AWS Glue Elastic Views enables you to replicate data across multiple AWS data stores to use with your applications without having to write custom code. With Elastic Views, you use Structured Query Language (SQL) compatible PartiQL queries to quickly create a view of the data you want to replicate from a different data store. Based on the view you create, Elastic Views replicates data from the source data store, and lets you materialized the view in a target data store.
As on today, Only DynamoDB is supported as the source and we can chose between three different destinations: S3 or ElasticSearch or Redshift.
 Image Credit: AWS Docs
Image Credit: AWS Docs
This means, you can query your DynamoDB table with SQL like querying in(Athena/Redshift) or use the power of full text search offered by Elasticsearch. You can also extend this data by enriching it with data from other sources. Say for example, orders data in DynamoDB can be combined along with customer profile from another datastore.
As of now(Q1 2021) this service is in preview. That means lots of new functionality will get added in the future and any limitations mentioned in those post may be removed in future.
In this demo, lets us see how we can materialize data from DynamoDB to S3 and query them using Athena.

-
Let us a single region for all our resources - For example
us-east-1-
DynamoDB Table: We want to start with a very simple table that will have movies data. You can use the instruction provided in AWS Docs1. Let us call this table
ev-demo-movies-tablePrimary Key/Partition Key-yearand type asNumberSort Key-titleand type asString
I have included some sample data, in this repo under the directory
sample_data/movie_data_01.json. Ingest this data to the table. We will use this data to materialize in S3 later -
S3 Bucket: Setup a bucket in the same region as the table. Let us call this bucket
ev-demo-bkt-010 -
IAM Role for Elastic Views: We need a IAM role for Glue Elastic Views to write to our S3 bucket and a trust policy to allow the service to assume our role. Let us call this role
ev-demo-roleHere is the policy that you will need, do not forget to change the bucket name
YOUR_BUCKET_NAME_GOES_HEREthe target prefix nameYOUR_TARGET_PREFIX_NAME_GOES_HERE{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::YOUR_BUCKET_NAME_GOES_HERE" }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::YOUR_BUCKET_NAME_GOES_HERE/YOUR_TARGET_PREFIX_NAME_GOES_HERE/*" } ] }Likewise here is the trust policy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "materializedviews.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
-
-
As of Q1 2021, you need to request preview access to Glue ElasticViews
-
Source Configurations: DynamoDB
- AWS Console > Elastic Views > https://console.aws.amazon.com/elasticviews
- Choose Tables
- In the tables list, choose the link to the ev-demo-movies-table.ev-demo-movies-table table.
- On the table summary page, choose ACTIVATE. This operation can take a few minutes to complete.
- My assumption is that a Kinesis Data Streams for DynamoDb is being setup in the background
-
Create View
- AWS Console > Elastic Views > https://console.aws.amazon.com/elasticviews
- Choose Tables
- In the tables list, choose the link to the ev-demo-movies-table.ev-demo-movies-table table.
- View Name - For example
ev-demo-view-s3 - Provenance -
year, title - In Query editor, specify,
SELECT CAST(year AS int4), title FROM ev-demo-movies-table.ev-demo-movies-table; - Choose Create view
-
Start View
- AWS Console > Elastic Views > https://console.aws.amazon.com/elasticviews
- Choose Views
- In the views list, choose the link to the ev-demo-view-s3 view
- On the view summary page, choose ACTIVATE
-
Materialize View
- AWS Console > Elastic Views > https://console.aws.amazon.com/elasticviews
- Choose Views
- In the views list, choose the link to the ev-demo-view-s3 view
- On the view summary page, choose Materialize View
- Choose Materialize a view using AWS Glue EV
- Choose Add target
- On the Add target page, choose S3 as the target service > Target location,
- Location for materialized view >
s3://ev-demo-bkt-010 - For encryption use default encryption
- For Permission, choose the role we created earlier >
ev-demo-role
- Location for materialized view >
- Target Name > enter moviespath
- Elastic Views creates this folder in this location, and places the Parquet files and the manifest there when it materializes the view.
- Choose Add target > Verify Data type compatibility is without any errors.
- After all data types are compatible, choose Materialize view to finalize the materialization.
After a few minutes check the S3 bucket prefix path
moviespath, you will find parquet files -part-00000-1303f-25cd-4670-a16b-49e29-c000.snappy.parquetand the manifest file -
Query Materialize View
We will use Athena to query our data in S3. Let us begin by creating a database and table to query the movies.
-
Access Athena Console > Query Editor >
CREATE DATABASE ev-demo-movies-db;
-
Create an external table in Athena, and configure it to point to your Amazon S3
CREATE EXTERNAL TABLE ev-demo-materialized-table( title STRING, year INT ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://ev-demo-bkt-010/moviespath/_symlink_format_manifest/'
-
Query the table
select * from ev-demo-materialized-table limit 10;
At this point, we have materialized view working.
-
-
-
Let us try to insert a new item into the source DynamoDB table. In my example, I added a item with
titleasev_demoandyearas2021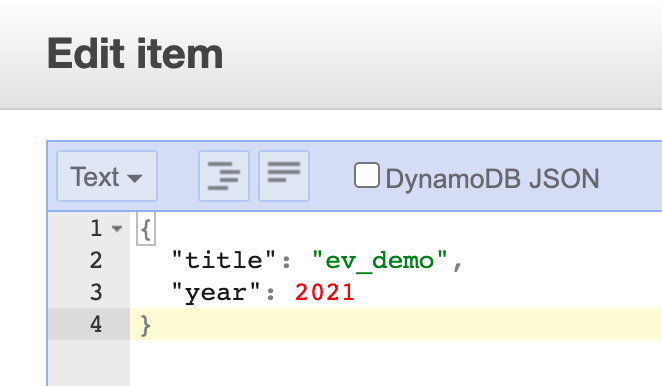
Wait for about a minutes and rerun the query on the materialized view, and check for the corresponding new item in the Amazon S3 target data store. Changes you make to relevant data at the source appear in the target in near-real time. If you don't see the changes immediately, try running the query again.
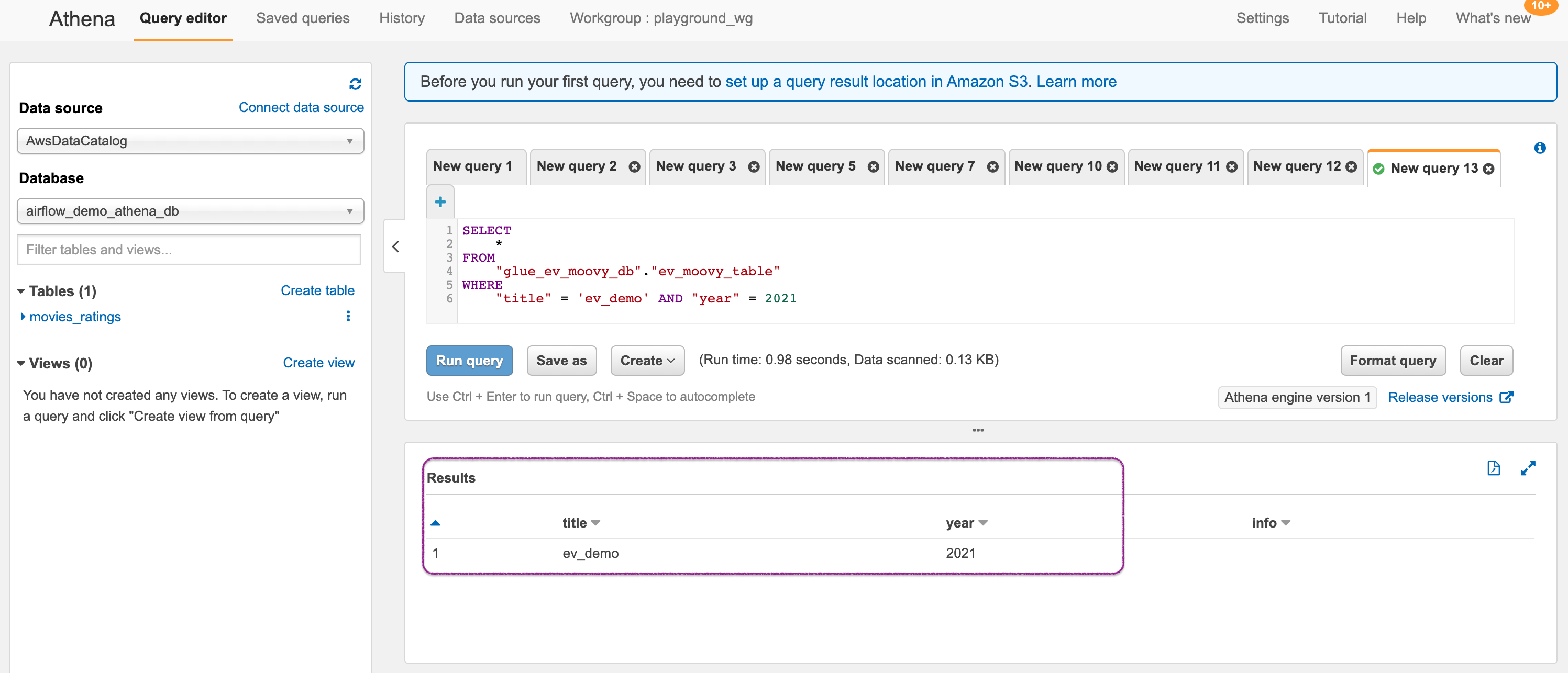
You can observe that the new items can be queried from the materialized view in S3.
-
Here we have demonstrated how to use Glue Elastic view to materialize views from DynamoDB to S3. You can extend this further by enriching the item with data from other sources using Glue workflows.
-
If you want to destroy all the resources created by the stack, Execute the below command to delete the stack, or you can delete the stack from console as well
- Resources created during Deploying The Application
- Delete CloudWatch Lambda LogGroups
- Any other custom resources, you have created for this demo
# Delete from cdk cdk destroy # Follow any on-screen prompts # Delete the CF Stack, If you used cloudformation to deploy the stack. aws cloudformation delete-stack \ --stack-name "MiztiikAutomationStack" \ --region "${AWS_REGION}"
This is not an exhaustive list, please carry out other necessary steps as maybe applicable to your needs.


This repository aims to show how to use Glue Elastic view to materialize views to new developers, Solution Architects & Ops Engineers in AWS. Based on that knowledge these Udemy course #1, course #2 helps you build complete architecture in AWS.
Thank you for your interest in contributing to our project. Whether it is a bug report, new feature, correction, or additional documentation or solutions, we greatly value feedback and contributions from our community. Start here

Level: 200