
This project is to extend deep learning framework on the Flink project. Currently supports tensorflow running on flink.
contents
- TensorFlow support
- Structure
- For More Information
- License
TensorFlow is a deep learning system developed by Google and open source, which is widely used in the field of deep learning. There are many inconveniences in distributed use and resource management of native TensorFlow, but it can not integrate with the existing widely used large data processing framework.
Flink is a data processing framework. It is widely used in data extraction, feature preprocessing and data cleaning.
This project combines TensorFlow with Flink and provides users with more convenient and useful tools. Currently, Flink job code uses java language and the algorithm code uses python language.
TensorFlow: 1.11.0
Flink: 1.8.0
Requirements
- python: 2.7 future support python 3
- pip
- cmake >= 3.6
- java 1.8
- maven >=3.3.0
Install python2
macOS
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
export PATH="/usr/local/bin:/usr/local/sbin:$PATH"
brew install python@2 Ubuntu
sudo apt install python-devInstall pip
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.pyUbuntu you can install with command:
sudo apt install python-pipInstall pip dependencies Install the pip package dependencies (if using a virtual environment, omit the --user argument):
pip install -U --user pip six numpy wheel mock grpcio grpcio-toolsInstall cmake
cmake version must >= 3.6
Install java 8
Install maven
maven version >=3.3.0
tar -xvf apache-maven-3.6.1-bin.tar.gz
mv -rf apache-maven-3.6.1 /usr/local/configuration environment variables
MAVEN_HOME=/usr/local/apache-maven-3.6.1
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/binCompiling source code depends on tensorflow 1.11.0. Compiling commands will automatically install tensorflow 1.11.0
mvn -DskipTests=true clean installIf you run all tests, this step may take a long time, about 20 minutes, and wait patiently. You can also skip the test run command: mvn -DskipTests=true clean install
Optional Commands
# run all tests
mvn clean install
# skip unit tests
mvn -DskipUTs=true clean install
# skip integration tests
mvn -DskipITs=true clean installIf the above command is executed successfully, congratulations on your successful deployment of flink-ai-extended. Now you can write algorithm programs.
- change project pom.xml item pip.install.option from --user to -U
- create virtual environment:
virtualenv tfenv- enter the virtual environment
source tfenv/bin/activate- install pip dependencies
pip install -U pip six numpy wheel mock grpcio grpcio-tools- build source
mvn clean install- exit from virtual environment
deactivate- tensorflow add example
python code:
import tensorflow as tf
import time
import sys
from flink_ml_tensorflow.tensorflow_context import TFContext
def build_graph():
global a
i = 1
a = tf.placeholder(tf.float32, shape=None, name="a")
b = tf.reduce_mean(a, name="b")
r_list = []
v = tf.Variable(dtype=tf.float32, initial_value=tf.constant(1.0), name="v_" + str(i))
c = tf.add(b, v, name="c_" + str(i))
add = tf.assign(v, c, name="assign_" + str(i))
sum = tf.summary.scalar(name="sum_" + str(i), tensor=c)
r_list.append(add)
global_step = tf.contrib.framework.get_or_create_global_step()
global_step_inc = tf.assign_add(global_step, 1)
r_list.append(global_step_inc)
return r_list
def map_func(context):
tf_context = TFContext(context)
job_name = tf_context.get_role_name()
index = tf_context.get_index()
cluster_json = tf_context.get_tf_cluster()
cluster = tf.train.ClusterSpec(cluster=cluster_json)
server = tf.train.Server(cluster, job_name=job_name, task_index=index)
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False,
device_filters=["/job:ps", "/job:worker/task:%d" % index])
t = time.time()
if 'ps' == job_name:
from time import sleep
while True:
sleep(1)
else:
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:' + str(index), cluster=cluster)):
train_ops = build_graph()
hooks = [tf.train.StopAtStepHook(last_step=2)]
with tf.train.MonitoredTrainingSession(master=server.target, config=sess_config,
checkpoint_dir="./target/tmp/s1/" + str(t),
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
print (mon_sess.run(train_ops, feed_dict={a: [1.0, 2.0, 3.0]}))
sys.stdout.flush()java code:
add maven dependencies<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.alibaba</groupId>
<artifactId>flink-ai-extended-examples</artifactId>
<version>0.1.0</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>com.alibaba.flink.ml</groupId>
<artifactId>flink-ml-tensorflow</artifactId>
<version>0.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-test</artifactId>
<version>2.7.1</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>You can refer to the following POM
class Add{
public static void main(String args[]) throws Exception{
// local zookeeper server.
TestingServer server = new TestingServer(2181, true);
String script = "./add.py";
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
// if zookeeper has other address
Map<String, String> prop = new HashMap<>();
prop.put(MLConstants.CONFIG_STORAGE_TYPE, MLConstants.STORAGE_ZOOKEEPER);
prop.put(MLConstants.CONFIG_ZOOKEEPER_CONNECT_STR, "localhost:2181");
TFConfig config = new TFConfig(2, 1, prop, script, "map_func", null);
TFUtils.train(streamEnv, null, config);
JobExecutionResult result = streamEnv.execute();
server.stop();
}
}Distributed running environment:
- Start zookeeper service https://zookeeper.apache.org/
- Prepare python virtual environment:
virtual environment workflow is shown in the following figure:
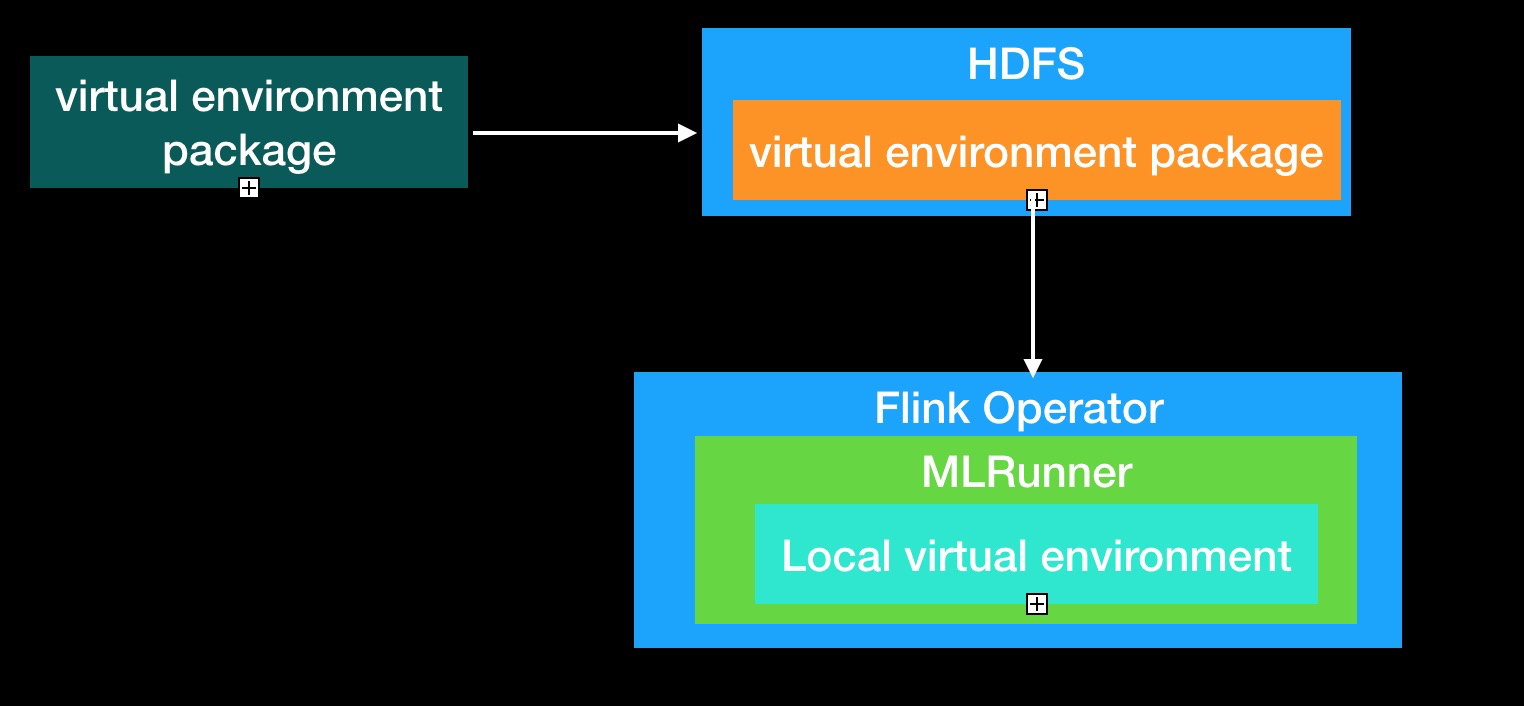

-
Build python virtual environment package.
-
Put virtual environment package to a share file system such as HDFS.
-
Configure the virtual environment package address in build Flink machine learning job configuration (TensorFlow:TFConfig, PyTorch:PyTorchConfig).
-
When running Flink job, each node downloads the virtual environment package and extracts it locally
- Prepare Flink Cluster
-
Developing Algorithmic Program
-
Developing Flink Job Program
-
Submit Flink job
- install docker
- install flink-ai-extended
mvn -DskipTests=true clean install- Change work dir
cd docker/build_cluster/Pay attention: projectRoot is flink-ai-extended project root path.
- Build Docker Image [build docker script]
sh build_flink_image.shYou can find flink image to use command:
docker images - Build Virtual Environment [build virtual environment script]
sh build_venv_package.shYou can find tfenv.zip in temp/test/ directory.
- start zookeeper
- start hdfs
- start flink cluster
- Start zookeeper
sh start_zookeeper.sh- Start HDFS
sh start_hdfs.sh- Start flink cluster
sh start_flink.shAlso can start all service
sh start_cluster.sh- Copy virtual environment package to hdfs
docker exec flink-jm /opt/hadoop-2.7.0/bin/hadoop fs -put -f /opt/work_home/temp/test/tfenv.zip /user/root/tfenv.zip- Download mnist data
sh download_mnist_data.sh- Put train data to docker container
docker cp ${projectRoot}/flink-ml-examples/target/data/ flink-jm:/tmp/mnist_input - Package user python code
cd ${projectRoot}/flink-ml-examples/target/
mkdir code && cp ${projectRoot}/flink-ml-examples/src/test/python/* code/
zip -r ${projectRoot}/flink-ml-examples/target/code.zip code- Put code package to hdfs
docker exec flink-jm /opt/hadoop-2.7.0/bin/hadoop fs -put -f /opt/work_home/flink-ml-examples/target/code.zip hdfs://minidfs:9000/user/root/docker exec flink-jm flink run -c com.alibaba.flink.ml.examples.tensorflow.mnist.MnistDist /opt/work_home/flink-ml-examples/target/flink-ml-examples-0.1.0.jar --zk-conn-str minizk --mode StreamEnv --setup /opt/work_home/flink-ml-examples/src/test/python/mnist_data_setup.py --train mnist_dist.py --envpath hdfs://minidfs:9000/user/root/tfenv.zip --mnist-files /tmp/mnist_input --with-restart false --code-path hdfs://minidfs:9000/user/root/code.zip sh stop_cluster.shIn the example above, zookeeper, flink, and HDFS can be deployed on different machines.
You can also use existing zookeeper, hdfs, flink cluster.
run build_wheel.sh script, you will find python package in dist dir. you can install the package with commend:
pip install --user $package_pathrunning distributed programs you need a virtual environment package to upload to hdfs.
build virtual environment script
you can change the script to add some extended python package.

- AM registers its address to zookeeper.
- Worker and Ps get AM address from zookeeper.
- Worker and Ps register their address to AM.
- AM collect all Worker and Ps address.
- Worker and Ps get cluster information.
- Worker and Ps start algorithm python process.