Add API to convert Unicode string to X52 code page
Closed this issue · 6 comments
A nice to have is an API to convert any Unicode or UTF8 string to the code page supported by the X52 Pro - the display character map is shown below
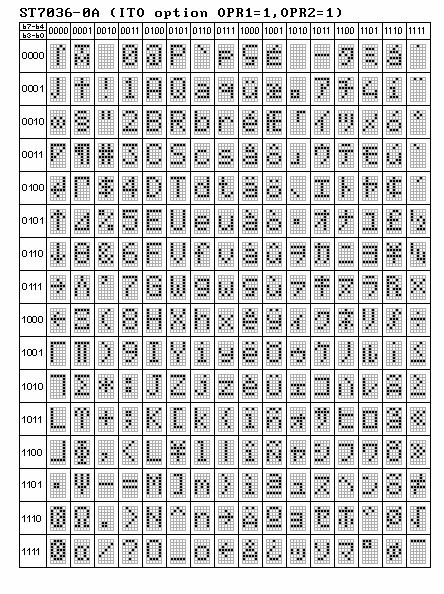
However, I'm having trouble deciphering the Kana characters in the above map - I think I have something, based on comparing the glyphs with that on the Wikipedia Katakana page, but since I don't read Japanese, I'm sure whatever I've come up with is wrong.
I thought Saitek was British/England based hardware? Instead the Saitek lower-level hardware is based on the embedded Japanese character set?
Well any ways after the past year, I myself, moved back to using explicitly only ASCII on my own computers because I do not use any non-ASCII characters within any file names, nor any files. I also experienced some anomalies while using some manufacturers' hardware using the FAT32 file system. Upon any non-ASCII character within the file name, the hardware would hard reset.
It maybe best to stick with what you do know, and omit guessing on what you do not know. (ie. Engineer the ASCII, but leave a good example for any Japanese fluent people to engineer themselves.) I know some Japanese, but not enough to read these Japanese glyphs! Obviously the ASCII set is there. What's interesting is I have some radio equipment with it's own embedded character set as well. Some of those ST7036-0A chars remind me of Commodore 64 characters. (ie Graphical characters in the far left first column.)
That does make sense, and I have an idea, though I need to flesh it out further. In the meantime, can you check if the MFD displays characters 0x00 through 0x07? On my unit, these all display as blank, so I think it might be a firmware issue, but I'm not sure if it's isolated to my unit or if it's potentially a global issue. The rest of the characters seem to match fine though on my unit.
Will do when I get time, likely tonight. Yup, seems to always be a random quality issue somewhere with these controllers.
I'm guessing I need to hack the code to specify hex addressed characters? (Escaping the address for "$ ./x52cli mfd 1 \0x01" doesn't seem to work.
As I'm thinking, the "x52cli mfd" should be able to handle hex value too? But back to reality, I'm guessing I need to augment the libx52_set_text function within libx52/src/x52_mfd_led.c file.
Here's another tip with your libx52 and the MFD display. When the libx52 is initially loaded, display
Line 0: uname (ie. Some shortened version as we're limited to screen $length without scrolling.)
Line 1: libx52-$version
Line 2: $date (ie. Mon Dec 7 12:14:59 EST 2015)
As far as the x52_test, might want to decrease the time delay between testing each brightness value, so the test only lasts five to 10 seconds, or some reasonable time period.
Also, does the X52 Pro contain a ST7036-0A chip? If so, shouldn't mention of this chip be made within the doc/ folder or README?
For hex characters, try using printf as follows. The only character you can't display is 0x00, because that's treated as a null terminator.
./x52cli mfd 1 "$(printf '\x01\x02...')"
I'm hesitant to have the library itself write anything to the MFD - that should be the prerogative of the application.
x52test is kind of a complete test suite to ensure that it checks every possible field, but I'll look into allowing the user to run select tests.
For the ST7036-0A, I actually found the character map on some forum a few years ago, and never thought again about it. Now that I think about it, and based on the ST7036-0A datasheet, it looks like the X52 Pro has configured the ST7036-0A chip to treat the first 8 characters as user configurable glyphs, although I'm not aware of any vendor command that will update the glyphs.
Now that's a nice command line example to note within the docs! Example: x52cli mfd 1 "$(printf '\x41\x42\x43...')"
x01-x07 displayed no characters.
x08 displays the left arrow character.
That seems to line up with my theory - the ST7036-0A is configured to load the first 8 characters from CGRAM instead of CGROM.