FYI: Language detector Lingua outperforming Optimaize
Opened this issue · 4 comments
Hello everyone who is reading this. I hope it is okay to open this issue as GitHub does not provide a better way of communication. If not, then feel free to delete this issue again.
I'm the developer of a competing language detection library called Lingua that clearly outperforms Optimaize's library. If you are looking for an accurate and regularly updated language detection library for the JVM that knows how to deal with both short and long text, then please give Lingua a try.
https://github.com/pemistahl/lingua
Please be assured that it is not my intention to offend this library's owner in any way. Some of you might say that I'm impudent to promote my own project here. However, as I come here and look at the newly created issues on a regular basis, I encounter that people do not seem to be aware that there are alternatives to Optimaize's library here on GitHub. They ask questions here whether this project is still maintained (it is not, obviously). Instead, they could simply use a proper one such as mine. Maybe you did not find it on Google or searched only for Java-based projects (mine has been implemented in Kotlin).
Just take a look at the comparison chart below. Optimaize's library is the worst among all language detection libraries that run on the JVM. If you want to spend your time on improving Optimaize's project, then it's perfectly fine. But if you are simply looking for good language detection, then please choose one of the alternatives. They exist. Thank you for your attention.
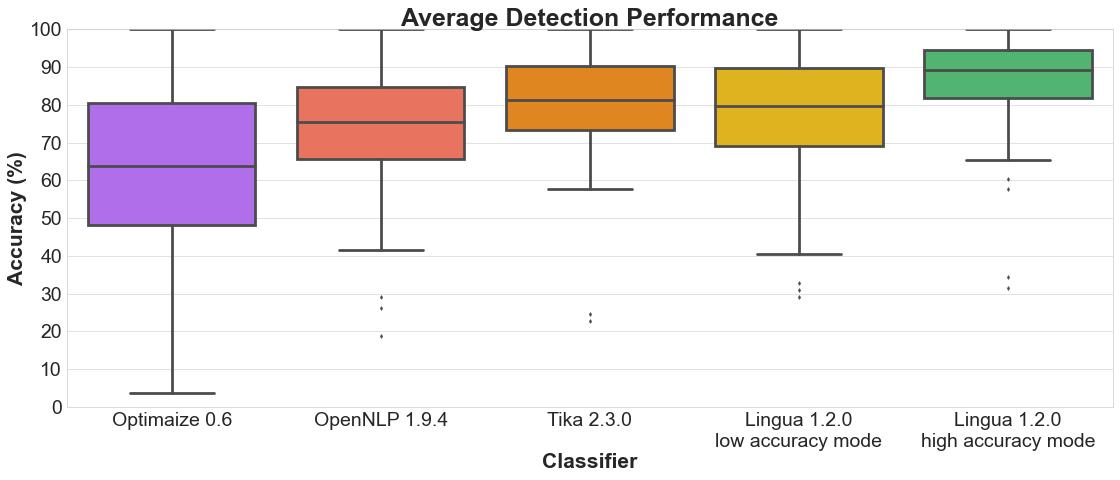
Thanks for the post, Peter. Is maven build planned in the near future?
@vvmar No, I switched from Maven to Gradle because it is much more flexible. Why is Maven important for you? You can simply add my library as a dependency to your Maven-based projects if that is your actual question.
Thanks. I will try it as a maven dep first.
Did a handful of comparisons for CJK, and Lingua was much more accurate than Optimaize. I tried detection on some text in Optimaize issues to demonstrate: