![]()





FedHKG为联邦异构知识图谱划分的工具箱,旨在提供为联邦场景下的知识图谱提供Non-IID的划分算法实现。在联邦场景下,
由于我们这里的本地知识图谱

其中在确定关系划分部分,我们选择随机地将关系
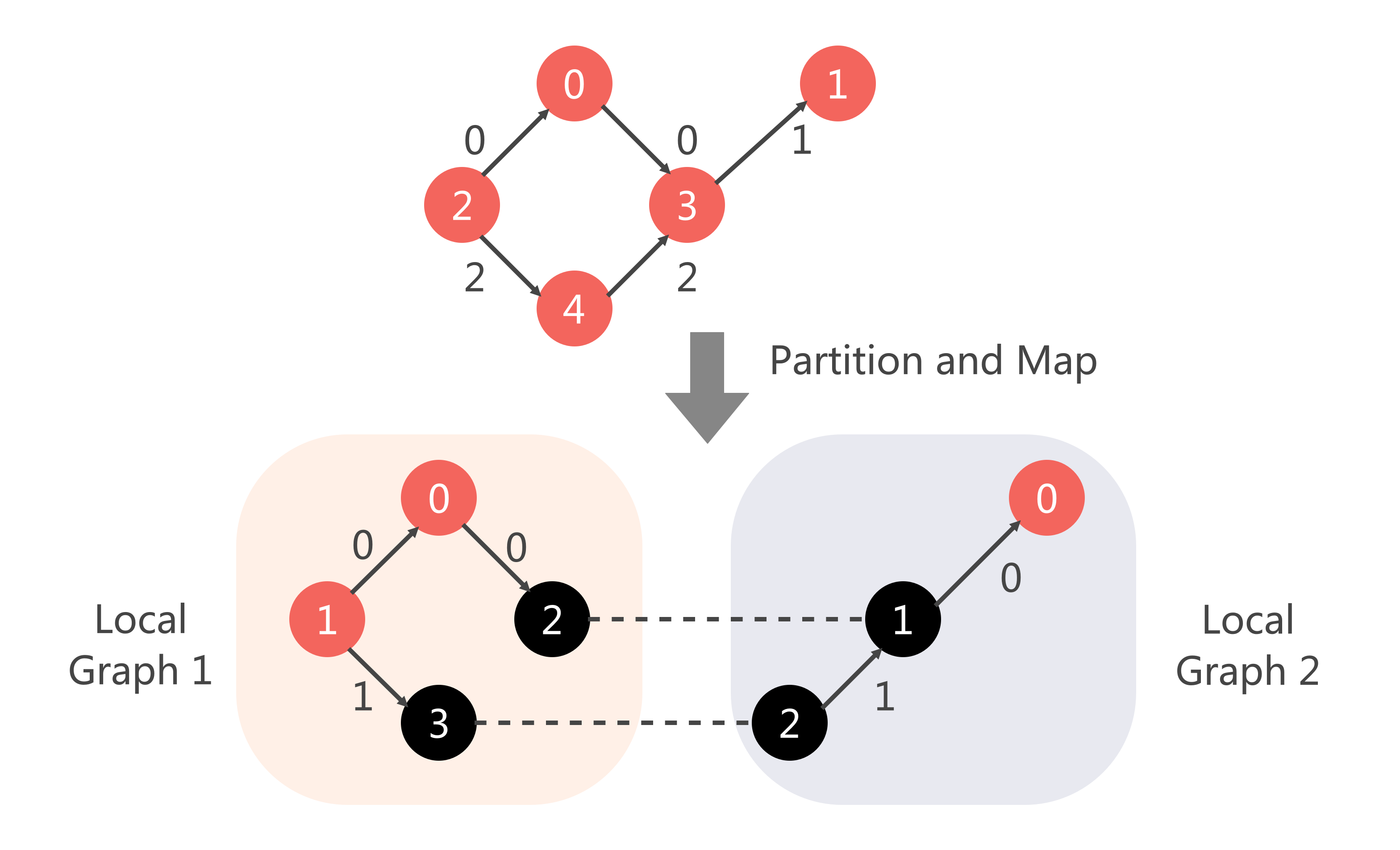
对于具体的局部索引如何安排,我们采用随机选择的方式。最后,进入训练、验证、测试集拆分部分,即还需要在本地划分训练集、验证集和测试集。数据集划分完毕之后,则训练/验证/测试集对应的实体(edge_index)和关系类型(edge_type)就都确立了。
我的Python版本为3.9.13 ,numpy版本为1.24.2
数据集我已经将其上传到了Google drive,大家可自行下载并放在项目目录中的benchmarks目录下。下载链接可参见:
您可以先cd openke进入到openke目录,然后在运行make.sh编译脚本
cd openke
bash make.sh x86注意,你如果是x86架构(大部分Linux服务器)请传入x86参数。如果你是M1芯片的Mac,请将参数修改为apple-m1。
如果编译成功,你会看到生成openke/release目录,且该目录下有个Base.so动态运行库文件。
之后,再运行main.py来生成联邦异构知识图谱数据集:
python main.py \
--dataset FB13 \
--n_clients 10 \
--train_frac 0.8 \
--valid_frac 0.2 \
--seed 42这里--dataset参数用于指定知识图谱数据集,可选的包括FB13、FB15K、FB15K237、NELL-995、WN11、WN18、WN18RR、YAGO3-10;--n_clients用于指定客户端的个数;--train_frac用于指定训练集所占的比例,--valid_frac用于指定在训练集中划分出验证集的比例。--seed为随机数种子。
数据集划分算法完毕后,可以在data目录下看到所乘车的联邦异构数据集文件。比如FB13-Fed10.pkl文件就是在FB13数据集和10个客户端的设置下所生成的联邦异构数据集。你可以使用pickle模块对其对其进行加载,并查看其一些统计量信息:
In [1]: import pickle
In [2]: import collections
In [3]: all_data = pickle.load(open('data/FB13-Fed10.pkl', 'rb'))
In [4]: all_data[0]['train']['edge_type'].shape
Out[4]: (18500,)
In [5]: all_data[0]['train']['edge_type_ori'].shape
Out[5]: (18500,)
In [6]: dict_ = dict(collections.Counter(all_data[0]['train']['edge_type']))
In [7]: dict_origin = dict(collections.Counter(all_data[0]['train']['edge_type_ori']))
In [8]: sorted(list(dict_))
Out[8]: [0]
In [9]: sorted(list(dict_origin))
Out[9]: [4][1] Chen M, Zhang W, Yuan Z, et al. Fede: Embedding knowledge graphs in federated setting[C]//The 10th International Joint Conference on Knowledge Graphs. 2021: 80-88.