How to kill distributed processes
nxphi47 opened this issue · 9 comments
Hi, I am running on one 8-GPU machine in nvidia docker with pytorch 1.0, cuda 10.
I follow the script as here to run the program.
However, the distributed processes do not terminate after I Ctrl+C. Some of the process still running on background and killing does not terminate it either. Please help.
Hence, how to properly terminate a ongoing process with distributed running?
Thank you,
Did you use python -m torch.distributed.launch or python train.py? I've noticed the latter approach is a bit more reliable at killing the children processes with Ctrl+C, since it uses multiprocessing and will propagate the KeyboardInterrupt to the children.
But in general when I spot zombie processes, you can usually kill them with kill <process_id> or kill -9 <process_id>.
Thanks for the response.
When I try python train.py, the program using python -m torch.distributed.launch --nproc_per_node 2 train.py ${DATA_DIR} --ddp-backend=no_c10d will be faster.
So I try the this distributed.launch command and I cannot complete kill all child processes. It does seem to kill the master process but not the child. using kill -9 <id> does not work either.
Thanks
Btw, I think the note about torch.distributed.launch being faster is no longer true, I’ll remove it. However, it remains true that in some cases --ddp-backend=no_c10d is faster (this is likely the case in your setting).
I use this script to kill zombie processes.
kill $(ps aux | grep "train.py" | grep -v grep | awk '{print $2}')
Did you use
python -m torch.distributed.launchorpython train.py? I've noticed the latter approach is a bit more reliable at killing the children processes with Ctrl+C, since it uses multiprocessing and will propagate the KeyboardInterrupt to the children.But in general when I spot zombie processes, you can usually kill them with
kill <process_id>orkill -9 <process_id>.
kill -9 does work for me!
I use this script to kill zombie processes.
kill $(ps aux | grep "train.py" | grep -v grep | awk '{print $2}')
Run the following command if you use python train.py, i.e. spawn processes from the main function:
kill $(ps aux | grep multiprocessing.spawn | grep -v grep | awk '{print $2}')
I use this script to kill zombie processes.
kill $(ps aux | grep "train.py" | grep -v grep | awk '{print $2}')Run the following command if you use
python train.py, i.e. spawn processes from the main function:
kill $(ps aux | grep multiprocessing.spawn | grep -v grep | awk '{print $2}')
Hello. Is there any better way to kill these children processes in the training code?
We do NOT want to kill these processes manually. Also, if there are two training tasks for one user, we have to figure out one task before killing it.
I found that you can catch the interrupt and clean all processes:
import os
import torch.distributed as dist
import torch.multiprocessing as mp
try:
mp.spawn(run, args=args, nprocs=world_size, join=True)
except KeyboardInterrupt:
print('Interrupted')
try:
dist.destroy_process_group()
except KeyboardInterrupt:
os.system("kill $(ps aux | grep multiprocessing.spawn | grep -v grep | awk '{print $2}') ")
Let me know whether it works. It works for me. One click ctrl-c trigger destroy, and second click ctrl-c if you don't want to wait pid.
Does anyone know which terminal command can be used to kill all running 8 GPUs . where I am using distributed processes by running cmd ```
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8
$(which fairseq-train) )
nvidia-smi
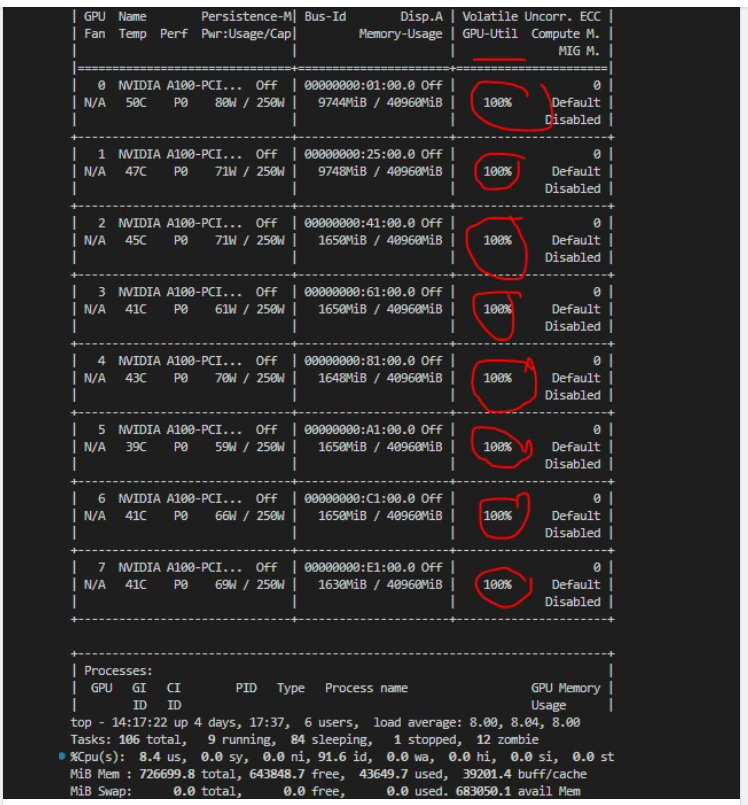
I solved it by typing cmd `top` and this will list all running GPUs
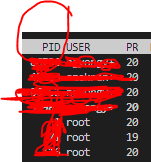
and kill them via PID
`kill -9 PID `