![]() ML
ML
![]()
![]()
Installation | Get started | Structure | Tasks & Algorithms | Model Zoo | Datasets | How-tos | Contribute
Open3D-ML is an extension of Open3D for 3D machine learning tasks. It builds on top of the Open3D core library and extends it with machine learning tools for 3D data processing. This repo focuses on applications such as semantic point cloud segmentation and provides pretrained models that can be applied to common tasks as well as pipelines for training.
Open3D-ML works with TensorFlow and PyTorch to integrate easily into existing projects and also provides general functionality independent of ML frameworks such as data visualization.
Open3D-ML is integrated in the Open3D v0.11+ python distribution and is compatible with the following versions of ML frameworks.
- PyTorch 2.0.*
- TensorFlow 2.13.* (macOS, see below for Linux)
- CUDA 10.1, 11.* (On
GNU/Linux x86_64, optional)
You can install Open3D with
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dTo install a compatible version of PyTorch or TensorFlow you can use the respective requirements files:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtTo test the installation use
# with PyTorch
$ python -c "import open3d.ml.torch as ml3d"
# or with TensorFlow
$ python -c "import open3d.ml.tf as ml3d"If you need to use different versions of the ML frameworks or CUDA we recommend to build Open3D from source or build Open3D in docker.
From v0.18 onwards on Linux, the PyPI Open3D wheel does not have native support for Tensorflow due to build incompatibilities between PyTorch and Tensorflow [See Python 3.11 support PR] for details. If you'd like to use Open3D with Tensorflow on Linux, you can build Open3D wheel from source in docker with support for Tensorflow (but not PyTorch) as:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
./docker_build.sh cuda_wheel_py310The dataset namespace contains classes for reading common datasets. Here we read the SemanticKITTI dataset and visualize it.
import open3d.ml.torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/path/to/SemanticKITTI/')
# get the 'all' split that combines training, validation and test set
all_split = dataset.get_split('all')
# print the attributes of the first datum
print(all_split.get_attr(0))
# print the shape of the first point cloud
print(all_split.get_data(0)['point'].shape)
# show the first 100 frames using the visualizer
vis = ml3d.vis.Visualizer()
vis.visualize_dataset(dataset, 'all', indices=range(100))
Configs of models, datasets, and pipelines are stored in ml3d/configs. Users can also construct their own yaml files to keep record of their customized configurations. Here is an example of reading a config file and constructing modules from it.
import open3d.ml as _ml3d
import open3d.ml.torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)
# fetch the classes by the name
Pipeline = _ml3d.utils.get_module("pipeline", cfg.pipeline.name, framework)
Model = _ml3d.utils.get_module("model", cfg.model.name, framework)
Dataset = _ml3d.utils.get_module("dataset", cfg.dataset.name)
# use the arguments in the config file to construct the instances
cfg.dataset['dataset_path'] = "/path/to/your/dataset"
dataset = Dataset(cfg.dataset.pop('dataset_path', None), **cfg.dataset)
model = Model(**cfg.model)
pipeline = Pipeline(model, dataset, **cfg.pipeline)Building on the previous example we can instantiate a pipeline with a pretrained model for semantic segmentation and run it on a point cloud of our dataset. See the model zoo for obtaining the weights of the pretrained model.
import os
import open3d.ml as _ml3d
import open3d.ml.torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)
model = ml3d.models.RandLANet(**cfg.model)
cfg.dataset['dataset_path'] = "/path/to/your/dataset"
dataset = ml3d.datasets.SemanticKITTI(cfg.dataset.pop('dataset_path', None), **cfg.dataset)
pipeline = ml3d.pipelines.SemanticSegmentation(model, dataset=dataset, device="gpu", **cfg.pipeline)
# download the weights.
ckpt_folder = "./logs/"
os.makedirs(ckpt_folder, exist_ok=True)
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os.path.exists(ckpt_path):
cmd = "wget {} -O {}".format(randlanet_url, ckpt_path)
os.system(cmd)
# load the parameters.
pipeline.load_ckpt(ckpt_path=ckpt_path)
test_split = dataset.get_split("test")
data = test_split.get_data(0)
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline.run_inference(data)
# evaluate performance on the test set; this will write logs to './logs'.
pipeline.run_test()Users can also use predefined scripts to load pretrained weights and run testing.
Similar as for inference, pipelines provide an interface for training a model on a dataset.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/path/to/SemanticKITTI/', use_cache=True)
# create the model with random initialization.
model = RandLANet()
pipeline = SemanticSegmentation(model=model, dataset=dataset, max_epoch=100)
# prints training progress in the console.
pipeline.run_train()For more examples see examples/
and the scripts/ directories. You
can also enable saving training summaries in the config file and visualize ground truth and
results with tensorboard. See this tutorial
for details.

The 3D object detection model is similar to a semantic segmentation model. We can instantiate a pipeline with a pretrained model for Object Detection and run it on a point cloud of our dataset. See the model zoo for obtaining the weights of the pretrained model.
import os
import open3d.ml as _ml3d
import open3d.ml.torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)
model = ml3d.models.PointPillars(**cfg.model)
cfg.dataset['dataset_path'] = "/path/to/your/dataset"
dataset = ml3d.datasets.KITTI(cfg.dataset.pop('dataset_path', None), **cfg.dataset)
pipeline = ml3d.pipelines.ObjectDetection(model, dataset=dataset, device="gpu", **cfg.pipeline)
# download the weights.
ckpt_folder = "./logs/"
os.makedirs(ckpt_folder, exist_ok=True)
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os.path.exists(ckpt_path):
cmd = "wget {} -O {}".format(pointpillar_url, ckpt_path)
os.system(cmd)
# load the parameters.
pipeline.load_ckpt(ckpt_path=ckpt_path)
test_split = dataset.get_split("test")
data = test_split.get_data(0)
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline.run_inference(data)
# evaluate performance on the test set; this will write logs to './logs'.
pipeline.run_test()Users can also use predefined scripts to load pretrained weights and run testing.
Similar as for inference, pipelines provide an interface for training a model on a dataset.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d.datasets.KITTI(dataset_path='/path/to/KITTI/', use_cache=True)
# create the model with random initialization.
model = PointPillars()
pipeline = ObjectDetection(model=model, dataset=dataset, max_epoch=100)
# prints training progress in the console.
pipeline.run_train()Below is an example of visualization using KITTI. The example shows the use of bounding boxes for the KITTI dataset.
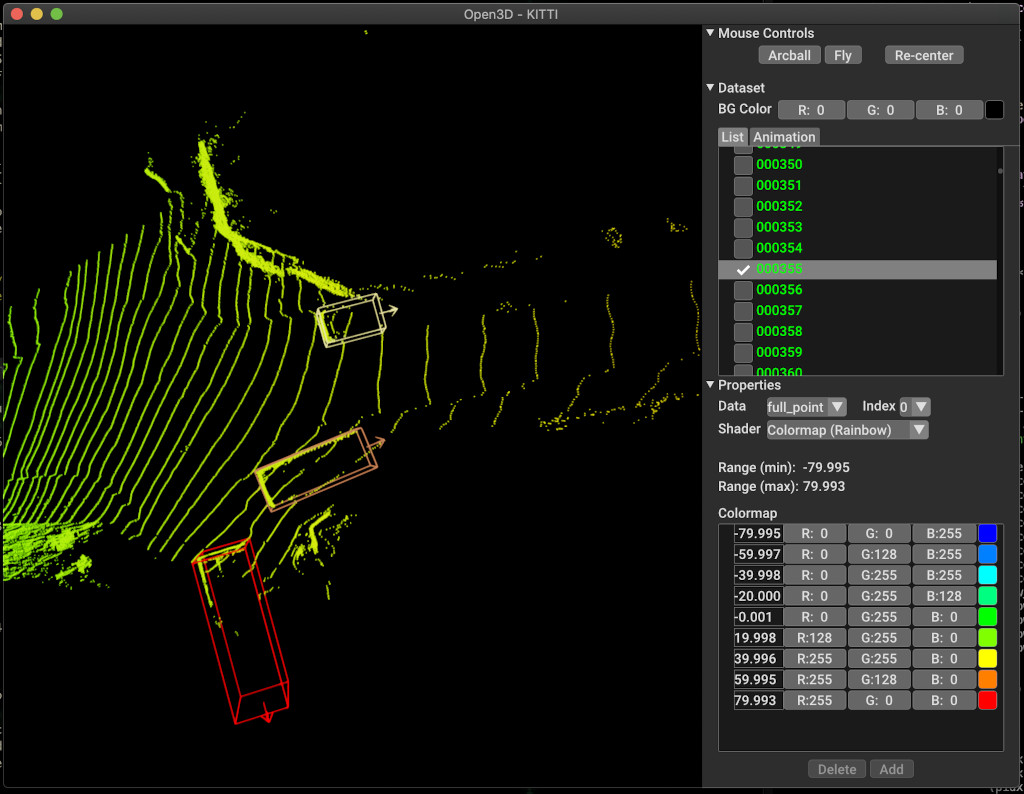
For more examples see examples/
and the scripts/ directories. You
can also enable saving training summaries in the config file and visualize ground truth and
results with tensorboard. See this tutorial
for details.

scripts/run_pipeline.py
provides an easy interface for training and evaluating a model on a dataset. It saves
the trouble of defining specific model and passing exact configuration.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
You can use script for both semantic segmentation and object detection. You must specify
either SemanticSegmentation or ObjectDetection in the pipeline parameter.
Note that extra args will be prioritized over the same parameter present in the configuration file.
So instead of changing param in config file, you may pass the same as a command line argument while launching the script.
For eg.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
For further help, run python scripts/run_pipeline.py --help.
The core part of Open3D-ML lives in the ml3d subfolder, which is integrated
into Open3D in the ml namespace. In addition to the core part, the directories
examples and scripts provide supporting scripts for getting started with
setting up a training pipeline or running a network on a dataset.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
For the task of semantic segmentation, we measure the performance of different methods using the mean intersection-over-union (mIoU) over all classes. The table shows the available models and datasets for the segmentation task and the respective scores. Each score links to the respective weight file.
| Model / Dataset | SemanticKITTI | Toronto 3D | S3DIS | Semantic3D | Paris-Lille3D | ScanNet |
|---|---|---|---|---|---|---|
| RandLA-Net (tf) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0* | - |
| RandLA-Net (torch) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0* | - |
| KPConv (tf) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| KPConv (torch) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| SparseConvUnet (torch) | - | - | - | - | - | 68 |
| SparseConvUnet (tf) | - | - | - | - | - | 68.2 |
| PointTransformer (torch) | - | - | 69.2 | - | - | - |
| PointTransformer (tf) | - | - | 69.2 | - | - | - |
(*) Using weights from original author.
For the task of object detection, we measure the performance of different methods using the mean average precision (mAP) for bird's eye view (BEV) and 3D. The table shows the available models and datasets for the object detection task and the respective scores. Each score links to the respective weight file. For the evaluation, the models were evaluated using the validation subset, according to KITTI's validation criteria. The models were trained for three classes (car, pedestrian and cyclist). The calculated values are the mean value over the mAP of all classes for all difficulty levels. For the Waymo dataset, the models were trained on three classes (pedestrian, vehicle, cyclist).
| Model / Dataset | KITTI [BEV / 3D] @ 0.70 | Waymo (BEV / 3D) @ 0.50 |
|---|---|---|
| PointPillars (tf) | 61.6 / 55.2 | - |
| PointPillars (torch) | 61.2 / 52.8 | avg: 61.01 / 48.30 | best: 61.47 / 57.55 [^wpp-train] |
| PointRCNN (tf) | 78.2 / 65.9 | - |
| PointRCNN (torch) | 78.2 / 65.9 | - |
[^wpp-train]: The avg. metrics are the average of three sets of training runs with 4, 8, 16 and 32 GPUs. Training was for halted after 30 epochs. Model checkpoint is available for the best training run.
To use ground truth sampling data augmentation for training, we can generate the ground truth database as follows:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
This will generate a database consisting of objects from the train split. It is recommended to use this augmentation for dataset like KITTI where objects are sparse.
The two stages of PointRCNN are trained separately. To train the proposal generation stage of PointRCNN with PyTorch, run the following command:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
After getting a well trained RPN network, we can train RCNN network with frozen RPN weights.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
For a full list of all weight files see model_weights.txt and the MD5 checksum file model_weights.md5.
The following is a list of datasets for which we provide dataset reader classes.
- SemanticKITTI (project page)
- Toronto 3D (github)
- Semantic 3D (project-page)
- S3DIS (project-page)
- Paris-Lille 3D (project-page)
- Argoverse (project-page)
- KITTI (project-page)
- Lyft (project-page)
- nuScenes (project-page)
- Waymo (project-page)
- ScanNet(project-page)
For downloading these datasets visit the respective webpages and have a look at the scripts in scripts/download_datasets.
- Visualize network predictions
- Visualize custom data
- Adding a new model
- Adding a new dataset
- Distributed training
- Visualize and compare input data, ground truth and results in TensorBoard
- Inference with Intel OpenVINO
There are many ways to contribute to this project. You can:
- Implement a new model
- Add code for reading a new dataset
- Share parameters and weights for an existing model
- Report problems and bugs
Please, make your pull requests to the dev branch. Open3D is a community effort. We welcome and celebrate contributions from the community!
If you want to share weights for a model you trained please attach or link the weights file in the pull request. For bugs and problems, open an issue. Please also check out our communication channels to get in contact with the community.
- Forum: discussion on the usage of Open3D.
- Discord Chat: online chats, discussions, and collaboration with other users and developers.
Please cite our work (pdf) if you use Open3D.
@article{Zhou2018,
author = {Qian-Yi Zhou and Jaesik Park and Vladlen Koltun},
title = {{Open3D}: {A} Modern Library for {3D} Data Processing},
journal = {arXiv:1801.09847},
year = {2018},
}