[2.2.0-*] cron_schedule forever increasing in size. Lots of pending jobs never cleared
gwharton opened this issue · 98 comments
Preconditions
- Magento 2.2.0-rc30 running on Ubunti 16.04
- Deployed initially from zip, but updated to 2.2.0-rc30 using composer
Steps to reproduce
- Nothing, just look at the cron_schedule table
Expected result
- On 2.1.9 my cron_schedule table is around 180 items in size. Its size is pretty much static. A snapshot shows the vast majority of jobs are in the success state, with a couple of pending jobs about to be run in the next minute or so.
Actual result
- On 2.2.0-rc30 which has been running for around 8 days (upgraded from previous rc) the size of the cron_schedule table is around 6500 items in size. The size is constantly increasing every minute. The majority of the jobs are in the pending state. Some are marked as success.
The cronjob steadily increases in the time taken to complete, at the moment it is taking around 30 seconds to complete, during which time, mysql and php are taking up heavy CPU usage.
A MYSQL query log shows magento churning through all the pending requests, but they are never marked as success. Hence the ever increasing list of jobs to run.
Snippet from the Mysql Query log below
90 Query START TRANSACTION
90 Query UPDATE "cron_schedule" SET "job_code" = "catalog_product_outdated_price_values_cleanup", "status" = "pending", "messages" = NULL, "created_at" = "2017-09-15 09:29:06", "scheduled_at" = "2017-09-15 09:48:00", "executed_at" = NULL, "finished_at" = NULL WHERE (schedule_id="189337")
90 Query COMMIT
90 Query UPDATE "cron_schedule" AS "current" LEFT JOIN "cron_schedule" AS "existing" ON existing.job_code = current.job_code AND existing.status = "running" SET "current"."status" = "running" WHERE (current.schedule_id = "189338") AND (current.status = "pending") AND (existing.schedule_id IS NULL)
90 Query START TRANSACTION
90 Query UPDATE "cron_schedule" SET "job_code" = "catalog_product_frontend_actions_flush", "status" = "pending", "messages" = NULL, "created_at" = "2017-09-15 09:29:06", "scheduled_at" = "2017-09-15 09:33:00", "executed_at" = NULL, "finished_at" = NULL WHERE (schedule_id="189338")
90 Query COMMIT
90 Query UPDATE "cron_schedule" AS "current" LEFT JOIN "cron_schedule" AS "existing" ON existing.job_code = current.job_code AND existing.status = "running" SET "current"."status" = "running" WHERE (current.schedule_id = "189339") AND (current.status = "pending") AND (existing.schedule_id IS NULL)
90 Query START TRANSACTION
90 Query UPDATE "cron_schedule" SET "job_code" = "catalog_product_frontend_actions_flush", "status" = "pending", "messages" = NULL, "created_at" = "2017-09-15 09:29:06", "scheduled_at" = "2017-09-15 09:34:00", "executed_at" = NULL, "finished_at" = NULL WHERE (schedule_id="189339")
90 Query COMMIT
90 Query UPDATE "cron_schedule" AS "current" LEFT JOIN "cron_schedule" AS "existing" ON existing.job_code = current.job_code AND existing.status = "running" SET "current"."status" = "running" WHERE (current.schedule_id = "189340") AND (current.status = "pending") AND (existing.schedule_id IS NULL)
90 Query START TRANSACTION
90 Query UPDATE "cron_schedule" SET "job_code" = "catalog_product_frontend_actions_flush", "status" = "pending", "messages" = NULL, "created_at" = "2017-09-15 09:29:06", "scheduled_at" = "2017-09-15 09:35:00", "executed_at" = NULL, "finished_at" = NULL WHERE (schedule_id="189340")
90 Query COMMIT
90 Query UPDATE "cron_schedule" AS "current" LEFT JOIN "cron_schedule" AS "existing" ON existing.job_code = current.job_code AND existing.status = "running" SET "current"."status" = "running" WHERE (current.schedule_id = "189341") AND (current.status = "pending") AND (existing.schedule_id IS NULL)
90 Query START TRANSACTION
90 Query UPDATE "cron_schedule" SET "job_code" = "catalog_product_frontend_actions_flush", "status" = "pending", "messages" = NULL, "created_at" = "2017-09-15 09:29:06", "scheduled_at" = "2017-09-15 09:36:00", "executed_at" = NULL, "finished_at" = NULL WHERE (schedule_id="189341")
90 Query COMMIT
90 Query UPDATE "cron_schedule" AS "current" LEFT JOIN "cron_schedule" AS "existing" ON existing.job_code = current.job_code AND existing.status = "running" SET "current"."status" = "running" WHERE (current.schedule_id = "189342") AND (current.status = "pending") AND (existing.schedule_id IS NULL)
@gwharton, thank you for your report.
We were not able to reproduce this issue by following the steps you provided. If you'd like to update it, please reopen the issue.
We tested the issue on 2.2.0
@gwharton I have been having the same problem since upgrading to 2.2.0. Have you done anything outside of clearing the cron_schedule table to fix it? I have done the same, but old entries are still not deleted. The timezone is set correctly, but that doesn't seem related.
All of my installations are working as they should. The size of my cron_schedule tables are fairly static at around 1200 rows. This seems to be the correct behaviour, as the Magento settings regarding keeping cron history say to keep 1 hour, and looking at the entries in the table that is correct. The behaviour I saw in 2.1 where the cron_schedule table was only a 100 or so rows seemed to be incorrect behaviour, as it was only keeping the last minute. I suspect this was some sort of timezone problem on the timestamps.
I did have a couple of occasions where one of the cron jobs appeared to start, but had no finish time. This resulted in the table growing in size out of control as new rows for that cron job were added in the pending state, but never got run because the "stuck" job was still running as far as Magento was concerned. Clearing the table seemed to set things going again.
I have no idea why the job was stuck. Feels like Magento should have some method of detecting stuck jobs, or jobs that completed but didn't update their completed timestamp. Without this, Magento never recovers, resulting in the ramp up of CPU usage, eventually hitting 100% in a couple of weeks time as it repeatedly parses through the massive and growing amount of pending jobs every minute.
Unfortunately I haven't been able to reproduce this recently.
One thought that I did have, is that I was doing a lot of development work on a module at the time these problems occurred. During some of these changes/recompiles/updates I would get emails telling me that the cron process failed, or when I restarted mysql that the database connection failed. Perhaps this is when the cron job starts but doesn't finish and then from this point on it just creates the pending jobs forever.
Since this, I now updated my cron jobs to check if Magento is in maintenance mode
* * * * * ! test -e ~/public_html/var/.maintenance.flag && php ~/public_html/bin/magento cron:run .........
This way, it makes sure that the cron jobs are never run while you are in maintenance mode. I don't know if this is recommended or not, but it feels much cleaner that cron jobs aren't run when I am carrying out magento upgrades/recompiles/development.
I have a standard shell script which I run every time I make changes or want to upgrade the store. It puts the store into maintenance mode while it updates magento to latest version, clears all static content, upgrades/recompiles/deploys static content and then clears the caches. Since religiously using this script to enforce maintenance mode, and having the cron jobs disabled while in maintenance mode I have not had any further issues.
#!/bin/sh
php bin/magento maintenance:enable
composer update
rm -rf pub/static/*
rm -rf var/view_preprocessed
rm -rf generated/code
rm -rf var/cache
rm -rf generated/metadata
rm -rf var/page_cache
php bin/magento setup:upgrade
php bin/magento setup:di:compile
php bin/magento setup:static-content:deploy --area=frontend --theme=Gw/frontend --language=en_US
php bin/magento setup:static-content:deploy --area=adminhtml --theme=Gw/backend --language=en_US
php bin/magento cache:clean
php bin/magento cache:enable
php bin/magento maintenance:disable
When updating modules, once I am happy they work on my test store, I put the production store into maintenance mode, upload the necessary updates, then run the above script to finish the deployment.
Unfortunately the cron_schedule table kept growing even after a redeployment in maintenance mode, like you described. To fix my problem, I just wrote a cronjob that cleans old entries in cron_schedule every hour.

My dev store went again at about 2am on the 17th. See phpmyadmin attached. The first entry in the table is marked as running. Then there are 6000 odd entries following it, all in the pending state and growing.
@magento-engcom-team I am unable to reproduce this on demand, but it feels like Magento is missing some cleanup code that detects cron jobs that are stuck in the running state. Really it should detect a stuck job, clear it and log some sort of error, allowing the future pending jobs to clear naturally. Just repeatedly adding pending jobs infinitum seems like a poor decision.
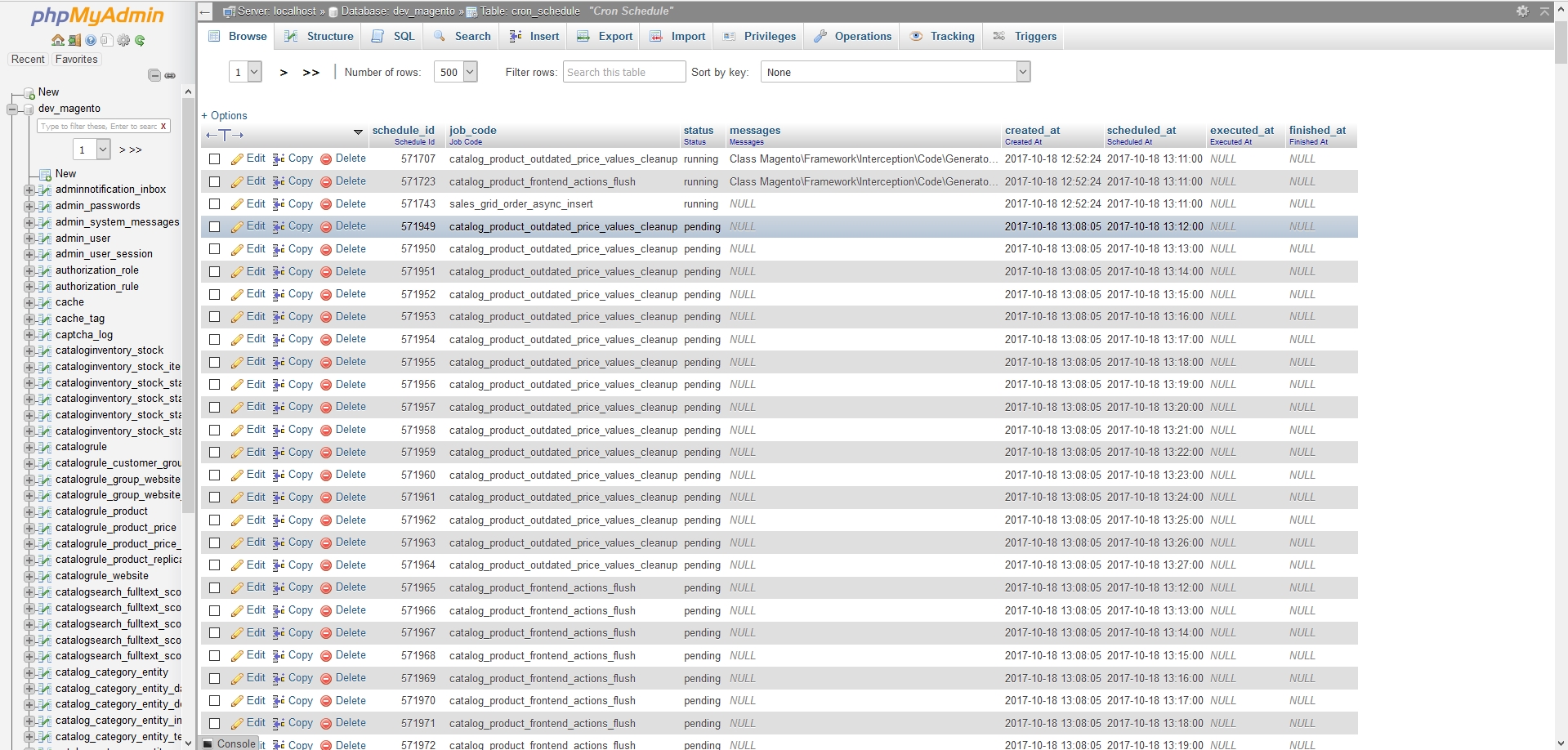
I deleted the first row of the table, that was in the running state, and on the next cron run, it cleared all the pending tasks for this stuck cron, however rising to the top of the table, 3 more stuck cron jobs the following day at midday.
These DO correspond to when I was performing maintenance on the store, where there may have been code installed containing errors, or the database dropped etc or other anomoly going on.
@cytracon I didn't change anything. I just added a new cronjob to the crontab.
0 * * * *
mysql magento-db -e "delete from cron_schedule where scheduled_at < date_sub(now(), interval 1 hour)"
Of course you could also write a magento cronjob, but I don't trust those anymore.
(Edit: see gwhartons post below)
Not wanting to stray off topic but @dwirt If it's a shared server then beware of putting your mysql password in the command line like that. It can be viewed by anyone while the process is running.
The preferred method is to create a ~/.my.cnf file and specify mysql magento-db ..... on the command line. The host, username and password will be read from the file automatically.
The contents of .my.cnf should be
[mysql]
host = <hostname>
user = <username>
password = <password>
You can then secure this file with chmod 600 to keep it safe. You can also add the equivalent section for [mysqldump] if you use that command in cron jobs for database backups etc.
@gwharton Thanks!
@magento-engcom-team Can this issue be re-opened. I, and several others by the looks of it, are having to go into the database on a regular basis to clear out cron jobs that are stuck in the running state.
It seems to be worse on development installs, where cron jobs may be crashing whilst being run and never being marked as completed. Its not the same job every time. Seems to be random which one gets stuck.
If you don't manually delete the stuck running job, then, on my webserver, the CPU is overwhelmed at 100% within about 3 days as the never ending list of pending jobs in the cron_schedule table increases. If you don't spot the problem, the first you will know about it, is when your webserver is unresponsive as MySQL is overwhelmed by Magento cycling through thousands of pending cron jobs every minute.
@gwharton: yes exactly, I've seen this behavior a couple of times on our projects, a development server was running at 100% CPU for over 2 weeks until someone noticed it was because of a cronjob or indexer which got stuck somehow.
This should really get fixed!
I've been battling some negative behavior with cron:run lately and I think this thread is describing the root cause of my issue.
I started up a new virtual machine with Magento and it was working fine at first. But after a week or 2 the server was super slow and unresponsive to the point of not being usable. I eventually noticed there would 10 or more instances of the cron:run process running simultaneously and hammering MySQL. I had the process set to run every minute, as seems to be the default.
I walked back the cron schedule to every 8 minutes and that prevented mutliple cron:run processes from running simultaneously.
I finally found this issue and it lead to counting the rows in cron_schedule, which was 208,046! I ran the query posted above and that brought it down to 252 rows.
My site has just been under light developement, no traffic.
After running the query
delete from cron_schedule where scheduled_at < date_sub(now(), interval 1 hour)
now I've switched all 3 standard magento cron process - cron:run, setup:cron:run, cron.php - back to running every minute, and all 3 run pretty much instantly in under 5 - 10 seconds or less.
I'm new to magento, so I can't speak to the cause but i can say anyone that runs will be left with an unusable site, unless they heavily upgrade their hardware. I posted this question to magento.stackexchange.com and another user said they were experiencing the same issue, check out the comments. https://magento.stackexchange.com/questions/201063/should-2-of-the-standard-cron-always-be-running?noredirect=1#comment278625_201063
UPDATE: After adding this query to the crontab after reading about this, it fixed all negative behavior and after switching my 3 magento crons back to running every minute, the cron_schedule table is holding steady at around 1030 - 1050 rows with the delete query deleting about 20 rows every 15 minutes when it runs.
I have the same problem. Magento 2.2.1.
I have created a test module that implements a cron job that crashes during execution.
It can be downloaded from here Gw_CronCrash.zip
This is a simple cron job that just throws an invalid exception, instead of actually doing anything useful. It simulates a cron job crashing for whatever reason during execution.
Once installed, on the next 1 minute boundary, the exception is logged in var/log/magento.cron.log (if you have setup logging of cron output).
Now if you check your cron_schedule table
SELECT * FROM 'cron_schedule' WHERE 'job_code' = 'Gw_CronCrash'
You will see the first row shows the first time it tried to run the job. The job will be in the "running" state, even though the job crashed and failed a long time ago.
Every 15 minutes, a new batch of 15 jobs in the pending state are added to the cron table with status "pending". No rows are ever removed.
The table will grow forever.
Even if you fix the problem with the code in the module, the cron job for that module is NEVER run again. 1440 rows are added to the cron table every day. Every minute, every row of the cron_schedule table is parsed by Magento. Depending on the capabilities of your machine, your CPU could be maxed out in as little as a week.
The only way out is to manually delete the first entry in the cron_schedule table to remove the "running" job. Magento, then does a nice job of cleaning up the remainder of the "pending" entries, as you would expect.
Could this issue be reopened. It is 100% reproducable with this example module.
@gwharton Your hard work on this is appreciated. I have raised this to the comeng team for reopening, and am investigating this solution myself now.
There is some work happening in this PR #12497 which aims to prevent the same cron group being run concurrently. It doesn't sound like it would fix this issue on the cleaning up of the crashed cron task but it might help in alleviate the issue of piled up cron jobs.
Hello. I have the same issue on Magento 2.2.1. Here is how many cronjobs there are in pending status from 2017-11-22:
SELECT * FROM `ver_cron_schedule` WHERE `status`='pending'
Showing rows 0 - 24 (146437 total, Query took 0.1034 seconds.) [created_at: 2017-11-22 16:56:05... - 2017-11-22 16:56:05...]
@gwharton, thank you for your report.
We've created internal ticket(s) MAGETWO-83782 to track progress on the issue.
Not terribly useful but just wanted to add that I ran into this problem on Magento 2.2.1, my count for cron_schedule had grown to 532983. Clearing the schedule solved the problem, so thanks to those who found the reason. I just hope someone can find a fix for the cause of the growing table.
Implementing the stub scheduled cleanup of this table has dropped the execution timeout low enough that jobs are no longer timing out within a 15 minute period.
Read: this is me
#Ansible: Workaround while upstream bug #11002 is being resolved
*/5 * * * * systemd-cat --identifier=magento_cron_cleanup -- flock --timeout="900" /run/lock/magento_cron_cleanup.lock /usr/local/bin/n98-magerun2.phar --root-dir="/var/www/html" db:query 'DELETE FROM cron_schedule WHERE scheduled_at < DATE_SUB(NOW(), INTERVAL 1 HOUR)'; echo "magento_cron_cleanup_exit_code $?" > /var/metrics/prometheus/magento_cron_cleanup.prom
#Ansible: Execute the Magento scheduled job runner
* * * * * systemd-cat --identifier=magento_system_cron -- flock --timeout="900" /run/lock/magento_system_cron.lock /usr/bin/php /var/www/html/bin/magento cron:run; echo "magento_system_cron_exit_code $?" > /var/metrics/prometheus/magento_system_cron.prom
same here!
Hello there, I've got the same problem o Magento 2.2.0 when creating one custom cron job. I've also have Magento 2.2.1 installed on different server without any custom cron jobs and cron is working fine, cron_schedule table contains something around 1k records where on 2.2.0 containing one custom cron job have 150k records.
I can see a bunch of PHP processes running, it's killing my 8CPUs server and MySQL:

Each one is eating 0.5GB of memory.
i can totally relate - i have the same issue as described in this thread - any update??
I can confirm I get this issue on 2.2.2 as well!
I can also confirm this on M2.2.2CE (open source).

select count(*) as 'jobs' from cron_schedule where status='pending';
result: 32567 records
This is on an AWS c4.xlarge (4 vCPUs and 7.5GB RAM) and it's impacting performance quite a bit.
I ran with @andrewhowdencom 's approach, but implemented one without any 3rd party dependencies (such as n98-magerun or prometheus)
I created a directory in my magento installation's var directory called cron_cleanup to group everything together ... I also am using a standalone php script to interact with the db. Depending on someone's situation, this might not be acceptable, but it works for me. Also, the actual log that the cron entries create might not server any real purpose as-is for most people, so change them to do what you would like or remove them all together.
#Workaround while upstream bug #11002 is being resolved
*/5 * * * * systemd-cat --identifier=magento_cron_cleanup -- flock --timeout="900" /run/lock/magento_cron_cleanup.lock /usr/bin/php /var/www/magento/var/cron_cleanup/execute.php; echo "magento_cron_cleanup_exit_code $?" > /var/www/magento/var/cron_cleanup/issue-11002.cleanup.log
#Execute the Magento scheduled job runner
* * * * * systemd-cat --identifier=magento_system_cron -- flock --timeout="900" /run/lock/magento_system_cron.lock /usr/bin/php /var/www/magento/bin/magento cron:run; echo "magento_system_cron_exit_code $?" > /var/www/magento/var/cron_cleanup/issue-11002.magentosystemcron.log
My execute.php file is as such:
<?php
require '/var/www/magento/app/bootstrap.php';
$bootstrap = \Magento\Framework\App\Bootstrap::create(BP, $_SERVER);
$objectManager = $bootstrap->getObjectManager();
$resource = $objectManager->get('Magento\Framework\App\ResourceConnection');
$connection = $resource->getConnection();
$tableName = $resource->getTableName('cron_schedule');
$sql = "DELETE FROM {$tableName} WHERE scheduled_at < DATE_SUB(NOW(), INTERVAL 1 HOUR);";
$connection->query($sql);
*make sure the execute.php has execution permissions chmod +x /var/www/magento/cron_cleanup/execute.php
This approach is working for me so far...I'm on CE (Open Source), but on EE (Commerce) there's also the issue of consumers to take into consideration ... so if someone's installation isn't using RabbitMQ, then the Mysql Queue will still be pounded with consumers. Again, all the implementation details here and approach is fine for me, but maybe not for others..YMMV and change it up to work for you.
Hopefully this helps someone, and thanks @andrewhowdencom and @skukla .
2.2.1 also it happens.
- Cron selects all "pending" jobs:
SELECTmain_table.* FROMcron_scheduleASmain_tableWHERE (status= 'pending') - Adds some new ones:
INSERT INTOcron_schedule(job_code,status,created_at,scheduled_at) VALUES ('indexer_update_all_views', 'pending', '2018-01-09 10:17:06', '2018-01-09 10:20:00') - Each selected record updates to "running" status
UPDATEcron_scheduleAScurrentLEFT JOINcron_scheduleASexistingON existing.job_code = current.job_code AND existing.status = 'running' SETcurrent.status= 'running' WHERE (current.schedule_id = '1119') AND (current.status = 'pending') AND (existing.schedule_id IS NULL) - Updates them to "pending" status backward
UPDATEcron_scheduleSETjob_code= 'my_custom_job_cide',status= 'pending',messages= NULL,created_at= '2018-01-08 09:42:03',scheduled_at= '2018-01-08 09:44:00',executed_at= NULL,finished_at= NULL WHERE (schedule_id='1127')
Repeat every minute, we have pretty snowball effect now ;)
I can confirm the same issue with M2.2.2CE
We have heavy magento cron job that works 15 minutes. With this bug, we make a big load on the database.
So now we use a separate php file that configured directly in Linux crontab :)
The way to reproduce this bug:
- Implement "fatal error" in cron job eg.
$this->getNonExistingObject()->doSomething(); - Run cron job, error is thrown and as fatal error is not fetched by
try { .. } catch { ... } - Script just ends its execution immediately
- Job remains 'running' instead marking as done with error
- And then is updated to 'pending' again
- Next cron run tries to execute it again
So as we can see there are main two faults for this situation happen:
- Bad-written cron job method (throwing fatal error in specific conditions)
- Cron jobs handler which is trying to execute again and again until the world ends
@magento-team This is a pathetic bug that is wreaking havoc on our cron. Can you at least respond to this?
@wildcard27
for tempory solution you can use
Ok so we've analyzed this issue and here is what we found:
The problem appear since you have entry in cron_schedule which has status = running and it will never be finished. Usual reason to that might be
- virtual machine terminated
- cron process shutdown
- computer switch off
etc.
Then in Magento\Cron\Model\ResourceModel\Schedule we have method trySetJobUniqueStatusAtomic which will permanently return false for this particular job_code.
That will results in all new cron schedules with the same job_code to be not executed/managed.
They won't be run, they won't be marked as missed and number of these schedules will permantently grow which lead cron:run to work slower and slower.
Solution which i see is that old schedules with status "running" should be marked as "error". I think this lifetime could be configured in admin config.
@magento-team Let me know what do you think about this solution so we can start to think about Pull Request.
I had an issue where mysql/php service was burning 100% CPU, as it seemed that crons were backlogging. Within hours of rebooting the server or restarting the services, everything would come to a stand-still again.
It turned out that a recent composer update had overwritten my .htaccess (something that never occurred to me), thus reducing my memory_limit from 2G to the default value of 756M. Within 2-4 minutes of updating the .htaccess file and clearing out the cron table, my CPU calmed right the way down. Been fine for a couple of weeks now.
Same issue here.
Magento 2.2.2 is killing my server.
100% CPU load -> 8 Cores 2.6
Yes indeed, we are also still seeing this happening in Magento 2.2.2, cronjobs still can end up in the state running forever, which then in turn keeps adding new pending jobs forever and you end up with > 30.000 jobs in the database, until you manually delete them from the table in the database.
@dmanners: I've noticed you have a backport open to fix this in Magento 2.1, but I think you should hold of with that until this gets properly fixed in Magento 2.2, I have the feeling (not scientifically proved) that the state of crons in Magento 2.1.11 is actually better then in 2.2.2 at this point.
Maybe PR #12497 will fix it for good, but I haven't tested it yet.
Cron's are still really a mess and should be fixed rather sooner than later, we have to go into servers a lot lately to fix the state of cronjobs. Even on the Magento Cloud infrastructure we keep running into issues with this.
Same issue here! 150000+ rows in table and growing. Killing the server.
Magento | 2.2.2
Apache | 2.4.29
PHP | 7.0.27
MySQL | 5.6.39-cll-lve
Is this error/bug fixed in 2.2.3?
@jontesamuelsson No this isn't fixed in 2.2.3.
#13775 is in the process of being merged which will reduce the server load when the cron_schedule table grows unbounded, but it does not fix the root cause of this issue, which is the cron_schedule table growing in the first place.
@gwharton Thanks for quick answer. Let's hope the root problem gets fixed soon to :-)
Quick tip for this is described in here: https://alekseon.com/en/blog/post/magento-2-slow-and-cpu-usage-gets-high-this-might-be-the-reason/
And fix itself is here: https://github.com/Alekseon/CleanRunningJobs
Hey @Linek, nice one on the plugin however it's still a core issue with Magento and should be addressed by the developers - this issue has been stagnant for an extremely long time and it's a critical bug.
I'm sure this could be re-worked into a pull request, if it ever gets approved/looked at...
Hi @Jean-PierreGassin
I absolutely agree that it should be fixed in the core however our fix is only workaround. I don’t think that deleting some “running” flow if it’s older than x days is perfect solution.
And if it is, then what should be an x ...
seem i might be getting this issue too in 2.2.2
n98-magerun2 db:query "SELECT * FROM mags_cron_schedule WHERE status='pending';" --skip-root-check | wc -l
428
@centminmod I think you might be ok there actually. Magento schedules cron jobs in batches, so the pending jobs you are seeing there are probably the scheduled jobs for the next 20 minutes or so. This "scheduling ahead" behaviour can be configured in
Stores -> Configuration -> Advanced -> System -> Cron configuration options for group : xxxx -> Schedule Ahead for
and
Stores -> Configuration -> Advanced -> System -> Cron configuration options for group : xxxx -> Generate Schedules every
The default group settings are to schedule the next 20 minutes cron jobs, every 15 minutes. You should find if operating correctly the table should fluctuate in size with the number of pending jobs being somewhere between about 70 and 500 ish. You should see somewhere between 5 and 20 pending items for each cron job depending on when the query is run.
We wrote an extension to fix these bugs, speed up performance, and control the execution of tasks: https://github.com/magemojo/m2-ce-cron
A part of this issue is going to be fixed by #12805 and it's being worked as we speak. Feel free to test the patch and comment on the PR.
Thanks for the help @ericvhileman, is there any plan to move the fixes to the core instead of a separated module?
@miguelbalparda it could be folded into the core, but the extension replaces the cron functionality entirely so would probably need to have the core team approve the undertaking before trying
there's also a few linux specific points of new functionality that would need to be addressed so the 5 or so people running m2 on windows could still have functioning crons
@akellberg comment worked for me
After running the query
delete from cron_schedule where scheduled_at < date_sub(now(), interval 1 hour)
This could also be cause
www>html>var>log>update.log
PHP Memory_limit
[2018-03-20 21:40:02] setup-cron.ERROR: Your current PHP memory limit is 128M. Magento 2 requires it to be set to 756M or more. As a user with root privileges, edit your php.ini file to increase memory_limit.
I ran into this issue on a Magento 2.2.2 Commerce site, even though none of my jobs were getting left in a running state.
- The default Magento CRON groups have a
history_success_lifetimevalue of10080(7 days). With these two CRONs running every minute, if you have ~70 CRON jobs, you can easily end up with hundreds of thousands ofsuccessjobs in the DB. - When the CRON runs, all cron groups configured with
use_separate_process= 1 will all run in parallel. This is not normally a problem—however if thecron_scheduletable has a massive number of records and each of those CRON jobs tries to delete the individual outdatedcron_scheduleentries, you start running into lock wait timeouts. - We had a production server that was using crazy amounts of CPU/memory when the CRON jobs would run (which would lock up the server):

- During the time when the CRON was running, if we ran
SHOW PROCESSLISTin MySQL, we would see that multiple processes were trying to delete the same record from the DB at the same time:

We would also see these errors during this time:
[Zend_Db_Statement_Exception]
SQLSTATE[40001]: Serialization failure: 1213 Deadlock found when trying to get lock; try restarting transaction, query was: DELETE FROM `cron_schedule` WHERE (schedule_id='6594032')
- During these periods, we noticed that the CRON jobs would get backed up, waiting on the previous ones to finish running:

To workaround this issue, we deceased the number of entries in cron_schedule by going into STORES > Configuration > ADVANCED > System and decreasing the "Success History Lifetime" value from "10080" to "1440". Hopefully the #12497 PR will resolve this issue.

Spot the two occurrences of this bug this week. Managed to catch both in time before any damage done. I have the MYSQL DELETE fix setup as a cron job for my live and production stores, but this was a temporary store I installed for some destructive development which didn't have the MYSQL DELETE cron job set up.
Referenced here #15190
and here #4978

Any ETA on the update, is it gonna be in version 2.2.6 ?
That snowball effect is crashing a lot of servers worldwide ;)
Workaround to minimize the impact :
Run the cron with "flock -w 1 cron.lock php bin/magento cron:run" this cron should be run every minute (it's very important because the heartbeat is scheduled every minute in magento like this the table will not be flooded exponentially
No I'm on version 2.2.3, I was preparing an update to 2.2.5 but I didn't see the cron fix in any changelog
@kandy
I'll see after that update
It was done by community in #12497 PR
Also you can apply patches for 2.2.3 from this comment #12497 (comment)
I can confirm that in 2.2.5, certainly in my situation, that cron jobs that crash during execution are now marked as "error" in cron_schedule instead of sitting in the running state. This means that the cron cleanup code now properly deals with these jobs and successive jobs run as planned. Initial testing shows the race condition that allowed the cron_schedule table to grow infinitely in size is now fixed. Closing this issue as fixed. Phew!
Will there be a patch / fix for 2.1.x?
After updating from 2.2.3 to 2.2.5 I have the same Cron issue. The table is growing and I don't know how to proceed.
Yeah, since 2.2.5 ive had it twice so it looks like it isnt fixed. Look for the entry in cron-schedule table that is in the running state and delete that row. Magento will then clean up for you.
My bad, the table have little bit more that 10 000, but I get error
[Magento\Framework\DB\Adapter\DeadlockException]
SQLSTATE[40001]: Serialization failure: 1213 Deadlock found when trying to get lock; try restarting transaction, query was: DELETE FROM cron_schedule WHERE (status = 'missed') AND (job_code in ('currency_rates_update', 'backend_clean_cache', 'visitor_clean', 'catalog_index_refresh_price', 'catalog_product_flat_indexer_store_cleanup', 'catalog_product_outdated_price_values_cleanup', 'catalog_product_frontend_actions_flush', 'catalog_product_attribute_value_synchronize', 'catalogrule_apply_all', 'system_backup', 'security_clean_admin_expired_sessions', 'security_clean_password_reset_request_event_records', 'sales_clean_quotes', 'sales_clean_orders', 'aggregate_sales_report_order_data', 'aggregate_sales_report_invoiced_data', 'aggregate_sales_report_refunded_data', 'aggregate_sales_report_bestsellers_data', 'sales_grid_order_async_insert', 'sales_grid_order_invoice_async_insert', 'sales_grid_order_shipment_async_insert', 'sales_grid_order_creditmemo_async_insert', 'sales_send_order_
emails', 'sales_send_order_invoice_emails', 'sales_send_order_shipment_emails', 'sales_send_order_creditmemo_emails', 'paypal_fetch_settlement_reports', 'outdated_authentication_failures_cleanup', 'expired_tokens_cleanup', 'newsletter_send_all', 'analytics_subscribe', 'analytics_update', 'analytics_collect_data', 'magento_newrelicreporting_cron', 'catalog_product_alert', 'aggregate_sales_report_coupons_data', 'persistent_clear_expired', 'captcha_delete_old_attempts', 'captcha_delete_expired_images', 'aggregate_sales_report_shipment_data', 'sitemap_generate', 'get_amazon_capture_updates', 'get_amazon_authorization_updates', 'amazon_payments_process_queued_refunds', 'aggregate_sales_report_tax_data', 'weltpixel_backend_moduleinfoupdate', 'yosto_arp_rule_apply_all')) AND (created_at < '2018-07-22 12:20:02')
What this means? I didn't have such issues before updating to 2.2.5
So,
I had a lot of pending jobs, deleted manually all of them and everything seems to be ok for day or two, but I started to receive the error like above again.
When I have checked, I had a lot of pending entries again at the end of the table, manually deleted them, for now it's ok
There was another blocking query running at the same time it was doing a delete and it locked the table. Most likely it was the query that it uses to update job statuses. That query always runs long and if there's a several running it deadlocks.
Also is there any good reason why all the job codes need to be called out in that delete?
I see the same behaviour as @AgentGod. Multiple sites start creating deadlock errors after updating to 2.2.5. When I clear the cron_schedule it seems fine for a few days, then it starts again.
I believe I have seen this issue happen with an exception being thrown by dotmailer/dotmailer-magento2-extension. We have used composer patches to prevent the known exception codepath from ever being triggered, but this seems like an issue that will likely cause issues on prod servers (as it did for us, unfortunately) so just trying to bump the priority here.
Where I can find a patch ?
@mpropl You can also try the MageMojo extension. I have used on a couple of installations since recently. It seems to fix these issues as well: https://github.com/magemojo/m2-ce-cron
MageMojo work for me for a while, but now it hangs and does not perform cron tasks :(
MageMojo use file locks, so it will not work on the multinode installation
@kandy you shouldn't be running the cron on multiple nodes. Cron should be scheduled on one node and there is not an issue with file locks.
@mpropl we're going to need more information about your issue if you would like us to help: magemojo/m2-ce-cron#51
@ericvhileman I does not think that use cron service on only one node is high-available solution. Also, this extension requires to run on unix-like OS and have to access to /proc/ filesystem.
@kandy dude... the cron docs LITERALLY say not to do this: "In a multi-node system, crontab can run on only one node. This applies to you only if you set up more than one webnode for reasons related to performance or scalability.". I can also think of many reasons why it's a terrible idea.
Source: https://devdocs.magento.com/guides/v2.2/config-guide/cli/config-cli-subcommands-cron.html
+1 to what @ericvhileman said about running crons only in one node.
@magento-engcom-team Please reopen. This is not resolved.
@Ctucker9233, Can I ask you to create new issues with concrete steps to reproduce? This ticket has many different issues described in the comments, so it hard to understand what concrete issues do you ask to resolve.
@magento-engcom-team Please reopen. This is not resolved. reproduced in 2.2.6
SELECT count() FROM cron_schedule WHERE status='pending';
+----------+
| count() |
+----------+
| 11888 |
+----------+
I can confirm this. Also 11000+ records in the table. One day after I truncated the table. Also 2.2.6
@acurvers @johnny-longneck Can you verify the settings for cron history lifetime is set to 60min, not to 1 week? It configured in SYSTEM CONFIGURATION > ADVANCED > System > Cron (Scheduled Tasks)
I had overwritten previous history lifetime to 740 as recommended somewhere. I switched back to "use global settings" which is now 60. This might seem to have resolved the table overload.
Cron Table now constant at ca. 1000 entries.
@kandy I did but it was closed as a duplicate
@acurvers @johnny-longneck Can you verify the settings for cron history lifetime is set to 60min, not to 1 week? It configured in SYSTEM CONFIGURATION > ADVANCED > System > Cron (Scheduled Tasks)
@kandy Which setting is this? Failure history lifetime?
I have been stuck on this same issue for several weeks. I think I finally got it figured out with the help of this post. I made a quick blog post about it so I can refer to it in the future. https://toweringmedia.com/blog/magento-2-cron-job-pending-jobs-never-cleared-solved/
Same issue in 2.3.3.
After 24 hours on a clean install, the cron table is 4080 lines with 410 jobs pending
Why is this closed when it's an on-going issue?
@vincentteyssier Sounds normal behaviour to me. Default behaviour is every 15 minutes, magento will schedule in the next 20 minutes of cron jobs into the cron_schedule table. These will be in the pending state. Take a look at the times of your pending jobs. Are they all scheduled to run in the next 15 minutes or so. Once run they will change to success/failed status and will eventually be cleared. All of the lifetime timings of cron jobs in the cron_schedule table can be configured in admin config. With a fairly standard setup, you should see the cron_schedule table hover between 1000-4000 entries with a ratio of pending/successful jobs of between 25 and 75% depending on where in the 20 minute cycle you are.
@markojak If you believe this is still happening in 2.3-develop, then please create a new issue.
@gwharton you're right, after 24 more hours it is stable between 4k-4.1k and approx 300 pending
Is this issue actually fixed. I've just had two separate development servers use up over 1 million CPU seconds in a few hours as a result of the magento cron, on a pretty much vanilla installation of Magento 2.3.3 with 30 products and zero activity apart from the cron running
One server had 10000 rows in the cron schedule table and the other had just over 1000 (after I had changed the save history lifetime setting). I'm not sure I'm seeing the same issue that other people see with hundreds of thousands of jobs stacked up in the cron_schedule table so I'm not sure if I need to raise a separate ticket.
In the error logs the high cpu usage seemed to coincide with the database server rebooting and a high memory usage when creating a temporary table.
Looking through this thread it seems to me that the cron module does a huge amount of unnecessary work and it also seems to lack necessary indexes to make its queries fast. For example the clean up of missed jobs looks at the created_at column but this is not indexed so the query has to table scan. You can see how the cron grinds to a halt once the table gets large. Doesn't look like this is my problem though.
On further investigation it appears that my problem of excessive cpu usage is due to a bug in magento queue consumer logic in 2.3 that means they never complete. see #17951
Probably not fixed. M2 devs loves to close issues because they are "task oriented" and have to fill their daily quota of finished tasks (without actually fixing anything).
However this problem is still present and we are having increase CPU usage over time with cronjobs and mysql slow queries.
I've not seen this specific bug in a long time on my production install. Currently on 2.3.3.
Please raise a new issue with full steps to reproduce if problem still persists for you.
Still a problem at least in 2.3.0
Still a problem in 2.3.4:
MariaDB [db]> SELECT count(*) FROM cron_schedule WHERE status='pending';
+----------+
| count(*) |
+----------+
| 261 |
+----------+
1 row in set (0.007 sec)
@zzvara see above comment #11002 (comment)
261 is within normal range - I'd suggest monitoring this over time to see if this increases.
I'm not sure. Magento is already using 12/24 cores constantly. I'll post more data for you to tackle down the problem. We are using Kubernetes and HelmReleases, it should be fairly easy to reproduce.
Not much is running on that Kubelet node, but Magento is using 12/24 cores.

The site itself has become incredibly slow as well. These CRON jobs are running all the time. They are all on default values of 2.3.4.
We are using the following deployment: https://github.com/bitnami/charts/tree/master/bitnami/magento
The following Dockerfile that contains all plugins:
FROM bitnami/magento:2.3.4-debian-10-r12
USER root
RUN apt update
RUN apt install wget -y
RUN apt install rsync -y
RUN apt install vim -y
ENV COMPOSER_MEMORY_LIMIT -1
# This is the home directory of Magento.
WORKDIR /opt/bitnami/magento/htdocs
ADD auth.json .
RUN chown bitnami:daemon auth.json || exit 1
USER bitnami:daemon
RUN composer require mageplaza/module-core
RUN composer require mageplaza/module-smtp
RUN composer require mageplaza/module-gdpr
RUN composer require mageplaza/magento-2-social-login
RUN composer require dhl/module-rates-express
RUN composer require mageplaza/magento-2-hungarian-language-pack:dev-master
COPY extensions/geo-ip-redirect-1.3.0-CE/app/code/Amasty /opt/bitnami/magento/htdocs/app/code/Amasty
USER root
RUN chown -R bitnami:daemon app
RUN chown -R bitnami:daemon pub
RUN find /opt/bitnami/magento/htdocs -type d -print0 | xargs -0 chmod 775 && find /opt/bitnami/magento/htdocs -type f -print0 | xargs -0 chmod 664 && chown -R bitnami:daemon /opt/bitnami/magento/htdocs
Dockerfile is frequently rebuilt and the container therefore restarted.
Here is the entry point:
echo "Adding Magento core cron entries."
ln -sf /opt/bitnami/magento/conf/cron /etc/cron.d/magento
/usr/sbin/cron
echo "Running upgrade on Magento."
sudo -u bitnami php -d memory_limit=4096M /opt/bitnami/magento/htdocs/bin/magento setup:upgrade -vvv || true
echo "Running compile on Magento."
sudo -u bitnami php -d memory_limit=4096M /opt/bitnami/magento/htdocs/bin/magento setup:di:compile -vvv || true
echo "Running deployment on Magento sources."
sudo -u bitnami php -d memory_limit=4096M /opt/bitnami/magento/htdocs/bin/magento setup:static-content:deploy -f -vvv || true
echo "Install and start Cron."
sudo -u bitnami php bin/magento cron:install || true
echo "Maybe adding custom cron entries."
if [ -f "/opt/bitnami/magento/htdocs/custom-cron-entries" ]; then
echo "Found custom cron entries, so adding it to 'crontab -e'."
echo "Custom cron entries are: "
cat /opt/bitnami/magento/htdocs/custom-cron-entries
runuser -l bitnami -c '(crontab -l 2>/dev/null; cat /opt/bitnami/magento/htdocs/custom-cron-entries) | crontab -'
fi
echo "Starting Apache..."
exec httpd -f /opt/bitnami/apache/conf/httpd.conf -D FOREGROUND
root@magento-788c7d54f-kxkx4:/opt/bitnami/magento/htdocs# cat /etc/cron.d/magento
* * * * * bitnami /opt/bitnami/php/bin/php /opt/bitnami/magento/htdocs/bin/magento cron:run
* * * * * bitnami /opt/bitnami/php/bin/php /opt/bitnami/magento/htdocs/update/cron.php
* * * * * bitnami /opt/bitnami/php/bin/php /opt/bitnami/magento/htdocs/bin/magento setup:cron:run
root@magento-788c7d54f-kxkx4:/opt/bitnami/magento/htdocs# cat /opt/bitnami/magento/htdocs/custom-cron-entries
0 1 * * * redacted_copy_backups_to_remote_server.sh
@marthasimons7777 Can I suggest you upgrade to supported version of Commerce where this issue is resolved?