Focus on ElasticSearch Ecosystem/Elastic Stack
Opened this issue · 1 comments
Elasticsearch 基本介绍
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名。
Elasticsearch 的工作原理
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。数据采集
指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以接近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
Elasticsearch Stack/Elasticsearch Ecosystem
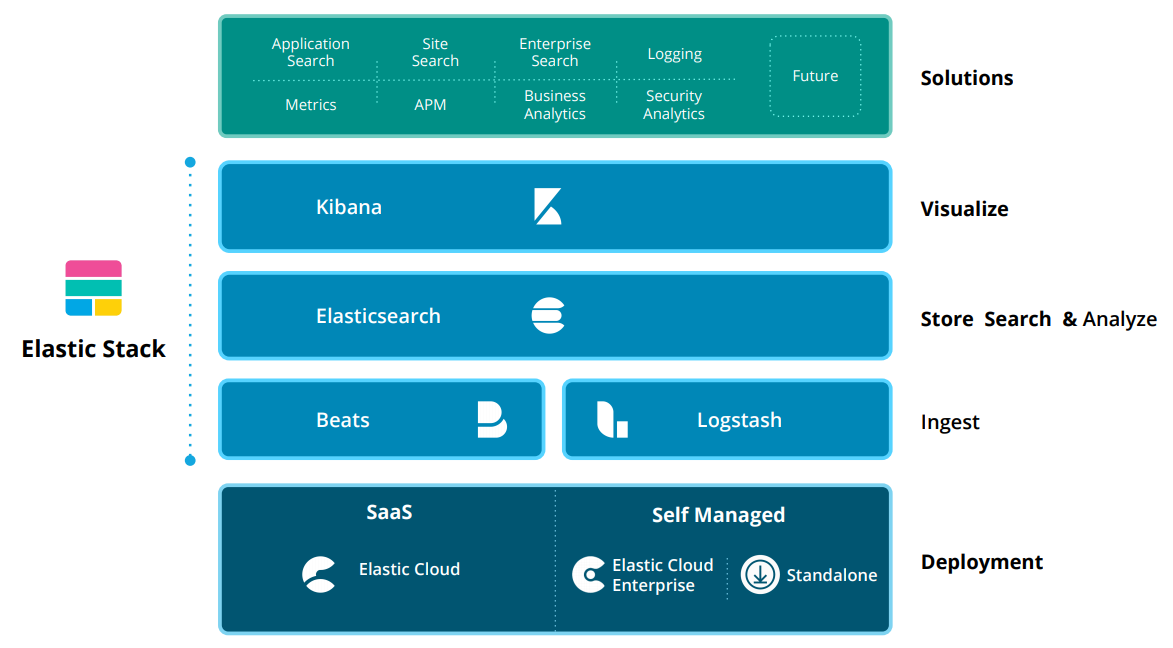
Elasticsearch 是 Elastic Stack 的核心组件,Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
Logstash
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
Kibana
Kibana 是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。Kibana 同时还包括诸如 Canvas 和 Elastic Maps 等高级应用程序;Canvas 允许用户基于自身数据创建定制的动态信息图表,而 Elastic Maps 则可用来对地理空间数据进行可视化。
Elasticsearch 的优势
**Elasticsearch 很快。**由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个接近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
**Elasticsearch 具有分布式的本质特征。**Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
**Elasticsearch 包含一系列广泛的功能。**除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
**Elastic Stack 简化了数据采集、可视化和报告过程。**通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
Elasticsearch 的一些典型应用场景
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种业务场景中:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
Misc
Elastic Search基于Lucene,Lucene基于Java开发,曾经有人在ES的社区内问过为什么ES基于Java开发,有社区的负责人回答考虑到Lucene基于Java开发,而Lucene开发者曾经提到过Java能提供执行效率和开发效率/友好度之间一个比较好的折衷。也有人在ES Github仓库中提issue询问是否有C++重构的想法,答复是没有。
目前虽然有一些计划作为ES替代品的项目,比如使用C++/Rust/Go等语言编写的性能更好的搜索引擎:
- manticoresearch, C++, 2K+ stars
- Toshi, Rust, 3.6K+ stars
- meilisearch, Rust, 28.5K+ stars
- sonic, Rust, 13.6K+ stars
- zinc, Go, 9.9K+ stars
但由于这些项目起步都较晚,虽然在某些方面上(比如说搜索性能,加载速度等)要比ES强,但ES目前经过这么多年的发展,目前已经有了一个比较完整的生态(Elastic Stack, Elastic Search Ecosystem),也已经得到了非常广泛的应用,有很多成熟的解决方案,这是其他项目所无法比拟的,至少就目前而言。
在知乎上看到过有人说Linux的设计哲学之一就是每个程序只做一件事情,尽量把这件事情做到最好。ES虽然也可以提供大规模的分布式数据存储,但因为ES本身是为搜索设计的,存储时还要进行分词操作,会造成额外的开销,因此使用ES来进行大规模的数据存储往往并不是最优的方案。
ES主要做的事情就是搜索,对数据建立索引,对接收到的搜索请求在数据(索引?)中计算相关性并排序,将排序过的结果返回作为响应,支持模糊搜索。通过数据库和SQL虽然也可以做搜索,但SQL搜索一般是通过like来做,无法利用索引,速度会比较慢,而且返回的是数据库中所有满足条件的结果,还是没有排序的。另外用户在进行搜索的时候往往并不需要所有相关的结果,而是只关注最相关的一部分结果,这些很难用数据库和SQL简单地实现。
clickhouse、数据库行存/列存、不同数据库的份额情况
comment test