Dynamic Convolution: Attention over Convolution Kernels
jinglescode opened this issue · 0 comments
jinglescode commented
Paper
Link: https://arxiv.org/pdf/1912.03458.pdf
Year: 2020
Summary
- increases model complexity without increasing the network depth or width
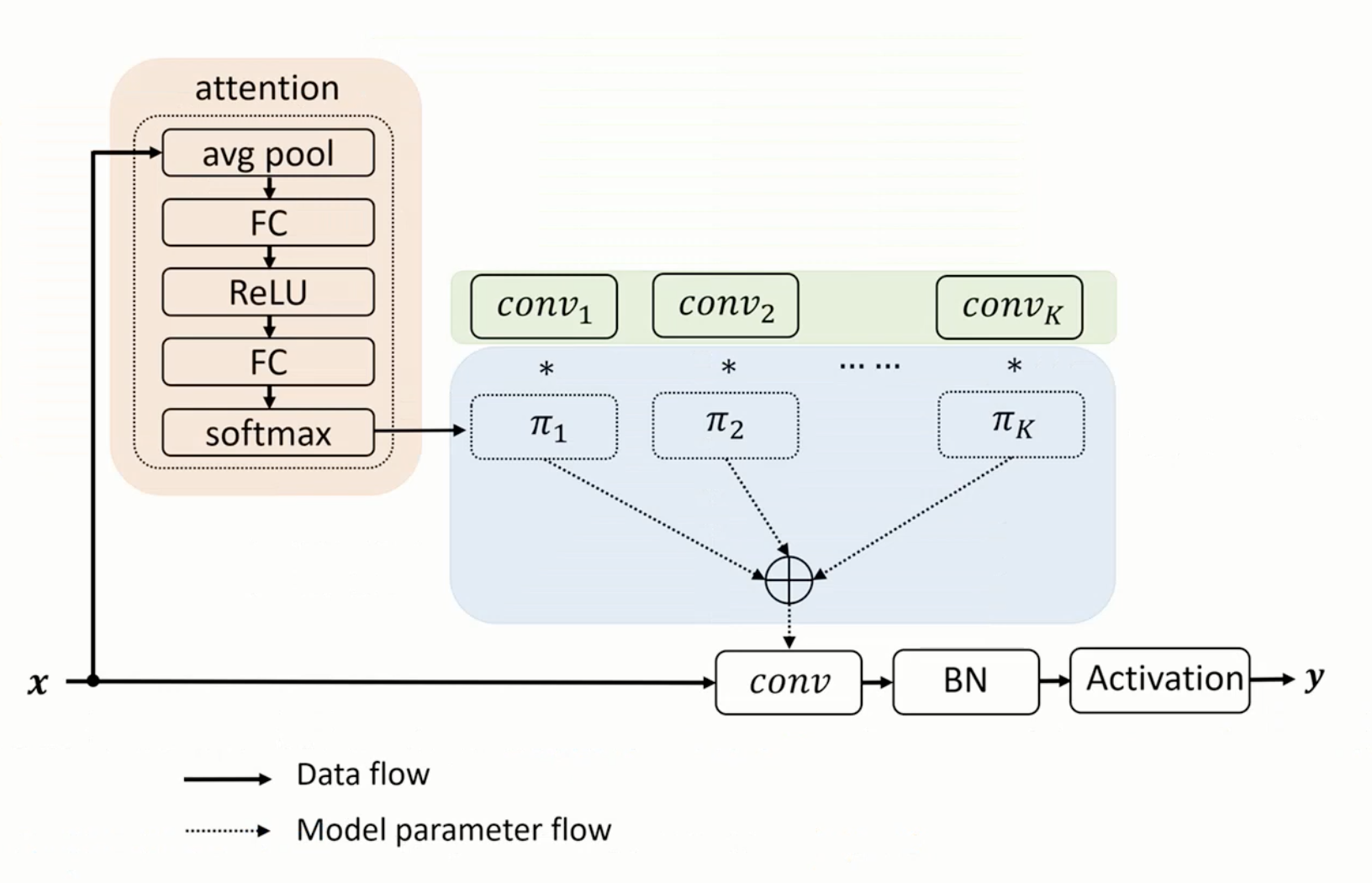
- single convolution kernel per layer, dynamic convolution aggregates multiple parallel convolution kernels dynamically based upon their attentions, which are input dependent
- can be easily integrated into existing CNN architectures
Video: https://www.youtube.com/watch?v=FNkY7I2R_zM
Contributions and Distinctions from Previous Works
- two most popular strategies to boost the performance are making neural networks “deeper” or “wider”. However, they both incur heavy computation cost, thus are not friendly to efficient neural networks.
- dynamic convolution, which does not increase either the depth or the width of the network, but increase the model capability by aggregating multiple convolution kernels via attention
Methods
Results
- comparing to classic MobileNetV2, MobileNetV3 and ResNet, with dynamic convolution, it significantly improves the representation capability with negligible extra computation cost
- simply replacing each convolution kernel in MobileNet (V2 and V3) with dynamic convolution, we achieve solid improvement for both image classification and human pose estimation