Table of Contents generated with DocToc
- 1 设计模式
- 2 多线程
- 2.1 多线程基础
- 2.2 JUC
- 2.2.1 基础巩固
- 2.2.2 JUC生产者消费者
- 2.2.3 Condition精准通知和唤醒
- 2.2.4 锁的本质
- 2.2.5 集合类不安全
- 2.2.6 Collable多线程
- 2.2.7 常用辅助类
- 2.2.8 ReadWriteLock读写锁
- 2.2.9 阻塞队列
- 2.2.10 线程池
- 2.2.11 四大函数式接口
- 2.2.12 Stream流式计算
- 2.2.13 ForkJoin
- 2.2.14 异步回调
- 2.2.15 JMM
- 2.2.16 volatile
- 2.2.17 单例模式
- 2.2.18 深入理解CAS
- 2.2.19 原子引用解决ABA问题
- 2.2.20 各种锁的理解
- 2.2.21 关于中断
- 2.3 并发编程实战
- 3 BIO/NIO/AIO
- 4 集合源码
- 5 常用的工具类/包
- 6 MySQL提高
- 6.1 MySQL基础巩固
- 6.1.1 DISTINCT
- 6.1.2 LIMIT
- 6.1.3 完全限定.
- 6.1.4 ORDER BY
- 6.1.5 where过滤
- 6.1.6 LIKE+通配符
- 6.1.7 正则表达式搜索
- 6.1.8 计算字段
- 6.1.9 使用数据处理函数
- 6.1.10 汇总函数
- 6.1.11 分组数据
- 6.1.12 使用子查询
- 6.1.13 联结表
- 6.1.14 组合查询
- 6.1.15 全文本搜索("索引")
- 6.1.16 插入数据
- 6.1.17 更新和删除数据
- 6.1.18 创建和操作表
- 6.1.19 使用视图("虚拟表")
- 6.1.20 使用存储过程("函数")
- 6.1.21 使用游标
- 6.1.22 使用触发器
- 6.1.23 管理事务
- 6.2 MySQL性能优化
- 6.2.1 并发控制的锁策略
- 6.2.2 事务的ACID
- 6.2.3 事务的隔离级别
- 6.2.4 多版本并发控制(MVCC)
- 6.2.5 MySQL的存储引擎
- 6.2.6 库表结构优化
- 6.2.7 索引优化
- 6.2.8 查询优化
- 6.3 SQL笔试题
- 6.4 中间件MyCat
- 6.1 MySQL基础巩固
- 7 分布式微服务
- 7.1 SpringCloud
- 7.1.1 项目模块的创建
- 7.1.2 RestTemplate
- 7.1.3 Hutool工具包
- 7.1.4 Eureka服务注册与发现
- 7.1.5 Zookeeper服务注册与发现
- 7.1.6 Consul服务注册与发现
- 7.1.7 三个注册中心的异同点
- 7.1.8 Ribbon负载均衡服务调用
- 7.1.9 OpenFeign服务调用
- 7.1.10 Hystrix服务降级/熔断/限流
- 7.1.11 Gateway网关
- 7.1.12 Config分布式服务配置
- 7.1.13 Bus消息总线
- 7.1.14 Stream消息驱动
- 7.1.15 Sleuth分布式请求链路跟踪
- 7.1.16 SpringCloud Alibaba
- 7.1.17 Nacos服务注册和配置中心
- 7.1.18 Sentinel熔断与限流
- 7.1.19 Seata分布式事务
- 7.2 SpringBoot
- 7.2.1 加速依赖包的导入
- 7.2.2 SpringBoot的配置
- 7.2.3 容器功能
- 7.2.4 自动配置原理⭐
- 7.2.5 热更新
- 7.2.6 配置文件(yml)
- 7.2.7 Web开发
- 7.2.8 数据访问
- 7.2.9 单元测试
- 7.2.10 指标监控
- 7.2.11 高级特性
- 7.3 WebFlux响应式编程
- 7.1 SpringCloud
- 8 Algorithm
- 9 JVM
- 10 Effective Java
- 11 Redis
- 12 消息中间件MQ
- 13 Nginx
- 14 Zookeeper
- 15 ElasticSearch
- 16 面试点总结
- 16.0 经典好文
- 16.1 自增变量
- 16.2 单例模式
- 16.3 类初始化和实例初始化
- 16.4 方法的参数传递机制
- 16.5 递归与迭代
- 16.6 成员变量与局部变量
- 16.7 Spring Bean作用域区别
- 16.8 Spring支持的事务传播属性和事务隔离级别
- 16.9 SpringMVC中如何解决POST请求中文乱码
- 16.10 简述SpringMVC的工作流程
- 16.11 MyBatis中当实体类的属性和表中的字段不一致时如何解决?
- 16.12 Linux常用服务类相关命令
- 16.13 Git分支相关命令及实际应用
- 16.14 Redis持久化
- 16.15 MySQL什么时候适合索引?
- 16.16 JVM垃圾回收机制
- 16.17 Redis在项目中的使用场景
- 16.18 ElasticSearch和Solr的区别
- 16.19 单点登录的实现过程
- 16.20 购物车
- 16.21 消息队列
- 16.22 谈谈你对volatile的理解
- 16.23 关于指令重排
- 16.24 关于JMM
- 16.25 谈谈CAS
- 16.26 ABA问题与原子戳引用
- 16.27 List不安全之并发修改异常
- 16.28 Set不安全之并发修改异常
- 16.29 Map不安全之并发修改异常
- 16.30 公平锁/非公平锁
- 16.31 可重入锁(递归锁)
- 16.32 自旋锁的实现
- 16.33 独占锁(写锁)/共享锁(读锁)/互斥锁
- 16.34 CountDownLatch(倒计时器/减法计数器)
- 16.35 CyclicBarrier(栅栏/加法计数器)
- 16.36 Semaphore(信号量)
- 16.37 阻塞队列(3种生产者/消费者模式的实现)
- 16.38 synchronized和ReentrantLock的区别
- 16.39 Callable接口
- 16.40 线程池使用及优势
- 16.41 关于线程池
- 16.42 死锁编码及定位分析
- 16.43 关于GC Roots
- 16.44 JVM参数类型
- 16.45 查看JVM初始默认值
- 16.46 通过程序获得堆栈信息
- 16.47 JVM常用的基本配置参数
- 16.48 强/软/弱/虚引用的理解
- 16.49 关于WeakHashMap
- 16.50 关于OOM
- 16.51 关于垃圾收集器
- 16.52 七大默认垃圾收集器
- 16.53 JVM项目调优
- 16.54 生产环境服务器变慢,诊断思路和性能评估?
- 16.55 CPU占用过高的定位分析思路
- 16.56 JVM监控和性能分析工具
- 16.57 如何利用GitHub检索
- 16.58 String.intern()返回引用
- 16.59 LockSupport
- 16.60 AQS(AbstractQueuedSynchronizer)
- 16.61 Spring AOP顺序
- 16.62 Spring循环依赖
- 16.63 Redis的落地应用
- 16.64 Redis分布式锁
- 16.65 Redis内存淘汰策略
- 16.66 LRU算法的实现
- 16.67 过滤器(Filter)与拦截器(Interceptor)
- 16.68 重定向与请求转发的区别
- 16.69 Socket与Servlet区别
- 16.70 雪花算法
- 16.71 静态内部类和成员内部类
- 16.72 实现深拷贝的两种方式(原型模式)
- 16.73 中断线程的几种方法
- 16.74 notify和notifyAll的区别
- 16.75 sleep()和wait()的区别
- 16.76 泛型方法的调用
- 16.77 乐观锁/悲观锁/自旋锁/自适应自旋/锁消除/锁粗化/轻量级锁/偏向锁
- 16.78 java内存模型
- 16.79 jps/jstat/jinfo/jmap/jhat/jstack/jconsole/jvisualvm
- 16.80 wait/notify/notifyAll/sleep/join/yield
- 16.81 不可变类
- 16.82 竞争条件
- 16.82 代理模式/静态代理/动态代理/Cglib代理
- 16.83 JDK/JRE/JVM之间的关系
- 16.84 关于ThreadLocal
- 16.85 B-Tree/B+Tree/聚集索引/辅助索引/磁盘块/页块
- 16.86 数据库的三大范式
- 16.87 MySQL如何保证一致性、原子性、持久性
- 16.88 写SQL的几点注意事项
- 16.89 drop/delete/truncate
- 16.90 MySQL的默认隔离级别?MySQL如何解决幻读问题?
- 16.100 MySQL中如何优化大表
- 16.101 视图/存储过程/函数/触发器
- 16.102 数据库并发策略/锁种类
- 16.103 交叉连接/内连接/外连接
- 16.104 DDL/DML/DCL/DQL
- 16.105 Spring Bean的生命周期
- 16.106 如何使Spring中单例Bean线程安全
- 16.107 怎么重载的Spring Bean的生命周期方法
- 16.108 切面/通知/切点/连接点/切点表达式
- 16.109 SpringBoot有哪几种读取配置的方式
- 16.110 Eureka和Zookeeper用作服务注册与发现的区别
- 16.111 服务熔断和降级的区别
- 16.112 RPC和REST调用的区别
- 16.113 面试盲点
- 16.114 常考容器类源码
- 16.114.1 HashMap
- 16.114.2 ConcurrentHashMap
- 16.114.3 CopyOnWriteArrayList
- 16.114.4 CopyOnWriteArraySet
- 16.114.5 AbstractQueuedSynchronizer
- 16.114.6 ReentrantLock
- 16.114.7 ReentrantReadWriteLock
- 16.114.8 Semaphore
- 16.114.9 CountDownLatch
- 16.114.10 CyclicBarrier
- 16.114.11 synchronized锁升级过程
- 16.114.12 LongAdder
- 17 Undertow+JMeter压力测试
- 18 Linux
- 18.1 上传下载文件
- 18.2 文件权限
- 18.3 进程
- 18.4 服务
- 18.5 软件安装
模式定义:保证一个类只有一个实例,并且提供一个全局访问点。
应用场景:重量级的对象,不需要多个实例,如线程池、数据库连接池。
概念:延迟加载,只有在真正使用的时候,才开始实例化。
public class LazySingletonTest {
public static void main(String[] args) {
// 单线程情况
LazySingleton instance = LazySingleton.getInstance();
LazySingleton instance1 = LazySingleton.getInstance();
System.out.println(instance == instance1); // 输出 true
}
}
class LazySingleton{
private static LazySingleton instance;
private LazySingleton(){
}
public static LazySingleton getInstance(){
if (instance == null){
instance = new LazySingleton();
}
return instance;
}
}存在问题:
- 多线程情况下会出现线程安全问题
- double check 加锁优化
- 编译器(JIT),CPU有可能对指令进行重新排序,导致使用到尚未初始化的实例,可以通过添加volatile关键字进行修饰;对于volatile修饰的字段,可以防止指令重排。
下面详细进行介绍:如下代码可以演示在多线程情况下会出现线程安全问题。
public class LazySingletonTest {
public static void main(String[] args) {
//多线程情况
new Thread( () -> {
LazySingleton instance = LazySingleton.getInstance();
System.out.println(instance); // 输出LazySingleton@51a22f1d
}).start();
new Thread( () -> {
LazySingleton instance = LazySingleton.getInstance();
System.out.println(instance); // 输出LazySingleton@6706a70b
}).start();
}
}
class LazySingleton{
private static LazySingleton instance;
private LazySingleton(){
}
public static LazySingleton getInstance(){
if (instance == null){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
instance = new LazySingleton();
}
return instance;
}
}解决方法一:在getInstance()方法上添加synchronized关键字可以解决这一问题,但是会导致性能降低。
class LazySingleton{
private static LazySingleton instance;
private LazySingleton(){
}
public synchronized static LazySingleton getInstance(){ // 添加synchronized关键字
if (instance == null){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
instance = new LazySingleton();
}
return instance;
}
}解决方法二:为了解决方法一的性能问题,可以采用double check 加锁优化。
class LazySingleton{
private static LazySingleton instance;
private LazySingleton(){
}
public static LazySingleton getInstance(){
if (instance == null){
synchronized(LazySingleton.class){ // double check 加锁优化
if (instance == null){
instance = new LazySingleton();
}
}
}
return instance;
}
}解决办法三:方法二可能在编译层出现重排序问题,添加volatile关键字可以保证编译时先进行初始化,再引用赋值,否则可能会出现空指针问题。
class LazySingleton{
private volatile static LazySingleton instance; // 添加volatile关键字
private LazySingleton(){
}
public static LazySingleton getInstance(){
if (instance == null){
synchronized(LazySingleton.class){
if (instance == null){
// 字节码层运行细节
// 1.分配空间-->2.初始化-->3.引用赋值
// 添加volatile可以防止重排序(即先进行初始化,再引用赋值,保证二者不会颠倒执行),否则可能会出现空指针问题
instance = new LazySingleton();
}
}
}
return instance;
}
}概念:类加载的初始化阶段就完成了实例的初始化,本质上就是借助于jvm类加载机制,保证实例的唯一性。
类加载过程:
-
加载二进制数据到内存中,生成对应的Class数据结构。
-
连接:a.验证;b.准备(给类的静态成员变量赋默认值);c.解析。
-
初始化:给类的静态变量赋初值。
只有在真正使用对应的类时,才会触发初始化。(如当前类时启动类即main函数所在类,直接进行new操作、访问静态属性、访问静态方法、用反射访问类、初始化一个类的子类)
public class HungrySingletonTest {
public static void main(String[] args) {
HungrySingleton instance = HungrySingleton.getInstance();
HungrySingleton instance1 = HungrySingleton.getInstance();
System.out.println(instance == instance1); // 输出true
}
}
class HungrySingleton{
private static HungrySingleton instance = new HungrySingleton();
private HungrySingleton(){
}
public static HungrySingleton getInstance(){
return instance;
}
}s概念:
- 本质上是利用类的加载机制来保证线程安全。
- 只有在实际使用的时候,才会触发静态内部类的初始化,所以也是懒加载的一种形式。
class InnerClassSingleton{
private static class InnerClassHolder{
private static InnerClassSingleton instance = new InnerClassSingleton();
}
private InnerClassSingleton(){
}
public static InnerClassSingleton getInstance(){
return InnerClassHolder.instance;
}
}
- 使用饿汉模式和静态内部类模式创建的单例类,在使用反射时不能保证单例性。
public class SingletonTest { public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException { Constructor<InnerClassSingleton> declaredConstructor = InnerClassSingleton.class.getDeclaredConstructor(); declaredConstructor.setAccessible(true); InnerClassSingleton innerClassSingleton = declaredConstructor.newInstance(); InnerClassSingleton instance = InnerClassSingleton.getInstance(); System.out.println(innerClassSingleton == instance); // 输出false } }
- 可以在饿汉模式和静态内部类模式对该问题进行防护,使用懒汉模式则不能进行防护。
class InnerClassSingleton{ private static class InnerClassHolder{ private static InnerClassSingleton instance = new InnerClassSingleton(); } private InnerClassSingleton(){ if(InnerClassHolder.instance!=null){ throw new RuntimeException("单例不允许多个实例"); } } public static InnerClassSingleton getInstance(){ return InnerClassHolder.instance; } }
OO设计原则:
- 找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。(策略模式)
- 针对接口编程,而不是针对实现编程。(策略模式)
- 多用组合,少用继承。(策略模式)
- 为了交互对象之间的松耦合设计而努力。(观察者模式)
- 类应该对扩展开放,对修改关闭。(装饰者模式)
策略模式(Strategy Pattern):定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户。
"模拟鸭子的世界":

观察者模式(Observer Pattern):定义了对象之间的一对多依赖,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并自动更新。观察者模式提供了一种对象设计,让主题和观察者之间松耦合。松耦合的设计之所以能让我们建立有弹性的OO系统,能够应对变化,是因为对象之间的互相依赖降到了最低。
"气象检测站":
自定义观察者模式:

JDK观察者模式:Java提供的观察者模式:Observable类和Observer接口。
需要注意的是:Observable是一个类,违反了OO设计原则(针对接口编程,而不是针对实现编程)。由于java不支持多重继承,限制了Observable的复用潜力;此外,Observable的serChange方法被定义成protected,导致只有继承Observable类,才能将创建的Observable实例组合到自己的设计对象中来,这违反了OO设计又一个原则(多用组合,少用继承)。

装饰者模式(Decorator Pattern):动态地将责任附加到对象上;若要扩展功能,装饰者提供了比继承更有弹性的替代方案。
"咖啡与调料"
自定义装饰者模式:

增强Java I/O的装饰者模式:

工厂模式(Factory Pattern):
"比萨工厂"
本部分图表使用IDEA+PlantUML+Graphviz制作:
设计模式概览:

单例模式:一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。
当系统中只需要一个实例对象或者系统中只允许一个公共访问点,除了这个公共访问点外,不能通过其他访问点访问该实例时,可以使用单例模式。单例模式的主要优点就是节约系统资源、提高了系统效率,同时也能够严格控制客户对它的访问。也许就是因为系统中只有一个实例,这样就导致了单例类的职责过重,违背了“单一职责原则”,同时也没有抽象类,所以扩展起来有一定的困难。其UML结构图非常简单,就只有一个类。
Java类库中的应用:
java.lang.Runtime#getRuntime()java.awt.Desktop#getDesktop()java.lang.System#getSecurityManager()
识别方法: 单例可以通过返回相同缓存对象的静态构建方法来识别。
详见1.1。
工厂方法模式:一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。
作为抽象工厂模式的孪生兄弟,工厂方法模式定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个,也就是说工厂方法模式让实例化推迟到子类。工厂方法模式非常符合"开闭原则",当需要增加一个新的产品时,我们只需要增加一个具体的产品类和与之对应的具体工厂即可,无须修改原有系统。同时在工厂方法模式中用户只需要知道生产产品的具体工厂即可,无须关系产品的创建过程,甚至连具体的产品类名称都不需要知道。虽然他很好的符合了“开闭原则”,但是由于每新增一个新产品时就需要增加两个类,这样势必会导致系统的复杂度增加。
Java类库中的应用:
java.util.Calendar#getInstance()java.util.ResourceBundle#getBundle()java.text.NumberFormat#getInstance()java.nio.charset.Charset#forName()java.net.URLStreamHandlerFactory#createURLStreamHandler(String)java.util.EnumSet#of()javax.xml.bind.JAXBContext#createMarshaller()
识别方法: 工厂方法可通过构建方法来识别, 它会创建具体类的对象, 但以抽象类型或接口的形式返回这些对象。

抽象工厂模式:一种创建型设计模式, 它能创建一系列相关的对象, 而无需指定其具体类。
提供一个接口,用于创建相关或者依赖对象的家族,而不需要明确指定具体类。他允许客户端使用抽象的接口来创建一组相关的产品,而不需要关系实际产出的具体产品是什么。这样一来,客户就可以从具体的产品中被解耦。它的优点是隔离了具体类的生成,使得客户端不需要知道什么被创建了,而缺点就在于新增新的行为会比较麻烦,因为当添加一个新的产品对象时,需要更加需要更改接口及其下所有子类。
Java类库中的应用:
javax.xml.parsers.DocumentBuilderFactory#newInstance()javax.xml.transform.TransformerFactory#newInstance()javax.xml.xpath.XPathFactory#newInstance()
识别方法: 我们可以通过方法来识别该模式——其会返回一个工厂对象。 接下来, 工厂将被用于创建特定的子组件。

建造者模式(也称为生成器模式):一种创建型设计模式, 使你能够分步骤创建复杂对象。 该模式允许你使用相同的创建代码生成不同类型和形式的对象。
对于建造者模式而言,它主要是将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。适用于那些产品对象的内部结构比较复杂。建造者模式将复杂产品的构建过程封装分解在不同的方法中,使得创建过程非常清晰,能够让我们更加精确的控制复杂产品对象的创建过程,同时它隔离了复杂产品对象的创建和使用,使得相同的创建过程能够创建不同的产品。但是如果某个产品的内部结构过于复杂,将会导致整个系统变得非常庞大,不利于控制,同时若几个产品之间存在较大的差异,则不适用建造者模式,毕竟这个世界上存在相同点大的两个产品并不是很多,所以它的使用范围有限。
Java类库中的应用:
java.lang.StringBuilder#append()java.lang.StringBuffer#append()java.nio.ByteBuffer#put()javax.swing.GroupLayout.Group#addComponent()java.lang.Appendable的所有实现
识别方法: 生成器模式可以通过类来识别, 它拥有一个构建方法和多个配置结果对象的方法。 生成器方法通常支持方法链 (例如 someBuilder->setValueA(1)->setValueB(2)->create() )。

建造者模式的一种简化(去掉Director):
public class Car {
private String carType;
private int seats;
private String engine;
private String transmission;
private String tripComputer;
private String gpsNavigator;
/* 禁止无参构造 */
private Car(){
throw new RuntimeException("Can't init...");
}
private Car(Builder builder){
this.carType = builder.carType;
this.seats = builder.seats;
this.engine = builder.engine;
this.transmission = builder.transmission;
this.tripComputer = builder.tripComputer;
this.gpsNavigator = builder.gpsNavigator;
}
@Override
public String toString() {
return "Car{" +
"carType='" + carType + '\'' +
", seats=" + seats +
", engine='" + engine + '\'' +
", transmission='" + transmission + '\'' +
", tripComputer='" + tripComputer + '\'' +
", gpsNavigator='" + gpsNavigator + '\'' +
'}';
}
public static final class Builder{
private String carType;
private int seats;
private String engine;
private String transmission;
private String tripComputer;
private String gpsNavigator;
public Builder(){ }
public Builder setCarType(String carType){
this.carType = carType;
return this;
}
public Builder setSeats(int seats){
this.seats = seats;
return this;
}
public Builder setEngine(String engine){
this.engine = engine;
return this;
}
public Builder setTransmission(String transmission){
this.transmission = transmission;
return this;
}
public Builder setTripComputer(String tripComputer){
this.tripComputer = tripComputer;
return this;
}
public Builder setGpsNavigator(String gpsNavigator){
this.gpsNavigator = gpsNavigator;
return this;
}
public Car build(){
return new Car(this);
}
}
public static void main(String[] args) {
Car car = new Builder()
.setCarType("SUV")
.setSeats(6)
.setEngine("1.6T")
.setTransmission("混合动力")
.setTripComputer("12.9寸液晶大屏")
.setGpsNavigator("北斗")
.build();
System.out.println(car);
}
}原型模式:一种创建型设计模式, 使你能够复制已有对象, 而又无需使代码依赖它们所属的类。
在我们应用程序可能有某些对象的结构比较复杂,但是我们又需要频繁的使用它们,如果这个时候我们来不断的新建这个对象势必会大大损耗系统内存的,这个时候我们需要使用原型模式来对这个结构复杂又要频繁使用的对象进行克隆。所以原型模式就是用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。它主要应用与那些创建新对象的成本过大时。它的主要优点就是简化了新对象的创建过程,提高了效率,同时原型模式提供了简化的创建结构。
根据拷贝方式不同,原型模式又可以分为:浅克隆和深克隆。一般实现的是浅克隆方式。
Java类库中的应用:
java.lang.Object#clone()
识别方法: 原型可以简单地通过 clone或 copy等方法来识别。

适配器模式:一种结构型设计模式, 它能使接口不兼容的对象能够相互合作。
在应用程序中我们可能需要将两个不同接口的类来进行通信,在不修改这两个的前提下我们可能会需要某个中间件来完成这个衔接的过程。这个中间件就是适配器。所谓适配器模式就是将一个类的接口,转换成客户期望的另一个接口。它可以让原本两个不兼容的接口能够无缝完成对接。作为中间件的适配器将目标类和适配者解耦,增加了类的透明性和可复用性。
Java类库中的应用:
java.util.Arrays#asList()java.util.Collections#list()java.util.Collections#enumeration()java.io.InputStreamReader(InputStream)java.io.OutputStreamWriter(OutputStream)javax.xml.bind.annotation.adapters.XmlAdapter#marshal()
识别方法:适配器可以通过以不同抽象或接口类型实例为参数的构造函数来识别。 当适配器的任何方法被调用时, 它会将参数转换为合适的格式, 然后将调用定向到其封装对象中的一个或多个方法。

桥接模式:一种结构型设计模式, 可将一个大类或一系列紧密相关的类拆分为抽象和实现两个独立的层次结构, 从而能在开发时分别使用。
如果说某个系统能够从多个角度来进行分类,且每一种分类都可能会变化,那么我们需要做的就是讲这多个角度分离出来,使得他们能独立变化,减少他们之间的耦合,这个分离过程就使用了桥接模式。所谓桥接模式就是讲抽象部分和实现部分隔离开来,使得他们能够独立变化。桥接模式将继承关系转化成关联关系(关联优于继承),封装了变化,完成了解耦,减少了系统中类的数量,也减少了代码量。
使用示例: 桥接模式在处理跨平台应用、支持多种类型的数据库服务器或与多个特定种类(例如云平台和社交网络等)的API供应商协作时会特别有用。
识别方法: 桥接可以通过一些控制实体及其所依赖的多个不同平台之间的明确区别来进行识别。

组合模式:一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能像使用独立对象一样使用它们。
组合模式组合多个对象形成树形结构以表示“整体-部分”的结构层次。它定义了如何将容器对象和叶子对象进行递归组合,使得客户在使用的过程中无须进行区分,可以对他们进行一致的处理。在使用组合模式中需要注意一点也是组合模式最关键的地方:叶子对象和组合对象实现相同的接口。这就是组合模式能够将叶子节点和对象节点进行一致处理的原因。
虽然组合模式能够清晰地定义分层次的复杂对象,也使得增加新构件也更容易,但是这样就导致了系统的设计变得更加抽象,如果系统的业务规则比较复杂的话,使用组合模式就有一定的挑战了。
Java类库中的应用:
java.awt.Container#add(Component)javax.faces.component.UIComponent#getChildren()
识别方法: 组合可以通过将同一抽象或接口类型的实例放入树状结构的行为方法来轻松识别。

装饰模式:一种结构型设计模式, 允许你通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。
我们可以通过继承和组合的方式来给一个对象添加行为,虽然使用继承能够很好拥有父类的行为,但是它存在几个缺陷:一、对象之间的关系复杂的话,系统变得复杂不利于维护。二、容易产生“类爆炸”现象。三、是静态的。在这里我们可以通过使用装饰者模式来解决这个问题。装饰者模式,动态地将责任附加到对象上。若要扩展功能,装饰者提供了比继承更加有弹性的替代方案。虽然装饰者模式能够动态将责任附加到对象上,但是他会产生许多的细小对象,增加了系统的复杂度。
Java类库中的应用:
java.io.InputStream、 OutputStream、 Reader 和 Writer 的所有代码都有以自身类型的对象作为参数的构造函数。java.util.Collections; checkedXXX()、 synchronizedXXX() 和 unmodifiableXXX() 方法。javax.servlet.http.HttpServletRequestWrapper 和 HttpServletResponseWrapper。
识别方法:装饰可通过以当前类或对象为参数的创建方法或构造函数来识别。

外观模式:也称为"门面模式"。一种结构型设计模式, 能为程序库、 框架或其他复杂类提供一个简单的接口。
我们都知道类与类之间的耦合越低,那么可复用性就越好,如果两个类不必彼此通信,那么就不要让这两个类发生直接的相互关系,如果需要调用里面的方法,可以通过第三者来转发调用。外观模式非常好的诠释了这段话。外观模式提供了一个统一的接口,用来访问子系统中的一群接口。它让一个应用程序中子系统间的相互依赖关系减少到了最少,它给子系统提供了一个简单、单一的屏障,客户通过这个屏障来与子系统进行通信。通过使用外观模式,使得客户对子系统的引用变得简单了,实现了客户与子系统之间的松耦合。但是它违背了“开闭原则”,因为增加新的子系统可能需要修改外观类或客户端的源代码。
Java类库中的应用:
javax.faces.context.FacesContext在底层使用了LifeCycle、ViewHandler和NavigationHandler这几个类,但绝大多数客户端不知道。javax.faces.context.ExternalContext在内部使用了ServletContext、HttpSession、HttpServletRequest、HttpServletResponse和其他一些类。
识别方法:外观可以通过使用简单接口, 但将绝大部分工作委派给其他类的类来识别。 通常情况下, 外观管理着其所使用的对象的完整生命周期。

享元模式:一种结构型设计模式, 它摒弃了在每个对象中保存所有数据的方式, 通过共享多个对象所共有的相同状态, 让你能在有限的内存容量中载入更多对象。
在一个系统中对象会使得内存占用过多,特别是那些大量重复的对象,这就是对系统资源的极大浪费。享元模式对对象的重用提供了一种解决方案,它使用共享技术对相同或者相似对象实现重用。享元模式就是运行共享技术有效地支持大量细粒度对象的复用。系统使用少量对象,而且这些都比较相似,状态变化小,可以实现对象的多次复用。这里有一点要注意:享元模式要求能够共享的对象必须是细粒度对象。享元模式通过共享技术使得系统中的对象个数大大减少了,同时享元模式使用了内部状态和外部状态,同时外部状态相对独立,不会影响到内部状态,所以享元模式能够使得享元对象在不同的环境下被共享。同时正是分为了内部状态和外部状态,享元模式会使得系统变得更加复杂,同时也会导致读取外部状态所消耗的时间过长。
Java类库中的应用:
java.lang.Integer#valueOf(int)]以及Boolean、Byte、Character、Short、Long和BigDecimal
识别方法: 享元可以通过构建方法来识别, 它会返回缓存对象而不是创建新的对象。

代理模式:一种结构型设计模式, 让你能够提供对象的替代品或其占位符。 代理控制着对于原对象的访问, 并允许在将请求提交给对象前后进行一些处理。
代理模式就是给一个对象提供一个代理,并由代理对象控制对原对象的引用。它使得客户不能直接与真正的目标对象通信。代理对象是目标对象的代表,其他需要与这个目标对象打交道的操作都是和这个代理对象在交涉。代理对象可以在客户端和目标对象之间起到中介的作用,这样起到了的作用不仅保护了目标对象,同时也在一定程度上面减少了系统的耦合度。
Java类库中的应用:
java.lang.reflect.Proxyjava.rmi.*javax.ejb.EJBjavax.inject.Injectjavax.persistence.PersistenceContext
识别方法:代理模式会将所有实际工作委派给一些其他对象。 除非代理是某个服务的子类, 否则每个代理方法最后都应该引用一个服务对象。

责任链模式:亦称"职责链模式" 。一种行为设计模式, 允许你将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
职责链模式描述的请求如何沿着对象所组成的链来传递的。它将对象组成一条链,发送者将请求发给链的第一个接收者,并且沿着这条链传递,直到有一个对象来处理它或者直到最后也没有对象处理而留在链末尾端。避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止,这就是职责链模式。在职责链模式中,使得每一个对象都有可能来处理请求,从而实现了请求的发送者和接收者之间的解耦。同时职责链模式简化了对象的结构,它使得每个对象都只需要引用它的后继者即可,而不必了解整条链,这样既提高了系统的灵活性也使得增加新的请求处理类也比较方便。但是在职责链中我们不能保证所有的请求都能够被处理,而且不利于观察运行时特征。
Java类库中的应用:
javax.servlet.Filter#doFilter()java.util.logging.Logger#log()
识别方法:该模式可通过一组对象的行为方法间接调用其他对象的相同方法来识别, 而且所有对象都会遵循相同的接口。

命令模式:一种行为设计模式, 它可将请求转换为一个包含与请求相关的所有信息的独立对象。 该转换让你能根据不同的请求将方法参数化、 延迟请求执行或将其放入队列中, 且能实现可撤销操作。
有些时候我们想某个对象发送一个请求,但是我们并不知道该请求的具体接收者是谁,具体的处理过程是如何的,们只知道在程序运行中指定具体的请求接收者即可,对于这样将请求封装成对象的我们称之为命令模式。所以命令模式将请求封装成对象,以便使用不同的请求、队列或者日志来参数化其他对象。同时命令模式支持可撤销的操作。
命令模式可以将请求的发送者和接收者之间实现完全的解耦,发送者和接收者之间没有直接的联系,发送者只需要知道如何发送请求命令即可,其余的可以一概不管,甚至命令是否成功都无需关心。同时我们可以非常方便的增加新的命令,但是可能就是因为方便和对请求的封装就会导致系统中会存在过多的具体命令类。
Java类库中的应用:
-
java.lang.Runnable -
javax.swing.Action
识别方法: 命令模式可以通过抽象或接口类型 (发送者) 中的行为方法来识别, 该类型调用另一个不同的抽象或接口类型 (接收者) 实现中的方法, 该实现则是在创建时由命令模式的实现封装。 命令类通常仅限于一些特殊行为。

迭代器模式:一种行为设计模式, 让你能在不暴露集合底层表现形式 (列表、 栈和树等) 的情况下遍历集合中所有的元素。
对于迭代在编程过程中我们经常用到,能够游走于聚合内的每一个元素,同时还可以提供多种不同的遍历方式,这就是迭代器模式的设计动机。在我们实际的开发过程中,我们可能会需要根据不同的需求以不同的方式来遍历整个对象,但是我们又不希望在聚合对象的抽象接口中充斥着各种不同的遍历操作,于是我们就希望有某个东西能够以多种不同的方式来遍历一个聚合对象,这时迭代器模式出现了。
何为迭代器模式?所谓迭代器模式就是提供一种方法顺序访问一个聚合对象中的各个元素,而不是暴露其内部的表示。迭代器模式是将迭代元素的责任交给迭代器,而不是聚合对象,我们甚至在不需要知道该聚合对象的内部结构就可以实现该聚合对象的迭代。通过迭代器模式,使得聚合对象的结构更加简单,它不需要关注它元素的遍历,只需要专注它应该专注的事情,这样就更加符合单一职责原则了。
Java类库中的应用:
java.util.Iteratorjava.util.Scannerjava.util.Enumeration
识别方法:迭代器可以通过导航方法 (例如 next和 previous等) 来轻松识别。 使用迭代器的客户端代码可能没有其所遍历的集合的直接访问权限。

中介者模式:一种行为设计模式, 能让你减少对象之间混乱无序的依赖关系。 该模式会限制对象之间的直接交互, 迫使它们通过一个中介者对象进行合作。
租房各位都有过的经历吧!在这个过程中中介结构扮演着很重要的角色,它在这里起到一个中间者的作用,给我们和房主互相传递信息。在外面软件的世界里同样需要这样一个中间者。在我们的系统中有时候会存在着对象与对象之间存在着很强、复杂的关联关系,如果让他们之间有直接的联系的话,必定会导致整个系统变得非常复杂,而且可扩展性很差!在前面我们就知道如果两个类之间没有不必彼此通信,我们就不应该让他们有直接的关联关系,如果实在是需要通信的话,我们可以通过第三者来转发他们的请求。同样,这里我们利用中介者来解决这个问题。
所谓中介者模式就是用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。在中介者模式中,中介对象用来封装对象之间的关系,各个对象可以不需要知道具体的信息通过中介者对象就可以实现相互通信。它减少了对象之间的互相关系,提供了系统可复用性,简化了系统的结构。
在中介者模式中,各个对象不需要互相知道了解,他们只需要知道中介者对象即可,但是中介者对象就必须要知道所有的对象和他们之间的关联关系,正是因为这样就导致了中介者对象的结构过于复杂,承担了过多的职责,同时它也是整个系统的核心所在,它有问题将会导致整个系统的问题。所以如果在系统的设计过程中如果出现“多对多”的复杂关系群时,千万别急着使用中介者模式,而是要仔细思考是不是您设计的系统存在问题。
Java类库中的应用:
-
java.util.Timer -
java.util.concurrent.Executor#execute() -
java.util.concurrent.ExecutorService -
java.util.concurrent.ScheduledExecutorService(invokeXXX()和submit()方法) -
java.lang.reflect.Method#invoke()

备忘录模式:一种行为设计模式, 允许在不暴露对象实现细节的情况下保存和恢复对象之前的状态。
后悔药人人都想要,但是事实却是残酷的,根本就没有后悔药可买,但是也不仅如此,在软件的世界里就有后悔药!备忘录模式就是一种后悔药,它给我们的软件提供后悔药的机制,通过它可以使系统恢复到某一特定的历史状态。
所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。它实现了对信息的封装,使得客户不需要关心状态保存的细节。保存就要消耗资源,所以备忘录模式的缺点就在于消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
Java类库中的应用:
- 所有
java.io.Serializable的实现都可以模拟备忘录 - 所有
javax.faces.component.StateHolder的实现
观察者模式:亦称"事件订阅者"/"监听者"/"Event-Subscriber"/"Listener"/"Observer"。是一种行为设计模式, 允许你定义一种订阅机制, 可在对象事件发生时通知多个"观察"该对象的其他对象。
何谓观察者模式?观察者模式定义了对象之间的一对多依赖关系,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并且自动更新。在这里,发生改变的对象称之为观察目标,而被通知的对象称之为观察者。一个观察目标可以对应多个观察者,而且这些观察者之间没有相互联系,所以么可以根据需要增加和删除观察者,使得系统更易于扩展。所以观察者提供了一种对象设计,让主题和观察者之间以松耦合的方式结合。
Java类库中的应用:
java.util.Observer/java.util.Observable(极少在真实世界中使用)java.util.EventListener的所有实现(几乎广泛存在于Swing组件中)javax.servlet.http.HttpSessionBindingListenerjavax.servlet.http.HttpSessionAttributeListenerjavax.faces.event.PhaseListener

状态模式:一种行为设计模式, 让你能在一个对象的内部状态变化时改变其行为, 使其看上去就像改变了自身所属的类一样。
在很多情况下我们对象的行为依赖于它的一个或者多个变化的属性,这些可变的属性我们称之为状态,也就是说行为依赖状态,即当该对象因为在外部的互动而导致他的状态发生变化,从而它的行为也会做出相应的变化。对于这种情况,我们是不能用行为来控制状态的变化,而应该站在状态的角度来思考行为,即是什么状态就要做出什么样的行为。这个就是状态模式。
所以状态模式就是允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
在状态模式中我们可以减少大块的if…else语句,它是允许态转换逻辑与状态对象合成一体,但是减少if…else语句的代价就是会换来大量的类,所以状态模式势必会增加系统中类或者对象的个数。同时,状态模式是将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。但是这样就会导致系统的结构和实现都会比较复杂,如果使用不当就会导致程序的结构和代码混乱,不利于维护。
Java类库中的应用:
javax.faces.lifecycle.LifeCycle#execute()(由FacesServlet控制,行为依赖于当前JSF生命周期的阶段(状态))。
识别方法:状态模式可通过受外部控制且能根据对象状态改变行为的方法来识别。

策略模式:一种行为设计模式, 它能让你定义一系列算法, 并将每种算法分别放入独立的类中, 以使算法的对象能够相互替换。
我们知道一件事可能会有很多种方式来实现它,但是其中总有一种最高效的方式,在软件开发的世界里面同样如此,我们也有很多中方法来实现一个功能,但是我们需要一种简单、高效的方式来实现它,使得系统能够非常灵活,这就是策略模式。
策略模式就是定义了算法族,分别封装起来,让他们之前可以互相转换,此模式然该算法的变化独立于使用算法的客户。在策略模式中它将这些解决问题的方法定义成一个算法群,每一个方法都对应着一个具体的算法,这里的一个算法我就称之为一个策略。虽然策略模式定义了算法,但是它并不提供算法的选择,即什么算法对于什么问题最合适这是策略模式所不关心的,所以对于策略的选择还是要客户端来做。客户必须要清楚的知道每个算法之间的区别和在什么时候什么地方使用什么策略是最合适的,这样就增加客户端的负担。同时,策略模式也非常完美的符合了"开闭原则",用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。但是一个策略对应一个类将会是系统产生很多的策略类。
Java类库中的应用:
-
对
java.util.Comparator#compare()的调用来自Collections#sort()。 -
javax.servlet.http.HttpServlet#service()方法, 还有接受HttpServletRequest和HttpServletResponse对象作为参数的doXXX()方法。 -
javax.servlet.Filter#doFilter()。
识别方法: 策略模式可以通过允许嵌套对象完成实际工作的方法以及允许将该对象替换为不同对象的设置器来识别。

模板方法模式:是一种行为设计模式, 它在超类中定义了一个算法的框架(骨架), 允许子类在不修改结构的情况下重写算法的特定步骤。
有些时候我们做某几件事情的步骤都差不多,仅有那么一小点的不同,在软件开发的世界里同样如此,如果我们都将这些步骤都一一做的话,费时费力不讨好。所以我们可以将这些步骤分解、封装起来,然后利用继承的方式来继承即可,当然不同的可以自己重写实现嘛!这就是模板方法模式提供的解决方案。
所谓模板方法模式就是在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。模板方法模式就是基于继承的代码复用技术的。在模板方法模式中,我们可以将相同部分的代码放在父类中,而将不同的代码放入不同的子类中。也就是说我们需要声明一个抽象的父类,将部分逻辑以具体方法以及具体构造函数的形式实现,然后声明一些抽象方法让子类来实现剩余的逻辑,不同的子类可以以不同的方式来实现这些逻辑。所以模板方法的模板其实就是一个普通的方法,只不过这个方法是将算法实现的步骤封装起来的。
Java类库中的应用:
java.io.InputStream、java.io.OutputStream、java.io.Reader和java.io.Writer的所有非抽象方法java.util.AbstractList、java.util.AbstractSet和java.util.AbstractMap的所有非抽象方法javax.servlet.http.HttpServlet,所有默认发送HTTP 405"方法不允许"错误响应的doXXX()方法,你可随时对其进行重写
识别方法:模版方法可以通过行为方法来识别,该方法已有一个在基类中定义的"默认"行为。

-
泛化关系(继承关系):带三角箭头的实线,箭头指向父类。
-
实现关系**:带三角箭头的虚线,箭头指向接口**。
-
关联关系:
- 双向关联**:有两个普通箭头或者没有箭头的实线。**
- 单向关联**:带普通箭头的实线,指向被拥有者。**
-
聚合关系:是整体与部分的关系,且部分可以离开整体而单独存在。聚合是一种强的关联关系。
- 带空心菱形的实心线,菱形指向整体。
-
组合关系:是整体与部分的关系,但部分不能离开整体而单独存在。组合是一种比聚合还要强的关联关系。
- 带实心菱形的实线,菱形指向整体。
-
依赖关系:是一种使用的关系,即一个类的实现需要另一个类的协助。
- 带普通箭头的虚线,指向被使用者。
-
可见性:
- public:+
- protected:#
- private:-
- package:~
- IDEA安装PlantUML-integration插件。
- 安装Graphviz软件。
- 学习PlantUML语法。
- 依赖关系:
..> - 继承关系:
--|> - 实现关系:
..|> - 关联关系:
Computer --> Mouse - 聚合关系:
Person o-- IDCard - 组合关系:
Person *-- Head
- 依赖关系:
参考文章博客:JDK里的设计模式、《HeadFirst设计模式》、UML类图、设计模式总结、PlantUML使用教程、PlantUML官方教程、设计模式的学习、设计模式英文教程
程序:是指令和数据的有序集合,本身没有任何运行含义,是一个静态的概念。
进程:程序执行的过程,是一个动态的概念。进程是系统资源分配的单位,一个进程中可以包含多个线程。
- 进程是操作系统分配资源的最小单元。
- 一个程序至少有一个进程,一个进程至少有一个线程。
线程:线程是CPU调度和执行的单位。Java默认有2个线程(main和gc)。Java本身并不能真正开启线程,底层通过native本地方法使用C语言开启线程。
- 线程是操作系统调度的最小单元。
并发:CPU一核,模拟出来多条线程,快速交替。(查看CPU的核数:Runtime.getRuntime().availableProcessors())。并发编程的本质是充分利用CPU的资源。
并行:CPU多核,多个线程可以同时执行。(使用线程池提高性能)
线程创建的三种方式:
- Thread类
# 1. 自定义线程类继承Thread类
# 2. 重写Run方法,编写线程执行体
# 3. 创建线程对象,调用start方法启动线程- Runnable接口
# 1. 实现Runnable接口
# 2. 实现重写Run方法,编写线程执行体
# 3. 创建线程对象,调用start方法启动线程
这里与Thread类有区别:Runnable实现类必须作为Thread类的构造参数;本质是Thread类实现了Runnable接口。
# 注意:避免单继承局限性,推荐使用Runnable接口- Callable接口
# 1. 实现Callable接口,需要返回值类型
# 2. 重写call方法,需要抛出异常
# 3. 创建目标对象
# 4. 创建执行服务(线程池): ExecutorService service = Executors.newFixedThreadPool(1);
# 5. 提交执行(submit方法): Future<返回值类型> result1 = service.submit(t1);
# 6. 获取结果: 返回值类型 r1 = result1.get();
# 7. 关闭服务: service.shutdownNow();
# Callable的好处:可以定义返回值;可以抛出异常静态代理模式:
Lamda表达式:
线程的六种状态:
- 创建(NEW):新创建了一个线程对象,但还没有调用start()方法。
- 运行(RUNNABLE):Java线程中将就绪(READY)和运行中(RUNNING)两种状态笼统的称为"运行"。
- 阻塞(BLOCKED):表示线程阻塞于锁。
- 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
- 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
- 死亡(TERMINATED):表示该线程已经执行完毕。

# 1. 如何停止线程?
# 1.1 不建议使用stop方法(已废弃)
# 1.2 建议线程正常停止(可以利用循环次数控制,不建议死循环)
# 1.3 或者使用标志位
# 2. 线程休眠(sleep)
# 2.1 sleep(时间)指定当前线程阻塞的毫秒数
# 2.2 sleep存在异常InterruptedException
# 2.3 sleep时间达到后线程进入就绪状态
# 2.4 sleep可以模拟网络延时、倒计时等
# 2.5 每一个对象都有一个锁,sleep不会释放锁
# 3. 线程礼让(yield)
# 3.1 礼让线程,让当前正在执行的线程暂停,但不阻塞
# 3.2 将线程从运行状态转为就绪状态
# 3.3 让CPU重新调度,例如不一定成功,看CPU心情
# 4. 线程强制执行(join)
# 4.1 Join合并线程,待此线程执行完成后,再执行其他线程,其他线程阻塞(类似于插队)
# 5. 常见的与线程相关的方法
# 5.1 获取当前线程的名称:Thread.currentThread().getName()
# 5.2 获取线程状态的方法:thread.getState()
# 5.3 设置/获取线程的优先级:setPriority(int xxx),getPriority(),默认优先级是5守护线程:
- 线程分为用户线程和守护线程(使用**setDaemon(true)**可以设置为守护线程)。
- 虚拟机必须确保用户线程执行完毕(如main方法为用户线程)。
- 虚拟机不用等待守护线程执行完毕(如gc方法为守护线程)。
- 守护线程的应用:后台记录操作日志、监控内存、垃圾回收...
使用锁机制(synchronized)解决同步必然会带来如下问题:
- 一个线程持有锁会导致其他所有需要此锁的线程挂起。
- 在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,会引起性能问题。
- 如果一个优先级高的线程等待一个优先级低的线程释放锁,会导致优先级倒置,引起性能问题。
同步方法:在方法上添加synchronized关键字。若将一个大的方法声明为synchronized将会影响效率。
同步块:
- 在代码块上添加synchronized(同步监视器)。
- 同步监视器可以是任何对象,但是推荐使用共享资源作为同步监视器。
- 同步方法中无需指定同步监视器,因为同步方法的同步监视器就是this。
死锁:多个线程各自占有一些共享资源,并且互相等待其他线程占有的资源才能运行,而导致两个或者多个线程都在等待对方释放资源,都停止执行的情形。某一个同步块同时拥有"两个以上对象的锁"时,就可能会发生"死锁"问题。
产生死锁的四个必要条件:
- 互斥条件:即当资源被一个线程使用(占有)时,别的线程不能使用。
- 不可抢占:资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占用者主动释放。
- 请求和保持:当资源的请求者在请求其他的资源的同时保持对原有资源的占有。
- 循环等待:即存在一个等待队列, P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。
关于Lock锁:
- 从jdk5.0开始,Java提供了更强大的线程同步机制:通过显示定义同步锁对象来实现同步,同步锁使用Lock对象充当。
- java.util.concurrent.locks.Lock接口是控制多个线程对共享资源进行访问的工具。锁提供了对共享资源的独立访问,每次只能有一个线程对Lock对象加锁,线程开始访问共享资源之前应先获得Lock对象。
- ReentrantLock类实现了Lock,它拥有与synchronized相同的并发性和内存语义,在实现线程安全的控制中,比较常用的是ReentrantLock,可以显示加锁(lock()方法)和释放锁(unlock()方法)。
synchronized与Lock的对比:
- 类型不同:synchronized是内置的java关键字;Lock是一个类。
- 使用灵活性不同:synchronized无法判断获取锁的状态;Lock可以判断是否获取到了锁。
- 使用方法不用:synchronized是隐式锁,出了作用域自动释放;Lock是显示锁(需手动开启和释放锁,如果不释放锁,会造成死锁)。
- 锁的限制不同:synchronized加锁后,若线程没获取到锁,会一致等待下去;Lock锁不一定会等待下去(
lock.tryLock()方法)。 - 锁的类型不同:synchronized是可重入锁,不可中断的,非公平锁;Lock锁是可重入锁,但是可以判断锁,是非公平锁(可以自己设置)。(公平锁与非公平锁:公平锁遵循先来后到;非公平锁可以"插队"(Java默认是非公平锁))
- 使用范围不同:synchronized有代码块锁和方法锁;Lock只有代码块锁。
- 使用场景不同:synchronized适合锁少量的代码同步问题;Lock适合锁大量的同步代码(JVM将花费较少的时间来调度线程),此外Lock锁具有更好的扩展性(提供更多的子类)。优先使用顺序:Lock-->同步代码块-->同步方法。
- 线程通信:生产者与消费者问题
- 使用以下几个方法解决线程之间的通信问题:wait()/wait(long timeout),notify()/notifyAll()。
- 与sleep方法不同,wait方法会释放锁。
- 有两种解决生产者与消费者问题的方法:管程法、信号灯法。
常见的线程池技术:c3p0、Druid。
volatile: volatile修饰的变量不允许线程内部缓存和重排序,只能直接修改内存,所以对其他线程是可见的;但是,volatile只能让被他修饰的内容具有可见性,但不能保证它具有原子性。例如volatile int a = 0; ,之后有一个操作a++;,这个变量a具有可见性,但是a++;依然是一个非原子操作,也就是这个操作同样存在线程安全的问题。此外,volatile还可以禁止指令重排序,可以使用volatile和synchronized两个关键字来保证线程之间操作的有序性。
transient:将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会被序列化。
JUC,是指jdk里的三个与多线程有关的工具包:java.util.concurrent、java.util.concurrent.atomic、java.util.concurrent.locks。
关于多线程开发:企业级开发为了降低耦合度,线程就是一个单独的资源类,没有任何附属的操作。
**
* 真正的多线程开发,公司中的开发,降低耦合性。线程就是一个单独的资源类,没有任何附属的操作!
*
*/
public class SaleTicketDemo01 {
public static void main(String[] args) {
// 并发:多线程操作同一个资源类, 把资源类丢入线程
Ticket ticket = new Ticket();
// @FunctionalInterface 函数式接口,jdk1.8 lambda表达式 (参数)->{ 代码 }
new Thread(()->{
for (int i = 1; i < 40 ; i++) {
ticket.sale();
}
},"A").start();
new Thread(()->{
for (int i = 1; i < 40 ; i++) {
ticket.sale();
}
},"B").start();
new Thread(()->{
for (int i = 1; i < 40 ; i++) {
ticket.sale();
}
},"C").start();
}
}
// 资源类 OOP
class Ticket {
// 属性、方法
private int number = 30;
// 卖票的方式
// synchronized 本质: 队列,锁
public synchronized void sale(){ // synchronized可以换成lock锁
if (number>0){
System.out.println(Thread.currentThread().getName()+"卖出了"+(number--)+"票,剩余:"+number);
}
}
}面试高频点:单例模式、排序算法、生产者和消费者、死锁。
生产者消费者中的虚假唤醒问题:
/**
* 线程之间的通信问题:生产者和消费者问题,等待唤醒,通知唤醒
* 线程交替执行:A、B 操作同一个变量num = 0
* A num+1
* B num-1
*/
public class A {
public static void main(String[] args) {
Data data = new Data();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"A").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"B").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"C").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"D").start();
}
}
// 判断等待,业务,通知
class Data{ // 数字 资源类
private int number = 0;
public synchronized void increment() throws InterruptedException { //+1
if (number!=0){ //0 (将if改为while即可解决虚假唤醒问题)
this.wait(); // 等待
}
number++;
System.out.println(Thread.currentThread().getName()+"=>"+number);
this.notifyAll(); // 通知其他线程,我+1完毕了
}
public synchronized void decrement() throws InterruptedException { //-1
if (number==0){ // 1 (将if改为while即可解决虚假唤醒问题)
this.wait(); // 等待
}
number--;
System.out.println(Thread.currentThread().getName()+"=>"+number);
this.notifyAll(); // 通知其他线程,我-1完毕了
}
}若有A、B、C、D四个线程,且Data类中increment和decrement在if条件中等待唤醒,则会出现虚假唤醒的问题。具体原因可以参见jdk文档中的解释:
// 以下解释来源于jdk文档:
// 线程也可以唤醒,而不会被通知、中断或超时,即所谓的虚假唤醒。虽然这在实践中很少发生,但应用程序必须通过测试应该使线程被唤醒的条件来防范,并且如果条件不满足则继续等待。换句话说,等待应该总是出现在循环中,类似这样:
synchronized (obj) {
while (<condition does not hold>){
obj.wait(timeout);
}
...
}
// 关于生产者消费者中的虚假唤醒问题:将if改为while即可解决虚假唤醒问题。关于Condition接口:Condition接口位于java.util.concurrent.locks包下。jdk文档中是这么解释Condition接口的:Condition因素出Object监视器方法( wait , notify和notifyAll )成不同的对象,以得到具有多个等待集的每个对象,通过将它们与使用任意的组合的效果Lock个实现。 Lock替换synchronized方法和语句的使用, Condition取代了对象监视器方法的使用。

public class B {
public static void main(String[] args) {
Data2 data = new Data2();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"A").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"B").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"C").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"D").start();
}
}
// 判断等待,业务,通知
class Data2{ // 数字 资源类
private int number = 0;
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
//+1
public void increment() throws InterruptedException {
lock.lock();
try {
while (number!=0){ //0
condition.await(); // 等待
}
number++;
System.out.println(Thread.currentThread().getName()+"=>"+number);
condition.signalAll(); // 通知其他线程,我+1完毕了
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
//-1
public synchronized void decrement() throws InterruptedException {
lock.lock();
try {
while (number==0){ // 1
condition.await(); // 等待
}
number--;
System.out.println(Thread.currentThread().getName()+"=>"+number);
condition.signalAll(); // 通知其他线程,我-1完毕了
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}使用Condition可以实现精准通知和唤醒。
/**
* A 执行完调用B,B执行完调用C,C执行完调用A
*/
public class C {
public static void main(String[] args) {
Data3 data = new Data3();
new Thread(()->{
for (int i = 0; i <10 ; i++) {
data.printA();
}
},"A").start();
new Thread(()->{
for (int i = 0; i <10 ; i++) {
data.printB();
}
},"B").start();
new Thread(()->{
for (int i = 0; i <10 ; i++) {
data.printC();
}
},"C").start();
}
}
class Data3{ // 资源类 Lock
private Lock lock = new ReentrantLock();
private Condition condition1 = lock.newCondition();
private Condition condition2 = lock.newCondition();
private Condition condition3 = lock.newCondition();
private int number = 1; // 1A 2B 3C
public void printA(){
lock.lock();
try {
// 业务,判断-> 执行-> 通知
while (number!=1){
// 等待
condition1.await();
}
System.out.println(Thread.currentThread().getName()+"=>AAAAAAA");
number = 2;
condition2.signal(); // 唤醒,唤醒指定的人,B
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printB(){
lock.lock();
try {
// 业务,判断-> 执行-> 通知
while (number!=2){
condition2.await();
}
System.out.println(Thread.currentThread().getName()+"=>BBBBBBBBB");
number = 3;
condition3.signal(); // 唤醒,唤醒指定的人,c
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printC(){
lock.lock();
try {
// 业务,判断-> 执行-> 通知
while (number!=3){
condition3.await();
}
System.out.println(Thread.currentThread().getName()+"=>BBBBBBBBB");
number = 1;
condition1.signal(); // 唤醒,唤醒指定的人,A
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}synchronized 修饰方法:锁的是this对象(不唯一)。
static + synchronized 修饰方法:锁的是Class对象(唯一)。
ArrayList:并发下ArrayList是不安全的,会抛出java.util.ConcurrentModificationException并发修改异常。解决方法有以下几种方式:
-
第1种解决方法:使用Vector代替ArrayList(Vector出现的比ArrayList早,那ArrayList存在的意义?)。
-
第2种解决方法:使用集合工具类
Collections.synchronizedList(List<T> list)。 -
第3种解决方法:使用JUC下的CopyOnWriteArrayList类(CopyOnWrite写入时复制,简称COW,是计算机程序设计领域的一种优化策略,在写入的时候避免覆盖造成的数据问题)。CopyOnWriteArrayList使用Lock锁,效率更高;而Vector使用的是synchronized锁,效率低。
HashSet:并发下HashSet也是不安全的,会抛出java.util.ConcurrentModificationException并发修改异常。解决方法有以下几种方式:
- 第1种解决办法:使用集合工具类
Collections.synchronizedSet(Set<T> set)。 - 第2种解决办法:使用JUC下的CopyOnWriteArraySet类(写入时复制)。
HashMap:并发下HashMap(HashMap的加载因子与初始化容量?)也是不安全的,会抛出java.util.ConcurrentModificationException并发修改异常。解决方法有以下几种方式:
- 第1种解决方法:使用集合工具类
Collections.synchronizedMap(Map<K,V> m)。 - 第2种解决办法:使用JUC下的ConcurrentHashMap类(ConcurrentHashMap的原理?)。
Collable:可以有返回值;可以抛出异常;call方法(类似于Runnable种的run方法)。
注意事项:
- Collable的执行结果会被缓存。
- 获取返回结果可能需要等待,从而会导致阻塞。
public class CallableTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// new Thread(new Runnable()).start();
// new Thread(new FutureTask<V>()).start();
// new Thread(new FutureTask<V>( Callable )).start();
new Thread().start(); // 怎么启动Callable
MyThread thread = new MyThread();
FutureTask futureTask = new FutureTask(thread); // 适配类
new Thread(futureTask,"A").start();
new Thread(futureTask,"B").start(); // 结果会被缓存,效率高
Integer o = (Integer) futureTask.get(); //这个get 方法可能会产生阻塞!把他放到最后;或者使用异步通信来处理!
System.out.println(o);
}
}
class MyThread implements Callable<Integer> {
@Override
public Integer call() {
System.out.println("call()"); // 会打印几个call
// 耗时的操作
return 1024;
}
}CountDownLatch(减法计数器,也称倒计时器):允许一个或多个线程等待直到在其他线程中执行的一组操作完成的同步辅助。
原理:每次有线程调用countDown方法,则数量减1;若计数器变为0,await方法就会被唤醒,继续执行。
- countDownLatch.countDown():数量-1;
- countDownLatch.await():等待计数器归0,然后再往下执行。
// 计数器
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
// 总数是6,必须要执行任务的时候,再使用!
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 1; i <=6 ; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+" Go out");
countDownLatch.countDown(); // 数量-1
},String.valueOf(i)).start();
}
countDownLatch.await(); // 等待计数器归零,然后再向下执行
System.out.println("Close Door");
}
}CyclicBarrier(加法计数器,也称栅栏):允许一组线程全部等待彼此达到共同屏障点的同步辅助。 循环阻塞在涉及固定大小的线程方的程序中很有用,这些线程必须偶尔等待彼此。 屏障被称为循环 ,因为它可以在等待的线程被释放之后重新使用。
public class CyclicBarrierDemo {
public static void main(String[] args) {
/**
* 集齐7颗龙珠召唤神龙
*/
// 召唤龙珠的线程
CyclicBarrier cyclicBarrier = new CyclicBarrier(8,()->{
System.out.println("召唤神龙成功!");
});
for (int i = 1; i <=7 ; i++) {
final int temp = i;
// lambda能操作到 i 吗?不能,需要通过中间变量temp
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"收集"+temp+"个龙珠");
try {
cyclicBarrier.await(); // 等待
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}Semaphore(信号量,用于限流):一个计数信号量。 在概念上,信号量维持一组许可证。 如果有必要,每个acquire()都会阻塞,直到许可证可用,然后才能使用它。 每个release()添加许可证,潜在地释放阻塞获取方。 但是,没有使用实际的许可证对象;Semaphore只保留可用数量的计数,并相应地执行。
原理:常用于多个共享资源的互斥(例如抢车位)。
- semaphore.acquire():获得,如果已经满了,等待被释放为止。
- semaphore.release():释放,会将当前的信号量释放+1,然后唤醒等待的线程。
public class SemaphoreDemo {
public static void main(String[] args) {
// 线程数量:停车位! 限流!
Semaphore semaphore = new Semaphore(3);
for (int i = 1; i <=6 ; i++) {
new Thread(()->{
// acquire() 得到
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"抢到车位");
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName()+"离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(); // release() 释放
}
},String.valueOf(i)).start();
}
}
}ReadWriteLock:维护一对关联的locks,一个用于只读操作,一个用于写入操作。 read lock可以由多个阅读器线程同时进行,只要没有作者。 write lock是独家的。
独占锁:写锁。
共享锁:读锁。
/**
* 独占锁(写锁) 一次只能被一个线程占有
* 共享锁(读锁) 多个线程可以同时占有
* ReadWriteLock
* 读-读 可以共存!
* 读-写 不能共存!
* 写-写 不能共存!
*/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
// 写入
for (int i = 1; i <= 5 ; i++) {
final int temp = i;
new Thread(()->{
myCache.put(temp+"",temp+"");
},String.valueOf(i)).start();
}
// 读取
for (int i = 1; i <= 5 ; i++) {
final int temp = i;
new Thread(()->{
myCache.get(temp+"");
},String.valueOf(i)).start();
}
}
}
// 加锁的
class MyCacheLock{
private volatile Map<String,Object> map = new HashMap<>();
// 读写锁: 更加细粒度的控制
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private Lock lock = new ReentrantLock();
// 存,写入的时候,只希望同时只有一个线程写
public void put(String key,Object value){
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"写入"+key);
map.put(key,value);
System.out.println(Thread.currentThread().getName()+"写入OK");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
// 取,读,所有人都可以读!
public void get(String key){
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"读取"+key);
Object o = map.get(key);
System.out.println(Thread.currentThread().getName()+"读取OK");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}阻塞队列:遵循FIFO。放入时若队列已满,则必须阻塞等待;取出时若队列是空的,则必须阻塞等待放入。
BlockingQueue(阻塞队列)的实现类:ArrayBlockingQueue(数组阻塞队列)、LinkedBlockingQueue(链表阻塞队列)、SynchronousQueue(同步阻塞队列)。
阻塞队列的应用:多线程并发处理、线程池。
阻塞队列的四组API:
| 方式 | 抛出异常 | 有返回值,不抛出异常 | 阻塞等待 | 超时等待 |
|---|---|---|---|---|
| 添加 | add | offer() | put() | offer(,,) |
| 移除 | remove | poll() | take() | poll(,) |
| 检测队首元素 | element | peek | - | - |
- 抛出异常。
- 不会抛出异常。
- 阻塞、一直等待。
- 超时等待。
public class Test {
public static void main(String[] args) throws InterruptedException {
test4();
}
public static void test1(){ // 抛出异常
// 队列的大小
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.add("a"));
System.out.println(blockingQueue.add("b"));
System.out.println(blockingQueue.add("c"));
// IllegalStateException: Queue full 抛出异常!
// System.out.println(blockingQueue.add("d"));
System.out.println("=-===========");
System.out.println(blockingQueue.element()); // 查看队首元素是谁
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
// java.util.NoSuchElementException 抛出异常!
// System.out.println(blockingQueue.remove());
}
public static void test2(){ // 有返回值,不会抛出异常
// 队列的大小
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.offer("a"));
System.out.println(blockingQueue.offer("b"));
System.out.println(blockingQueue.offer("c"));
System.out.println(blockingQueue.peek());
// System.out.println(blockingQueue.offer("d")); // false 不抛出异常!
System.out.println("============================");
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll()); // null 不抛出异常!
}
public static void test3() throws InterruptedException { // 等待,阻塞(一直阻塞)
// 队列的大小
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
// 一直阻塞
blockingQueue.put("a");
blockingQueue.put("b");
blockingQueue.put("c");
// blockingQueue.put("d"); // 队列没有位置了,一直阻塞
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take()); // 没有这个元素,一直阻塞
}
public static void test4() throws InterruptedException { // 等待,阻塞(等待超时)
// 队列的大小
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
blockingQueue.offer("a");
blockingQueue.offer("b");
blockingQueue.offer("c");
// blockingQueue.offer("d",2,TimeUnit.SECONDS); // 等待超过2秒就退出
System.out.println("===============");
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
blockingQueue.poll(2,TimeUnit.SECONDS); // 等待超过2秒就退出
}
}SynchronousQueue队列:同步队列,和其他BlockingQueue不一样,SynchronousQueue不存储元素,put了一个元素,必须从里面先take取出来,否则不能再put进去值。
/**
* 同步队列
* 和其他的BlockingQueue 不一样, SynchronousQueue 不存储元素
* put了一个元素,必须从里面先take取出来,否则不能再put进去值!
*/
public class SynchronousQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new SynchronousQueue<>(); // 同步队列
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+" put 1");
blockingQueue.put("1");
System.out.println(Thread.currentThread().getName()+" put 2");
blockingQueue.put("2");
System.out.println(Thread.currentThread().getName()+" put 3");
blockingQueue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"T1").start();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
},"T2").start();
}
}线程池面试点**:三大方法、七大参数、四种拒绝策略**。
池化技术:事先准备好一些资源,有人要用,就来这里取,用完之后再还回来。池化技术的本质是优化资源的使用。例如:线程池、连接池、内存池、对象池...
线程池的好处:降低资源的消耗;提高响应速度;方便管理。(总结好处**:线程复用、可以控制最大并发数、管理线程**)
- Executors.newSingleThreadExecutor():创建单个线程。
- Executors.newFixedThreadPool(5):创建一个固定大小的线程池。
- Executors.newCachedThreadPool():创建一个可伸缩的(遇强则强、遇弱则弱)线程池。
阿里巴巴开发手册规定:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
- FixedThreadPool和SingleThreadExecutor:允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
- CachedThreadPool和ScheduledThreadPool:允许创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
三大方法的本质均是调用ThreadPoolExecutor创建线程池,ThreadPoolExecutor的构造器有七大参数:
- int corePoolSize:核心线程的数量。
- int maximumPoolSize:最大核心线程池大小。
最大线程池大小如何设置?:
若是CPU密集型应用:最大线程数=CPU的核数。
若是IO密集型应用:最大线程数>IO线程的数量(一般最大线程数取IO线程的2倍即可)。
- long keepAliveTime:超时了但没有人调用就会释放。
- TimeUnit unit : 超时时间。
- BlockingQueue workQueue:阻塞队列。
- ThreadFactory threadFactory:线程工厂,创建线程的,一般不用动。
- RejectedExecutionHandler handler:拒绝策略。
- new ThreadPoolExecutor.AbortPolicy() :银行满了,还有人进来,不处理这个人的,抛出异常。
- new ThreadPoolExecutor.CallerRunsPolicy():哪来的回哪去,不会抛出异常。
- new ThreadPoolExecutor.DiscardPolicy():队列满了,丢掉任务,不会抛出异常。
- new ThreadPoolExecutor.DiscardOldestPolicy() :队列满了,尝试去和最早的竞争(若竞争四百则丢掉任务),也不会抛出异常。
/**
* new ThreadPoolExecutor.AbortPolicy() // 银行满了,还有人进来,不处理这个人的,抛出异常
* new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里!
* new ThreadPoolExecutor.DiscardPolicy() //队列满了,丢掉任务,不会抛出异常!
* new ThreadPoolExecutor.DiscardOldestPolicy() //队列满了,尝试去和最早的竞争,也不会抛出异常!
*/
public class Demo01 {
public static void main(String[] args) {
// 自定义线程池!工作 ThreadPoolExecutor
// 最大线程到底该如何定义
// 1、CPU 密集型,几核,就是几,可以保持CPu的效率最高!
// 2、IO 密集型 > 判断你程序中十分耗IO的线程,
// 程序 15个大型任务 io十分占用资源!
// 获取CPU的核数
System.out.println(Runtime.getRuntime().availableProcessors());
List list = new ArrayList();
ExecutorService threadPool = new ThreadPoolExecutor(
2,
Runtime.getRuntime().availableProcessors(), // 获取电脑的核数(最大线程数=CPU的核数)
3,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()); //队列满了,尝试去和最早的竞争,也不会抛出异常!
try {
// 最大承载:Deque + max
// 超过 RejectedExecutionException
for (int i = 1; i <= 9; i++) {
// 使用了线程池之后,使用线程池来创建线程
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+" ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 线程池用完,程序结束,关闭线程池
threadPool.shutdown();
}
}
}需要重点掌握**:函数式接口、Lambda表达式、链式编程、Stream流式计算**。
函数式接口:只有一个方法的接口(主要用于简化编程模型,在新版本的框架底层大量应用)。只要是函数式接口就可以用Lambda表达式简化。
Function函数式接口:有一个输入参数,有一个输出参数。
/**
* Function 函数型接口, 有一个输入参数,有一个输出
* 只要是函数型接口,就可以用Lambda表达式简化
*/
public class Demo01 {
public static void main(String[] args) {
//
// Function<String,String> function = new Function<String,String>() {
// @Override
// public String apply(String str) {
// return str;
// }
// };
Function<String,String> function = str->{return str;};
System.out.println(function.apply("asd"));
}
}Predicate断定式接口:有一个输入参数,返回一个boolean类型。
/**
* 断定型接口:有一个输入参数,返回值只能是 布尔值!
*/
public class Demo02 {
public static void main(String[] args) {
// 判断字符串是否为空
// Predicate<String> predicate = new Predicate<String>(){
//// @Override
//// public boolean test(String str) {
//// return str.isEmpty();
//// }
//// };
Predicate<String> predicate = (str)->{return str.isEmpty(); };
System.out.println(predicate.test(""));
}
}Consumer消费型接口:只有输入,没有返回值。
/**
* Consumer 消费型接口: 只有输入,没有返回值
*/
public class Demo03 {
public static void main(String[] args) {
// Consumer<String> consumer = new Consumer<String>() {
// @Override
// public void accept(String str) {
// System.out.println(str);
// }
// };
Consumer<String> consumer = (str)->{System.out.println(str);};
consumer.accept("sdadasd");
}
}Supplier供给型接口:没有输入,只有返回值。
/**
* Supplier 供给型接口 没有参数,只有返回值
*/
public class Demo04 {
public static void main(String[] args) {
// Supplier supplier = new Supplier<Integer>() {
// @Override
// public Integer get() {
// System.out.println("get()");
// return 1024;
// }
// };
Supplier supplier = ()->{ return 1024; };
System.out.println(supplier.get());
}
}大数据:存储 + 计算。集合、MySQL本质是存储,计算都应该交给流来操作。
/**
* 题目要求:一分钟内完成此题,只能用一行代码实现!
* 现在有5个用户!筛选:
* 1、ID 必须是偶数
* 2、年龄必须大于23岁
* 3、用户名转为大写字母
* 4、用户名字母倒着排序
* 5、只输出一个用户!
*/
public class Test {
public static void main(String[] args) {
User u1 = new User(1,"a",21);
User u2 = new User(2,"b",22);
User u3 = new User(3,"c",23);
User u4 = new User(4,"d",24);
User u5 = new User(6,"e",25);
// 集合就是存储
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
// 计算交给Stream流
// lambda表达式、链式编程、函数式接口、Stream流式计算
list.stream()
.filter(u->{return u.getId()%2==0;})
.filter(u->{return u.getAge()>23;})
.map(u->{return u.getName().toUpperCase();})
.sorted((uu1,uu2)->{return uu2.compareTo(uu1);})
.limit(1)
.forEach(System.out::println);
}
}ForkJoin: ForkJoin在jdk1.7中引入的,并行执行任务,提高效率。
ForkJoin特点:工作窃取。原因是底层是采用双端队列实现的。(ForkJoin的具体使用?Stream并行流的具体使用?)
/**
* 求和计算的任务!
* 3000 6000(ForkJoin) 9000(Stream并行流)
* // 如何使用 forkjoin
* // 1、forkjoinPool 通过它来执行
* // 2、计算任务 forkjoinPool.execute(ForkJoinTask task)
* // 3. 计算类要继承 ForkJoinTask
*/
public class ForkJoinDemo extends RecursiveTask<Long> {
private Long start; // 1
private Long end; // 1990900000
// 临界值
private Long temp = 10000L;
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
// 计算方法
@Override
protected Long compute() {
if ((end-start)<temp){
Long sum = 0L;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else { // forkjoin 递归
long middle = (start + end) / 2; // 中间值
ForkJoinDemo task1 = new ForkJoinDemo(start, middle);
task1.fork(); // 拆分任务,把任务压入线程队列
ForkJoinDemo task2 = new ForkJoinDemo(middle+1, end);
task2.fork(); // 拆分任务,把任务压入线程队列
return task1.join() + task2.join();
}
}
}
// 比较几种不同方法的计算速度
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// test1(); // 12224ms
// test2(); // 10038ms
// test3(); // 153ms
}
// 普通程序员
public static void test1(){
Long sum = 0L;
long start = System.currentTimeMillis();
for (Long i = 1L; i <= 10_0000_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
// 会使用ForkJoin
public static void test2() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinDemo(0L, 10_0000_0000L);
ForkJoinTask<Long> submit = forkJoinPool.submit(task);// 提交任务
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
public static void test3(){
long start = System.currentTimeMillis();
// Stream并行流 () (]
long sum = LongStream.rangeClosed(0L, 10_0000_0000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("sum="+"时间:"+(end-start));
}
}Future的设计初衷:对将来的某个事件的结果进行建模。使用Future的实现类CompletableFuture可以实现异步调用。
/**
* 异步调用: CompletableFuture
* // 异步执行
* // 成功回调
* // 失败回调
*/
public class Demo01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 没有返回值的 runAsync 异步回调
// CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(()->{
// try {
// TimeUnit.SECONDS.sleep(2);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// System.out.println(Thread.currentThread().getName()+"runAsync=>Void");
// });
//
// System.out.println("1111");
//
// completableFuture.get(); // 获取阻塞执行结果
// 有返回值的 supplyAsync 异步回调
// ajax,成功和失败的回调
// 返回的是错误信息;
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+"supplyAsync=>Integer");
int i = 10/0;
return 1024;
});
System.out.println(completableFuture.whenComplete((t, u) -> {
System.out.println("t=>" + t); // 正常的返回结果
System.out.println("u=>" + u); // 错误信息:java.util.concurrent.CompletionException: java.lang.ArithmeticException: / by zero
}).exceptionally((e) -> {
System.out.println(e.getMessage());
return 233; // 可以获取到错误的返回结果
}).get());
}
}JMM: Java Memory Model,Java内存模型。
关于JMM的一些同步的约定:
- 线程解锁前,必须把共享变量立刻刷回主存。
- 线程加锁前,必须读取主存中的最新值到工作内存中。
- 加锁和解锁是同一把锁。
线程的工作内存与主内存之间有8种操作:

- lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
- load(载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中。
- use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令。
- assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中。
- store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用。
- write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write。
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存。
- 不允许一个线程将没有assign的数据从工作内存同步回主内存。
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作。
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁。
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值。
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量。
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存。
针对多个线程修改共享变量的情况:若不引入volatile,会出现问题。(引出下节的volatile可以解决这一问题)

volatile:是java虚拟机提供的轻量级的同步机制。有如下三大特性:
- 保证可见性。
public class JMMDemo {
// 不加volatile程序就会死循环
// 加volatile可以保证可见性
private volatile static int num = 0;
public static void main(String[] args) { // main
new Thread(()->{ // 线程 1 对主内存的变化不知道的
while (num==0){
}
}).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
num = 1;
System.out.println(num);
}
}-
不保证原子性(原子性即不可分割,表示线程在执行任务的时候,不能被打扰,也不能被分割,要么同时成功,要么同时失败)。
(数据库里的ACID四大原则?)
**如果不加lock和synchronized,怎么保证原子性?**使用原子类可以保证原子性。原子类的底层直接和操作系统挂钩,会直接在内存中修改值(Unsafe类是一个很特殊的存在)。
**那为什么原子类可以保证原子性?**原子类的底层用的CAS,详见
2.2.18节。
// volatile 不保证原子性
public class VDemo02 {
// volatile 不保证原子性
// 原子类的 Integer
private volatile static AtomicInteger num = new AtomicInteger();
public static void add(){
// num++; // 不是一个原子性操作
num.getAndIncrement(); // AtomicInteger + 1 方法, CAS
}
public static void main(String[] args) {
//理论上num结果应该为 2 万
for (int i = 1; i <= 20; i++) {
new Thread(()->{
for (int j = 0; j < 1000 ; j++) {
add();
}
}).start();
}
while (Thread.activeCount()>2){ // main gc
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " " + num);
}
}- 禁止指令重排。
**什么是指令重排?**你写的程序,计算机并不是按照你写的那样去执行的。
源代码到程序的过程:源代码-->编译器优化的重排-->指令并行也可能重排-->内存系统也会重排-->执行。
处理器在进行指令重排的时候,会考虑数据之间的依赖性,这在多线程情况下会出现问题(例如:A线程没有出现数据依赖,B线程也没有出现数据依赖,但B线程的指令重排后的结果对线程出现了依赖,就可能会出现问题)。
举个例子:a、b、x、y默认值都是0
| 线程A | 线程B |
|---|---|
| x=a | y=b |
| b=1 | a=2 |
正常的结果:x = 0; y = 0; 但是可能由于指令重排:
| 线程A | 线程B |
|---|---|
| b=1 | a=2 |
| x=a | y=b |
指令重排导致的诡异结果:x = 2; y = 1; volatile关键字就可以避免指令重排。
**那为什么volatile可以避免指令重排呢?**添加volatile之后,在volatile写的时候,会在指令前后添加内存屏障,以禁止上下指令之间的交换。
普通读-->普通写-->内存屏障(禁止上下指令顺序交换)-->volatile写-->内存屏障(禁止上下指令顺序交换)。
**那volatile在那里应用最多呢?**在单例模式的饿汉模式使用最多。
- 饿汉模式:详见
1.1节。 - 懒汉模式:详见
1.1节。(双重检测 + volatile,简称DCL模式) - 静态内部类:详见
1.1节。
注意:饿汉模式、懒汉模式及静态内部类都是不安全的,使用反射可以破解这种单例模式。
// 例子1:使用反射破坏原有的单例模式(饿汉/懒汉模式)
public static void main(String[] args) throws Exception {
LazyMan instance = LazyMan.getInstance();
Constructor<LazyMan> declaredConstructor = LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
LazyMan instance2 = declaredConstructor.newInstance();
System.out.println(instance);
System.out.println(instance2); // 输出instance与instance2不相等(反射可以破坏单例)
}
// 例子2:升级为三重判断,依然可以使用反射破坏单例模式
public class LazyMan {
private LazyMan(){
synchronized (LazyMan.class){
if (lazyMan!=null){ // 使用三重判断
throw new RuntimeException("不要试图使用反射破坏异常");
}
}
}
private volatile static LazyMan lazyMan;
// 双重检测锁模式的 懒汉式单例 DCL懒汉式
public static LazyMan getInstance(){
if (lazyMan==null){
synchronized (LazyMan.class){
if (lazyMan==null){
lazyMan = new LazyMan(); // 不是一个原子性操作
}
}
}
return lazyMan;
}
// 反射!
public static void main(String[] args) throws Exception {
Constructor<LazyMan> declaredConstructor = LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
LazyMan instance = declaredConstructor.newInstance();
LazyMan instance2 = declaredConstructor.newInstance();
System.out.println(instance);
System.out.println(instance2); // 输出instance2依然不等于instance
}
}
// 例子3:使用红绿灯模式,通过反射依然可以破坏单例模式
public class LazyMan {
private static boolean qinjiang = false;
private LazyMan(){
synchronized (LazyMan.class){
if (qinjiang == false){
qinjiang = true;
}else {
throw new RuntimeException("不要试图使用反射破坏异常");
}
}
}
private volatile static LazyMan lazyMan;
// 双重检测锁模式的 懒汉式单例 DCL懒汉式
public static LazyMan getInstance(){
if (lazyMan==null){
synchronized (LazyMan.class){
if (lazyMan==null){
lazyMan = new LazyMan(); // 不是一个原子性操作
}
}
}
return lazyMan;
}
// 反射!
public static void main(String[] args) throws Exception {
Field qinjiang = LazyMan.class.getDeclaredField("qinjiang");
qinjiang.setAccessible(true);
Constructor<LazyMan> declaredConstructor = LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
LazyMan instance = declaredConstructor.newInstance();
qinjiang.set(instance,false);
LazyMan instance2 = declaredConstructor.newInstance();
System.out.println(instance);
System.out.println(instance2); // 输出instance2依然不等于instance
}
}
// 例子4: 使用枚举(反射不会破坏枚举)单例模式,这种情况下才不可以被破坏
public enum EnumSingle {
INSTANCE;
public EnumSingle getInstance(){
return INSTANCE;
}
}
class Test{
public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
EnumSingle instance1 = EnumSingle.INSTANCE;
Constructor<EnumSingle> declaredConstructor = EnumSingle.class.getDeclaredConstructor(String.class,int.class);
declaredConstructor.setAccessible(true);
EnumSingle instance2 = declaredConstructor.newInstance();
// NoSuchMethodException: com.progzc.single.EnumSingle.<init>()
System.out.println(instance1);
System.out.println(instance2);
}
}CAS: Compare and Swap,即比较再交换。比较当前工作中的值和主内存中的值,如果这个值是期望的,那么则执行操作;如果不是则一直循环(底层是自旋锁)。
CAS原理:CAS底层使用Unsafe的本地方法(C语言)去操作内存(保证了很高的效率),操作的底层采用了自旋锁。
CAS缺点:
- 循环会耗事。
- 一次性只能保证一个共享变量的原子性。
- ABA问题。
什么是ABA问题?
解决ABA问题:引入待版本号的原子引用,对应的**是乐观锁。
public class CASDemo {
//AtomicStampedReference 注意,如果泛型是一个包装类,注意对象的引用问题
// 正常在业务操作,这里面比较的都是一个个对象
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(1,1);
// CAS compareAndSet : 比较并交换!
public static void main(String[] args) {
new Thread(()->{
int stamp = atomicStampedReference.getStamp(); // 获得版本号
System.out.println("a1=>"+stamp);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
Lock lock = new ReentrantLock(true);
atomicStampedReference.compareAndSet(1, 2,
atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println("a2=>"+atomicStampedReference.getStamp());
System.out.println(atomicStampedReference.compareAndSet(2, 1,
atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1));
System.out.println("a3=>"+atomicStampedReference.getStamp());
},"a").start();
// 乐观锁的原理相同!
new Thread(()->{
int stamp = atomicStampedReference.getStamp(); // 获得版本号
System.out.println("b1=>"+stamp);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(atomicStampedReference.compareAndSet(1, 6, stamp, stamp + 1));
System.out.println("b2=>"+atomicStampedReference.getStamp());
},"b").start();
}
}注意事项:Integer使用了对象缓存机制,默认范围是-128~127,推荐使用静态工厂方法valueOf获取对象实例,而不是New,因为valueOf使用缓存,而New一定会创建新的对象,分配新的内存空间。
阿里巴巴开发手册:所有相同类型的包装类对象之间值得比较,全部使用equals方法比较。这是因为:对于Integer var = ? 在-128~127之间的赋值,Integer对象是在IntegerCache.cache产生,会复用已有对象,这个区间内的Integer值可以直接使用==进行判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象。这是一个大坑,推荐使用equals方法进行判断。
公平锁:不能插队,必须先来后到。
非公平锁:可以插队(默认都是非公平锁)。
public ReentrantLock() { // 默认都是非公平锁
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
// 例子:非公平锁
public class FairLocked implements Runnable {
private int seatNumber = 100;
// 公平锁实现 ReentrantLock构造方法中设置为true:代表公平锁
// 设置为false:代表非公平锁 默认也是非公平锁
private ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
while (true) {
try {
lock.lock();
if (seatNumber > 0) {
Thread.sleep(100);
--seatNumber;
System.out.println(Thread.currentThread().getName() + "占用1个座位,还剩余 " + seatNumber + "个座位");
} else {
System.out.println(Thread.currentThread().getName() + ":不好意思,票卖完了!");
break;
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) {
FairLocked rlbr = new FairLocked();
Thread t1 = new Thread(rlbr, "A窗口");
Thread t2 = new Thread(rlbr, "B窗口");
t1.start();
t2.start();
}
}可重入锁:可以理解为递归锁(拿到了外面的锁,才能获取里面的锁)。
Synchronized版的可重入锁:
// Synchronized
public class Demo01 {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(()->{
phone.sms();
},"A").start();
new Thread(()->{
phone.sms();
},"B").start(); // 先输出A的sms和call,再输出B的sms和call
}
}
class Phone{
public synchronized void sms(){
System.out.println(Thread.currentThread().getName() + "sms");
call(); // 这里也有锁
}
public synchronized void call(){
System.out.println(Thread.currentThread().getName() + "call");
}
}Lock版的可重入锁:
public class Demo02 {
public static void main(String[] args) {
Phone2 phone = new Phone2();
new Thread(()->{
phone.sms();
},"A").start();
new Thread(()->{
phone.sms();
},"B").start();
}
}
class Phone2{
Lock lock = new ReentrantLock();
public void sms(){
lock.lock(); // 细节问题:lock.lock(); lock.unlock(); // lock 锁必须配对,否则就会死在里面
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "sms");
call(); // 这里也有锁
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
lock.unlock();
}
}
public void call(){
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "call");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}自旋锁:加锁后陷入无限循环。自旋锁是计算机科学用于多线程同步的一种锁,线程反复检查锁变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。
// 利用CAS实现自定义自旋锁
public class SpinlockDemo {
// int 0
// Thread null
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock(){ // 加锁
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "==> mylock");
while (!atomicReference.compareAndSet(null,thread)) { // 自旋锁
}
}
public void myUnLock(){ // 解锁
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "==> myUnlock");
atomicReference.compareAndSet(thread,null);
}
}
// 测试自旋锁
public class TestSpinLock {
public static void main(String[] args) throws InterruptedException {
// 底层使用的自旋锁CAS
SpinlockDemo lock = new SpinlockDemo();
new Thread(()-> {
lock.myLock();
try {
TimeUnit.SECONDS.sleep(5);
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.myUnLock();
}
},"T1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
lock.myLock();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.myUnLock();
}
},"T2").start();
}
}死锁的例子:
public class DeadLockDemo {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new MyThread(lockA, lockB), "T1").start();
new Thread(new MyThread(lockB, lockA), "T2").start();
}
}
class MyThread implements Runnable{
private String lockA;
private String lockB;
public MyThread(String lockA, String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA){
System.out.println(Thread.currentThread().getName() + "lock:"+lockA+"=>get"+lockB);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB){
System.out.println(Thread.currentThread().getName() + "lock:"+lockB+"=>get"+lockA);
}
}
}
}怎么排查解决死锁?
- 第一步:使用jps定位进程号(使用命令
jps -l)。 - 第二步:使用jstack查看进程信息(使用命令
jstack 进程号)
面试中问怎么排除问题?
- 查看日志。
- 查看堆栈信息。(这样比较专业)
结束线程的方法:
-
Thread类的
public final void stop()方法,但这个方法被标记为了过时,简单的说,我们不应该使用它,可以忽略它。 -
使用中断机制:中断并不是强迫终止一个线程,它是一种协作机制,是给线程传递一个取消信号,但是由线程来决定如何以及何时退出。
-
Thread类的
public boolean isInterrupted()方法- 属于实例方法,需要通过线程对象调用。
- 返回对应线程的中断标志位是否为true。
-
Thread类的
public void interrupt()方法- 属于实例方法,需要通过线程对象调用。
- 调用该方法的线程的状态将被置为"中断"状态。注意:线程中断仅仅是设置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法(也就是线程中断后会抛出InterruptedException的方法,比如这里的sleep,以及Object.wait等方法)就是在监视线程的中断状态,一旦线程的中断状态被置为"中断状态",就会抛出中断异常。
-
Thread类的
public static boolean interrupted()方法- 属于静态方法,实际会调用Thread.currentThread()操作当前线程。
- 返回当前线程的中断标志位是否为true,但它还有一个重要的副作用,就是清空中断标志位,也就是说,连续两次调用interrupted(),第一次返回的结果为true,第二次一般就是false (除非同时又发生了一次中断)。
public class Interrupt { public static void main(String[] args) throws Exception { Thread t = new Thread(new Worker()); t.start(); Thread.sleep(200); t.interrupt(); System.out.println("Main thread stopped."); } public static class Worker implements Runnable { public void run() { System.out.println("Worker started."); try { Thread.sleep(500); } catch (InterruptedException e) { Thread curr = Thread.currentThread(); //再次调用interrupt方法中断自己,将中断状态设置为“中断” curr.interrupt(); System.out.println("Worker IsInterrupted: " + curr.isInterrupted()); System.out.println("Worker IsInterrupted: " + curr.isInterrupted()); System.out.println("Static Call: " + Thread.interrupted());//clear status System.out.println("---------After Interrupt Status Cleared----------"); System.out.println("Static Call: " + Thread.interrupted()); System.out.println("Worker IsInterrupted: " + curr.isInterrupted()); System.out.println("Worker IsInterrupted: " + curr.isInterrupted()); } System.out.println("Worker stopped."); } } } // 输出 Worker started. Main thread stopped. Worker IsInterrupted: true Worker IsInterrupted: true Static Call: true ---------After Interrupt Status Cleared---------- Static Call: false Worker IsInterrupted: false Worker IsInterrupted: false Worker stopped.
-
B站多线程教程、线程的六种状态及切换、volatile关键字、transient关键字、B站并发编程、Java内存模型、CAS、周明志-深入理解JAVA虚拟机、中断线程的几种方法对比
操作系统的作用:
- 为各个独立的进程分配资源,如内存、文件句柄、安全证书等。
- 在进程中通过一些通信机制来交换数据,如套接字、信号处理器、共享内存、信号量、文件等。
并发的作用:
- 提高系统的资源利用率。
- 公平性。使不同的用户和程序对计算机上的资源有着同等的使用权。
- 便利性。可以使用多个程序来执行一个任务。
线程与进程:
- 线程是轻量级的进程。
- 线程会共享进程范围内的资源(如内存句柄、文件句柄),但是每个线程都有各自的程序计数器、栈以及局部变量。
线程的优势:
- 发挥多核处理器的强大能力。
- 建模的简单性。
- 异步事件的简化处理。
- 响应更灵敏的用户界面。
线程带来的风险:
-
安全性问题("永远不发生糟糕的事情"):如自增不是一个原子性操作(读/自增/写)。
竞态条件是一种常见的并发安全问题,可以采用同步机制(synchronized)来解决。
-
活跃性问题("某件正确的事情最终会发生"):如死锁、饥饿、活锁问题。
-
性能问题:上下文切换带来的系统开销。
总结:线程无处不在:JVM、各种框架(框架通过在框架线程中调用应用程序代码将并发性引入到程序中)。
共享:变量可以由多个线程同时访问。
可变:变量的值在其生命周期内可以发生变化。
当多个线程访问同一个可变的状态变量时没有使用合适的同步,那么程序可能会出现错误,解决方法有三种:
- 不在线程之间共享该状态变量。
- 将状态变量修改为不可变的变量。
- 在访问状态变量时使用同步。
线程安全性:
- 当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安装的。
- 无状态对象一定是线程安全的。
竞态条件:在并发编程中,由于不恰当的执行时序而出现不正确的结果。当某个计算的正确性取决于多个线程的交替执行时序时,就会发生竞态条件。竞态条件的本质是基于一种可能失效的观察结果来做出判断或执行某个计算。
- "先检查后执行"的一种常见情况就是延迟初始化(例如单例模式),延迟初始化中包含一个竞态条件。
- 要避免竞态条件,就必须在某个线程修改该变量时,通过某种方式防止其他线程使用这个变量。
原子操作:对于访问同一个状态的所有操作(包括该操作本身)来说,这个操作是一个以原子方式执行的操作。
复合操作:包含了一组必须以原子方式执行的操作,如"先检查后执行"、"读取-修改-写入"(如自增)都是复合操作。
将复合操作变成线程安全的方法:
- 使用
java.util.concurrent.atomic包下的原子变量类(线程安全状态变量,如AtomicLong),这些原子变量类用于实现在数值和对象引用上的原子状态转换(如AtomicLong的incrementAndGet方法是一种原子操作的自增)。在实际情况中,应尽可能地使用现有的线程安全对象(如AtomicLong)来管理类的状态。 - 在方法上加锁。
- 使用不可变对象。
为什么要加锁解决线程安全问题,难道使用原子变量类不行吗?
当在不变性条件中涉及多个变量时,各个变量之间并不是彼此独立的,而是某个变量的值会对其他变量的值产生约束。因此,当更新某一个变量时,需要在同一个原子操作中对其他变量同时进行更新。这个时候锁登场了。
内置锁:同步代码块(Synchronized Block)。同步代码块由两部分组成:锁的对象引用+锁保护的代码块。
- 若以关键字Synchronized修饰普通方法,则该同步代码块的锁就是方法调用所在对象。
- 若以关键字Synchronized修饰静态方法,则该同步代码块的锁就是Class对象。
- 每个java对象都可以当作锁,这种锁称之为内置锁或监视器锁。
- java的内置锁是一种互斥锁。
- 在方法上使用同步代码块,往往可以解决线程安全问题,但是又会带来性能问题。
重入:
- 内置锁是可重入的。若某个线程试图获得一个已经由它自己持有的锁,那么这个请求就会成功。
- "重入"意味着获取锁的操作粒度是"线程",而不是"调用"。
- "重入"的实现方式是为每个锁关联一个获取计数值和一个所有者线程。
- "重入"提升了加锁行为的封装性,简化了面向对象并发代码的开发。如父类有一个Synchronized方法,而子类也继承并重写了这个方法,同时也添加了Synchronized,当调用子类的Synchronized方法时,重入避免了死锁的发生。需要注意的是,调用子类的Synchronized方法时加的锁是父类的锁。
用锁来保护状态:
- 对于可能被多个线程同时访问的可变状态变量,在访问它时都需要持有同一个锁;每个共享的可变变量都应该只由一个锁来保护。
- 常见的加锁约定:将所有的可变状态都封装在对象内部,并通过对象的内置锁对所有访问可变状态的代码路径进行同步,使得在该对象上不会发生并发访问(如Vector类)。
- 通过缩小同步代码块的作用范围,可以既确保并发性,又提高性能。
- 同时使用同步代码块和原子变量,不仅会带来混乱,还会降低性能。
线程的安全性和对象的共享形成了构建线程安全类以及通过java.util.concurrent类库来构建并发应用程序的重要基础。
- 为了确保多个线程之间对内存写入操作的可见性,必须使用同步机制(如在获取或改变变量的代码块上添加Synchronized关键字)。
- 重排序:在没有同步的情况下,编译器、处理器以及运行时等都可能对操作的执行顺序进行一些意想不到的调整。
- 只要有数据在多个线程之间共享,就使用正确的同步。
- 在多线程程序中使用共享且可变的非volatile类型的long和double变量是不安全的。
使变量可见性的方法:
- 在获取或改变变量的代码块上添加Synchronized关键字(效率低)。
- 将变量声明为volatile类型(在访问volatile变量时不会执行加锁操作,因此不会导致线程阻塞;volatile变量是一种比Synchronized更轻量级的同步机制)。
volatile的作用:
- 使变量可见,确保将变量的更新操作通知到其他线程(volatile变量不会被缓存在寄存器或者其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值)。
- 防止编译器对该变量进行重排序。
- volatile不能保证原子性。
volatile本质:在写入volatile变量之前对A可见的所有变量(包括非volatile修饰的变量)的值,在B读取了volatile变量之后,对B也是可见的。**从内存角度来看,写入volatile变量相当于退出了同步代码块,而读取volatile变量相当于进入了同步代码块。**不建议过度依赖volatile变量控制状态的可见性,这会比锁大的代码更脆弱,也更加难以理解。
volatile的使用场景:volatile变量通常用作某个操作完成、发生中断或者状态的标志。
发布:使对象能在当前作用域之外的代码中使用。
发布对象的方法:
- 将对象的引用保存到一个公有的静态变量中,以便任何类和线程都能看到该对象。
- 如果从非私有方法中返回一个引用,那么同样会发布返回的对象。
- 发布一个内部的类实例。
逸出:某个不应该发布的对象被发布。
- 不要在构造过程中使this引用逸出。
线程封闭:如果仅在单线程内访问数据,就不需要同步。
线程封闭的例子:
- Swing
- JDBC的Connection对象。
Ad-hoc线程封闭:指维护线程封闭性的职责完全由程序实现来承担。在程序中尽量少用Ad-hoc线程封闭。
栈封闭:是线程封闭的一种,在栈封闭中,只能通过局部变量才能访问对象。
- 基本类型的局部变量始终封闭在线程内。
ThreadLocal类:维持线程封闭性的一种更规范方法是使用ThreadLocal,这个类能使线程中的某个值与保存值的对象关联起来。
- ThreadLocal变量类似于全局变量,能降低代码的可重用性,并在类之间引入隐含的耦合性,因此在使用时要格外小心。
不可变对象:使用不可变对象可以满足同步需求。
- 不可变对象一定是状态安全的。
- 不可变对象由构造函数来控制。
- 在某些情况下,不可变对象能提供一种弱形式的原子性。
不可变对象的必备条件:
- 对象创建以后其状态就不能修改。
- 对象的所有域都是final类型(String是不可变对象,StringBuilder是可变对象)。
- 对象是正确创建的(在对象的创建期间,this引用没有逸出)。
final关键字:除非需要某个域是可变的,否则应将其声明为final域。
-
final类型的域不能修改(指引用地址不变),但是域引用的对象是可变的。
-
在java内存模型中,final域能确保初始化过程的安全性,可以不受限制地访问不可变对象,并在共享这些对象时无须同步。
安全发布的方法:
- 在静态初始化函数中初始化一个对象引用。
- 将对象的引用保存到volatile类型的域或者AtomicReference对象中。
- 将对象的引用保存到某个正确构造对象的final类型域中。
- 将对象的引用保存到一个由锁保护的域中(包括线程安装容器内部的同步)。
对象的发布需求取决于它的可变性:
- 不可变对象可以通过任意机制来发布。
- 事实不可变对象必须通过安全方式来发布。
- 可变对象必须通过安全方式来发布,并且必须是线程安全的或者由某个锁保护起来。
在设计线程安全类的过程中,需要包含以下三个基本要素:
- 找出构成对象状态的所有变量。
- 找出约束状态变量的不变性条件。
- 建立对象状态的并发访问管理策略。
实例封闭要满足两个条件:
- 保证被封闭对象不能超出它们既定的作用域。
- 对象本身不会逸出。
实例封闭举例:
- 使用一些包装器的工厂方法(如:Collections.synchronizedXxx方法(装饰器模式))来进行实例封闭
- 使用监视器模式进行实例封闭(如:Vector、Hashtable)
- 将线程安全委托给其他状态变量(要求其他状态变量之间不存在耦合关系,否则(存在复合操作)委托会失效)
- 扩展类加锁
- 客户端加锁机制
- 通过组合(采用java监视器模式)
同步容器类包括:Vector、Hashtable以及Collections.synchronizedXxx等工厂方法创建的同步封装器类。
同步容器类实现线程安全的原理:将类的状态封装起来,并对每个公有方法都进行同步,使得每次只有一个线程能访问容器的状态。
注意事项:
-
同步容器上常见的复合操作:迭代(即使使用迭代器迭代)、跳转、条件运算、"若没有则添加"...
-
虽然同步容器类的单个操作是原子性的,但是对于复合操作要采用客户端加锁(一般使用同步容器类本身的锁)来保证线程安全性。
-
使用迭代器也无法避免在迭代期间对容器加锁。设计同步容器类的迭代器时并未考虑到并发修改的问题,其行为表现出是"即时失败"(当容器在迭代过程中被修改时,会抛出
ConcurrentModificationException异常)。 -
同步容器类在进行迭代时,为了保证安全性,有两种方案:
- 一种方案是迭代期间对同步容器加锁(性能很低)
- 另一种方案是克隆容器,在副本上迭代(以空间换时间)
-
注意隐藏迭代器带来的线程安全问题
- 例如:
System.out.println(set);,其中set是一个Set集合,而set的toString方法会迭代集合。 - 同步容器的hashCode、equals、containsAll、removeAll、和retainAll等方法以及把容器作为参数的构造方法同样也会间接执行迭代操作。
- 例如:
同步容器的局限:同步容器将所有对容器状态的访问都串行化,以实现它们的线程安全性,但代价是严重降低并发性。
并发容器:针对多个线程并发访问而设计,增加了对一些常见复合操作的支持(如:"若没有则添加"、替换以及有条件删除等)。对比同步容器而言,并发容易可以极大地提高伸缩性并降低风险。
对比ConcurrentHashMap与synchronizedMap:
-
与同步容器类不同,ConcurrentHashMap采用粒度更细的
分段锁机制来实现更大程度的共享。分段锁机制使得ConcurrentHashMap在并发下实现更高的吞吐量,而在单线程下只损失非常小的性能。分段锁机制:
- 任意数量的读线程可以并发访问Map;
- 读线程和写线程可以并发访问Map;
- 一定线程的写线程可以并发修改Map。
-
ConcurrentHashMap提供的迭代器不会抛出
ConcurrentModificationException异常,因此无须在迭代过程中对容器加锁。ConcurrentHashMap的迭代器具有"弱一致性"。 -
由于ConcurrentHashMap的"弱一致性",在并发下其size和isEmpty方法方法一个近似值而非精确值。
-
与Hashtable、synchronizedMap相比,ConcurrentHashMap中没有实现对Map加锁以提供独占访问(这会带来一些劣势,但是却带来性能上的巨大提升)。总而言之,除非应用程序需要加锁Map进行独占访问才应该放弃使用ConcurrentHashMap。
-
由于ConcurrentHashMap中没有实现对Map加锁以提供独占访问,所以无法使用客户端加锁来创建新的原子操作,但是一些常见的复合操作,如"若没有则添加"(putIfAbsent方法)、"若相等则移除"(remove方法)、"若相等则替换"(replace方法)都以及实现了原子操作并在ConcurrentMap的接口中进行了声明。
对比CopyOnWriteArrayList与synchronizedList: CopyOnWriteArraySet与synchronizedSet同理。
- CopyOnWriteArrayList在迭代时不需对容器进行加锁和复制,但是CopyOnWriteArrayList在每次迭代时都会对底层数组进行复制(这会提供更好的并发性能;但当容器特别大时,会带来空间和复制的开销)。
- CopyOnWriteArrayList不会抛出
ConcurrentModificationException异常,并且返回的元素与迭代器创建时的元素完全一致,而不必考虑之后修改操作所带来的影响。 - 只有当迭代操作远远多于修改操作时,才应该使用"写入时复制"容器(即CopyOnWriteArrayList并发容器),典型的例子例子是事件监听器。
阻塞队列(BlockingQueue)支持生成者-消费者这种设计模式,且支持任意数量的生产者和消费者。
- put方法:生产者方法;take方法:消费者方法。
- offer方法:定时的生产者方法;poll方法:定时的消费者方法。
- 实现类:LinkedBlockingQueue、ArrayBlockingQueue、PriorityBlockingQueue(可以实现排序)、SynchronousQueue(实际上不是一个真正的队列,没有存储功能,侧重"直接交付")。
典型应用:
- 线程池与工作队列组合(如Executor任务执行框架)
- 构建资源管理机制。
Deque、BlockingDeque(双端阻塞队列)分别对Queue、BlockingQueue进行了扩展,具体实现是ArrayDeque和LinkedBlockingDeque。
参考博客文章:使用BlockingQueue实现生产者-消费者模式
恢复被中断的状态:Thread.currentThread().interrupt();
同步工具类:可以是任何对象,只要它根据其自身的状态来协调线程的控制流。同步工具类包括阻塞队列、信号量、栅栏、闭锁。
闭锁:可以延迟线程的进度直到其到达终止状态。闭锁可以确保某些活动直到其他活动都完成后才继续执行。典型的闭锁有CountDownLatch。另外,FutureTask(异步任务)也可以实现闭锁。
计数信号量:作用是限流,可以控制任务的到达率。用来控制同时访问某个特定资源的操作数量,或者同时执行某个指定操作的数量。
栅栏:类似于闭锁。二者的关键区别在于,所以线程必须同时到达栅栏位置,才能继续执行。闭锁用于等待事件,而栅栏用于等待其他线程。典型的栅栏有CyclicBarrier、Exchanger。
构建高效且可伸缩的结果缓存的关键点:
- 使用ConcurrentHashMap;
- 使用FutureTask;
- 使用ConcurrentHashMap的putIfAbsent方法而不是put方法。
参考博客文章:Future与FutureTask
无限制创建线程的不足:
- 线程生命周期的开销非常高。
- 资源消耗。
- 稳定性。
Executors静态工厂方法创建线程池的方法:
- newFixedThreadPool:创建一个固定长度的线程池,每当提交一个任务时就创建一个线程,直到达到线程池的最大数量。
- newCachedThreadPool:创建一个可缓存的线程池,如果线程池的规模超过了处理需求时,那么将收回空闲的线程。
- newSingleThreadExecutor:一个单线程的Executor,它创建单个工作者线程来执行任务,如果这个线程异常结束,会创建另一个线程来替代。
- newScheduledThreadPool:创建一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
其中,newFixedThreadPool和newCachedThreadPool这两个工厂方法返回通用的ThreadPoolExecutor实例,这些实例可以直接用来构造专门用途的executor。
ExecutorService接口:解决执行服务的生命周期问题,同时还有一些用于提交的便利方法。
ExecutorService的生命周期有3种状态:运行、关闭和已终止
- shutdown方法将执行平稳的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完成,包括那些还未开始执行的任务。
- shutdownNow方法将执行粗暴的关闭过程:它将尝试取消所有运行中的任务,并且不再启动队列中尚未开始执行的任务。
Timer:负责管理延迟任务("在100ms后执行该任务")以及周期任务("每10ms执行一次任务")。然而,Timer存在一些缺陷(Timer支持基于绝对时间而不是相对时间的调度机制,因此任务的执行对系统时钟非常敏感;而ScheduledThreadPoolExecutor只支持基于相对时间的调度),因此,实际中推荐使用ScheduledThreadPoolExecutor的构造函数或newScheduledThreadPool工厂方法来创建ScheduledThreadPoolExecutor对象。
- Timer在执行所有定时任务时只会创建一个线程。如果某个任务的执行时间过长,那么将破坏其他TimerTask的定时精确性。
- 若TimerTask抛出了一个未检查的异常,那么Timer将表现出糟糕的行为。Timer并不会捕获异常,当TimerTask抛出未检查的异常时将终止定时线程(已经被调度旦但尚未执行的TimerTask将不会再执行,新的任务也不能被调度)。
- 在java5.0或更高的JDK中,将很少使用Timer。
Callable:
- Callable能返回结果并抛出异常。
java.security.PrivilegedAction能将Runnable封装为一个Callable。- Executor执行的任务有4个生命周期**:创建、提交、开始和完成**。
Future:表示一个任务的生命周期,并提供了相应的方法来判断是否已经完成或取消,以及获取任务的结果和取消任务等。
- get方法会阻塞直到任务完成(或抛出异常)。
- getCause方法获取抛出的异常。
- 任务提交和获取结果中包含的安全发布属性确保了这个方法是线程安全的(另外,在将Runnable或Callable提交到Executor的过程中,也包含了一个安全发布过程)。
并行任务的局限性:
- 通过对异构任务进行并行化来获得重大的性能提升是很困难的(如:并行执行两个不同类型的任务获得性能提升很困难)。
- 如果没有在相似任务之间找出细粒度的并行性,那么这种方法带来的好处将减少(如:任务A的执行时间是任务B的10倍)。
- 并行任务的适用场景**:大量相互独立且同构的任务**。
CompletionService:将Executor和BlockingQueue的功能融合在了一起,实现类是ExecutorCompletionService。
// 从以下两点优化:
// 1. 为每幅图片的下载都创建一个独立任务,并在线程池中执行它们,从而将串行的下载过程转换为并行的过程
// 2. 通过从CompletionService中获取结果(take方法)以及使每张图片在下载完成后立刻显示出来,能使用户获得一个更加动态和更高响应性的用户界面
public abstract class Renderer {
private final ExecutorService executor;
Renderer(ExecutorService executor) {
this.executor = executor;
}
void renderPage(CharSequence source) {
final List<ImageInfo> info = scanForImageInfo(source);
CompletionService<ImageData> completionService =
new ExecutorCompletionService<ImageData>(executor);
for (final ImageInfo imageInfo : info)
completionService.submit(new Callable<ImageData>() {
public ImageData call() {
return imageInfo.downloadImage();
}
});
renderText(source);
try {
for (int t = 0, n = info.size(); t < n; t++) {
Future<ImageData> f = completionService.take();
ImageData imageData = f.get();
renderImage(imageData);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}为任务设置定时:
- 在支持时间限制的Future.get中支持这种需求:当结果可用时,它将立即返回;如果在指定时限内没有计算出结果,那么将抛出TimeoutException。
- 当任务超时后应该立即停止(cancel方法),避免为继续计算一个不再使用的结果而浪费计算资源。
- 使用限时的invokeAll:当超过指定时限后,任何未完成的任务都会取消。
任务取消的原因:用户请求取消、有时间限制的操作、应用程序事件、错误、关闭。
中断:它并不会真正地中断一个正在运行的线程,而只是发出中断请求,然后由线程在下一个合适的时刻(取消点)中断自己(如:wait、sleep、join)。
- 解决阻塞队列中的中断问题:使用中断(如:Thread.currentThread().isInterrupted())而不是boolean标志来请求取消。
中断策略:尽快退出,在必要时进行清理,通知某个所有者该线程已经退出。
响应中断的两种策略:传递异常、恢复中断状态。
注意事项:
- 除非清楚线程的中断策略,否则不要中断线程。当执行任务的线程是由标准的Executor创建的,它实现了一种中断策略使得任务可以通过中断被取消(此时,可以通过Future来取消中断,并设置cancel方法的参数mayInterruptIfRunning为true,表示这个线程能被中断)。
- 对于执行不可中断操作而被阻塞的线程,可以使用类似于中断的手段来停止这些线程,但这要求我们必须知道线程阻塞的原因。
- 封装非标准的取消。
注意事项:
-
关闭ExecutorService: shutdown或shutdownNow
-
通过ExecutorService(newSingleThreadExecutor方法产生)封装单个线程。
-
使用"毒丸现象"(毒丸是指一个放在队列上的对象,当得到这个对象时,立即停止)关闭生产者-消费者服务。只有在生产者和消费者的数量都已知的情况下,才可以使用"毒丸"现象。
-
只执行一次的服务的生命周期受限于方法调用。
-
解决shutdownNow的局限性(shutdownNow只会返回所有已提交但尚未开始的任务):封装ExecutorService跟踪Executor关闭时哪些任务正在执行。
注意事项:
- 使用try...catch或try...catch...finally捕获非正常关闭的线程的异常。
- 使用UncaughtExceptionHandler异常处理器处理未捕获的异常(只有通过execute提交的任务,它抛出的异常才会交给UncaughtExceptionHandler处理;而submit抛出的异常会被认为是任务返回状态的一部分)。
JVM正常关闭的触发方式:
- 线程(非守护)正常关闭时。
- 调用了System.exit。
- 其他平台方法:如Ctrl+C。
关闭钩子:通过Runtime.addShutdownHook注册的但尚未开始的线程。
饥饿死锁:只要线程池中的任务需要无限期地等待一些必须由池中其他任务才能提供的资源或条件(例如某个任务等待另一个任务的返回值或执行结果),那么除非线程池足够大,否则将发生线程饥饿死锁。
解决无限制等待:限定任务等待资源的时间。
线程池的最优大小:N_threads = N_cpu * U_cpu * (1+W/C),其中N_cpu为CPU的核数,U_cpu为CPU的利用率,W为等待时间,C为计算时间。
ThreadPoolExecutor的七大参数:
-
corePoolSize:线程池的大小。
-
maximumPoolSize:线程池的最大大小。
-
keepAliveTime:线程的存活时间(超时了没人调用就会释放)
-
TimeUnit:存活时间的单位
-
BlockingQueue:阻塞队列,保存等待执行的任务(基本的任务有三种:无界队列、有界队列和同步移交),队列的选择与其他的配置参数有关(如线程池的大小)。
- newFixedThreadPool和newSingleThreadExecutor在默认情况下将使用一个无界的LinkedBlockingQueue。
- 有界队列(如ArrayBlockingQueue(FIFO)、有界的LinkedBlockingQueue(FIFO)、PriorityBlockingQueue(可以按照优先级处理任务))有助于避免资源耗尽的情况发生。队列的大小与线程池的大小必须一起调节,若线程池较小而队列较大,那么有助于减少内存使用量、降低CPU的使用率,同时还可以减少上下文切换,缺点是会限制吞吐量。
- 对于非常大或者无界的线程池,可以使用SynchronousQueue来避免任务排队,直接将任务从生产者移交给工作者线程。只有当线程池是无界的或者可以拒绝任务时,SynchronousQueue才有实际价值。newCachedThreadPool工厂方法中就使用了SynchronousQueue。
-
ThreadFactory:线程工厂。每当线程池需要创建一个线程时,都是通过线程工厂方法来完成的。
- ThreadFactory接口只有一个newThread方法。
-
RejectedExecutionHandler:饱和策略(当有界队列填满后,饱和策略开始发挥作用)。
- AbortPolicy**:中止策略(默认的饱和策略)**,队列满了会抛出RejectedExecutionException异常。
- CallerRunsPolicy**:调用者运行策略**(既不会抛弃任务,也不会抛出异常,而是将任务退回到调用者)
- DiscardOldestPolicy**:抛弃最旧的策略**(队列满了就会尝试去和最早的竞争,竞争失败就会丢掉任务,且不会抛出异常)。
- 若阻塞队列是一个优先级队列,那么抛弃最旧的策略将导致抛弃优先级最高的任务,因此不要将抛弃最旧的策略与优先级队列一起使用。
- DiscardPolicy**:抛弃策略**(队列满了就会丢掉任务,且不会抛出异常)。
注意事项:
- corePoolSize、maximumPoolSize和keepAliveTime共同负责线程的创建与销毁。
- newFixedThreadPool工厂方法将线程池的基本大小和最大大小设置为参数中指定的值,而且创建的线程池不会超时。
- newCachedThreadPool工厂方法将线程池的最大大小设置为Integer.MAX_VALUE,而将其基本大小设置为0,超时设置为1分钟,这种线程池可以无限扩展,需求降低时会自动收缩。
以下方法可以扩展ThreadPoolExecutor的行为:
- beforeExecute:若beforeExecute抛出一个RuntimeException,任务将不会被执行,afterExecute也不会被调用。
- afterExecute:无论任务是从run中正常返回,还是抛出一个异常而返回,afterExecute都会被调用;若任务在完成后带有一个Error,则afterExecute不会被调用。
- terminated:在线程池完成关闭操作时调用terminated。terminated可以用来释放Executor在其生命周期里分配的各种资源,此外,还可以执行发送通知、记录日志或者收集finalize统计信息等操作。
- 若循环中的迭代操作都是独立的,并且不需要等待所有的迭代操作都完成再继续执行,那么就可以使用Executor将串行循环转化为并行循环。
死锁:在线程A持有锁L并想获得锁M的同时,线程B持有锁M并尝试获得锁L,那么这两个线程将永远地等待下去。
- 锁顺序死锁:如果所有线程以固定的顺序来获得锁,那么在程序中就不会出现锁顺序死锁问题。
- 动态的锁顺序死锁:可以使用
System.identityHashCode方法来指定锁的顺序和加时赛锁以解决死锁问题。 - 在协作对象之间发生死锁:通过**开放调用((解决协作对象之间的死锁。
- 资源死锁:
- 支持定时的锁
- 通过线程转储信息来分析死锁
- 饥饿:当线程由于无法访问它所需要的资源而不能继续执行时,就发生了"饥饿",引发饥饿的最常见资源就是CPU时钟频率。
- 要避免使用线程优先级,因为这回增加平台的依赖性,并可能导致活跃性问题。
- 糟糕的响应性:
- 活锁:线程将不断重复执行相同的操作,而且总会失败。
多线程带来的性能开销:
- 线程之间的切换
- 增加的上下文切换
- 线程的创建和销毁
- 线程的调度
应用程序性能的衡量指标:服务时间、延迟时间、吞吐率、效率、可伸缩性、容量...
可伸缩性:当增加计算资源时(如CPU、内存、存储容量或I/O带宽),程序的吞吐量或者处理能力能相应地增加。
Amdahl定律:在增加计算资源的情况下,程序在理论上能够实现最高加速比,这个值取决于程序中可并行组件与串行组件所占的比重。
最高加速比: $$ S<=1/(F+(1-F)/N) $$ 其中N为处理器的数量,F为串行执行的部分。
两种降低锁粒度的计数:锁分解(将一个锁分解为两个锁)、锁分段(把一个锁分解为多个锁)。
- 上下文切换:在JVM和操作系统的代码中消耗越多的CPU时钟周期,应用程序的可用CPU时钟周期就越少;但上下文切换的开销并不只包含JVM和操作系统的开销。
- 内存同步:在synchronized和volatile提供的可见性保证中可能会使用一些特殊指令,即内存栅栏。内存栅栏可以刷新缓存,使缓存无效,刷新硬件的写缓冲,以及停止执行管道。在内存栅栏中,大多数操作都是不能被重排序的。
- 阻塞:自旋等待或挂起
降低锁竞争的三种方式:
- 减少锁的持有时间:缩小锁的范围("快进快出")
- 降低锁的请求频率:减小锁的粒度("锁分解"、"锁分段")
- 若程序采用锁分段技术,那么一定要表现出在锁上的竞争频率高于在锁保护的数据上发生竞争的频率。
- 放弃独占锁,使用并发容器、读-写锁、不可变对象以及原子变量。
- 使用带有协调机制的独占锁,这些机制允许更高的并发性
CPU没有得到充分利用的原因有:
- 负载不充足
- I/O密集
- 外部限制
- 锁竞争
Map的性能的比较:
ConcurrentHashMap(锁分段+读写锁)>ConcurrentSkipListMap>synchronized HashMap(独占锁) >synchronized TreeMap
Lock:提供了一种无条件的、可轮询的、定时的以及可中断的锁获取操作,所有加锁和解锁的方式都是显式的。
ReentrantLock:实现了Lock,并提供了与synchronized相同的互斥性和内存可见性。
- 使用ReentrantLock时,一定要在finally块中释放锁。(使用FindBugs插件可以检查这种错误)
- 使用可定时(定时的tryLock)的与可轮询(tryLock)的锁可以避免死锁的发生
- 定时的tryLock同样能响应中断,因此当需要实现一个定时的和可中断(lockInterruptibly)的锁获取操作时,可使用tryLock方法
JDK的版本也会影响锁的性能。
- JDK5.0中,从单线程变为多线程时,内置锁的性能急剧下降,而ReentrantLock的性能下降则比较平稳。
- JDK6.0中,从单线程变为多线程时,内置锁的性能不会由于竞争而急剧下降,内置锁和ReentrantLock的可伸缩性基本相当。
ReentrantLock:有两种构造函数(公平锁和非公平锁)
- 公平锁:线程按照它们发出请求的顺序来获得锁。当持有锁的时间相对较长,或者请求锁的平均时间间隔较长,那么应该使用公平锁。
- 非公平锁:允许"插队"
- Semaphore也有公平锁和非公平锁
- 大多数情况下,非公平锁的性能要高于公平锁的性能
ReentrantLock与synchronized的选择:
- ReentrantLock提供可定时的、可轮询的与可中断的锁获取操,公平队列、以及非块结构的锁。
- ReentrantLock使用更复杂,需要在finally块中释放锁。
- synchronized更容易使jvm发现死锁。
读写锁(ReadWriteLock接口):一个资源可以被多个读操作访问、或者被一个写操作访问,但两者不能同时进行。
读写锁的两者实现:
- ReentrantReadWriteLock
- ReadWriteLockView
锁与volatile:
- 与锁相比,volatile变量是一种更轻量级的同步机制,因为在使用这些变量时不会发生上下文切换或线程调度等操作。
- volatile不能构建原子的复合操作。
现代处理器:支持比较并交换(CAS)或关联加载/条件存储指令。
比较并交换(CAS,相当于乐观锁):包含3个操作数,需要读写的内存位置V、进行比较的值A和拟写入的新值B。
- 当且仅当V的值等于A时,CAS才会通过原子方式用新值来更新V的值,否则不会执行任何操作。
- 无论位置V的值是否等于A,都将返回V原有的值。
- 线程在竞争CAS失败时不会阻塞。
- 基于CAS的计数器在性能上远远好于基于锁的计数器。
- 在程序内部执行CAS时不需要执行JVM代码、系统调用或线程调度操作。
- CAS的缺点是需要调用者处理竞争问题(如重试、回退或放弃),而锁能够自动处理竞争问题(线程在获得锁之前一直阻塞)
原子变量类:比锁的粒度更细、量级更轻,更适合于在多处理器系统上实现高性能的并发代码。
- 更新原子变量类不需要挂起或重新调度线程。
- 原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。
- 在高度竞争的情况下,锁的性能会超过原子变量的性能;但由于在实际中,锁在发生竞争时会挂起线程,会降低CPU的使用率和共享内存总线上的同步通信量,从而导致在真实环境下,原子变量的性能反而会更好。
非阻塞算法:一个线程的失败或挂起不会导致其他线程也失败或挂起。
参考博客文章:《JAVA并发编程实战》


-
模板方法模式:
-
策略模式:File+FilenameFilter
-
装饰模式:new BufferedWriter(new OutputStreamWriter(new FileInputStream("文件路径")))
-
适配器模式:
几个概念的理解(以"银行取款"为例):
-
同步:使用同步IO时,Java自己处理IO读写。
- 例:自己亲自出马持银行卡到银行取钱。
-
异步:使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS处理,需要将数据缓冲区地址和大小传给OS,OS需要支持异步IO操作API。
- 例:委托一个小弟拿银行卡到银行取钱,然后给你,前提当然是需要将银行卡和密码交给小弟。
-
阻塞:使用阻塞IO时,Java调用会一直阻塞到读写完成才返回。
- 例: ATM排队取款,你只能等待。
-
非阻塞:使用非阻塞IO时,如果不能读写Java调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成。
- 例:柜台取款,取个号,然后坐在椅子上做其它事,等号期间广播会通知你办理,没到号你就不能去,你可以不断问大堂经理排到了没有,大堂经理如果说还没到你就不能去。
-- 综合举例
-- 同步阻塞:自己去银行ATM取款
-- 异步阻塞:委托小弟去银行ATM取款
-- 异步非阻塞:委托小弟去银行柜台拿号取款Java对BIO、NIO、AIO的支持:
- Java BIO (blocking I/O):同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
- Java NIO (non-blocking I/O): 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
- Java AIO(NIO 2) (Asynchronous I/O) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
BIO、NIO、AIO适用场景分析:
- BIO方式适用于连接数目比较小且固定的架构,对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
- NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
- AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
NIO与IO的主要区别:NIO的核心在于通道(Channel,打开到IO设备(如文件、套接字)的连接,负责传输)、缓冲区(Buffer,负责存储)和选择器(NIO的核心,作用是实现非阻塞)。
| IO | NIO |
|---|---|
| 面向流(Stream Oriented):单向的 | 面向缓冲区(Buffer Oriented):双向的 |
| 同步阻塞IO(Blocking IO) | 同步非阻塞IO(Non Blocking IO) |
| - | 选择器(Selectors) |
缓冲区(Buffer)用法总结:

通道(Channel)用法总结:

套接字(Socket)用法总结:

选择器(Selector)用法总结:

NIO的三大核心:Channel通道、Buffer缓冲区、Selector选择器
直接缓冲区与非直接缓冲区:字节缓冲区要么时直接的,要么是非直接的。如果为直接字节缓冲区,则Java虚拟机会尽最大努力直接在此缓冲区上执行本机IO操作。也就是说,在每次调用基础操作系统的一个本机I/O操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
- 非直接缓冲区通过allocate()方法分配缓冲区,将缓冲区建立在JVM内存中。
- 直接缓冲区通过allocateDirect()方法分配直接缓冲区,将缓冲区建立在操作系统的物理内存中,可以提供效率。
- allocateDirect()方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。
- 直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此对应用程序的内存需求量造成的影响可能并不明显。建议将直接缓冲区主要分配给那些易受基础系统的本机I/O操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们。
- 直接字节缓冲区还可以通过FileChannel的map()方法(返回MappedByteBuffer)将文件区域直接映射到内存中来创建。Java平台的实现有助于通过JNI从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常。


通道与DMA:

通道的主要实现类:FileChannel、SocketChannel、ServerSocketChannel、DatagramChannel...
获取通道的几种方法:
- 使用getChannel()方法:FileInputStream/FileOutputStream/RandomAccessFile(针对本地IO)、Socket/ServerSocket/DatagramSocket(针对网络IO)。
- 在NIO中针对各个通道的静态open()方法。
- 在NIO中的Files工具类的newByteChannel()方法。
select/poll/epoll的区别:
select缺点:
- bitmap数组默认大小为1024,虽然可以自己设置,但还是大小有限。
- FD_SET不可重用。
- 用户态到内核态切换存在开销。
- 判断哪一个socket有数据需要进行遍历(轮询),时间复杂度为O(n)。
poll:解决了缺点1(因为基于链表处理)和缺点2。
epoll:解决了select的缺点1、2、3、4,具有广泛的应用(Redis/Nginx/Java NIO(Linux下))。
AIO的用法总结:

参考博客文章:Java IO中的设计模式、BIO/NIO/AIO整理、select/poll/epoll的区别、<<NIO与Socket编程技术指南>>、直接缓冲区与非直接缓冲区的区别、JVM直接内存的使用与回收
集合的框架一栏:


List/Set/Map的比较:
- List:可以有顺序地存取对象。
- Set:不允许重复对象存放到集合中。
- Map:采用键值对存储对象,使用哈希码来进行快速搜素。
ArrayList/LinkedList的比较:
-
是否保证线程安全:均不同步,即不保证线程安全。
-
底层数据结构不同:ArraytList底层是数组,LinkedList底层是双向链表(JDK1.6之前为双向循环链表;JDK1.7则取消了循环,变成了双向链表)。
-
插入和删除操作:插入和删除的时间复杂度均受元素位置的影响。
-
ArrayList底层采用数组结构,插入和删除的性能较低,但是查询性能较高。
-
ListedList底层采用双向链表,插入和删除的性能较高,但是查询性能较低。
-
-
查询操作:LinkedList不支持高效的随机元素访问;而ArraytList支持按元素索引快速获取元素对象。
-
由于ArraytList支持按索引随机获取元素,所以ArrayList实现了RandomAccess接口(标识接口),而LinkedList没有实现RandomAccess接口。
-
在Collections工具类的binarySearch方法中,会根据list判断是否是RandomAccess接口的实例。若是,则调用Collections的indexedBinarySearch方法进行搜索;反之,则调用Collections的iteratorBinarySearch方法来搜索。
-
实现了RandomAccess接口(如ArrayList)的List,优先选择fori遍历,其次是forEach遍历;未实现RandomAccess接口(如LinkedList)的List,优先选择iterator进行遍历(forEach底层也是iterator实现遍历),当size很大时,禁止使用fori遍历。
// 当List的size=200000时,ArrayList和LinkedList使用不同方式遍历的耗时如下: // ArrayList使用fori遍历,耗时:1ms // ArrayList使用iterator遍历,耗时:3ms // LinkedList使用fori遍历,耗时:21805ms // LinkedList使用iterator遍历,耗时:5ms public class TraverseMethodTest { public static void main(String[] args) { List<Integer> list1 = new ArrayList<>(); List<Integer> list2 = new LinkedList<>(); for (int i = 0; i < 200000; i++) { list1.add(i); list2.add(i); } // ArrayList使用fori遍历,耗时:5ms int size = list1.size(); long start1 = System.currentTimeMillis(); for (int i = 0; i < size; i++) { list1.get(i); } long end1 = System.currentTimeMillis(); System.out.println("ArrayList使用fori遍历,耗时:" + (end1 - start1) + "ms"); // ArrayList使用iterator遍历,耗时:25ms long start2 = System.currentTimeMillis(); Iterator<Integer> it1 = list1.iterator(); while (it1.hasNext()) { Integer next = it1.next(); } long end2 = System.currentTimeMillis(); System.out.println("ArrayList使用iterator遍历,耗时:" + (end2 - start2) + "ms"); // LinkedList使用fori遍历,耗时:ms int size2 = list2.size(); long start3 = System.currentTimeMillis(); for (int i = 0; i < size2; i++) { list2.get(i); } long end3 = System.currentTimeMillis(); System.out.println("LinkedList使用fori遍历,耗时:" + (end3 - start3) + "ms"); // LinkedList使用iterator遍历,耗时:ms long start4 = System.currentTimeMillis(); Iterator<Integer> it2 = list2.iterator(); while (it2.hasNext()) { Integer next = it2.next(); } long end4 = System.currentTimeMillis(); System.out.println("LinkedList使用iterator遍历,耗时:" + (end4 - start4) + "ms"); } }
-
-
内存空间占用不同:LinkedList则需要存储指向下个元素的引用;ArrayList会在List的结尾预留一定的容量空间。ArrayList的扩容机制如下:
-
ArrayList默认容量是10;
-
每次扩容按照1.5倍进行增长;
-
允许的最大容量就是Integer的最大值。
-
使用ArrayList的注意事项:
- 在forEach/iterator迭代时,不能使用集合本身进行添加或删除元素(否则会出现ConcurrentModificationException)。
- 在forEach/iterator迭代时,可以使用迭代器可以进行删除元素,但仍然不能进行添加元素。
- 在fori迭代时,可以使用集合本身进行添加或删除元素。
- 若使用CopyOnWriteArrayList替代ArrayList,则在迭代(forEach/iterator/fori)时,可以使用集合本身进行添加或删除元素。
// 测试iterator迭代
@Test
public void test1() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
int i = (int) it.next();
// 在iterator迭代时,不能使用ArrayList集合本身进行添加或删除元素
list.add(i); // java.util.ConcurrentModificationException
list.remove(i); // java.util.ConcurrentModificationException
}
}
// 测试forEach迭代
@Test
public void test2() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
for (Integer i : list) {
// 在forEach迭代时,不能使用ArrayList集合本身进行添加或删除元素
list.add(i); // java.util.ConcurrentModificationException
list.remove(i); // java.util.ConcurrentModificationException
}
}
// 测试fori迭代
@Test
public void test3() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
for (int i = 0; i < 5; i++) {
// 在fori迭代时,可以使用ArrayList集合本身进行添加或删除元素
list.add(i);
list.remove(i);
}
System.out.println(list); // [1, 3, 5, 7, 9, 0, 1, 2, 3, 4]
}
// 测试使用迭代器删除元素
@Test
public void test4() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
it.next();
// 在forEach/iterator迭代时,可以使用迭代器可以进行删除元素,但仍然不能进行添加元素
it.remove();
}
System.out.println(list); // 输出[]
}
// 测试使用CopyOnWriteArrayList
@Test
public void test5() {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
int i = (int) it.next();
// 在iterator迭代时,可以使用CopyOnWriteArrayList集合本身进行添加或删除元素
list.add(i);
list.remove(i);
}
System.out.println(list); // [1, 3, 5, 7, 9, 1, 3, 5, 7, 9]
}ArrayList/Vector的比较:
-
Vector和ArrayList的底层均采用数组结构实现。
-
Vector的所有方法都是同步方法(添加了synchronized关键字)。多线程下可以安全地访问同一个Vector对象,缺点是在整个方法上添加了同步锁,导致性能很低。由于Vector的性能低下,因此多线程下也不推荐使用Vector,应使用CopyOnWriteArrayList。
-
ArrayList的方法不是同步的,无法在多线程下保证安全性。
HashMap/Hashtable的比较:
-
线程是否安全:HashMap线程不安全,HashTable是线程安全的(Hashtable内部的方法基本都使用synchronized修饰)。
-
效率:由于线程安全的问题,HashMap的效率比HashTable要高。HashTable由于性能较低,已经被淘汰,多线程下使用ConcurrentHashMap 。
-
对null Key 和null Value的支持:
- HashMap中,null可以作为Key,且只能存在一个null Key,但可以存在多个Key对应的Value为null;
- Hashtable的Key和Value均不能为null(否则会抛出NullPointerException异常)。
集合类 Key Value super 说明 Hashtable 不允许为null 不允许为null Dictionary 线程安全 ConcurrentHashMap 不允许为null 不允许为null AbstractMap 锁分段技术(JDK8:CAS) TreeMap 不允许为null 允许为null AbstractMap 线程不安全 HashMap 允许为null 允许为null AbstractMap 线程不安全 -
初始容量及扩容机制不同:
- Hashtable默认的初始容量为11(之所以设计为11,是因为11是一个素数,发生哈希碰撞的概率要小于合数),之后每次扩容为2n+1(n为原来的容量大小),默认负载因子为0.75(负载因子太小了浪费空间并且会发生更多次数的resize,太大了哈希冲突增加会导致性能不好。负载因子取0.75本质是空间与时间成本的一种折中)。
- HashMap默认的初始容量为16(16为合数,2^n也为合数),之后每次扩容为2n(n为原来的容量大小),默认负载因子为0.75。
- 若创建时制定了初始容量,Hashtable会直接使用给定的大小,而HashMap会将其扩充为2的幂次方大小(HashMap总是使用2的幂次方作为哈希表的大小)。
-
底层数据结构不同:
- JDK1.8之前,HashMap底层由数组+链表组成,数组是HashMap的主体,链表则是为了解决哈希冲突而存在的("拉链法"解决冲突);JDK1.8之后,在解决Hash冲突时有了较大的变化,当链表的长度大于阈值(默认是8)时,将链表转化为红黑树,以减少搜索时间。
- Hashtable底层仍然采用数组+链表组成。
HashMap/HashSet的比较:HashSet底层是使用HashMap实现的。
| HashMap | HashSet |
|---|---|
| 实现了Map接口 | 实现了Set接口 |
| 存储键值对 | 仅存储对象 |
| 调用put方法向map中添加元素 | 调用add方法向Set中添加元素(底层使用HashMap实现,value是一个Object常量) |
| HashMap使用键(Key)计算哈希码 | HashSet使用对象计算哈希码,若两个对象的哈希码相同,再使用equals方法用来判断对象的相等性 |
HashSet检查重复的步骤:
- 检查对象哈希码。若哈希码不同,则没有重复的对象;若哈希码相同,则下一步使用equals方法进行比较。
- 使用equals方法进行比较,若为true则表示有重复的对象,反之则没有重复的对象。
HashMap的底层实现:
- JDK1.8之前,HashMap底层采用数组和链表组成的链表数组结构(即"哈希桶"数组,底层对应的是Node[])。
// JDk1.7的计算散列码的方法
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}- JDK1.8之后,HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)且数组容量大于64时,将链表转化为红黑树,以减少搜索时间。
// JDk1.8的计算散列码的方法
// JDK1.8的哈希码计算只经过了一次扰动,性能比JDk1.7要高
static final int hash(Object key) {
int h;
// key.hashCode(): 返回散列值也就是hashcode
// ^: 按位异或
// >>>:无符号右移, 忽略符号位, 空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- TreeMap、TreeSet 以及 JDK1.8 之后的HashMap 底层都用到了红黑树结构,红黑树可以解决二叉查找树在某些情况下会退化成线性结构的缺陷。
HashMap的长度为什么是2的幂次方?
为了能让 HashMap 存取高效,尽量减少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是(n - 1) & hash(n 代表数组长度)。这也就解释了HashMap 的长度为什么是2的幂次方。
这个算法应该如何设计呢?我们首先可能会想到采用%取余的操作来实现。但是:取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说hash%length==hash&(length-1)的前提是 length是2的n次方);并且采用二进制位操作&,相对于%能够提高运算效率,这就解释了HashMap的长度为什么是2的幂次方。
在多线程下使用HashMap可能会由于rehash造成元素之间形成一个循环链表,导致HashMap在get元素时出现死循环问题。不过,好在JDK1.8后解决这个问题(JDK8依然存在该问题)。但是正如Sun设计的初衷一样,多线程下应该使用ConcurrentHashMap来代替HashMap。
ConcurrentHashMap/Hashtable的比较:
-
底层数据结构不同:
- JDK1.7的ConcurrentHashMap底层采用分段的数组+链表实现;JDK1.8采用和HashMap一样的结构,即数组+链表/红黑树实现。
- Hashtable采用数组+链表实现。
-
实现线程安全的方式不同:
- JDK1.7时,ConcurrentHashMap采用分段锁策略对整个桶数进行了分割分段(Segment,Segment是一种可重入锁),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率;JDK1.8时,抛弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized+CAS来操作。
- JDK1.8的实现降低了锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)。
- Hashtable使用同步方法(在方法上添加synchronized关键字)保证线程安全("全表锁"),效率非常低下(例如:当put的时候,也不能get)。
- JDK1.7时,ConcurrentHashMap采用分段锁策略对整个桶数进行了分割分段(Segment,Segment是一种可重入锁),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率;JDK1.8时,抛弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized+CAS来操作。
Comparable/Comparator的比较:
- 出处不同:
- Comparable接口出自
java.lang包,Comparable的compareTo(Object obj)方法用来排序。 - Comparator接口出自
java.util包,Comparator的compare(Object obj1, Object obj2)方法用来排序。
- Comparable接口出自
- 使用不同:Comparator具有更大的灵活性。
- 当需要对一个集合使用自定义排序时,我们就要重写
compareTo()方法或compare()方法。 - 当需要对一个集合实现两种排序方式时,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo()方法和使用自制的Comparator方法、或以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的
Collections.sort()。
- 当需要对一个集合使用自定义排序时,我们就要重写
LinkedHashMap/HashMap比较:
- 类的关系:LinkedHashMap继承自HashMap。
- 对null Key 和null Value的支持:与HashMap相同,Key和Value都允许为空。
- 底层数据结构:
- HashMap:数组+链表/红黑树。
- LinkedMap:数组+链表/红黑树+双向链表。
- 线程是否安全:都属于线程不安全的集合。
- 是否有序:HashMap无序;LinkedHashMap有序(分为插入顺序和访问顺序两种),若是访问顺序,当put和get操作已经存在的Entry时,都会把Entry移动到双向链表的末尾(其实是先删除再插入)。
LinkedHashSet/HashSet比较:
-
类的关系:LinkedHashSet继承自HashSet。
-
对null Key 和null Value的支持:HashSet、LinkedHashSet均只可以存储一个null。
-
底层数据结构:
- HashSet:底层使用HashMap实现,采用数组+链表/红黑树结构。
- LinkedHashSet:采用数组+链表/红黑树+双向链表结构。
-
线程是否安全:都属于线程不安全的集合。
-
是否有序:HashSet无序;LinkedHashSet有序。
集合数据结构总结:
-
List
- ArrayList: Object数组。
- Vector: Object数组。
- LinkedList: 双向链表(JDK1.6之前为双向循环链表,JDK1.7则取消了循环,变成了双向链表)。
-
Set
- HashSet(无序唯一):底层采用HashMap实现。
- TreeSet(有序唯一):红黑树(自平衡的排序二叉树)。
- LinkedHashSet:底层采用LinkedHashMap来实现,而LinkedHashMap内部又是基于HashMap实现。
-
Map
- HashMap: JDK1.8之前由数组+链表实现,JDK1.8采用数组+链表/红黑树实现。
- Hashtable:数组+链表。
- TreeMap:红黑树(自平衡的排序二叉树)。
- LinkedHashMap:继承自HashMap,底层采用数组+链表/红黑树实现;此外,还增加了一条双向链表,从而保证键值对的插入顺序。
HashMap七种遍历方式如下:
- 迭代器(Iterator)EntrySet的方式。
- 迭代器(Iterator)KeySet的方式。
- forEach EntrySet的方式。
- forEach KeySet的方式。
- Lambda表达式的方式。
- Stream API单线程的方式。
- Stream API多线程的方式。
// 使用JMH对以上七种遍历方式进行测试
// Benchmark Mode Cnt Score Error Units
// HashMapTest.entrySet thrpt 5 4.181 ± 0.170 ops/ms
// HashMapTest.forEachEntrySet thrpt 5 4.224 ± 0.837 ops/ms
// HashMapTest.forEachKeySet thrpt 5 4.334 ± 0.297 ops/ms
// HashMapTest.keySet thrpt 5 4.304 ± 0.440 ops/ms
// HashMapTest.lambda thrpt 5 4.237 ± 0.179 ops/ms
// HashMapTest.parallelStreamApi thrpt 5 2.426 ± 0.273 ops/ms
// HashMapTest.streamApi thrpt 5 4.525 ± 2.226 ops/ms
@BenchmarkMode(Mode.Throughput) // 测试类型:吞吐量
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 2 轮,每次 1s
@Measurement(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS) // 测试 5 轮,每次 3s
@Fork(1) // fork 1 个线程
@State(Scope.Thread) // 每个测试线程一个实例
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {{
// 添加数据
for (int i = 0; i < 10; i++) {
put(i, "val:" + i);
}
}};
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(HashMapTest.class.getSimpleName()) // 要导入的测试类
.output("C:/Users/zcpro/Desktop/jmh-map.log") // 输出测试结果的文件
.build();
new Runner(opt).run(); // 执行测试
}
@Benchmark
public void entrySet() {
// 使用迭代器(Iterator)EntrySet的方式进行遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
@Benchmark
public void keySet() {
// 使用迭代器(Iterator)KeySet的方式进行遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key);
System.out.println(map.get(key));
}
}
@Benchmark
public void forEachEntrySet() {
// 使用ForEach EntrySet的方式进行遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
@Benchmark
public void forEachKeySet() {
// 使用ForEach KeySet的方式进行遍历
for (Integer key : map.keySet()) {
System.out.println(key);
System.out.println(map.get(key));
}
}
@Benchmark
public void lambda() {
// 使用Lambda表达式的方式进行遍历
map.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
}
@Benchmark
public void streamApi() {
// 使用Stream API单线程的方式进行遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
@Benchmark
public void parallelStreamApi() {
// 使用Stream API多线程的方式进行遍历
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}总结:
- HashMap除了Stream API多线程(并行循环parallelStream)的方式性能比较高之外,其他的遍历方式在性能方面几乎没有任何差别。
- 无论是forEach遍历还是迭代器遍历,EntrySet的遍历性能都要略高于KeySet(相差不大)。
- 从
HashMapTest.class字节码文件可以看出:- 使用迭代器和forEach遍历的底层实现一致(相当于forEach是一种语法糖)。
- Lambda表达式采用Key-Value对遍历,类似于KeySet遍历。
- Stream单线程和Stream多线程均采用EntrySet遍历,多线程遍历性能提升极大。
- 从安全性角度:
- 在迭代器遍历中使用迭代器本身删除元素安全。
- 在forEach遍历中使用集合本身操作(增加/删除/修改)元素不安全,会出现
ConcurrentModificationException异常。 - 在Lambda遍历中使用集合本身操作(增加/删除/修改)元素不安全,会出现
ConcurrentModificationException异常;可以先使用Lambda的 removeIf方法删除多余的数据,再进行循环才是一种正确操作集合的方式。 - 在Stream遍历中使用集合本身操作(增加/删除/修改)元素不安全,会出现
ConcurrentModificationException异常;可以在流中使用filter对集合元素进行过滤达到"删除"的效果。

快速失败(fail-fast):Java集合的一种错误检测机制。在使用迭代器对集合进行遍历时,若在多线程下操作(增加/删除/修改)非安全失败的集合可能就会触发fail-fast机制,导致抛出ConcurrentModificationException异常;此外,在单线程下,若在遍历时对集合对象的内容进行了操作(增加/删除/修改)也会触发fail-fast机制;值得注意的是,forEach循环也是借助于迭代器进行遍历。
原因:每当迭代器使用hashNext/next遍历下一个元素前,都会检测modCount变量是否为expectedModCount值,确认OK就返回遍历,否则抛出异常,终止遍历。若在集合被遍历期间对其进行修改(增加/删除/修改,修改为什么会改变modCount的值)的话,就会改变modCount的值,进而导致modCount≠expectedModCount,进而抛出ConcurrentModificationException异常。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}安全失败(fail-safe):采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问,而是先复制原有集合内容,在拷贝的集合上进行遍历。所以。在遍历过程中对原集合所作的修改并不能被迭代器检测到,故不会抛出ConcurrentModificationException异常。
Arrays.asList()避坑指南:
-
Arrays.asList()方法:返回由指定数组支持的固定大小列表(数组与集合之间转化的桥梁),返回的List是可序列化并实现了RandomAccess接口。
-
需要注意,转换后的List集合,不能使用其修改集合相关的方法,其add/remove/clear方法会抛出
UnsupportedOperationException异常。这是因为asList的返回对象是一个Arrays内部类,并未实现集合的修改方法。Arrays.asList体现的是适配器模式,只是转换接口,后台的数据仍是数组。String[] str = new String[]{"you", "wu"}; List list = Arrays.asList(str); // 第一种情况:list.add("yangguanbao");运行时异常 // 第二种情况:str[0]="gujin";那么list.get(0)也会随之修改
-
-
集合的toArray()方法:将集合转化为数组。
Arrays.asList()注意事项:
-
传入的数组必须是对象数组,而不是基本类型。
// 当传入一个基本数据类型数组时,Arrays.asList()的真正得到的参数就不是数组中的元素,而是数组对象本身,此时List的唯一元素就是这个数组 public void test8() { // 改成Integer[] myArray = {1, 2, 3};可以避免出现异常 int[] myArray = {1, 2, 3}; List myList = Arrays.asList(myArray); System.out.println(myList.size()); // 1 System.out.println(myList.get(0)); // 数组地址值 // System.out.println(myList.get(1)); // 报错: ArrayIndexOutOfBoundsException int[] array = (int[]) myList.get(0); System.out.println(Arrays.toString(array)); // [1, 2, 3] }
-
转换后的List集合,不能使用其修改集合相关的方法,其add/remove/clear方法会抛出
UnsupportedOperationException异常。Arrays.asList()⽅法返回的并不是java.util.ArrayList,而是java.util.Arrays的⼀个内部类,这个内部类并没有实现集合的修改⽅法或者说并没有重写这些⽅法。public void test9() { List myList = Arrays.asList(1, 2, 3); System.out.println(myList.getClass()); // class java.util.Arrays$ArrayList myList.add(4); // 运⾏时报错: UnsupportedOperationException myList.remove(1); // 运⾏时报错: UnsupportedOperationException myList.clear(); // 运⾏时报错: UnsupportedOperationException }
ArrayList源码分析、LinkedList源码分析、HashMap源码分析、Vector和Stack源码分析、深入理解Java集合框架、哈希表解决冲突的两种方式、JDK1.8ArrayList主要方法和扩容机制(源码解析)、Java8系列之重新认识HashMap、HashMap的7种遍历方式与性能分析、HashMap的死循环、LinkedHashMap源码详细分析、Java Array to List Examples、fail-fast和fail-safe
-
Math.round():"四舍五入", 该函数返回的是一个四舍五入后的的整数。
- 注意:负数,小数点第一位是5时,直接舍去,整数部分不+1; 正数,小数点第一位是5时,往整数部分+1。
-
Math.ceil():"向上取整",即小数部分直接舍去,并向正数部分进1。
-
Math.floor():"向下取整",即小数部分直接舍去。
- 注意:Math.floor()容易出现精度问题。例如,对小数8.54保留两位小数(虽然它已经保留了2位小数),
Math.floor(8.54*100)/100 // 输出结果为 8.53, 注意是 8.53 而不是 8.54。Math.floor()慎用!
- 注意:Math.floor()容易出现精度问题。例如,对小数8.54保留两位小数(虽然它已经保留了2位小数),
// 排序
sort()
// 查找
binarySearch()
// 比较
equals()
// 填充
fill()
// 将数组转换为列表
asList()
// 转换为字符串
Arrays.toString()
// 复制
copyOf()
// 截取复制
copyRangeOf()- 排序
// 反转
void reverse(List list)
// 随机排序
void shuffle(List list)
// 按自然排序的升序排序
void sort(List list)
// 定制排序,由Comparator控制排序逻辑
void sort(List list, Comparator c)
// 交换两个索引位置的元素
void swap(List list, int i , int j)
// 旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
void rotate(List list, int distance)- 查找与替换操作
// 对List进行二分查找,返回索引,注意List必须是有序的
int binarySearch(List list, Object key)
// 根据元素的自然顺序,返回最大的元素
int max(Collection coll)
// 根据定制排序,返回最大元素
int max(Collection coll, Comparator c)
// 用指定的元素代替指定list中的所有元素
void fill(List list, Object obj)
// 统计元素出现次数
int frequency(Collection c, Object o)
// 统计target在list中第一次出现的索引,找不到则返回-1
int indexOfSubList(List list, List target)
// 用新元素替换旧元素
boolean replaceAll(List list, Object oldVal, Object newVal)- 同步控制:禁止使用,效率很低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。
// 返回指定Collection支持的同步(线程安全的)Collection
synchronizedCollection(Collection<T> c)
// 返回指定列表支持的同步(线程安全的)List
synchronizedList(List<T> list)
// 返回由指定映射支持的同步(线程安全的)Map
synchronizedMap(Map<K,V> m)
// 返回指定Set支持的同步(线程安全的)Set
synchronizedSet(Set<T> s)- 设置不可变集合
// 下面三类方法的参数是原有的集合对象,返回值是该集合的"只读"版本
// 返回一个空的、不可变的集合对象,此处的集合既可以是List/Set/Map
emptyXxx()
// 返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是List/Set/Map
singletonXxx()
// 返回指定集合对象的不可变视图,此处的集合可以是List/Set/Map
unmodifiableXxx()commons-lang可能是最常用的java工具包之一。commons-lang包的基本组织结构如下:

ArchUtils:java运行环境的系统信息工具类。
getArch();// 获取电脑处理器体系结构 32 bit、64 bit、unknown
getType();// 返回处理器类型 x86、ia64、ppc、unknown
is32Bit();// 检查处理器是否为32位
is64Bit();// 检查处理器是否为64位
isIA64();// 检查是否是英特尔安腾处理器类型
isPPC();// 检查处理器是否是电源PC类型
isX86();// 检查处理器是否是x86类型ArrayUtils:数组工具类。
// add(boolean[] array, boolean element) 将给定的数据添加到指定的数组中,返回一个新的数组
ArrayUtils.add(null, true) = [true]
ArrayUtils.add([true], false) = [true, false]
ArrayUtils.add([true, false], true) = [true, false, true]
// add(boolean[] array, int index, boolean element) 将给定的数据添加到指定的数组下标中,返回一个新的数组
ArrayUtils.add(null, 0, true) = [true]
ArrayUtils.add([true], 0, false) = [false, true]
ArrayUtils.add([false], 1, true) = [false, true]
ArrayUtils.add([true, false], 1, true) = [true, true, false]
// addAll(boolean[] array1, boolean... array2) 将给定的多个数据添加到指定的数组中,返回一个新的数组
ArrayUtils.addAll(array1, null) = cloned copy of array1
ArrayUtils.addAll(null, array2) = cloned copy of array2
ArrayUtils.addAll([], []) = []
// clone(boolean[] array) 复制数组并返回 结果数组为空将返回空
// contains(boolean[] array, boolean valueToFind) 检查该数据在该数组中是否存在,返回一个boolean值
// getLength(Object array) 返回该数组长度
ArrayUtils.getLength(null) = 0
ArrayUtils.getLength([]) = 0
ArrayUtils.getLength([null]) = 1
ArrayUtils.getLength([true, false]) = 2
ArrayUtils.getLength([1, 2, 3]) = 3
ArrayUtils.getLength(["a", "b", "c"]) = 3
// hashCode(Object array) 返回该数组的哈希Code码
// indexOf(boolean[] array, boolean valueToFind) 从数组的第一位开始查询该数组中是否有指定的数值,存在返回index的数值,否则返回-1
// indexOf(boolean[] array, boolean valueToFind, int startIndex) 从数组的第startIndex位开始查询该数组中是否有指定的数值,存在返回index的数值,否则返回-1
// insert(int index, boolean[] array, boolean... values) 向指定的位置往该数组添加指定的元素,返回一个新的数组
ArrayUtils.insert(index, null, null) = null
ArrayUtils.insert(index, array, null) = cloned copy of 'array'
ArrayUtils.insert(index, null, values) = null
// isEmpty(boolean[] array) 判断该数组是否为空,返回一个boolean值
// isNotEmpty(boolean[] array) 判断该数组是否为空,而不是null
// isSameLength(boolean[] array1, boolean[] array2) 判断两个数组的长度是否一样,当数组为空视长度为0。返回一个boolean值
// isSameType(Object array1, Object array2) 判断两个数组的类型是否一样,返回一个boolean值
// isSorted(boolean[] array) 判断该数组是否按照自然排列顺序排序,返回一个boolean值
// isSorted(T[] array, Comparator<T> comparator) 判断该数组是否按照比较器排列顺序排序,返回一个boolean值
// lastIndexOf(boolean[] array, boolean valueToFind) 从数组的最后一位开始往前查询该数组中是否有指定的数值,存在返回index的数值,否则返回-1
// lastIndexOf(boolean[] array, boolean valueToFind, int startIndex) 从数组的最后startIndex位开始往前查询该数组中是否有指定的数值,存在返回index的数值,否则返回-1
// nullToEmpty(boolean[] array) 将null转换为空的数组,如果数组不为null,返回原数组,如果数组为null,返回一个空的数组
// remove(boolean[] array, int index) 删除该数组指定位置上的元素,返回一个新的数组,所有后续元素左移(下标减1)
ArrayUtils.remove([true], 0) = []
ArrayUtils.remove([true, false], 0) = [false]
ArrayUtils.remove([true, false], 1) = [true]
ArrayUtils.remove([true, true, false], 1) = [true, false]
// removeAll(boolean[] array, int... indices) 删除该数组多个指定位置上的元素,返回一个新的数组,所有后续元素左移(下标减1)
ArrayUtils.removeAll([true, false, true], 0, 2) = [false]
ArrayUtils.removeAll([true, false, true], 1, 2) = [true]
// removeAllOccurences(boolean[] array, boolean element) 从该数组中删除指定的元素,返回一个新的数组
// removeElement(boolean[] array, boolean element) 从该数组中删除指定的元素,返回一个新的数组
// removeElements(boolean[] array, boolean... values) 从该数组中删除指定数量的元素,返回一个新的数组
// reverse(boolean[] array) 数组反转
// reverse(boolean[] array, int startIndexInclusive, int endIndexExclusive) 数组从指定位置区间进行反转
// shuffle(boolean[] array) 把数组中的元素按随机顺序重新排列
// subarray(boolean[] array, int startIndexInclusive, int endIndexExclusive) 截取数组,按指定位置区间截取并返回一个新的数组
// swap(boolean[] array, int offset1, int offset2) 指定该数组的两个位置的元素交换进行交换
ArrayUtils.swap([1, 2, 3], 0, 2) -> [3, 2, 1]
ArrayUtils.swap([1, 2, 3], 0, 0) -> [1, 2, 3]
ArrayUtils.swap([1, 2, 3], 1, 0) -> [2, 1, 3]
ArrayUtils.swap([1, 2, 3], 0, 5) -> [1, 2, 3]
ArrayUtils.swap([1, 2, 3], -1, 1) -> [2, 1, 3]
// toArray(T... items) 创建数组
String[] array = ArrayUtils.toArray("1", "2");
String[] emptyArray = ArrayUtils.<String>toArray();
// toMap(Object[] array) 将二维数组转换成Map并返会Map
Map colorMap = ArrayUtils.toMap(new String[][] {
{"RED", "#FF0000"},
{"GREEN", "#00FF00"},
{"BLUE", "#0000FF"}}
);
// toObject(boolean[] array) 将基本类型数组转换成对象类型数组并返回
// toPrimitive(Boolean[] array) 将对象类型数组转换成基本类型数组并返回
// toString(Object array) 将数组转换为string字符串并返回
// toStringArray(Object[] array) 将Object数组转换为String数组类型BooleanUtils:布尔工具包。
// and(boolean... array) 逻辑与
// compare(boolean x, boolean y) 比较两个布尔值并返回int类型 如果x == y返回0, !x && y 返回小于 0 ,x && !y 返回大于0
// isFalse(Boolean bool) 是否是假并返回boolean
// isTrue(Boolean bool) 是否是真并返回boolean
// negate(Boolean bool) 逻辑非
// or(boolean... array) 逻辑或
// toBoolean(Boolean bool) 将对象类型转换为基本数据类型并返回
// toBoolean(int value) 将int类型转换为boolean类型并返回
// toBoolean(String str) 将string类型转换为boolean类型并返回
// toInteger(boolean bool) 将boolean类型数据转换为int类型并返回
// toStringOnOff(boolean bool) 将boolean类型数据转换为String类型'on' or 'off'并返回
// toStringTrueFalse(Boolean bool) 将boolean类型数据转换为String类型''true' or 'false'并返回
// toStringYesNo(boolean bool) 将boolean类型数据转换为String类型'yes' or 'no'并返回
// xor(boolean... array) 异或ClassPathUtils: class路径工具。
// toFullyQualifiedName(Class<?> context, String resourceName) 返回一个由class包名+resourceName拼接的字符串
ClassPathUtils.toFullyQualifiedName(StringUtils.class, "StringUtils.properties") = "org.apache.commons.lang3.StringUtils.properties"
// toFullyQualifiedName(Package context, String resourceName) 返回一个由class包名+resourceName拼接的字符串
ClassPathUtils.toFullyQualifiedName(StringUtils.class.getPackage(), "StringUtils.properties") = "org.apache.commons.lang3.StringUtils.properties"
// toFullyQualifiedPath(Class<?> context, String resourceName) 返回一个由class包名+resourceName拼接的字符串
ClassPathUtils.toFullyQualifiedPath(StringUtils.class, "StringUtils.properties") = "org/apache/commons/lang3/StringUtils.properties"
// toFullyQualifiedPath(Package context, String resourceName) 返回一个由class包名+resourceName拼接的字符串
ClassPathUtils.toFullyQualifiedPath(StringUtils.class, "StringUtils.properties") = "org/apache/commons/lang3/StringUtils.properties"EnumUtils:枚举工具类。
// getEnum(Class<E> enumClass, String enumName) 通过类返回一个枚举,可能返回空
// getEnumList(Class<E> enumClass) 通过类返回一个枚举集合
// getEnumMap(Class<E> enumClass) 通过类返回一个枚举map
// isValidEnum(Class<E> enumClass, String enumName) 验证enumName是否在枚举中,返回true falseObjectUtils: Object工具类。
// allNotNull(Object... values) 检查所有元素是否为空,返回一个boolean
// anyNotNull(Object... values) 检查元素是否为空,返回一个boolean,如果有一个元素不为空返回true
// clone(T obj) 拷贝一个对象并返回
// compare(T c1, T c2) 比较两个对象,返回一个int值
// defaultIfNull(T object, T defaultValue) 如果对象为空返回一个默认值
// firstNonNull(T... values) 返回数组中第一个不为空的值
// notEqual(Object object1, Object object2) 判断两个对象不相等,返回一个booleanRandomUtils:随机工具类。
// nextBoolean() 返回一个随机boolean值
// nextBytes(int count) 返回一个指定大小的随机byte数组
// nextDouble() 返回一个随机double值
// nextDouble(double startInclusive, double endInclusive) 返回一个指定范围的随机double值
// nextFloat() 返回一个随机float值
// nextFloat(float startInclusive, float endInclusive) 返回一个指定范围的随机float值
// nextInt() 返回一个随机int值
// nextInt(int startInclusive, int endExclusive) 返回一个指定范围的随机int值
// nextLong() 返回一个随机long值
// nextLong(long startInclusive, long endExclusive) 返回一个指定范围的随机long值SystemUtils:操作系统工具类。
// FILE_ENCODING 返回系统编码
// IS_JAVA_1_1、...、IS_JAVA_1_8、IS_JAVA_10、IS_JAVA_9 判断java版本,返回一个boolean
// IS_OS_LINUX 判断系统是否是linux,返回一个boolean
// IS_OS_MAC 判断系统是否是mac,返回一个boolean
// IS_OS_LINUX 判断系统是否是linux,返回一个boolean
// JAVA_CLASS_PATH 返回系统CLASS_PATH值
// JAVA_CLASS_VERSION 返回系统java版本
// JAVA_HOME 返回系统java home
// JAVA_RUNTIME_VERSION 返回java运行版本
// JAVA_VERSION 返回java版本
// OS_NAME 返回系统名
// OS_VERSION 返回系统版本
// USER_COUNTRY 返回用户国家编号
// USER_DIR 返回项目文件夹
// USER_HOME 返回系统用户主文件夹
// USER_LANGUAGE 返回系统用户语言
// USER_NAME 返回系统用户名StringUtils:字符串工具类。
// abbreviate(String str, int maxWidth) 返回一个指定长度加省略号的字符串,maxWidth必须大于3
StringUtils.abbreviate(null, *) = null
StringUtils.abbreviate("", 4) = ""
StringUtils.abbreviate("abcdefg", 6) = "abc..."
StringUtils.abbreviate("abcdefg", 7) = "abcdefg"
StringUtils.abbreviate("abcdefg", 8) = "abcdefg"
StringUtils.abbreviate("abcdefg", 4) = "a..."
StringUtils.abbreviate("abcdefg", 3) = IllegalArgumentException
// abbreviate(String str, int offset, int maxWidth) 返回一个指定长度加省略号的字符串,maxWidth必须大于3
// abbreviate(String str, String abbrevMarker, int maxWidth) 返回一个自定义省略号的指定长度字符串,maxWidth必须大于3
StringUtils.abbreviate(null, "...", *) = null
StringUtils.abbreviate("abcdefg", null, *) = "abcdefg"
StringUtils.abbreviate("", "...", 4) = ""
StringUtils.abbreviate("abcdefg", ".", 5) = "abcd."
StringUtils.abbreviate("abcdefg", ".", 7) = "abcdefg"
StringUtils.abbreviate("abcdefg", ".", 8) = "abcdefg"
StringUtils.abbreviate("abcdefg", "..", 4) = "ab.."
StringUtils.abbreviate("abcdefg", "..", 3) = "a.."
StringUtils.abbreviate("abcdefg", "..", 2) = IllegalArgumentException
StringUtils.abbreviate("abcdefg", "...", 3) = IllegalArgumentException
// abbreviateMiddle(String str, String abbrevMarker, int maxWidth) 将字符串缩短到指定长度(length),字符串的中间部分用替换字符串(middle)显示
StringUtils.abbreviateMiddle("abc", null, 0) = "abc"
StringUtils.abbreviateMiddle("abc", ".", 0) = "abc"
StringUtils.abbreviateMiddle("abc", ".", 3) = "abc"
StringUtils.abbreviateMiddle("abcdef", ".", 4) = "ab.f"
// appendIfMissing(String str, CharSequence suffix, CharSequence... suffixes) 如果str不是以任何suffixes结尾,将字符串suffix拼接到字符串str后面
StringUtils.appendIfMissing(null, null) = null
StringUtils.appendIfMissing("abc", null) = "abc"
StringUtils.appendIfMissing("", "xyz") = "xyz"
StringUtils.appendIfMissing("abc", "xyz") = "abcxyz"
StringUtils.appendIfMissing("abcxyz", "xyz") = "abcxyz"
StringUtils.appendIfMissing("abcXYZ", "xyz") = "abcXYZxyz"
// appendIfMissingIgnoreCase(String str, CharSequence suffix, CharSequence... suffixes) 同上 不区分大小写
// capitalize(String str) 将字符串第一个字符大写并返回
// center(String str, int size) 用空格字符填充使字符串str位于长度为size的大字符串中间
StringUtils.center(null, *) = null
StringUtils.center("", 4) = " "
StringUtils.center("ab", -1) = "ab"
StringUtils.center("ab", 4) = " ab "
StringUtils.center("abcd", 2) = "abcd"
StringUtils.center("a", 4) = " a "
// center(String str, int size, char padChar) 用指定字符填充使字符串str位于长度为size的大字符串中间
// chomp(String str) 删除字符串末尾的一个换行符,返回一个新的字符串(换行符"n", "r", or "rn")
StringUtils.chomp(null) = null
StringUtils.chomp("") = ""
StringUtils.chomp("abc \r") = "abc "
StringUtils.chomp("abc\n") = "abc"
StringUtils.chomp("abc\r\n") = "abc"
StringUtils.chomp("abc\r\n\r\n") = "abc\r\n"
StringUtils.chomp("abc\n\r") = "abc\n"
StringUtils.chomp("abc\n\rabc") = "abc\n\rabc"
StringUtils.chomp("\r") = ""
StringUtils.chomp("\n") = ""
StringUtils.chomp("\r\n") = ""
// chop(String str) 删除字符串末尾的一个字符,返回一个新的字符串
// compare(String str1, String str2) 比较两个字符串,返回一个int值:str1等于str2(或都为空)返回0;str1小于str2返回小于0;str1大于str2返回大于0
StringUtils.compare(null, null) = 0
StringUtils.compare(null , "a") < 0
StringUtils.compare("a", null) > 0
StringUtils.compare("abc", "abc") = 0
StringUtils.compare("a", "b") < 0
StringUtils.compare("b", "a") > 0
StringUtils.compare("a", "B") > 0
StringUtils.compare("ab", "abc") < 0
// contains(CharSequence seq, CharSequence searchSeq) 检查字符串中是否包含指定字符,返回boolean
// containsAny(CharSequence cs, CharSequence... searchCharSequences) 检查字符串中是否包含任一字符,返回boolean
// containsNone(CharSequence cs, String invalidChars) 检查字符串不包含指定字符,返回boolean
// containsOnly(CharSequence cs, String validChars) 检查字符串只包含特定的字符,返回boolean
// containsWhitespace(CharSequence seq) 检查字符串中是否包含空格字符,返回boolean
// countMatches(CharSequence str, CharSequence sub) 检查字符串中出现指定字符的次数,返回一个int值
// defaultIfBlank(T str, T defaultStr) 如果字符串为null、空(""),或全是空格,将返回指定字符串,否则返回原值
// defaultIfEmpty(T str, T defaultStr) 如果字符串为null、空(""),将返回指定字符串,否则返回原值
// defaultString(String str) 如果字符串为null,将返回空的字符串(""),否则返回原值
// defaultString(String str, String defaultStr) 如果字符串为null,将返回指定字符,否则返回原值
// deleteWhitespace(String str) 删除字符串中的空格字符,并返回新的字符串
// difference(String str1, String str2) 比较两个字符串差异,并返回差异的字符,返回第二个字符串的剩余部分,这意味着“ABC”和“AB”之间的区别是空字符串而不是“C”。
// endsWith(CharSequence str, CharSequence suffix) 检查字符串是否以指定字符结尾,返回一个boolean
// endsWithAny(CharSequence sequence, CharSequence... searchStrings) 检查字符串是否以指定字符数组结尾,返回一个boolean
// endsWithIgnoreCase(CharSequence str, CharSequence suffix) 检查字符串是否以指定字符(不区分大小写)结尾,返回一个boolean
// equals(CharSequence cs1, CharSequence cs2) 比较两个字符串是否相等,返回一个boolean
// equalsAnyIgnoreCase(CharSequence string, CharSequence... searchStrings) 比较两个字符串是否相等(不区分大小写),返回一个boolean
// equalsAny(CharSequence string, CharSequence... searchStrings) 比较字符串是否与指定字符串数组中某一值相等,返回一个boolean
// equalsAnyIgnoreCase(CharSequence string, CharSequence... searchStrings) 比较字符串是否与指定字符串数组中某一值相等(不区分大小写),返回一个boolean
// getCommonPrefix(String... strs) 获取字符串数组元素公共字符,返回string
// indexOf(CharSequence seq, CharSequence searchSeq) 检查指定字符在字符串中出现的位置,返回一个int值
// indexOfIgnoreCase(CharSequence seq, CharSequence searchSeq) 检查指定字符在字符串中出现的位置(不区分大小写),返回一个int值
// isAllBlank(CharSequence... css) 检查数组所有字符是否为null、empty、或全是空格字符,返回一个boolean
// isAllEmpty(CharSequence... css) 检查数组所有字符是否为null、empty,返回一个boolean
// isAllLowerCase(CharSequence cs) 检查字符串中所有字符是否是小写,返回一个boolean
// isAllUpperCase(CharSequence cs) 检查字符串中所有字符是否是大写,返回一个boolean
// isAnyBlank(CharSequence... css) 检查数组中字符串是否有一个为null、empty或全是空格字符,返回一个boolean
// isAnyEmpty(CharSequence... css) 检查数组中字符串是否有一个为null、empty,返回一个boolean
// isBlank(CharSequence cs) 检查字符串是否为null、empty或空格字符,返回一个boolean
StringUtils.isBlank(null) = true
StringUtils.isBlank("") = true
StringUtils.isBlank(" ") = true
StringUtils.isBlank("bob") = false
StringUtils.isBlank(" bob ") = false
// isEmpty(CharSequence cs) 检查字符串是否为null、empty,返回一个boolean
StringUtils.isEmpty(null) = true
StringUtils.isEmpty("") = true
StringUtils.isEmpty(" ") = false
StringUtils.isEmpty("bob") = false
StringUtils.isEmpty(" bob ") = false
// isNotBlank(CharSequence cs) 检查字符串是否不为null、empty或空格字符,返回一个boolean
// isNotEmpty(CharSequence cs) 检查字符串是否不为null、empty,返回一个boolean
// isNumeric(CharSequence cs) 检查字符串是否是数字,返回一个boolean
// isWhitespace(CharSequence cs) 检查字符串是否是空格字符,返回一个boolean
// join(byte[] array, char separator) 将字节数组转换成string,以指定字符分隔
StringUtils.join(null, *) = null
StringUtils.join([], *) = ""
StringUtils.join([null], *) = ""
StringUtils.join([1, 2, 3], ';') = "1;2;3"
StringUtils.join([1, 2, 3], null) = "123"
// joinWith(String separator, Object... objects) 将多个元素已指定字符分隔拼接成String
StringUtils.joinWith(",", {"a", "b"}) = "a,b"
StringUtils.joinWith(",", {"a", "b",""}) = "a,b,"
StringUtils.joinWith(",", {"a", null, "b"}) = "a,,b"
StringUtils.joinWith(null, {"a", "b"}) = "ab"
// lastIndexOf(CharSequence seq, CharSequence searchSeq) 获取指定字符在字符串中的最后一个索引位置
StringUtils.lastIndexOf(null, *) = -1
StringUtils.lastIndexOf(*, null) = -1
StringUtils.lastIndexOf("", "") = 0
StringUtils.lastIndexOf("aabaabaa", "a") = 7
StringUtils.lastIndexOf("aabaabaa", "b") = 5
StringUtils.lastIndexOf("aabaabaa", "ab") = 4
StringUtils.lastIndexOf("aabaabaa", "") = 8
// left(String str, int len) 返回从左边开始指定大小的字符串
StringUtils.left(null, *) = null
StringUtils.left(*, -ve) = ""
StringUtils.left("", *) = ""
StringUtils.left("abc", 0) = ""
StringUtils.left("abc", 2) = "ab"
StringUtils.left("abc", 4) = "abc"
// right(String str, int len) 同上相反
// length(CharSequence cs) 获取字符串大小,返回一个int
// lowerCase(String str) 将字符串转换为小写,返回一个string
// upperCase(String str) 同上相反
// mid(String str, int pos, int len) 获取字符串指定位置区间的字符,返回一个string
// overlay(String str, String overlay, int start, int end) 在字符串位置区间插入指定字符,返回一个string
// prependIfMissing(String str, CharSequence prefix, CharSequence... prefixes) 在字符串最左边插入指定字符,如果已存在,将不插入,返回一个string
// prependIfMissingIgnoreCase(String str, CharSequence prefix, CharSequence... prefixes) 同上,只是不区分大小写
// remove(String str, char remove) 删除字符串中指定字符,返回一个string
// removeIgnoreCase(String str, String remove) 同上,只是不区分大小写
// removeAll(String text, String regex) 根据匹配规则删除所有字符,返回一个string
StringUtils.removeAll(null, *) = null
StringUtils.removeAll("any", null) = "any"
StringUtils.removeAll("any", "") = "any"
StringUtils.removeAll("any", ".*") = ""
StringUtils.removeAll("any", ".+") = ""
StringUtils.removeAll("abc", ".?") = ""
StringUtils.removeAll("A<__>\n<__>B", "<.*>") = "A\nB"
StringUtils.removeAll("A<__>\n<__>B", "(?s)<.*>") = "AB"
StringUtils.removeAll("ABCabc123abc", "[a-z]") = "ABC123"
// removeEnd(String str, String remove) 删除字符串结尾指定字符,返回一个string
StringUtils.removeEnd(null, *) = null
StringUtils.removeEnd("", *) = ""
StringUtils.removeEnd(*, null) = *
StringUtils.removeEnd("www.domain.com", ".com.") = "www.domain.com"
StringUtils.removeEnd("www.domain.com", ".com") = "www.domain"
StringUtils.removeEnd("www.domain.com", "domain") = "www.domain.com"
StringUtils.removeEnd("abc", "") = "abc"
// removeStart(String str, String remove) 同上相反
// removeEndIgnoreCase(String str, String remove) 同上,只是不区分大小写
// removeFirst(String text, String regex) 根据匹配规则删除第一次出现的字符,返回一个string
// repeat(String str, int repeat) 将字符重复指定次数拼接成新的字符串,返回一个string
// replace(String text, String searchString, String replacement) 用replacement替换字符串中的所有searchString,返回一个string
// reverse(String str) 将字符串反转,返回一个string
// reverseDelimited(String str, char separatorChar) 将字符串指定分隔符出的字符反转
StringUtils.reverseDelimited(null, *) = null
StringUtils.reverseDelimited("", *) = ""
StringUtils.reverseDelimited("a.b.c", 'x') = "a.b.c"
StringUtils.reverseDelimited("a.b.c", ".") = "c.b.a"
// split(String str, String separatorChars) 将字符串以指定字符分隔,返回数组
StringUtils.split(null, *) = null
StringUtils.split("", *) = []
StringUtils.split("abc def", null) = ["abc", "def"]
StringUtils.split("abc def", " ") = ["abc", "def"]
StringUtils.split("abc def", " ") = ["abc", "def"]
StringUtils.split("ab:cd:ef", ":") = ["ab", "cd", "ef"]
// substring(String str, int start) 将字符串从指定位置区间截取,返回string
// swapCase(String str) 将字符串大小写互转,返回一个string
StringUtils.swapCase(null) = null
StringUtils.swapCase("") = ""
StringUtils.swapCase("The dog has a BONE") = "tHE DOG HAS A bone"
// toEncodedString(byte[] bytes, Charset charset) 将字符串转为指定编码格式,返回一个string
// trim(String str) 去除字符串空格
// trimToEmpty(String str) 去除字符串空格,null转为empty,返回一个string
StringUtils.trimToEmpty(null) = ""
StringUtils.trimToEmpty("") = ""
StringUtils.trimToEmpty(" ") = ""
StringUtils.trimToEmpty("abc") = "abc"
StringUtils.trimToEmpty(" abc ") = "abc"参考博客文章:commons-lang3工具类学习(一)、commons-lang3工具类学习(二)、commons-lang3工具类学习(三)、commons-lang3常用工具类api整理
注意事项:不能部分使用DISTINCT,DISTINCT关键字应用于所有列而不仅仅是前置它的列。如果给出SELECT DISTINCT 字段1,字段2,除非指定的两个列都不同,否则所有行都将被检索出来。
注意事项:
LIMIT 5:表示返回数据不多于5行(带一个值的LIMIT总是从第一行开始,给出的数为返回的行数)。LIMIT 5, 5:表示返回从行5开始的5行(带二个值的LIMIT,第一个数为开始位置,第二个数为要检索的行数)。- 行0:检索出来的第一行为行0而不是行1(如LIMIT 1, 1将检索出第二行而不是第一行)。
LIMIT 4 OFFSET 3 等价于 LIMIT 3, 4: MySQL 5版本之后。
- 表名.字段名:完全限定列。
- 数据库名.表名:完全限定表。
ORDER BY 字段1,字段2:表示先按字段1排序,再按照字段2排序。DESC:降序。ASC:升序(很少使用,因为升序是默认的)。- MySQL中默认字典排序中的A和a视为相同,但是数据库管理员可以变更这种行为。
- 顺序问题:ORDER BY 需位于FROM之后,LIMIT需位于ORDER BY之后,即
FROM...ORDER BY...LIMIT...。
- 顺序问题:
FROM...where...ORDER BY...LIMIT...。 - 过滤:也可以在应用层过滤数据。
- 关于!=与<>:
- BETWEEN...AND:包含开始值与结束值。
- IS NULL: NULL与不匹配含义不同。
- 优先级:AND>OR。
- IN与OR能实现相同的功能,但是IN更优雅、效率更快、计算次序更易管理,且IN中可以包含其他SELECT语句。
- 关于NOT: MySQL支持使用NOT对IN、BETWEEN、和EXISTS子句取反,这与多数其他DBMS允许使用NOT对各种条件取反有很大的差别。
- %:表示任何字符出现任意次数(包含0个字符);但是%不能匹配NULL,%可以匹配空格,但一般不这样使用(一般采用函数去掉首尾空格)。
- _:只能匹配单个字符(不能是0个字符)。
- 通配符效率很低,尽量少使用。
-
REGEXP + 正则表达式
-
LIKE与REGEXP: LIKE是整个匹配,REGEXP是只要出现就算匹配;REGEXP配合使用^和$可以实现与LIKE相同的功能(可以比LIKE更精确)。
-
正则表达式匹配默认不区分大小写,若要区分,则使用
REGEXP BINARY + 正则表达式。 -
|:类似于OR匹配。注意
'1|2|3 Ton'和'(1|2|3) Ton'的区别,时刻不要忘记加括号(务必避免歧义的出现)。 -
[]:类似于枚举,另一种形式的OR匹配。
-
[a-z]:匹配范围。
-
[^a-z]:反向匹配。
-
\\.:匹配.特殊字符(\\类似于转义字符)。 -
匹配字符类:
[:alnum:]:同[a-zA-Z0-9] [:alpha:]:同[a-zA-Z] [:blank:]:同[\\t] [:cntrl:]:匹配ASCII控制字符(ASCII 0到31和127) [:digit:]:同[0-9],例如[[:digit:]]{4}等价于[0-9]{4} [:lower:]:同[a-z] [:upper:]:同[A-Z] [:xdigit:]:同[a-fA-F0-9]
-
匹配多个实例:
* 0个或多个匹配 + 1个或多个匹配,同{1,} ? 0个或1个匹配,同{0,1} {n} 指定数目的匹配 {n,} 不少于指定数目的匹配 {n,m} 匹配数目的范围(m不超过255)
-
定位符:
^ 文本的开始 $ 文本的结束 [[:<:]] 词的开始 [[:>:]] 词的结尾
- Concat():拼接字段。
- RTrim(): 去掉右边所有的空格。
- AS:设置别名。
- 执行算术计算。
-
文本处理函数:
RTrim() 去除列值右边的空格 LTrim() 去除列值左边的空格 Upper() 将文本转化为大写 Lower() 将串转换为小写 Length() 串的长度 Locate() 找出串的一个字串 Right() 返回串右边的字符 SubString() 返回字串的字符 Soundex() 返回串的SOUNDEX值,可以匹配发音相同的值
-
日期和时间处理函数:
AddDate() 增加一个日期(天、周等) AddTime() 增加一个时间(时、分等) CurDate() 返回当前日期 CurTime() 返回当前时间 Date() 返回日期时间的日期部分(很重要) Time() 返回日期事件的时间部分(很重要) Date_Format() 返回一个格式化的日期或时间串 Year() 返回一个日期的年份部分(很重要) Month() 返回一个日期的月份部分(很重要) MySQL默认使用的日期格式为yyyy-mm-dd -- 以下函数使用频率较高 now():显示当前年份、月份、日期、小时、分钟和秒 current_date():仅显示当前年份、月份、日期 datadiff(A,B):确定两个日期之间的差异、通常用于计算年龄 subtimes(A,B):确定两次之间的差异
-
数值处理函数:
Abs() 返回绝对值 Mod() 但会除操作数的余数 Rand() 返回一个随机数
-
聚集函数:
AVG() 返回某列的平均值(会忽略列值为NULL的行) COUNT() 返回某列的行数(会忽略列值为NULL的行) COUNT(*) 返回某列的行数(不会忽略列值为NULL的行) MAX() 返回某列的最大值(会忽略列值为NULL的行) MIN() 返回某列的最小值(会忽略列值为NULL的行) SUM() 返回某列值之和(会忽略列值为NULL的行)
使用GROUP BY创建分组:
-
顺序问题:
FROM...WHERE...GROUP BY...ORDER BY...LIMIT...。 -
GROUP BY子句中不能使用聚集函数和别名。
-
如果列中有多行NULL值,将被分为一组。
-
使用WITH ROLLUP可以得到每个分组以及每个分组汇总级别。
使用HAVING过滤分组:
- HAVING与WHERE的区别:WHERE过滤行,HAVING过滤分组。
- 顺序问题:
FROM...WHERE...GROUP BY...HAVING...ORDER BY...LIMIT...。
- 子查询非常难以阅读,尽量少用。
-
建立联结关系时,再引用的列可能出现二义性时,必须用完全限定列名。
-
不使用where条件建立联结表时,会使用笛卡尔积建立联结表。
-
INNER JOIN...ON:注意这里使用ON而不是where。
-
联结表非常耗费资源,尽量少使用或者使用联结的表越少越好。
-
联结的种类:自联结/自然联结/外部联结。
-
外部联结:LEFT OUTER JOIN...ON:左外联结;RIGHT OUTER JOIN...ON:右外联结。
-
使用UNION关键字。
-
UNION规则:
- 必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 列数据类型必须兼容。
-
UNION会自动去除重复的行;若不想去除重复的行,可以使用UNION ALL。
-
对组合结果进行排序:
SELECT...WHERE...UNION...SELECT...WHERE...ORDER BY...;组合查询时,ORDER BY只能出现在最后一条SELECT语句之后,但可以对所有组合结果进行排序。
-
MyISAM支持全文本搜索(MySQL的默认引擎是MyISAM);InnoDB不支持全文本搜索。
-
采用通配符+正则表达式可以实现全文本搜索,有以下缺点(正是这些缺点的存在,才会引入全文本搜索):
- 性能非常低(匹配表中所有行+极少使用表索引)。
- 不能明确控制匹配什么和不匹配什么。
- 不能提供一种智能化的选择结果的方法(不能对结果进行优先级排序)。
-
启用全文本搜索支持:创建表时,添加
FULLTEXT(字段名)子句。 -
进行全文本搜索:
SELECT...FROM...WHERE Match(字段名) Against('指定要搜索的表达式') -
除非使用BINARY方式,否则全文本搜索不区分大小写。
-
使用查询拓宽:
SELECT...FROM...WHERE Match(字段名) Against('指定要搜索的表达式' WITH QUERY EXPANSION)。(使用查询拓展时,MySQL会进行两遍扫描来完成搜索:第一遍找出与搜索条件匹配的所有行,第二遍使用所有有用的词再次进行全文本搜索)。 -
布尔文本搜索:
SELECT...FROM...WHERE Match(字段名) Against('指定要搜索的表达式,包含布尔操作符+(包含词)>(包含且增加等级值)-(排除词)<(排除且减少等级值)~(取消一个词的排序值)和(截断操作符,类似于词尾的通配符)' IN BOOLEAN MODE)。
全文本搜索的注意事项:
-
在索引全文本数据时,短词(3个及以下字符的词,数目可以更改)被忽略且从索引中排除。
-
MySQL自带一个内建的非用词列表(可以更改覆盖这个表),这字额词在索引全文本数据时总是被忽略。
-
如果一个词出现在50%以上的行中,那么它将作为一个非用词忽略;50%规则不用于IN BOOLEAN MODE。
-
若表中的行数少于3行,则全文本搜索不返回结果(因为每个词或者不出现,或者至少出现在50%的行中)。
-
忽略词中的单引号,如don't索引为dont。
-
不具有词分隔符(包括日语和汉语)的语言不能恰当地返回全文文搜索结果。
-
仅在MyISAM数据库引擎中支持全文本搜索。
- 插入完整的行:
INSERT INTO 表名 VALUES(字段1值,字段2值,...);(高度依赖表中列的定义次序,不推荐)。 - 插入行的一部分:
INSERT INTO 表名(字段1, 字段2..) VALUES(字段1值,字段2值,...);。 - 插入多行:
INSERT INTO 表名(字段1, 字段2..) VALUES(字段1值,字段2值,...),(字段1值,字段2值,...)...;(比每次插入一行效率更高)。 - 插入某些查询的结果:
INSERT INTO 表名(字段1, 字段2..) SELECT...FROM...WHERE...;
- 更新特定行:
UPDATE 表名 SET...WHERE...; - 使用子查询更新:
UPDATE 表名 SELECT子查询 WHERE...; - 更新表中所有的行:
UPDATE 表名 SET...; - 若更新时出错即要全部撤销更新可以使用
UPDATE IGNORE关键字。 - 删除特定的行:
DELETE FROM 表名 WHERE...; - 删除所有行:
DELETE FROM 表名;或者TRUNCATE 表名(后者速度更快,因为后者的本质是删除原来的表,并重新新建一张表,而前者是逐行删除表中的数据)。
注意事项:
- 除非确实打算更新和删除每一行,否则绝对不要使用不带WHERE子句的UPDATE或DELETE语句。
- 保证每个表都由主键,尽可能像WHERE子句那样使用它。
- 在对UPDATE或DELETE语句使用WHERE子句前,应该先使用SELECT进行测试,保证它过滤的是正确的记录,以防编写的WHERE子句不正确。
- 使用强制实施引用完整性的数据库,这样MySQL将不允许删除具有与其他表相关联的数据的行。
-
创建表:
CREATE TABLE 表名 IF NOT EXISTS(字段1 类型, 字段2 类型,...,PRIMARY KEY(字段名))ENGINE=InnoDB; -
使用多个列构成的主键:
CREATE TABLE 表名 IF NOT EXISTS(字段1 类型, 字段2 类型,...,PRIMARY KEY(字段1,字段2...))ENGINE=InnoDB; -
确定AUTO_INCREMENT的值:让MySQL生成主键的一个缺点是你不知道这些值都是谁,而使用
SELECT last_insert_id()函数可以获得这个值。 -
引擎类型:引擎类型可以混用(缺点是外键不能跨引擎,即使用一个引擎的表不能引用具有使用不同引擎的表的外键),不同表可以使用不同的引擎类型。
- InnoDB:一个可靠的事务处理引擎,但不支持全文本搜索。
- MEMORY:在功能上等同于MyISAM,但由于数据存储在内存中,速度很快(适合于临时表)。
- MyISAM:一个性能极高的引擎,不支持事务处理,但支持全文本搜索。
-
更改表:
- 给表增加一个列:
ALTER TABLE 表名 ADD 字段1 数据类型; - 删除表的一个列:
ALTER TABLE 表名 DROP COLUMN 字段1; - 定义外键:
ALTER TABLE 表1 ADD CONSTRAINT 外键名 FOREIGN KEY(表1的字段) REFERENCES 表2 (表2的字段);
- 给表增加一个列:
-
删除表:
DROP TABLE 表名 -
重命名表:
RENAME TABLE 表名 TO 新表名;、RENAME TABLE 表名1 TO 新表名1, 表名2 TO 新表名2, 表名3 TO 新表名3;
视图:虚拟的表(本质是一个SQL查询的结果集形成的一个虚拟表),不包含表中应该有的任何列或数据。
视图的作用:
- 重用SQL语句。
- 简化复杂的SQL操作。
- 使用表的组成部分而不是整个表。
- 保护数据。可以给用户授权表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示,视图可返回与底层表的表示和格式不同的数据。
视图的规则:
- 唯一命名。
- 视图数目无限制。
- 创建视图需要足够的访问权限。
- 视图可以嵌套。
- 视图不能索引,也不能有关联的触发器或默认值。
- ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也包含ORDER BY,那么该视图中的ORDER BY将被覆盖。
- 视图可以和表一起使用。
使用视图:
- 创建视图:
CREATE VIEW 视图名 AS SELECT语句;。 - 查看创建视图的语句:
SHOW CREATE VIEW 视图名;。 - 删除视图:
DROP VIEW 视图名;。 - 更新视图:
CREATE OR REPLACE VIEW 视图名 AS SELECT语句;(也可以分两步,先DROP,再CREATE)。 - 过滤视图:
CREATE VIEW 视图名 AS SELECT语句 视图的WHERE语句;。 - 更新视图:对视图增加或删除行,实际上是对其基表增加或删除行;但如果视图定义中有以下操作:分组(使用GROUP BY 或HAVING)、联结、子查询、并、聚集函数、DISTINCT、导出(计算)列,则不能进行视图的更新。
存储过程:为以后的使用而保存的一条或多条MySQL语句的集合(可将其视为批文件,本质是一种函数)。
存储过程的作用:简单、安全、高性能。
- 简化复杂的操作。
- 防止错误并保证了数据的一致性。
- 简化对变动的管理。
- 提高性能(使用存储过程比使用单独的SQL语句更快)。
存储过程的缺点:
- 编写存储过程需要更高的技能,更丰富的经验。
- 创建存储过程需要一定的访问权限。
使用存储过程:
- 执行(也称之为调用)存储过程:
CALL 存储过程名(参数1, 参数2, 参数3...);(类似于调用函数) - 创建存储过程:
# 1. 定义带参的存储过程
# OUT表示从存储过程传出值,IN表示传入值,INOUT表示传入传出
CREATE PROCEDURE 存储过程名(OUT 参数1 参数1类型, OUT 参数2 参数2类型, IN 参数3 参数3类型)
BEGIN
SELECT语句;
END; // 注意这里:存储过程的分隔符默认是;,可以使用DELEMITER指定分割符,如DELEMITER // 即指定// 为存储火车的分隔符
# 2. 调用存储过程
CALL 存储过程名(@参数1, @参数2, 2005)
# 3. 显示调用时传出的值
SELECT @参数值-
删除存储过程:
DROP PROCEDURE 存储过程名; -
建立智能化存储过程:
- 使用注释:
--空格。 - 使用DECLARE定义变量:
DECLARE 变量名 变量类型 DEFAULT 变量默认值;。 - 加入程序流程语句:
IF...END IF;。
- 使用注释:
-
显示存储过程创建的语句:
SHOW CREATE PROCEDURE 存储过程名; -
获得何时、由谁创建等详细信息:
SHOW PROCEDURE STATUS 存储过程名;
游标:是一个存储在MySQL服务器上的数据库查询,不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据(MySQL游标只能用于存储过程(和函数))。
游标的注意事项:
- 使用前必须先声明定义游标(使用声明过的游标不需要再次声明,用OPEN语句打开它就可以了)。
- 一旦声明后,必须打开游标以供使用。
- 对于添有数据的游标,根据需要取出(检索)各行。
- 在结束游标使用时,必须关闭游标(一个游标关闭后,若未重新打开,则不能使用它)。
游标的使用:
- 创建游标:
CREATE PROCEDURE 存储过程名()
BEGIN
# 定义游标
DECLARE 游标名 CURSOR
FOR
SELECT语句;
OPEN 游标名;
CLOSE 游标名;
END; # 若此前未关闭游标,到END这里,MySQL会自动帮助关闭游标- 打开游标:
OPEN 游标名; - 关闭游标:
CLOSE 游标名; - 使用游标数据:
触发器:MySQL响应DELETE/INSERT/UPDATE语句而自动执行的某种处理。
场景:
- 每当增加一个顾客到某个数据库表时,都检查其电话号码格式是否正确,州的缩写是否为大写。
- 每当订购一个产品时,都从库存数量中减去订购的数量。
- 无论何时删除一行,都在某个存档表中保留一个副本。
触发器的4各必要条件:
- 唯一的触发器名(数据库中唯一,虽然MySQL 5中要求每个表中唯一即可)
- 触发器关联的表
- 触发器应该响应的活动(DELETE、INSERT、UPDATE)
- 触发器何时执行(处理之前或之后)
触发器的使用:
- 创建触发器:
CREATE TRIGGER 触发器名 AFTER/BEFORE 响应活动(DELETE/INSERT/UPDATE) ON 表名 FOR EACH ROW SELECT '消息'; - 删除触发器:
DROP TRIGGER 触发器名; - 使用触发器:
- INSERT触发器:(例:自动填充创建时间)
- DELETE触发器:(例:逻辑删除)
- UPDATE触发器:(例:自动填充更新时间)
-- 例子:自动给zcprog数据库中的article表中的记录插入创建时间
DELIMITER $$
CREATE
TRIGGER `zcprog`.`auto_insert_datetime` BEFORE INSERT
ON `zcprog`.`article`
FOR EACH ROW BEGIN
SET new.create_time=NOW();
END$$
DELIMITER ;注意事项:
- 每个表每个事件每次只允许一个触发器(因此,每个表最多支持6个触发器,每条INSERT/UPDATE/DELETE的之前和之后)。
- 单一触发器不能与多个事件或多个表关联。
- 若BEFORE触发器失败,则请求操作将不被执行;若BEFORE触发器或语句本身失败,MySQL将不执行AFTER触发器(如果有的话)。
几个概念:
- 事务(transaction):指一组SQL语句。
- 回退(rollback):指撤销指定SQL语句的过程。
- 提交(commit):指将未存储的SQL语句结果写入数据库表。
- 保留点(savepoint):指事务处理中设置的临时占位符,你可以对它发布回退。
使用事务处理:
-
开启事务:
START TRANSACTION; -
回退:
ROLLBACK;(当COMMIT和ROLLBACK语句执行后,事务会自动关闭,将来的更改会隐含提交) -
提交事务:
COMMIT;(当COMMIT和ROLLBACK语句执行后,事务会自动关闭,将来的更改会隐含提交) -
使用保留点:
SAVEPOINT 保留点名称;、ROLLBACK TO 保留点名称; -
更该默认的提交行为:
SET autocommit=0;(默认的MySQL是自动提交所有修改,这里设置为不自动提交更改)。
MySQL性能优化的几个方向**:库表结构优化**、索引优化、查询优化、分区优化(与索引类似)、查询缓存优化。
MySQL并发控制的锁策略:
- 表锁:最基本的锁策略,是开销最小的策略**(举例:MyISAM)**
- 会锁定整张表,当对表进行写操作(插入/删除/更新)前,需要先获取锁,这会阻塞其他用户对该表的所有读写操作;
- 只有没有写锁时,其他读取的用户才能获得读锁;
- 读锁之间是不相互阻塞的。
- 行级锁:最大程度地支持并发处理,同时也带来了最大的锁开销**(举例:InnoDB)**
- 行级锁只在存储引擎层实现,而在MySQL服务器层没有实现
- 所有的存储引擎都以自己的方式显现了锁机制。
- 典型的,InnoDB引擎和XtraDB引擎实现了行级锁。
- 原子性(Atomicity):事务不可分隔,要么全部成功,要么全部失败。
- 一致性(Consistency):事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
- 隔离性(Isolation):事务的隔离性是指一个事务的执行不能被其他事务干扰(即对其他事务不可见)。
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的。即使系统重启也不会丢失。
关于隔离级别:较低的隔离级别(SQL标准中定义了四种隔离级别)可以执行更高的并发,系统的开销也越低。
-
未提交读(READ UNCOMMITTED):
-
事务中的修改,即使没有提交,对其他事务也都是可见的。
-
事务可以读取未提交的数据,称之为脏读。
-
从性能上来说,不会比其他级别好太多,实际中一般很少使用。
-
-
提交读(READ COMMITTED):
- 大多数数据库系统的默认隔离级别都是READ COMMITTED(但MySQL不是),READ COMMITTED满足ACID中隔离性的定义。
- 一个事务从开始直到提交之前,所做的任何修改对其他事务都不可见。这个级别也称之为不可重复读。通俗点说,就是指在⼀个事务内多次读同⼀数据;在这个事务还没有结束时,另⼀个事务也访问该数据。那么,在第⼀个事务中的两次读数据之间,由于第⼆个事务的修改导致第⼀个事务两次读取的数据可能不⼀样。
- 两次执行同样的查询,可能会得到不一样的结果。
-
可重复读(REPEATABLE READ):
- 解决了脏读的问题;保证了在同一个事务中多次读取同样记录的结果是一致的。
- 无法解决幻读问题。所谓幻读,是指当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻读。
- REPEATABLE READ是MySQL的默认事务隔离级别。InnoDB和XtraDB存储引擎通过多版本并发控制解决了幻读的问题。
-
可串行化(SERIALIZABLE):
- 是最高的隔离级别,通过强制事务串行执行,避免了幻读的问题。
- SERIALIZABLE会在读取的每一行数据上都加锁,可能导致大量的超时和锁争用问题。
- 实际中很少使用,只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑该级别。
下面是总结:

InnoDB的MVCC原理:通过在每行记录后面保存两个隐藏的列来实现MVCC。一个列是保存行的创建时间,一个是保存行的过期时间(或删除时间)。当然,存储的并不是实际的时间指,而是系统版本号。每开始一个新的事务,系统版本号会自动递增;事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
在可重复读隔离级别下,MVCC的操作:
- SELECT: InnoDB只查找版本早于当前事务版本的数据行,这样可以确保事务读取的行,要么是事务开始前已存在,要么是事务自身插入或修改的;行的删除版本要么未定义,要么大于当前事务版本号,可以确保事务读取到的行。在事务开始之前未被删除。
- INSERT:为新插入的每一行保存当前系统版本号作为行版本号。
- DELETE:为删除的每一行保存当前系统版本号作为删除标识。
- UPDATE: InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统原来的行作为行删除标识。
MVCC只在可重复读和提交读两个隔离级别下工作。
查看表的信息:SHOW TABLE STATUS LIKE '表名'
InnoDB的特性:事务型引擎
- 数据存储在表空间中。
- 采用MVCC来支持高并发,实现了四个标准的隔离级别,默认级别是可重复读,并且通过间隙锁策略防止幻读的出现。
- InnoDB表是基于聚族索引建立的。
存储引擎的对比:

MyISAM与InnoDB的区别:
- InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条 SQL语言放在begin和commit之间,组成一个事务。
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败。
- InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到 主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文 件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上 述语句时只需要读出该变量即可,速度很快。
- Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高。
MyISAM的特性:非事务型引擎
- 不支持事务和行级锁,崩溃后无法完全修复。
- 将表存储在两个文件中:数据文件和索引文件。
- 采用表锁策略。读取时会对所有表加共享锁,写入时则对表加排他锁。
- 可以手工或者自动执行检查和修复操作。
- 支持全文索引(基于分词创建的索引),可以支持复杂的查询。
- 延迟更新索引键,将索引写入到内存缓冲区中,提升写入性能,缺点是崩溃时会造成索引损坏。
Archive引擎:非事务型引擎
- 只支持INSERT和SELECT操作,每次SELECT查询都需要执行全表扫描,但是INSERT时会缓存所有的写,插入时非常快速。
- 支持行级锁和专用的缓冲区,可以实现高并发的插入。
Memory引擎:
- 所有的数据都保存在内存中,不需要进行磁盘IO。
- Memory表的结构在重启后还会保留,但数据会丢失。
- Memory表支持Hash索引,查找操作非常快。
- Memory是表级锁,并发写入的性能较低。
遵循原则:
-
尽量选择使用可以正确存储数据的最小数据类型。
-
简单数据类型的操作通常需要更少的CPU周期。
- 整型比字符操作代价更低;
- 应该使用MySQL内建的类型而不是字符串来存储日期和时间;
- 应该用整型存储IP地址...
-
尽量避免NULL(最后指定列为NOT NULL,除非真的需要存储NULL值)。
- 可为NULL的列使得索引、索引统计和值比较都更复杂;
- 可为NULL的列会使用更多的存储空间;
- 通常把可为NULL的列改为NOT NULL带来的性能提升比较小,调优时没有必要首先修改掉这种情况,除非确定这会导致问题;
- 若计划在列上建索引,应尽量避免设计成可为NULL的列;
- 有一点例外:InnoDB使用单独的位(bit)存储NULL值,故对于稀疏数据有很好的空间效率。
-
选择合理的数据类型
4.1 整数类型
- MySQL可以为整数类型指定宽度,例如INT(11),对于大多数应用这是没有意义的,它不会限制值的合法范围,只是规定了MySQL的一些交互工具用来显示字符的个数。对于存储和计算来说,INT(1)和INT(20)是相同的。
4.2 实数类型
- 因为需要额外的空间和计算开销,应该尽量只在对小数进行精确计算时才使用DECIMAL,例如存储财务数据。但在数据量比较大的时候,可以考虑使用BIGINT代替DECIMAL,将需要存储的货币单位根据小数的位数乘以相应的倍数即可,这样可以同时避免浮点存储计算不精确和DECIMAL精确计算代价高的问题。
4.3 字符串类型
- VARCHAR比定长类型更节省空间,它仅使用必要的空间。有一种例外:若MySQL表使用ROW_FORMAT=FIXED创建的话,每一行都会使用定长存储,这会很浪费空间。
- VARCHAR需要使用1或2个额外字节记录字符串的长度:若列的最大长度小于或等于255个字节,则只使用1个字节标识,否则使用2个字节。如假设采用latin1字符集,一个VARCHAR(10)的列需要11个字节的存储空间;一个VARCHAR(1000)的列则需要1002个字节的存储空间。
- VARCHAR由于行是变长的,在UPDATE时可能会带来额外的开销。VARCHAR适合于以下情形:若字符串的最大长度比平均长度大很多,列的更新很少,所以碎片不是问题;若使用了像UTF-8这样复杂的字符集,每个字符都使用不同的字节数进行存储。
- CHAR适合存储很短的字符串,或者所有值都接近同一个长度。CHAR适用于以下情形:适合存储密码的MD5值;对于经常需要变更的数据,定长的CHAR不容易产生碎片;对于很短的列,CHAR比VARCHAR在存储空间上更有效率,因为VARCHAR需要额外的字节记录字符串的长度。
- CHAR会截断(MySQL服务器层进行处理)末尾的空格,而VARCHAR不会。
- 使用枚举(ENUM)代替字符串类型。MySQL在存储枚举时非常紧凑,会根据列表值的数量压缩到一个或者两个字节中;MySQL在内部会将每个值在列表中的位置保存为整数,并且在表的.frm文件中保存"数字-字符串"映射关系的"查找表"。此外,枚举字段是按照内部存储的整数而不是定义的字符串进行排序的,绕过这种限制的方式是按照需要的顺序来定义枚举列。
4.4 日期类型
- DATETIME和TIMESTAMP列都可以存储相同类型的数据:时间和日期,精确到秒;而TIMESTAMP只使用DATETIME一半的存储空间,并且会根据时区变化,具有特殊的自动更新能力;但TIMESTAMP允许的时间范围要小的多(TIMESTAMP存储范围为1970-2038年,而DATETIME存储范围为1001-9999年),这有时候会成为障碍。由于空间效率更高,通常应该尽量使用TIMESTAMP。
- TIMESTAMP显示的值依赖于时区。若在多个时区存储或访问数据,TIMESTAMP和DATETIME的行为将很不一样,前者提供的值与时区有关系,后者则保留文本表示的日期和时间。
- TIMESTAMP有DATETIME没有的特殊行为,在插入时若未指定值,则MySQL会设置值为当前时间。
- TIMESTAMP列默认为NOT NULL,这也和其他数据类型不一样。
4.5 位数据类型
- MySQL 5.0以后,可以使用BIT列在一列中存储一个或多个true/false值;BIT(1)定义一个包含单个位的字段,BIT(2)存储2个位...BIT列的最大长度是64个位。
- MySQL把BIT当作字符串类型,而不是数字类型;当检索BIT(1)的值时,结果是一个包含二进制0或1值的字符串,而不是ASCII码的"0"或"1"。例如,若存储一个值b '00111001'(二进制值等于57)到BIT(8)的列并且检索它,得到的内容是字符码为57的字符串,即得到ASCII码为57的字符串9,但是在数字上下文场景中,得到的是数字57。这令人费解,应尽可能避免使用BIT数据类型。
4.6 选择标识符
4.7 特殊类型数据
- 例如IPv4地址,人们经常使用VARCHAR(15)列来存储IP地址;然而,IPv4实际上是32位无符号整数,不是字符串。使用小数点将地址分成4段的表示方法只是为了让人们更易于阅读,故应该使用无符号整数存储IP地址,MySQL提供INET_ATON()和INET_NTOA()函数在两种表示方法之间转换。
-
不要使用太多的列。MySQL存储时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,从行缓冲中将编码过的列传换成行数据结构的操作代价非常高。
-
不要使用太多的关联。MySQL限制了每个关联操作最多只能有61张表。一个经验法则是**:如果希望查询执行得快速且并发性好,单个查询最好在12个表以内做关联**。
-
不要过度使用枚举。例如:country enum('','0', '1', '2',...,'31')这种设计不可取。
-
尽可能使用枚举代替SET集合。
-
尽量避免使用NULL,但是实际业务需求要求使用NULL,那就大胆使用,因为使用神奇常数会导致代码更复杂,也越容易引入Bug。
范式化的优点:
- 更新操作通常比反范式更快。
- 当数据较好地范式化时,就只有很少或者没有重复数据,故只需修改更少得数据。
- 范式化得表通常更小,可以更好地放在内存中,故执行操作会更快。
- 很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句。
范式化的缺点:
- 通常需要关联,复杂查询代价昂贵。
反范式化的优点:
- 当数据比内存大时会比关联要快得多,可以避免随机IO。
- 反范式化的表也能使用更有效的索引策略。
反范式化的缺点:
- 表结构不清晰,有很多重复数据。
- 插入和删除代价昂贵。
实际应用:混用范式化与反范式化:
- 最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
- 避免完全反范式化带来的插入和删除问题。
缓存表:表示存储哪些可以比较简单地从其他表获取(但是每次获取的速度比较慢)数据的表(例如,逻辑上冗余的数据)。
汇总表:保存的是使用GROUP BY语句聚合数据的表(例如,数据不是逻辑上冗余的)。
- 主库切换
- 影子拷贝
- 使用ALTER COLUMN
- 只修改.frm文件
- 快速创建MyISAM索引
索引:在MySQL中也叫做key,是存储引擎用于快速找到记录的一种数据结构。
索引的特点:
- 索引优化应该是对查询性能优化最有效的手段,能够轻易将查询性能提高几个数量级。
- 最优的索引有时比一个好的索引性能要好两个数量级。
- 创建一个真正最优的索引经常需要重写查询。
- 索引可以包含一个或多个列的值。若索引包含多个列,那么列的顺序也十分重要,因为MySQL只能高效地使用索引的最左前缀列。
MySQL支持的索引类型:B-Tree索引、哈希索引、R-Tree索引、全文索引...
B-Tree索引(多路搜索树结构)适用于全键值、键值范围或键前缀查找,其中键前缀查找只适用于根据最左前缀的查找。InnoDB引擎使用的是B-Tree索引。
B-Tree原理:多路搜索树结构的实现。
B-Tree索引的应用:
- 全值匹配:指和索引中的所有列进行匹配。
- 匹配最左前缀。
- 匹配列前缀。
- 匹配范围值。
- 精确匹配某一列并范围匹配另外一列。
- 只访问索引的查询。
- 用于查询中的ORDER BY操作(即可用于排序)。
- 索引中存储了实际的列值,查询获取速度非常快。
B-Tree索引的限制:索引列的顺序很重要!
- 若不是按照索引的最左列开始查找,则无法使用索引。
- 不能跳过索引中的列。
- 若查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查询。
哈希索引:基于哈希表实现,只有精确匹配索引所有列的查询才有效。在MySQL中只有Memory引擎支持哈希索引(如果哈希值相同,会以链表的方式存储),Memory引擎也支持B-Tree索引。
哈希索引的原理:对每一行数据,存储引擎都会对所有的索引列计算出一个哈希码(不同键值的行计算出的哈希码不同);哈希索引将所有的哈希码存储在索引中,同时在哈希索引表中保存指向每个数据行的指针。
哈希索引的优点:结构紧凑、查询速度快。
哈希索引的限制:
- 哈希索引只包含哈希值和行指针,而不存储字段值,不能使用索引中的值来避免读取行;但由于访问内存中的行速度很快,故这一点对性能影响并不明显。
- 哈希索引数据并不是按照索引值顺序存储的,无法用于排序。
- 哈希索引不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。
- 哈希索引只支持等值比较查询,不支持任何范围查询。
- 当出现哈希冲突时,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
- 若哈希冲突很多,则索引维护操作的代价会很高。
自适应哈希索引:属于InnoDB的一种功能,当InnoDB注意到某些索引值被使用的非常频繁时,会在内存中基于B-Tree索引之上再创建一个哈希索引,这样就让B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。但这是一种完全自动的、内部的行为,用户无法控制或配置。
创建自定义哈希索引:在B-Tree基础上创建一个伪哈希索引,使用B-Tree进行查找时,是使用哈希值而不是键本身进行索引查找,需要做的就是在WHERE子句中手动指定使用哈希函数,然后采用触发器维护哈希值。常用的生成哈希的函数有CRC32(若数据表太大,CRC32会产生大量的哈希冲突),不要使用SHA1和MD5函数来生成哈希值(字符串太长,会浪费大量空间),可以使用MD5函数的部分返回值作为哈希值(会比自己写一个哈希算法的性能要差),还可以使用FNV64作为哈希函数,其哈希值为64位,速度快,且冲突比CRC32要少很多。
处理哈希冲突的方法:为了处理哈希冲突,必须在WHERE子句中带入哈希值和对应列值;若只是进行不精确的统计计数,那可以不带对应列值。
R-Tree索引:即空间索引,可以用作地理数据存储。MyISAM引擎支持空间索引。
R-Tree特点:
- 无须前缀查询,空间索引会从所有维度来索引数据;
- 查询时,可以有效地使用任意维度来组合查询;
- 必须使用MySQL的GIS相关函数如MBRCONTAINS()等来维护数据。
全文索引:一种特殊类型的索引,查找的是文本中的关键词,而不是直接比较索引的值。全文索引需要注意的细节有:停用词、词干和复数、布尔搜索等。全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配。
- 索引大大减少了服务器需要扫描的数据量,可以让服务器快速地定位到表的指定位置。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机I/O变为顺序I/O。
"独立的列"是指索引列不能是表达式的一部分,也不能是函数的参数;应该始终将索引列单独放在比较符号的一侧。
-
通过索引开始的部分字符,可以大大节约索引空间,从而提高索引效率,但是会降低索引的选择性(不重复的索引值和数据表的记录总数的比值;唯一索引的选择性是1,这是最好的索引选择性,性能也最好)。
-
前缀索引的关键是:保证前缀索引的选择性接近于索引整个列的选择性。
-
确定前缀索引合适长度的方法:
- 方法一:找到组最常见的值列表,然后和最常见的前缀列表进行比较。
- 方法二:计算完整列的选择性,并使前缀的选择性接近于完整列的选择性。
-- 创建前缀索引的方法:以city字段的前7个字符作为前缀索引 ALTER TABLE sakila.city_demo ADD KEY(city(7))
-
"后缀索引":例如找到某个域名的所有电子邮件地址。MySQL原生并不支持反向索引,但是可以把字符串反转后存储,并基于此建立前缀索引,可以通过触发器来维护这种索引。
-
前缀索引的优缺点
- 优点:能使索引更小、更快。
- 缺点:MySQL无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
- 在多个列上建立独立的单列索引大部分情况下并不能提高MySQL的查询性能。
- MySQL 5.0 的索引合并策略**:OR条件的联合**、AND条件的相交、组合前面两种情况的联合及相交。
- 索引合并策略的使用,恰恰说明表上的索引建得很糟糕,应尽可能避免使用索引合并:
- 当出现多个AND条件的索引合并时,通常意味着需要一个包含所有相关列的多列索引。
- 当出现多个OR条件的索引合并时,通常意味着需要耗费大量CPU和内存资源在算法的缓存、排序和合并操作上。
- 多列B-Tree索引可以实现精确排序。
- 选择索引列顺序的经验法则:当不考虑排序和分组时,将选择性最高的列放到索引最前列。
- 性能不只依赖于索引索引列的选择性,也和查询条件的具体值有关(也就是和值的分布有关),故可能需要根据那些运行频率最高的查询来调整索引列的顺序,让这种情况下索引的选择性最高。
- 不要假设平均情况下的性能也能代表特殊情况下的性能,特殊情况可能会摧毁整个应用的性能。
- 不要忘记WHERE子句中的排序、分组和范围条件等因素,这些也可对查询的性能造成非常大的影响。
聚簇索引:并不是一种单独的索引类型,而是一种数据存储方式。InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中,而节点页则只包含索引列(InnoDB的索引列就是主键列;若没有主键,则InnoDB会选择一个唯一的非空索引代替;若没有唯一的非空索引,则InnoDB会隐式定义一个主键来作为聚簇索引)。因无法把数据行存放在两个不同的地方,故一个表只能有一个聚簇索引。
聚簇索引的优缺点:
-
优点:
- 可以把相关数据保存在一起。如实现电子邮箱时,可根据用户ID来聚集数据,这样只需从磁盘读取少数数据页就能获取某个用户的全部邮件;若没有聚簇索引,则每封邮件都可能导致依次磁盘I/O。
- 数据访问更快。
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
-
缺点:
- 聚簇数据最大限度提高了I/O密集型应用的性能,若将数据全部存放在内存中,则聚簇索引就没什么优势了。
- 插入速度严重依赖于插入顺序。
- 更新聚簇索引列的代价高昂。
- 插入新行时,可能会导致"页分裂"问题,而页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能会导致全表扫描变慢,对于稀疏表尤其如此。
- 二级索引访问需要两次索引查找。二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。对于InnoDB,自适应哈希索引能够减少这样的重复工作。
注意事项:
- 最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于I/O密集型的应用。如使用UUID(对比AUTO_INCREMENT自增,UUID不仅耗时多,而且占用空间也更大)来作为聚簇索引就会很糟糕,它使得聚簇索引的插入变得完全随机,使得数据没有任何聚集特性。最简单的方法是使用AUTO_INCREMENT自增列作为聚簇索引。
覆盖索引:如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为"覆盖索引"。
覆盖索引的优点:
- 索引条目通常远小于数据行的大小,若只需读取索引,那MySQL就会极大地减少数据访问量。
- 索引是按照列值顺序存储的,对于I/O密集型的范围查询会比随机从磁盘读取每一行数据的I/O要少得多。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表(特别是InnoDB的二级主键若能够覆盖查询,则可以避免对主键索引的二次查询)特别有用。
注意事项:
- 覆盖索引必须存储索引列的值,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。
- MySQL不能在索引中执行LIKE操作,但可以使用延迟关联来解决这一问题。
索引排序:若EXPLAIN出来的type列的值为"index",则说明MySQL使用了索引扫描来做排序。
注意事项:
- MySQL可以使用同一个索引既满足排序,又用于查找行。
- 只有当索引的列排序和ORDER BY子句的顺序完全一致,并且所有列的排序方向(倒序或正序)都一样时,MySQL才能使用索引来对结果做排序。
- 若查询需要关联多张表,则只有当ORDER BY子句引用的字段全部为第一个表时,才能使用索引做排序。
- 索引排序不支持范围查询。
- 索引排序要么要么都是正序,要么都是逆序。
压缩索引:MyISAM使用前缀压缩来减少索引的大小,从而让更多的索引可以放入内存中,这在某些情况下能极大地提高性能。默认之压缩字符串,可以在CREATE TABLE语句中指定PACK_KEYS参数来控制索引压缩的方式。
压缩索引原理:先完全保存索引块中的第一个值,然后将其他值和第一个值进行比较得到相同前缀的字节数和剩余不同后缀的部分,把这部分存储起来即可。
压缩索引的优缺点:
- 优点:占用更少的空间。
- 缺点:
- 由于每个值的压缩前缀依赖于前面的值,所以MyISAM查找时无法在索引块使用二分查找而只能从头开始扫描。
- 倒序扫描的速度很慢。
- 在块中查找某一行的操作平均都需要扫描半个索引块。
重复索引:指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复索引,发现以后也应该立即移除。
-- 举例:用户可能是想创建一个主键,先加上唯一限制,然后再加上索引以供查询使用,但是却在不经意间造成了重复索引
-- 因为MySQL的唯一限制和主键限制都是通过索引实现的,因此下面的写法实际上在相同的列上创建了三个重复的索引(通常这样做没有意义,除非是在同一列上创建不同类型的索引来满足不同的查询需求)
CREATE TABLE test(
ID INT NOT NULL PRIMARY KEY,
A INT NOT NULL,
UNIQUE(ID),
INDEX(ID)
)ENGINE=InnoDB;冗余索引:例如,如创建了索引(A,B):若再创建索引(A)(针对B-Tree索引而言,索引(A)是索引(A,B)的前缀索引)就是冗余索引;若再创建索引(B,A)则不是冗余索引;若再创建索引(B)也不是冗余索引;其他不同类型的索引(如哈希索引或者全文索引)也不会是B-Tree的冗余索引(无论覆盖的索引列是什么)。
注意事项:
- 冗余索引通常发生在为表添加新索引的时候。
- 大多数情况下都不需要冗余索引,应该尽量扩展已有索引而不是创建新索引;但若扩展已有索引会导致其变得很大,出于性能考虑也可使用冗余索引。
- 冗余索引会造成INSERT/UPDATE/DELETE速度很慢。
分析未使用索引的工具:MariaDB、Percona Toolkit中的pt-index-usage。
- InnoDB 只有在访问行的时候才会对其加锁,而索引能够减少InnoDB访问的次数,从而减少锁的数量。
- 即使使用了索引,InnoDB也可能锁定一些不需要的数据。
考虑点:
-
首先要考虑的事情是需要使用索引来排序,还是先检索数据再排序,使用索引排序会严格限制索引和查询的设计(例如**:如果MySQL使用某个索引进行范围查询,也就无法再使用另一个索引进行排序了**)。
-
可以在索引中加入更多的列,并通过IN()的方式覆盖那些不在WHERE子句中的列(但不可滥用,因为每增加一个IN()条件,优化器需要做的组合都将以指数形式增长,而这会极大地降低查询性能)。
-
考虑表上所有的选项,要有大局观。
-
尽可能将需要做范围查询的列放到索引的后面,以便优化器能使用尽可能多的索引列。
-
对于范围条件查询(如WHERE...>...),MySQL无法再使用范围后面的其他索引列了,但是对于多个等值条件查询(如WHERE..IN...),则没有限制。
-
为了实现多个范围条件查询,可以将其他范围条件查询(只保留一个范围条件查询)转换为多个等值条件查询。
-
使用延迟关联优化排序。
维护表的三个目的:
-
找到并修复损坏的表
- 检查是否发生了表损坏:
CHECK TABLE - 修复损坏的表:
REPAIR TABLE - 不做任何操作的ALTER操作重建表:
ALTER TABLE 表名 ENGINE=INNODB(INNODB为当前存储引擎)
- 检查是否发生了表损坏:
-
更新索引统计信息
-
获取存储引擎的索引值的分布信息:
- records_in_range():通过向存储引擎传入两个边界值获取在这个范围大概有多少条记录(InnoDB是预估值)。
- info():返回各种类型的数据,包括索引的基数(每个键值有多少条记录)。
-
重新生成信息统计:
ANALYZE TABLE(MyISAM在分析时需要锁表,InnoDB采用的时取样分析) -
查看索引的基数:
SHOW INDEX FROM 表名
-
-
减少索引和数据的碎片
- B-Tree索引的碎片化。
- 表存储碎片化的三种类型**:行碎片**(数据行被存储为多个地方的多个片段中;InnoDB不会出现行碎片,因为其会移动短小的行并重写到一个片段中)、行间碎片(指逻辑上顺序的页、或者行在磁盘上不是顺序存储的)、剩余空间碎片(指数据页中有大量的空余空间)。
- 减少碎片化的方式:
- 重新整理数据:
OPTIMIZE TABLE - 先删除、再重新创建索引
- 不做任何操作的ALTER操作重建表:
ALTER TABLE 表名 ENGINE=INNODB(INNODB为当前存储引擎)
- 重新整理数据:
选择和编写利用索引的查询时,有以下三个原则:
- 单行访问很慢:可以选择合适的索引避免单行查找
- 按顺序访问范围数据是很快的:尽可能使用原生顺序从而避免额外的排序操作
- 索引覆盖查询是很快的:尽可能使用索引覆盖
慢查询的分析方向:
-
确认是否向数据库请求了不需要的数据。
典型案例:
-
查询不需要的记录。解决方法:在查询后面加上LIMIT。
-
多表关联时返回全部列。解决办法:不要使用未加限定的*。
-
总是取出全部列。解决办法:严禁使用SELECT *,这会让优化器无法完成索引覆盖,也会带来额外的I/O、内存和CPU的消耗。
-
重复查询相同的数据。解决方法:使用缓存。
-
-
确认MySQL服务层是否在分析大量超过需要的数据行。
- 衡量查询开销的3个指标**:响应时间**、扫描的行数(检查慢日志是找出扫描行数过多的查询的好办法)、返回的行数。
- 响应时间:服务时间和排队时间之和。
- 访问类型(type)由慢到快:全表扫描(ALL)、索引扫描(index)、范围扫描(range)、唯一索引扫描(ref)、单值访问(const)...
- 应用WHERE条件的三种方式(从好到坏依次是)
- 在索引中使用WHERE条件来过滤不匹配的记录,这是在MySQL存储引擎层完成的。
- 使用索引覆盖扫描来返回记录,这是在MySQL服务器层完成的,但无须再回表查询记录。
- 从数据表中返回数据,然后过滤不满足条件的记录,这是在MySQL服务器层完成的。
- 一个复杂查询还是多个简单查询:不要害怕使用简单查询,MySQL从设计上让连接和断开连接都很轻量级;在通用服务器上,能够运行每秒超过10万的查询。
- 切分查询:例如分页查询、分割成小事务。
- 分解关联查询的优点:
- 可以让缓存更高效(缓存更精细),减少冗余记录的查询(会减少网络和数据库服务器内存的消耗)
- 执行单个查询可以减少锁的竞争
- 在应用层做关联,可以更容易对数据库进行拆分、可扩展性更强
- 分解后的查询往往效率会更高
查询执行路径:
客户端-->MySQL查询缓存-->MySQL解析器-->生成解析树-->预处理器-->解析树-->查询优化器-->查询执行计划-->查询执行引擎-->API调用接口-->存储引擎-->数据。
查询状态:SHOW FULL PROCESSLIST
- Sleep:线程正在等待客户端发送新的请求。
- Query:线程正在执行查询或者正在将结果发送给客户端。
- Locked:在MySQL服务器层,该线程正在等待表锁(在存储引擎级别实现的锁,如InnoDB的行锁,并不会体现在线程状态中)。
- Analyzing and statistics:线程正在收集存储引擎的统计信息,并生成查询的执行计划。
- Copy to temp table:线程正在执行查询,并将其结果集都复制到一个临时表中(这种状态一般要么是在做GROUP BY操作、要么是文件排序操作、或者是UNION操作)。
- Sorting result:线程正在对结果集进行排序。
- Sending data:线程可能在多个状态之间传送数据、或者在生成结果集、或者在向客户端返回数据。
查询缓存:通过一个对大小写敏感的哈希查找实现的。
查询优化处理:
-
语法解析器和预处理
-
查询优化器(基于成本预测的优化器):找出最好的执行计划(此时假设读取任何数据只需依次磁盘I/O)
MySQL中能够处理的优化类型:
-
重新定义关联表的顺序
-
将外连接转化成内连接
-
使用等价变换规则
-
优化COUNT()、MIN()、MAX()
-
预估并转化成为常数表达式
-
覆盖索引扫描
-
子查询优化
-
提前终止查询
-
等值传播
-
列表IN()的比较:MySQL中的IN()并不等同于多个OR()子句;MySQL将IN()列表中的数据先进行排序,然后通过二分查找的方式来确定列表中的值是否满足要求,这是一个O(log n)的操作,等价地转换为OR查询的复杂度为O(n),对于IN()列表中有大量取值的时候,MySQL的处理速度将更快。
......
-
执行计划:MySQL并不会生成查询字节码来执行查询,而是会生成一颗指令树,然后通过存储引擎执行完成这颗指令树并返回结果,最终的执行树包含了重构查询的全部信息。若对某个查询执行EXPLAIN EXTENDED后,再执行SHOW WARNINGS就可以看到重构出的查询。MySQL的执行计划是一颗左侧深度优先的树。
关联查询优化器:通过评估不同顺序的成本来选择一个代价最小的关联顺序。
排序优化:排序操作成本高昂,从性能角度考虑,应尽可能避免排序或者尽可能避免对大量数据进行排序。当不能使用索引排序时,MySQL会自己进行排序,数据量小时会在内存中进行,数据量大时会使用磁盘,不过MySQL将这个过程统一称之为文件排序。
- MySQL的两种排序算法:
- 两次传输排序(旧版本使用)
- 单词传输排序(新版本使用)
查询执行引擎:根据执行计划完成整个查询。
-
关联子查询:
- 不要使用WHERE...IN...嵌套子查询,应该使用JOIN(
INNER JOIN ON/LEFT JOIN ON/RIGHT JOIN ON)来进行关联查询,JOIN的执行效率更高。 - 并不是所有关联查询的性能都会很差;很多时候,关联查询是一种非常合理、自然、甚至是性能最好的写法。
- 针对含DISTINCT/GROUP BY(会产生临时表)的关联查询,子查询的效果会更高。
- 不要使用WHERE...IN...嵌套子查询,应该使用JOIN(
-
UNION的限制**:UNION会进行重复值扫描并删除重复值,而UNION ALL不会**
-
若希望UNION的各个子句能根据LIMIT只取部分结果集,或者希望能先排好序再合并结果集,就需要在UNION的各个子句中分别使用这些子句。
-
使用UNION时,需要注意从临时表中取出数据的顺序并不是一定的,若想获得正确的顺序,还需加上一个全局的ORDER BY和LIMIT操作。
-
-
索引合并优化
-
等值传递:避免产生一个非常大的IN()列表。
-
并行执行:MySQL无法利用多核特性来并行执行查询。
-
哈希关联:MySQL并不支持哈希关联,但是可以创建自定义哈希索引。
-
松散索引扫描:MySQL不支持松散索引扫描,无法按照不连续的方式扫描一个索引。
-- 例如:假设有如下索引(a,b)
-- 有下面的查询:因索引的前导字段是列a,但是在查询中只指定了字段b,导致MySQL无法使用索引,只能通过全表扫描找到匹配的行
SELECT ... FROM tb1 WHERE b BETWEEN 2 AND 3-
最大值和最小值优化
-
在同一个表上查询和更新:通过使用生成表的形式达到对同一张表同时进行查询和更新。
-- 使用生成表der来达到对同一张表同时进行查询和更新的操作
UPDATE tb1
INNER JOIN(
SELECT type, count(*) AS cnt
FROM tb1
GROUP BY type
) AS der USING(type)
SET tb1.cnt = der.cnt;查询优化器的提示:通过在查询中加入相应的提示,可以控制该查询的执行计划。具体请查询MySQL官方手册。
值得指出的是,优化技巧和特定的版本有关,对于未来的MySQL版本未必适用。
COUNT()的作用:
- 统计某个列值的数量(列值非空)
- 统计行数:使用COUNT(*)的时候,这种情况下通配符*并不会像我们猜想的那样扩展成所有的列,它会忽略所有的列而直接统计所有的行数。
常见的错误:在括号内指定了一个列,却希望统计结果集的行数。若希望知道结果集的行数,最好使用COUNT(*),这样写意义清晰,性能也会更好。
注意事项:
- 若MySQL知道某列col不可能为NULL值,那么MySQL内部会将COUNT(col)表达式优化为COUNT(*)。
- 可以使用MyISAM在COUNT(*)全表非常快的整个特性,来加速一些特定条件的COUNT()查询。
-- 查询所有ID大于5的城市
SELECT COUNT(*) FROM world.City WHERE ID>5
-- 优化:将扫描行数减少到5行以内
SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*) FROM world.City WHERE ID <= 5
-- 在同一个查询中统计同一个列的不同值的数量,以减少查询的语句量- 使用COUNT()在同一个查询中统计同一个列的不同值的数量,以减少查询的语句量。
-- 如统计不同颜色的商品数量
SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL) AS red FROM items;
-- 使用SUM函数也可以实现同样的功能
SELECT SUM(IF(color = 'blue', 1, 0)) AS blue, SUM(IF(color = 'red', 1, 0)) AS red FROM items;- 使用近似值;
- 若业务场景不需要完全精确的COUNT值,可以使用近似值来代替。EXPLAIN出来的优化器估算的行数就是一个不错的近似值,执行EXPLAIN并不需要真正地去执行查询,所以成本很低。
- 某些场景,可以尝试删除DISTINCT这样的约束来避免文件排序,这样重写后的查询要比精确统计的查询快得多,返回结果近似。
- 确保ON或USING子句中的列上有索引,并且创建索引的时候就要考虑到关联的顺序。一般来说,除非有其他利用,一般只在关联顺序中的第2个表的相应列上创建索引。
-- 例如:当表A和表B用列C关联时,如果优化器的关联顺序是B,A,那么就不需在B表的对应列上创建索引。- 确保任何GROUP BY和ORDER BY中的表达式只涉及到一个表中的列,这样MySQL才有可能使用索引来优化这个过程。
- 当升级MySQL时需要注意:关联语法、运算符优先级等其他可能会发生变化的地方。
- 尽可能(不绝对)使用关联查询替代子查询。
- 最有效的方法是采用索引来优化。
- 无法使用索引时,在MySQL中,GROUP BY使用两种策略来完成:使用临时表、或者使用文件排序来做分组。这两种策略都可以通过使用提示SQL_BIG_RESULT和SQL_SMALL_RESULT来让优化器按照所希望的方式运行。
- 若需要对关联查询做分组(GROUP BY),并且是按照查找表中的某个列进行分组,通常采用查找表的标识列分组的效率会比其他列更高。
- 若没有通过ORDER BY显示指定排序列,当查询使用GROUP BY时,结果集会自动按照分组的字段进行排序;若不关心结果集的顺序,而这种默认排序又导致了需要文件排序,则可以使用
ORDER BY NULL,达到让MySQL不再进行文件排序的效果;也可以在GROUP BY子句中直接使用DESC或ASC关键字,使分组的结果集按需要的方向排序。 - GROUP BY WITH ROLLUP可以对GROUP BY的结果再做一次超级聚合,但是这会导致文件排序或临时表的产生,最好的办法是尽可能将WITH ROLLUP功能转移到应用程序中处理。
- 一个常见又令人头疼的问题是,使用LIMIT分页时,若偏移量非常大(如LIMIT 10000, 20),这时MySQL需要查询10020条记录然后只返回最后20条,前面10000条记录都将被抛弃,这样的代价非常高。一个最简单的优化方法是尽可能地使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次延迟关联操作再返回所需的列,对于偏移量很大的分页查询效率提升会非常大。
-- LImIT分页优化前
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 10000, 20;
-- LIMIT分页优化后
SELECT film.film_id, film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film
ORDER BY title LIMIT 10000, 20
) AS lim USING(film_id);- 也可以将LIMIT查询转换为已知位置的查询,让MySQL通过范围扫描获得到对应的结果。
-- 若在一个位置列上有索引,并且预先计算出了边界值,则分页查询可以优化为
SELECT film_id, description FROM sakila.film WHERE position BETWEEN 10000 AND 10019 ORDER BY position;- LIMIT的问题本质上是OFFSET的问题,可以使用书签记录上次取数据的位置,下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用OFFSET(即增加一个where条件查询)。
-- 通过记录位置优化LIMIT分页:16030为上一次查询的主键
SELECT * FROM sakila.rental WHERE rental_id < 16030 ORDER BY rental_id DESC LIMIT 20;- 采用冗余表。
- 分页时,可以再LIMIT语句中加上SQL_CALC_FOUND_ROWS提示(hint),这样就可以获得去掉LIMIT以后满足条件的行数,因此可以作为分页的总数。将扫描到的所有满足条件的数据存储到缓存中,提升后续的查询速度。
- MySQL总是通过创建并填充临时表的方式来执行UNION查询,因此很多优化策略在UNION查询中都没法很好地使用。经常需要手动地将WHERE、LIMIT、ORDER BY等子句"下推"到UNION的各个子查询中,以便优化器可以充分利用这些条件进行优化。
- 除非确实需要服务器消除重复的行,否则就一定要使用UNION ALL;若没有ALL,MySQL会给临时表加上DISTINCT选项,这会导致对整个临时表的数据做唯一性检查,代价非常高昂。
使用Percona Toolkit的pt-query-advisor能够解析查询日志、分析查询模式,然后给出所有可能存在潜在问题的查询及建议。
用户自定义变量是一个用来存储内容的临时容器,在连接MySQL的整个过程中都存在。可以使用SET和SELECT语句来定义它们。
-- 自定义变量
@one:=1;
@min_actor:=(SELECT MIN(actor_id) FROM sakila.actor);
@last_week:=CURRENT_DATE-INTERVAL 1 WEEK;
-- 使用变量
SELECT ... WHERE col <= @last_week;下面这些场景不能使用用户自定义变量:
- 使用自定义变量的查询,无法使用查询缓存。
- 不能在使用常量或标识符的地方使用自定义变量,例如表名、列名和LIMIT子句中。
- 自定义变量的生命周期是一个连接中有效,不能用来做连接间的通信。
- 若使用连接池或持久化连接,自定义变量可能让看起来毫无关系的代码发生交互。
- 在MySQL 5.0之前,大小写敏感。
- 不能显式地声明自定义变量的类型。
- MySQL优化器在某些场景下可能会将这些变量优化掉。
- 赋值的顺序和赋值的时间点不固定,依赖于优化器的决定。
- 赋值符号:=的优先级非常低,所以赋值表达式应该使用明确的括号。
- 使用未定义变量不会产生任何语法错误。
使用场景:
- 优化排名语句
-- 使用变量优化排名语句
SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;
SELECT actor_id,
@curr_cnt := cnt AS cnt,
@rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,
@prev_cnt := @curr_cnt AS dummy
FROM(
SELECT actor_id, COUNT(*) AS cnt
FROM sakila.film_actor
GROUP BY actor_id
ORDER BY cnt DESC
LIMIT 10
) AS der;- 避免重复查询刚刚更新的数据
-- 更新行的同时又希望获得行的信息
UPDATE t1 SET lastUpdated = NOW() WHERE id =1;
SELECT lastUpdated FROM t1 WHERE id = 1;
-- 使用变量优化
UPDATE t1 SET lastUpdated = NOW() WHERE id = 1 AND @now := NOW();
SELECT @now;- 统计更新和插入的数量
-- 这里只是演示变量的用法,MySQL的协议会返回被更改的总行数,所以不需要单独统计这个值
INSERT INTO t1(c1, c2) VALUES(4, 4), (2, 1), (3, 1)
ON DUPLICATE KEY UPDATE
c1 = VALUES(c1) + ( 0 * ( @x := @x + 1 ))- 确定取值的顺序
-- 让变量的赋值和取值发生在执行查询的同一阶段
SET @rownum := 0;
SELECT actor_id, @rownum AS rownum
FROM sakila.actor
WHERE (@rownum := @rownum +1) <= 1;- 编写偷懒的UNION
-- 将第一个子查询作为分支条件先执行,如果找到了匹配的行,则跳过第二个分支
SELECT GREATEST(@found := -1, id) AS id, 'users' AS which_tb1
FROM users WHERE id = 1
UNION ALL
SELECT id, 'users_archived'
FROM users_archived WHERE id = 1 AND @found IS NULL
UNION ALL
SELECT 1, 'reset'
FROM DUAL WHERE (@found := NULL) IS NOT NULL;- 用户自定义变量的其他应用
- 查询运行时计算总数和平均值
- 模拟GROUP语句中的函数FIRST()和LAST()
- 对大量数据做一些数据计算
- 计算一个大表的MD5散列值
- 编写一个样本处理函数,当样本中的数值超过某个边界值的时候将其变成0
- 模拟读/写游标
- 在SHOW语句的WHERE子句中加入变量值
MySQL也可以实现地理位置信息,同样,Redis也实现了地理位置信息计算。
-- 地理位置坐标:(经度, 维度)
-- 现有坐标A(latA, lonA)、B(latB, lonB),则A和B两点之间的距离计算公式如下(前提假设地球是圆的)
-- R为地球的半径:R=6371km
ACOS( COS(latA) * COS(latB) * COS(lonA-lonB) + SIN(latA) * SIN(latB) ) * R- 附近的人...
解决思路:
- 先建一个索引过过滤出近似值。
- 再使用精确条件匹配所有的记录并移除不满足条件的记录。
- 根据毕达哥拉斯定理来计算地理位置空间距离。
-
dense_rank():语法结构为dense_rank() over(partition by 分组列 order by 排序列 desc) -
row_number():语法结构为row_number() over(partition by 分组列 order by 排序列 desc) -
rank():语法结构为row_number() over(partition by 分组列 order by 排序列 desc)- 在使用
dense_rank()、row_number()、rank()函数的时候,over()里头的分组以及排序的执行晚于where、group by、order by的执行。
- 在使用
三种排名函数的区别:以给定的五个成绩为例(99,99,85,80,75)
| 函数名 | 关键词 | 作用 | 排序输出效果 |
|---|---|---|---|
| dense_rank() | 连续 | 当出现并列结果时,下一个排名应该是下一个连续的整数值,名次之间没有间隔 | 1,1,2,3,4 |
| row_number() | 行号 | 按顺序输出表的行号 | 1,2,3,4,5 |
| rank() | 间隔 | 当出现并列结果时,下一个排名应该像后递增一位,名次之间有间隔 | 1,1,3,4,5 |
参考题目:分数排名问题
IFNULL(expression, alt_value):用于判断第一个表达式是否为NULL,如果为NULL则返回第二个参数的值,如果不为NULL则返回第一个参数的值。
解决第N高的问题:
- 方法一:使用IFNULL+LIMIT
- 方法二:使用临时表+LIMIT
- 方法三:使用DISTINCT+LIMIT
参考题目:第二高的薪水
定义变量的几种方式:
- 用户定义的变量(前缀为@)
- 局部变量(无前缀)
- 服务器系统变量(以@@为前缀)
:=与=的区别:
- :=主要用在select中显示行号(循环赋值)
- =主要用于set中赋值
参考题目:第N高的薪水
join=inner join=from table1, table2
解决查找重复项的问题:
- 方法一:使用join自联结
- 方法二:使用group by+临时表
- 方法三:使用group by +having(推荐)
参考题目:查找重复的电子邮箱
解决存在/不存在问题:
- 存在:in
- 不存在:not in
- 两个字段的in
delete的新的用法:DELETE t1 FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;,官方sql中,DELETE p1就表示从p1表中删除满足WHERE条件的记录。
参考题目:删除重复的电子邮箱
日期相差1:datediff(date1,date2)=1
参考题目:上升的温度
分库(垂直拆分)分表(水平拆分)
参考博客文章**:《MySQL必知必会》-已读完、《正则表达式必知必会》、关于MySQL可重复读的理解、《高性能MySQL》-已读完前六章**、数据库之六大范式详解、MySQL中key和index的区别、MySQL EXPLAIN type类型说明
本篇是关于SpringCloud+SpringCloud Alibaba的学习总结。
微服务内容:
- 服务注册中心:Eureka(已停更)/Zookeeper/Consul/Nacos
- 服务调用:Ribbon/LoadBalancer
- 服务调用2: Feign(已停更)/OpenFeign
- 服务降级:Hystrix(已停更)/Resilience4j(国外)/Alibaba Sentinel(国内)
- 服务网关:Zuul(已停更)/GateWay
- 配置中心管理:Config(已停更)/Nacos
- 服务总线:Bus(已停更)/Nacos
- ...
SpringCloud:分布式微服务架构的一站式解决方案,是多种微服务架构落地技术的集合体,俗称微服务全家桶。 微服务一般分为无业务基础服务(如全局配置、ID自增器、短链接服务、文件存储服务、身份验证、邮件短信平台、语言回拨...)和业务型基础服务(如:用户中心、账户中心、支付中心、信审系统、信息抓取系统、消息中心、活动广告(CMS)...)。
版本选型:SpringBoot 2.2.2+SpringCloud Hoxton SR1+SpringCloud Alibaba 2.1.0+Java 8+Maven 3.5以上+MySql 5.7以上。
-
查看SpringCloud与SpringBoot大版本对应关系:https://spring.io/projects/spring-cloud#overview
-
查看SpringCloud与SpringBoot小版本的对应关系:https://start.spring.io/actuator/info。
参考文档:
- https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/
- https://www.bookstack.cn/read/spring-cloud-docs/docs-index.md
设置编码设置:IDEA-->Settings-->File Encodings
注解生效激活:IDEA-->Settings-->Annotation Processors-->Enable annotation processing
设置编译版本:java 8
项目模块的创建步骤如下:建Module-->改POM-->写YML-->主启动-->业务类
RestTemplate:提供了多种便捷访问远程HTTP服务的方法,是一种简单便捷的访问restFul服务模块类,是Spring提供的用于访问rest服务的客户端模板工具集。
Hutool:一个Java工具包类库,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类。
- 日期工具:通过DateUtil类,提供高度便捷的日期访问、处理和转换方式。
- HTTP客户端:通过HttpUtil对HTTP客户端的封装,实现便捷的HTTP请求,并简化文件上传操作。
- 转换工具:通过Convert类中的相应静态方法,提供一整套的类型转换解决方案,并通过ConverterRegistry工厂类自定义转换。
- 配置文件工具:通过Setting对象,提供兼容Properties文件的更加强大的配置文件工具,用于解决中文、分组等JDK配置文件存在的诸多问题。
- 日志工具:Hutool的日志功能,通过抽象Log接口,提供对Slf4j、LogBack、Log4j、JDK-Logging的全面兼容支持。
- JDBC工具类:通过db模块,提供对MySQL、Oracle等关系型数据库的JDBC封装,借助ActiveRecord**,大大简化数据库操作。
服务治理:SpringCloud封装了Netflix公司开发的Eureka模块来实现服务治理。在传统的RPC远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,所以需要使用服务治理来管理服务与服务之间的依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
服务注册与发现:Eureka采用了CS的设计架构,Eureka Server作为服务注册功能的服务器,它是服务注册的中心,而系统中的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心跳连接。这样系统的维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常运行。
在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息(比如服务地址、通讯地址等)以别名方式注册到注册中心;另一方(消费者|服务提供者)以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用框架。核心设计**在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何RPC远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址))。

-
Eureka Server:提供服务注册服务。各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观看到。
作用:
- 服务注册:将服务信息注册进注册中心
- 服务发现:从注册中心上获取服务信息
- 实质:存key(服务名),取value(调用地址)
步骤:
-
引入依赖
spring-cloud-starter-netflix-eureka-server -
启动类上使用注解@EnableEurekaServer(用于服务注册中心)
-
配置项:
eureka: instance: hostname: eureka7002.com # Eureka服务端的实例名称 client: register-with-eureka: false # false表示不向注册中心注册自己 fetch-registry: false # false表示自己就是注册中心,我的职责就是维护服务实例,并不需要去检索服务 service-url: # 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖整个地址 defaultZone: http://eureka7001.com:7001/eureka/
-
Eureka Client:通过注册中心进行访问。一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把整个服务节点移除(默认90秒)。
-
引入依赖
spring-cloud-starter-netflix-eureka-client -
启动类上使用注解@EnableEurekaClient(用于服务消费者和服务生产者)
-
RestTemplate上使用@LoadBalanced赋予其负载均衡(默认是轮询)的能力
-
@EnableDiscoveryClient+
org.springframework.cloud.client.discovery.DiscoveryClient可用于服务发现(获取服务信息) -
配置项:
eureka: client: # 表示是否将自己注册进Eureka Server,默认为true register-with-eureka: true # 是否从Eureka Server抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合Ribbon使用负载均衡 fetchRegistry: true service-url: defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # actuator微服务信息完善 instance: instance-id: payment8002 # 主机名称:服务名称修改 prefer-ip-address: true # 访问信息有IP地址显示(需要引入spring-boot-starter-actuator)
-
Eureka自我保护:保护模式主要用于一组客户端和Eureka Server之间存在网络分区场景下的保护。一旦进入保护模式,Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据,也就是不会注销任何微服务。简言之,某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存(属于CAP里的AP分支)。
# 下面这句话表示Eureka进入了自我保护模式
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.为什么会产生Eureka自我保护机制?为了防止Eureka Client可以正常运行,但是与Eureka Server网络不通情况下,Eureka Server不会立刻将Eureka Client服务剔除。
什么是自我保护模式?默认情况下,若Eureka Server在一定时间内没有接收到某个微服务实例的心跳,Eureka Server将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与Eureka Server之间无法正常通信,以上行为可能变得非常危险了,因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过"自我保护模式"来解决这个问题——当Eueka Server节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。自我保护模式是一种应对网络异常的安全保护措施,它的设计哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留)也不会盲目注销任何健康的微服务。使用自我保护模式,可以让Eureka Server集群更加的健壮、稳定。
怎么禁止自我保护?
-
自我保护默认是开启的
# 注册中心Eureka Server将enable-self-preservation设置为false,可以关闭自我保护 eureka.server.enable-self-preservation=true
-
客户端向注册中心发送心跳的时间间隔
# 客户端Eureka Client中可以设置向注册中心Eureka Server发送心跳的时间间隔(默认为30s) eureka.instance.lease-renewal-interval-in-seconds=30
-
注册中心剔除服务的超时时间
# 客户端Eureka Client中可以设置注册中心Eureka Server剔除服务的时间(默认为90s) eureka.instance.lease-expiration-duration-in-seconds
Netflix公司表示Eureka 2.X停更了。
Eureka停止更新后,可以使用Zookeeper替代Eureka。
关于Zookeeper注册中心:
- Zookeeper是一个分布式协调工具,可以实现注册中心功能
- 关闭Linux服务器防火墙后启动Zookeeper服务器
- Zookeeper服务器取代Eureka服务器,作为服务注册中心
使用Zookeeper作为注册中心的步骤:
-
引入Zookeeper依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> </dependency>
-
启动类上使用@EnableDiscoveryClient用于向Zookeeper注册服务
- Zookeeper的服务节点默认是临时的(非持久性的)
- Zookeeper属于CAP里的AP分支
-
配置yml
server: port: 8004 # 8004表示注册到Zookeeper服务器的支付服务提供者端口号 spring: application: name: cloud-provider-payment # 服务别名,注册Zookeeper到注册中心名称 cloud: zookeeper: connect-string: 8.129.65.158:2181 # Zookeeper的IP地址加端口号
-
服务调用:在RestTemplate上使用@LoadBalanced注解
-
搭建Zookeeper集群?
Consul:一套开源的分布式服务发现和配置管理系统,由HashiCorp公司用Go语言开发。提供了微服务系统中的服务治理、配置中心、控制总线等功能,这些功能中的每一个都可以根据需要单独使用,也可以一起使用以构建全方位的服务网络,总之Consul提供了一种完整的服务网格解决方案。它具有很多优点,包括基于raft协议,比较简洁;支持健康检查,同时支持HTTP和DNS协议支持跨数据中心的WAN集群,提供图形界面,跨平台,支持Linux、Mac、Windows。Consul的作用:
- 服务发现:提供HTTP和DNS两种发现方式
- 健康检查:支持多种方式,HTTP、TCP、Docker、Shell脚本定制化
- KV存储:Key、Value的存储方式
- 多数据中心:Consul支持多数据中心
- 可视化Web界面
使用Consul作为注册中心的步骤:
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-consul-discovery</artifactId> </dependency>
-
下载Consul,启动Consul:
consul agent -dev -
启动类上使用@EnableDiscoveryClient用于向Zookeeper注册服务
-
配置yml
server: port: 8006 # Consul服务端口号 spring: application: name: consul-provider-payment # 服务名称 cloud: consul: host: localhost # Consul注册中心地址 port: 8500 discovery: service-name: ${spring.application.name}
-
服务调用:在RestTemplate上使用@LoadBalanced注解
-
搭建Consul集群?
三个注册中心的异同点:
| 组件名 | 语言 | CAP | 服务健康检查 | 对外暴露接口 | SpringCloud集成 | 社区活跃度 |
|---|---|---|---|---|---|---|
| Eureka | Java | AP | 可配支持 | HTTP | 已集成 | 低(2.x版本闭源) |
| Consul | Go | CP | 支持 | HTTP/DNS | 已集成 | 高 |
| Zookeeper | Java | CP | 支持 | 客户端 | 已集成 | 中 |
| Nacos | Java | AP | 支持 | HTTP | 已集成 | 高 |
CAP理论:即Consistency(强一致性)、Availability(可用性)、Partition tolerance(分区容错性);CAP理论关注粒度是数据,而不是整体系统设计的策略。一个分布式系统不可能同时很好的满足一致性、可用性及分区容错性这三个需求。因此,根据CAP原理将NoSQL数据库分成了满足CA原则、满足CP原则和满足AP原则三大类。
- CA:单点集群,满足一致性、可用性的系统,通常在可扩展性上不太强大。
- CP:满足一致性,分区容错性的系统,通常性能不是特别高。
- AP:满足可用性、分区容错性的系统,通常可能对一致性要求低一些。

Ribbon:是Netflix Ribbon实现的一套客户端,用作负载均衡的工具。简单来说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时、重试等。简言之,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单的轮询,随机连接等)去连接这些机器我们很容里使用Ribbon实现自定义的负载均衡算法。
Ribbon目前进入了维护模式。
负载均衡(Load Balance,简称LB)是什么?就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用);常见的负载均衡软件有Nginx、LVS、硬件F5等。
Ribbon本地负载均衡客户端 VS Nginx服务端负载均衡的区别:
- Nginx是服务端负载均衡(集中式LB):客户端所有的请求都会交给Nginx,然后由Nginx实现请求转发,即负载均衡是由服务端实现的。
- Ribbon本地负载均衡(进程内LB):在调用微服务接口的时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
集中式LB与进程内LB:
- 集中式LB:即在服务的消费方和提供方之间使用独立的LB设施(可以是硬件,如F5,也可以是软件,如Nginx),由该设施负责把访问请求通过某种策略转发至服务的提供方。
- 进程内LB:将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。Ribbon就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址。
Ribbon在工作时分为两步:
- 先选择Eureka Server,它优先选择在同一个区域内负载较少的Server。
- 再根据用户指定的策略,在从Server取到的服务注册列表中选择一个地址。其中Ribbon提供了多种策略(比如轮询、随机和根据响应时间加权)。
引入依赖:
<!--spring-cloud-starter-netflix-eureka-client中已经引入了Ribbon(spring-cloud-starter-netflix-ribbon)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>关于RestTemplate的使用:
-
返回对象为响应体中数据转化成的对象,基本上可以理解为Json
@GetMapping("/consumer/payment/get/{id}") public ComonResult<Payment> getPayment(@PathVariable("id") Long id){ return restTemplate.getForObject(PAYMENT_SRV+"/payment/get/"+id, CommonResult.class); }
-
返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等
@GetMapping("/consumer/payment/getForEntity/{id}") public CommonResult<Payment> getPayment2(@PathVariable("id") Long id){ ResponseEntity<CommonResult> entity = restTemplate.getForEntity(PAYMENT_URL + "/payment/get/" + id, CommonResult.class); if (entity.getStatusCode().is2xxSuccessful()){ return entity.getBody(); }else{ return new CommonResult<>(444, "操作失败"); } }
IRule:根据特定算法从服务列表中选取一个要访问的服务。常用的算法如下:
- RoundRobinRule:轮询
- RandomRule:随机
- RetryRule:先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试
- WeightedResponseTimeRule:对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
- BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
- AvailabilityFilteringRule:先过滤掉故障实例,再选择并发较小的实例
- ZoneAvoidanceRule:默认规则,复合判断server所在区域的性能和server的可用性选择服务器

如何替换默认的负载均衡规则?
-
负载均衡配置类不能放在@ComponentScan所扫描的当前包下以及子包下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的。
-
新建MySelfRule类
@Configuration public class MySelfRule { @Bean public IRule myRule(){ //定义为随机 return new RandomRule(); } }
-
主启动类上添加@RibbonClient注解
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class)
轮询负载均衡算法的原理:rest接口第几次请求数%服务器集群总数量=实际调用服务器位置下标
- 每次服务重启动后rest接口计数从1开始
- 服务器位置下标从0开始
自定义负载均衡算法的步骤:关键是原子变量+CAS+自旋锁
-
在RestTemplate上去掉@LoadBalanced注解
-
采用原子变量+CAS+自旋锁定义负载均衡算法
// 定义接口 public interface LoadBalancer { ServiceInstance instances(List<ServiceInstance> serviceInstances); } // 采用原子变量+CAS+自旋锁定义负载均衡算法 @Component public class MyLB implements LoadBalancer { private AtomicInteger atomicInteger = new AtomicInteger(0); public final int getAndIncrement() { int current; int next; do { current = this.atomicInteger.get(); next = current >= Integer.MAX_VALUE ? 0 :current+1; }while (!this.atomicInteger.compareAndSet(current, next)); System.out.println("*****第几次访问,次数next: "+next); return next; } @Override public ServiceInstance instances(List<ServiceInstance> serviceInstances) { int index = getAndIncrement() % serviceInstances.size(); return serviceInstances.get(index); } }
-
服务消费者Controller的编写
@GetMapping(value = "/consumer/payment/lb") public String getPaymentLB() { List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE"); if (CollectionUtils.isEmpty(instances)) { return null; } ServiceInstance serviceInstance = loadBalancer.instances(instances); URI uri = serviceInstance.getUri(); System.out.println(uri); return restTemplate.getForObject(uri + "/payment/lb", String.class); }
OpenFeign:Feign是一个声明式的web服务客户端,让编写web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可。
- Feign指在使编写Java HTTP客户端变得更容易。前面在使用Ribbon+RestTemplate时,利用RestTemplate对HTTP请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步封装,由它来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用SpringCloud Ribbon时,自动封装服务调用客户端的开发量。
- Feign集成了Ribbon,利用Ribbon维护了Payment的服务列表信息,并且通过轮询实现了客户端的负载均衡;而与Ribbon不同的是,通过Feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
Feign与OpenFeign的区别:
| Feign | OpenFeign |
|---|---|
| Feign是SpringCloud组件中的一个轻量级RestFul的HTTP服务客户端;Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。 | OpenFeign是SpringCloud在Feign的基础上支持了SpringMVC的注解,如@RequestMapping等等,OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
org.springframework.cloud spring-cloud-starter-feign |
org.springframework.cloud spring-cloud-starter-openfeign |
采用OpenFeign实现服务调用的步骤:
-
引入依赖
-
主启动类上添加@EnableFeignClients
-
编写服务消费者的service层接口:使用@FeignClient注解(OpenFeign底层采用Ribbon,自带负载均衡配置项,负载均衡切换方法与Ribbon相同)
@Service @FeignClient(value = "CLOUD-PAYMENT-SERVICE") public interface PaymentFeignService { @GetMapping(value = "/payment/get/{id}") public CommonResult<Payment> getPaymentById(@PathVariable("id") Long id); }
-
编写服务消费者的controller
超时控制:
-
OpenFeign默认等待1秒钟,服务端处理超时,会导致Feign客户端报错
java.net.SocketTimeoutException: Read timed out -
在配置文件中设置超时控制
# 设置Feign客户端超时时间(OpenFeign默认支持ribbon) ribbon: # 指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间 ReadTimeout: 5000 # 指的是建立连接后从服务器读取到可用资源所用的时间 ConnectTimeout: 5000
日志增强:OpenFeign提供了日志打印功能,可以通过配置来调整日志级别,从而了解OpenFeign中HTTP请求的细节。简言之,对Feign接口的调用情况进行监控和输出。OpenFeign的日志级别:
-
NONE:默认的,不显示任何日志
-
BASIC:仅记录请求方法、URL、响应状态码及执行时间
-
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息
-
FULL:除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据
开启日志增强的步骤:
-
创建配置类
@Configuration public class FeignConfig { @Bean Logger.Level feignLoggerLevel(){ return Logger.Level.FULL; } }
-
配置yml
logging: level: # OpenFeign日志以什么级别监控哪个接口 com.zcprog.springcloud.service.PaymentFeignService: debug
Hystrix已停止更新,进入维护阶段
服务雪崩:多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的"扇出"。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,造成"雪崩效应"。
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
雪崩:通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者称为雪崩。
Hystrix:一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器"本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
Hystrix的用途:服务降级、服务熔断、服务限流、接近实时的监控...
-
服务降级:服务器忙,请稍候再试,不让客户端等待并立刻返回一个友好提示,fallback。下面这些情况会发出降级:
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
-
服务熔断:类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示。
- 服务的降级-->进而熔断-->恢复调用链路
-
服务限流:秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行。
Hystrix的使用:
-
引入依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
-
配置yml
server: port: 8001 spring: application: name: cloud-provider-hystrix-payment # eviction-interval-timer-in-ms: 2000 eureka: client: register-with-eureka: true # 表示向注册中心注册自己 fetch-registry: true # 表示需要去检索服务 service-url: #设置与eureka server交互的地址查询服务和注册服务都需要依赖这个地址 # defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/ # 集群模式 defaultZone: http://eureka7001.com:7001/eureka/ # 单机模式 # server: # enable-self-preservation: false # 关闭自我保护
-
在启动类上使用@EnableEurekaClient注解
高并发下导致服务器变慢或宕机/出错的解决方法:
- 对方服务(8001)超时了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)宕机了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者),自己处理降级
服务降级:既可以放在客户端,也可以放在服务端;一般建议放在客户端。
服务端进行服务降级的步骤:
-
启动类上添加@EnableCircuitBreaker(或使用@EnableHystrix,@EnableHystrix本质是对@EnableCircuitBreaker的封装)、@EnableEurekaClient
-
Service方法上使用@HystrixCommand(其对热部署支持不太友好,有时需要重新启动)
// fallbackMethod:出现异常或者超时后跳转的方法 @HystrixCommand(fallbackMethod = "paymentInfo_TimeOutHandler", commandProperties = { @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000") })
客户端进行服务降级的步骤:
-
开启feign-hystrix
feign: hystrix: enabled: true # 开启feign的hystrix支持
-
在启动类上添加@EnableHystrix、@EnableFeignClients
-
控制器方法上使用@HystrixCommand(其对热部署支持不太友好,有时需要重新启动)
@GetMapping("/consumer/payment/hystrix/timeout/{id}") // fallbackMethod:出现异常或者超时后跳转的方法 @HystrixCommand(fallbackMethod = "paymentTimeOutFallbackMethod", commandProperties = { @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1500") })
-
Service接口上使用@FeignClient注解,表示使用OpenFeign进行服务调用
@FeignClient(value = "CLOUD-PROVIDER-HYSTRIX-PAYMENT")
-
在控制器类上使用@DefaultProperties可以添加全局降级方法:当控制器方法上使用@HystrixCommand时但未指定降级方法时,全局降级方法生效
// 类上 @DefaultProperties(defaultFallback = "payment_Global_FallbackMethod") // 方法上 @GetMapping("/consumer/payment/hystrix/timeout/{id}") @HystrixCommand
-
为了实现代码解耦,可以采用在第4步的@FeignClient注解中添加fallback属性(该属性指定的类实现了该Service接口,重写的方法都是降级方法),指定降级方法。这样处理之后,可以取消代替第3步和第5步。
@FeignClient(value = "CLOUD-PROVIDER-HYSTRIX-PAYMENT", fallback = PaymentFallbackServer.class)
熔断机制:是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息;当检测到该节点微服务调用相应正常后,恢复调用链路;在SpringCloud里,熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的情况,当失败的调用到一定阈值(缺省是最近10秒内20次调用50%失败),就会启动熔断机制(使用注解@HystrixCommand)。
服务熔断的设置:
// 服务熔断
// 在HystrixCommandProperties.java包含了所有默认配置
@HystrixCommand(fallbackMethod = "paymentCircuitBreaker_fallback", commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"), //是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"), //请求次数(默认值为20)
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "5000"), //全开到半开的时间(默认为5000)
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000"), //滚动时间窗口范围(默认为10000)
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60"), //失败率达到多少后跳闸(默认为50%)
})熔断类型:
- 熔断打开:请求不再进行调用当前服务,内部设置时钟一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入熔断状态
- 熔断关闭:熔断关闭不会对服务进行熔断
- 熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
熔断器在什么情况下开始起作用:涉及到断路器的3个重要参数(快照时间窗、请求总数阈值、错误百分比阈值)
- 快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
- 请求总数阈值:在快照时间窗内,必须满足请求总数阈值才有资格熔断。默认为20次,意味着在10秒内,如果该Hystrix命令的调用次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
- 错误百分比阈值:当请求总数在快照时间窗口内超过了阈值,比如发生了20次调用,如果在这20次调用中,有10次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阈值情况下,这时候就会将断路器打开。
断路器开启或者关闭的条件:
- 当满足一定阀值的时候(默认10秒内超过20个请求次数)
- 当失败率达到一定的时候(默认10秒内超过50%请求失败)
- 到达以上阀值,断路器将会开启
- 当开启的时候,所有请求都不会进行转发
- 一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
断路器打开之后:
- 再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback,通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
- 原来的主逻辑如何恢复呢?当断路器打开,对主逻辑进行熔断之后,Hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑;当休眠时间窗到期,短路器将进入半开状态,释放一次请求到原来的主逻辑上;如果此次请求正常返回,那么断路器将继续闭合,如果此次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
熔断器的所有配置如下:
@HystrixCommand(fallbackMethod = "paymentCircuitBreaker_fallback",
groupKey = "strGroupCommand",
commandKey = "strCommand",
threadPoolKey = "strThreadPool",
threadPoolProperties = {
// 该参数用来设置执行命令线程池的核心线程数,该值也就是命令执行的最大并发量
@HystrixProperty(name = "coreSize", value = "10"),
// 该参数用来设置线程池的最大队列大小。当设置为-1时,线程池将使用SynchronousQueue实现的队列,
// 否则将使用LinkedBlockingQueue实现的队列
@HystrixProperty(name = "maxQueueSize", value = "-1"),
// 该参数用来为队列设置拒绝阈值。通过该参数,即使队列没有达到最大值也能拒绝请求。该参数主要是对LinkedBlockingQueue队列的补充,
// 因为LinkedBlockingQueue队列不能动态修改它的对象大小,而通过该属性就可以调整拒绝请求的队列大小了
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "5"),
},
// 相关属性在HystrixCommandProperties中
commandProperties = {
// 设置隔离策略,THREAD表示线程池,SEMAPHORE表示信号池隔离
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
// 当隔离策略选择信号池隔离时,用来设置信号池的大小(最大并发数)
@HystrixProperty(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 配置命令执行的超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "10"),
// 是否启用超时时间
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
// 执行超时的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnTimeout", value = "true"),
// 执行被取消的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnFutureCancel", value = "true"),
// 允许回调方法执行的最大并发数
@HystrixProperty(name = "fallback.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 服务降级是否启用,是否执行回调函数
@HystrixProperty(name = "fallback.enabled", value = "true"),
// 是否开启断路器
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
// 该属性用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为20的时候,如果滚动时间窗(默认10秒)内收到了19个请求,
// 即使这19个请求都失败了,断路器也不会打开
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"),
// 该属性用来设置在滚动时间窗中,在请求数量超过50次的情况下,如果错误请求数超过50%,就把断路器设置为"打开"状态,否则就设置为
// "关闭"状态
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
// 该属性用来设置当断路器打开之后的休眠时间窗。休眠时间窗结束之后,会将断路器置为"半开"状态,尝试熔断的请求命令,如果依然失败就
// 将断路器继续设置为"打开"状态,如果成功就设置为"关闭"状态
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "5000"),
// 断路器强制打开
@HystrixProperty(name = "circuitBreaker.forceOpen", value = "false"),
// 断路器强制关闭
@HystrixProperty(name = "circuitBreaker.forceClosed", value = "false"),
// 滚动时间窗设置,该时间用于断路器判断健康度时需要收集信息的持续时间
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000"),
// 该属性用来设置滚动时间窗统计指标信息时划分"桶"的数量,断路器在收集指标信息的时候会根据设置的时间窗长度拆分成多个"桶"来累计各度
// 量值,每个"桶"记录了一段时间内的采集指标。比如10秒内拆分成10个"桶"收集这样,所以timeInMilliseconds必须能被numBuckets
// 整除,否则会抛出异常
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "10"),
// 该属性用来设置对命令执行的延迟是否使用百分位数来跟踪和计算。若设置为false,那么所有的概要统计都将返回
@HystrixProperty(name = "metrics.rollingPercentile.enabled", value = "false"),
// 该属性用来设置百分位统计的滚动窗口的持续时间
@HystrixProperty(name = "metrics.rollingPercentile.timeInMilliseconds", value = "60000"),
// 该属性用来设置百分位统计的滚动窗口中使用"桶"的数量
@HystrixProperty(name = "metrics.rollingPercentile.numBuckets", value = "60000"),
// 该属性用来设置在执行过程中每个"桶"中保留的最大执行次数。如果在滚动时间窗内发生超过该设定值的执行次数,就从最初的位置开始重写。
// 例如,将该值设置为100,滚动窗口为10秒,若在10秒内一个"桶"中发生了500次执行,那么该"桶"中只保留最后的100次执行的统计。另外,
// 增加该值的大小将会增加内存量的消耗,并增加排序百分位数所需的计算时间
@HystrixProperty(name = "metrics.rollingPercentile.bucketSize", value = "100"),
// 该属性用来设置采集影响断路器状态的健康快照(请求的成功、错误的百分比)的间隔等待时间
@HystrixProperty(name = "metrics.healthSnapshot.intervalInMilliseconds", value = "500"),
// 是否开启请求缓存
@HystrixProperty(name = "requestCache.enabled", value = "true"),
// HystrixCommand的执行和事件是否打印日志到HystrixRequestLog中
@HystrixProperty(name = "requestLog.enabled", value = "true"),
})可以使用Alibaba的Sentinel来替代。
Hystrix的工作流程图如下:

Hystrix Dashboard:准实时的调用监控。Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少请求、多少成功、多少失败等。Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控。SpringCloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面。
使用Hystrix Dashboard进行图形化监控的步骤:
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency>
-
主启动类上添加@EnableHystrixDashboard注解
-
主启动类中配置ServletRegistrationBean(SpringBoot 2.x才需要)
@Bean public ServletRegistrationBean getServlet(){ HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet(); ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet); registrationBean.setLoadOnStartup(1); registrationBean.addUrlMappings("/hystrix.stream"); registrationBean.setName("HystrixMetricsStreamServlet"); return registrationBean; }
如何查看该图的信息:
- 七色
- 一圈:即实心圆,共有两种含义。它通过颜色的变化代表了实例的健康程度,他的健康度从绿色<黄色<橙色<红色递减。该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例。
- 一线:曲线用来记录2分钟流量的相对变化,可以通过它来观察流量的上升和下降趋势。

Gateway(基于异步非阻塞):基于Spring5.0+SpringBoot2.0+Project Reactor等技术开发的网关,旨在为微服务架构提供一种简单有效的统一的API路由管理方式。Gateway作为SpringCloud生态系统中的网关,目标是替代Zuul,在SptingCloud2.0以上版本中,没有对新版本的Zuul2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。简言之,Gateway使用的Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架。
Gateway的作用:反向代理、鉴权、流量控制、熔断、日志监控...
微服务架构中的网关:

Gateway具有的特性:基于Spring5.0+SpringBoot2.0+Project Reactor构建
- 动态路由:能够匹配任何请求属性
- 可以对路由指定Predicate(断言)和Filter(过滤器)
- 集成Hystrix的断路器功能
- 集成SpringCloud服务发现功能
- 易于编写的Predicate(断言)和Filter(过滤器)
- 请求限流功能
- 支持路径重写
Gateway与Zuul的区别:Gateway基于异步非阻塞架构,而Zuul 1.x基于阻塞架构,Zuul 2.x基于Netty的非阻塞和支持长连接
Gateway的三大核心概念:
-
路由(Route):路由是构建网关的基本模块,它由ID、目标URI、一系列的断言和过滤器组成,如果断言为true则匹配该路由。
-
断言(Predicate):参考的是java8的java.util.function.Predicate开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由。
-
过滤器(Filter):指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
Gateway的工作流程:路由转发(包含断言)和执行过来长期链。
- 客户端向SpringCloud Gateway发出请求,然后在Gateway Handler Mapping中找到与请求相匹配的路由,将其发送到Gateway Web Handler。
- Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。
- Filter在"pre"类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等;在"post"类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等有着非常重要的作用。
Gateway的使用:
-
引入依赖(不需要引入spring-boot-starter-web和spring-boot-starter-actuator):除了网关不需引入actuator,其他都需要引入actuator
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>
-
主启动类上添加@EnableEurekaClient、@EnableDiscoveryClient
-
进行配置
server: port: 9527 spring: application: name: cloud-gateway cloud: gateway: routes: - id: payment_routh # 路由的ID,没有固定规则但要求唯一,建议配合服务名 uri: http://localhost:8001 # 匹配后提供服务的路由地址 predicates: - Path=/payment/get/** # 断言,路径相匹配的进行路由 - id: payment_routh2 uri: http://localhost:8001 predicates: - Path=/payment/lb/** # 断言,路径相匹配的进行路由 eureka: instance: hostname: cloud-gateway-service client: service-url: register-with-eureka: true fetch-registry: true defaultZone: http://eureka7001.com:7001/eureka
Gateway网关路由有两种配置方式:
-
在yml中配置
-
在配置文件中注入RouteLocator的Bean
@Configuration public class GatewayConfig { /** * 配置了一个id为path_route的路由规则,当访问地址http://localhost:9527/guonei时会自动转发到http://news.baidu.com/guonei */ @Bean public RouteLocator customRouteLocator(RouteLocatorBuilder routeLocatorBuilder) { RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes(); routes.route("path_route", r -> r.path("/guonei").uri("http://news.baidu.com/guonei")).build(); return routes.build(); } }
动态路由:默认情况下Gateway会根据注册中心的服务列表,以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由的功能。
修改配置文件:
spring:
application:
name: cloud-gateway
cloud:
gateway:
discovery:
locator:
enabled: true # 开启从注册中心动态创建路由的功能,利用微服务名进行路由
routes:
- id: payment_routh # 路由的ID,没有固定规则但要求唯一,建议配合服务名
# uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service # 匹配动态路由
predicates:
- Path=/payment/get/** #断言,路径相匹配的进行路由
- id: payment_routh2
# uri: http://localhost:8001
uri: lb://cloud-payment-service # 匹配动态路由
predicates:
- Path=/payment/lb/** #断言,路径相匹配的进行路由常用的断言如下:

具体配置:官方地址
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
# Path Route Predicate
- Path=/payment/lb/** #断言,路径相匹配的进行路由
# After Route Predicate
# - After=2021-01-15T22:15:25.348+08:00[Asia/Shanghai] # 这种日期格式可以由ZonedDateTime.now()获得
# Before Route Predicate
# - Before=2017-01-20T17:42:47.789-07:00[America/Denver]
# Between Route Predicate
# - Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
# Cookie Route Predicate:需要两个参数,一个是Cookie name,一个是正则表达式。路由规则会通过对应的Cookie name值和正则表达式
# 去匹配,如果匹配上就会执行路由,如果没有匹配上则不执行
# 使用curl工具(类似于postman)进行测试:curl http://localhost:9527/payment/lb --cookie "username=zzyy"
# - Cookie=username,zzyy
# Header Route Predicate:需要两个参数,一个是属性名称和一个正则表达式,这个属性值和正则表达式匹配则执行
# 使用curl工具(类似于postman)进行测试:curl http://localhost:9527/payment/lb -H "X-Request-Id:1234"
# - Header=X-Request-Id, \d+
# Host Route Predicate
# 使用curl工具(类似于postman)进行测试:curl http://localhost:9527/payment/lb -H "Host:abc.somehost.org"
# - Host=**.somehost.org,**.anotherhost.org
# Method Route Predicate
# 使用curl工具(类似于postman)进行测试:curl http://localhost:9527/payment/lb -X GET
# - Method=GET,POST
# Query Route Predicate
# 使用curl工具(类似于postman)进行测试:curl http://localhost:9527/payment/lb?username=122
- Query=username,\d+Gateway的过滤器:可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用。SpringCloud Gateway内置了多种路由过滤器,它们都由GatewayFilter的工厂类来产生。
- 生命周期:pre、post
- 种类:GatewayFilter、GlobalFilter
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
# Path Route Predicate
- Path=/payment/lb/** #断言,路径相匹配的进行路由
filters:
- AddRequestHeader=X-Request-red, blue自定义全局过滤器GlobalFilter:实现GlobalFilter和Ordered两个接口。
@Component
@Slf4j
public class MyLogGateWayFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("*********come in MyLogGateWayFilter: "+new Date());
String username = exchange.getRequest().getQueryParams().getFirst("username");
if(StringUtils.isEmpty(username)){
log.info("*****用户名为Null, 非法用户,(┬_┬)");
//给人家一个回应
exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
/**
* @return 加载过滤器优先级的顺序,数字越小,优先级越高
*/
@Override
public int getOrder() {
return 0;
}
}提供类似SpringCloud Config功能的还有阿里巴巴的Necos、携程的Apollo。
Config产生背景:微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。
SpringCloud Config能干什么?
- 集中管理配置文件
- 不同环境不同配置,动态化的配置更新,分环境部署比如dev/test/prod/beta/release
- 运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
- 当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
- 将配置信息以REST接口的形式暴露:post、curl访问刷新均可....
SpringCloud Config与Github整合配置:由于SpringCloud Config默认使用Git来存储配置文件(也有其它方式,比如支持svn和本地文件,但最推荐的还是Git,而且使用的是http/https访问的形式)
SpringCloud Config服务端的使用:
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency>
-
创建Git仓库:springcloud-config
-
配置yml
server: port: 3344 spring: application: name: cloud-config-center # 注册进Eureka服务器的微服务名 cloud: config: server: git: uri: https://github.com/progzc/springcloud-config.git # 存放配置文件的github路径 search-paths: - springcloud-config label: main eureka: client: service-url: defaultZone: http://localhost:7001/eureka
-
主启动类上使用@EnableConfigServer、@EnableEurekaClient
配置文件读取规则:
-
/{application}/{profile}[/{label}]
http://config-3344.com:3344/config/dev/main -
/{application}-{profile}.yml
# 验证失败-Why? http://config-3344.com:3344/config-dev.yml
-
/{label}/{application}-{profile}.yml
# 推荐采用这种方法配置文件读取规则 http://config-3344.com:3344/main/config-dev.yml
-
/{application}-{profile}.properties
-
/{label}/{application}-{profile}.properties
SpringCloud Config客户端的使用:
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> </dependency>
-
配置bootstrap.yml
application.yml是用户级的资源配置项;bootstrap.yml是系统级的,优先级更高。
- SpringCloud会创建一个"Bootstrap Context",作为Spring应用的"Application Context"的父上下文。初始化的时候,"Bootstrap Context"负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的"Environment"。
- Bootstrap属性有高优先级,默认情况下,它们不会被本地配置覆盖。"Bootstrap Context"和"Application Context"有着不同的约定,所以新增了一个"bootstrap.yml"文件,保证"Bootstrap Context"和"Application Context"配置的分离。
- 客户端模块的application.yml要改为bootstrap.yml。
server: port: 3355 spring: application: name: config-client cloud: # 配置客户端访问的中心配置文件地址:http://config-3344.com:3344/main/config-dev.yml config: label: main # 分支名称 name: config # 配置文件名称 profile: dev # 读取后缀 uri: http://localhost:3344 # 服务端地址 eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka
-
controller从服务读取配置中心(Github)上的配置文件内容
@RestController public class ConfigClientController { @Value("${config.info}") private String configInfo; @GetMapping("/configInfo") public String getConfigInfo() { return configInfo; } }
背景:修改配置中心(Github)上的配置文件后,服务端可以动态加载变更后的配置文件,但是客户端不能动态加载变更后的配置文件(只能重新启动才能加载更新后的文件),这在生产环境下是不允许的,因此有必要实现客户端的动态刷新。
使客户端动态刷新的步骤:避免了服务重启
-
修改客户端的bootstrap.yml文件
# 添加暴露监控端点 management: endpoints: web: exposure: include: "*"
-
在客户端业务类(本例是Controller)上添加@RefreshScope注解
-
运维人员每次修改配置中心文件后,需要发送Post请求给客户端,通知其进行刷新
curl http://localhost:3355/actuator/refresh -X POST
带来的问题:若存在很多客户端,那么每次更新配置文件后都需要发送很多次POST请求给对应的客户端,这样的解决方式不优雅,可以采用Bus消息总线解决这一问题。
关于RabbitMq的常见命令:
systemctl start rabbitmq-server # 启动RabbitMQ服务器进程
systemctl enable rabbitmq-server # 在引导时自动启动RabbitMQ
systemctl status rabbitmq-server # 检查RabbitMQ服务器的状态
systemctl stop rabbitmq-server # 停止RabbitMQ服务器进程
rabbitmq-plugins enable rabbitmq_management # 启动RabbitMQ Web管理控制台
chown -R rabbitmq:rabbitmq /var/lib/rabbitmq/ # 将RabbitMQ文件的所有权提供给RabbitMQ用户
rabbitmqctl add_user admin StrongPassword # 创建admin用户名及密码
rabbitmqctl set_user_tags admin administrator # 分组
rabbitmqctl set_permissions -p / admin “.*” “.*” “.*” # 给admin用户授权
rabbitmqctl change_password admin 'Newpassword' # 修改admin用户密码SpringCloud Bus:用来将分布式系5统的节点与轻量级消息系统链接起来的框架(与SpringCloud Config结合可以实现配置的分布式动态刷新),它整合了Java的事件处理机制和消息中间件的功能,SpringCloud Bus目前支持RabbitMQ和Kafka。

SpringCloud Bus的能干什么:Bus能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当作微服务间的通信通道。

什么是总线:在微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消息主题,并让系统中所有微服务实例都连接上来。由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线。在总线上的各个实例,都可以方便地广播一些需要让其他连接在该主题上的实例都知道的消息。
总线的基本原理:ConfigClient实例都监听MQ中同一个Topic(默认是SpringCloudBus),当一个服务刷新数据的时候,它会把这个消息放入到Topic中,这样其他监听同一个Topic的服务就能得到通知,然后去更新自身的配置。
有两种通知机制:
- 利用消息总线触发一个客户端/bus/refresh,进而刷新所有客户端的配置
- 利用消息总线触发一个服务端ConfigServer的/bus/refresh端点,进而刷新所有客户端的配置(优于第一种通知机制)
动态刷新全局广播的实现步骤:
-
引入依赖
<!--服务端引入依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bus-amqp</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <!--客户端引入依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bus-amqp</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
-
服务端配置application.yml,客户端配置bootstrap.yml
# 服务端配置application.yml server: port: 3344 spring: application: name: cloud-config-center # 注册进Eureka服务器的微服务名 cloud: config: server: git: uri: https://github.com/progzc/springcloud-config.git # 存放配置文件的github路径 search-paths: - springcloud-config label: main rabbitmq: host: 8.129.65.158 # 不要配置成http://8.129.65.158 port: 5672 # 15672是web管理界面的端口,5672是MQ访问的端口 username: admin password: admin123 eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka # 暴露监控端点 management: endpoints: web: exposure: include: "bus-refresh" #-------------------------------------------------------分割线----------------------------------------------------------- # 客户端配置bootstrap.yml server: port: 3355 # 客户端1配置3355,客户端2配置3366 spring: application: name: config-client cloud: # 配置客户端访问的中心配置文件地址:http://config-3344.com:3344/main/config-dev.yml config: label: main # 分支名称 name: config # 配置文件名称 profile: dev # 读取后缀 uri: http://localhost:3344 # 服务端地址 rabbitmq: host: 8.129.65.158 # 不要配置成http://8.129.65.158 port: 5672 # 15672是web管理界面的端口,5672是MQ访问的端口 username: admin password: admin123 eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka # 暴露监控端点 management: endpoints: web: exposure: include: "*"
-
服务端主启动类上添加@EnableConfigServer、@EnableEurekaClient;客户端上添加@EnableEurekaClient
-
修改Github上的配置文件config-dev
-
使用curl像服务端发送POST请求,则会动态刷新客户端
curl http://localhost:3344/actuator/bus-refresh -X POST
定点通知:修改Github上的配置文件后,不想全部通知(即全局广播),只想通知某些特定的客户端。
实现步骤与全局广播大体相同,区别在最后一步:使用curl像服务端发送POST请求,并指定生效的客户端
# /bus/refresh请求不再发送到具体的服务实例上,而是发给config server并通过destination参数类指定需要更新配置的服务或实例
# destination参数为"微服务名:端口号"
curl http://localhost:3344/actuator/bus-refresh/{destination} -X POST
# 举例:更新Github上的配置文件后,只想通知3355,不想通知3366,可以这样操作
curl http://localhost:3344/actuator/bus-refresh/config-client:3355 -X POSTSpringCloud Stream:屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离;通过向应用程序暴露统一的Channel通道,使得应用程序不需要再考虑各种不同的消息中间件实现。Stream中的消息通信方式遵循了发布-订阅模式,通过Topic主题进行广播(在RabbitMq中Topic就是Exchange,在Kafka中就是Topic)
官方定义SpringCloud Stream是一个构建消息驱动微服务的框架。应用程序通过inputs或者outputs来与SpringCloud Stream中binder对象交互。通过我们配置来binding(绑定),而SpringCloud Stream的binder对象负责与消息中间件交互。所以,我们只需要搞清楚如何与SpringCloud Stream交互就可以方便使用消息驱动的方式。
通过使用Spring Integration来连接消息代理中间件以实现消息事件驱动。SpringCloud Stream为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引用了发布-订阅、消费组、分区的三个核心概念。目前仅支持RabbitMq、Kafka。
Stream中的几个主要概念:
- Binder:很方便的连接中间件,屏蔽差异
- Channel:通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过对Channel对队列进行配置
- Source/Sink:简单的可理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入
编码API和常用注解:

常用的生产者与消费者模型:
-
引入依赖:生产者、消费者引入依赖相同
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
-
配置application.yml:生产者与消费者配置大体相似(生产者与消费者配置不同的地方使用###注释)
server: port: 8801 ### 生产者为8001,消费者为8802 spring: application: name: cloud-stream-provider ### 生产者为cloud-stream-provider,消费者为cloud-stream-consumer cloud: stream: binders: # 在此处配置要绑定的rabbitmq的服务信息; defaultRabbit: # 表示定义的名称,用于于binding整合 type: rabbit # 消息组件类型 environment: # 设置rabbitmq的相关的环境配置 spring: rabbitmq: host: 8.129.65.158 # 不要配置成http://8.129.65.158 port: 5672 # 15672是web管理界面的端口,5672是MQ访问的端口 username: admin password: admin123 bindings: # 服务的整合处理 # 与消费者唯一的区别在这里 output: ### 这个名字是一个通道的名称,生产者为output,消费者为input destination: studyExchange # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: defaultRabbit # 设置要绑定的消息服务的具体设置 # 解决Rabbit health check failed rabbitmq: host: 8.129.65.158 # 不要配置成http://8.129.65.158 port: 5672 username: admin password: admin123 eureka: client: # 客户端进行Eureka注册的配置 service-url: defaultZone: http://eureka7001.com:7001/eureka instance: lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒) lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒) instance-id: send-8801.com ### 在信息列表时显示主机名称,生产者为send-8801.com,消费者为receive-8802.com prefer-ip-address: true # 访问的路径变为IP地址
-
生产者与消费者主启动类上使用@EnableEurekaClient
-
生产者业务类中使用@EnableBinding(Source.class)+MessageChannel bean
// @EnableBinding底层包含@Component @EnableBinding(Source.class) //定义消息的推送管道 public class MessageProviderImpl implements IMessageProvider { @Resource private MessageChannel output; // 消息发送管道 @Override public String send() { String serial = UUID.randomUUID().toString(); output.send(MessageBuilder.withPayload(serial).build()); System.out.println("*****serial: " + serial); return null; } }
-
消费者业务类上使用@EnableBinding(Sink.class)+@StreamListener(Sink.INPUT)+Message bean
// @EnableBinding底层包含@Component @EnableBinding(Sink.class) //定义消息的接收管道 public class ReceiveMessageListenerController { @Value("${server.port}") private String serverPort; @StreamListener(Sink.INPUT) public void input(Message<String> message) { System.out.println("消费者1号,接受:"+message.getPayload()+"\t port:"+serverPort); } }
重复消费:若存在多个消费者,则需要注意重复消费的问题(这是由于默认分组(即组流水号)是不同的)。
解决方法:可以使用Stream中的消息分组来解决(自定义配置分为同一个组,解决重复消费问题)
- 在Stream中处于同一个group中的多个消费者是竞争关系,能够保证消息只会被其中一个应用消费一次。同一个组内会发生竞争关系,只有其中一个可以消费。
- 不同组是可以全面消费的(重复消费)。

解决方法:若不想重复消费,则需在yml配置文件中配置相同的分组名称。

在yml中配置group分组后,可以解决消息的持久化,即当消费者宕机后重新启动时,会从RabbitMQ中消费消息,不会造成消息的丢失。
Sleuth产生背景:在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
SpringCloud Sleuth:提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin dashboard。
zipkin:SpringCloud从F版起已不需要自己构建Zipkin Server了,只需要调用jar包即可。在下载地址下载zipkin-server-2.12.9-exec.jar,下载完成后直接运行java -jar zipkin-server-2.12.9-exec.jar,浏览器输入http://localhost:9411/zipkin/,可以看见zipkin的控制台。
Sleuth原理:一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各Span通过Parent Id关联起来。
- Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
- Span:表示调用链路来源,通俗的理解span就是一次请求信息

搭建链路监控的步骤:
-
引入依赖:消费者和服务提供方引入同样的依赖
<!--包含了sleuth+zipkin--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
-
配置application.yml
# 消费者配置 spring: application: name: cloud-order-service zipkin: base-url: http://localhost:9411 sleuth: sampler: probability: 1 # 采样率,值介于0~1之间,1则表示全部采集 # 服务提供方配置 spring: application: name: cloud-payment-service zipkin: base-url: http://localhost:9411 sleuth: sampler: probability: 1 # 采样率,值介于0~1之间,1则表示全部采集
-
正常写业务逻辑即可
查看调用链路:需要事先启动zipkin

产生背景:
- 2018年12月12日,SpringCloud Netflix项目进入维护模式。
- 2018年10月31日,SpringCloud Alibaba正式入驻了SpringCloud官方孵化器,并在Maven**仓库发布了第一个版本。
SpringCloud Alibaba能干什么:
-
服务的限流降级:默认支持Servlet、Feign、RestTemplate、Dubbo和RocketMQ限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级Metrics监控。
-
服务注册与发现:适配SpringCloud服务注册与发现标准,默认集成了Ribbon的支持。
-
分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
-
消息驱动能力:基于SpringCloud Stream为微服务应用构建消息驱动能力。
-
阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
-
分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于Cron表达式)任务调度服务,同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有Worker(schedulerx-client)上执行。
-
阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
Nacos:Dynamic Naming and Configuration Service,前四个字母分别为Naming和Configuration的前两个字母,最后的s为Service。Nacos是一个更易于构建云原生应用的动态服务发现,配置管理和服务管理中心。简言之,Nacos就是注册中心+配置中心的组合,即Nacos= Eureka+Config+Bus。
Nacos用作服务注册与发现的步骤:
-
启动nacos-server
-
引入依赖
<!--消费者与服务提供方引入相同的依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
-
配置application.yml
# 服务提供方 server: port: 9001 spring: application: name: nacos-payment-provider cloud: nacos: discovery: server-addr: 127.0.0.1:8848 #配置Nacos地址 management: endpoints: web: exposure: include: '*' # 服务消费者 server: port: 83 spring: application: name: nacos-order-consumer cloud: nacos: discovery: server-addr: 127.0.0.1:8848 #配置Nacos地址 service-url: # 自定义属性 nacos-user-service: http://nacos-payment-provider # 消费者将要访问的微服务名称(注册成功进nacos的微服务提供者)
-
消费者与服务提供方主启动类上添加@EnableDiscoveryClient
-
消费者使用@LoadBalanced+RestTemplate,nacos集成了Ribbon,天生自带轮询的负载均衡算法
Nacos与其他注册中心的对比:
-
Nacos与其他注册中心最大的区别是Nacos支持AP(A的定义是所有的请求都会收到响应)和CP(C是所有节点在同一时间点看到的数据是一致的)模式的切换。
-
如何选择何种模式?临时实例(Eureka、Zookeeper)、持久化实例(Consul、CoreDNS)、即可用作临时实例,也可用作服务实例(Nacos)
- 如果不需要存储服务级别的信息且服务实例是通过nacos-client注册,并能够保持心跳上报,那么就可以选择AP模式。当前主流的服务如SpringCoud和Dubbo服务,都适用于AP模式,AP模式为了服务的可用性而减弱了一致性,因此AP模式下只支持注册临时实例。
- 如果需要在服务级别编辑或者存储配置信息,那么CP是必须,K8S服务和DNS服务则适用于CP模式。CP模式下则支持注册持久化实例,此时则是以Raft协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。
-
Nacos中AP和CP模式的切换
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'
-
| Nacos | Eureka | Consul | CoreDNS | Zookeeper | |
|---|---|---|---|---|---|
| 一致性协议 | CP+AP | AP | CP | / | CP |
| 健康检查 | TCP/HTTP/MySQL/Client Beat | Client Beat | TCP/HTTP/gRPC/Cmd | / | Client Beat |
| 负载均衡 | 权重/DSL/metadata/CMDB | Ribbon | Fabio | RR | / |
| 雪崩保护 | 支持 | 支持 | 不支持 | 不支持 | 不支持 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 不支持 | 支持 |
| 访问协议 | HTTP/DNS/UDP | HTTP | HTTP/DNS | DNS | TCP |
| 监听支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 多数据中心 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 跨注册中心 | 支持 | 不支持 | 支持 | 不支持 | 不支持 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| Dubbo集成 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| k8s集成 | 支持 | 不支持 | 支持 | 支持 | 不支持 |
Nacos也可以作为服务配置中心的服务端(类似于SpringCloud Config的服务端;且Nacos也可作为配置中心,功能类似于Github),步骤如下:
-
引入依赖
<!--nacos-config--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--nacos-discovery--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
-
配置bootstrap.yml和application.yml
-
Nacos中的dataid的组成格式与SpringBoot配置文件中的匹配规则:官方地址
组成格式:
${prefix}-${spring.profiles.active}.${file-extension}prefix默认为spring.application.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profiles.active即为当前环境对应的 profile,详情可以参考 Spring Boot文档。 注意:当spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension}file-exetension为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型。
-
例如,下面的配置说明dataid为:
nacos-config-client-dev.yaml
# 配置bootstrap.yml,从配置中心进行配置拉取 # bootstrap.yml优先级高于application.yml server: port: 3377 spring: application: name: nacos-config-client cloud: nacos: discovery: server-addr: localhost:8848 # 服务注册中心地址 config: server-addr: localhost:8848 # 配置中心地址 file-extension: yaml # 指定yaml格式的配置 # application.yml spring: profiles: active: dev
-
-
主启动类上使用@EnableDiscoveryClient
-
业务类上使用SpringCloud原生注解@RefreshScope,实现配置自带更新。
@RestController @RefreshScope public class ConfigClientController { @Value("${config.info}") private String configInfo; @GetMapping("/config/info") public String getConfigInfo() { return configInfo; } }
背景:多环境多项目管理
- 问题1:实际开发中,通常一个系统会准备dev开发环境、test测试环境、prod生产环境,如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件呢?
- 问题2:一个大型分布式微服务系统会有很多微服务子项目,每个微服务项目又都会有相应的开发环境、测试环境、预发环境、正式环境...,那怎么对这些微服务配置进行管理呢?
Namespace+Group+Data ID三者关系:类似于Java里面的package名和包名

-
最外层的Namespace是可以用于区分部署环境的;默认的Namespace为public
- 例如,我们现在有三个环境:开发、测试、生产环境,我们就可以创建三个Namespace,不同的Namespace之间是隔离的
-
Group和Data ID逻辑上区分两个目标对象;默认的Group为DEFAULT_GROUP,默认的DataID为DEFAULT
- Group可以把不同的服务划分到同一个分组里面去
-
Service就是微服务;一个Service可以包含多个Cluster(集群),Nacos默认Cluster是DEFAULT,Cluster是指对指定微服务的一个虚拟划分,比方说为了容灾,将Service微服务分别部署在了杭州机房和广州机房,这时就可以给杭州机房的Service微服务起一个集群名称(HZ),给广州机房的Service微服务起一个集群名称(GZ),还可以尽量让同一个机房的微服务互相调用,以提升性能。
-
Instance:就是微服务的实例
如何进行分类配置?三种方案加载配置
-
方案一:DataID
- 在applicaiton.yml中指定spring.profiles.active和配置文件的DataID来使不同环境下读取不同的配置
-
方案二:Group
- 通过Group实现环境区分
- 在bootstrap.yml中下增加一条group的配置即可,可配置为DEV_GROUP或TEST_GROUP
-
方案三:Namespace
- 通过Namespace实现环境区分
- 在bootstrap.yml中增加一条namespace的配置即可,配置为Namespace ID,如
cab22b95-ed96-4f37-bc08-63cd981bc461
Nacos的持久化:就是将注册信息存储到MySQL中。
Nacos支持三种部署模式:
- 单机模式:用于测试和单机使用
- 集群模式:用于生产环境,确保高可用
- 多集群模式:用于多数据中心场景
Nacos默认自带的是嵌入式数据库derby,生产上使用Nacos集群+高可用MySQL实现部署,derby切换到MySQL的配置步骤:
-
nacos-server-1.1.4\nacos\conf目录下找到sql脚本,在MySQL中创建nacos_config数据库,执行nacos-mysql.sql脚本
CREATE DATABASE nacos_config; USE nacos_config;
-
nacos-server-1.1.4\nacos\conf目录下找到application.properties,添加如下内容
### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root
-
重启Nacos
Nacos集群搭建:1个Nginx+3个Nacos注册中心+1个MySQL
-
Linux下安装Nginx
-
Linux下安装MySQL 5.7.14:安装教程、设置MySQL字符编码
-
Linux下安装nacos
-
创建nacos_config数据库,并执行
nacos/config/nacos-mysql.sql脚本 -
配置
nacos/config/application.properties### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root
-
配置集群
nacos/conf/cluster.conf# 192.168.111.144不能写成localhost,也不能写成127.0.0.1 # 192.168.111.144必须是`hostname -i`命令的值 192.168.111.144:3333 192.168.111.144:4444 192.168.111.144:5555
-
编辑Nacos的启动脚本
nacos/bin/startup.sh,使它能够接受不同的启动端口


-
修改Nginx配置文件
/usr/local/nginx/conf/nginx.conf,进行负载均衡配置;修改完成后启动Nginx -
启动
./startup.sh -p 3333、./startup.sh -p 4444、./startup.sh -p 5555;启动完成后查看nacos集群的启动情况:
ps -ef|grep nacos|grep -v grep|wc -l -
端口、进程之间的相互查询:
- 根据端口查进程号:
lsof -i:port、netstat -nap|grep port、 - 根据进程号查找端口:
netstat -nap|grep pid - 根据程序名称查进程号:
pidof -x program_name、ps -ef|grep program_name、ps aux
- 根据端口查进程号:



Sentinel:以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性,功能上类似于Hystrix,区别在于:
- Sentinel提供单独独立的组件;而Hystrix需要程序员手动搭建监控平台。
- Sentinel可以进行界面化的细粒度统一配置;而Hystrix没有一套web界面可以给我们进行更加细粒度化的配置了(流控、速率控制、服务熔断、服务降级...)
Sentinel的主要特性:

Sentinel分为两部分:
- 核心库(Java客户端)不依赖任何框架/库,能够运行于所有java运行时环境,同时对Dubbo/SpringCloud等框架也有较好的支持
- 控制台(Dashboard)基于SpringBoot开发,打包后可以直接运行,不需要额外的Tomcat等应用容器
- 运行
java -jar sentinel-dashboard-1.7.0.jar - 浏览器输入
localhost:8080,默认用户名和密码都是sentinel
- 运行
Sentinel的基本使用步骤:
-
运行
sentinel-dashboard-1.7.0.jar,访问http://localhost:8080 -
引入依赖
<!--用于Sentinel持久化--> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency> <!--用于服务发现与中注册--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--引入Sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!--引入OpenFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
-
配置application.yml
server: port: 8401 spring: application: name: cloudalibaba-sentinel-service cloud: nacos: discovery: server-addr: 8.129.65.158:8090 # 配置Nginx地址(反向代理转发到Nacos) sentinel: transport: dashboard: localhost:8080 # 配置Sentinel dashboard地址 port: 8719 # 默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口 # Sentinel的持久化配置 datasource: ds1: nacos: server-addr: 8.129.65.158:8090 # 配置Nginx地址(反向代理转发到Nacos) dataId: cloudalibaba-sentinel-service groupId: DEFAULT_GROUP data-type: json rule-type: flow management: endpoints: web: exposure: include: '*'
-
主启动类添加@EnableDiscoveryClient,启动web项目
-
使用Sentinel进行流控、降级、热点key、熔断的设置
- Sentinel采用懒加载机制,需要先执行一次或多次访问,才能在Sentinel中跟踪到簇点链路
-
流控规则
-
资源名:唯一名称,默认请求路径
-
针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)
-
阈值类型/单机阈值:
- QPS(每秒钟的请求数量):当调用该api的QPS达到阈值时,进行限流
- 线程数:当调用该api的线程数达到阈值时,进行限流
-
是否集群:未选中表示不需要集群
-
流控模式:
- 直接:api达到限流条件时,直接限流
- 关联:当关联的资源达到阈值时,就限流自己
- 链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流),属于api级别的针对来源
-
流控效果:
- 快速失败:直接失败,抛异常(默认响应为:
Blocked by Sentinel (flow limiting),可查看com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController) - Warm Up:即预热/冷启动方式,根据codeFactor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的QPS阈值(可查看
com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController)- 应用场景:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是为了保护系统,慢慢的把流量放进来,慢慢把阈值增长到设定的值。
- 排队等待:匀速排队(对应的是漏桶算法),让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效(可查看
com.alibaba.csp.sentinel.slots.block.flow.controller.RateLimiterController)- 应用场景:主要用于处理间隔性突发的流量(削峰填谷),例如消息队列。想象以下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
- 快速失败:直接失败,抛异常(默认响应为:
-
-
降级规则
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其他的资源而导致级联错误;当资源被降级后,在接下来的降级时间窗口之内,对资源的调用都自动熔断,默认行为是先抛出DegradeException;Sentinel的断路器没有半开状态。
- RT(平均响应时间,毫秒级):平均响应时间超出阈值且在1s内通过的请求>=5,这两个条件同时满足后触发降级,窗口期过后关闭断路器。RT最大4900(更大的需要通过
-Dcsp.sentinel.statistic.max.rt=XXX才能生效)。 - 异常比例(秒级):QPS>=5且每秒异常比例超过阈值时,触发降级;时间窗口结束后,关闭降级。
- 异常数(分钟级):近1min异常数超过阈值时,触发降级;时间窗口结束后,关闭降级。
- 由于统计时间窗口是分钟级别的,若时间窗口小于60s,则结束熔断状态后仍可能再进入熔断状态,因此时间窗口一定要>=60s。
- RT(平均响应时间,毫秒级):平均响应时间超出阈值且在1s内通过的请求>=5,这两个条件同时满足后触发降级,窗口期过后关闭断路器。RT最大4900(更大的需要通过
-
热点key限流
相比于普通的流控规则,热点规则可以进行更细粒度(可以对请求参数)的限流。
参数例外项:可以设置当参数是某个特殊值时,它的限流值和平时不一样。
-
系统规则
系统规则一般较少使用,因为不符合web应用的初衷。
系统保护规则是从应用级别的入口流量进行控制,从单台机器的load、CPU使用率、平均RT、入口QPS和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(
EntryType.IN),比如Web服务或 Dubbo服务端接收的请求,都属于入口流量。系统规则支持以下的模式:
- Load自适应(仅对Linux/Unix-like机器生效):系统的load作为启发指标,进行自适应系统保护。当系统load 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。 - CPU usage(1.5.0+ 版本):当系统CPU使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均RT达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的QPS达到阈值即触发系统保护。
- Load自适应(仅对Linux/Unix-like机器生效):系统的load作为启发指标,进行自适应系统保护。当系统load 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的




对比Sentinel和Hystrix,Sentinel的@SentinelResource类似于Hystrix的@HystrixCommand。
注意点:
- 允许按照Url限流或按照资源名限流。二者的区别在于:按照URL限流,限流生效后会返回Sentinel自带默认的限流处理信息(
Blocked by Sentinel (flow limiting));而按照资源名限流,可以自定义限流处理信息(通过blockHandlerClass属性指定类,通过blockHandler指定类中的静态方法)。如果方法上存在@SentinelResource,推荐按照资源名限流。 - @SentinelResource的blockHandler属性主管Sentinel配置异常,不管RuntimeException;fallback属性主管RuntimeException(但除了exceptionsToIgnore属性指定的异常);若同时违背Sentinel配置异常,且程序中抛出RuntimeException,则blockHandler属性生效。
@GetMapping("/rateLimit/customerBlockHandler")
@SentinelResource(value = "customerBlockHandler",
blockHandlerClass = CustomerBlockHandler.class,
blockHandler = "handleException2")
public CommonResult customerBlockHandler() {
return new CommonResult(200, "按客戶自定义", new Payment(2020L, "serial003"));
}
// 注意:CustomerBlockHandler中必须是静态方法
public class CustomerBlockHandler {
// 必须是静态方法
public static CommonResult handleException(BlockException exception) {
return new CommonResult(4444, "按客户自定义,global handlerException----1");
}
// 必须是静态方法
public static CommonResult handleException2(BlockException exception) {
return new CommonResult(4444, "按客户自定义,global handlerException----2");
}
}服务熔断:整合Nacos+Sentinel+Ribbon+OpenFeign
不同熔断框架的比较:
| Sentinel | Hystrix | resilience4j | |
|---|---|---|---|
| 隔离策略 | 信号量隔离(并发线程数限流) | 线程池隔离/信号量隔离 | 信号量隔离 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数 | 基于异常比率 | 基于异常比率、响应时间 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于RxJava) | Ring Bit Buffer |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 | 有限支持 |
| 扩展性 | 多个扩展点 | 插件的形式 | 接口的形式 |
| 基于注解的支持 | 支持 | 支持 | 支持 |
| 限流 | 基于QPS,支持基于调用关系的限流 | 有限的支持 | Rate Limiter |
| 流量整型 | 支持预热模式、匀速器模式、预热排队模式 | 不支持 | 简单的Rate Limiter模式 |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现 | 简单的监控查看 | 不提供控制台、可对接其他监控系统 |
Sentinel的持久化:可以将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上Sentinel上的流控规则持续有效。
Sentinel持久化步骤:
-
引入依赖
<dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency>
-
在application.yml中配置Sentinel的持久化信息
server: port: 8401 spring: application: name: cloudalibaba-sentinel-service cloud: nacos: discovery: server-addr: 8.129.65.158:8090 # 配置Nginx地址(反向代理转发到Nacos) sentinel: transport: dashboard: localhost:8080 # 配置Sentinel dashboard地址 port: 8719 # 默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口 # Sentinel的持久化配置 datasource: ds1: nacos: server-addr: 8.129.65.158:8090 # 配置Nginx地址(反向代理转发到Nacos) dataId: cloudalibaba-sentinel-service groupId: DEFAULT_GROUP data-type: json rule-type: flow management: endpoints: web: exposure: include: '*'
-
在Nacos中配置限流策略:本质是将限流策略写入到Nacos中,启动时将限流策略从服务端加载进Sentinel
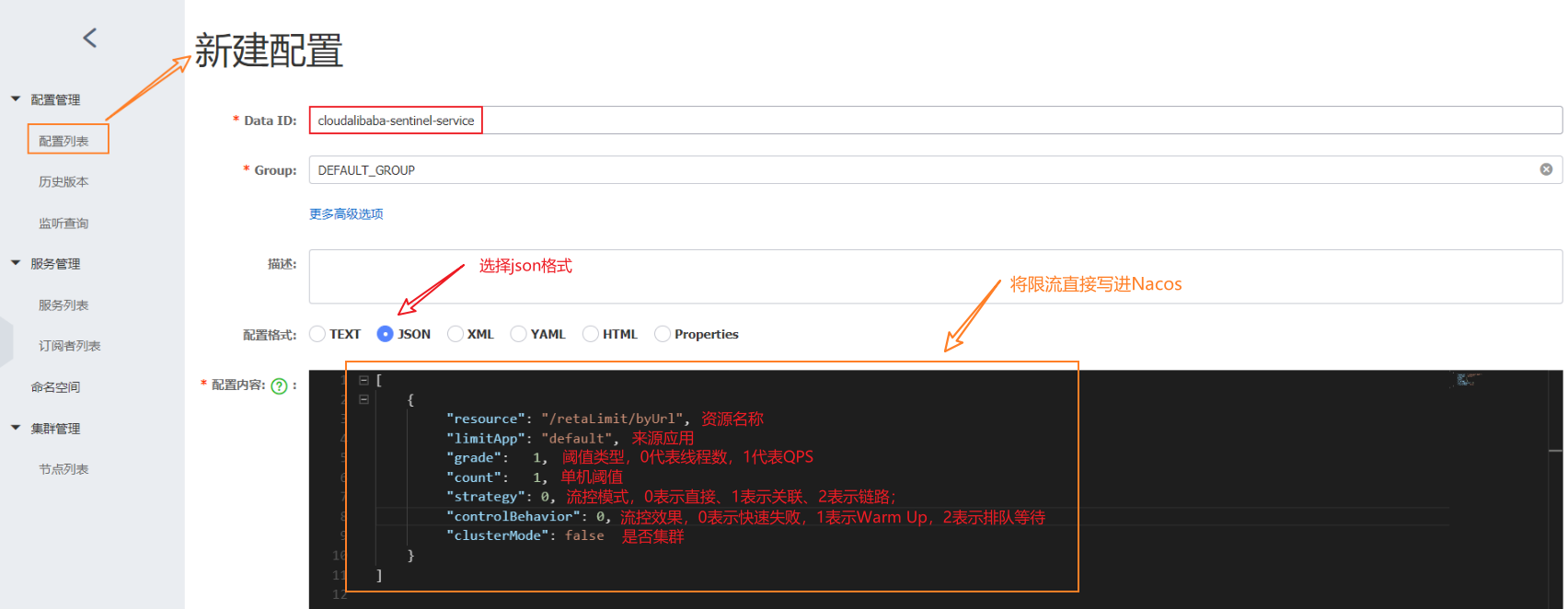

分布式事务:一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题。
Seata:一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。Seata默认是AT模式。
分布式事务处理过程的-ID+三组件模型:
- 一个ID:即Transaction ID XID,全局唯一的事务ID。
- 三组件:
- Transaction Coordinator(TC) :事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚
- Transaction Manager(TM) :事务管理器,控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议
- Resource Manager(RM) :资源管理器,控制分支事务,负责分支注册,状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
Seata的工作原理:
- TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID
- XID在微服务调用链路的上下文中传播
- RM向TC注册分支事务,将其纳入XID对应全局事务的管辖
- TM向TC发起针对XID的全局提交或回滚决议
- TC调度XID下管辖的全部分支事务完成提交或回滚请求

Seata的使用步骤:
-
下载并解压
seata-server-0.9.0,打开seata-server-0.9.0\seata\conf\file.conf,修改自定义事务组名称+事务日志存储模式为db+数据库连接信息。service { # 自定义事务组名称 vgroup_mapping.my_test_tx_group = "fsp_tx_group" default.grouplist = "127.0.0.1:8091" enableDegrade = false disable = false max.commit.retry.timeout = "-1" max.rollback.retry.timeout = "-1" } store { # 修改事务日志存储模式为db mode = "db" file { dir = "sessionStore" max-branch-session-size = 16384 max-global-session-size = 512 file-write-buffer-cache-size = 16384 session.reload.read_size = 100 flush-disk-mode = async } db { datasource = "dbcp" db-type = "mysql" driver-class-name = "com.mysql.jdbc.Driver" # 修改数据库连接信息,包括连接地址、用户名、密码 url = "jdbc:mysql://127.0.0.1:3306/seata" user = "root" password = "root" min-conn = 1 max-conn = 3 global.table = "global_table" branch.table = "branch_table" lock-table = "lock_table" query-limit = 100 } } -
先创建Seata数据库,然后执行
seata-server-0.9.0\seata\conf\db_store.sql脚本。 -
修改
seata-server-0.9.0\seata\conf\registry.conf,指明注册中心为nacos,及修改nacos连接信息# 指明注册中心为nacos,及修改nacos连接信息 registry { type = "nacos" nacos { serverAddr = "localhost:8848" namespace = "" cluster = "default" } }
-
先启动Nacos,再启动seata-server.bat
-
业务说明及创建数据库、数据表
- 业务说明:创建三个服务(订单服务、库存服务、账户服务)
- 当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存
- 接着通过远程调用账户服务来扣减用户账户里面的余额
- 最后在订单服务中修改订单状态为已完成
# 创建订单数据库 CREATE DATABASE seata_order; # 创建库存数据库 CREATE DATABASE seata_storage; # 创建账户数据库 CREATE DATABASE seata_account; #----------------------------------------------------分割线-------------------------------------------------------------- # 在seata_order数据库下创建t_order数据表 CREATE TABLE t_order( `id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id', `product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id', `count` INT(11) DEFAULT NULL COMMENT '数量', `money` DECIMAL(11,0) DEFAULT NULL COMMENT '金额', `status` INT(1) DEFAULT NULL COMMENT '订单状态:0:创建中; 1:已完结' ) ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8; SELECT * FROM t_order; # 在seata_storage数据库下创建t_storage表 CREATE TABLE t_storage( `id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id', `total` INT(11) DEFAULT NULL COMMENT '总库存', `used` INT(11) DEFAULT NULL COMMENT '已用库存', `residue` INT(11) DEFAULT NULL COMMENT '剩余库存' ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; INSERT INTO seata_storage.t_storage(`id`,`product_id`,`total`,`used`,`residue`) VALUES('1','1','100','0','100'); SELECT * FROM t_storage; # 在seata_account数据库下创建t_account表
- 业务说明:创建三个服务(订单服务、库存服务、账户服务)
CREATE TABLE t_account(
id BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'id',
user_id BIGINT(11) DEFAULT NULL COMMENT '用户id',
total DECIMAL(10,0) DEFAULT NULL COMMENT '总额度',
used DECIMAL(10,0) DEFAULT NULL COMMENT '已用余额',
residue DECIMAL(10,0) DEFAULT '0' COMMENT '剩余可用额度'
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO seata_account.t_account(id,user_id,total,used,residue) VALUES('1','1','1000','0','1000');
SELECT * FROM t_account;
6. 按照上述3库分别建对应的回滚日志表,即分别在seata_order、seata_storage、seata_account数据库中执行`seata-server-0.9.0\seata\conf\db_undo_log.sql`脚本。
7. 创建**订单**、**库存**、**账户**三个模块,添加`@GlobalTransactional(name = "fsp-create-order", rollbackFor = Exception.class)`注解
#### 7.1.19.1 Seata的工作原理
[分布式事务的工作原理](https://blog.csdn.net/qq_35067322/article/details/110914143)、[Seata官网的介绍](https://seata.io/zh-cn/docs/overview/what-is-seata.html)
**分布式事务的执行流程**:
1. TM开启分布式事务(TM向TC注册全局事务记录)
2. 换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
3. TM结束分布式事务,事务**一阶段**结束(TM通知TC提交/回滚分布式事务)
4. TC汇总事务信息,决定分布式事务是提交还是回滚
5. TC通知所有RM提交/回滚资源,事务**二阶段**结束。
**Seata AT模式的工作原理**:基于两阶段提交协议的演变
1. 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 解析SQL:得到SQL的类型(UPDATE)、表(product),条件(where name='TXC')等相关的信息
- **查询前镜像**:根据解析得到的条件信息,生成查询语句,定位数据
- 执行业务SQL
- **查询后镜像**:根据前镜像的结果,通过**主键**定位数据
- **插入回滚日志**:把前后镜像数据以及业务SQL相关的信息组成一条回滚日志记录,插入到`UNDO_LOG`表中
- 提交前,向TC注册分支,申请得到记录的**全局锁**
- 本地事务提交:业务数据的更新和前面步骤中生成的`UNDO LOG`一并提交
- 将本地事务提交的结果上报给TC

2. 二阶段:
- 提交异步化,非常快速地完成
- 收到TC的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给TC
- 异步任务阶段的分支提交请求将异步和批量地删除相应`UNDO LOG`记录

- 回滚通过一阶段的回滚日志进行反向补偿
- 收到TC的分支回滚请求,开启一个本地事务,执行如下操作
- 通过XID和Branch ID查找到相应的`UNDO LOG`记录
- 数据校验:拿`UNDO LOG`中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理
- 根据`UNDO LOG`中的前镜像和业务SQL的相关信息生成并执行回滚的语句
- 提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给TC

**多个全局事务的执行**:
1. 一阶段本地事务提交前,需要确保先拿到**全局锁**
2. 拿不到**全局锁**,不能提交本地事务
3. 拿**全局锁**的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁
多个全局事务执行举例:
1. 两个全局事务tx1和tx2,分别对a表的m字段进行更新操作,m的初始值1000。
2. tx1先开始,开启本地事务,拿到本地锁,更新操作m=1000-100=900。本地事务提交前,先拿到该记录的全局锁,本地提交释放本地锁。
3. tx2后开始,开启本地事务,拿到本地锁,更新操作m=900-100=800。本地事务提交前,尝试拿该记录的全局锁 ,tx1全局提交前,该记录的全局锁被 tx1持有,tx2需要重试等待全局锁 。
4. tx1二阶段全局提交,释放全局锁 。tx2拿到全局锁提交本地事务。
5. 如果tx1的二阶段全局回滚,则tx1需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。此时,如果tx2仍在等待该数据的全局锁,同时持有本地锁,则tx1的分支回滚会失败。分支的回滚会一直重试,直到 tx2的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,tx1的分支回滚最终成功。
#### 7.1.19.2 本例的系统架构原理图
本例的系统架构原理图如下:(实际未加Sentinel)

## 7.2 SpringBoot
### 7.2.1 加速依赖包的导入
在`apache-maven-3.5.2\conf\settings.xml`中配置使用阿里云服务器加速导入依赖包的速度:
```xml
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
<profiles>
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
</profiles>
参考博客文章:解决阿里镜像无法下载jar包的问题
启动类使用注解:@SpringBootApplication=@SpringBootConfiguration(标注当前类是配置类)+@EnableAutoConfiguration(启用自动配置功能)+@ComponentScan(组件扫描)
- 默认扫描的包:启动类所在包及其下面的所有子包。
- 手动配置扫描的包:
- 方法一:@SpringBootApplication(scanBasePackages="包名")
- 方法二:在启动类上使用@ComponentScan("包名")
SpringBoot的自动配置:在spring-boot-autoconfigure包。
控制器使用注解:@RestController=@Controller+@ResponseBody
配置类:@Configuration,配置类本身也是组件。
@Configuration(proxyBeanMethods = false):proxyBeanMethods默认为true(Full模式,全配置:这种模式可以解决组件依赖的问题),表示通过配置类实例调用方法获取返回对象时,保持返回对象的单实例(若容器中存在该对象的实例,直接返回即可);proxyBeanMethods设置为false(Lite模式,轻量级配置),则返回对象是多实例的。- Full模式:每次方法调用会从容器中检查,性能较差,但可以保证对象的单例性;配置类组件之间无依赖关系用Lite模式加速容器启动过程,减少判断。
- Lite模式:每次方法调用不会从容器中检查,性能较好,但是通过方法调用返回的对象是多例的;配置类组件之间有依赖关系,方法会被调用得到之前单实例组件,用Full模式。
配置组件:@Bean、@Component、@Controller、@Service、@Repository
导入组件:@Import({User.class, DBHelper.class})(可以将注解放在配置类上或组件上),自动导入的组件名字为全类名。
条件装配:@Conditional,满足Conditional指定的条件,则进行组件注入。org.springframework.boot.autoconfigure.condition包中有大量的条件装配注解。如:
- @ConditionalOnBean
- @ConditionalOnMissingBean
导入资源:在配置类上添加注解@ImportResource("classpath:beans.xml")可以导入类路径下的beans.xml中的组件。
-
方法一:在容器中的组件,可以利用注解进行配置绑定,
@Component(组件上)+@ConfigurationProperties(prefix = "mycar")(组件上) -
方法二:在配置类上开启指定组件的属性配置功能(一般用于想为第三方包配置),
@Configuration(配置类上)+@EnableConfigurationProperties(Car.class)(配置类上)+@ConfigurationProperties(prefix = "mycar")(组件上)@EnableConfigurationProperties(Car.class)有两个作用:一是开启Car的属性配置;二是将Car自动注册到组件中。
@SpringBootApplication=@SpringBootConfiguration+@ComponentScan+@EnableAutoConfiguration
-
@SpringBootConfiguration:代表当前是一个配置类。
@Configuration public @interface SpringBootConfiguration
-
@ComponentScan:Spring的注解,指定扫描哪些类。
-
@EnableAutoConfiguration:
// 批量导入启动类所在包(未指定包的情况下,默认是启动类所在的包及其子包)下的组件 @AutoConfigurationPackage // 1. 利用getAutoConfigurationEntry(annotationMetadata);给容器中批量导入一些组件 // 2. 调用List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类(127个) // 2.1 利用工厂加载 Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader);得到所有的组件 // 2.2 从META-INF/spring.factories位置来加载一个文件。默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件,spring-boot-autoconfigure-2.3.4.RELEASE.jar包里面也有META-INF/spring.factories @Import(AutoConfigurationImportSelector.class) public @interface EnableAutoConfiguration // 利用Registrar给容器中导入一系列组件,将指定的一个包下的所有组件导入进来?MainApplication所在包下 @Import(AutoConfigurationPackages.Registrar.class) public @interface AutoConfigurationPackage
虽然127个场景的所有自动配置启动的时候(@Import(AutoConfigurationImportSelector.class) 的作用)默认全部加载。xxxxAutoConfiguration,按照条件装配规则(@Conditional),最终会按需配置。
SpringBoot默认会在底层配好所有的组件,但是如果用户自己配置了以用户的优先(通过条件装配)。
SpringBoot的自动配置原理总结:
- SpringBoot先加载所有的自动配置类xxxxxAutoConfiguration。
- 自动配置类按照条件进行生效,默认都会绑定配置文件指定的值,从xxxxProperties里面取;而xxxxProperties又会从application.properties中取。
- 生效的配置类就会给容器中装配很多组件,只要容器中有这些组件,相当于这些功能就有了。
- 定制化配置:
- 方法一:用户直接自己@Bean替换底层的组件。
- 方法二:修改组件的配置文件属性的默认值。
根据自动配置原理,不同场景下的整合遵循以下步骤即可:
- 引入场景依赖:查看SpringBot官网
- 查看该场景下的自动配置:
- 自己分析,引入场景对应的自动配置一般都生效了
- 在application.yaml配置文件中开启自动配置报告(debug=true),Negative matches(未生效)\Positive matches(已生效)
- 是否需要修改自动配置的默认值:
- 参照文档修改默认值:
- 查看SpringBoot官网
- 自己分析xxxxProperties绑定了配置文件的哪些属性
- 自定义加入或者替换组件:@Bean、@Component...
- 参照文档修改默认值:
使用Spring Initailizr开发向导可以加速项目的创建。
SpringBoot支持使用spring-boot-devtools(本质是Restart,并非真正意义上的热更新)进行热更新(查看SpringBoot官网):
- 引入依赖,请查看官网。
- 项目或者页面修改以后,使用
Ctrl+F9。
另一种进行热重启的方法是使用springload。
使用JRebel可以实现真正意义上的热更新(本质是Reload),但该软件是付费的, JRebel的安装和使用请查看JRebel插件使用详解。安装完JRebel并启用之后,当修改完java代码,可以通过Ctrl+shift+F9进行热更新(不需要重启,直接进行重载可以节省大量时间)。
推荐使用JRebel进行热更新。
YAML(YAML Ain't Markup Language)用法如下:.yml格式不支持@PropertySource注解导入配置
- key: value(kv之间有空格)
- 大小写敏感
- 使用缩进表示层级关系
- 缩进不允许使用tab,只允许空格(IDEA对此进行了优化)
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- '#'表示注释
- 字符串无需加引号,如果要加,''与""表示字符串内容会被转义(单引号会将\n作为字符输出)/不转义(双引号会将\n作为换行输出)
自定义类配置的属性绑定的提示功能:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<!--spring-boot-configuration-processor与业务功能无关,只是开发时提供便利,故需要排除掉-->
<exclude>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>只要静态资源放在类路径下:/static(或/public或/resources或/META-INF/resources),则访问访问为:当前项目根路径/ + 静态资源名。
原理: 静态映射/**;请求进来,先去找Controller看能不能处理。不能处理的所有请求又都交给静态资源处理器(ResourceHttpRequestHandler);静态资源也找不到则响应404页面。
改变默认的静态资源目录:
spring.web.resources.static-locations=[classpath:/aaa/,classpath:/bbb/]配置之后,只有类路径下的aaa目录和bbb目录下存放的静态资源可以被直接访问到。
静态资源访问默认无前缀,直接为/**,可以配置静态资源访问前缀:
spring.mvc.static-path-pattern=/resources/**配置静态资源访问前缀之后,则访问静态资源的路径为:当前项目+static-path-pattern+静态资源名=静态资源文件夹/static(或/public或/resources或/META-INF/resources)下找。
访问jar包里的静态资源:会自动映射为/webjars/**
<!--例如:引入jquery包-->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>jquery</artifactId>
<version>3.5.1</version>
</dependency>访问jquery包下的静态资源路径为:http://localhost:8080/webjars/jquery/3.5.1/jquery.js,后面的地址(jquery/3.5.1/jquery.js)要按照依赖里面的包路径来填写。
访问项目的根路径,会默认访问欢迎页,欢迎页有两种形式:
- 存放在静态资源目录下的index.html(Bug:若配置了静态资源访问前缀,则会导致welcome page失效)。
- Controller能处理/index(这种方法需要请求路径中包含/index)。
将favicon.ico放在静态资源目录下即可(Bug:若配置了静态资源访问前缀,则会导致网站小图标失效)。
若禁用了浏览器缓存,会导致网站小图标不显示。
关于静态资源的配置管理,需要注意以下几点:
-
SpringBoot启动默认加载xxxAutoConfiguration类(自动配置类)
-
SpringMVC功能的自动配置类WebMvcAutoConfiguration,默认生效。

-
WebMvcAutoConfiguration自动配置类中加载了spring.mvc(对应WebMvcProperties类)、spring.resources(对应ResourceProperties类)、spring.web(对应WebProperties类)的属性配置。
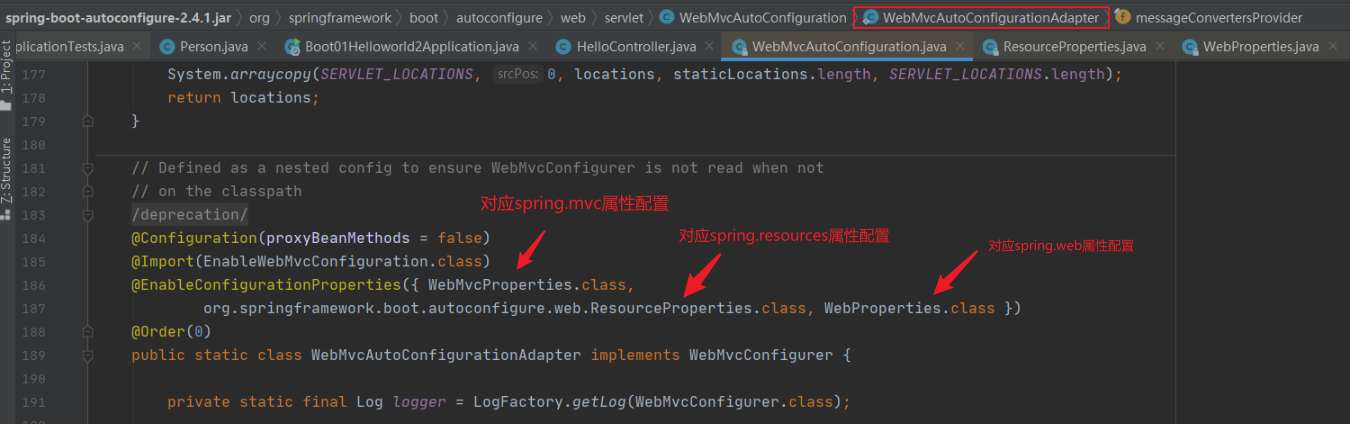
-
可以配置禁用所有的静态资源、配置静态资源的缓存时间。
# 禁用所有静态资源(默认为true,表示不禁用) spring.resources.add-mappings: false # 配置静态资源的缓存时间(以秒为单位),配置之后会在第一次访问静态资源后,将其缓存在浏览器中 spring.resources.cache.period: 11000 # 访问/webjars/**的请求,等价于访问"classpath:/META-INF/resources/webjars/"jar包下类路径中的静态资源 # addResourceLocations(getResourceLocations(this.resourceProperties.getStaticLocations()))方法即配置了默认的静态资源访问路径
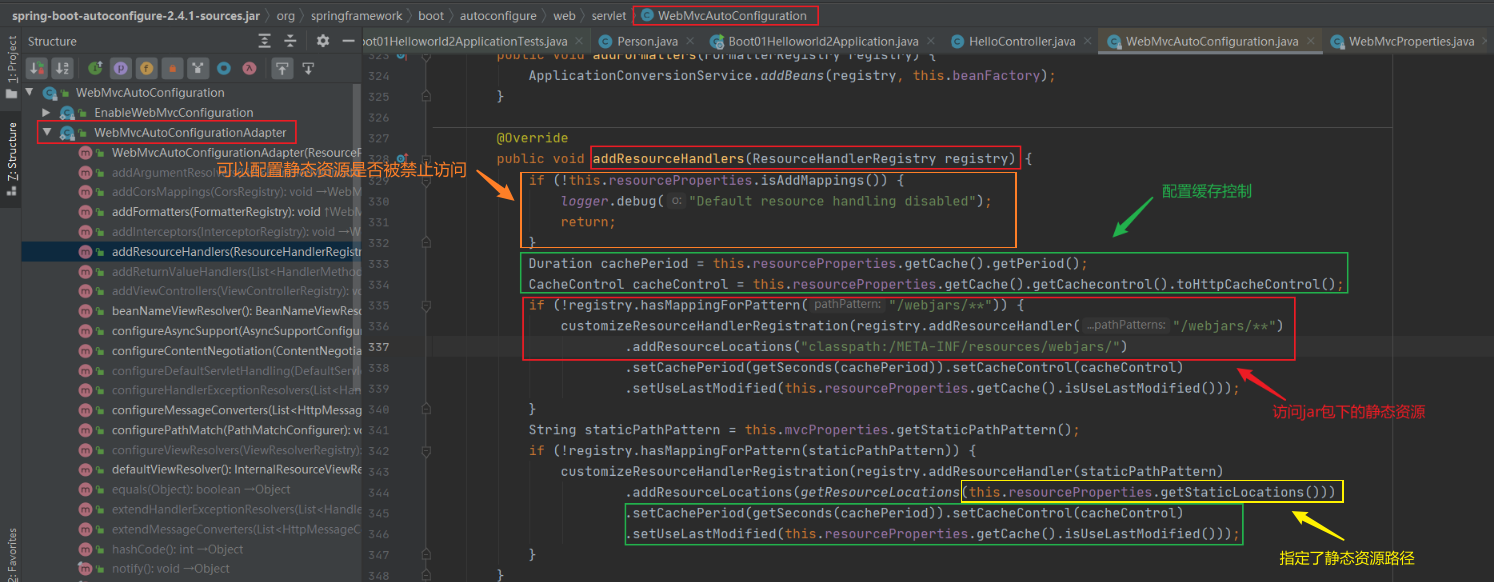
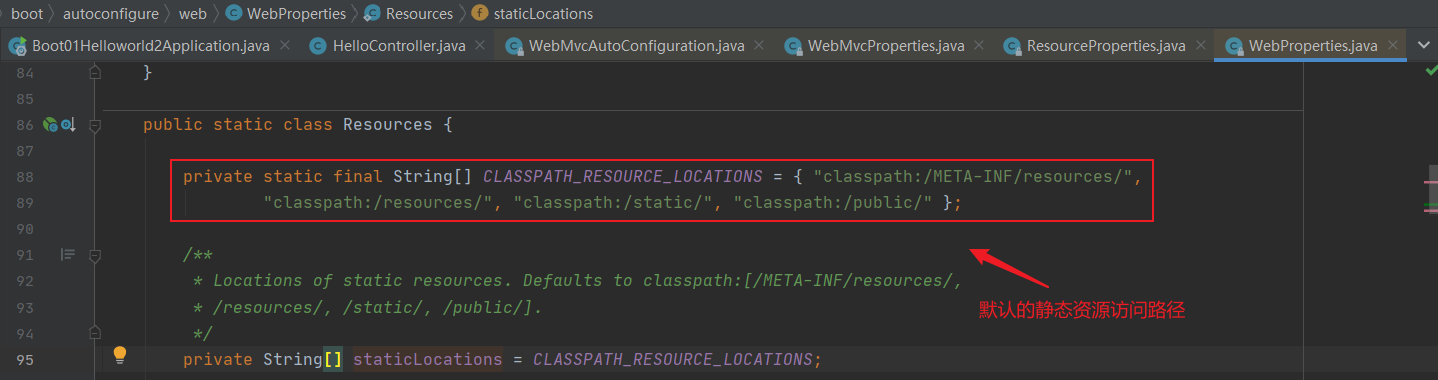
-
欢迎页的访问:在WebMvcAutoConfiguration.EnableWebMvcConfiguration#welcomePageHandlerMapping方法会返回WelcomePageHandlerMapping对象,WelcomePageHandlerMapping对象中配置了欢迎页的访问路径。
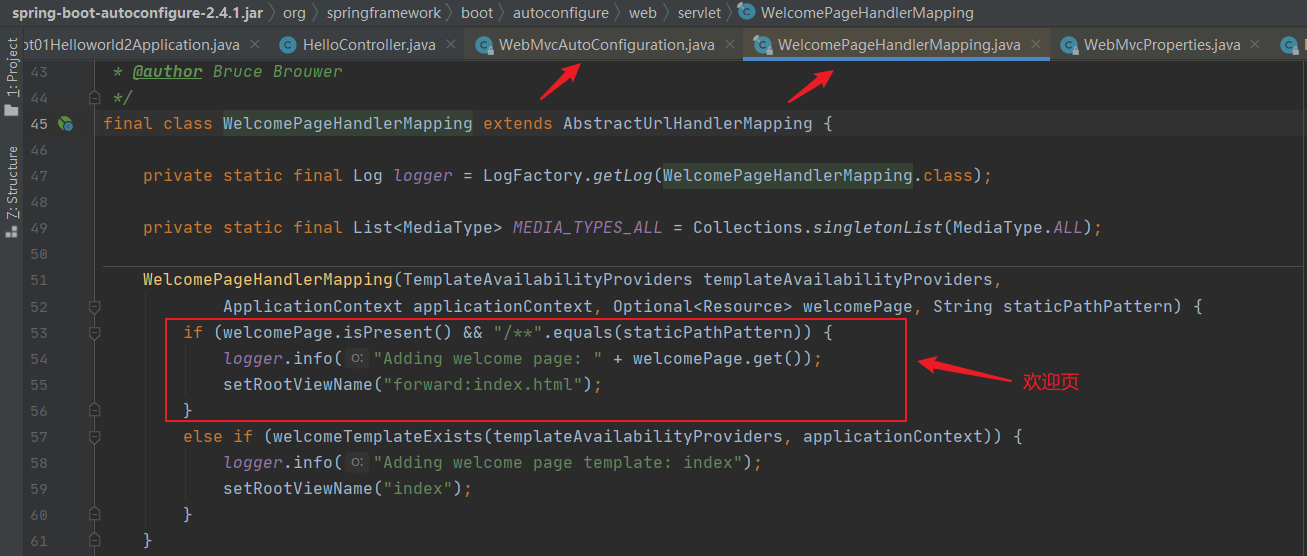





请求映射:满足以下两个条件
- @xxxMapping注解:@GetMapping、@PostMapping、@PutMapping、@DeleteMapping
- Rest风格支持(使用HTTP请求方式动词来表示对资源的操作)
- 以前:/getUser获取用户、/deleteUser删除用户、/editUser修改用户、/saveUser保存用户
- 现在:/user GET请求获取用户、DELETE请求删除用户、PUT请求修改用户、POST请求保存用户
Rest原理(表单提交要使用REST的时候):如使用PostMan直接发送Put、delete等方式请求,无需Filter。
-
表单提交会带上_method=PUT
-
请求过来被HiddenHttpMethodFilter拦截(需配置开启HiddenHttpMethodFilter)
-
- 请求是否正常,并且是POST
-
-
- 获取到_method的值。
- 兼容以下请求:PUT/DELETE/PATCH
- 原生request(post),采用装饰模式requesWrapper重写了getMethod方法,返回的是传入的值。
- 过滤器链放行的时候用wrapper,以后的方法调用getMethod是调用**requesWrapper的。
-
表单使用POST方式提交DELETE/PUT请求:
-
第一步:表单method=post,隐藏域 _method=put
<form action="/user" method="post"> <input name="_method" type="hidden" value="DELETE"/> <input value="REST-DELETE提交" type="submit"/> </form> <form action="/user" method="post"> <input name="_method" type="hidden" value="put"/> <input value="REST-PUT提交" type="submit"/> </form>
-
第二步:配置HiddenMethodFilter
# 开启页面表单的REST功能 spring.mvc.hiddenmethod.filter.enabled=true
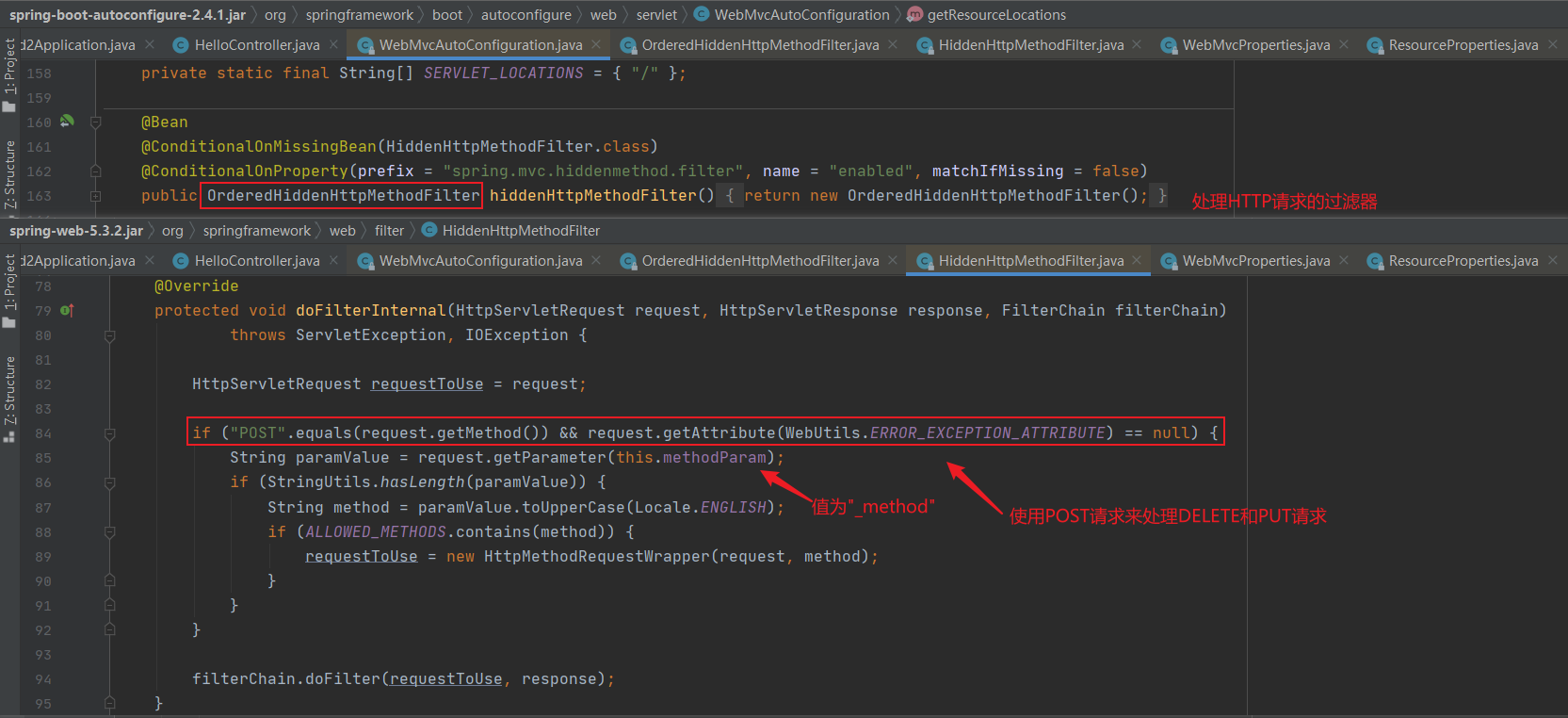

请求映射原理如下:

-
SpringMVC功能分析都从
org.springframework.web.servlet.DispatcherServlet的doDispatch方法开始。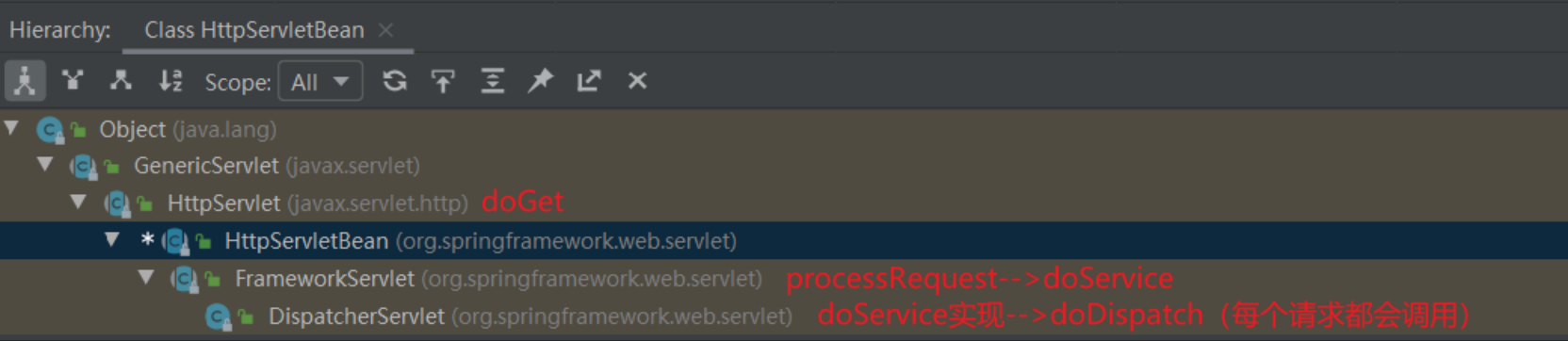
-
DispatcherServlet的doDispatch方法中通过调用HandlerMapping(包含多种HandlerMapping)获得HandlerExecutionChain对象(HandlerExecutionChain对象中包含了HandlerInterceptor和handler,其中的handler包含了Controller.method()的信息)。
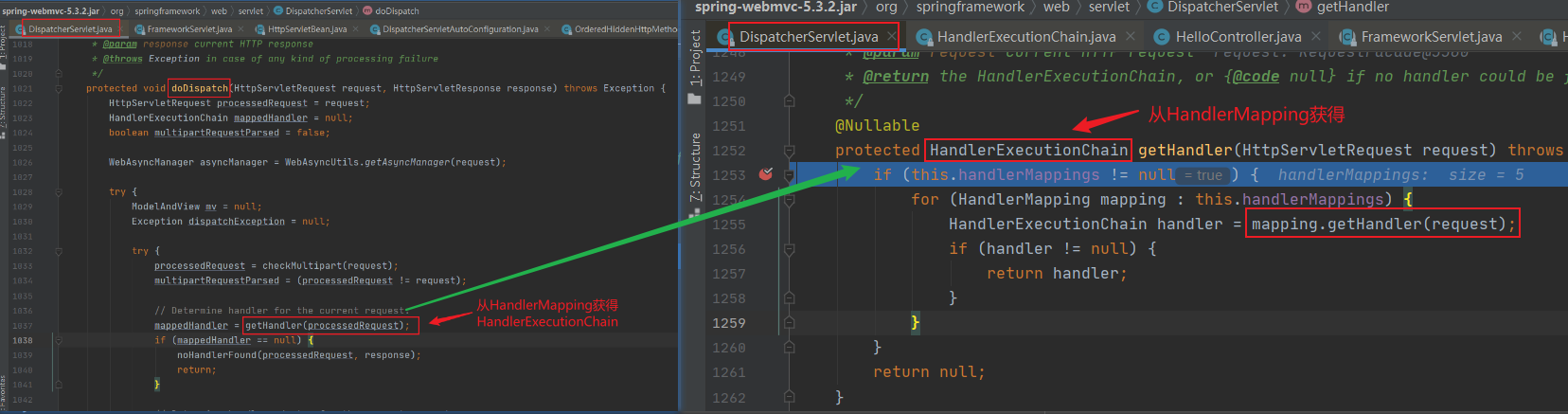
所有的请求映射都在HandlerMapping中,HandlerMapping具体又包括:
- 配置欢迎页的WelcomePageHandlerMapping,访问 /能访问到index.html
- 配置了默认的RequestMappingHandlerMapping,保存了所有@RequestMapping和handler的映射规则,Controller中的所有映射都会保存在此
- 请求进来,挨个尝试所有的HandlerMapping看是否有请求信息:
- 如果有就找到这个请求对应的HandlerMapping,并通过该HandlerMapping返回HandlerExecutionChain对象
- 如果没有就在下一个HandlerMapping里寻找
- 可以自定义HandlerMapping来进行映射处理
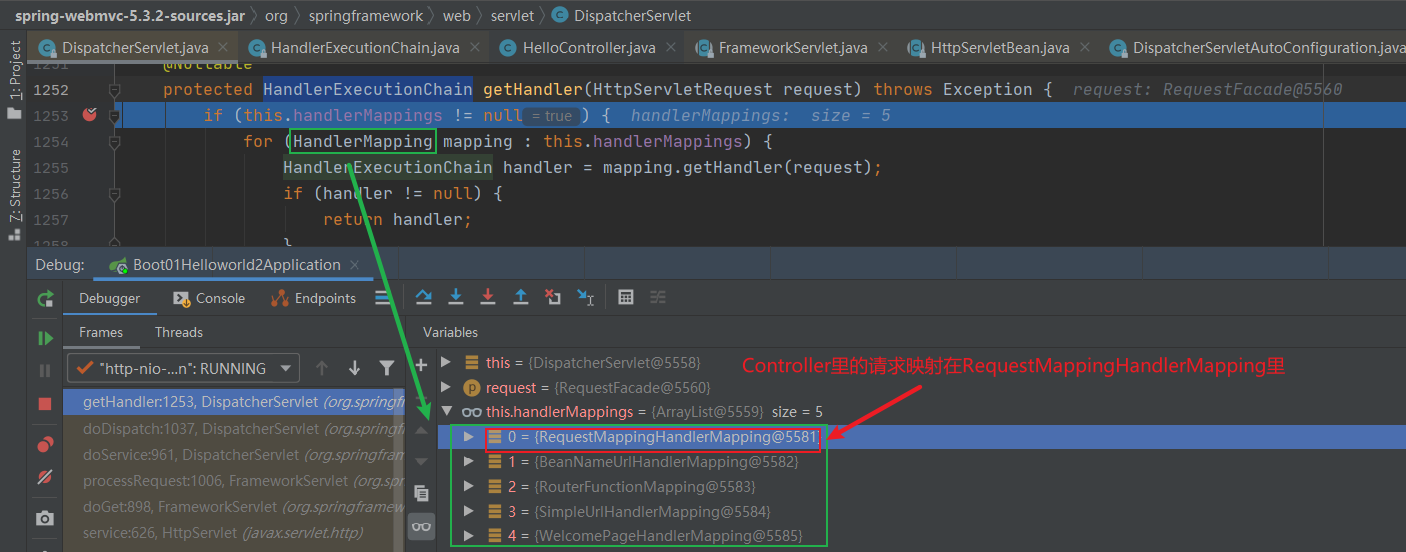
-
为当前handler找一个适配器HandlerAdapter(一般就是找RequestMappingHandlerAdapter),由适配器执行目标方法并确定方法参数的每一个值。
// Actually invoke the handler. // DispatcherServlet的doDispatch方法中执行 mv = ha.handle(processedRequest, response, mappedHandler.getHandler()); // RequestMappingHandlerAdapter的handleInternal方法中执行目标方法 // 执行前先使用参数解析器进行解析 mav = invokeHandlerMethod(request, response, handlerMethod);
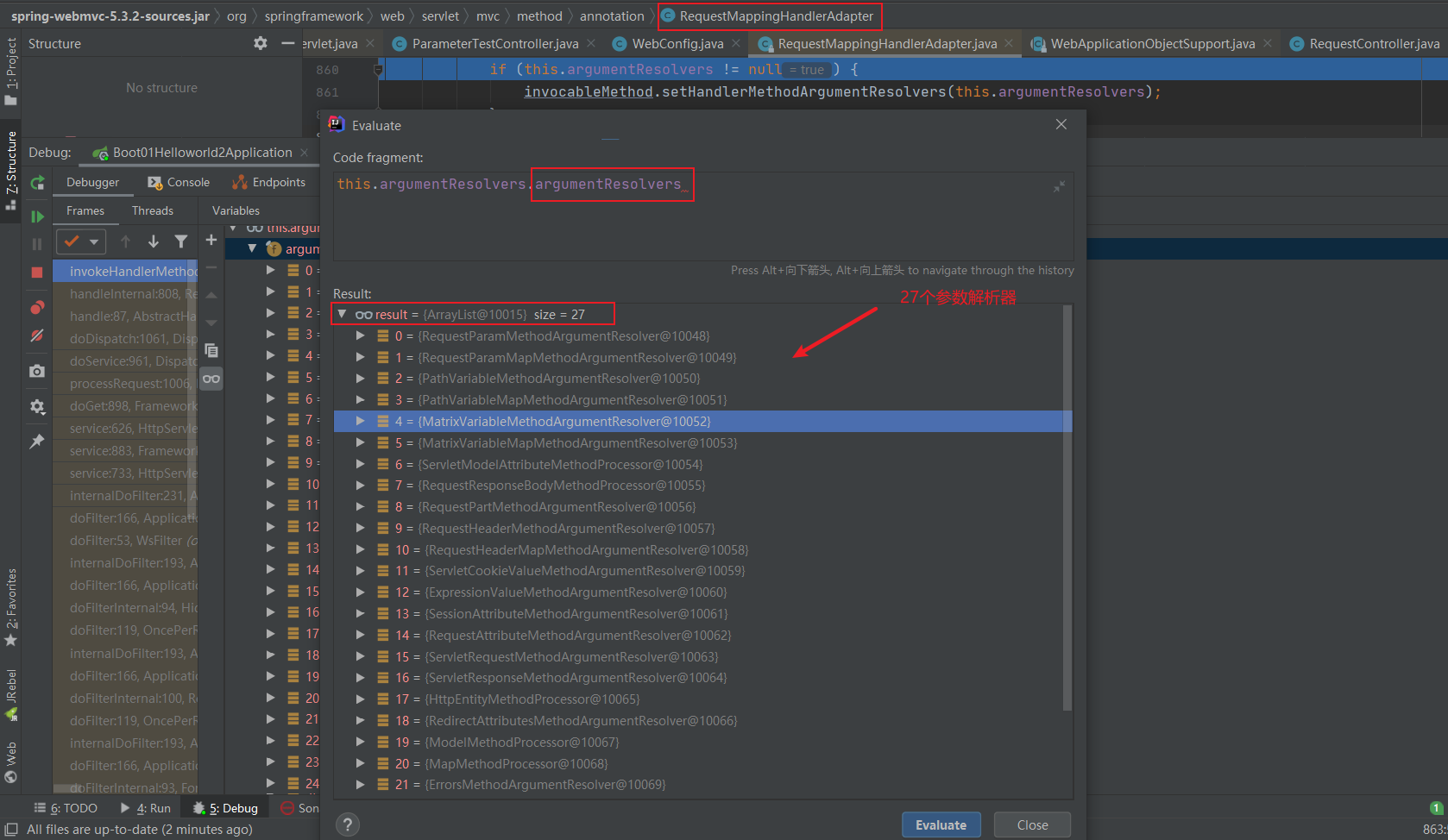
-
HandlerMethodArgumentResolver是一个接口,有两个方法:当前解析器是否支持解析这种参数;支持就进行调用解析。HandlerMethodArgumentResolver有27个实现子类,对应27个参数解析器。
// InvocableHandlerMethod的getMethodArgumentValues方法为获取具体参数值的过程 -
HandlerMethodReturnValueHandler也是一个接口,拥有15个实现子类,对应15个返回值处理器。
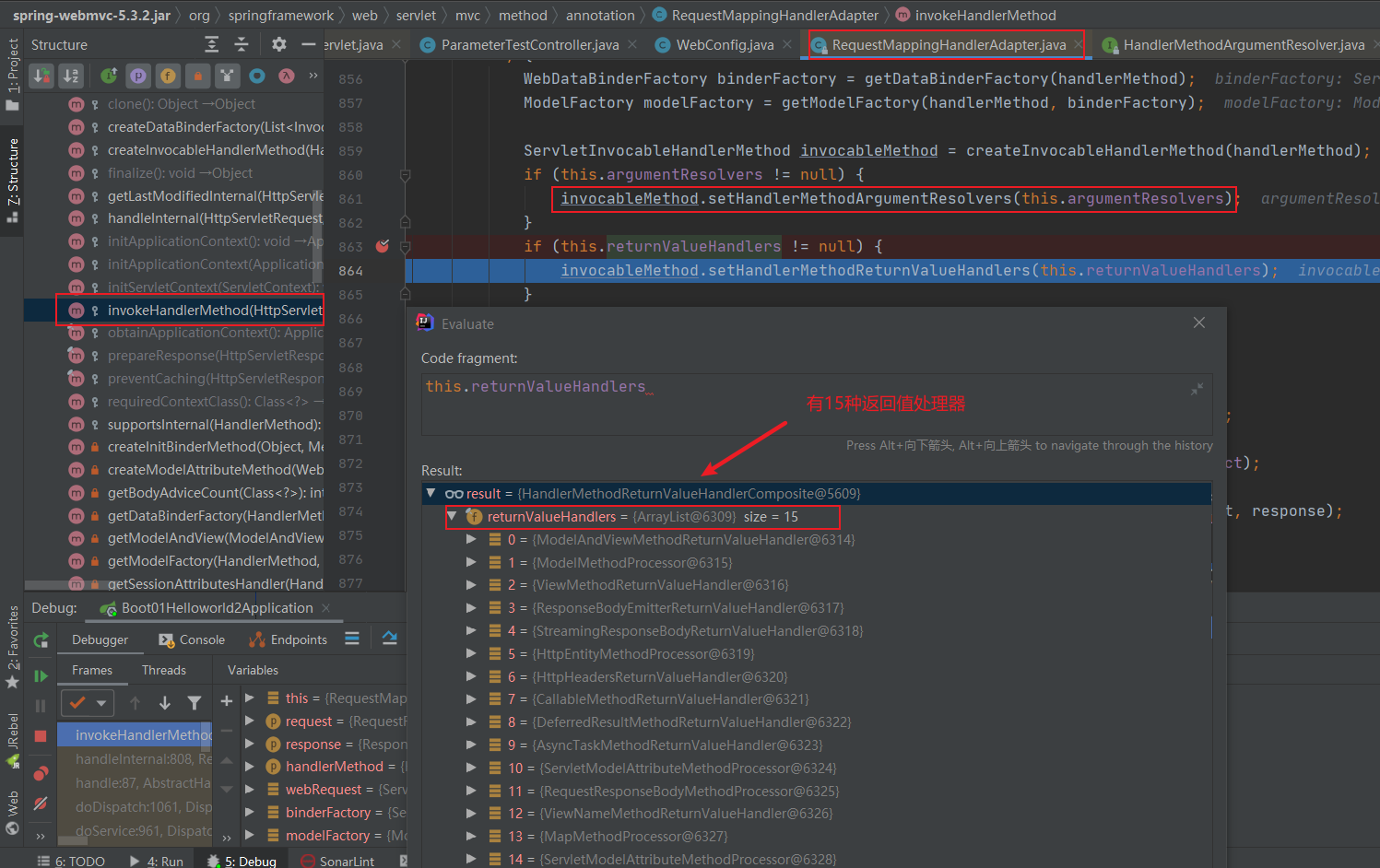





请求参数传递的几种方式:
-
基本注解:@RequestBody、@RequestParam、@PathVariable、@RequestHeader、@CookieValue、@RequestAttribute、@MatrixVariable、@ModelAttribute、@RequestPart
// @RequestBody、@RequestParam、@PathVariable、@RequestHeader、@CookieValue的使用测试 @RestController public class ParameterTestController { // car/2/owner/zhangsan?age=18&inters=basketball&&inters=game @GetMapping("/car/{id}/owner/{username}") public Map<String,Object> getCar( @PathVariable("id") Integer id, // 获取请求路径中的id值 @PathVariable("username") String name, // 获取请求路径中的username值 @PathVariable Map<String,String> pv, // 获取请求路径中的所有参数及值 @RequestHeader("User-Agent") String userAgent, // 获取所有的请求头中User-Agent的信息 @RequestHeader Map<String,String> header, // 获取所有的请求头信息 @RequestParam("age") Integer age, // 获得单个参数的值 @RequestParam("inters") List<String> inters, // 获得数组 @RequestParam Map<String,String> params, // 把所有请求参数封装到Map中 @CookieValue("token") String _ga, // 获取Cookie中_ga的值 @CookieValue("token") Cookie cookie) // 获取_ga的Cookie { Map<String,Object> map = new HashMap<>(); map.put("id",id); map.put("name",name); map.put("pv",pv); map.put("userAgent",userAgent); map.put("headers",header); map.put("age",age); map.put("inters",inters); map.put("params",params); map.put("token",_ga); System.out.println(cookie.getName()+"===>"+cookie.getValue()); System.out.println(map); return map; } @PostMapping("/save") public Map postMethod(@RequestBody String content){ Map<String,Object> map = new HashMap<>(); map.put("content",content); return map; } } //------------------------------------------我是分割线------------------------------------------------------------------- // @MatrixVariable的使用测试,SpringBoot默认是禁用了矩阵变量的功能,因此使用前需要先进行配置 @Configuration(proxyBeanMethods = false) public class WebConfig implements WebMvcConfigurer { @Bean public HiddenHttpMethodFilter hiddenHttpMethodFilter(){ HiddenHttpMethodFilter methodFilter = new HiddenHttpMethodFilter(); methodFilter.setMethodParam("_m"); return methodFilter; } // 方法一 @Bean public WebMvcConfigurer webMvcConfigurer(){ return new WebMvcConfigurer() { @Override public void configurePathMatch(PathMatchConfigurer configurer) { UrlPathHelper urlPathHelper= new UrlPathHelper(); // 不移除;后面的内容,矩阵变量功能就可以生效 urlPathHelper.setRemoveSemicolonContent(false); configurer.setUrlPathHelper(urlPathHelper); } }; } // 方法二 // @Override // public void configurePathMatch(PathMatchConfigurer configurer){ // UrlPathHelper urlPathHelper= new UrlPathHelper(); // // 不移除;后面的内容,矩阵变量功能就可以生效 // urlPathHelper.setRemoveSemicolonContent(false); // configurer.setUrlPathHelper(urlPathHelper); // // } } @RestController public class ParameterTestController { //1、语法: 请求路径:/cars/sell;low=34;brand=byd,audi,yd //2、SpringBoot默认是禁用了矩阵变量的功能 // 手动开启:原理。对于路径的处理,使用UrlPathHelper进行解析。 // removeSemicolonContent(移除分号内容)支持矩阵变量的 //3、矩阵变量必须有url路径变量才能被解析 /** * 一个面试题:页面开发,cookie被禁用了,Session里面的内容怎么使用? * 正常情况下:session.set(a,b)--->jsessionid--->cookie--->每次发请求携带 * 解决方法:url重写:/abc;jsessionid=xxxx,把cookie的值使用矩阵变量的方式进行传递 */ @GetMapping("/cars/{path}") public Map carsSell(@MatrixVariable("low") Integer low, @MatrixVariable("brand") List<String> brand, @PathVariable("path") String path){ Map<String,Object> map = new HashMap<>(); map.put("low",low); map.put("brand",brand); map.put("path",path); return map; } // /boss/1;age=20/2;age=10 @GetMapping("/boss/{bossId}/{empId}") public Map boss(@MatrixVariable(value = "age",pathVar = "bossId") Integer bossAge, @MatrixVariable(value = "age",pathVar = "empId") Integer empAge){ Map<String,Object> map = new HashMap<>(); map.put("bossAge",bossAge); map.put("empAge",empAge); return map; } } //------------------------------------------我是分割线------------------------------------------------------------------- // 测试请求转发以及@RequestAttribute的使用 @Controller public class RequestController { @GetMapping("/goto") public String goToPage(HttpServletRequest request){ request.setAttribute("msg", "成功了"); request.setAttribute("code", 200); // 转发到/success请求 return "forward:/success"; } @ResponseBody @GetMapping("/success") public Map success(@RequestAttribute("msg") String msg, @RequestAttribute("code") Integer code, HttpServletRequest request){ Object msg1 = request.getAttribute("msg"); Object code1 = request.getAttribute("code"); Map<String, Object> map = new HashMap<>(); map.put("reqMethod_msg", msg1); map.put("reqMethod_code", code1); map.put("annotation_msg",msg); return map; } }
-
Servlet API:WebRequest、ServletRequest、MultipartRequest、 HttpSession、javax.servlet.http.PushBuilder、Principal、InputStream、Reader、HttpMethod、Locale、TimeZone、ZoneId
ServletRequestMethodArgumentResolver支持以上参数的解析。
@Override public boolean supportsParameter(MethodParameter parameter) { Class<?> paramType = parameter.getParameterType(); return (WebRequest.class.isAssignableFrom(paramType) || ServletRequest.class.isAssignableFrom(paramType) || MultipartRequest.class.isAssignableFrom(paramType) || HttpSession.class.isAssignableFrom(paramType) || (pushBuilder != null && pushBuilder.isAssignableFrom(paramType)) || Principal.class.isAssignableFrom(paramType) || InputStream.class.isAssignableFrom(paramType) || Reader.class.isAssignableFrom(paramType) || HttpMethod.class == paramType || Locale.class == paramType || TimeZone.class == paramType || ZoneId.class == paramType); }
-
复杂参数:Map、Model(map、model里面的数据会被放在request的请求域request.setAttribute)、Errors/BindingResult、RedirectAttributes(重定向携带数据)、ServletResponse(response)、SessionStatus、UriComponentsBuilder、ServletUriComponentsBuilder
-
自定义对象参数:可以自动类型转换与格式化,可以级联封装。
- WebDataBinder binder = binderFactory.createBinder(webRequest, attribute, name)
- WebDataBinder:web数据绑定器,将请求参数的值绑定到指定的JavaBean里面
- WebDataBinder利用它里面的Converters将请求数据转成指定的数据类型。再次封装到JavaBean中
- GenericConversionService:在设置每一个值的时候,找它里面的所有converter那个可以将这个数据类型
-
响应json
使用jackson.jar+@ResponseBody。
<!--spring-boot-starter-web里已经引入了spring-boot-starter-json,底层采用jackson--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-json</artifactId> <version>2.4.1</version> <scope>compile</scope> </dependency>
原理:
-
返回值处理器判断是否支持这种类型返回值supportsReturnType
-
返回值处理器调用handleReturnValue进行处理
-
RequestResponseBodyMethodProcessor可以处理返回值标了@ResponseBody注解的。
-
- 利用MessageConverters进行处理将数据写为json
-
-
- 内容协商(浏览器默认会以请求头的方式告诉服务器他能接受什么样的内容类型)
- 服务器最终根据自己自身的能力,决定服务器能生产出什么样内容类型的数据,
- SpringMVC会挨个遍历所有容器底层的HttpMessageConverter,看谁能处理?
-
-
-
-
- 1、得到MappingJackson2HttpMessageConverter可以将对象写为json
- 2、利用MappingJackson2HttpMessageConverter将对象转为json再写出去
-
-
SpringMVC支持的返回值类型:ModelAndView、Model、View、ResponseEntity 、ResponseBodyEmitter、StreamingResponseBody、HttpEntity、HttpHeaders、Callable、DeferredResult、ListenableFuture、CompletionStage、WebAsyncTask
-
-
内容协商
根据客户端接收能力不同,返回不同媒体类型的数据:
<!--引入依赖支持内容协商,这个依赖支持响应输出XML和json数据类型--> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> </dependency> <!--导入了jackson处理xml的包,xml的converter就会自动进,原理如下--> // WebMvcConfigurationSupport类中 jackson2XmlPresent = ClassUtils.isPresent("com.fasterxml.jackson.dataformat.xml.XmlMapper", classLoader); if (jackson2XmlPresent) { Jackson2ObjectMapperBuilder builder = Jackson2ObjectMapperBuilder.xml(); if (this.applicationContext != null) { builder.applicationContext(this.applicationContext); } messageConverters.add(new MappingJackson2XmlHttpMessageConverter(builder.build())); }
-
默认通过获取客户端(PostMan、浏览器)Accept请求头字段(如:application/xml)来决定输出什么媒体类型的数据。
-
为了方便内容协商,也可以开启基于请求参数的内容协商功能:基于参数的内容协商优先级高于基于请求头字段的内容协商。
# 开启请求参数内容协商模式 spring.mvc.contentnegotiation.favor-parameter=true
- 请求响应json格式数据:http://localhost:8080/test/person?format=json
- 请求响应xml格式数据:http://localhost:8080/test/person?format=xml
-
自定义消息响应格式(以请求头的方式):给容器种添加WebMvcConfigurer Bean,并重写extendMessageConverters方法(需要自定义HttpMessageConverter)
-
自定义消息响应格式(以参数的方式):给容器种添加WebMvcConfigurer Bean,并重写configureContentNegotiation方法(需要先自定义请求头方式的消息响应)
-

常用的模板引擎:thymeleaf、freemaker、velocity
thymeleaf:现代化、服务端Java模板引擎
-
表达式语法
表达式名字 语法 用途 变量取值 ${...} 获取请求域、session域、对象等值 选择变量 *{...} 获取上下文对象值 消息 #{...} 获取国际化等值 链接 @{...} 生成链接 片段表达式 ~{...} jsp:include 作用,引入公共页面片段 -
字面量
- 文本值:'one text' , 'Another one!' ,…
- 数字:0 , 34 , 3.0 , 12.3 ,…
- 布尔值:true , false
- 空值:null
- 变量:one,two,.... 变量不能有空格
-
文本操作
- 字符串拼接: +
- 变量替换: |The name is ${name}|
-
数学运算
- 运算符:+ , - , * , / , %
-
布尔运算
- 运算符:and , or
- 一元运算:! , not
-
比较运算
- 比较:> , < , >= , <= ( gt , lt , ge , le )
- 等式:== , != ( eq , ne )
-
条件运算
- If-then:(if) ? (then)
- If-then-else:(if) ? (then) : (else)
- Default::(value) ?: (defaultvalue)
-
特殊操作
- 无操作:_
-
设置属性值-th:attr
<!--设置单个值--> <form action="subscribe.html" th:attr="action=@{/subscribe}"> <fieldset> <input type="text" name="email" /> <input type="submit" value="Subscribe!" th:attr="value=#{subscribe.submit}"/> </fieldset> </form> <!--设置多个值--> <img src="../../images/gtvglogo.png" th:attr="src=@{/images/gtvglogo.png},title=#{logo},alt=#{logo}" /> <!--替代写法--> <input type="submit" value="Subscribe!" th:value="#{subscribe.submit}"/> <form action="subscribe.html" th:action="@{/subscribe}">
-
迭代
<tr th:each="prod : ${prods}"> <td th:text="${prod.name}">Onions</td> <td th:text="${prod.price}">2.41</td> <td th:text="${prod.inStock}? #{true} : #{false}">yes</td> </tr> <tr th:each="prod,iterStat : ${prods}" th:class="${iterStat.odd}? 'odd'"> <td th:text="${prod.name}">Onions</td> <td th:text="${prod.price}">2.41</td> <td th:text="${prod.inStock}? #{true} : #{false}">yes</td> </tr>
-
条件运算
<a href="comments.html" th:href="@{/product/comments(prodId=${prod.id})}" th:if="${not #lists.isEmpty(prod.comments)}">view</a> <div th:switch="${user.role}"> <p th:case="'admin'">User is an administrator</p> <p th:case="#{roles.manager}">User is a manager</p> <p th:case="*">User is some other thing</p> </div>
引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>自动配置:
-
thymeleaf的配置值都在ThymeleafProperties
public static final String DEFAULT_PREFIX = "classpath:/templates/"; // 放置位置 public static final String DEFAULT_SUFFIX = ".html"; // 文件命名
-
配置好了模板引擎SpringTemplateEngine
-
配置了试图解析器ThymeleafViewResolver
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties(ThymeleafProperties.class)
@ConditionalOnClass({ TemplateMode.class, SpringTemplateEngine.class })
@AutoConfigureAfter({ WebMvcAutoConfiguration.class, WebFluxAutoConfiguration.class })
public class ThymeleafAutoConfiguration { }-
目标方法处理的过程中,所有数据都会被放在ModelAndViewContainer 里面(包括数据和视图地址)
-
方法的参数是一个自定义类型对象(从请求参数中确定的),把他重新放在ModelAndViewContainer
-
任何目标方法执行完成以后都会返回 ModelAndView(数据和视图地址)
-
processDispatchResult 处理派发结果(页面改如何响应)
- render(mv, request, response); 进行页面渲染逻辑
- 根据方法的String返回值得到View对象(定义了页面的渲染逻辑)
- 所有的视图解析器尝试是否能根据当前返回值得到View对象
- 得到了redirect:/main.html-->Thymeleaf new RedirectView()
- ContentNegotiationViewResolver 里面包含了下面所有的视图解析器,内部还是利用下面所有视图解析器得到视图对象
- view.render(mv.getModelInternal(), request, response); 视图对象调用自定义的render进行页面渲染工作
- RedirectView 如何渲染(重定向到一个页面)
- 获取目标url地址
- response.sendRedirect(encodedURL)
- RedirectView 如何渲染(重定向到一个页面)
-
视图解析的过程:
- 返回值以forward:开始:new InternalResourceView(forwardUrl);转发request.getRequestDispatcher(path).forward(request, response)
- 返回值以redirect:开始:new RedirectView()-->render就是重定向
- 返回值是普通字符串:new ThymeleafView()