间的读写缓冲是公用的内存,我们必须要确保用户侧写的数据已经写入,读的数据已经读走,防止未读的数据被覆盖,防止脏数据被读走(可能得到一个错误的返回字节数)。而这些保护可以是:
- KFIFO机制
- 使用阻塞和非阻塞IO
- 异步-信号机制通知
而且我们要考虑,驱动使用者的实体可能不是只有一个,可能有多个调用者一起read和write,对于共享的资源,必须要列出来逐个排查有没有可能造成资源竞争的问题。
5.2 KFIFO机制123
条状FIFO模型:
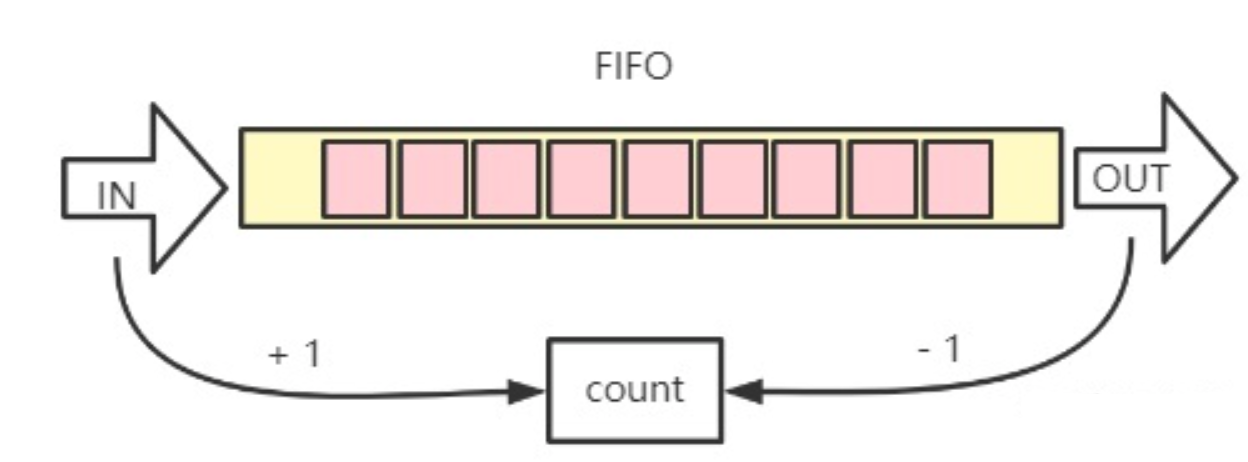
Ring KFIFO模型:
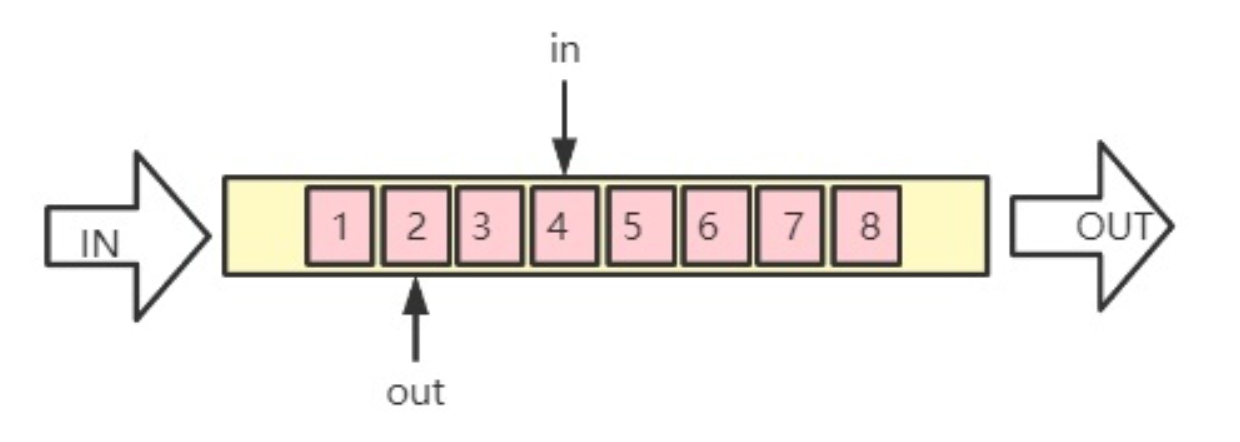
KFIFO机制使用的是一个环形缓冲区来解决读写序的问题。上面说的条状buffer读写指针共用就会出现一个非常大的问题, 可能未读的数据被覆盖,可能脏数据被读走。从算法上可以把读写指针分开,这样就不会造成数据冲突了。当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率。更重要的是,kfifo采用了并行无锁技术,kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的。
这个无锁只是针对“单生产者-单消费者”而言的。“多生产者”时,则需要对入队操作进行加锁;同样的,“多消费者”时需要对出队操作进行加锁。
Linux内核实现了KFIFO环形缓冲区的机制:
#define DEFINE_KFIFO(fifo, type, size)
#define kfifo_from_user(fifo, from, len, copied)
#define kfifo_to_user(fifo, to, len, copied)
//除上述两种定义方式外,还支持用户自己申请缓存,然后传递给fifo进行初始化:
kfifo_init(fifo, buffer, size)
//带锁的出入队
kfifo_in_locked(fifo, buf, n, lock)
kfifo_out_locked(fifo, buf, n, lock)
//获取队列的已有空间长度
kfifo_len(fifo)
//获取队列的空闲空间长度
kfifo_avail(fifo)
//判断队列是否为空
kfifo_is_empty(fifo)
//判断队列是否为满
kfifo_is_full(fifo)
//清空队列
kfifo_reset(fifo)DEFINE_ KFIFO用于定义并初始化一个FIFO,这个变量的名字由fifo参数决定, type是FIFO中成员的类型,size 则指定这个FIFO有多少个元素,但是元素的个数必须是2的幂。
使用起来也非常简单:
static ssize_t
demodrv_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int actual_readed;
int ret;
ret = kfifo_to_user(&mydemo_fifo, buf, count, &actual_readed);
if (ret)
return -EIO;
printk("%s, actual_readed=%d, pos=%lld\n",__func__, actual_readed, *ppos);
return actual_readed;
}
static ssize_t
demodrv_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
unsigned int actual_write;
int ret;
printk("%s: count=%u\n", __func__, count);
ret = kfifo_from_user(&mydemo_fifo, buf, count, &actual_write);
if (ret)
return -EIO;
printk("%s: actual_write =%d, ppos=%lld\n", __func__, actual_write, *ppos);
return actual_write;
}在userspace的程序:
```C
int main()
{
char buffer[256];
int fd;
int ret;
size_t len;
char message[] = "Testing the virtual FIFO device";
char *read_buffer;
len = sizeof(message);
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failded\n", DEMO_DEV_NAME);
return -1;
}
/*1. write the message to device*/
ret = write(fd, message, len);
if (ret != len) {
printf("canot write on device %d, ret=%d", fd, ret);
return -1;
}
read_buffer = malloc(2*len);
memset(read_buffer, 0, 2*len);
ret = read(fd, read_buffer, 2*len);
printf("read %d bytes\n", ret);
printf("read buffer=%s\n", read_buffer);
close(fd);
return 0;
}这里要注意,在write和read并没有任何的锁机制,而且例程在user空间只有一个使用者,实际上这样对于KFIFO来说,当SMP的场景,多个核的多个进程对同样的read和write函数操作同一份KFIFO这个时候就要小心了。这不是读写指针能控制的事情了,而是读写序在编译器层面或者执行时候流水线层面对读写操作的重排问题,这就引入了kfifo的内存屏障的问题。需要说明的是Linux 2.6.12版本的内核实现中并没有使用内存屏障,而在后续版本中添加了内存屏障,它是实现无锁队列的核心和关键。
__kfifo_put是入队操作,它先将数据放入buffer中,然后移动in的位置,其源代码如下:
unsigned int __kfifo_put(struct kfifo *fifo, const unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}- 6行,环形缓冲区的剩余容量为fifo->size - fifo->in + fifo->out,让写入的长度取len和剩余容量中较小的,避免写越界;
- 13行,加内存屏障,保证在开始放入数据之前,fifo->out取到正确的值(另一个CPU可能正在改写out值)
- 16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1),所以fifo->size - (fifo->in & (fifo->size - 1)) 即位 fifo->in 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为需要拷贝l 字节到fifo->buffer + fifo->in的位置上。
- 17行,拷贝l 字节到fifo->buffer + fifo->in的位置上,如果l = len,则已拷贝完成,第20行len – l 为0,将不执行,如果l = fifo->size - (fifo->in & (fifo->size - 1)) ,则第20行还需要把剩下的 len – l 长度拷贝到buffer的头部。
- 27行,加写内存屏障,保证in 加之前,memcpy的字节已经全部写入buffer,如果不加内存屏障,可能数据还没写完,另一个CPU就来读数据,读到的缓冲区内的数据不完全,因为读数据是通过 in – out 来判断的。
- 29行,注意这里 只是用了 fifo->in += len而未取模,这就是kfifo的设计精妙之处,这里用到了unsigned int的溢出性质,当in 持续增加到溢出时又会被置为0,这样就节省了每次in向前增加都要取模的性能,锱铢必较,精益求精,让人不得不佩服。
说完KFIFO的知识,虽然我们解决了读写并发的问题(程序上有读写指针分开,指令和编译上有内存屏障)可如果写把KFIFO的buffer长度写超了,会如何呢?这个程序十分的简单,没有任何的抗干扰能力,我们必须在驱动里面去handle这种情况,否则写超了,in指针会按照最大长度折叠(in的index比out的index小),KFIFO一直是满的状态,无法缓存数据,可能buffer会丢掉。所以我们必须有保护机制。
5.3 非阻塞IO/阻塞IO
对于上面KFIFO是满还是未满的状态,我们在程序上必须做出处理,这样就分为非阻塞和阻塞两种处理方法:
- 非阻塞IO:发现FIFO不符合要求的时候,我们直接返回错误码,要用户自己去处理;
- 阻塞IO:发现FIFO不符合要求的时候,我们让这次用户的请求睡眠,直到满足要求之后唤醒,然后给用户返回数据;
在驱动里面我们必须选定这个阻塞IO还是非阻塞IO,或者我们需要一个函数内对于这两种状态都要有处理。另外提示一下,阻塞IO和非阻塞IO并不是VFS层帮我们代理的,而是需要在驱动的read和write的函数中进行处理的。
驱动和内核会协定使用文件系统的flags来标识是非阻塞打开还是阻塞状态的打开,这个标识是O_NONBLOCK标记,如果没有这个标识,则表示是阻塞状态。在内核空间如果用户访问的设备资源不可用的时候需要返回-EAGAIN的错误码。
还需要分清楚同步/异步与阻塞和非阻塞概念:
1. 同步和异步 同步和异步描述的是消息通信的机制。同步:当一个request发送出去以后,会得到一个response,这整个过程就是一个同步调用的过程。哪怕response为空,或者response的返回特别快,但是针对这一次请求而言就是一个同步的调用。异步:当一个request发送出去以后,没有得到想要的response,而是通过后面的callback、状态或者通知的方式获得结果。可以这么理解,对于异步请求分两步:1)调用方发送request没有返回对应的response(可能是一个空的response);2)服务提供方将response处理完成以后通过callback的方式通知调用方。
2. 阻塞和非阻塞:阻塞和非阻塞描述的是程序在等待调用结果(消息,返回值)时的状态。阻塞:阻塞调用是指调用方发出request的线程因为某种原因(如:等待系统资源)被服务方挂起,当服务方得到response后就唤醒挂起线程,并将response返回给调用方。非阻塞调用是指调用方发出request的线程在没有等到结果时不会被挂起,直到得到response后才返回。阻塞和非阻塞最大的区别就是看调用方线程是否会被挂起。
5.3.1 非阻塞I/O
非阻塞IO对驱动来说十分好实现,检测状态不满足直接返回,其他的维护工作需要在用户空间实现。我们来改造一下上面的FIFO驱动,把他改成非阻塞模式。
static ssize_t
demodrv_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int actual_readed;
int ret;
/* 增加non block检测,如果用户读的时候buffer还是空的就返回 */
if (kfifo_is_empty(&mydemo_fifo)) {
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
}
ret = kfifo_to_user(&mydemo_fifo, buf, count, &actual_readed);
if (ret)
return -EIO;
printk("%s, actual_readed=%d, pos=%lld\n",__func__, actual_readed, *ppos);
return actual_readed;
}
static ssize_t
demodrv_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
unsigned int actual_write;
int ret;
/* 增加non block检测, 如果用户写的时候是满的就返回。 */
if (kfifo_is_full(&mydemo_fifo)){
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
}
ret = kfifo_from_user(&mydemo_fifo, buf, count, &actual_write);
if (ret)
return -EIO;
printk("%s: actual_write =%d, ppos=%lld, ret=%d\n", __func__, actual_write, *ppos, ret);
return actual_write;
}这样,我们在驱动上面增加了非阻塞机制,使我们的驱动handle的能力进一步增强了。
5.3.2 阻塞I/O
现在我们来实现阻塞,非阻塞场景在很多情况用户是不想选择的,因为这样他们在user空间不得不去维护一个复杂的状态机,而阻塞场景是经常使用的。阻塞的业务就要求,如果用户请求的资源(比如这里是KFIFO的状态)不符合要求,那么就让用户的请求睡下去,等到资源就绪之后,去唤醒这个操作。这套机制不需要我们来实现,Linux提供了现成的Wait Queue机制,我们在0x23_LinuxKernel_内核活动(三)中断体系结构(中断下文)部分对等待队列进行了整理。而驱动阻塞IO这块是应用等待队列的最好的例子。
Linux内核提供了睡眠等待和唤醒的接口:
wait_event(wq, condition)
wait_event_interruptible(wq, condition) // 进入中断可抢占的睡眠状态
wait_event_timeout(wq, condition, timeout)
wait_event_interruptible_timeout(wq, condtion, timeout)
wake_up(x)
wake_up_interruptible(x)注意:
- wake_up会唤醒等待队列中的所有进程。
- wake_up应该和wait_event或者wait_event_timeout配对使用
- wake_up_interruptible()或wait_event_interruptible()或者wait_event_interruptible_timeou()配对使用。
我们先对queue进行初始化:
static int __init simple_char_init(void)
{
int ret;
struct mydemo_device *device = kmalloc(sizeof(struct mydemo_device), GFP_KERNEL);
if (!device)
return -ENOMEM;
ret = misc_register(&mydemodrv_misc_device);
if (ret) {
printk("failed register misc device\n");
goto free_device;
}
device->dev = mydemodrv_misc_device.this_device;
device->miscdev = &mydemodrv_misc_device;
init_waitqueue_head(&device->read_queue);
init_waitqueue_head(&device->write_queue);
mydemo_device = device;
printk("succeeded register char device: %s\n", DEMO_NAME);
return 0;
free_device:
kfree(device);
return ret;
}这里一共初始化两个等待队列的元素,一个用于通知写,一个用于通知读。逻辑就是,当不满足写的条件的时候,调用waitqueue,让这个写的队列等待;接着在另一个读完成之后来唤醒这个写的。反之,亦然。
tatic ssize_t
demodrv_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
struct mydemo_private_data *data = file->private_data;
struct mydemo_device *device = data->device;
int actual_readed;
int ret;
if (kfifo_is_empty(&mydemo_fifo)) {
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
/* 等待写 */
printk("%s: pid=%d, going to sleep\n", __func__, current->pid);
ret = wait_event_interruptible(device->read_queue,
!kfifo_is_empty(&mydemo_fifo));
if (ret)
return ret;
}
ret = kfifo_to_user(&mydemo_fifo, buf, count, &actual_readed);
if (ret)
return -EIO;
/* 接着唤醒对方 */
if (!kfifo_is_full(&mydemo_fifo))
wake_up_interruptible(&device->write_queue);
printk("%s, pid=%d, actual_readed=%d, pos=%lld\n",__func__,
current->pid, actual_readed, *ppos);
return actual_readed;
}
static ssize_t
demodrv_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
struct mydemo_private_data *data = file->private_data;
struct mydemo_device *device = data->device;
unsigned int actual_write;
int ret;
if (kfifo_is_full(&mydemo_fifo)){
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
/* 等待写 */
printk("%s: pid=%d, going to sleep\n", __func__, current->pid);
ret = wait_event_interruptible(device->write_queue,
!kfifo_is_full(&mydemo_fifo));
if (ret)
return ret;
}
ret = kfifo_from_user(&mydemo_fifo, buf, count, &actual_write);
if (ret)
return -EIO;
/* 读完之后唤醒写 */
if (!kfifo_is_empty(&mydemo_fifo))
wake_up_interruptible(&device->read_queue);
printk("%s: pid=%d, actual_write =%d, ppos=%lld, ret=%d\n", __func__,
current->pid, actual_write, *ppos, ret);
return actual_write;
}5.4 异步通知 - 信号机制
我们来想一下,在驱动里面使用阻塞和非阻塞的方式。如果用户使用了阻塞的方式,我们会让用户进程睡眠,无形中耽误了用户的作业;而如果使用非阻塞方式,用户不断的去调用read和write来尝试缓冲区是否准备好。这两种方式都有弊端,我们是否可以通知到到用户,缓冲区已经准备好了,你可以来读了,如果有这样的事件能够通知到用户,那就起到了事半功倍的效果了。
这样的机制是有的,那就是异步-信号机制。我们在Linux空间可以注册信号,然后当信号发生的时候就会进入到程序的handler函数中。我们在驱动里面也可以发射这样的信号。异步通知到使用了signal()函数和sigcation()函数。
我们来给上面的阻塞程序增加信号机制吧,让用户尽可能少的睡眠在我们的内核里面。
- 我们要在我们设备context里面使用信号机制的结构体
strcut fasync_struct *fasync,这个就是使用信号机制的结构体。 - 我们还要在file_operations里面注册
.fasync,这个函数主要是构造异步通知的节点注册到内核之中。用户在用户空间不是注册了一个handler么,在这里会建立这个联系。static int demodrv_fasync(int fd, struct file *file, int on) { struct mydemo_private_data *data = file->private_data; struct mydemo_device *device = data->device; printk("%s send SIGIO\n", __func__); return fasync_helper(fd, file, on, &device->fasync); }
- 在read和write适当的位置发射信号。
static ssize_t
demodrv_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
struct mydemo_private_data *data = file->private_data;
struct mydemo_device *device = data->device;
int actual_readed;
int ret;
if (kfifo_is_empty(&device->mydemo_fifo)) {
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
printk("%s:%s pid=%d, going to sleep, %s\n", __func__, device->name, current->pid, data->name);
ret = wait_event_interruptible(device->read_queue,
!kfifo_is_empty(&device->mydemo_fifo));
if (ret)
return ret;
}
ret = kfifo_to_user(&device->mydemo_fifo, buf, count, &actual_readed);
if (ret)
return -EIO;
if (!kfifo_is_full(&device->mydemo_fifo)){
wake_up_interruptible(&device->write_queue);
/* 发射信号SIGIO */
kill_fasync(&device->fasync, SIGIO, POLL_OUT);
}
printk("%s:%s, pid=%d, actual_readed=%d, pos=%lld\n",__func__,
device->name, current->pid, actual_readed, *ppos);
return actual_readed;
}
static ssize_t
demodrv_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
struct mydemo_private_data *data = file->private_data;
struct mydemo_device *device = data->device;
unsigned int actual_write;
int ret;
if (kfifo_is_full(&device->mydemo_fifo)){
if (file->f_flags & O_NONBLOCK)
return -EAGAIN;
printk("%s:%s pid=%d, going to sleep\n", __func__, device->name, current->pid);
ret = wait_event_interruptible(device->write_queue,
!kfifo_is_full(&device->mydemo_fifo));
if (ret)
return ret;
}
ret = kfifo_from_user(&device->mydemo_fifo, buf, count, &actual_write);
if (ret)
return -EIO;
if (!kfifo_is_empty(&device->mydemo_fifo)) {
wake_up_interruptible(&device->read_queue);
/* 发射信号SIGIO */
kill_fasync(&device->fasync, SIGIO, POLL_IN);
printk("%s kill fasync\n", __func__);
}
printk("%s:%s pid=%d, actual_write =%d, ppos=%lld, ret=%d\n", __func__,
device->name, current->pid, actual_write, *ppos, ret);
return actual_write;
}这部分需要User处理和注册一些事情:
void my_signal_fun(int signum, siginfo_t *siginfo, void *act)
{
int ret;
char buf[64];
if (signum == SIGIO) {
if (siginfo->si_band & POLLIN) {
printf("FIFO is not empty\n");
if ((ret = read(fd, buf, sizeof(buf))) != -1) {
buf[ret] = '\0';
puts(buf);
}
}
if (siginfo->si_band & POLLOUT)
printf("FIFO is not full\n");
}
}
int main(int argc, char *argv[])
{
int ret;
int flag;
struct sigaction act, oldact;
sigemptyset(&act.sa_mask);
sigaddset(&act.sa_mask, SIGIO);
act.sa_flags = SA_SIGINFO;
act.sa_sigaction = my_signal_fun;
if (sigaction(SIGIO, &act, &oldact) == -1)
goto fail;
fd = open("/dev/mydemo0", O_RDWR);
if (fd < 0)
goto fail;
/*设置异步IO所有权*/
if (fcntl(fd, F_SETOWN, getpid()) == -1)
goto fail;
/*将当前进程PID设置为fd文件所对应驱动程序将要发送SIGIO,SIGUSR信号进程PID*/
if (fcntl(fd, F_SETSIG, SIGIO) == -1)
goto fail;
/*获取文件flags*/
if ((flag = fcntl(fd, F_GETFL)) == -1)
goto fail;
/*设置文件flags, 设置FASYNC,支持异步通知*/
if (fcntl(fd, F_SETFL, flag | FASYNC) == -1)
goto fail;
while (1)
sleep(1);
fail:
perror("fasync test");
exit(EXIT_FAILURE);
}5.5 同步通知 - poll机制
很多应用程序很复杂,open read write close很难满足这些业务逻辑。对于这些应用程序而言,当设备上有数据的时候或者驱动程序到来的时候,系统最好能够采用同步或者异步的方式通知他们。同步的方式就是轮询poll,异步的方式就是上面提到的信号机制。
Linux也提供了轮询操作,而且轮询附带了可以多个文件描述符一起管理的方法。Linux内核提供了poll/select/epoll这三种机制。一旦某个文件描述符就绪,就立刻通知程序进行相应的写操作。因此,他们经常在那些需要使用多个输入或者输出数据流而不会阻塞在其中的一个数据流。
5.5.1 I/O 多路复用之select、poll、epoll详解4
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
epoll操作过程需要三个接口,分别如下:
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);5.5.2 在驱动中增加轮询
Linux内核在file_operation上面提供了poll()方法的实现。当用户打开设备文件执行poll或者select时候就会被调用。设备驱动的poll流程是:
- 在一个或者多个等待队列中调用
poll_wait函数。poll_wait函数会把当前的进程添加到指定的列表中(poll_table),也就是POLLIN和POLLOUT等掩码。 - 返回监听事件,也就是让应用程序同时等待多个数据流
一般这样的驱动都采用多路复用IO,是多个相同的设备。
注册
这里注册MYDEMO_MAX_DEVICES各设备,要向系统申请MYDEMO_MAX_DEVICES个id号。然后使用for循环创建等待队列机制,这里一共有 2 * MYDEMO_MAX_DEVICES个等待队列。
static int __init simple_char_init(void)
{
int ret;
int i;
struct mydemo_device *device;
ret = alloc_chrdev_region(&dev, 0, MYDEMO_MAX_DEVICES, DEMO_NAME);
if (ret) {
printk("failed to allocate char device region");
return ret;
}
demo_cdev = cdev_alloc();
if (!demo_cdev) {
printk("cdev_alloc failed\n");
goto unregister_chrdev;
}
cdev_init(demo_cdev, &demodrv_fops);
ret = cdev_add(demo_cdev, dev, MYDEMO_MAX_DEVICES);
if (ret) {
printk("cdev_add failed\n");
goto cdev_fail;
}
for (i = 0; i < MYDEMO_MAX_DEVICES; i++) {
device = kmalloc(sizeof(struct mydemo_device), GFP_KERNEL);
if (!device) {
ret = -ENOMEM;
goto free_device;
}
sprintf(device->name, "%s%d", DEMO_NAME, i);
mydemo_device[i] = device;
init_waitqueue_head(&device->read_queue);
init_waitqueue_head(&device->write_queue);
ret = kfifo_alloc(&device->mydemo_fifo,
MYDEMO_FIFO_SIZE,
GFP_KERNEL);
if (ret) {
ret = -ENOMEM;
goto free_kfifo;
}
printk("mydemo_fifo=%px\n", &device->mydemo_fifo);
}
printk("succeeded register char device: %s\n", DEMO_NAME);
return 0;
free_kfifo:
for (i =0; i < MYDEMO_MAX_DEVICES; i++)
if (&device->mydemo_fifo)
kfifo_free(&device->mydemo_fifo);
free_device:
for (i =0; i < MYDEMO_MAX_DEVICES; i++)
if (mydemo_device[i])
kfree(mydemo_device[i]);
cdev_fail:
cdev_del(demo_cdev);
unregister_chrdev:
unregister_chrdev_region(dev, MYDEMO_MAX_DEVICES);
return ret;
}注册poll
需要在file_operations注册poll函数:
static unsigned int demodrv_poll(struct file *file, poll_table *wait)
{
int mask = 0;
struct mydemo_private_data *data = file->private_data;
struct mydemo_device *device = data->device;
poll_wait(file, &device->read_queue, wait);
poll_wait(file, &device->write_queue, wait);
if (!kfifo_is_empty(&device->mydemo_fifo))
mask |= POLLIN | POLLRDNORM;
if (!kfifo_is_full(&device->mydemo_fifo))
mask |= POLLOUT | POLLWRNORM;
return mask;
}
static const struct file_operations demodrv_fops = {
.owner = THIS_MODULE,
.open = demodrv_open,
.release = demodrv_release,
.read = demodrv_read,
.write = demodrv_write,
.poll = demodrv_poll,
};这部分就是返回可用状态。
read和write
这部分不需要做任何的操作,全部都由poll来负责更新状态。
用户侧
int main(int argc, char *argv[])
{
int ret;
struct pollfd fds[2];
char buffer0[64];
char buffer1[64];
fds[0].fd = open("/dev/mydemo0", O_RDWR);
if (fds[0].fd == -1)
goto fail;
fds[0].events = POLLIN;
fds[1].fd = open("/dev/mydemo1", O_RDWR);
if (fds[1].fd == -1)
goto fail;
fds[1].events = POLLIN;
while (1) {
ret = poll(fds, 2, -1);
if (ret == -1)
goto fail;
if (fds[0].revents & POLLIN) {
ret = read(fds[0].fd, buffer0, sizeof(buffer0));
if (ret < 0)
goto fail;
printf("%s\n", buffer0);
}
if (fds[1].revents & POLLIN) {
ret = read(fds[1].fd, buffer1, sizeof(buffer1));
if (ret < 0)
goto fail;
printf("%s\n", buffer1);
}
}
fail:
perror("poll test failed");
exit(EXIT_FAILURE);
}这里测试了两个设备。通过poll来检查fd的状态,然后再去决定操作哪个设备。