字符编码 ASCII、URI 、UNICODE、Base64
pfan123 opened this issue · 0 comments
ASCII
ASCII(American Standard Code for Information Interchange:美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,由美国国家标准学会 ANSI(American National Standard Institude)于1968年正式制定。它是现今最通用的信息交换标准,并等同于国际标准ISO/IEC 646。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
-
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
-
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
-
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
URI
统一资源标识符(英语:Uniform Resource Identifier,缩写:URI)是一个用于标识某一互联网资源名称的字符串。URI 是一个通用的概率,由两个主要的子集 URL (统一资源定位符,又称 百分号编码 ) 和 URN (统一资源名) 构成,URL 是通过描述资源的位置来标识资源的,URN 则是通过名字来识别资源,与它们当前所处的位置无关。
- URI:RFC1630,发布于 1994 年 6 月,被称为“Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web”。它是一个Informational RFC —— 也就是说,它没有获得社区的任何认可。
- URL:RFC1738,发布于 1994 年 12 月, 被称为“Uniform Resource Locators”。它是一个 Proposed Standard —— 也就是说,它是一个共识过程的结果,虽然它还没有经过测试,并成熟到足以成为一个完整的 Internet Standard。
- URN:RFC1737,发布于 1994 年 12 月,被称为“Functional Requirements for Uniform Resource Names”。
URI编码
URI的字符类型
URI所允许的字符分作保留与未保留。保留字符是那些具有特殊含义的字符,例如:斜线字符用于URL(或URI)不同部分的分界符;未保留字符没有这些特殊含义。百分号编码把保留字符表示为特殊字符序列。上述情形随URI与URI的不同版本规格会有轻微的变化。
RFC 3986 section 2.2 保留字符 (2005年1月)
! |
* |
' |
( |
) |
; |
: |
@ |
& |
= |
+ |
$ |
, |
/ |
? |
# |
[ |
] |
|---|
RFC 3986 section 2.3 未保留字符 (2005年1月)
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
- |
_ |
. |
~ |
URI中的其它字符必须用百分号编码。
保留字符的百分号编码
如果一个保留字符在特定上下文中具有特殊含义(称作"reserved purpose") , 且URI中必须使用该字符用于其它目的, 那么该字符必须百分号编码。百分号编码一个保留字符,首先需要把该字符的ASCII的值表示为两个16进制的数字,然后在其前面放置转义字符("%"),置入URI中的相应位置。(对于非ASCII字符, 需要转换为UTF-8字节序, 然后每个字节按照上述方式表示.)
例如,"/", 如果用作URI的路径成分的分界符, 则是具有特殊含义的保留字符. 如果该字符需要出现在URI一个路径成分的内部, 则三字符序列"%2F"或"%2f"就用于代替原本的"/"出现在该URI路径成分的内部.
! |
# |
$ |
& |
' |
( |
) |
* |
+ |
, |
/ |
: |
; |
= |
? |
@ |
[ |
] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
%21 |
%23 |
%24 |
%26 |
%27 |
%28 |
%29 |
%2A |
%2B |
%2C |
%2F |
%3A |
%3B |
%3D |
%3F |
%40 |
%5B |
%5D |
在特定上下文中没有特殊含义的保留字符也可以被百分号编码,在语义上与不百分号编码的该字符没有差别.
在URI的"查询"成分(?字符后的部分)中, 例如"/"仍然是保留字符但是没有特殊含义,除非一个特定的URI有其它规定. 该/字符在没有特殊含义时不需要百分号编码.
如果保留字符具有特殊含义,那么该保留字符用百分号编码的URI与该保留字符仅用其自身表示的URI具有不同的语义。
受限字符或不安全字符
受限字符或不安全字符,直接放在Url中的时候,可能会引起解析程序的歧义,也需要百分号编码。
| 受限字符 | 为何受限 | 例子 |
|---|---|---|
% |
作为编码字符的转义标志,因此本身需要编码 | encodeURI('%') // "%25" |
| 空格 | Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。 | encodeURI(' ') // "%20" |
<>" |
尖括号和引号通常用于在普通文本中起到分隔Url的作用,所以应该对其进行编码 | encodeURI('<>"') // "%3C%3E%22" |
{} |
\^~[]' |
某一些网关或者传输代理会篡改这些字符。你可能会感到奇怪,为什么使用一些不安全字符的时候并没有发生什么不好的事情,比如无需对~字符进行编码,前面也说了,对某些传输协议来说不是问题。 |
| 0x00-0x1F, 0x7F | 受限,这些十六进制范围内的字符都在US-ASCII字符集的不可打印区间内 | 比如换行键是0x0A |
| >0x7F | 受限,十六进制值在此范围内的字符都不在US-ASCII字符集的7比特范围内 | encodeURI('京东') // "%E4%BA%AC%E4%B8%9C" |
javascript 转义字符
Javascript中提供六个方法来处理特殊保留字符、受限字符、不安全字符,如下
escape(已废弃) 针对 ASCII字母、数字、标点符号"@ * _ + - . /"以外,其他所有字符进行编码 unicode 字符
unescape(已废弃)
encodeURI对整个URL进行编码,除了常见的符号以外,对其他一些在网址中有特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
decodeURI
encodeURIComponent与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,"; / ? : @ & = + $ , #",这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码
decodeURIComponent
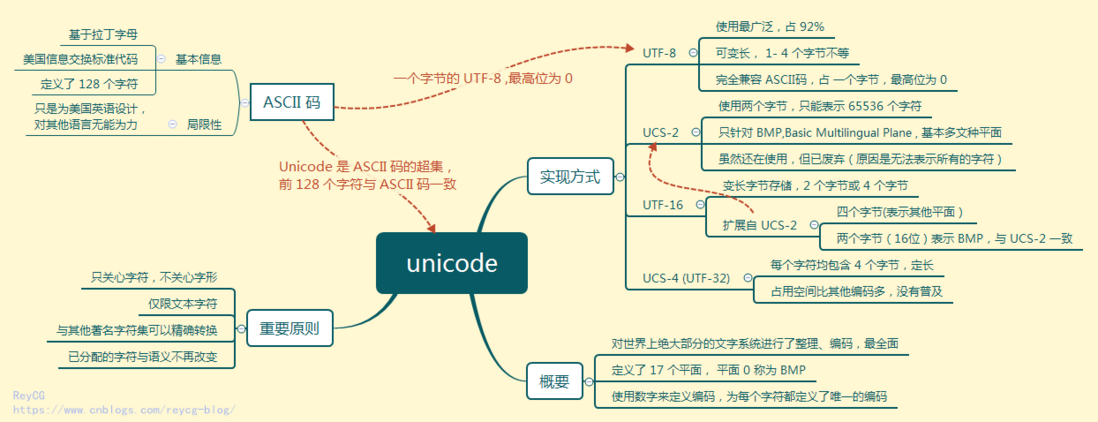
Unicode
Unicode(统一码、万国码、单一码,简称UCS)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 字符集(简称为ucs),国际标准组织于1984年4月成立ISO/IEC JTCI/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立 Unicode Consortium ,并于1991年10月与WG2达成协议,采用统一编码字集。
大概来说,Unicode编码系统可分为编码方式和实现方式两个层次。
Unicode 编码规则
统一码的编码方式与ISO 10646的通用字符集概念相对应。当前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示2^16(即65536)个字符。
采用16位编码体系基本满足各种语言的使用,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留20249个,共计65534个。Unicode 编码后的大小是一样的,例如一个英文字母 “a” 和 一个汉字 “好”,编码后占用的空间大小是一样的都是两个字节。
随着中文,日文和韩文引入,原有的 Unicode 定义的字符集无法满足。Unicode 定义的字符集已经超过16位所能表达的范围,把所有这些 CodePoint 分成17个平面 (Code Plane): U+0000 ~ U+FFFF 划入基本多语言平面(Basic MultilingualPlane, 简记为BMP),其余划入16个辅助平面(Supplementary Plane), 代码点范围U+10000(2^16) ~ U+10FFFF(2^20+2^16).

| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面(未正式使用[1]) | Tertiary Ideographic Plane,简称TIP |
| 4号平面 至 13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区)[2] | Private Use Area-A,简称PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区)[2] | Private Use Area-B,简称PUA-B |
在Unicode中,私人使用区 (Private Use Areas) 指其解释未在Unicode标准中指定,而是由合作用户之间的私人协议决定其用途的一系列码位。 当前定义了三个私人使用区:一个在基本多语言平面(U+E000-U+F8FF)中,另外两个几乎包含了整个第15和第16平面(分别为U+F0000-U+FFFFD,U+100000-U+10FFFD)。
基本多语言平面的字符的编码为U+hhhh,其中每个h代表一个十六进制数字,与UCS-2编码完全相同。而其对应的4字节UCS-4编码后两个字节一致,前两个字节则所有位均为0。
关于统一码和ISO 10646及UCS的详细关系,见通用字符集。

\u则代表unicode编码
Unicode 编码实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际存储传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),Unicode的实现方式有UTF-7、UTF-8、UTF-16、UTF-32、Punycode、CESU-8、SCSU、UTF-32、GB18030等, 其中 UTF-8、UTF-16、UTF-32 使用比较广泛。
UTF-8 编码
UTF-8 是使用互联网上使用最广泛的 unicode 编码方式,目前已经占有整个互联网 92% 的份额。
UTF-8 是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同(Unicode 中的前 128 个字符和 ASCII 码都是一一对应的)。
| 编号范围 | 字节 |
|---|---|
| 0x0000 - 0x007F | 1 |
| 0x0080 - 0x07FF | 2 |
| 0x0800 - 0xFFFF | 3 |
| 0x010000 - 0x10FFFF | 4 |
0x 开头代表十六进制
1个字节是8位,二进制8位:xxxxxxxx 范围从00000000-11111111,表示0到255。一位16进制数(用二进制表示是xxxx)最多只表示到15(即对应16进制的F 1111),要表示到255,就还需要第二位。所以1个字节=2个16进制字符,一个16进制位=0.5个字节。
UTF-16 编码
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
UTF-32 编码
UTF-32 对 Unicode 中的每个字符都用 4 个字节来表示。UTF-32 的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
截自网友 Unicode 的思维导图:
javascript Unicode 字符转义
Javascript中提供了相关方法来处理 Unicode 转义,如下:
charAt() 方法可返回指定位置的字符。
charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
fromCharCode() 可接受一个指定的 Unicode 值,然后返回一个字符串。String 的静态方法,字符串中的每个字符都由单独的数字 Unicode 编码指定.
示例:
str = "中文";
// 获取字符
char0 = str.charAt(0); // "中"
// 对应字符 Unicode 编码值,根据 Unicode 表寻找对应字符
code = str.charCodeAt(0); // 20013
// Unicode 编码转换为字符串
str0 = String.fromCharCode(code); // "中"
// 转为16进制数组
code16 = code.toString(16); // "4e2d"
// 变成字面量表示法
ustr = "\\u"+code16; // "\u4e2d"
'\u4e2d' === '中' // true
// 包装为JSON
jsonstr = '{"ustr": "'+ ustr +'"}'; //'{"ustr": "\u4e2d"}'
// 使用JSON工具转换
obj = JSON.parse(jsonstr); // Object {ustr: "中"}
//
ustr_n = obj.ustr; // "中"小知识:计算机喜欢用16进制
字节(byte)在计算机内部出现的频率较高,使用一种简洁的方式将内在含义准确表达出来,会带来很多方便。选择十六进制,因为8位二进制的数字可以方便的转换为2个十六进制的数字。一个字节能且只能由一对十六进制来表示,比如10110110可以表示为B6。
Base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于
A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
Base64编码转换方式
Base64,选出64个字符----小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"(再加上作为垫字的"=",实际上是65个字符)----作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符。具体来说,转换方式可以分为四步。
-
第一步,将每三个字节作为一组,一共是24个二进制位。
-
第二步,将这24个二进制位分为四组,每个组有6个二进制位。
-
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节。
-
第四步,根据 Base64 索引表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
Base64索引表:
| 数值 | 字符 | 数值 | 字符 | 数值 | 字符 | ||
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。也就是说,当最后剩余两个八位字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表:
| 文本(1 Byte) | A | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base64编码 | Q | Q | = | = | ||||||||||||||||||||
| 文本(2 Byte) | B | C | ||||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base64编码 | Q | k | M | = |
注意:Base64将三个字节转化成四个字节,因此Base64编码后的文本,会比原文本大出三分之一左右。
Base64编码转换示例
- 编码“Man”
| 文本 | M | a | n | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII编码 | 77 | 97 | 110 | |||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| 索引 | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64编码 | T | W | F | u |
在此例中,Base64算法将3个字节编码为4个字符。
- 编码汉字"严"
汉字本身可以有多种编码,比如gb2312、utf-8、gbk等等,每一种编码的Base64对应值都不一样。下面的例子以utf-8为例。
| 文本 | 严 | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| utf-8 编码 | E4B8A5 | |||||||||||||||||||||||||||||||
| 二进制位(24位) | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | ||||||||
| 二进制位(32位) | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 索引 | 57 | 11 | 34 | 37 | ||||||||||||||||||||||||||||
| Base64编码 | 5 | L | i | l |
扩展进制转换(-)
// 十进制转其他进制
const x = 110;
x.toString(2)//转为2进制
x.toString(8)//转为8进制
x.toString(16)//转为16进制
// 其他进制转十进制
const x = "110" // 二进制的字符串表示
parseInt(x, 2) // 二进制, 转为十进制
const x = "70" // 八进制的字符串表示
parseInt(x, 8) // 八进制, 转为十进制
const x = "ff" // 十六进制的字符串表示
parseInt(x, 16) // 十六进制, 转为十进制扩展进制转换(二)
形如——
&name; // html 转义字符,类似前面学到 uri 使用 % 转义字符
&#dddd; // 十进制数字
&#xhhhh; // 十六进制数字
——的一串字符是 HTML、XML 等 SGML 类语言的转义序列(escape sequence)。它们不是「编码」。
以 HTML 为例,这三种转义序列都称作 character reference:
1.第一种是 character entity reference,后接预先定义的 entity 名称,而 entity 声明了自身指代的字符。
2.后两种是 numeric character reference(NCR),数字取值为目标字符的 Unicode code point;以「&#」开头的后接十进制数字,以「&#x」开头的后接十六进制数字。
从 HTML 4 开始,NCR 以 Unicode 为准,与文档编码无关。
「**」二字分别是 Unicode 字符 U+4E2D 和 U+56FD,十六进制表示的 code point 数值「4E2D」和「56FD」就是十进制的「20013」和「22269」。所以——
中国
中国
参考阅读:
Unicode®字符百科
ASCII
Unicode
Unicode字符列表
UTF-8
百分号编码
字符,字节和编码
字符编码笔记:ASCII,Unicode 和 UTF-8
阮一峰 - Unicode与JavaScript详解
阮一峰 - 关于URL编码
阮一峰 - Base64笔记
探究 dataURI 中使用 SVG 正确姿势
escape,encodeURI,encodeURIComponent有什么区别?
URL编码的奥秘
你真的了解 Unicode 和 UTF-8 吗?
彻底弄懂 Unicode 编码
二进制
计算机的血肉:数据
Javascript 与字符编码
Unicode® 6.0.0