scrapy抓取数据存储至本地mysql数据库 基于python开发,采用scrapy,数据存储至本地数据库(或excel表格) 程序的主要目的是完成抓取和分析的任务同时学习爬虫相关知识,所以在细节处理上略有不足,但考虑到最终的目的是记录自己的学习,另外帮助到他人学习,所以这些细节无关紧要(毕竟不是面向用户的程序)。 程序还有建立商家-用户点评的表格还在进行中...
也许你可以在这里找到一些帮助,比如:一次返回两个,多个item,切割中文,中文转数字等问题
1)一次返回两个、多个item
在pipelines.py文件中,可以看到。如果是不同的spider返回的,直接根据spider的name来判断即可
elif isinstance(item, User_shopItem):
2)而一个spider返回两个、多个item,则通过item的name来判断(item的名字可以在spider中调试并输出)
if str(str1) == "<class 'dianping.items.CommentItem'>":
1.首先创建MySQl数据库
在/dianping/settings.py中写定了
MYSQL_DBNAME = 'dianpingshop'
MYSQL_USER = 'root'
MYSQL_PASSWD = 'okgoogle'
当然你也可以修改
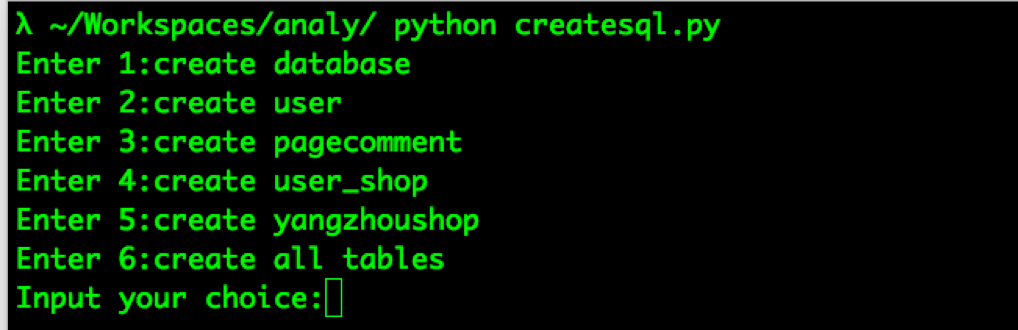
比如选择6,创建程序用的所有表格
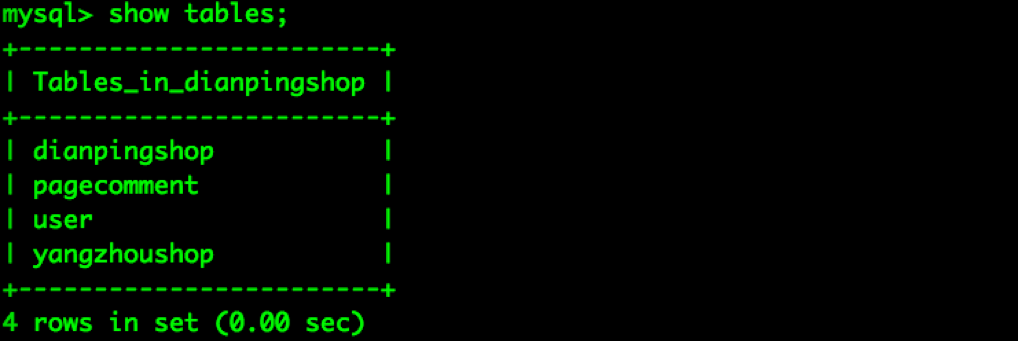
2.根据Scrapy的常用语法抓取数据
比如运行scrapy crawl dianping抓取扬州地区前50页的数据
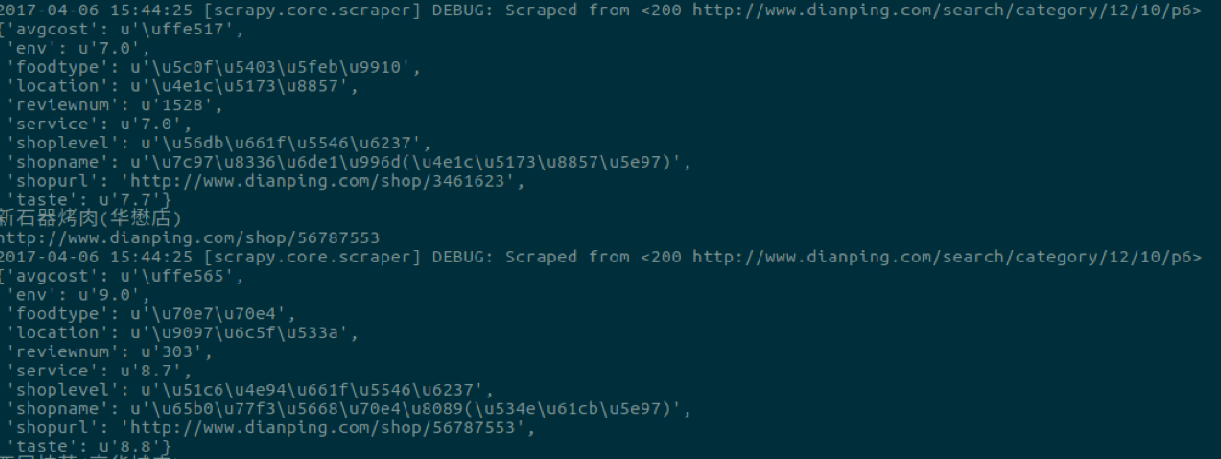
抓取的数据存储在本地MySQL数据库中,当然之后也可以转换成Excel表格
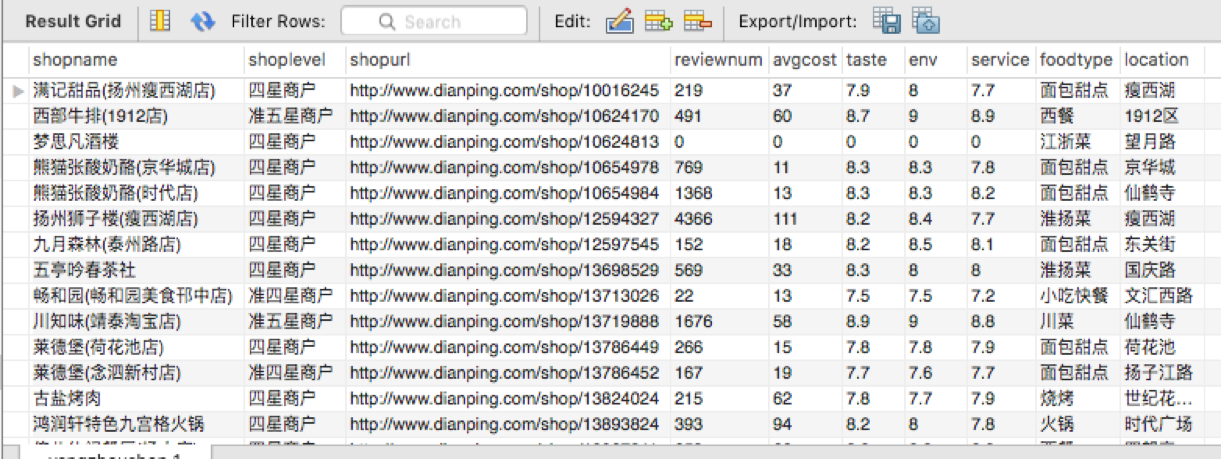
用户选择某种种类继续抓取(考虑到日常生活中,人类大多数会从某一种类中选择某一商家)
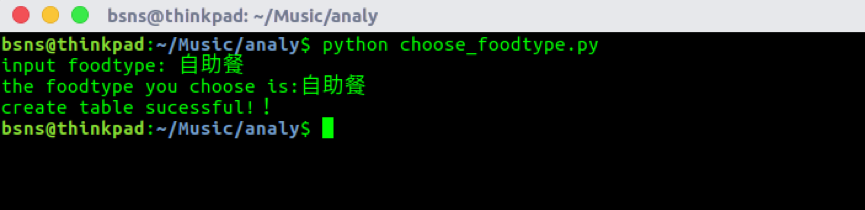
在已经抓取的yangzhoushop总选择所有种类为自助餐的数据,存入dianping表中,等待继续抓取
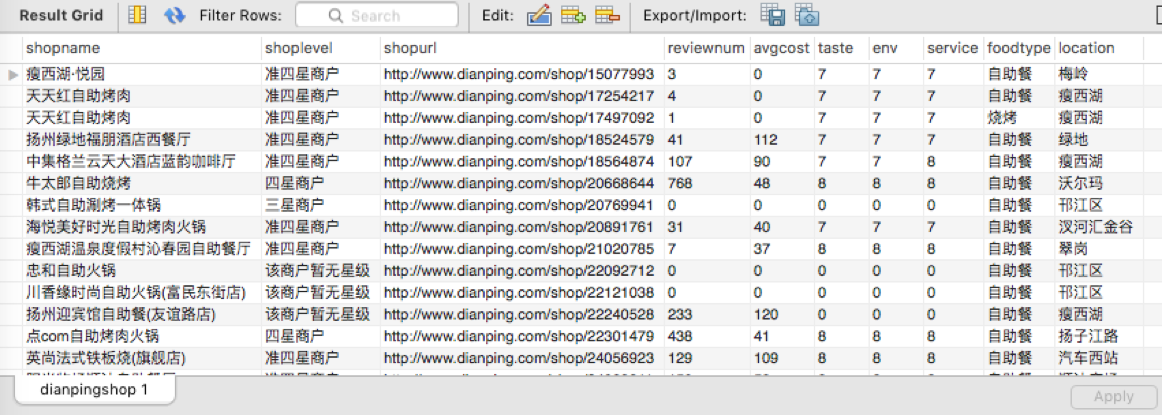
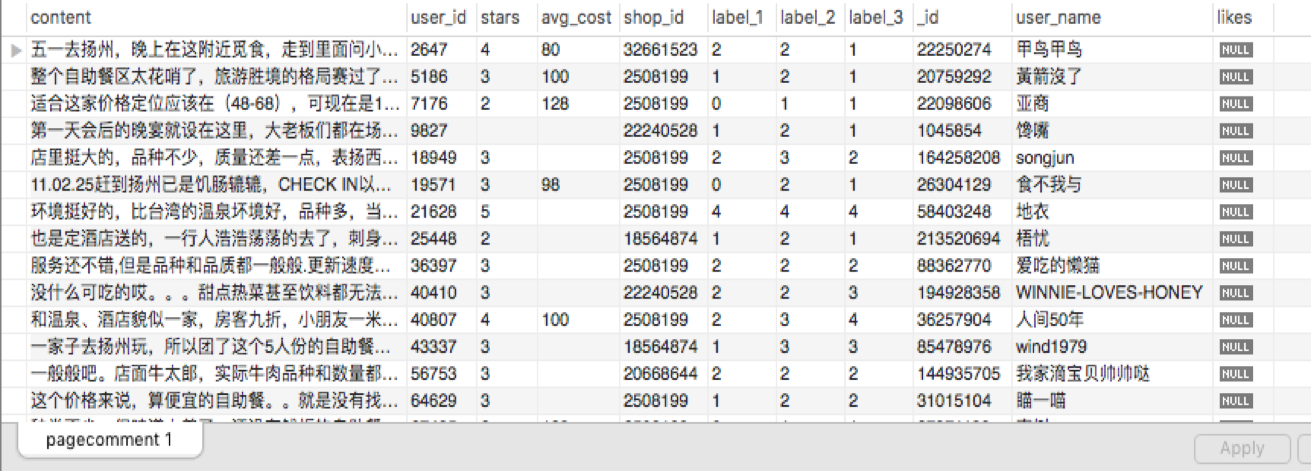
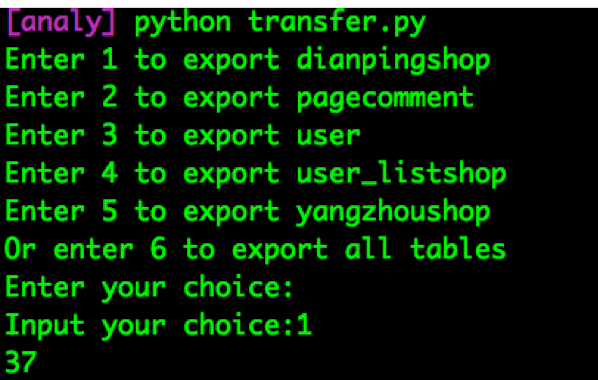
运行transfer.py把数据从MySQL中导出到Excel表格中

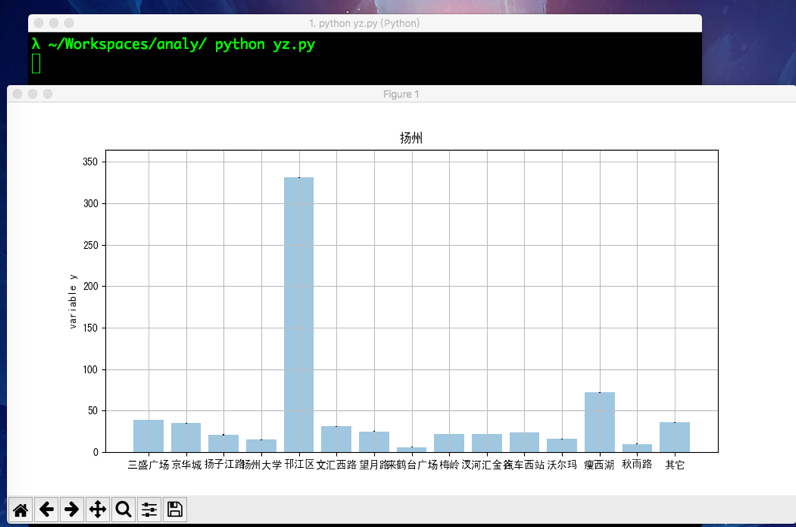
运行yz.py 生成地理位置的条形图(这一步骤是刚开始学习时编写的,所以数据是写定的)
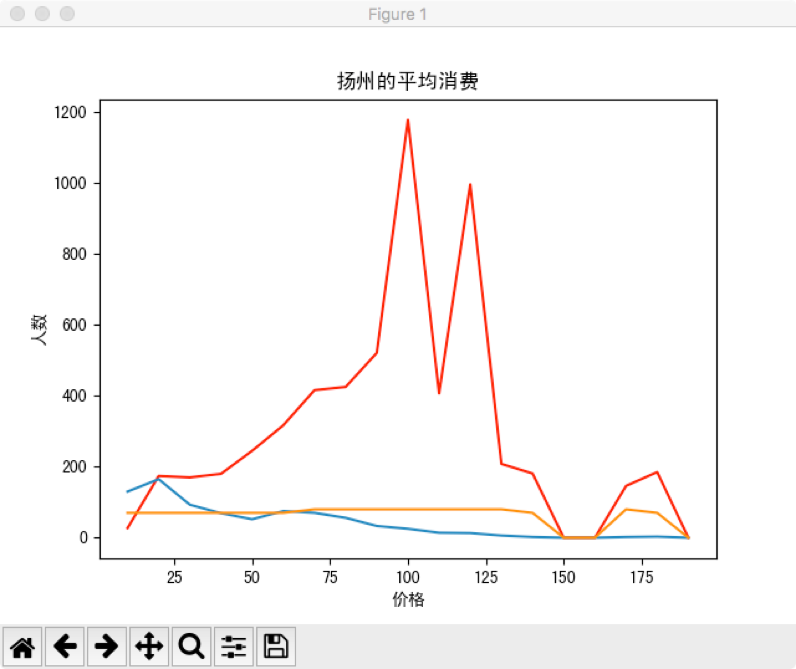
运行price.py显示价格相关的条形图
根据横轴的价格增长,三条曲线分别为
1)红色:消费人数
2)蓝色:商店数量
3)黄色:评分
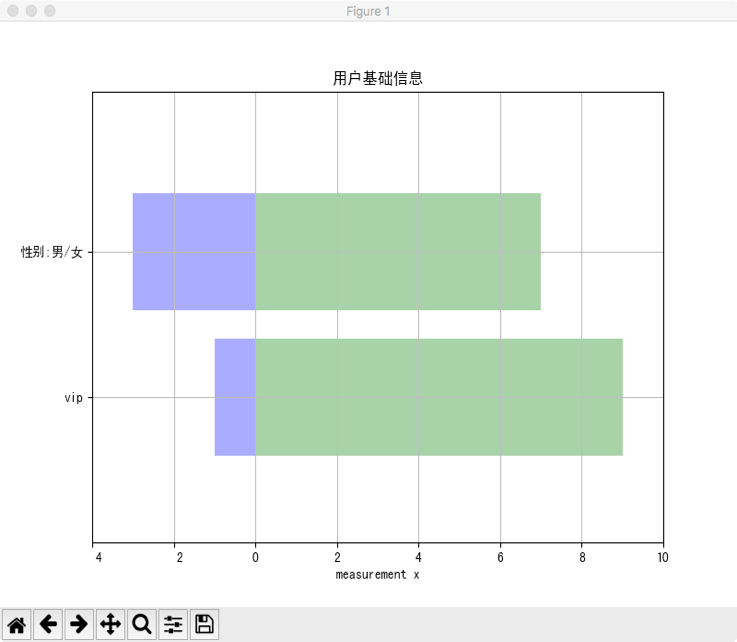
运行gender.py
显示男女比例,vip、非vip的比例
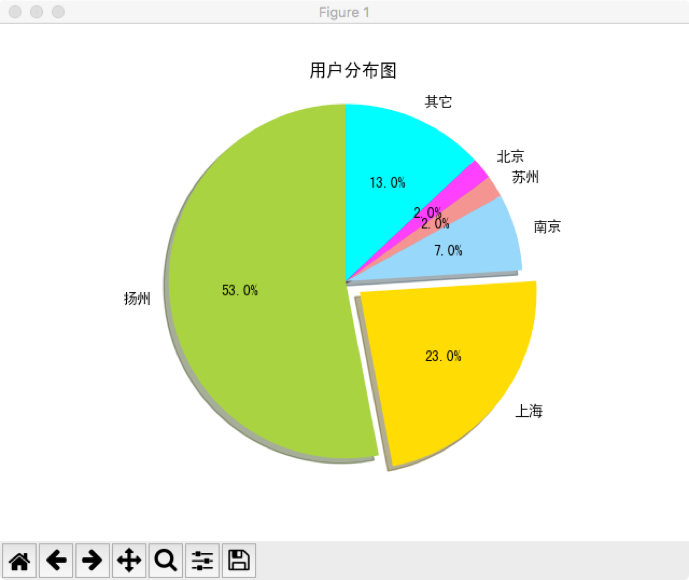
运行user_location.py显示用户地理位置的分布图
运行analy_shop.py分析具体商家
程序显示几家商店,从中继续选择某一家分析
生成词云
