Code for the paper Neural Generation of Regular Expressions from Natural Language with Minimal Domain Knowledge (EMNLP 2016).
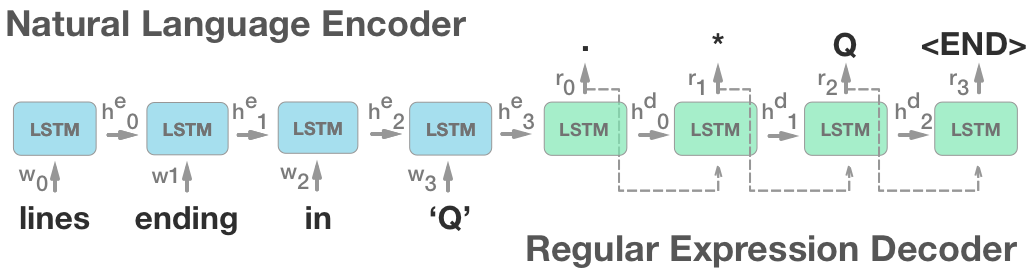
Our neural model translates natural language queries into regular expressions which embody their meaning. We model the problem as a sequence-to-sequence mapping task using attention-based LSTM's. Our model achieves a performance gain of 19.6% over previous state-of-the-art models.
We also present a methodology for collecting a large corpus of regular expression, natural language pairs using Mechanical Turk and grammar generation. We utilize this methology to create the NL-RX dataset.
This dataset is open and available in this repo.
pip install -r requirements.txt
- Install torch (http://torch.ch/docs/getting-started.html)
- Install packages:
luarocks install nn
luarocks install nngraph
luarocks install hdf5
- From
/deep-regex-model/, runbash train_single.sh $full_data_directory
-
From
/deep-regex-model/, runbash eval_single.sh $data_directory $model_file_name- There are 3 valid
$full_data_directorystrings:data_kushman_eval_kushmandata_turk_eval_turkdata_synth_eval_synth
- There are 3 valid
$data_directorystrings (after training):data_kushman_eval_kushman/data_100data_turk_eval_turk/data_100data_synth_eval_synth/data_100
- There are 3 valid
Datasets are provided in 3 folders within /datasets/: KB13, NL-RX-Synth, NL-RX-Turk. Datasets are open source under MIT license.
KB13is the data from Kushman and Barzilay, 2013.NL-RX-Synthis data fromNL-RX1 with original synthetic descriptions.NL-RX-Turkis data fromNL-RX1 with Mechanical-Turk paraphrased descriptions.
1 NL-RX is the dataset from our paper.
The data is a parallel corpus, so the folder is split into 2 files: src.txt and targ.txt. src.txt is the natural language descriptions. targ.text is the corresponding regular expressions.
- Note - all models (ours and previous) that perform this task perform string replacement of any string in quotation marks. This means that "lines that contain 'blue'" and "lines that contain 'red'", will both be identical in some form "lines that contain ".
- Our datasets have this already pre-computed - for each example, the words in quotations appear in the order 'dog', 'truck', 'ring', 'lake' to universally indicate their position.
Code used to generate new data (Regexes and Synthetic Descriptions) is in /data_gen/ folder.
From /data_gen/, run python generate_regex_data.py to run the generation process described in the paper.
- Yoon Kim's seq2seq-attn
- Facebook's torch
MIT