Rethinking Attention with Performers
jinglescode opened this issue · 0 comments
jinglescode commented
Paper
Link: https://arxiv.org/abs/2009.14794
Year: 2020
Summary
- proposes a set of techniques called Fast Attention Via positive Orthogonal Random features (FAVOR+) to approximate softmax self attention in Transformers and achieve better space and time complexity when the sequence length is much higher than feature dimensions
- Performers, is provably and practically accurate in estimating regular full-rank attention without relying on any priors such as sparsity or low-rankness. It can also be applied to efficiently model other kernalizable attention mechanisms beyond softmax, achieving better empirical results than regular Transformers on some datasets with such strong representation power
- tested on a rich set of tasks including pixel-prediction, language modeling and protein sequence modeling, and demonstrated competitive results with other examined efficient sparse and dense attention models
Contributions and Distinctions from Previous Works
- this work aim to reduce Transformers’ space complexity
Methods

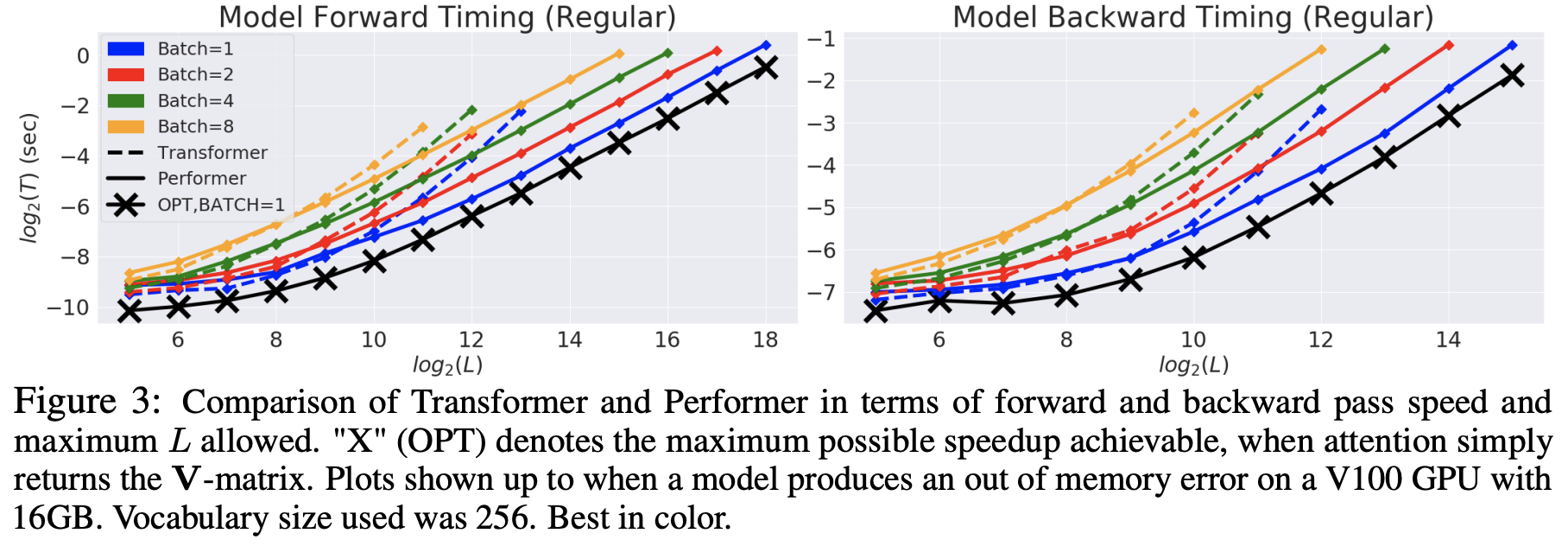
Results
Comments
- math heavy paper, potential for some breakthrough for speed and space complexity
- google blog post
- blog post to understand more
- presentation by Krzysztof Choromanski