Elistimator is a different take on the TensorFlow's Estimator implementation. The Elistimator is a class wrapper for model training, evaluation and prediction that aims to save developing time by abstracting the heavy lifting and common tasks usually associated with developing.
- Setup Elistimator once and call
.train()/.validate()to create the standard train/validate loops. After each call control is back with the user for easy implementation of things like Snapshot Ensembling or early stopping - Verbosity during training with time evaluations and metrics.
- TensorBoard logs are automatically generated for metrics and loss and supports custom visualizations seamlessly
- Predicting never been easier. Elistimator automatically infers the input tensors and lets you interact with them directly so exploring model behavior is a simple task
- Saving and restoring, recovery from an unplanned stopped training session won't be a problem
While Elistimator abstracts many operations, it is not for the TensorFlow newbie. It gives you at any time full access to the session and the graph and relies heavily on tf.data.Datasets.
Elistimator aims to save time for the adept TensorFlow developer.
Elistimator usage demonstration will be using the MNIST data (pip install mnist), and the model taken from the TensorFlow official tutorials
Reading through the usage, the reader should assume that every code block is following the one before it unless stated otherwise.
Most of the code from this section can be found at the mnist_example.py file.
Before actually using the Elistimator, we need two main things; (1) input function(s) and a (2) model function.
While the Elistimator only obligates the training input function, we will using the optional validation input function for a standard training/validation loop.
All input functions must be functions that accept no argument, and return a tf.data.Dataset instance. Make sure you define the batch size and optionally the prefetch amount for optimization when running on GPUs.
If you are going to use any mapping functions, padding etc. make sure you include them in the input function code.
With the MNIST data, the input functions:
from elistimator.elistimator import Elistimator, TrainSpec, EvaluationSpec, PredictSpec
import tensorflow as tf # pip install tensorflow_gpu
import mnist # pip install mnist
import numpy as np # pip install numpy
# Load train images and labels
train_images = mnist.train_images()
train_images = train_images.reshape(
(train_images.shape[0], train_images.shape[1] * train_images.shape[2])) # Flatten
train_images = train_images.astype(np.float32)
train_labels = mnist.train_labels()
train_labels = train_labels.astype(np.int32)
# Load test images and labels
test_images = mnist.test_images()
test_images = test_images.reshape((test_images.shape[0], test_images.shape[1] * test_images.shape[2])) # Flatten
test_images = test_images.astype(np.float32)
test_labels = mnist.test_labels()
test_labels = test_labels.astype(np.int32)
# Parameters dictionary
params = {
'img_height': 28,
'img_width': 28,
'batch_size': 56,
'epochs': 5}
# Input functions
train_input_fn = lambda: \
tf.data.Dataset.from_tensor_slices({'images': train_images, 'labels': train_labels})\
.batch(params['batch_size'])\
.prefetch(params['batch_size']).shuffle(buffer_size=1000)
validation_input_fn = lambda: \
tf.data.Dataset.from_tensor_slices({'images': test_images, 'labels': test_labels})\
.batch(params['batch_size'])\
.prefetch(params['batch_size'])By using lambda we created the dataset retrieval functions.
Next, we need to prepare our model function. Model functions are functions that accept 3 arguments:
data- A dictionary which is fed using the dataset from the input functions. In this example,datawill be a dictionary of two keys,xandyas defined in our input functions and will havebatch_sizeentry in eachis_training- A booleantf.placeholderto indicate the model's mode (training or not)params- A Pythondictwhere the developer can store parameters that will be available for the model code.
Model functions must return 3 values:
elistimator.TrainSpec- A class that points to the loss tensor as well as to the training opelistimator.EvaluationSpec- Optional. A class that points to the loss tensor and holds the evaluation metrics. Even though optional, it is highly recommended to use this since it will allow the developer to use a validation set during training and run evaluation once model is trainedelistimator.PredictSpec- Optional. A class that holds all the outputs of the network. Even though optional, it is highly recommended to use this since it will allow the developer to predict with ease either in batches or one-offs
Since the model function must return 3 values, if you choose not to use any of the optional return values, pass None in their place.
Let's go ahead and implement the model function
def cnn_model_fn(features, is_training, params):
input_layer = tf.reshape(features['images'], [-1, params['img_width'], params['img_height'], 1])
# Convolutional Layer #1
# Computes 32 features using a 5x5 filter with ReLU activation.
# Padding is added to preserve width and height.
# Input Tensor Shape: [batch_size, 28, 28, 1]
# Output Tensor Shape: [batch_size, 28, 28, 32]
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #1
# First max pooling layer with a 2x2 filter and stride of 2
# Input Tensor Shape: [batch_size, 28, 28, 32]
# Output Tensor Shape: [batch_size, 14, 14, 32]
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Convolutional Layer #2
# Computes 64 features using a 5x5 filter.
# Padding is added to preserve width and height.
# Input Tensor Shape: [batch_size, 14, 14, 32]
# Output Tensor Shape: [batch_size, 14, 14, 64]
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #2
# Second max pooling layer with a 2x2 filter and stride of 2
# Input Tensor Shape: [batch_size, 14, 14, 64]
# Output Tensor Shape: [batch_size, 7, 7, 64]
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Flatten tensor into a batch of vectors
# Input Tensor Shape: [batch_size, 7, 7, 64]
# Output Tensor Shape: [batch_size, 7 * 7 * 64]
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
# Dense Layer
# Densely connected layer with 1024 neurons
# Input Tensor Shape: [batch_size, 7 * 7 * 64]
# Output Tensor Shape: [batch_size, 1024]
dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)
# Add dropout operation; 0.6 probability that element will be kept
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=is_training)
# Logits layer
# Input Tensor Shape: [batch_size, 1024]
# Output Tensor Shape: [batch_size, 10]
logits = tf.layers.dense(inputs=dropout, units=10)
predictions = {
# Generate predictions (for PredictSpec and EvaluationSpec)
"classes": tf.argmax(input=logits, axis=1),
# Add `softmax_tensor` to the graph. It is used for PredictSpec.
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
predict_spec = PredictSpec(output=predictions)
# Calculate Loss (for both TrainSpec and EvaluationSpec)
loss = tf.losses.softmax_cross_entropy(onehot_labels=tf.one_hot(features['labels'], depth=10), logits=logits)
# Configure the Training Op (for TrainSpec)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
train_spec = TrainSpec(loss=loss, train_op=train_op)
# Add evaluation metrics (for EvaluationSpec)
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=features['labels'], predictions=predictions["classes"])}
eval_spec = EvaluationSpec(loss=loss, eval_metric_ops=eval_metric_ops)
return train_spec, eval_spec, predict_specOnce the model function and input functions are ready, the Elistimator does all the rest of the work for us. Lets make an instance of an Elistimator, and set it up for training. To get to know the Elistimator better we will also add some extra functionality - we will choose to save a maximum of 3 checkpoints (default to 5) and restrict the GPU usage to 50% only.
# 50% GPU restriction
session_args = {'config': tf.ConfigProto(gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.5))}
# Create the Elistimator instance
estimator = Elistimator(model_fn=cnn_model_fn,
params=params,
session_args=session_args)
# Setup
estimator.setup(train_input_fn=train_input_fn,
validation_input_fn=validation_input_fn,
train_saver_args={'max_to_keep': 3}) # Save maximum of 3 checkpointsThe Elistimator constructor takes 4 arguments:
model_fn- The model functionmodel_dir- Optional, directory to store model in - if not supplied uses a temporary directory.params- Optional, parameters dictionary that will be passed to the model functionsession_args- Optional, arguments to be passed on to thetf.Session
Take note that train_saver_args accepts any arguments acceptable by tf.train.Saver.
Now we have a estimator ready for training.
Next we run a train and validation loop, saving a checkpoint after each of the validation rounds
# Train and validation loop
for _ in range(params['epochs']):
estimator.train().validate()
estimator.save_ckpt()Let's understand better what is going on here.
When calling the train() the returned value is the estimator itself, so we can chain calls to it like we do here with the validate() method right after.
The validate() method return a dictionary of all the metrics assigned to the EvaluationSpec, since in our example we saved the accuracy metric, each validate() call will return a dict that will contain the accuracy of this validation round - {'accuracy': 0.9779, 'loss': 0.099933796} for example.
Lastly the save_ckpt() invokes the tf.train.Saver and saves a checkpoint, this method returns the return value of tf.train.Saver.save.
During training, a progress bar will be displayed. Since Elistimator does not know how long is the input, it will show a progress bar with a time estimation from the second train()/validate() call and forward. On the first call only progress (without time estimation) will be displayed:
Training (1): 1072it [00:05, 196.23it/s, loss=0.039297]
Validation: 179it [00:00, 359.25it/s]
accuracy=0.9682 loss=0.099933796
Training (2): 100%|█████████| 1072/1072 [00:04<00:00, 226.56it/s, loss=0.040465]
Validation: 100%|████████████████████████████| 179/179 [00:00<00:00, 392.63it/s]
accuracy=0.9779 loss=0.07041411
Training (3): 100%|█████████| 1072/1072 [00:04<00:00, 233.39it/s, loss=0.009604]
Validation: 100%|████████████████████████████| 179/179 [00:00<00:00, 419.40it/s]
accuracy=0.9812 loss=0.057436574
Training (4): 100%|█████████| 1072/1072 [00:04<00:00, 238.72it/s, loss=0.007166]
Validation: 100%|████████████████████████████| 179/179 [00:00<00:00, 417.53it/s]
accuracy=0.9832 loss=0.052273564
Training (5): 100%|█████████| 1072/1072 [00:04<00:00, 229.07it/s, loss=0.001529]
Validation: 100%|████████████████████████████| 179/179 [00:00<00:00, 370.69it/s]
accuracy=0.9839 loss=0.04783208
Notice that after each validation, the metrics passed to EvaluationSpec will be displayed also.
Lets examine what the Elistimator has stored for us for now.
Elistimator has a model_dir member, if we run print(estimator.model_dir) we can see where all the related files are stored (if you supplied model_dir to the Elistimator constructor - this will be it).
After the train/validate loop the contents of this directory would be something like:
.
├── checkpoints
│ ├── checkpoint
│ ├── elistimator_meta
│ ├── model_iter-3216.data-00000-of-00001
│ ├── model_iter-3216.index
│ ├── model_iter-3216.meta
│ ├── model_iter-4288.data-00000-of-00001
│ ├── model_iter-4288.index
│ ├── model_iter-4288.meta
│ ├── model_iter-5360.data-00000-of-00001
│ ├── model_iter-5360.index
│ └── model_iter-5360.meta
├── train
│ └── events.out.tfevents.1549100159.fabf6e6ba5bc
└── validation
└── events.out.tfevents.1549100160.fabf6e6ba5bc
The checkpoints directory holds all the outputs tf.train.Saver - notice there are only 3, since we have chosen to keep a maximum of 3 checkpoints.
The train / validation directories hold the TensorBoard logs, so if you launch TensorBoard with the logdir pointing at the parent directory of the model directory, you will see the following output:
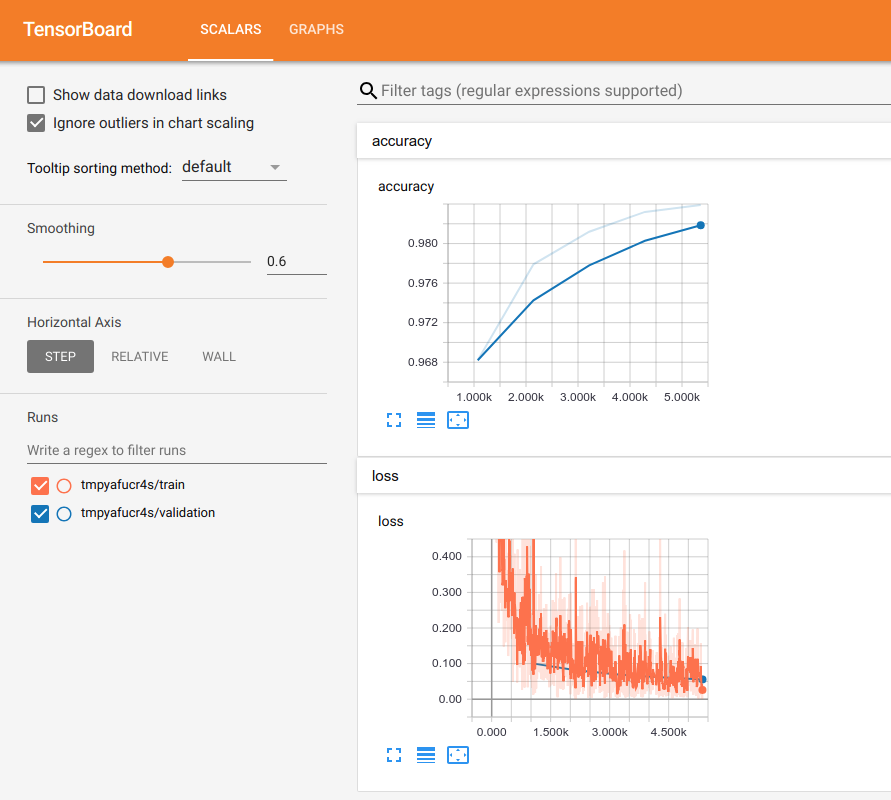
Once we have a trained Elistimator, we can use the predict() method.
We can use predict() with the input function interface, or with one-offs predictions
When using input functions, the predict() will return a Python generator, so we could process prediction in batches (depending on the batch size defined in the input function).
For example, using input function prediction call would look something like follows
# Predicting using an input function
all_predictions = []
for p in estimator.predict(input_fn=validation_input_fn):
all_predictions.append(p)Each p will a dictionary with entries according to the PredictSpec, where each entry contains batch outputs.
In our case, it will look like {'classes': [...], 'probabilities': [...]} where each array length corresponds to the batch length.
For a more granular prediction, we might want to predict very specific entries.
When first setting up the Elistimator, it stores the input signature (which are the outputs of the dataset).
Since our input functions have the 'images' key, the Elistimator can now accept it as a key-word argument for the .predict() method.
For predicting only the first image:
# Predicting using one-off predictions
prediction = estimator.predict(images=test_images[:1]) # Predict single imageWhere prediction will hold exactly the same information as p from the Using input functions section, but with only one entry per key. In this case the predict method will return a dictionary and not a generator like with input functions.
*Notice since the model expects to get a rank 2 tensor as input, passing test_images[0] will not work since its shape is (, 784), passing test_images[:1] will have a shape of (1, 784) which has rank 2.
Just like training evaluation also uses input functions. The evaluate() method will return all the metrics that were stored in the EvaluationSpec.
So if we call:
# Evaluating
evaluation = estimator.evaluate(input_fn=validation_input_fn)The evaluation variable will hold a dictionary like {'accuracy': 0.9779}.
Elistimator can restore previous states, using the checkpoints saved.
To examine the checkpoints, we can view the contents of .checkpoints, in our case we should see something like this
print(estimator.checkpoints)
>>> {3216: {'file': '/tmp/tmp4yndnyvv/checkpoints/model_iter-3216', 'metrics': {'accuracy': 0.9799, 'loss': 0.061388314}},
>>> 4288: {'file': '/tmp/tmp4yndnyvv/checkpoints/model_iter-4288', 'metrics': {'accuracy': 0.982, 'loss': 0.05492399}},
>>> 5360: {'file': '/tmp/tmp4yndnyvv/checkpoints/model_iter-5360', 'metrics': {'accuracy': 0.9847, 'loss': 0.04968348}}}Each entry stores as key the global_step and as values the path prefix of the checkpoint and the 'metrics' entry if we have used the validate() methods right before/after saving a checkpoint.
We have methods for restoring
restore_ckpt(path_prefix: str)- Which expects a file prefix, so a call would look likeestimator.restore_ckpt(path_prefix='/tmp/tmp4yndnyvv/checkpoints/model_iter-3216')restore_latest_ckpt()- Which will restore the latest checkpoint (greatestglobal_stepvalue)restore_best_ckpt()- Which will restore the best checkpoint, using the minimumlossvalue.
Sometimes, our training script might unexpectedly end due to an electricity problem or something out of our control - in this case, we can restore an Elistimator from a disk saved Elistimator directory, assuming we have at least one checkpoints saved (at least one save_ckpt() call).
The following code assumes a new script, without any Elistimator instatiated.
To restore from disk, we can use the static method from_disk passing it the model directory
from elistimator.elistimator import Elistimator
estimator = Elistimator.from_disk(model_dir='/tmp/tmp4yndnyvv')Now estimator would be functional and calling predict() and evaluate() will work perfectly.
If you want to use train() and validate() again, you should call setup() just as you did before.
For testing the Elistimator code, a supplied Dockerfile could be used to check the basic functionality of the Elistimator class. Testing is done through Docker on a GPU - so one must have docker installed alongside nvidia-docker.
First, build the docker image, in a linux shell, go into the elistimator/tests directory and run the following command
docker build -t elistimator-testing:1.0 -f Dockerfile .
This will result in a docker image named elistimator-testing:1.0.
After the image has been built, to run the tests, go one directory above (now you should be in elistimator/) and run the following command in the shell
docker run --runtime=nvidia --rm -v $(pwd):/opt elistimator-testing:1.0
This will launch a container, run the tests and remove the container afterwards.