0x32_LinuxKernel_内存管理(二)虚拟内存管理、缺页与调试工具
carloscn opened this issue · 0 comments
0x32_LinuxKernel_内存管理(二)虚拟内存管理、缺页与调试工具
我们经常在Linux的应用程序中使用malloc()这个函数分配内存,而这部分我们从来没有探究过它里面到底如何实现的。理论上,64位的操作系统可以访问到256T的内存空间地址,可以远远大于物理内存,我们在这章就要去弄懂,Linux内核如何去管理这些内存?出了malloc()动态分配的函数,还有mmap()是用户空间中用于建立文件映射或匿名映射的函数,这部分本章也需要讲解一些原理性的内容。
0 内核内存分配
先来回顾一下内核地址空间:
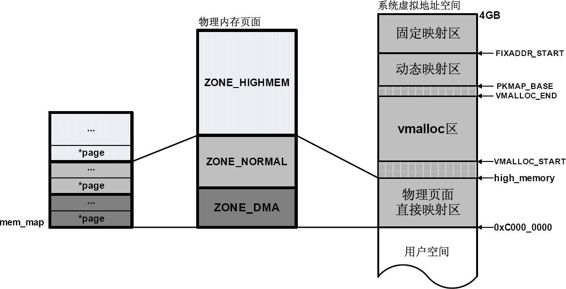
在内核态申请内存比在用户态申请内存要更为直接,它没有采用用户态那种延迟分配(通过缺页机制来反馈)内存技术。一旦有内核函数申请内存,那么就必须立刻满足该申请内存的请求,并且这个请求一定是正确合理的。相反,对于用户态申请内存的请求,内核总是尽量延后分配物理内存,用户进程总是先获得一个虚拟内存区的使用权,最终通过缺页异常获得一块真正的物理内存。
内核虚拟地址空间只有 1GB 大小,因此可以直接将 1GB 大小的物理内存映射到内核地址空间,但超出 1GB 大小的物理内存(高端内存)就不能映射到内核空间。为此,内核采取了下面的方法使得内核可以使用所有的物理内存:
-
高端内存不能全部映射到内核空间,也就是说这些物理内存没有对应的线性地址。不过,内核为每个物理页都分配了对应的页描述符,所有的页框描述符都保存在 mem_map 数组中,因此每个页描述符的线性地址都是固定存在的。内核此时可以使用 alloc_pages() 和 alloc_page() 来分配高端内存,因为这些函数返回页框描述符的线性地址。
-
内核地址空间的后 128MB 专门用于映射高端内存,否则,没有线性地址的高端内存不能被内核所访问。这些高端内存的内核映射显然是暂时映射的,否则也只能映射 128MB 的高端内存。当内核需要访问高端内存时就临时在这个区域进行地址映射,使用完毕之后再用来进行其他高端内存的映射。
由于要进行高端内存的内核映射,因此直接能够映射的物理内存大小只有 896MB,该值保存在 high_memory 中。内核地址空间的线性地址区间如下图所示:
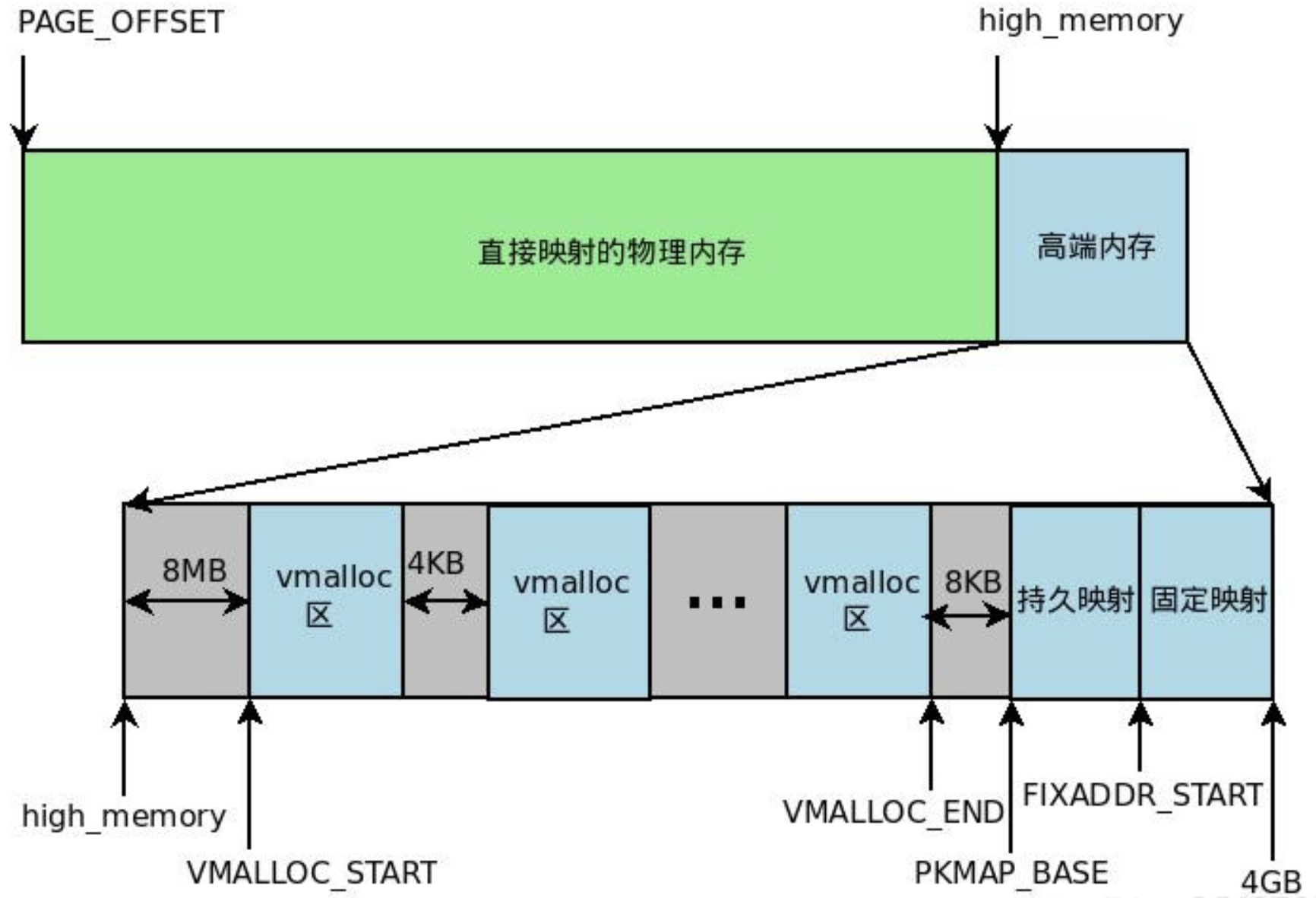
从图中可以看出,内核采用了三种机制将高端内存映射到内核空间:永久内核映射、固定映射和 vmalloc 机制。
而这些底层依赖于内核 API:
- mempool_create:创建内存池对象
- mempool_alloc:分配函数获得该对象
- mempool_free:释放一个对象
- mempool_destroy:销毁内存池
这里就涉及了**内存池(memory pool) **的概念。
0.1 内存池1
通常的进程发起申请内存的动作之后,会在系统的空闲内存区寻找合适大小的内存块(底层分配函数__alloc_node_mask),如果满足就直接分配,如果不满足就会向上查找。如果过大就会进行分裂,一部分分给申请进程,一部分放入空闲区。释放时需要找到这个块对应的伙伴,如果伙伴也为空闲,就进行合并,放入高阶空闲链表,如果不空闲就放入对应链表。同时对于多线程申请和释放内存,需要加锁。这样的默认的分配方式考虑到了系统中的大部分情况,具有通用性,但是无可避免的会产生内部碎片,而且加锁,解锁的开销也很大。程序可以通过系统的内存分配方法预先分配一大块内存来做一个内存池,之后程序的内存分配和释放都由这个内存池来进行操作和管理,当内存池不足时再向系统申请内存。
我们通常使用malloc等函数来为用户进程分配内存。它的执行过程通常是由用户程序发起malloc申请内存的动作,在标准库找到对应函数,对不满128k的调用brk()系统调用来申请内存(申请的内存是堆区内存),接着由操作系统来执行brk系统调用。
我们知道malloc是在标准库,真正的申请动作需要操作系统完成。所以由应用程序到操作系统就需要3层。内存池是专为应用程序提供的专属的内存管理器,它属于应用程序层。所以程序申请内存的时候就不需要通过标准库和操作系统,明显降低了开销。
这部分请参考: Linux机制之内存池.md
0.2 vmalloc和kmalloc函数2
vmalloc和kmalloc的分配内存的特点大概如下:

区别大概可总结为:
- vmalloc分配的一般为高端内存,只有当内存不够的时候才分配低端内存;kmallco从低端内存分配。
- vmalloc分配的物理地址一般不连续,而kmalloc分配的地址连续,两者分配的虚拟地址都是连续的;
- vmalloc分配的一般为大块内存,而kmalloc一般分配的为小块内存,(一般不超过128k);
0.2.1 vmalloc
vmalloc 分配的虚拟地址区间,位于 vmalloc_start 与 vmalloc_end 之间的动态内存映射区。一般用分配大块内存,释放内存对应于 vfree,分配的虚拟内存地址连续,物理地址上不一定连续。函数原型在 <linux/vmalloc.h> 中声明。一般用在为活动的交换区分配数据结构,为某些 I/O 驱动程序分配缓冲区,或为内核模块分配空间。
内核通过它来申请非连续的物理内存,若申请成功,该函数返回连续内存区的起始地址,否则,返回 NULL。vmalloc() 和 kmalloc() 申请的内存有所不同,kmalloc() 所申请内存的线性地址与物理地址都是连续的,而 vmalloc() 所申请的内存线性地址连续而物理地址则是离散的,两个地址之间通过内核页表进行映射。vmalloc() 使得内核通过连续的线性地址来访问非连续的物理页,这样可以最大限度的使用高端物理内存。
vmalloc() 的工作方式理解起来很简单:
- 寻找一个新的连续线性地址空间;
- 依次分配一组非连续的页框;
- 为线性地址空间和非连续页框建立映射关系,即修改内核页表;
vmalloc() 的内存分配原理与用户态的内存分配相似,都是通过连续的虚拟内存来访问离散的物理内存,并且虚拟地址和物理地址之间是通过页表进行连接的,通过这种方式可以有效的使用物理内存。但是应该注意的是,vmalloc() 申请物理内存时是立即分配的,因为内核认为这种内存分配请求是正当而且紧急的;相反,用户态有内存请求时,内核总是尽可能的延后,毕竟用户态跟内核态不在一个特权级。
可见,vmalloc 的主要目的就是用多个碎片来拼凑出一个大内存,相当于收集一些 “边角料”,组装成一个成品后再 “出售”。
0.2.2 kmalloc
kmalloc() 分配的虚拟地址范围在内核空间的直接内存映射区。按字节为单位虚拟内存,一般用于分配小块内存,释放内存对应于 kfree ,可以分配连续的物理内存。函数原型在 <linux/kmalloc.h> 中声明,一般情况下在驱动程序中都是调用 kmalloc() 来给数据结构分配内存。
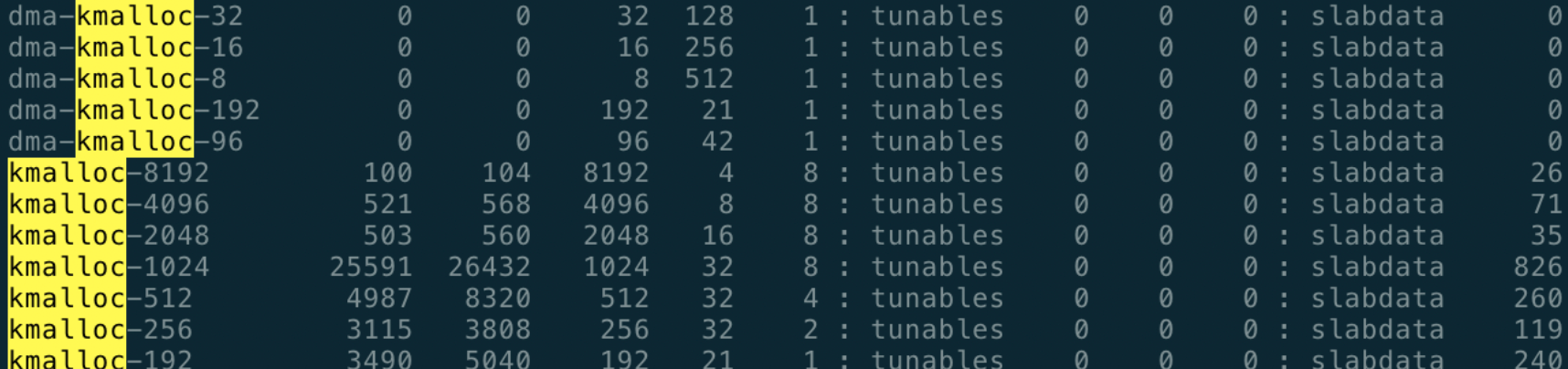
kmalloc 是基于 Slab 分配器的,同样可以用 cat /proc/slabinfo 命令,查看 kmalloc 相关 slab 对象信息,下面的 kmalloc-8、kmalloc-16 等等就是基于 Slab 分配的 kmalloc 高速缓存。
1 进程地址空间
1.1 温故ELF而知新
我们在ELF动态链接部分实际上涉及了一部分进程地址空间的概念04_ELF文件_加载进程虚拟地址空间 ,而且当时我们还留了一个悬念:
早期程序在ROM中直接加载到RAM里面执行,这种方法就十分简陋;RAM是一个十分珍贵的资源,这种方式当然不能被接受,后来人们提出了Overlay覆盖装入的方法,但这样的方法需要程序员自己对互不相关没有调用的函数进行管理,需要根据依赖关系组织成树状结构,对于开发者十分不友好;现代操作系统使用也映射(paging)的方法,按页完成数据和指令在ROM和RAM中的换入和换出(SWAP);现在操作系统还引入了MMU,让这种paging变得更为复杂。
1.1 ELF -> PVS -> PMS
最终程序的执行从编译出的ELF逻辑空间,会被映射到PVS(进程虚拟空间),最后被MMU映射到PMS(物理内存空间)。我们在编译一个文件的时候在ELF文件中readelf可以看到VMA的地址,VMA的地址是虚拟内存区域(Virtual Memory Area)。关于ELF->PVS,我们这里关注点在于ELF->PVS加载的过程,对于PVS->PMS属于MMU的知识范畴,这里暂时不涉及,相关TOPICS也会在ARM架构和Linux内核里面着重展开。
ELF中的各种段会被映射到进程虚拟空间上,如下图所示,.text段会被load到PVS上面。

进程地址空间(PAS)[内存区域] 指的是进程可寻址的虚拟地址空间。理论上,64位的操作系统可以寻址到256T的空间一一列举,但是需要注意的是:第一,用户进程没有权限访问内核空间的地址,只能通过系统调用的方式去合法访问;第二,内存区域是有属性标定的,比如可读可写可执行;因此理论上的空间访问是小于256T的,不是随心所欲可以访问的。
从Linux内核的视图3
| 64位 | 32位 |
|---|---|
 |
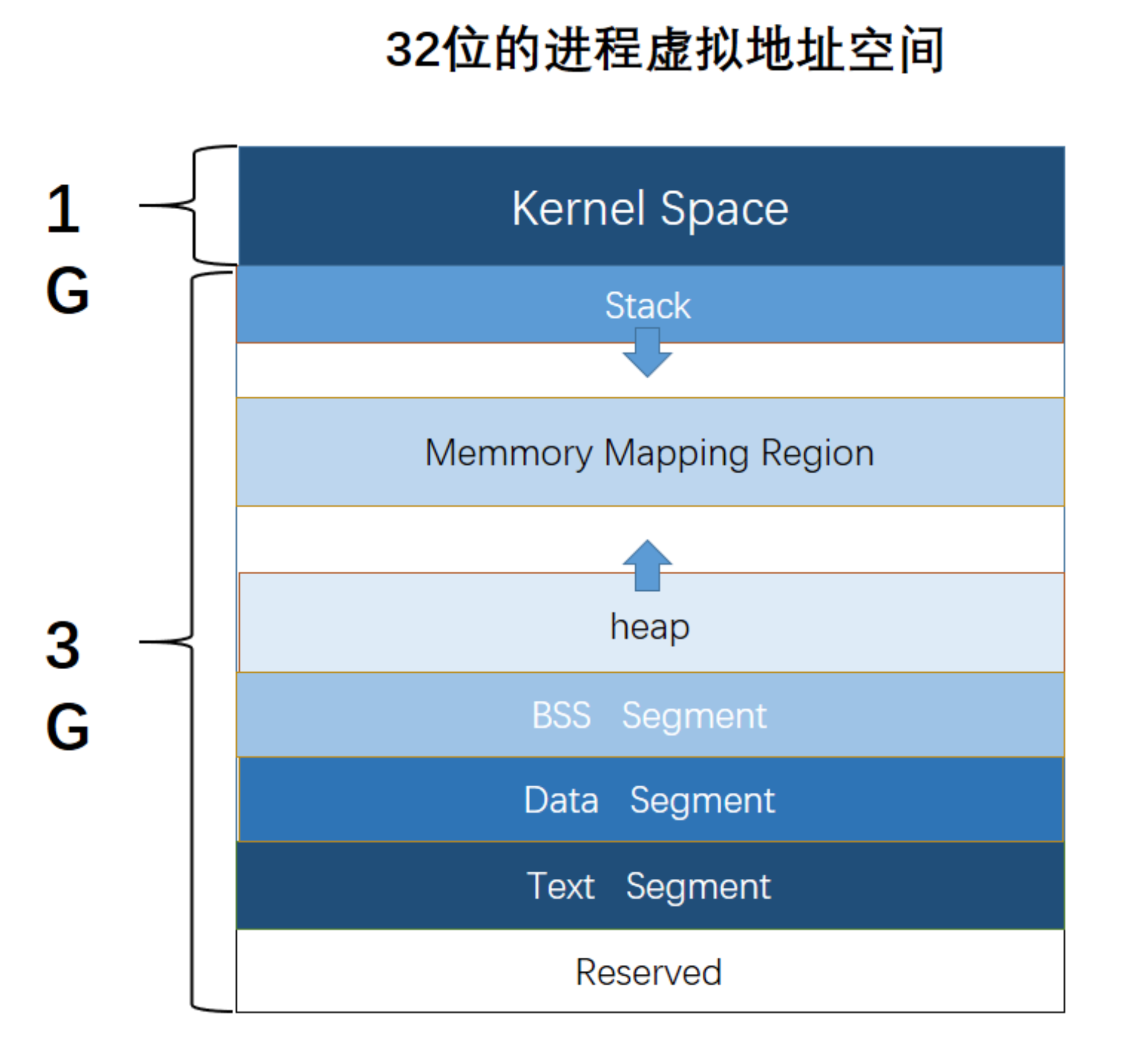 |
64位和32位的进程地址空间分配大致如上图所示。在elf中的section会被进行区域合并最后被映射为segment。
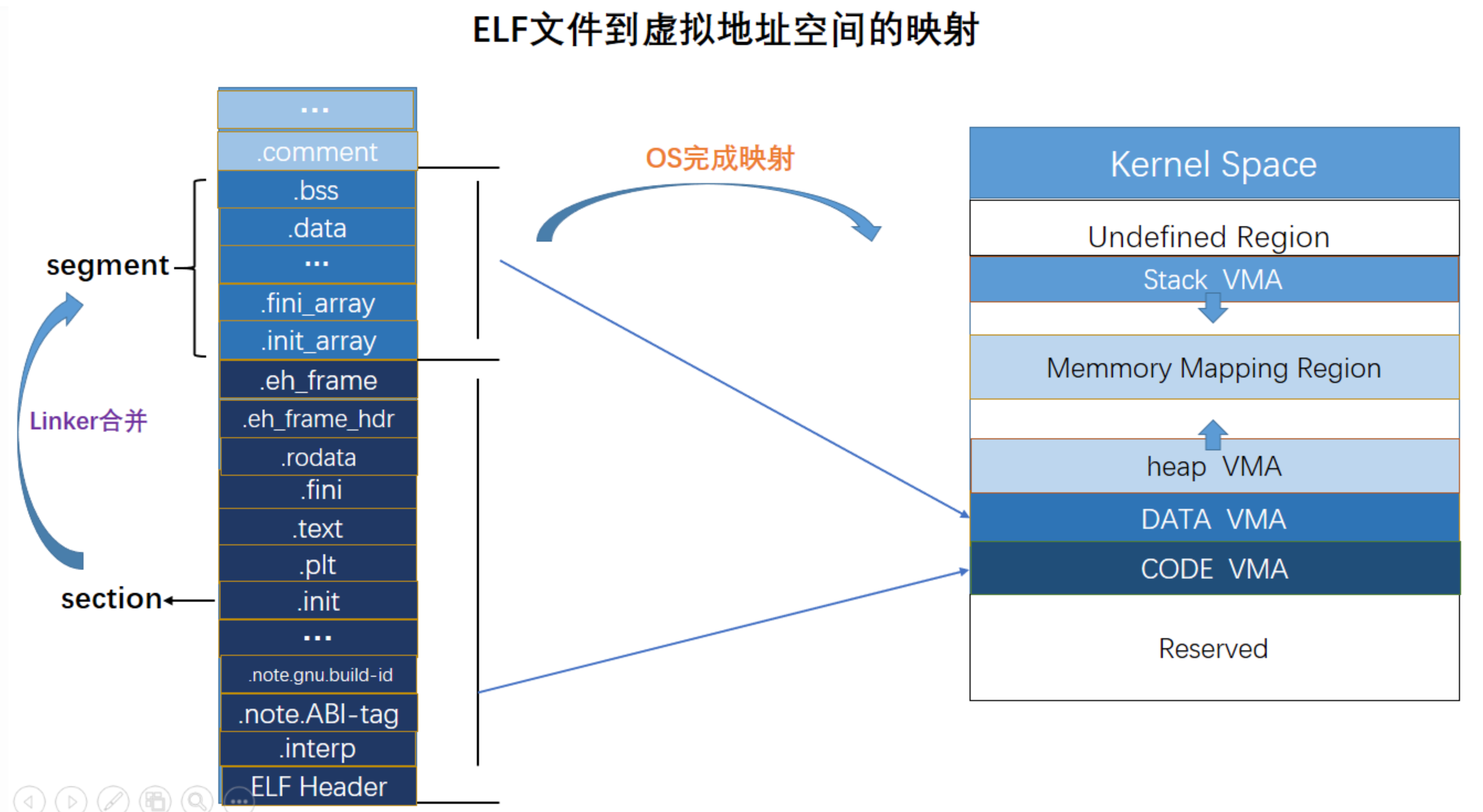
最后我们通过一个打印变量地址的小程序进行验证,仔细观察没有初始化的全局变量和一些静态变量的线性地址。

进程和进程之间还有一个进程内的内存区域不能重叠。但是我们经常看见一个现象,就是在两个进程中使用printf打印出变量的地址,会遇到碰撞的情况。实际上这样是合理的,每个进程都会自大的以为自己占用了所有的虚拟内存,可实际上这是操作系统的欺骗。操作系统会给每个进程一份单独的页表,而页表上有虚拟地址对应物理地址的空间映射关系,比如操作系统告诉进程A,虚拟地址0x1,对应的物理地址是0xffff1;转而在进程B的也表中告诉0x1虚拟地址对应的物理地址是0xaaaa1。操作系统依靠这种映射关系不一致的欺骗,造就了就算是两个进程的虚拟地址碰撞了也完全没有任何关系。操作系统“渣男”的行为脚踏N条船,让这些可怜的进程都洋洋得意的以为自己占据了整个操作系统。
1.2 内存描述符mm_struct
既然上面提到了说每个进程都有一份独立的页表,因此在进程的描述符task_struct中必然有一个结构体来表示内存信息,这个角色就是mm_struct。这里对于mm_struct的结构不展开了,用一个图来表示4:

linux的进程在内核中是由一个task_struct结构体描述的,其中task_struct里面有一个mm_struct结构体,该结构体是进程内存管理的主要结构体。其中mm_struct 存放了每一个虚拟地址段的起始地址;进程使用的真正的物理内存的页数;进程使用虚拟空间的数量;其他额外的信息。进程内存管理主要包括两部分:虚拟地址块的集合和页表5。
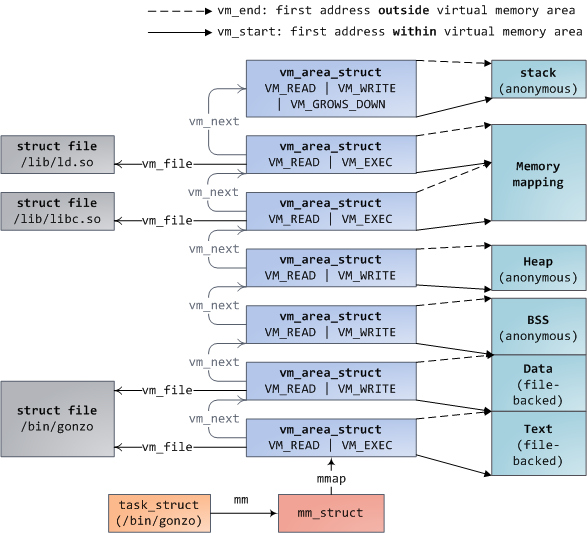
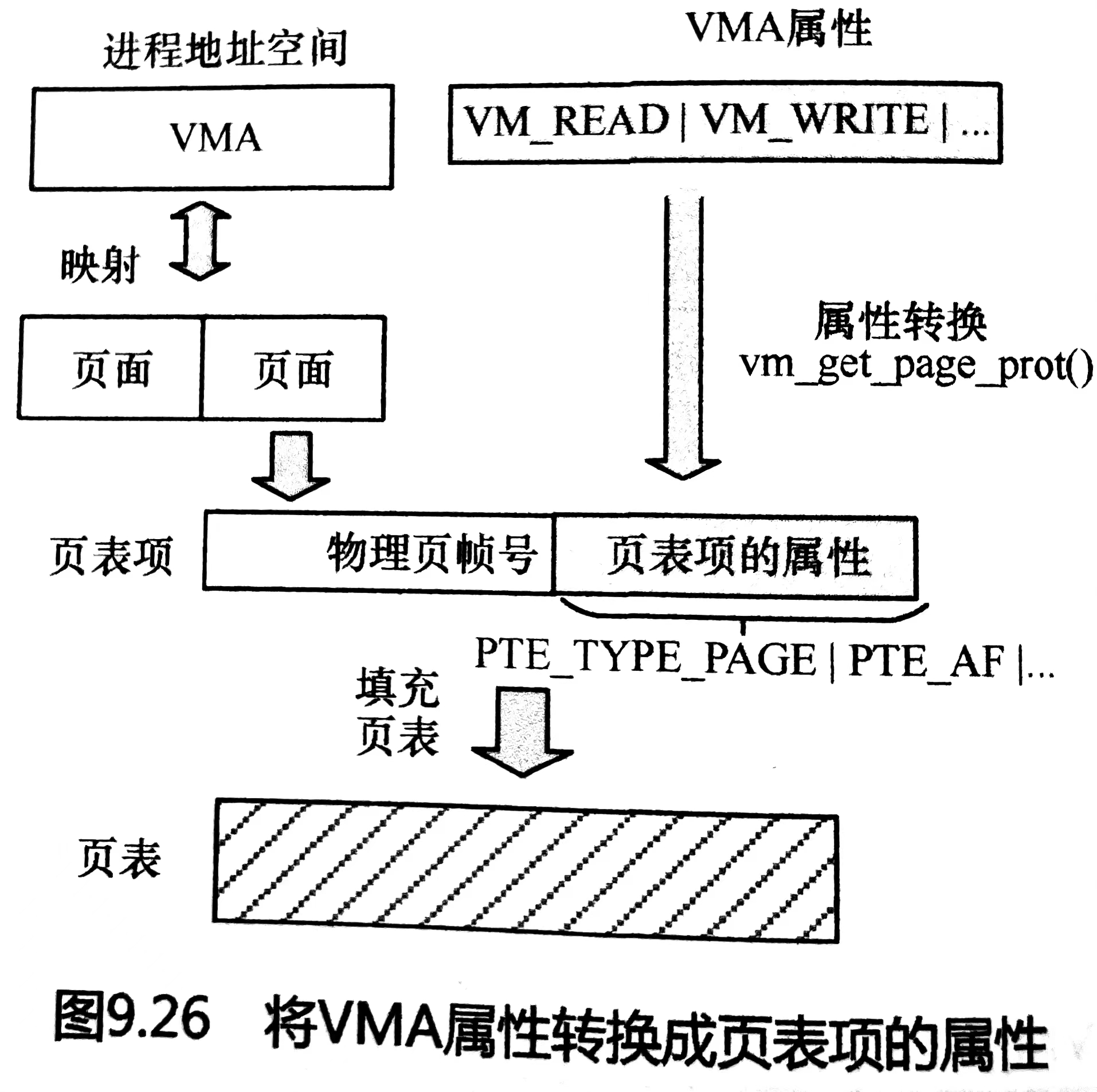
每一个虚拟地址空间(virtual memory area,简称VMA)是一段连续的虚拟地址区间,这些区间不会重叠。每一个VMA由一个vm_area_struct来描述,包括VMA的起始和结束地址,访问权限等。其中的vm_file字段表示了该区域映射的文件(如果有的话)。有些不映射文件的VMA是匿名的,例如上图中的heap/stack都分别对应于一个单独的匿名的VMA。进程的VMA存放在一个list和一个红黑树中,该list根据VMA的起始地址排序。存放在红黑树中是为了加快查找速度可以很快的查找某一地址是否在进程的某一个VMA中。通过命令读取/proc/pid_of_process/maps文件查看进程的内存映射时,其实内核只是简单便利了存放VMA的list然后打印出来。
VMA有着很多属性这些属性都会被写入到页表中,属性可以参考6。
1.3 malloc函数
malloc是从系统分配内存的函数。假设系统有进程A和进程B,分别使用testA()和testB()分配内存。
void testA(void)
{
char *bufA = malloc(100);
*bufA = 100;
}
void testB(void)
{
char *bufB = malloc(100);
mlock(bufB, 100);
}就这两个进程中的malloc,我提几个问题:
- malloc函数会不会立即分配物理内存?testA和testB什么时候分配内存呢?
- 假设不考虑libc的因素,如果malloc函数分配100字节,那么实际上内核会分配100字节吗?
- 假设bufA和bufB打印出的地址是一样的,会不会出现内存冲突?
malloc函数是C语言标准库中封装的一个核心的函数。C标准库在做一些处理之后最终会通过系统调用调到Linux内核中真正的分配和处理内存,这个系统调用就是brk()。如果malloc是一个零售商的话,brk就是代理商。malloc在自己的柜面上摆出一部分商品,当这些商品全部售空之后,才会用brk进货,而brk最终要向厂家(内核)批发更多的货物。
我来回答第一个问题:malloc函数会不会立即分配物理内存?testA和testB什么时候分配内存呢?
malloc更像是餐厅的预定功能,食客打电话给餐厅预定位置,就相当于malloc订出一部分虚拟地址空间,站在食客的角度,多了一层保险,自己喜欢的位置可以被保护一段时间,自己尽快动身出发去餐厅使用这个位置;站在餐厅角度,这部分被客人订出去了,别人来的时候会优先使用其他的位置。
因此,testA函数只是向malloc预定了一个100字节大小的空间,并没有真正的使用。当使用这段内存的时候,CPU去查询页表,发现页表为空,触发缺页异常,然后在缺页异常中一页页的分配内存,需要一页就给一页。
而TestB函数在预定完之后使用mlock保持住了这段内存,mlock的功能的意思是立即分页,且保证这些页的内存始终不会被换出。
我们再来回答第二个问题,malloc分配了100字节,那么实际会分配100字节吗?还是拿餐厅举例,餐厅的位置已经在建立店子的时候设定好了,有两人的,有四人的,也有包间十人的。我们去餐厅比如有5个,那么我们不会考虑选择四人的,只能考虑更大空间的,或许我们订一个十人的包间比较好,虽然这样有点浪费,但能满足我们的人数需求。malloc也是这样的,在设计的时候是以4K页大小为空间的。那么即便是我分配了100字节,那么也要按照页面对齐的原则。这就像是在写作业,我想写一篇作文,作业本就是A4纸大小,一般人会把一个话题另起一个新页。分配空间也是这样,即便我们可能就写了一句话,但是还要另起新页。你可能说,这样好浪费啊,但要注意这里本质是分配的是虚拟内存,几乎是想要多大就有多大,就像你在ipad上写字,一页写一个字都没有什么代价,因为没有实际的物理内存消耗,只是虚拟状态的内存。而真正touch物理内存的时候内存就要可丁可卯了。
malloc 是如何分配内存的?7
实际上,malloc() 并不是系统调用,而是 C 库里的函数,用于动态分配内存。malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
- 方式一:通过 brk() 系统调用从堆分配内存;
- 方式二:通过 mmap() 系统调用在文件映射区域分配内存;
方式一实现的方式很简单,就是通过 brk() 函数将「堆顶」指针向高地址移动(水线更新),获得新的内存空间。如下图:
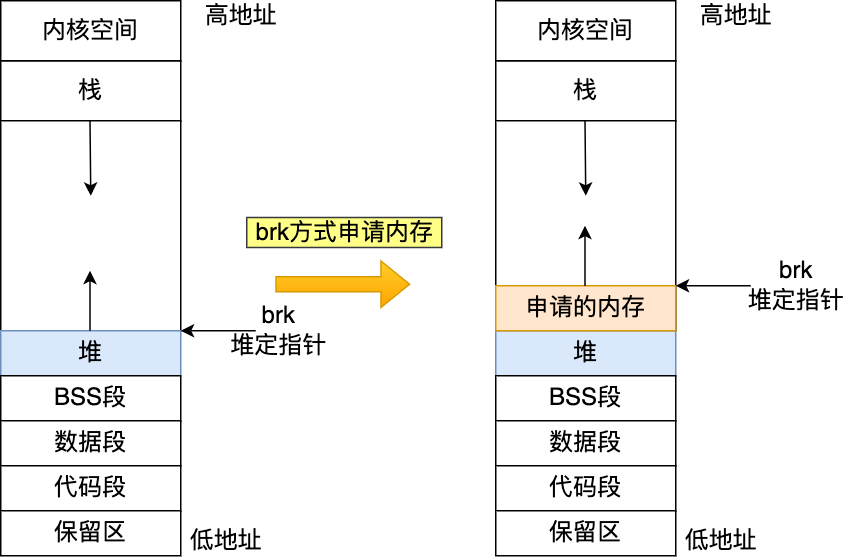
malloc(1) 会分配多大的虚拟内存?7
malloc() 在分配内存的时候,并不是老老实实按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池。具体会预分配多大的空间,跟 malloc 使用的内存管理器有关系,我们就以 malloc 默认的内存管理器(Ptmalloc2)来分析。接下里,我们做个实验,用下面这个代码,通过 malloc 申请 1字节的内存时,看看操作系统实际分配了多大的内存空间。
code: https://github.com/carloscn/clab/blob/master/linux/test_memory/malloc_failed.c
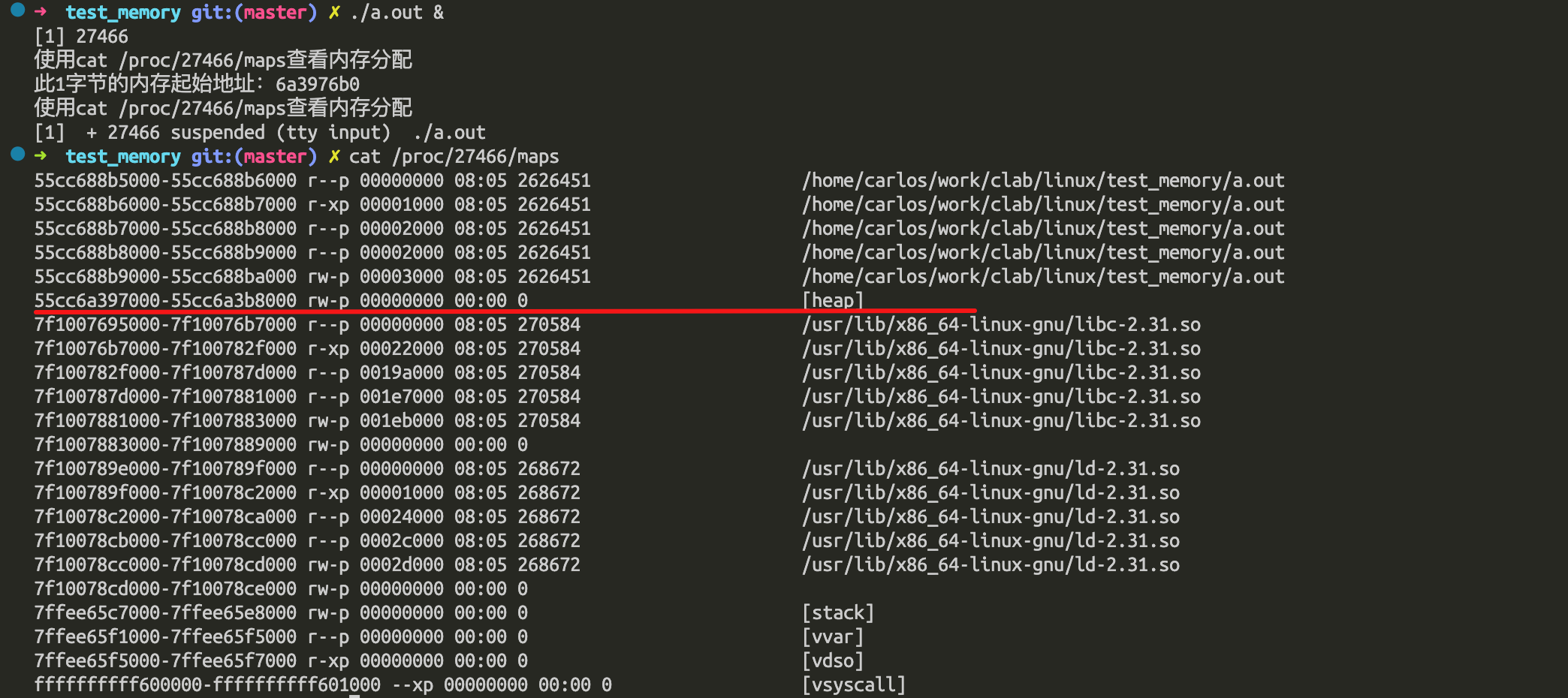
这个heap空间是 0x55cc6a397000 - 0x55cc6a3b8000 长度是 132K字节,我们开辟的内存起始位置是0x55cc6a3976b0 那么长度就是1712字节。在这个1712里面有一些系统需要去使用的heap,还包含了malloc管理内存的文件头信息。

free 释放内存,会归还给操作系统吗?7
我们在上面的进程往下执行,看看通过 free() 函数释放内存后,堆内存还在吗? 通过 free 释放内存后,堆内存还是存在的,并没有归还给操作系统。这个还要从malloc原理说起8:
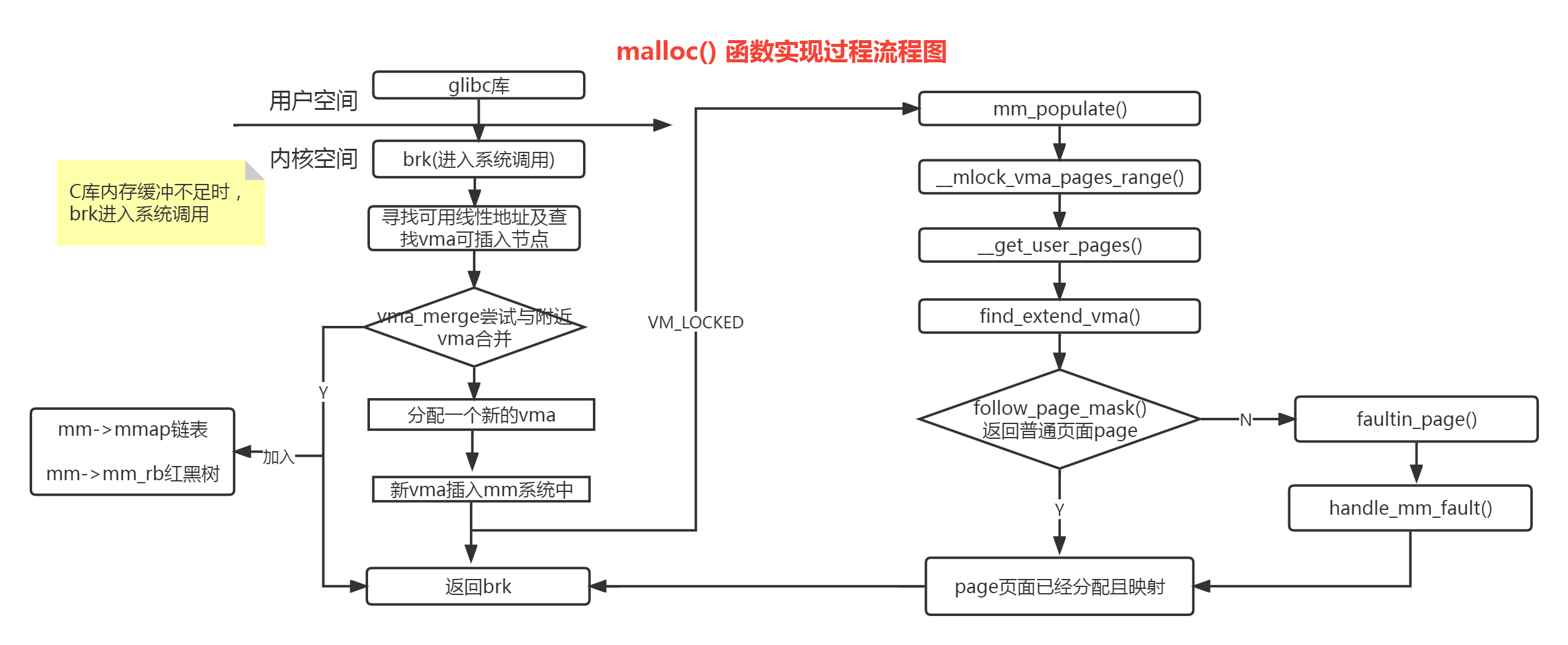
glibc库会调brk()系统调用,之后会寻找线性地址查找VMA的可插入节点,接着会尝试合并vma,如果失败就会分配一个新的vma,如果合并成功那么就直接返回这个地址。这个就相当于对于已经回收的地址进行一次利用从而减少碎片产生。
这里有个完整的图,有兴趣可以看看:
1.4 mmap函数
mmap()/munmap()是用户空间最常用的两个系统调用,无论在用户空间分配内存、读写大文件、动态库,还是在多进程之间的共享内存,都有对mmap的使用。
映射内容到进程地址空间示意图:
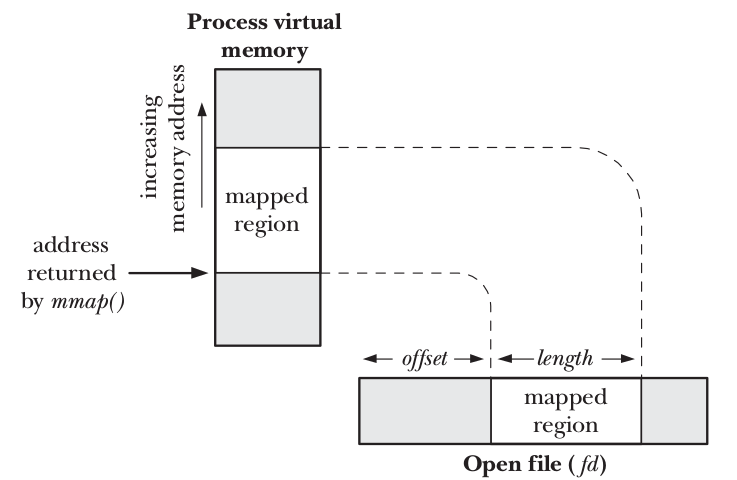
mmap的声明为9:
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);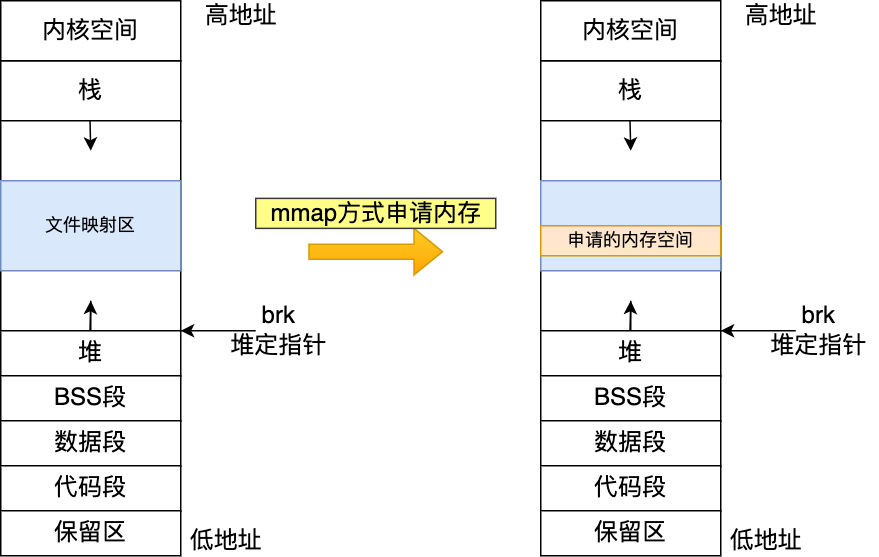
返回说明:
成功执行时,mmap()返回被映射区的指针,munmap()返回0。失败时,mmap()返回MAP_FAILED[其值为(void *)-1],munmap返回-1。errno被设为以下的某个值
EACCES:访问出错
EAGAIN:文件已被锁定,或者太多的内存已被锁定
EBADF:fd不是有效的文件描述词
EINVAL:一个或者多个参数无效
ENFILE:已达到系统对打开文件的限制
ENODEV:指定文件所在的文件系统不支持内存映射
ENOMEM:内存不足,或者进程已超出最大内存映射数量
EPERM:权能不足,操作不允许
ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
SIGSEGV:试着向只读区写入
SIGBUS:试着访问不属于进程的内存区
参数:
start:映射区的开始地址。
length:映射区的长度。
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
PROT_EXEC //页内容可以被执行
PROT_READ //页内容可以被读取
PROT_WRITE //页可以被写入
PROT_NONE //页不可访问
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
MAP_FIXED //使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
MAP_SHARED //与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。
MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
MAP_DENYWRITE //这个标志被忽略。
MAP_EXECUTABLE //同上
MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
MAP_LOCKED //锁定映射区的页面,从而防止页面被交换出内存。
MAP_GROWSDOWN //用于堆栈,告诉内核VM系统,映射区可以向下扩展。
MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联。
MAP_ANON //MAP_ANONYMOUS的别称,不再被使用。
MAP_FILE //兼容标志,被忽略。
MAP_32BIT //将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。
MAP_POPULATE //为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。
MAP_NONBLOCK //仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。
fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1。
offset:被映射对象内容的起点。
如果 malloc 通过 mmap 方式申请的内存,free 释放内存后就会归归还给操作系统。我们做个实验验证下, 通过 malloc 申请 128 KB 字节的内存,来使得 malloc 通过 mmap 方式来分配内存。
code: https://github.com/carloscn/clab/blob/master/linux/test_memory/malloc_failed.c

查看进程的内存的分布情况,可以发现最右边没有 [head] 标志,说明是通过 mmap 以匿名映射的方式从文件映射区分配的匿名内存。
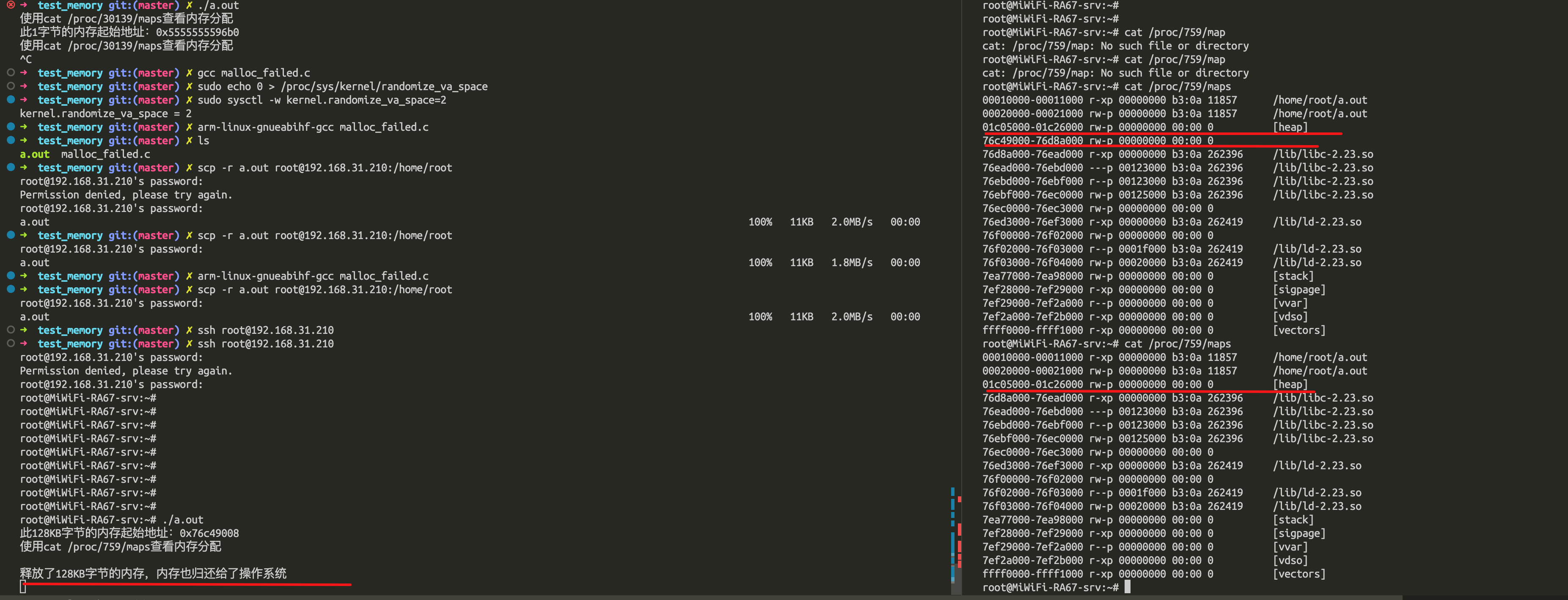
再次查看该 内存的起始地址,可以发现已经不存在了,说明归还给了操作系统。
对于 「malloc 申请的内存,free 释放内存会归还给操作系统吗?」这个问题,我们可以做个总结了:
- malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
- malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
示例:ZYNQ虚拟内存转物理内存
busybox有个工具devmem,可以在linux用户空间直接访问物理内存的数据。我们从devmem中提取一些关键的程序,来使用mmap来完成虚拟内存到物理内存的转换。
源代码https://github.com/carloscn/clab/blob/master/linux/test_mmap/devmem.c
我们做个实验,在uboot里面使用mw.w 0x50000000 0xaaaa 写入内存

然后在Linux用户空间读入内存 ./devmem.elf read 0x50000000 10

可以看到我们的数据。
为什么不全部使用 mmap 来分配内存?
因为向操作系统申请内存,是要通过系统调用的,执行系统调用是要进入内核态的,然后在回到用户态,运行态的切换会耗费不少时间。
所以,申请内存的操作应该避免频繁的系统调用,如果都用 mmap 来分配内存,等于每次都要执行系统调用。
另外,因为 mmap 分配的内存每次释放的时候,都会归还给操作系统,于是每次 mmap 分配的虚拟地址都是缺页状态的,然后在第一次访问该虚拟地址的时候,就会触发缺页中断。
也就是说,频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
为了改进这两个问题,malloc 通过 brk() 系统调用在堆空间申请内存的时候,由于堆空间是连续的,所以直接预分配更大的内存来作为内存池,当内存释放的时候,就缓存在内存池中。
等下次在申请内存的时候,就直接从内存池取出对应的内存块就行了,而且可能这个内存块的虚拟地址与物理地址的映射关系还存在,这样不仅减少了系统调用的次数,也减少了缺页中断的次数,这将大大降低 CPU 的消耗。
既然 brk 那么牛逼,为什么不全部使用 brk 来分配?
前面我们提到通过 brk 从堆空间分配的内存,并不会归还给操作系统,那么我们那考虑这样一个场景。如果我们连续申请了 10k,20k,30k 这三片内存,如果 10k 和 20k 这两片释放了,变为了空闲内存空间,如果下次申请的内存小于 30k,那么就可以重用这个空闲内存空间。但是如果下次申请的内存大于 30k,没有可用的空闲内存空间,必须向 OS 申请,实际使用内存继续增大。因此,随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。所以,malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128KB) 才使用 mmap 分配内存空间。
可以禁止malloc使用mmap分配10
mmap相比brk分配内存时候的效率底下解决办法:
- 禁止malloc调用mmap分配内存;
- 禁止内存紧缩 在进程启动的时候,
加入一下两行代码:
mallopt(M_MMAP_MAX,0);//禁止malloc调用mmap分配内存
mallopt(M_TRIM_THRESHOLD,-1);//禁止内存紧缩1.5 tmalloc函数(用户空间内存池)
这部分请参考: Linux机制之内存池.md
2 缺页异常
malloc和mmap是用户态的函数接口,他们只建立了进程空间内的虚拟内存,但没有建立虚拟内存和物理内存之间的映射关系。如果进程访问的内存刚好建立了关系,那就直接访问这个虚拟内存映射的物理内存,如果这个关系没有被建立,那就会触发缺页异常(异常处理在10_ARMv8_异常处理(一) - 入口与返回、栈选择、异常向量表 )。Linux对这部分异常必须要进行处理,一些工作也需要依赖于底层处理器,我们在ARM64中知道这种异常属于同步异常。
在发生异常的时候首先会跳到ARM的异常向量表中,接着会把异常存储到一个寄存器里面ESR (|保留|异常类型|IL|ISS|),会把失效的虚拟地址保存到FAR寄存器中。以发生在EL1下的数据异常为例,当异常发生的时候,处理器会首先跳转到ARM64的异常向量表中。在查询异常向量表后跳转到el1_sync()函数,并使用el1_sync()函数读取ESR判断异常类型,根据异常类型跳转到不同的处理函数中。在Linux,在el1_sync()函数内注册el1_da()函数,这个函数会读失效的地址,直接调用C的do_mem_abort()函数,系统通过一床状态最终调用到do_page_fault()函数
2.1 do_page_fault
缺页中断处理的核心函数是do_page_fault(),该函数的实现和具体的体系结构相关。代码在:arch/arm/mm/fault.c
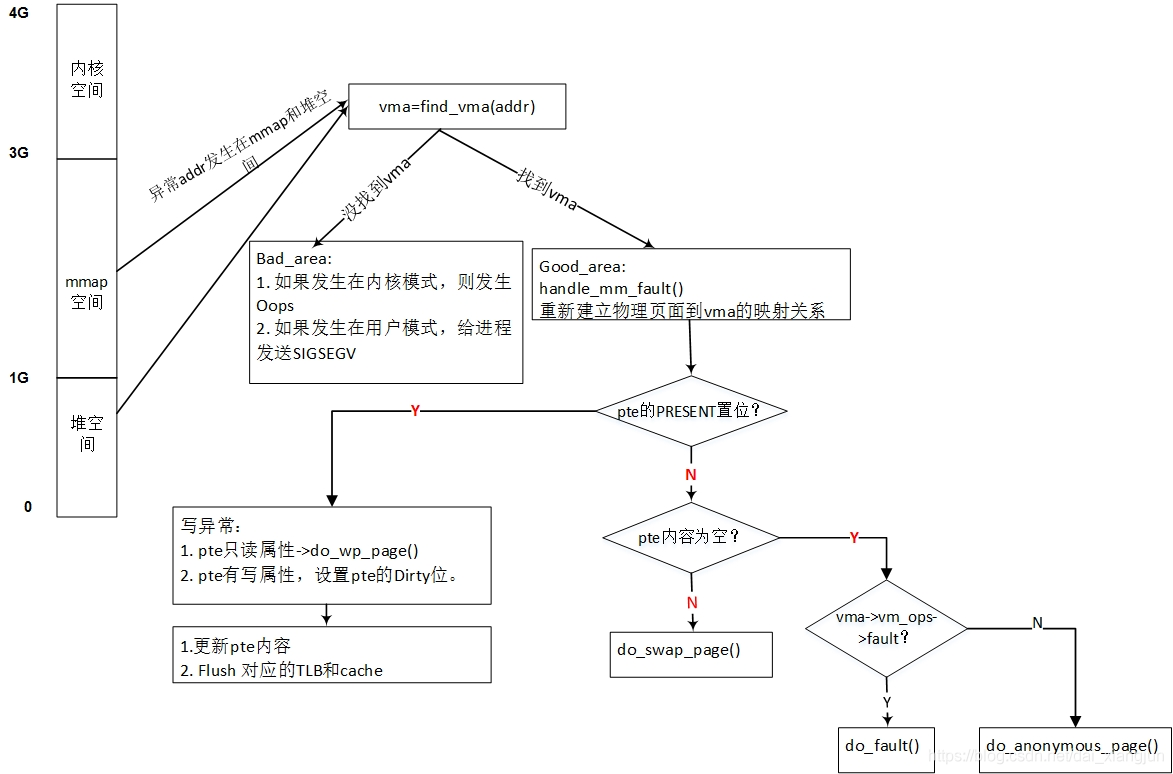
2.2 do_anonymous_page
以上是malloc使用brk分配内存的情况,但是如果malloc使用mmap机制分配内存,那么到时候的缺页异常是do_anonymous_page()匿名页面缺页异常。
2.3 do_wp_page
除此之外,还有写时复制,do_fork(),当子进程发生内存修改的时候,要进行写时复制,此时必然是缺页的,则调用do_wp_page()函数。
3 内存短缺
在Linux系统中,当内存有盈余的时候,内核会尽可能多的使用RAM资源作为文件缓存,从而提高系统的性能。文件缓存页面会被加入到LRU链表中;当内存系统紧张的时候,文件缓存页面会被丢弃,被修改的文件会刷回非易失性存储器中,与块设备同步之后便可以释放出物理内存。这也是为什么你经常看见,在Linux中如果U盘没有正确弹出,文件可能会拷贝失败;这也解释了,市面上那么多内存释放的小工具,本质都是把RAM一些页刷到磁盘里面。我们运行了一个非常大游戏,需要吃超过内存条的RAM,此时就会有SWAP技术,换入换出,在Ubuntu安装的时候,也会设定一个推荐2GB大小的swap空间,这些都是防止内存短缺的一些机制。
在Linux里面,内存机制短缺主要有两种:
- 页面回收(swap技术)
- OOM killer机制
3.1 页面回收
页面回收更依赖实现的算法,比如LRU最近最少使用算法。时间局部性原理把最少使用的页面换到磁盘里面,经常使用的放在内存里面。这里不再讲述原理了,本质上有个一个LRU链表,在链表上有标志位标志状态。除了LRU还有第二次机会算法,是在LRU上面的改进。不研究了!
3.2 OOM killer机制
当页面回收都无法满足分配器的需求的时候,OOM killer机制就是最后一道防线了。OOM Killer会选择占用内存比较高的进程来终止,从而释放内存。
Linux 内核有个机制叫OOM killer(Out Of Memory killer),该机制会监控那些占用内存过大,尤其是瞬间占用内存很快的进程,然后防止内存耗尽而自动把该进程杀掉。内核检测到系统内存不足、挑选并杀掉某个进程的过程可以参考内核源代码linux/mm/oom_kill.c,当系统内存不足的时候,out_of_memory()被触发,然后调用select_bad_process()选择一个”bad”进程杀掉。如何判断和选择一个”bad进程呢?linux选择”bad”进程是通过调用oom_badness(),挑选的算法和想法都很简单很朴实:最bad的那个进程就是那个最占用内存的进程。
当无限度的malloc空间的时候,可能我们会自己触发了OOM killer机制,这也是《Linux程序设计》第7.1.3滥用内存一节讲述的现象。
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#define ONE_K (1024)
int main() {
char *some_memory;
int size_to_allocate = ONE_K;
int megs_obtained = 0;
int ks_obtained = 0;
while (1) {
for (ks_obtained = 0; ks_obtained < 1024; ks_obtained++) {
some_memory = (char *)malloc(size_to_allocate);
if (some_memory == NULL) exit(EXIT_FAILURE);
sprintf(some_memory, "Hello World");
}
megs_obtained++;
printf("Now allocated %d Megabytes\n", megs_obtained);
}
exit(EXIT_SUCCESS);
}从另一个角度,所以说,有的时候Linux应用如果崩了,我们或许要考虑是不是测试环境中有其他进程导致触发了out of memory(OOM)而间接把我们坑了。
怎么确定是OOM导致的崩溃?
运行egrep -i -r 'killed process' /var/log命令,结果如下:
/var/log/syslog.1:May 6 10:02:51 iZuf66b59tpzdaxbchl3d4Z kernel: [1467990.340288] Killed process 17909 (procon) total-vm:5312000kB, anon-rss:4543100kB, file-rss:0kB也可运行dmesg命令,结果如下:
[1471454.635492] Out of memory: Kill process 17907 (procon) score 143 or sacrifice child
[1471454.636345] Killed process 17907 (procon) total-vm:5617060kB, anon-rss:4848752kB, file-rss:0kB显示可读时间的话可用dmesg -T查看:
[Wed May 15 14:03:08 2019] Out of memory: Kill process 83446 (machine) score 250 or sacrifice child
[Wed May 15 14:03:08 2019] Killed process 83446 (machine) total-vm:1920560kB, anon-rss:1177488kB, file-rss:1600kB4 内存工具
4.1 meminfo
cat /proc/meminfo
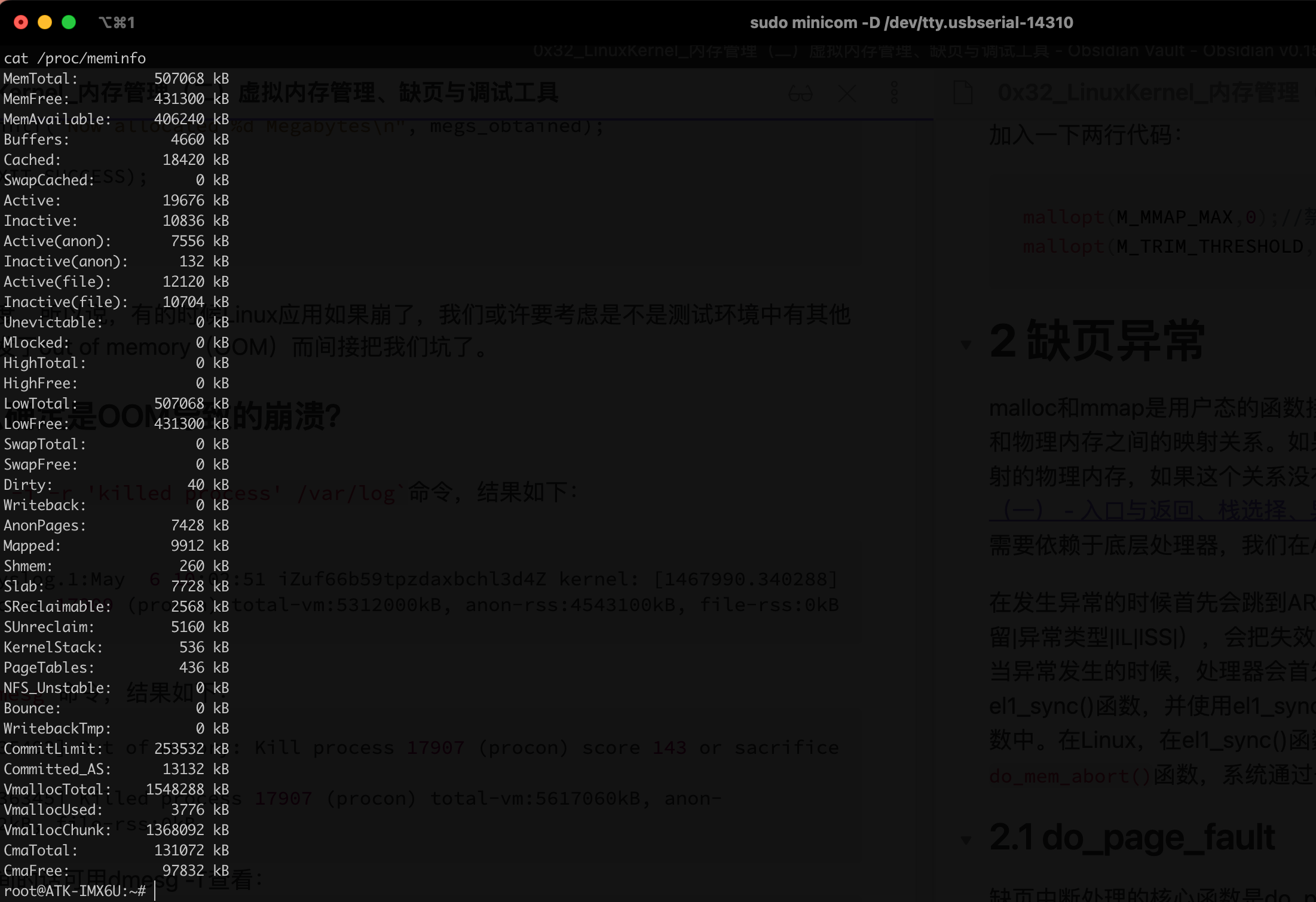
查看系统内存最准确的方法就是使用meminfo。
4.2 伙伴系统
cat /proc/buddyinfo

这个是ARMv7架构的,上面说了ARM没有DMA zone。
4.3 内存管理区
cat /proc/zoneinfo
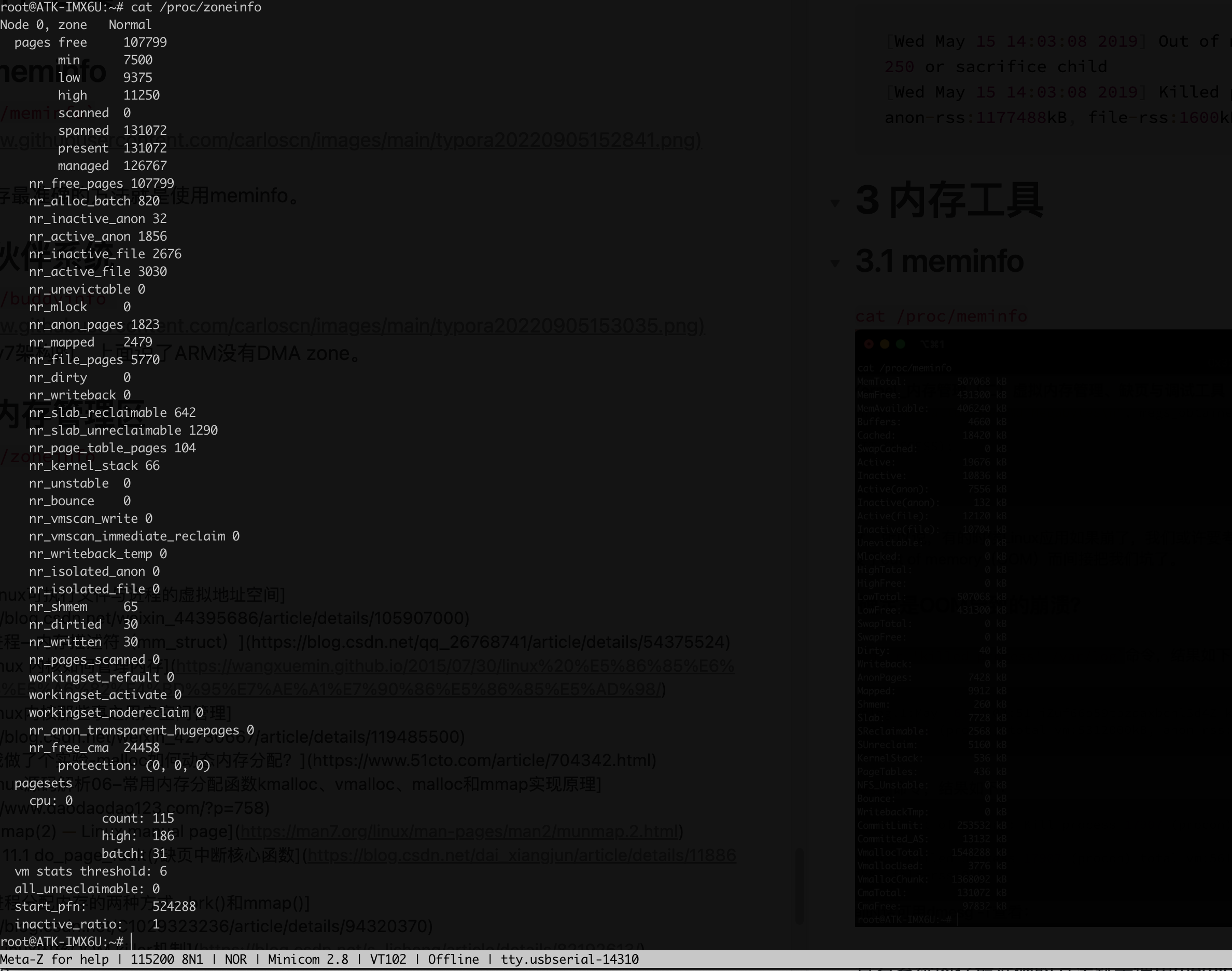
- 节点信息
- 当前zone的总信息
- zone的详细页面信息
- 显示每个CPU内存分配器信息
4.4 进程相关内存信息
cat /proc/pid/status | grep -E
4.5 查看系统内存工具
top和vmstat

Change Log
- 2022-9-13:
- 增加vmalloc和kmalloc的比较介绍;
- 增加线程池的概念,分别介绍内核中线程池的应用,及用户空间tmalloc线程池分配库。
- 2023-1-29:
- 增加mmap虚拟内存转物理内存的方法。