细说Unicode(三) Unicode 番外之附加字符
Opened this issue · 0 comments
在各种论坛上,经常会看到一些奇怪的字符,它们的内容会超出显示范围,
举个例子:
'Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞'常见的还有一些有泰文字符组成的。这里就不举例子了。这些看似乱文的字符是怎么形成的呢?
其实它们并不是乱文,尝试输出上面那个例子的字符长度
'Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞'.length; //75发现竟然包含了75个字符!我们用Array.from输出这些字符:
Array.from('Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞');
//["Z", "͑", "ͫ", "̓", "ͪ", "̂", "ͫ", "̽", "͏", "̴", "̙", "̤", "̞", "͉", "͚", "̯", "̞", "̠", "͍", "A", "ͫ", "͗", "̴", "͢", "̵", "̜", "̰", "͔", "L", "ͨ", "ͧ", "ͩ", "͘", "̠", "G", "̑", "͗", "̎", "̅", "͛", "́", "̴", "̻", "͈", "͍", "͔", "̹", "O", "͂", "̌", "̌", "͘", "̨", "̵", "̹", "̻", "̝", "̳", "!", "̿", "̋", "ͥ", "ͥ", "̂", "ͣ", "̐", "́", "́", "͞", "͜", "͖", "̬", "̰", "̙", "̗"]再查看其中某个字符的Unicode码点:
Array.from('Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞')[10].codePointAt(0);//793,即16进制的0x0319根据Unicode映射表查找出0x0319对应的字符,发现U+0300~U+036F称为结合附加符号,那么结合附加符号又是什么?

附加符号,是添加在字母上面的符号,以更改字母的发音或者以区分拼写相似词语。例如汉语拼音字母“ü”上面的两个小点,或“á”、“à”字母上面的标调符。变音符号可以放在字母的上方或下方,也可以放在其他的位置。当多个附加符号叠加的时候,就形成了看起来像乱码的符号。
而在泰文中,字符的组成也是由一些元音符号和声调符号组成的
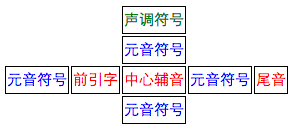
所以多个元音符号或声调符号叠加时也会有类似的效果。这里就不再做阐述。
在网页开发中,特别是评论区,如果遇到太多的"插楼"字符,就会对其他用户造成阅读障碍,影响阅读体验,那怎么避免这种情况呢。这里提供两种方法。
第一种是对字符串文字区域设置最大高度,超出的部分自动隐藏。
p {
height: 20px;
overflow: hidden;
}另一种方式就是对这种特殊字符做过滤操作。将附加字符进行过滤,这种方法在某种程度上会误杀一些需要正常显示的附加符号。但一般也不会影响整体功能,利大于弊。
var regexSymbolWithCombiningMarks = /([\0-\u02FF\u0370-\u1DBF\u1E00-\u20CF\u2100-\uD7FF\uDC00-\uFE1F\uFE30-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF])([\u0300-\u036F\u1DC0-\u1DFF\u20D0-\u20FF\uFE20-\uFE2F]+)/g;
function getSymbolsIgnoringCombiningMarks(string) {
// 删除附加符号:
var stripped = string.replace(regexSymbolWithCombiningMarks, function($0, symbol, combiningMarks) {
return symbol;
});
return stripped;
}
getSymbolsIgnoringCombiningMarks('Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞'); //"ZALGO!"讲到这里,我们对Unicode已经有了比较细致的了解。相信在开发中碰到问题也能找出根源所在了。
通过学习编码的历史,原理以及查询映射表,我们知道了乱码是怎么产生的,并且利用ES6或正则表达式,来解决绝大多数编码问题。
参考文章:
https://zh.wikipedia.org/wiki
https://mathiasbynens.be/notes/javascript-unicode