Stand-Alone Self-Attention in Vision Models
jinglescode opened this issue · 0 comments
Paper
Title:
Authors:
Link: https://arxiv.org/pdf/1906.05909.pdf
Year:
Summary
- self-attention can indeed be an effective stand-alone layer
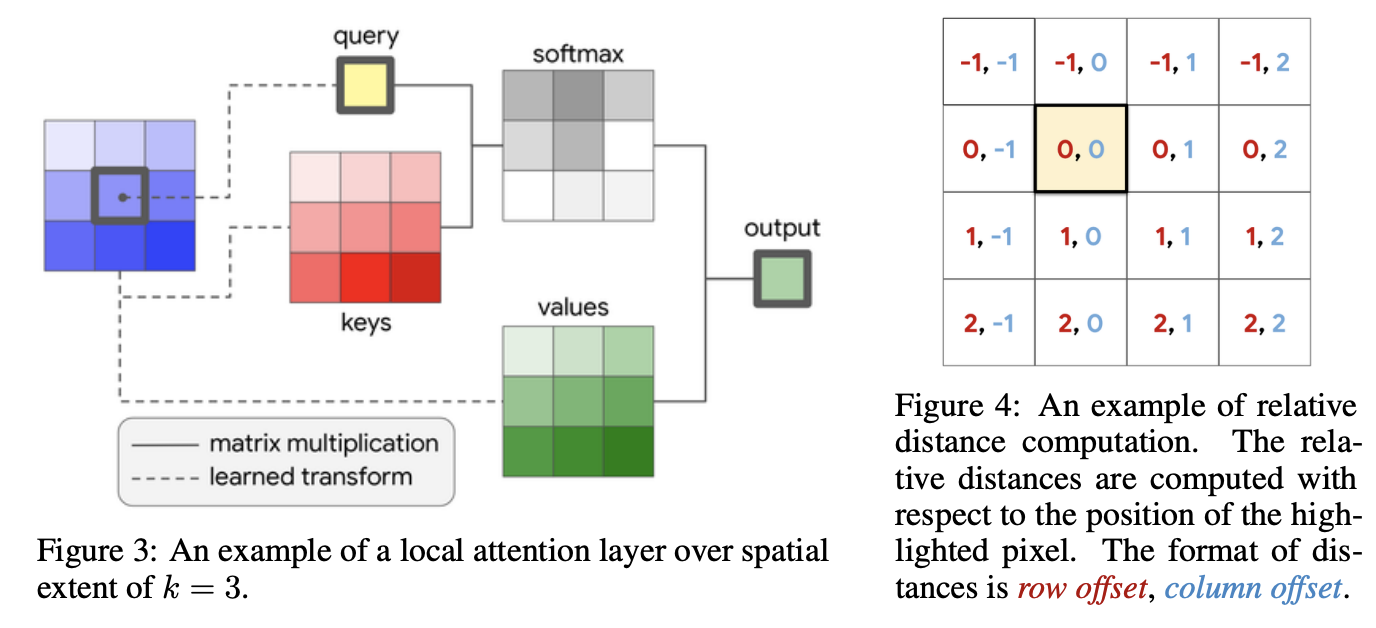
Convolutions are a fundamental building block of modern computer vision systems.
Recent approaches have argued for going beyond convolutions in order to capture
long-range dependencies. These efforts focus on augmenting convolutional models
with content-based interactions, such as self-attention and non-local means, to
achieve gains on a number of vision tasks. The natural question that arises is
whether attention can be a stand-alone primitive for vision models instead of
serving as just an augmentation on top of convolutions. In developing and testing
a pure self-attention vision model, we verify that self-attention can indeed be an
effective stand-alone layer. A simple procedure of replacing all instances of spatial
convolutions with a form of self-attention applied to ResNet model produces a fully
self-attentional model that outperforms the baseline on ImageNet classification with
12% fewer FLOPS and 29% fewer parameters. On COCO object detection, a pure
self-attention model matches the mAP of a baseline RetinaNet while having 39%
fewer FLOPS and 34% fewer parameters. Detailed ablation studies demonstrate
that self-attention is especially impactful when used in later layers. These results
establish that stand-alone self-attention is an important addition to the vision
practitioner’s toolbox.
Contributions and Distinctions from Previous Works
- replacing all instances of spatial convolutions with a form of self-attention applied to ResNet model produces a fully self-attentional model that outperforms the baseline on ImageNet classification with 12% fewer FLOPS and 29% fewer parameters
- pure self-attention model matches the mAP of a baseline RetinaNet while having 39% fewer FLOPS and 34% fewer parameters
Results
Compared to the ResNet-50 baseline, the full attention variant achieves 0.5% higher classification accuracy while having 12% fewer floating point operations (FLOPS) and 29% fewer parameters. Furthermore, this performance gain is consistent across most model variations generated by both depth and width scaling.