- Agent
- Soft Actor Critic (SAC)
- able to tune an update-to-date (UTD) ratio G
- Randomized Ensembled Double Q learning (REDQ)
- v1 : N critics and N critic optimizers
- v2 : N critics and 1 critic optimizer
- Soft Actor Critic (SAC)
- ETC
- multi-step Q learning
-
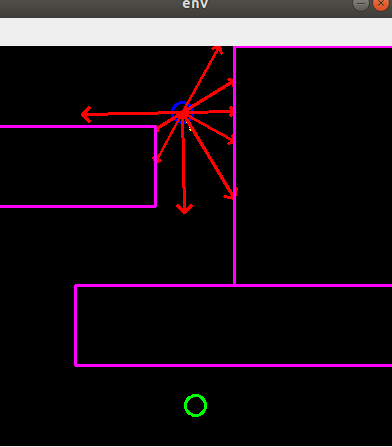
Unicycle model
-
Lidar-like sensor model
-
Task : reach the goal point with the green circle while avoiding the collision with walls
-
Observation : different direction scan measurement values
- the default number of scan value N : 9
- maximum distance : 10m
- historical window length H : H consecutive observations are concatenated with the shape (1, N*H)
- angle range : [-120 deg, 120 deg]
- minmax normalized to [0, 1]
-
Action : angular velocity
-
action range : [-pi/4 rad/s, pi/4 rad/s]
-
action range : [-pi/4 rad/s, pi/4 rad/s]
-
-
Linear velocity
- train : 3m/s, constant
- test : 1.5m/s, constant
-
Reward
- -5 if collisions happens
- 2 * clip(forward distance measure, 0, 0.5)
-
screen shot

- Soft actor critic
- After the training of REDQ, the parameters of the agent are saved in the directory
/maze_example/savefile/sacor/maze_example/savefile/sac_g20
- After the training of REDQ, the parameters of the agent are saved in the directory
cd REDQ_simple_example
python /maze_example/train_sac_agent.py --max_train_eps 100
python /maze_example/train_sac_agent.py --max_train_eps 100 --G 20
- REDQ
- After the training of REDQ, the parameters of the agent are saved in the directory
/maze_example/savefile/redqor/maze_example/savefile/redq_v2
- After the training of REDQ, the parameters of the agent are saved in the directory
cd REDQ_simple_example
python /maze_example/train_redq_agent.py --max_train_eps 100 --version v2
- Early stop the training process when the agent reaches the target for 10 consecutive episodes.
