Sequence-to-Sequence Speech Recognition with Time-Depth Separable Convolutions
jinglescode opened this issue · 0 comments
Paper
Link: https://arxiv.org/pdf/1904.02619.pdf
Year: 2019
Summary
fully convolutional encoder and a simple decoder can give superior results to a strong RNN baseline while being an order of magnitude more efficient. Key to the success of the convolutional encoder is a time-depth separable block structure which allows the model to retain a large receptive field
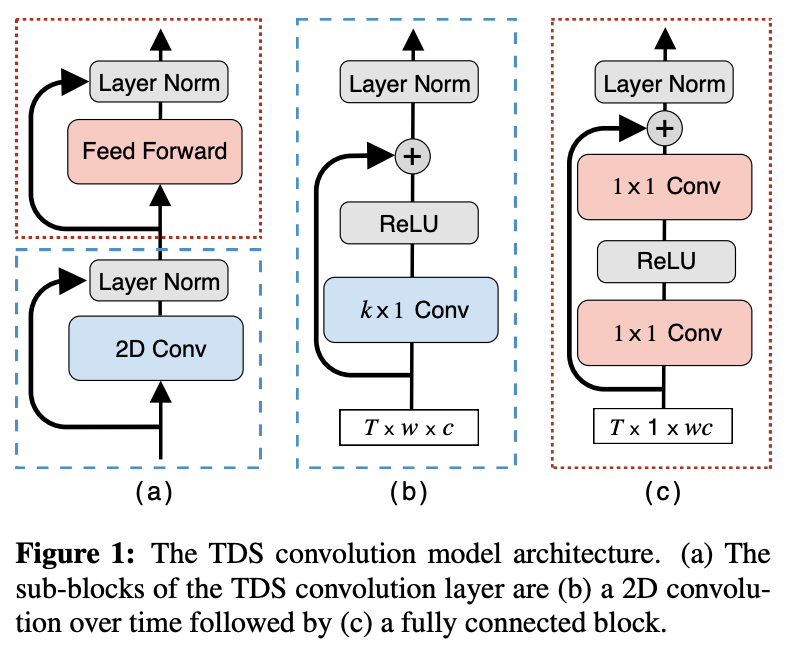
We propose a fully convolutional sequence-to-sequence encoder architecture with a simple and efficient decoder. Our
model improves WER on LibriSpeech while being an order of
magnitude more efficient than a strong RNN baseline. Key to
our approach is a time-depth separable convolution block which
dramatically reduces the number of parameters in the model
while keeping the receptive field large. We also give a stable and efficient beam search inference procedure which allows
us to effectively integrate a language model. Coupled with a
convolutional language model, our time-depth separable convolution architecture improves by more than 22% relative WER
over the best previously reported sequence-to-sequence results
on the noisy LibriSpeech test set.