16.JavaScript是如何工作的:存储引擎+如何选择合适的存储API
husky-dot opened this issue · 0 comments
概述
在设计 Web 应用程序时,为本地浏览器选择合适的存储机制至关重要, 一个好的存储引擎可以确保可靠地保存信息,减少带宽,提高响应能力。正确的存储缓存策略是实现离线移动 Web 体验的核心构建块,同时也大大的提高了用户体验。
在本章中,讨论可选择的存储 Api 和服务,并提供一些在构建 Web应用程序,该使用哪种存储引擎。
数据模型
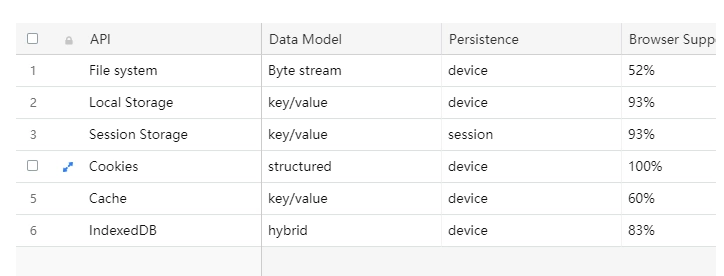
数据存储模型确定数据在内部的组织方式,这会影响 Web 应用程序的整个设计,合理的数据模式会让 Web 应用程序在完成它应有的任务下还能让运行速度更加高效。对于所有与工程相关的问题,没有存在最好的解决方法,也没有适用于所有问题的解决方案,不同场景下有不同的选择。所以,来看看可选择的数据模型:
-
结构化: 存储在具有预定义字段的表中的数据(这是典型的基于 SQL 的数据库管理系统)适行灵活的动态查询。浏览器中结构化数据存储的一个代表的例子是 IndexedDB。
-
Key/Value: 键/值 数据存储和相关的 NoSQL 数据库提供了存储和检索由唯一键索引的非结构化数据的能力。键/值 数据存储类似于哈希表,因为它们允许对索引的不透明数据进行长时间访问。 键/值 数据存储的代表例子是浏览器中的 Cache API 和服务器上的 Apache Cassandra。
Apache Cassandra 是一套开源分布式数据库管理系统,由Facebook开发,用于储存特别大的数据。
- **字节流:**这个简单的模型将数据存储为长度不透明的字节字符串变量,将任何形式的内部组织留给应用层。这个模型特别适合于文件系统和其他分层组织的数据块。字节流数据存储的代表例子包括文件系统和云存储服务。
持久化
web 应用程序的存储方法可以根据数据持久化的时间段进行划分:
-
会话持久化: 该类别中的数据仅在单个 Web 会话或浏览器选项卡保持激活状态时才持久,具有会话持久性的存储机制的一个示例是 Session Storage API。
-
设备的持久化: 此类别中的数据在特定设备上跨会话和浏览器选项卡/窗口持久化,具有设备持久化的存储机制的一个示例是 Cache API。
-
此类中的数据跨会话和设备持久化。因此,它是最健壮的数据持久性形式。但是,它不能存储在设备本身上,这意味需要在某种服务器端存储。在这里不会详细讨论它,因为本文的重点是在设备本身上存储数据。
浏览器中的数据持久化
现在,有相当多的浏览器 Api 用来存储数据。这里将逐一介绍其中的一些及它们的区别,以便后续我们能够容合理的选择使用。
然而,在选择如何持久化数据之前,有几件事需要考虑。当然,有必要知道的的第一件事是你的 Web 应用程序应用场景是什么,以及以后如何迭代和丰富。即使你知道了这些,最终也会有几个选择。所以,以下是需要了解的:
-
浏览器支持 — 标准化和完善的 API 更值得我们选择,因为它们往往寿命更长,支持更广泛, 这些API 还享有更丰富的文档和开发人员社区。
-
事务 — 有时,相关存储操作的集合原子地成功或失败是很重要的。传统上,数据库使用事务模型支持此功能,其中相关更新可以分组到任意单元中。
-
同步/异步 — 有些存储 Api 是同步的,因为存储或检索请求会阻塞当前活动的线程,直到请求完成。使用同步存储 API 会阻塞主线程,并为 Web 应用程序的 UI 创建冻结体验。如果可能,使用异步API。
比较
在本节中,了解决 Web 开发人员的当前可用存储 Api,并从各个维度上进行比较。
文件系统API

通过 FileSystem API, Web 应用就可以创建、读取、导航用户本地文件系统中的沙盒部分以及向其中写入数据。
API 被分为以下不同的主题:
- 读取和处理文件:File/Blob、FileList、FileReader
- 创建和写入:BlobBuilder、FileWriter
- 目录和文件系统访问:DirectoryReader、FileEntry/DirectoryEntry、LocalFileSystem
FileSystem API 是非标准 API。在发布环境因慎重使用,因为并是所有的浏览器都支持,实现方式可能存在很大的不兼容性,并且在将来可能也会发生变化。
请求文件系统
网络应用可通过调用 window.requestFileSystem() 请求对沙盒文件系统的访问权限:
// Note: The file system has been prefixed as of Google Chrome 12:
window.requestFileSystem = window.requestFileSystem || window.webkitRequestFileSystem;
window.requestFileSystem(type, size, successCallback, opt_errorCallback)
**type:**文件存储是否应该是持久的。可能的值包括 window.TEMPORARY 和 window.PERSISTENT。通过 TEMPORARY 存储的数据可由浏览器自行决定删除(例如在需要更多空间的情况下),要清除PERSISTENT 存储,必须获得用户或应用的明确授权,并且需要用户向你的应用授予配额。
**size: ** 应用需要用于存储的大小 (以字节为单位)。
**successCallback:**文件系统请求成功时调用的回调,其参数为 FileSystem 对象。
opt_errorCallback: 用于处理错误或获取文件系统的请求遭到拒绝时可选的回调,其参数为 FileError 对象。
如果你是首次调用 requestFileSystem(),系统会为你的应用创建新的存储。请注意,这是沙箱文件系统,也就是说,一个网络应用无法访问另一个应用的文件。
在访问文件系统之后,可以对文件和目录执行大多数标准操作。
与其他存储类型相比,文件系统是一个完全不同的存储类型,因为它的旨在满足数据库,很不能很好地服务的客户端存储用例。通常,这些应用程序处理大型二进制blob或与浏览器上下文之外的应用程序共享数据。
以下使用文件系统 API 的几个示例:
-
有上传的应用
-
当你选择一个文件或目录进行上传时,你可以赋值文件到一个本地沙盒并一次上传一个块。
-
应用可以在一次中断后重新上传,中断可能包括浏览器被关闭或崩溃,连接中断,或电脑被关闭。
-
视频游戏或其他使用大量媒体资源的应用
-
用下载一个或多个大压缩包并在本地将他们解压到一个文件目录中。
-
应用能在后台预取资源,从而让用户能够进入下一项工作或游戏等级,而不需要等待下载。
-
音频或照片编辑器使用线下访问或本地缓存
-
应用可以分段写入文件(例如只覆盖ID3/EXIF标签而不是整个文件)。
-
线下视频浏览
-
应用可以访问只下载了部分的文件。
-
线下网络邮件客户端
-
客户端下载附件并在本地存储它们。
-
客户端缓存附件用于稍后的上传。
目前浏览器对文件系统 API 的支持:

Local storage

只读的 localStorage 允许你访问一个 Document 的远端(origin)对象 Storage;其存储的数据能在跨浏览器会话保留。 localStorage 类似 sessionStorage,其区别在于:存储在 localStorage 的数据可以长期保留;而当页面会话结束——也就是说当页面被关闭时,存储在 sessionStorage 的数据会被清除 。
应注意无论数据存储在 localStorage 还是 sessionStorage ,它们都特定于页面的协议。
另外,localStorage 中的键值对总是以字符串的形式存储。
当前浏览器对API的支持:

Session storage

sessionStorage 属性允许你访问一个 session Storage 对象。它与 localStorage 相似,不同之处在于 localStorage 里面存储的数据没有过期时间设置,而存储在 sessionStorage 里面的数据在页面会话结束时会被清除。页面会话在浏览器打开期间一直保持,并且重新加载或恢复页面仍会保持原来的页面会话。在新标签或窗口打开一个页面时会在顶级浏览上下文中初始化一个新的会话,这点和 session cookies 的运行方式不同。
应该注意的是,无论是 localStorage 还是 sessionStorage 中保存的数据都仅限于该页面的协议。
当前浏览器对API的支持:

Cookies

HTTP Cookie(也叫Web Cookie或浏览器Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
Cookie主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
* 浏览器行为跟踪(如跟踪分析用户行为等)
Cookie曾一度用于客户端数据的存储,因当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie渐渐被淘汰。由于服务器指定Cookie后,浏览器的每次请求都会携带Cookie数据,会带来额外的性能开销(尤其是在移动环境下)。
cookie 类型有两种:
-
会话 Cookie — 浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。会话期Cookie不需要指定过期时间(Expires)或者有效期(Max-Age)。需要注意的是,有些浏览器提供了会话恢复功能,这种情况下即使关闭了浏览器,会话期Cookie也会被保留下来,就好像浏览器从来没有关闭一样。
-
持久 Cookie — 和关闭浏览器便失效的会话期Cookie不同,持久性Cookie可以指定一个特定的过期时间(Expires)或有效期(Max-Age)。
当机器处于不安全环境时,切记不能通过HTTP Cookie存储、传输敏感信息,且所有浏览器都广泛支持cookie。
Cache

Cache 接口为缓存的 Request/Response 对象对提供存储机制,例如,作为 ServiceWorker 生命周期的一部分。请注意,Cache 接口像 workers 一样,是暴露在 window 作用域下的。尽管它被定义在 service worker 的标准中, 但是它不必一定要配合 service worker 使用.
一个域可以有多个命名 Cache 对象。你需要在你的脚本 (例如,在 ServiceWorker 中)中处理缓存更新的方式。除非明确地更新缓存,否则缓存将不会被更新;除非删除,否则缓存数据不会过期。使用 CacheStorage.open(cacheName) 打开一个Cache 对象,再使用 Cache 对象的方法去处理缓存.
你需要定期地清理缓存条目,因为每个浏览器都硬性限制了一个域下缓存数据的大小。缓存配额使用估算值,可以使用 StorageEstimate API 获得。浏览器尽其所能去管理磁盘空间,但它有可能删除一个域下的缓存数据。浏览器要么自动删除特定域的全部缓存,要么全部保留。确保按名称安装版本缓存,并仅从可以安全操作的脚本版本中使用缓存。查看 Deleting old caches 获取更多信息.
CacheStorage 接口表示 Cache 对象的存储。
-
它提供了一个 ServiceWorker,其它类型worker或者 window 范围内可以访问到的所有命名cache的主目录(它并不是一定要和 service workers 一起使用,即使它是在 service workers 规范中定义的),并维护一份字符串名称到相应 Cache 对象的映射。
-
使用 CacheStorage.open() 获取 Cache 实例。
-
使用 CacheStorage.match() 检查给定的 Request 是否是 CacheStorage 对象跟踪的任何 Cache 对象中的键。
你可以通过 caches 属性访问 CacheStorage .
IndexedDB

IndexedDB 是一种在用户浏览器中持久存储数据的方法。因为它允许你创建具有丰富查询功能的 Web 应用程序,无论网络可用性如何,这些应用程序都可以在线和离线工作。IndexedDB 对于存储大量数据的应用程序(例如,借出库中的 DVD 目录)和不需要持久 internet 连接才能工作的应用程序(例如,邮件客户机、待办事项列表和记事本)非常有用。
在本文中,会更详细地讨论存储数据库,因为其余的存储 Api 都是众所周知的。另外,随着 Web 应用程序的复杂性越来越高,IndexedDB 也越来越受欢迎。
IndexedDB的内部结构
IndexedDB 通过“键”来存储和检索对象。对数据库所做的所有更改都发生在事务中,像大多数 Web 存储解决方案一样,IndexedDB 遵循同源策略。因此,虽然可以访问域中存储的数据,但是不能跨不同的域访问数据。
IndexedDB 是一个 异步 API,可以在大多数上下文中使用,包括 WebWorkers。它过去也包括一个同步版本,供 Web 开发者使用,但是由于 Web 社区对它缺乏兴趣,所以从规范中删除了这个版本。
IndexedDB 曾经有一个与之竞争的规范,称为 WebSQL 数据库,但是 W3C 弃用了它。虽然 IndexedDB 和WebSQL 都是存储解决方案,但它们提供的功能不同。WebSQL 数据库是一个关系数据库访问系统,而IndexedDB 是一个索引表系统。
不要一开始就使用 IndexedDB,这依赖于你对其他类型数据库的假设。相反,应该仔细阅读文档,以下是一些需要牢记的基本概念:
-
IndexedDB 数据库使用 key-value 键值对储存数据 — values 数据可以是结构非常复杂的对象,key可以是对象自身的属性。你可以对对象的某个属性创建索引(index)以实现快速查询和列举排序。key可以是二进制对象。
-
IndexedDB 是事务模式的数据库 — 任何操作都发生在事务(transaction)中。 IndexedDB API提供了索引(indexes)、表(tables)、指针(cursors)等等,但是所有这些必须是依赖于某种事务的。因此,你不能在事务外执行命令或者打开指针。事务(transaction)有生存周期,在生存周期以后使用它会报错。并且,事务(transaction)是自动提交的,不可以手动提交。
-
The IndexedDB API 基本上是异步的 — IndexedDB 的 API 不通过 return 语句返回数据,而是需要你提供一个回调函数来接受数据。执行 API 时,你不以同步(synchronous)方式对数据库进行“存储”和“读取”操作,而是向数据库发送一个操作“请求”。当操作完成时,数据库会以DOM事件的方式通知你,同时事件的类型会告诉你这个操作是否成功完成。这个过程听起来会有些复杂,但是里面是有明智的原因的。这个和 XMLHttpRequest 请求是类似的。
-
IndexedDB数据库“请求”无处不在 — 每一个“请求”都包含
onsuccess和onerror事件属性,同时你还对 “事件” 调用addEventListener()和removeEventListener()。“请求” 还包括readyState,result和errorCode属性,用来表示“请求”的状态。result属性尤其神奇,他可以根据“请求”生成的方式变成不同的东西,例如:IDBCursor 实例、刚插入数据库的数值对应的键值(key)等。 -
IndexedDB是面向对象的 — indexedDB 不是用二维表来表示集合的关系型数据库,这一点非常重要,将影响你设计和建立你的应用程序。
-
indexedDB 不使用结构化查询语言(SQL) — 它通过索引(index)所产生的指针(cursor)来完成查询操作,从而使你可以迭代遍历到结果集合。如果你不熟悉NoSQL系统,可以参考维基百科相关文章。
-
IndexedDB遵循同源(same-origin)策略 — “源”指脚本所在文档URL的域名、应用层协议和端口。每一个“源”都有与其相关联的数据库。在同一个“源”内的所有数据库都有唯一、可区别的名称。
IndexedDB局限性
以下情况不适合使用IndexedDB
- 全球多种语言混合存储。国际化支持不好。需要自己处理。
- 和服务器端数据库同步。你得自己写同步代码。
- 全文搜索。IndexedDB 接口没有类似 SQL 语句中 LIKE 的功能。
注意,在以下情况下,数据库可能被清除:
- 用户请求清除数据。
- 浏览器处于隐私模式。最后退出浏览器的时候,数据会被清除。
- 硬盘等存储设备的容量到限。
- 数据损坏。
- 进行与特性不兼容的操作。
- 确切的环境和浏览器特性会随着时间改变,但浏览器厂商通常会遵循尽最大努力保留数据的理念。
确切的环境和浏览器特性会随着时间改变,但浏览器厂商通常会遵循尽最大努力保留数据的理念。

选择正确的存储API
如前所述,最好选择尽可能多的浏览器广泛支持的 Api,并提供异步调用模型,以最大限度地提高 UI 响应能力。这些标准自然会导致以下技术选择:
-
对于离线存储,请使用 Cache API。任何支持创建离线应用程序所需的 Service Worker technology 的浏览器都可以使用这个 API,Cache API 非常适合存储与已知 URL 关联的资源。
-
要存储应用程序状态和用户生成的内容,请使用IndexedDB。这使得用户可以在更多的浏览器中离线工作,而不仅仅是那些支持缓存API的浏览器。
原文:
这篇主要一些内容原作者大部分是通过 MDN 整理的组合的,我也是根据中文的 MND 整理的组合。
你的点赞是我持续分享好东西的动力,欢迎点赞!
####欢迎加入前端大家庭,里面会经常分享一些技术资源。
