Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
jinglescode opened this issue · 0 comments
jinglescode commented
Paper
Link: https://arxiv.org/abs/1712.05884
Year: 2018
Summary
- text to speech synthesis, sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize time-domain waveforms from those spectrograms
Methods
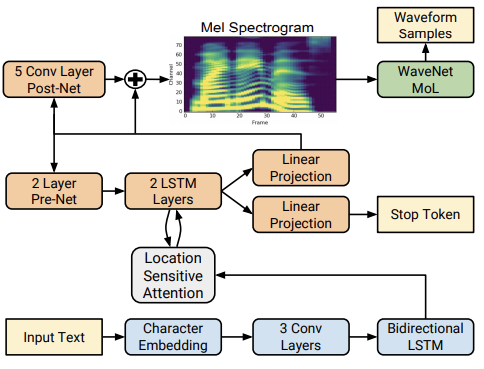
network is composed of an encoder and a decoder with attention
- encoder converts a character sequence into representations
- decoder consumes to predict a spectrogram
- attention network which summarizes the full encoded sequence as a fixed-length context vector for each decoder output step
- concatenation of the LSTM output and the attention context vector is projected through a linear transform to predict the target spectrogram frame