This repository describes the process of developing a Kernza stem detection/counting model using YOLOv8 and Ilastik.
This method uses the YOLOv8 model to detect and count Kernza stems in images. The dataset used to train this model can be found on Roboflow.
- Clone this repository to your local machine:
git clone https://github.com/collinswakholi/Kernza_stems_detection.git
cd Kernza_stems_detection- Install the requirements:
pip install -r requirements.txt- Download the dataset from Roboflow and extract it into the
"Data"folder of this repository. Rename the folder containing the images and labels to"img_size"depending on the image size of your dataset. For example, if your image size is512x512, rename the folder to"512". The folder structure should look like this:
Kernza_stems_detection
├── Data
│ ├── 512
│ │ │ ├── train
│ │ │ │ ├── images
│ │ │ │ ├── labels
│ │ │ ├── data.yaml
│ │ │ ├── README.roboflow.txt
│ │ │ ├── README.dataset.txt
├── utils
│ ├── do_shuffle.py
│ ├── shuffle_write.py
├── imgs
├── Test images
├── inference.py
├── Inference.ipynb
├── train_YOLOv8.py
├── README.md
├── requirements.txt- Edit the
data.yamlfile in the"Data/img_size"folder to match your dataset. Thedata.yamlfile should look like this:
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 1
names: ['stems']
roboflow:
workspace: usdaars
project: kz_measurestems
version: 17
license: CC BY 4.0
url: https://universe.roboflow.com/usdaars/kz_measurestems/dataset/17
-
First, open the
train_YOLOv8.pyfile and edit theimg_szvariable to match your dataset. -
Edit the training parameters in the
train_YOLOv8.pyfile to suit your needs.
# set training parameters
project = 'kernza_stems'
name = 'yolov8_model_'+str(img_sz)+'_'
data = yaml_dir
imgsz = img_sz
epochs = 500
batch = -1 # 2, 4, 8, 16, 32, 64, 128, 256 # batch size or -1 for auto (largest batch size possible)
optimizer = 'Adam' # 'SGD', 'Adam', 'AdamW', 'RMSprop', 'RAdam', 'Adamax', 'auto'
device = '0' # '0,1,2,3,4,5,6,7' # cuda device, i.e. 0 or 0,1,2,3 or cpu
patience = 100 # early stopping patience
verbose = True # print mAP every epoch
exist_ok = True # change to true if you want to overwrite previous results
name_val = name+"_val" # validation results
single_cls = False # train as single-class dataset
cache = True # use cache images for faster training- You can also edit the ratio of the training, validation, and test sets in the
utils/shuffle_write.pyfile. The default ratio is0.7:0.2:0.1for training, validation, and test sets respectively. This will create a new shuffled dataset in the"Data/img_size_shuffled"folder which will be used for training.
self.ratio = [0.7, 0.2, 0.1] # train, val, test- Run the
train_YOLOv8.pyfile to start training:
python train_YOLOv8.py- The training results will be saved in the
"project/name"folder. The best model will be saved in the"project/name/weights"folder.
- Download the stem count model artefacts from Google Drive.
- To run inference on images in a folder (For Example "Test images"), open the
inference.pyorinference.ipynbif you are using Colab. Edit the variables to match your dataset and model directory.
img_sz = 2048
image_folder = '/RawImages/AkronTest_CO' # change this to the path of your images
base_folder = '_'.join(image_folder.split('/')[-2:])
# set inference parameters
name = 'yolov8_model_'+str(img_sz)+'_Images_'+base_folder
project = 'YOLOResults'
save = True # save image results ######################################################################
save_txt = False # save results to *.txt
save_conf = False # save confidences in --save-txt labels
show_labels = False # hide labels
show_conf = False # hide confidences
line_width = 2
batch = -1 # batch size
visualize = False # visualize model features
conf_thres = 0.28 # confidence threshold
iou_thres = 0.55 # NMS IoU threshold
imgsz = img_sz # inference size (pixels)
exist_ok = True # if True, it overwrites current 'name' saving folder #####################################
half = True # use FP16 half-precision inference True/False
cache = True # use cache images for faster inference
img_fmt = '.JPEG' # image format- You can run inference on a subset of the images in the folder by editing the
nxvariable. The default isnx = 10which runs inference on batches of 10 images in the folder. Depending on how big the model is, amount of available VRAM, and the number of images in the folder, you can increase or decrease this value.
# split the list of images into batches of 10 images
nx = 10 # number of images per batch- Run the
inference.pyfile to start inference:
python inference.py- The results will be saved in the
"project/name"folder, including the stems count in the"project/name/stem_count_img_size.csv"file. - The same can be done using the
Inference.ipynbnotebook on Google Colab. Follow this Video for a step by step tutorial.
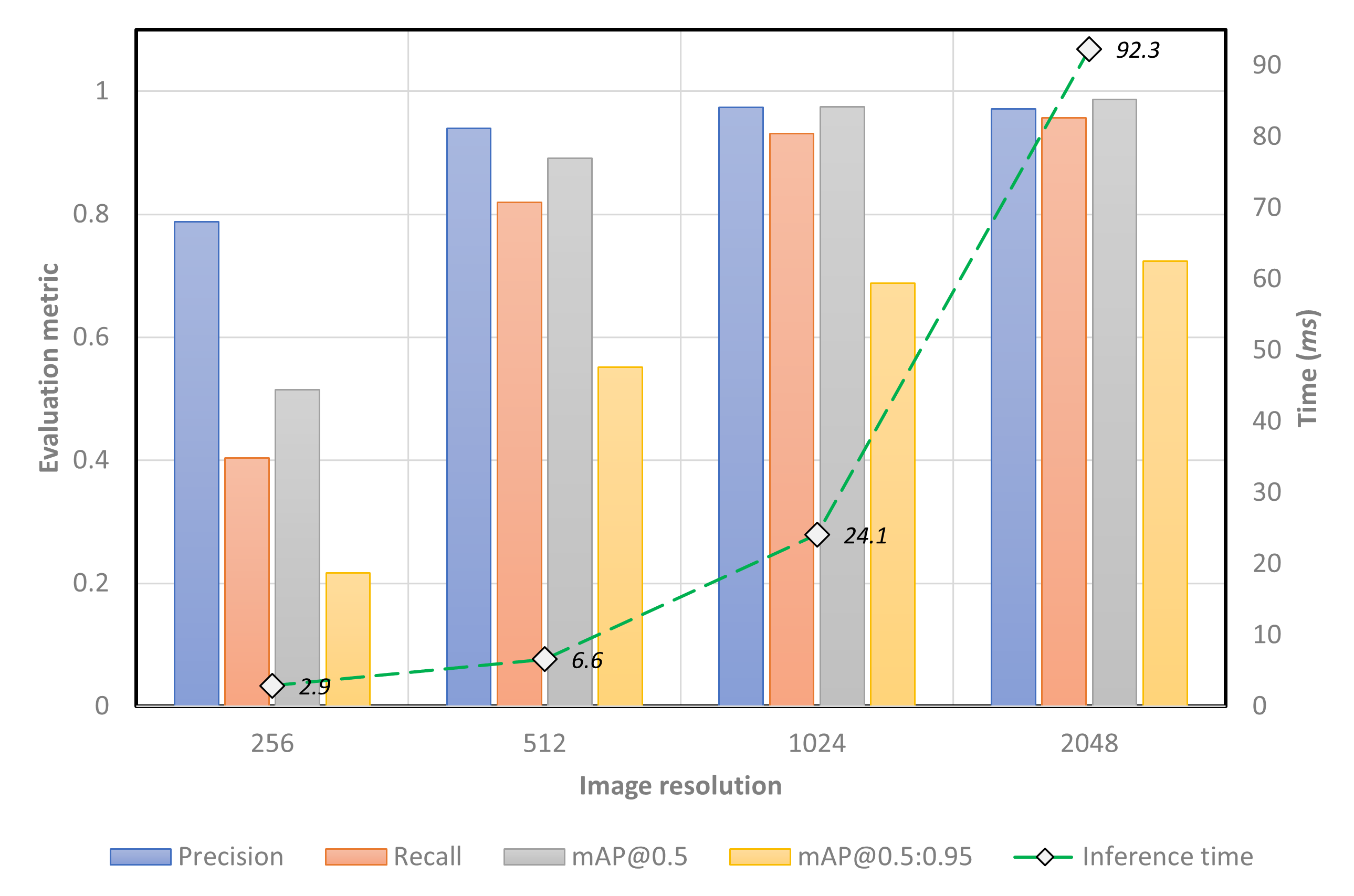
- Performance of the model on the test set:
- Example of the model's predictions on images





Check out these videos that explain how stem detection was done using Ilastik.
- Ilastik Pixel Classification Video (1/2)

- Ilastik Pixel Classification Video (2/2)
