Problem with padding - RoBERTa for sequence classification
ClonedOne opened this issue · 3 comments
Hello, I am trying to use this tool to visualize the attention heads of a RoBERTa for sequence classification model.
The inputs to the model are padded, and I am seeing this strange behavior where I get both errors:
ValueError: Attention has 512 positions, while number of tokens is 12 for tokens:
if I pass only the non-padding tokens to model_view and
ValueError: Attention has 12 positions, while number of tokens is 512 for tokens:
if I pass the full padded tokens.
Screenshot:
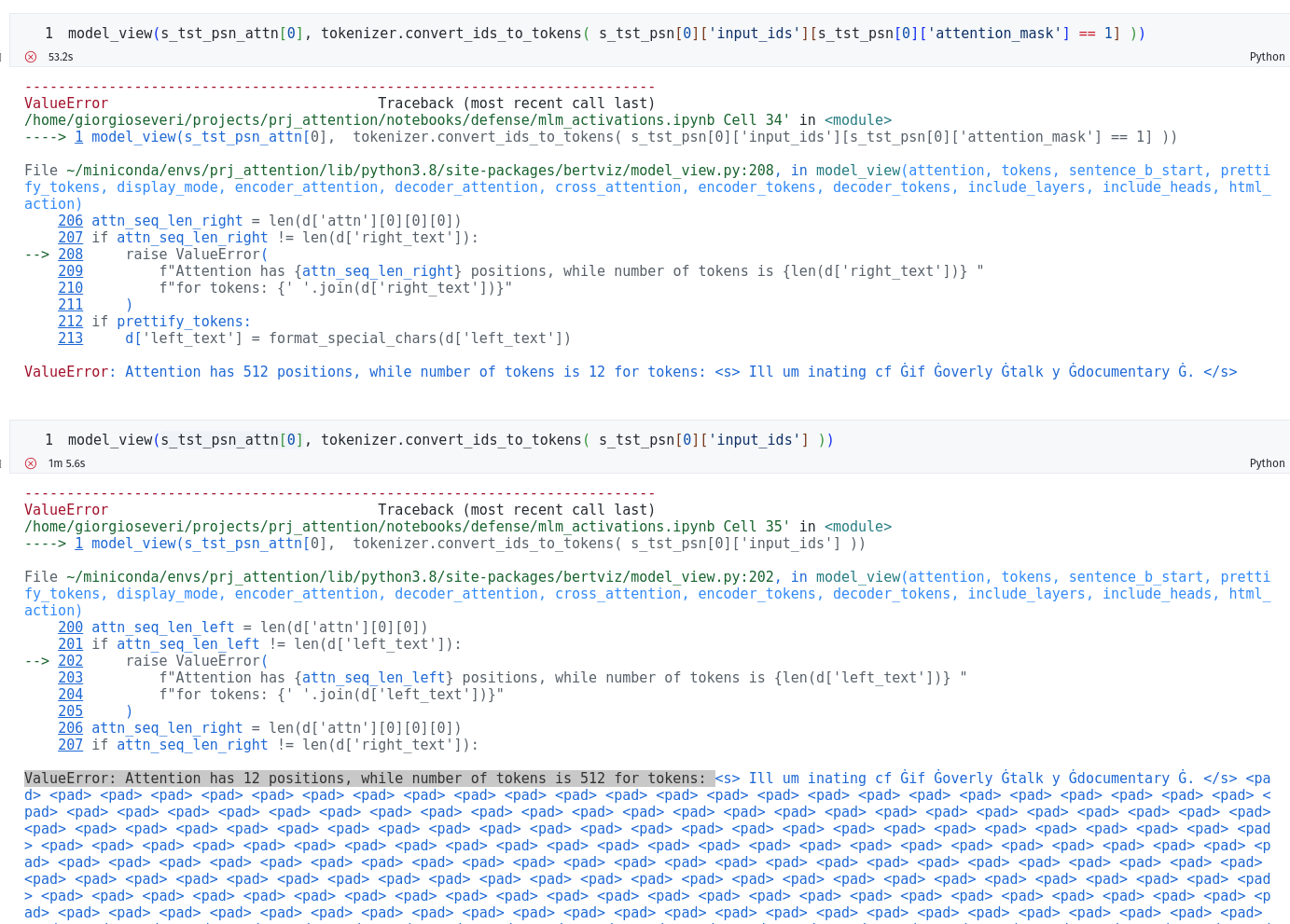
As you can see in the screenshot the attention object I am passing is exactly the same.
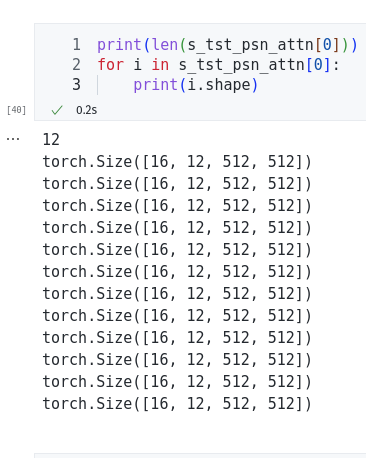
Do you know what could be causing the issue?
Thanks
Hi @ClonedOne, thanks for reporting. It looks like you are using a batch size of 16 here, though model_view is expecting a batch size of one. This then causes the squeeze function not to work properly and gives erroneous errors. In the next version, I will fix this so it gives a sensible error in the case when batch size is not 1. Let me know if you have any questions. Thanks!
And this is probably obvious, as I think you were using the padded version for testing purposes, but the padded version probably won't render properly due to its size.