Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
howardyclo opened this issue · 1 comments
Metadata
- Authors: Kexin Yi, Jiajun Wu, +3 authors, Joshua B. Tenenbaum.
- Organization: Harvard, MIT, DeepMind.
- Conference: NIPS 2018
- Paper: https://arxiv.org/pdf/1810.02338.pdf
- Code: https://github.com/kexinyi/ns-vqa
- Website: http://nsvqa.csail.mit.edu/
Summary
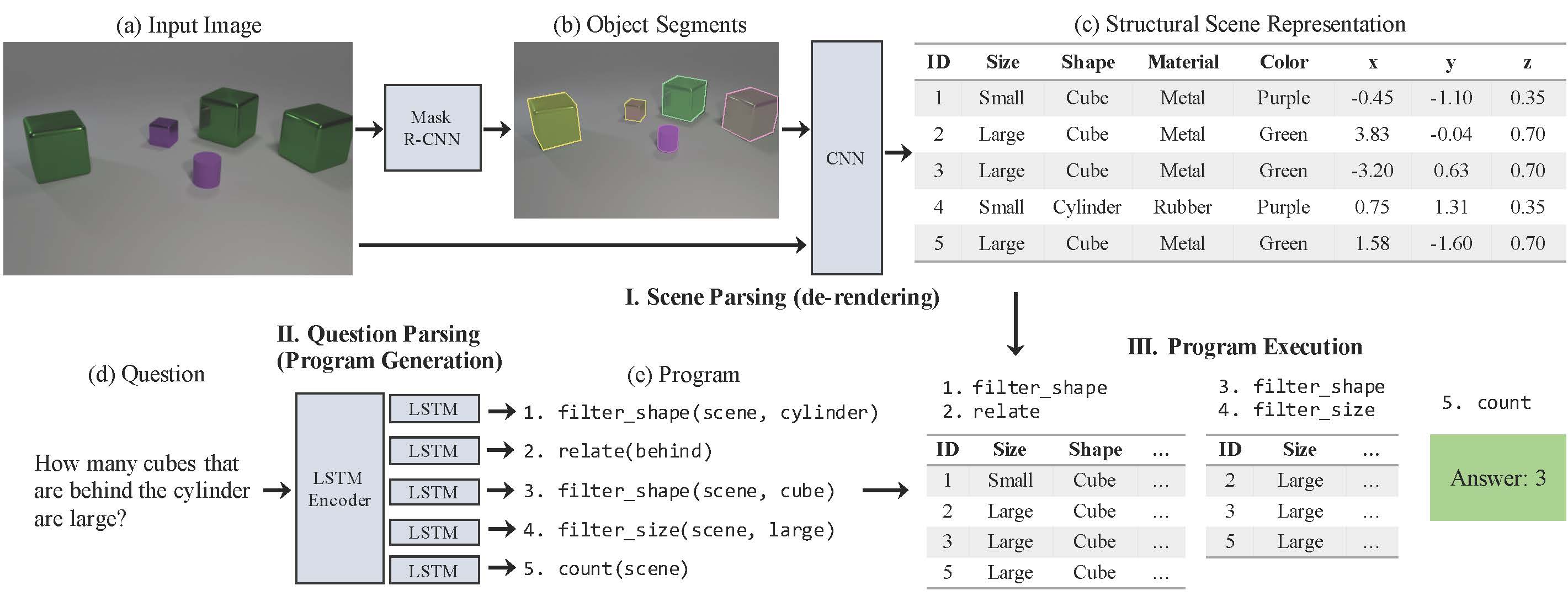
Neural-symbolic VQA (NS-VQA) model has three components:
- A scene parser (de-renderer) that segments an input image (a-b) and recovers a structural scene representation (c).
- A question parser (program generator) that converts a question in natural language (d) into a program (e).
- A program executor that runs the program on the structural scene representation to obtain the answer.
- State-of-the-art near-perfect accuracy on CLEVR dataset and demonstrates good generalizability on CLEVR-CoGenT and CLEVR-Humans, and even different dataset, Minecraft world.
Scene Parser
- Use Mask-RCNN (implementation based on Detectron and use ResNet-50 FPN as the backbone) to generate segment proposals of all objects. Along with segmentation mask, the network also predicts the categorical labels of discrete intrinsic attributes (e.g., color, material, size and shape).
- The segment for each single object is then paired with the original image, resized to 224 by 224 and sent to a ResNet-34 to extract the spacial attributes such as pose and 3D coordinates. Here the inclusion of the original full image enables the use of contextual information.
Question Parser
- Use Attention-based Seq2Seq "translate" question to sequence of function modules (program).
- Two-step procedure to train question parser:
- Pretrain with MLE on a small number of ground truth question-program pairs.
- Finetune with REINFORCE on a larger set of question-answer pairs. The reward is from the execution results of deterministic program executor.
Program Executor
- Implemented the program executor as a collection of deterministic, generic functional modules in Python, designed to host all logic operations behind the questions in the dataset. Each functional module is in one-to-one correspondence with tokens from the input program sequence, which has the same representation as in Johnson et al. [1].
- Each functional module sequentially executes on the output of previous one. The last module outputs the final answer to the answer. When type mismatch occurs between input and output across adjacent modules, an error flag is raised to the output, in which case the model will randomly sample an answer from all possible outputs of the final module.
Evaluation: Data-Efficient, Interpretable Reasoning
Dataset
CLEVR. The dataset includes synthetic images of 3D primitives with multiple attributes—shape, color, material, size, and 3D coordinates. Each image has a set of questions, each of which associates with a program (a set of symbolic modules) generated by machines based on 90 logic templates.
Quantitative results

Repeated experiments starting from different sets of programs show a standard deviation of less than 0.1 percent on the results for 270 pretraining programs (and beyond). The variances are larger when we train our model with fewer programs (90 and 180). The reported numbers are the mean of three runs.
Data-efficiency comparison

- Figure 4a shows the result when we vary the number of pretraining programs. NS-VQA outperforms the IEP [1] baseline under various conditions, even with a weaker supervision during REINFORCE (2K and 9K question-answer pairs in REINFORCE). The number of question-answer pairs can be further reduced by pretraining the model on a larger set of annotated programs. For example, our model achieves the same near-perfect accuracy of 99.8% with 9K question-answer pairs with annotated programs for both pretraining and REINFORCE.
- Figure 4b compares how well our NS-VQA recovers the underlying programs compared to the IEP model. IEP starts to capture the true programs when trained with over 1K programs, and only recovers half of the programs with 9K programs.
- Figure 4c shows the QA accuracy vs. the number of questions and answers used for training, where NS-VQA has the highest performance under all conditions. Among the baseline methods we compare with, MAC [2] obtains high accuracy with zero program annotations; in comparison, our method needs to be pretrained on 270 program annotations, but requires fewer question-answer pairs to reach similar performance.
Qualitative examples

IEP tends to fake a long wrong program that leads to the correct answer. In contrast, NS-VQA achieves 88% program accuracy with 500 annotations, and performs almost perfectly on both question answering and program recovery with 9K programs.
Evaluation: Generalizing to Unseen Attribute Combinations
Dataset
CLEVR-CoGenT. Derived from CLEVR and separated into two biased splits:
- Split A only contains cubes that are either gray, blue, brown or yellow, and cylinders that are red, green, purple or cyan.
- Split B has the opposite color-shape pairs for cubes and cylinders.
- Both splits contain spheres of any color. Split A has 70K images and 700K questions for training and both splits have 15K images and 150K questions for evaluation and testing. The desired behavior of a generalizable model is to perform equally well on both splits while only trained on split A.
Results

See Table 2a.
- The vanilla NS-VQA trained purely on split A and fine-tuned purely on split B (1000 images) does not generalize as well as the state-of-the-art. We observe that this is because of the bias in the attribute recognition network of the scene parser, which learns to classify object shape based on color. NS-VQA works well after we fine-tune it on data from both splits (4000 A, 1000 B). Here, we only fine-tune the attribute recognition network with annotated images from split B, but no questions or programs.
- Thanks to the disentangled pipeline and symbolic scene representation, our question parser and executor are not overfitting to particular splits. To validate this, we train a separate shape recognition network that takes gray-scale but not color images as input (NS-VQA+Gray).
- Further, with an image parser trained on the original condition (i.e. the same as in CLEVR), our question parser and executor also generalize well across splits (NS-VQA+Ori).
Evaluation: Generalizing to Questions from Humans
Dataset
- CLEVR-Humans, which includes human-generated questions on CLEVR images.
- Similar training paradigm to the original CLEVR dataset.
- Initialize encoder embedding with GloVe and keep it fixed during pretraining.
- The REINFORCE stage lasts for at most 1M iterations; early stop is applied.
Results
See Table 2b.
This shows our structural scene representation and symbolic program executor helps to exploit the
strong exploration power of REINFORCE, and also demonstrates the model’s generalizability across
different question styles.
Evaluation: Extending to New Scene Context
Dataset
- A new dataset where objects and scenes are taken from Minecraft and therefore have drastically different scene context and visual appearance. We use the dataset generation tool provided by Wu et al. [3] to render 10,000 Minecraft scenes, building upon the Malmo interface.
- We generate diverse questions and programs associated with each Minecraft image based on the
objects’ categorical and spatial attributes (position, direction). Each question is composed as a
hierarchy of three families of basic questions: first, querying object attributes (class, location,
direction); second, counting the number of objects satisfying certain constraints; third, verifying if an object has certain property. - Differences from CLEVR: Minecraft hosts a larger set of 3D objects with richer image content and visual appearance; our questions and programs involve hierarchical attributes. For example, a “wolf” and a “pig” are both “animals”, and an “animal” and a “tree” are both “creatures”
- We use the first 9,000 images with 88,109 questions for training and the remaining 1,000 images with 9,761 questions for testing.
Results

- Figure 5a shows the results on three test images: our NS-VQA finds the correct answer and recovers the correct program under the new scene context. Also, most of our model’s wrong answers on this dataset are due to errors in perceiving heavily occluded objects, while the question parser still preserves its power to parse input questions.
- Table 5b shows the overall behavior is similar to that on the CLEVR dataset, except that reasoning on Minecraft generally requires weaker initial program signals.
Future Research
Beyond supervised learning, some recent papers have made inspiring attempts to explore how concepts naturally emerge during unsupervised learning by Irina Higgins et al. [4] (See related work on Structural scene representation in the paper.) We see integrating our model with these approaches a promising future direction.
Reference
- [1] Inferring and Executing Programs for Visual Reasoning by Justin Johnson, Li Fei-Fei, et al. ICCV 2017. [See CLEVR-Humans Dataset & Code]
- [2] Compositional Attention Networks for Machine Reasoning by Drew A. Hudson, Christopher D. Manning. ICLR 2018. (#16)
- [3] Neural Scene De-rendering by Jiajun Wu et al. CVPR 2017.
- [4] beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework by Irina Higgins et al. ICLR 2017.